????????為系統引入緩存之前,第一件事情是確認系統是否真的需要緩 存。從開發角度來說,引入緩存會提 高系統復雜度,因為你要考慮緩存的失效、更新、一致性等問題;從運維角度來說,緩存會掩蓋一些缺 陷,讓問題在更久的時間以后,出現在距離發生現場更遠的位置上; 從安全角度來說,緩存可能會泄漏某些保密數據,也是容易受到攻擊 的薄弱點。冒著上述種種風險,仍能說服你引入緩存的理由,總結起 來無外乎以下兩種。
- 為緩解CPU壓力而引入緩存:譬如把方法運行結果存儲起來、 把原本要實時計算的內容提前算好、對一些公用的數據進行復用,這 可以節省CPU算力,順帶提升響應性能。
- 為緩解I/O壓力而引入緩存:譬如把原本對網絡、磁盤等較慢 介質的讀寫訪問變為對內存等較快介質的訪問,將原本對單點部件 (如數據庫)的讀寫訪問變為對可擴縮部件(如緩存中間件)的訪 問,順帶提升響應性能。
????????請注意,緩存雖然是典型以空間換時間來提升性能的手段,但它 的出發點是緩解CPU和I/O資源在峰值流量下的壓力,“順帶”而非 “專門”地提升響應性能。這里的言外之意是如果可以通過增強CPU、 I/O本身的性能(譬如擴展服務器的數量)來滿足需要的話,那升級硬 件往往是更好的解決方案,即使需要一些額外的投入成本,也通常要 優于引入緩存后可能帶來的風險。
緩存屬性
????????有不少軟件系統最初的緩存功能是以HashMap或者 ConcurrentHashMap為起點演進的。當開發人員發現系統中某些資源的 構建成本比較高,而這些資源又有被重復使用的可能時,會很自然地 產生“循環再利用”的想法,將它們放到Map容器中,待下次需要時取 出重用,避免重新構建,這種原始樸素的復用就是最基本的緩存。不 過,一旦我們專門把“緩存”看作一項技術基礎設施,一旦它有了通 用、高效、可統計、可管理等方面的需求,其中要考慮的因素就變得 復雜起來。通常,我們設計或者選擇緩存至少會考慮以下四個維度的 屬性。
- 吞吐量:緩存的吞吐量使用OPS值(每秒操作數,Operation per Second,ops/s)來衡量,反映了對緩存進行并發讀、寫操作的效率, 即緩存本身的工作效率高低。
- 命中率:緩存的命中率即成功從緩存中返回結果次數與總請求 次數的比值,反映了引入緩存的價值高低,命中率越低,引入緩存的 收益越小,價值越低。
- 擴展功能:即緩存除了基本讀寫功能外,還提供哪些額外的管 理功能,譬如最大容量、失效時間、失效事件、命中率統計,等等。
- 分布式緩存:緩存可分為“進程內緩存”和“分布式緩存”兩 大類,前者只為節點本身提供服務,無網絡訪問操作,速度快但緩存 的數據不能在各服務節點中共享,后者則相反。
吞吐量
????????緩存的吞吐量只在并發場景中才有統計的意義,因為若不考慮并 發,即使是最原始的、以HashMap實現的緩存,訪問效率也已經是常量 時間復雜度(即O(1)),其中涉及碰撞、擴容等場景的處理屬于數據 結構基礎,這里不再展開。但HashMap并不是線程安全的容器,如果要 讓它在多線程并發下正確地工作,就要用 Collections.synchronizedMap進行包裝,這相當于給Map接口的所有 訪問方法都自動加全局鎖;或者改用ConcurrentHashMap來實現,這相 當于給Map的訪問分段加鎖(從JDK 8起已取消分段加鎖,改為 CAS+Synchronized鎖單個元素)。無論采用怎樣的實現方法,這些線 程安全措施都會帶來一定的吞吐量損失。
命中率與淘汰策略
