9.1目標檢測
場景描述
-
目標檢測(Object Detection)任務是計算機視覺中極為重要的基礎問題,也是解決實例分割(Instance Segmentation)、場景理解(Scene Understanding)、目標跟蹤(ObjectTracking)、圖像標注(Image Captioning)等問題的基礎。
-
目標檢測,顧名思義,就是檢測輸入圖像中是否存在給定類別的物體,如果存在,則輸出物體在圖像中的位置信息。這里的位置信息通常用矩形邊界框(bounding box)的坐標值來表示。
-
物體檢測模型大致可以分為單階段(one-stage)模型和兩階段(two-stage)模型兩大類。
-
本節分析和對比了這兩類模型在架構、性能和效率上的差異,給出了原理解釋,并介紹了其各自的典型模型和發展前沿,以幫助讀者對物體檢測領域建立一個較為全面的認識。
知識點
物體檢測、單步模型、兩步模型、R-CNN系列模型、YOLO系列模型
9.1.1 簡述目標檢測領域中的單階段模型和兩階段模型的性能差異及其原因
-
單階段模型:
-
單階段模型是指沒有獨立地、顯式地提取候選區域(region proposal),直接由輸入圖像得到其中存在的物體的類別和位置信息的模型。
-
典型的單階段模型有
- OverFeat[1]、
- SSD(Single Shotmultibox-Detector)[2]、
- YOLO(You Only Look Once)[3-5]系列模型等。
-
兩階段模型:
-
兩階段模型有獨立的、顯式的候選區域提取過程,即先在輸入圖像上篩選出一些可能存在物體的候選區域,然后針對每個候選區域,判斷其是否存在物體,如果存在,就給出物體的類別和位置修正信息。
-
典型的兩階段模型有
- R-CNN [6]
- SPPNet [7]
- Fast R-CNN[8]
- Faster R-CNN[9]
