前面幾篇遇到updateQueue的時候,我們把它先簡單的當成了一個隊列處理,這篇我們來詳細討論一下這個更新隊列。 有關updateQueue中的部分,可以見源碼??UpdateQueue實現
Update對象
我們先來看一下UpdateQueue中的內容,Update對象,其實現如下:
/** 更新的Action 可以是State 也可以是函數 */
export type Action<State> = State | ((prevState: State) => State);
/** 定義Dispatch函數 */
export type Dispatch<State> = (action: Action<State>) => void;/** 更新對象 */
export class Update<State> {next: Update<State>;action: Action<State>;lane: Lane; // 當前更新的優先級Laneconstructor(action: Action<State>, lane: Lane) {this.action = action;this.next = null;this.lane = lane;}
}
其中,包含
- action: Action對象,可以是任意類型,對應的我們在setState中傳入的參數,如果傳入一個函數,對應的是函數類型action,則運行函數得到狀態值。如果不是函數,則直接將其作為狀態值。
- lane: 當前更新對應的優先級lane
- next: 涉及到updateQueue的數據結構,指向下一個Update對象?
我們在很多地方都需要創建更新對象,比如dispatchSetState是,即你修改狀態的時候
 ?初始化的時候,在updateContainer中,也會創建update對象
?初始化的時候,在updateContainer中,也會創建update對象
updateQueue - 環形鏈表?
updateQueue本質上是一個存儲Update對象的數據結構,但是其不是一個普通的數組,其內部實現了一個環形鏈表用來存儲Update對象,其定義如下
export class UpdateQueue<State> {shared: {pending: Update<State> | null;};/** 派發函數 */dispatch: Dispatch<State>;/** 基礎隊列 */baseQueue: Update<State> | null;/** 基礎state */baseState: State;
...
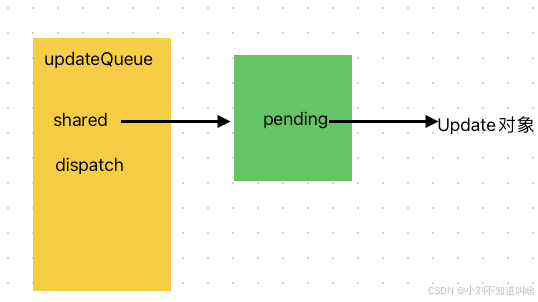
}其內部包含shared屬性,指向一個對象,對象中包含pending對象,指向Update對象,如下圖所示
其中,Update對象的next指針指向下一個Update對象,其組成一個環形鏈表,如圖所示:
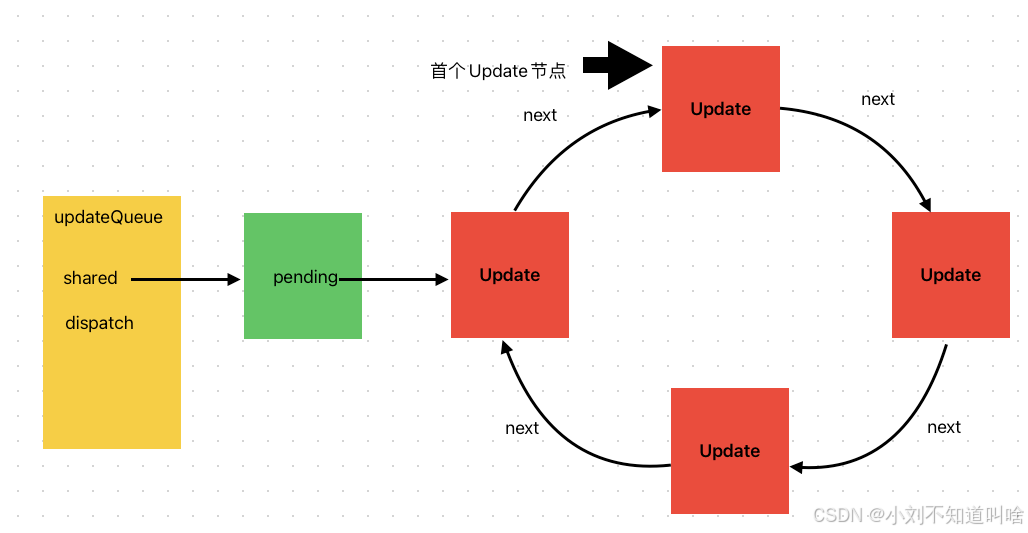
其中:
- updateQueue.shared.pending指向最后一個Update節點
- updateQueue.shared.pending.next 為第一個Update節點?