????????有限的物理存儲決定了任何緩存的容量都不可能是無限的,所以 緩存需要在消耗空間與節約時間之間取得平衡,這要求緩存必須能夠 自動或者人工淘汰掉緩存中的低價值數據。考慮到由人工管理的緩存 淘汰主要取決于開發者如何編碼,不能一概而論,這里只討論由緩存 自動進行淘汰的情況。筆者所說的“緩存如何自動地實現淘汰低價值 目標”,現在被稱為緩存的淘汰策略。
????????在了解緩存如何實現自動淘汰低價值數據之前,首先要定義怎樣 的數據才算是“低價值”。由于緩存的通用性,這個問題的答案必須 是與具體業務邏輯無關的,只能從緩存工作過程收集到的統計結果來 確定數據是否有價值,通用的統計結果包括但不限于數據何時進入緩 存、被使用過多少次、最近什么時候被使用,等等。一旦確定選擇何 種統計數據,就決定了如何通用地、自動地判定緩存中每個數據的價 值高低,也相當于決定了緩存的淘汰策略是如何實現的。目前,最基 礎的淘汰策略實現方案有以下三種。
- FIFO(First In First Out):優先淘汰最早進入被緩存的數據。 FIFO的實現十分簡單,但一般來說它并不是優秀的淘汰策略,越是頻 繁被用到的數據,往往會越早存入緩存之中。如果采用這種淘汰策 略,很可能會大幅降低緩存的命中率。
- LRU(Least Recent Used):優先淘汰最久未被訪問過的數據。 LRU通常會采用HashMap加LinkedList的雙重結構(如LinkedHashMap) 來實現,以HashMap來提供訪問接口,保證常量時間復雜度的讀取性 能,以LinkedList的鏈表元素順序來表示數據的時間順序,每次緩存命 中時把返回對象調整到LinkedList開頭,每次緩存淘汰時從鏈表末端開 始清理數據。對大多數的緩存場景來說,LRU明顯要比FIFO策略合 理,尤其適合用來處理短時間內頻繁訪問的熱點對象。但是如果一些 熱點數據在系統中被頻繁訪問,只是最近一段時間因為某種原因未被 訪問過,那么這些熱點數據此時就會有被LRU淘汰的風險,換句話 說,LRU依然可能錯誤淘汰價值更高的數據。
- LFU(Least Frequently Used):優先淘汰最不經常使用的數據。 LFU會給每個數據添加一個訪問計數器,每訪問一次就加1,需要淘汰 時就清理計數器數值最小的那批數據。LFU可以解決上面LRU中熱點數 據間隔一段時間不訪問就被淘汰的問題,但同時它又引入了兩個新的 問題。第一個問題是需要對每個緩存的數據專門維護一個計數器,每 次訪問都要更新,但這樣做會帶來高昂的維護開銷;另一個問題是不 便于處理隨時間變化的熱度變化,譬如某個曾經頻繁訪問的數據現在 不需要了,但很難自動將它清理出緩存。
????????緩存的淘汰策略直接影響緩存的命中率,沒有一種策略是完美 的、能夠滿足系統全部需求的。不過,隨著淘汰算法的不斷發展,近 年來的確出現了許多相對性能更好、也更復雜的新算法。以LFU為例, 針對它存在的兩個問題,近年來提出的TinyLFU和W-TinyLFU算法就會 有更好的效果。
分布式緩存
????????相比緩存數據在進程內存中讀寫的速度,一旦涉及網絡訪問,由 網絡傳輸、數據復制、序列化和反序列化等操作所導致的延遲要比內 存訪問高得多,所以對分布式緩存來說,處理與網絡相關的操作是對 吞吐量影響更大的因素,往往也是比淘汰策略、擴展功能更重要的關 注點,這也決定了盡管有Ehcache、Infinispan這類能同時支持分布式 部署和進程內部署的緩存方案,但通常進程內緩存和分布式緩存選型 時會有完全不同的候選對象及考察點。在我們決定使用哪種分布式緩 存前,首先必須確定自己的需求是什么。