- R-FCN[10]
- Mask R-CNN[11]等
性能差異
圖9.1總結了目標檢測領域重一些典型模型(包括單階段和兩階段)的發展歷程(截止2017年年底)[12]。
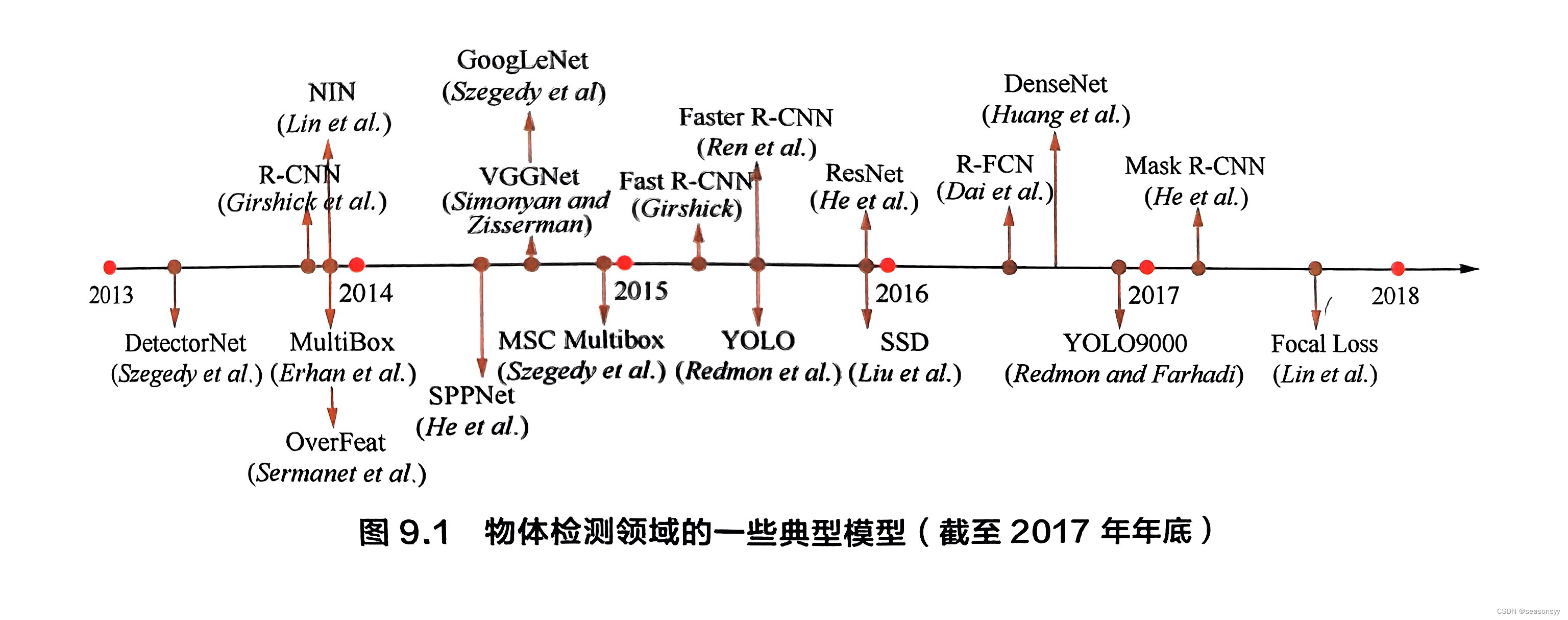
一般來說,單階段模型在計算效率上有優勢,兩階段模型在檢測精度上有優勢。
參考文獻[13]對比了Faster R-CNN和SSD等模型在速度和精度上的差異,如圖9.2所示。
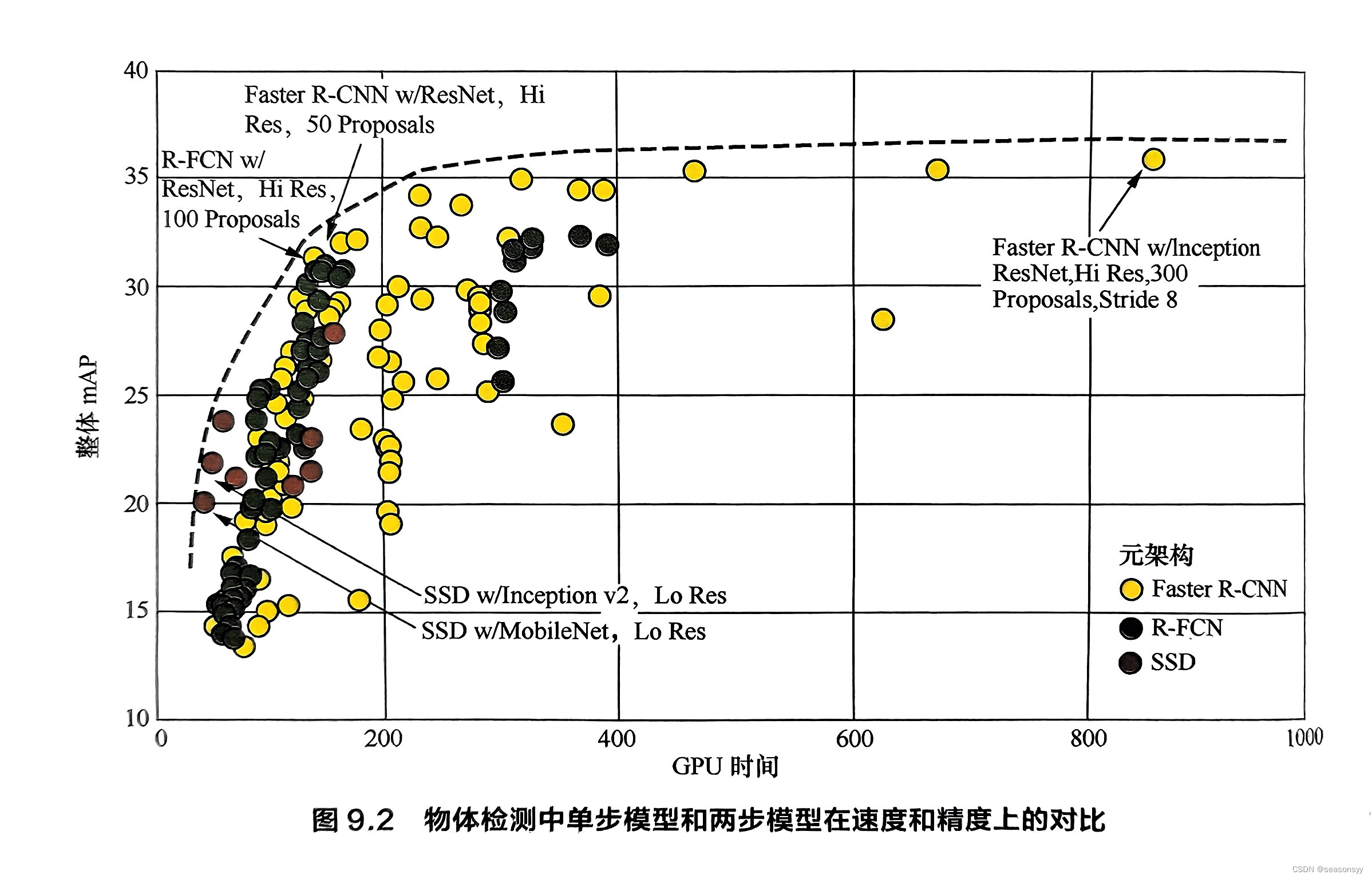
注:圖9.2中,SSD的顏色是棕色圓圈。R-FCN是深綠色圓圈。
可以看到:
當檢測時間較短時,單階段模型SSD能取得更高的精度;
而隨著檢測時間的增加,兩階段模型Faster R-CNN則在精度上取得優勢。
在速度和精度上的差異原因
對于單階段模型與兩階段模型在速度和精度上的差異,學術界一般認為有如下原因。
-
摘要:兩階段模型有獨立候選框提取步驟,所以到第二步分類和修正候選框的時候,正負樣本比例平衡。
單階段模型負樣本比例較大。
-
單階段模型:大多數單階段模型是利用**預設的錨框(Anchor Box)**來捕捉可能存在于圖像中各個位置的物體。
因此,單階段模型會對數量龐大的錨框進行是否含有物體及物體所屬類別的密集分類。
由于一幅圖像中實際含有的物體數目遠小于錨框的數目,因而在訓練這個分類器時正負樣本數目是極不均衡的,這會導致分類器訓練效果不佳。
RetinaNet(14)通過Focal Loss 來抑制負樣本對最終損失的貢獻以提升網絡的整體表現。
-
兩階段模型:在兩階段模型中,由于含有獨立的候選區域提取步驟,第一步就可以篩選掉大部分不含有待檢測物體的區域(負樣本),在傳遞給第二步進行分類和候選框位置/大小修正時,正負樣本的比例已經比較均衡,不存在類似的問題。
- 摘要:兩階段模型修正了兩次候選框,單階段模型沒有修正,所以單階段模型質量較差