?為什么使用環形鏈表?
這里使用環形鏈表的一個好處是,其可以很方便的找到首位元素,可以方便的遍歷鏈表,也可以方便的對兩個鏈表進行拼接,這個在后面的baseQueue 和 baseState邏輯中會用到。
?enqueue入隊
enqueue為UpdateQueue的類方法,其作用就是給隊列插入Update對象,其實現如下:
/** 入隊,構造環狀鏈表 */enqueue(update: Update<State>, fiber: FiberNode, lane: Lane) {if (this.shared.pending === null) {// 插入第一個元素,此時的結構為// shared.pending -> firstUpdate.next -> firstUpdateupdate.next = update;this.shared.pending = update;} else {// 插入第二個元素update.next = this.shared.pending.next;this.shared.pending.next = update;this.shared.pending = update;}/** 在當前的fiber上設置lane */fiber.lanes = mergeLane(fiber.lanes, lane);/** 在current上也設置lane 因為在beginwork階段 wip.lane = NoLane 如果bailout 需要從current恢復 */const current = fiber.alternate;if (current) {current.lanes = mergeLane(current.lanes, lane);}}我們用一個插入隊列來演示插入過程:
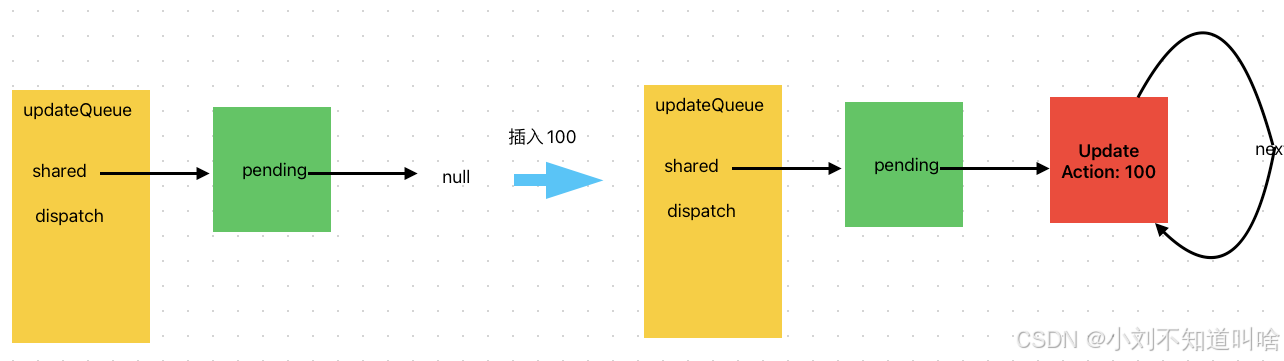
// 假設有插入隊列
enqueue(100)
enqueue(current => current + 1)
enqueue(200)插入100, 100對應的pending.next指向自己,此時100對應的Update又是首節點也是尾節點
插入curr=>curr+1的update節點,此時首節點為pending.nexy也就是 curr=>curr+1 尾節點為100
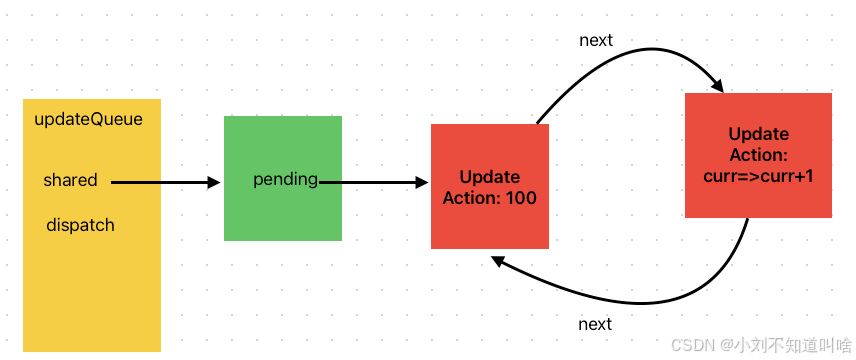
插入200節點,此時首節點為200 尾節點為100 都是從pending.next的位置插入,如圖
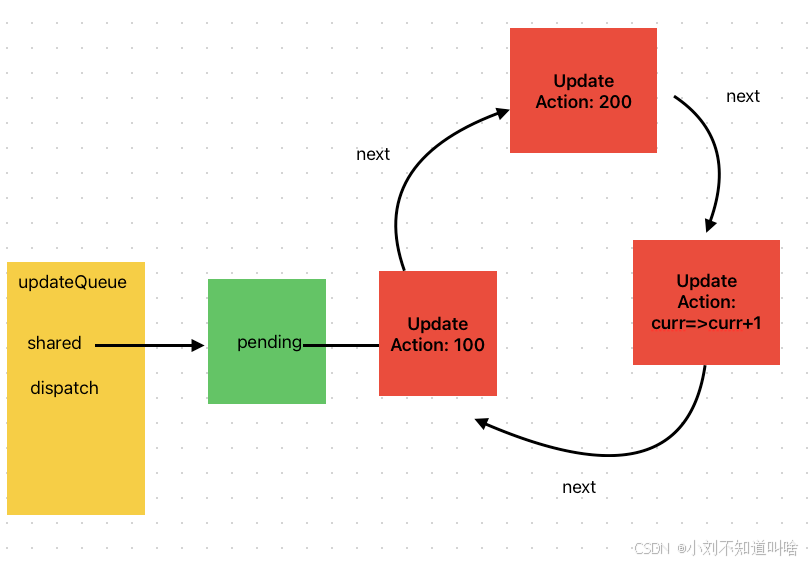
設置lane
enqueue方法除了傳入更新對象,還需要傳入更新所發生在的Fiber對象和對應的更新lane,其目的是在當前更新的Fiber上記錄lane,其邏輯如下:
/** 在當前的fiber上設置lane */fiber.lanes = mergeLane(fiber.lanes, lane);/** 在current上也設置lane 因為在beginwork階段 wip.lane = NoLane 如果bailout 需要從current恢復 */const current = fiber.alternate;if (current) {current.lanes = mergeLane(current.lanes, lane);}可以看到,當前更新的fiber節點的alternate節點的lanes也被設置了,這是為了先保存當前的lanes方便后面中短渲染 如bailout的時候能恢復當前fiber的lanes
processQueue - 處理更新
process函數的作用就是處理當前隊列的所有更新,在不考慮優先級的情況下,其實現可以簡化為如下代碼:
/** 處理任務 */process() {// 當前遍歷到的updatelet memorizedState;let currentUpdate = this.baseQueue?.next;if (currentUpdate) {do {const currentAction = currentUpdate.action;if (currentAction instanceof Function) {/** Action是函數類型 運行返回newState */memorizedState = currentAction(memorizedState);} else {/** 非函數類型,直接賦給新的state */memorizedState = currentAction;}currentUpdate = currentUpdate.next;} while (currentUpdate !== this.baseQueue?.next);}return memorizedState;}即循環遍歷整個環狀鏈表,對action的類型進行檢測,如果是函數則運行,如果是非函數直接把ation賦給memorizedState,最后將memorizedState返回即可!?
引入優先級lane
如果加入優先級lane的處理邏輯,process的處理邏輯會稍微有些復雜,我們看個例子
onClick={()=>{// 同步更新Lane = 1setvariable(100)startTransition(()=>{// 可以理解為 創建一個優先級lane=8的UpdatesetVariable(curr=>curr+100) })// 同步更新Lane = 1setVariable(curr => curr + 100)}}在一個onClick函數中,我們設置了三次setVariable函數,其中,第二次setter使用startTranstion包裹,這個函數由useTranstion hook提供,這個后面再講,你可以先理解為,在這個startTransition包裹的setter對應的優先級都會被改成 8 即可 TransitionLane
此時,variable hook中的updateQueue對應的shared.pending隊列如下:

由于隊列中的優先級不同,我們一次只處理一個優先級的Update對象,對于其他優先級的對象需要進行跳過。
但是需要注意,被我們跳過的更新需要在后面的更新中被執行,并且,雖然我們通過優先級把一次更新拆分成了兩次更新,但是最終的結果需要是一樣的。
比如,第一次更新?