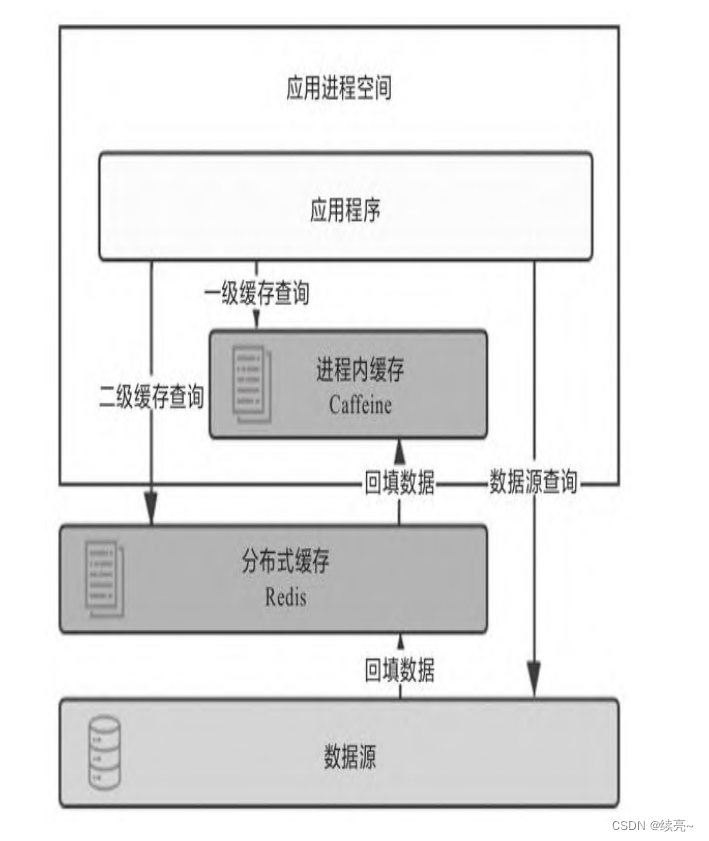
????????盡管多級緩存結合了進程內緩存和分布式緩存的優點,但它的代 碼侵入性較大,需要由開發者承擔多次查詢、多次回填的工作,也不 便于管理,如超時、刷新等策略都要設置多遍,數據更新更是麻煩, 很容易出現各個節點的一級緩存以及二級緩存中數據不一致的問題。 所以,必須“透明”地解決以上問題,才能使多級緩存具有實用的價 值。一種常見的設計原則是變更以分布式緩存中的數據為準,訪問以 進程內緩存的數據優先。大致做法是當數據發生變動時,在集群內發 送推送通知(簡單點的話可采用Redis的PUB/SUB,求嚴謹的話可引入 ZooKeeper或etcd來處理),讓各個節點的一級緩存中的相應數據自動 失效。當訪問緩存時,提供統一封裝好的一、二級緩存聯合查詢接 口,接口外部是只查詢一次,接口內部自動實現優先查詢一級緩存, 未獲取到數據再自動查詢二級緩存的邏輯。?
緩存風險
1.緩存穿透
????????緩存的目的是緩解CPU或者I/O的壓力,譬如對數據庫做緩存,大 部分流量都從緩存中直接返回,只有緩存未能命中的數據請求才會流 到數據庫中,這樣數據庫壓力自然就減小了。但是如果查詢的數據在 數據庫中根本不存在,緩存里自然也不會有,這類請求的流量每次都 不會命中,且每次都會觸及末端的數據庫,緩存就起不到緩解壓力的 作用了,這種查詢不存在的數據的現象被稱為緩存穿透。
????????緩存穿透有可能是業務邏輯本身就存在的固有問題,也有可能是 惡意攻擊所導致。為了解決緩存穿透問題,通常會采取下面兩種辦 法。
- 對于業務邏輯本身不能避免的緩存穿透,可以約定在一定時間 內對返回為空的Key值進行緩存(注意是正常返回但是結果為空,不 應把拋異常的也當作空值來緩存),使得在一段時間內緩存最多被穿 透一次。如果后續業務在數據庫中對該Key值插入了新記錄,那應當 在插入之后主動清理掉緩存的Key值。如果業務時效性允許的話,也 可以對緩存設置一個較短的超時時間來自動處理。
- 對于惡意攻擊導致的緩存穿透,通常會在緩存之前設置一個布 隆過濾器來解決。所謂惡意攻擊是指請求者刻意構造數據庫中肯定不 存在的Key值,然后發送大量請求進行查詢。布隆過濾器是用最小的 代價來判斷某個元素是否存在于某個集合的辦法。如果布隆過濾器給 出的判定結果是請求的數據不存在,直接返回即可,連緩存都不必去 查。雖然維護布隆過濾器本身需要一定的成本,但比起攻擊造成的資 源損耗仍然是值得的。
2.緩存擊穿
????????我們都知道緩存的基本工作原理是首次從真實數據源加載數據, 完成加載后回填入緩存,以后其他相同的請求就從緩存中獲取數據, 以緩解數據源的壓力。如果緩存中某些熱點數據忽然因某種原因失效 了,譬如由于超期而失效,此時又有多個針對該數據的請求同時發送 過來,這些請求將全部未能命中緩存,到達真實數據源中,導致其壓 力劇增,這種現象被稱為緩存擊穿。要避免緩存擊穿問題,通常會采 取下面兩種辦法。
- 加鎖同步,以請求該數據的Key值為鎖,使得只有第一個請求 可以流入真實的數據源中,對其他線程則采取阻塞或重試策略。如果 是進程內緩存出現問題,施加普通互斥鎖即可,如果是分布式緩存中 出現問題,就施加分布式鎖,這樣數據源就不會同時收到大量針對同 一個數據的請求了。
- 熱點數據由代碼來手動管理。緩存擊穿是僅針對熱點數據自動 失效才引發的問題,對于這類數據,可以直接由開發者通過代碼來有 計劃地完成更新、失效,避免由緩存的策略自動管理。
3.緩存雪崩