-
兩階段模型:在候選區域提取的過程會對候選框的位置和大小進行修正,因此在進入第二步前,候選區域的特征已被對齊,這樣有利于為第二步的分類提供質量更高的特征。
另外,兩階段模型在第二步中候選框會被再次修正,因此一共修正了兩次候選框,這帶來了更高的定位精度,但同時也增加了模型復雜度。
-
單階段模型:沒有候選區域提取過程,自然也沒有特征對齊步驟,各錨框的預測基于該層上每個特征點的感受野,其輸入特征未被對齊,質量較差,因而定位和分類精度容易受到影響。
- 摘要:兩階段模型在第二部對候選框進行分類和回歸時,受累于大量候選框,所以兩階段模型存在計算量大、速度慢的問題。
-
兩階段模型:以Faster R-CNN為代表的兩階段模型在第二步對候選區域進行分類和位置回歸時,是針對每個候選區域獨立進行的,因此該部分的算法復雜度線性正比于預設的候選區域數目,這往往十分巨大,導致兩階段模型的頭重腳輕(heavy head)問題。
解決:近年來雖然有部分模型(如Light-Head R-CNN[15])試圖精簡兩階段模型中第二步的計算量,但較為常用的兩階段模型仍受累于大量候選區域,相比于單階段模型仍存在計算量大、速度慢的問題。
最新的一些基于
-
單階段模型的物體檢測方法有CornerNet[16]、RefineDet[17]、ExtremeNet[18]等
-
兩階段模型的物體檢測方法有PANet[19]、Cascade R-CNN[20]、Mask Score R-CNN[21]等
參考文獻:
[1]SERMANET P, EIGEN D, ZHANG X, et al. OverFeat: Integrated recognition,localization and detection using convolutional networks[J]. arXiv preprintarXiv:1312.6229,2013.