執行 action 100
跳過 curr=>curr+100 并且記住此時的狀態100
執行curr => curr + 200
此時的結果為 300
第二次更新,需要從上次執行到的位置重新執行
執行curr=>curr+100 結果為200
執行 curr=>curr+200 (雖然此Update執行過了,但是為了保證結果一致,還需執行)結果為400
注意,雖然拆成了兩次更新,但是最終更新的結果一定是和不加startTranstion按順序執行的結果一樣的!
這樣我們就可以把高耗時的更新操作設置低優先級,先處理低耗時的更新,同時保證最終結果不變。
實現這樣邏輯的算法如下:
準備一個memorizedState,記錄當前updateQueue的狀態值
準備一個baseState 用來記錄第一個 跳過第一個Update時的狀態值
準備一個baseQueue,用來記錄本次更新跳過的更新對象?和 跳過更新之后的更新對象, 下一次更新就用這個baseQueue中的Update
遍歷隊列元素,使用isSubsetOfLanes來判斷當前Update.lane是不是等于當前正在更新的lane(wipRenderedLane)
如果是則看baseQueue隊列
? ?如果baseQueue隊列為空,?則執行action,給memorizedState賦值
? ?如果baseQueue隊列不為空, 則說明當前更新前面,已經有跳過的Update被加入到baseQueue了,那么其后面所有的Update對象都要加入baseQueue,則把當前Update對象克隆一份,并且設置優先級為Nolanes,以保證下次更細當前Update一定能被執行,推入baseQueue
并且,由于當前Update的lane是滿足的,需要執行action,更新memorizedState
如果不是, 看updateQueue隊列
?如果隊列為空,此時為第一個跳過的Update對象,把當前的Update對象克隆一 份push到baseQueue中,并且把當前memorizedState賦給baseState,記錄本次更新第一個跳過Update對應的狀態,下次更新就從此開始