????????緩存擊穿是針對單個熱點數據失效,由大量請求擊穿緩存而給真 實數據源帶來壓力。還有一種可能更普遍的情況,即不是針對單個熱 點數據的大量請求,而是由于大批不同的數據在短時間內一起失效, 導致這些數據的請求都擊穿緩存到達數據源,同樣令數據源在短時間 內壓力劇增。 出現這種情況,往往是因為系統有專門的緩存預熱功能,或者大 量公共數據是由某一次冷操作加載的,使得由此載入緩存的大批數據 具有相同的過期時間,在同一時刻一起失效;也可能是因為緩存服務 由于某些原因崩潰后重啟,造成大量數據同時失效。這種現象被稱為 緩存雪崩。要避免緩存雪崩問題,通常會采取下面三種辦法。
- 提升緩存系統可用性,建設分布式緩存的集群
- 啟用透明多級緩存,這樣各個服務節點一級緩存中的數據通常 會具有不一樣的加載時間,也就分散了它們的過期時間。
- 將緩存的生存期從固定時間改為一個時間段內的隨機時間,譬 如原本是1h過期,在緩存不同數據時,可以設置生存期為55min到 65min之間的某個隨機時間。
4.緩存污染
緩存污染是指緩存中的數據與真實數據源中的數據不一致的現象。這種情況通常是由于開發者在更新緩存時操作不規范造成的,可能導致數據的不一致性。雖然緩存通常不追求強一致性,但最終一致性仍然是必須的。
造成緩存污染的常見原因
- 更新緩存不規范:開發者從緩存中獲得某個對象并更新其屬性,但由于某些原因(如業務異常回滾),最終未能成功寫入數據庫,導致緩存中的數據是新的,但數據庫中的數據是舊的。
- 操作順序錯誤:如果更新操作的順序不正確,例如先失效緩存后寫數據源,可能會導致緩存和數據源的不一致。
提高緩存一致性的設計模式
為了盡可能地提高使用緩存時的一致性,以下幾種常見的設計模式可以幫助管理緩存更新:
-
Cache Aside:
- 讀數據:先讀緩存,如果緩存中沒有,再讀數據源,然后將數據放入緩存,再響應請求。
- 寫數據:先寫數據源,然后失效緩存。
這種模式的關鍵在于:
- 先后順序:必須先寫數據源后失效緩存。如果先失效緩存后寫數據源,可能在緩存失效和數據源更新之間存在時間窗口,此時新的查詢請求會讀到舊的數據并重新填充到緩存中,導致數據不一致。
- 失效緩存:而不是嘗試更新緩存,因為更新過程中數據源可能會被其他請求再次修改,處理多次賦值的時序問題非常復雜。失效緩存可以避免這種情況,確保下次讀取時自動回填最新的數據。
-
Read/Write Through:
- 讀數據:先讀緩存,如果沒有,再讀數據源,并將數據寫入緩存。
- 寫數據:先寫緩存,再寫數據源。
這種模式保證了緩存和數據源的一致性,但實現起來比較復雜,可能會帶來性能開銷。
-
Write Behind Caching:
- 讀數據:先讀緩存,如果沒有,再讀數據源,并將數據寫入緩存。
- 寫數據:先寫緩存,然后異步地將數據寫入數據源。
這種模式通過異步更新數據源,提高了寫操作的性能,但在數據源更新的延遲期間,可能會導致數據不一致。
Cache Aside 模式的局限性
Cache Aside 模式雖然簡潔且成本低,但依然不能完全保證一致性。例如,當某個從未被緩存的數據請求直接流到數據源,如果數據源的寫操作發生在查詢請求之后但回填到緩存之前,緩存中回填的內容可能與數據庫的實際數據不一致。然而,這種情況的發生概率較低,Cache Aside 模式仍然是一個低成本且相對可靠的解決方案。
通過以上設計模式,可以在一定程度上減少緩存污染,確保緩存與數據源之間的一致性,但完全避免是不現實的,特別是在高并發和復雜業務場景下。




語法)



:requests模塊處理cookie)

)