[2]LIU W,ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//European Conference on Computer Vision. Springer, 2016: 21-37.
[3]REDMON J,DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition, 2016: 779-788.
[4] REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition, 2017:7263-7271.
[5]REDMON J, FARHADI A. YOLOv3: An incremental improvement[J]. arXivpreprint arXiv:1804.02767,2018.
GIRSHICK R, DONAHU J,DARRELL T, et al. Rich feature hierarchies for[9]accurate object detection and semantic segmentation[C]//Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition, 2014:580-587.
[7] HE K,ZHANG X, REN S,et al. Spatial pyramid pooling in deep convolutionalnetworks for visual recognition[J]. IEEE Transactions on Pattern Analysisand Machine Intelligence, IEEE, 2015,37(9):1904-1916.
[8]GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE International Conferenceon Computer Vision, 2015: 1440-1448.
[9]REN S,HE K,GIRSHICK R, et al. Faster R-CNN: Towards real-time objectdetection with region proposal networks[C]//Advances in Neural InformationProcessing Systems, 2015:91-99.
[10] DAI J, LI Y, HE K, et al. R-FCN: Object detection via region-based fully convolutional networks[C]//Advances in Neural Information Processing Systems, 2016: 379-387.[11] HE K, GKIOXARI G, DOLLáR P, et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 2961-2969.
[12] LIU L, OUYANG W, WANG X, et al. Deep learning for generic object detection:A survey[J]. arXiv preprint arXiv:1809.02165,2018.
[13] HUANG J, RATHOD V, SUN C, et al. Speed/accuracy trade-offs for modernconvolutional object detectors[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, 2017: 7310-7311.
[14] LIN T-Y,GOYAL P,GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision,2017:2980-2988.
[15] LI Z, PENG C, YU G, et al. Light-head R-CNN: In defense of two-stage objectdetector[J].arXiv preprint arXiv:1711.07264,2017.
[16] LAW H, DENG J. CornerNet: Detecting objects as paired keypoints[C]//Proceedings of the European Conference on Computer Vision, 2018:734-750.
[17] ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network forobject detection[C]//Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, 2018: 4203-4212.
[18] ZHOU X, ZHUO J,KR?HENBüHL P. Bottom-up object detection by groupingextreme and center points[J]. arXiv preprnt arXiv:1901.08043,2019.
[19] LIU S, QI L,QIN H,et al. Path aggregation network for instance segmentation [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018:8759-8768.
[20] CAI Z, VASCONCELOS N. Cascade R-CNN: Delving into high qualityobject detection[C]//Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, 2018:6154-6162.
[21] HUANG Z,HUANG L, GONG Y,et al. Mask scoring R-CNN[C]//Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition,2019:6409-6418.
參考文獻:
《百面深度學習》 諸葛越 江云勝主編
出版社:人民郵電出版社(北京)
ISBN:978-7-115-53097-4
2020年7月第1版(2020年7月北京第二次印刷)
推薦閱讀:
//好用小工具↓
分享一個免費的chat工具
分享一個好用的讀論文的網站
// 深度學習經典網絡↓
LeNet網絡(1989年提出,1998年改進)
AlexNet網絡(2012年提出)
VGGNet網絡(2014年提出)
LeNet、AlexNet、VGGNet總結
GoogLeNet網絡(2014年提出)
ResNet網絡(2015年提出)





)
)


)








語法)