如果隊列不為空,和上面一樣,區別就是不賦baseState了,注意baseState只有第一次更新才設置
最后返回 memorizedState 并且把baseState baseQueue記錄在當前updateQueue對象上,復習一下UpdateQueue的ts定義。
export class UpdateQueue<State> {shared: {pending: Update<State> | null;};/** 派發函數 */dispatch: Dispatch<State>;/** 基礎隊列 */baseQueue: Update<State> | null;/** 基礎state */baseState: State; ... }
下面我們畫圖來解釋一下 Update隊列如下:
Update List
[action: 100,lane: 1]
[action: curr => curr + 100, lane: 8]
[action: curr = curr+ 200,lane: 1]此時的updateQueue和狀態如下:?
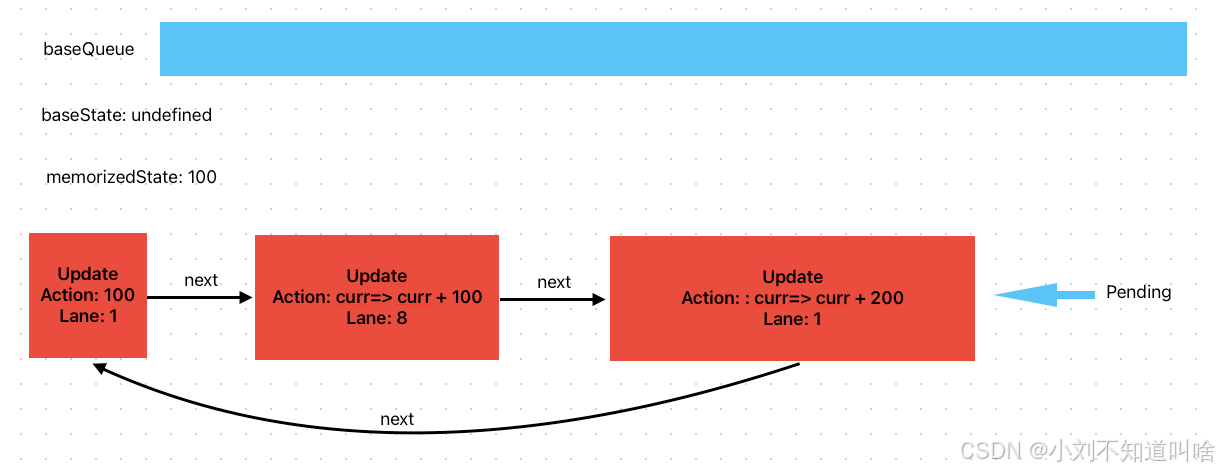
此時的root.pendinglanes 包含lane1 和 lane8 即SyncLane和TranstionLane
開始更新最高的優先級lane1?, 處理第一個Update,由于滿足優先級,直接計算并且更新memorizedState = 100
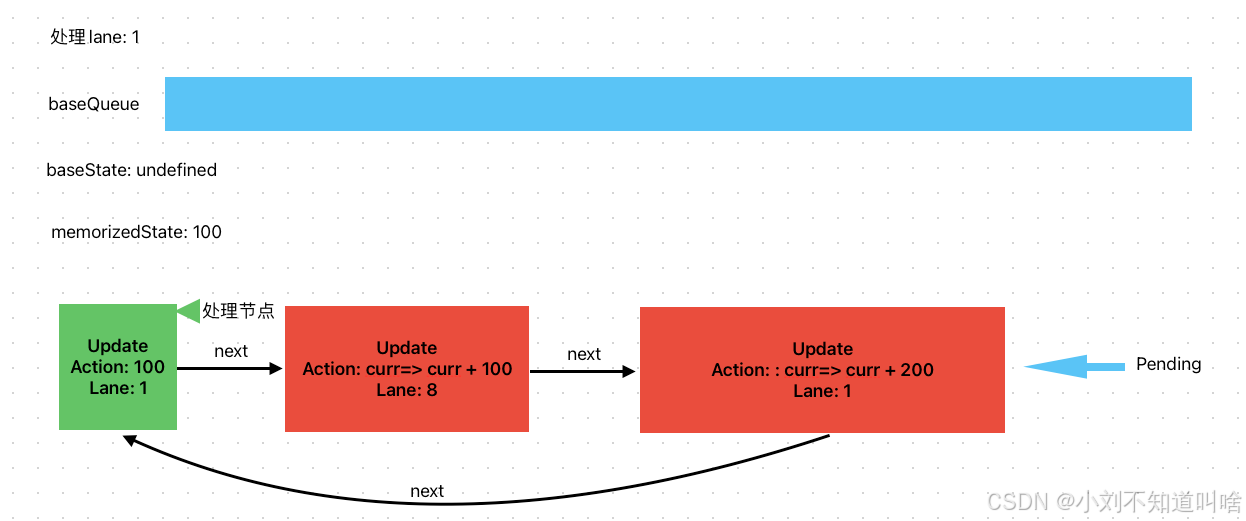
繼續處理到curr=>curr+100 此時lane=8 需要跳過,但是此時baseQueue為空,為第一個跳過的更新,需要baseState記錄跳過之前的memorizedState = 100,并且克隆一份Update 推入baseQueue
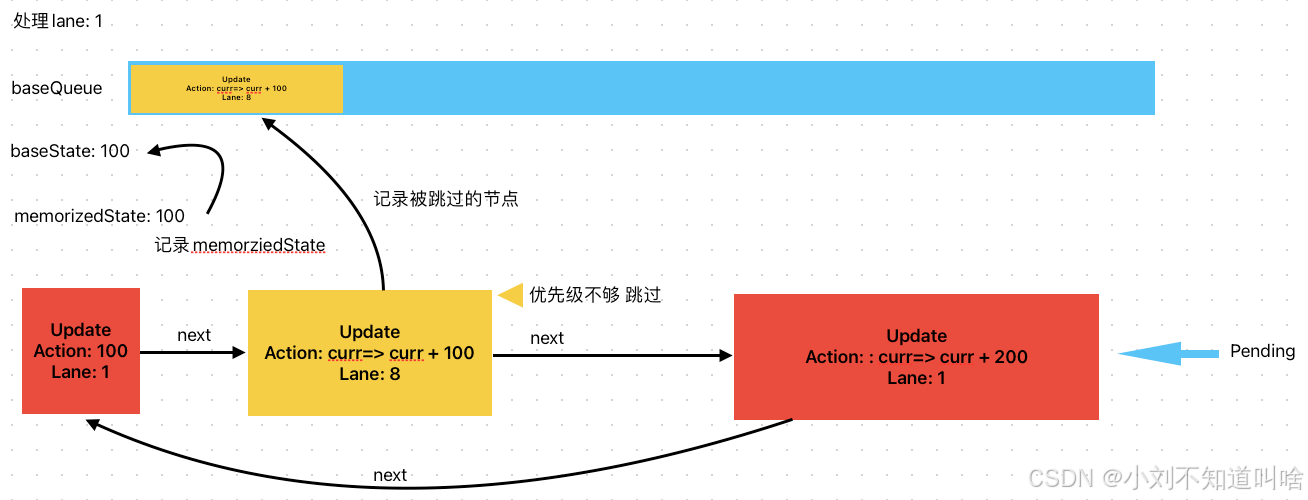 ?
?
繼續處理curr=>curr+200 此時滿足lane=1 但是由于baseQueue已經不為空,則后面所有的Update無論什么優先級,都需要克隆一份Update對象并且設置lanes為NoLane 推入baseQueue
同時需要計算action更新memorizedState為300
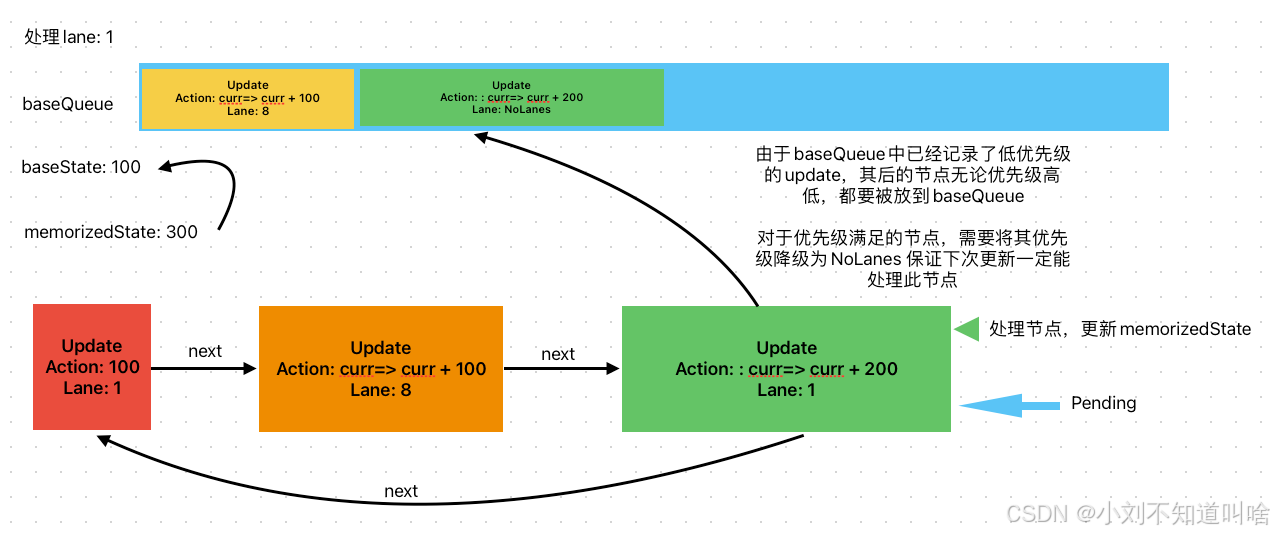 ?
?
第一輪更新結束,此時狀態為300,保存baseState和baseQueue并且刪除shared.pending隊列,因為已經用不上了。
第二輪更新 lane=8 此時從baseQueue中取出上次跳過的更新,繼續處理,此時memorizedState被baseState初始化為100
 ?處理第一個更新,此時memorizedState=200
?處理第一個更新,此時memorizedState=200
處理第二個更新,由于是任意Lanes&NoLanes === NoLanes 所以第二個update也滿足優先級,更新memorizedState=400 此時完成更新?
 ?最終結果為400
?最終結果為400
兩次更新,第一次更新值為300 第二次更新值為400 做到了過渡的作用
如果頁面中包含邏輯,如果variable === 400 則渲染10000個li 此時如果不用startTranstion降低優先級,則更新variable到400的那次更新的優先級lane=1 那么此時如果有更高優先級任務來,則此次lane=1的更新無法被打斷,導致頁面卡住不動 影響用戶體驗。
如果更新到400的更新優先級為8 那么當更高優先級更新來的時候,此次大規模的更新會被打斷,優先執行更高優先級更新(比如用戶事件) 在高優先級任務執行完成之后,再執行這個大規模更新渲染,優化了用戶體驗!
連接baseQueue和pending
每一輪更新之后,pending對應的update環會被清空,但是當處理本次更新的時候,又有新的update被掛上,此時baseQueue和pending都有值
比如,在某次更新的useEffect中,設置了setVariable 此時的更新隊列中又有新的更新了
此時就需要把baseQueue隊列和pending隊列連接,baseQueue隊列在前
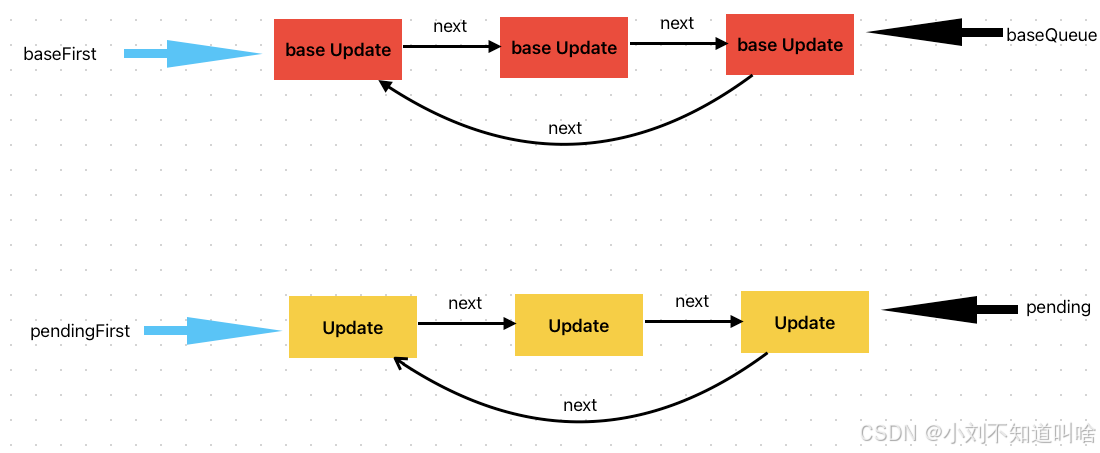
需要定義兩個變量 baseFirst 和 pendingFirst 分別指向baseQueue和pending的對頭,因為改變過pending/baseQueue.next 之后 就無法直接找到隊頭元素
第一步 設置baseQueue.next = pendingFirst 把baseQueue尾和pending頭連接 如圖
 ?第二步?Pending.next = baseFirst 此時pending隊列的尾和baseQueue頭連接 如圖
?第二步?Pending.next = baseFirst 此時pending隊列的尾和baseQueue頭連接 如圖
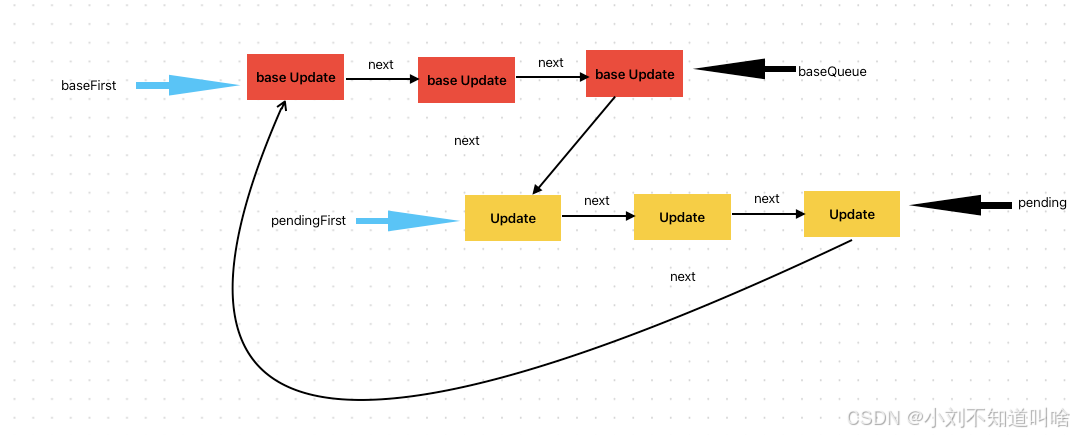
此時 baseFirst 就是整個隊列的頭部了
說完了原理,我們看一下process方法的完整實現:
/** 處理任務 */process(renderLane: Lane, onSkipUpdate?: (update: Update<any>) => void) {/** 獲取baseQueue pending 完成拼接 */let baseState = this.baseState;let baseQueue = this.baseQueue;const currentPending = this.shared.pending;// 生成新的baseQueue過程if (currentPending !== null) {if (baseQueue !== null) {// 拼接兩個隊列// pending -> p1 -> p2 -> p3const pendingFirst = currentPending.next; // p1// baseQueue -> b1->b2->b3const baseFirst = baseQueue.next; // b1// 拼接currentPending.next = baseFirst; // p1 -> p2 -> p3 -> pending -> b1 -> b2 -> b3baseQueue.next = pendingFirst; //b1-> b2 -> b3 -> baseQueue -> p1 -> p2 -> p3// p1 -> p2 -> p3 -> pending -> b1 -> b2 -> b3 baseQueue}// 合并 此時 baseQueue -> b1 -> b2 -> b3 -> p1 -> p2 -> p3baseQueue = currentPending;// 覆蓋新的baseQueuethis.baseQueue = baseQueue;// pending可以置空了this.shared.pending = null;}// 消費baseQueue過程// 設置新的basestate和basequeuelet newBaseState: State = baseState;let newBaseQueueFirst: Update<State> | null = null;let newBaseQueueLast: Update<State> | null = null;// 新的計算值let memorizedState: State = baseState;// 當前遍歷到的updatelet currentUpdate = this.baseQueue?.next;if (currentUpdate) {do {const currentUpdateLane = currentUpdate.lane;// 看是否有權限if (isSubsetOfLanes(renderLane, currentUpdateLane)) {// 有權限if (newBaseQueueFirst !== null) {// 已經存在newBaseFirst 則往后加此次的update 并且將此次update的lane設置為NoLane 保證下次一定能運行const clone = new Update(currentUpdate.action, NoLane);newBaseQueueLast = newBaseQueueLast.next = clone;}if (currentUpdate.hasEagerState) {memorizedState = currentUpdate.eagerState;} else {// 不論存不存在newBaseFirst 都要計算memorizedStateconst currentAction = currentUpdate.action;if (currentAction instanceof Function) {/** Action是函數類型 運行返回newState */memorizedState = currentAction(memorizedState);} else {/** 非函數類型,直接賦給新的state */memorizedState = currentAction;}}} else {// 無權限const clone = new Update(currentUpdate.action, currentUpdate.lane);if (onSkipUpdate) {onSkipUpdate(clone);}// 如果newBaseQueueFirst === null 則從第一個開始添加newbaseQueue隊列if (newBaseQueueFirst === null) {newBaseQueueFirst = newBaseQueueLast = clone;// newBaseState到此 不在往后更新 下次從此開始newBaseState = memorizedState;} else {newBaseQueueLast = newBaseQueueLast.next = clone;}}currentUpdate = currentUpdate.next;} while (currentUpdate !== this.baseQueue?.next);}if (newBaseQueueFirst === null) {// 此次沒有update被跳過,更新newBaseStatenewBaseState = memorizedState;} else {// newbaseState不變 newBaseQueueFirst newBaseQueueLast 成環newBaseQueueLast.next = newBaseQueueFirst;}// 保存baseState和BaseQueuethis.baseQueue = newBaseQueueLast;this.baseState = newBaseState;return { memorizedState };}?
![[SQL] 事務的四大特性(ACID)](http://pic.xiahunao.cn/[SQL] 事務的四大特性(ACID))




:科技新紀元的領航者)

,64G顯存微調13b模型)

)




)
-BFS廣度優先遍歷)



