標題:MedSegDiff-V2: Diffusion-Based(基于擴散模型)Medical Image Segmentation(醫學圖像分割)with Transformer
論文(AAAI):https://ojs.aaai.org/index.php/AAAI/article/view/28418/28816
源碼:KidsWithTokens/MedSegDiff: Medical Image Segmentation with Diffusion Model (github.com)
一、摘要
研究背景:擴散概率模型(DPM)最近在計算機視覺領域獲得了流行,這得益于其圖像生成應用,如Imagen、潛擴散模型和穩定擴散,這些應用展示了令人印象深刻的能力,并在社區內引發了許多討論。最近的研究進一步揭示了 DPM 在醫學圖像分析領域的效用,醫學圖像分割模型在各種任務中表現出的良好性能強調了這一點。
研究問題:盡管這些模型最初是由UNet架構支撐的,但?存在通過集成視覺transformer機制來提高其性能的潛在途徑?。然而,本文發現?簡單地組合這兩個模型會導致性能不佳?。
主要工作:為了有效地將這兩種前沿技術集成到醫學圖像分割中,本文提出一種新的基于transformer的擴散框架,稱為MedSegDiffV2。
實驗效果:在具有不同圖像模態的20個醫學圖像分割任務上驗證了其有效性。通過綜合評估,所提出方法證明了比之前最先進的(SOTA)方法的優越性。
二、引言
三、相關工作
四、方法
A. Diffusion Process of MedSegDiff-V2?( MedSegDiff-v2的擴散過程 )
基于(Ho, Jain 和 Abbeel 2020) 中提到的擴散模型設計了本文的模型。擴散模型是由兩個階段組成的生成式模型:正向擴散階段和反向擴散階段。在正向過程中,通過一系列步驟 t 逐步將高斯噪聲添加到分割標簽??中。在反向過程中,通過訓練神經網絡實現逆轉噪聲添加過程恢復數據。可以用數學表達式表示如下:
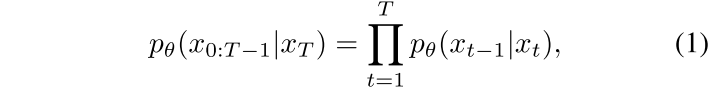
其中,θ 表示逆向過程中的參數。從高斯噪聲分布出發,,其中?
?是原始圖像,反向過程將潛變量分布?
?轉換為數據分布?
?。為了保持與前向過程的對稱性,反向過程逐步恢復噪聲圖像,最終獲得最終的清晰分割。
Q:什么是這里指的潛變量分布?
A:Latent variable distribution(潛變量分布)指的是在統計建模中用來描述未直接觀測到的、無法直接測量的變量的分布。
在本文和擴散模型中,Latent variable distribution(潛變量分布)常用來描述高斯噪聲和圖像加性后的數據分布,這是一個符合高斯分布的概率分布。
在DPM(擴散模型)的標準實現之后,本文利用編解碼器網絡進行學習。為了實現分割,本文以原始圖像的先驗信息為條件,采用步長估計函數?。這個條件可以表示為(這個公式是對整個模型的概述,包括模型的輸入,TransF模塊和解碼器的輸入):
![]()
這里,TransF 表示基于?transformer?的注意力機制。?表示條件特征嵌入,在本文中,它對應于原始圖像的嵌入。
?表示當前步驟的分割圖的特征嵌入。這兩個分量通過?transformer?合并在一起,并通過 UNet 解碼器?D?進行重建。步驟索引 t 與組合的嵌入和解碼器特征集成在一起,并且遵循(Ho,Jain,and Abbeel 2020)中描述的方法,使用共享的學習查找表來嵌入每個步驟索引。
B. Overall Architecture ( 整體架構 )
MedSegDiff-V2的整體流程如圖所示。?
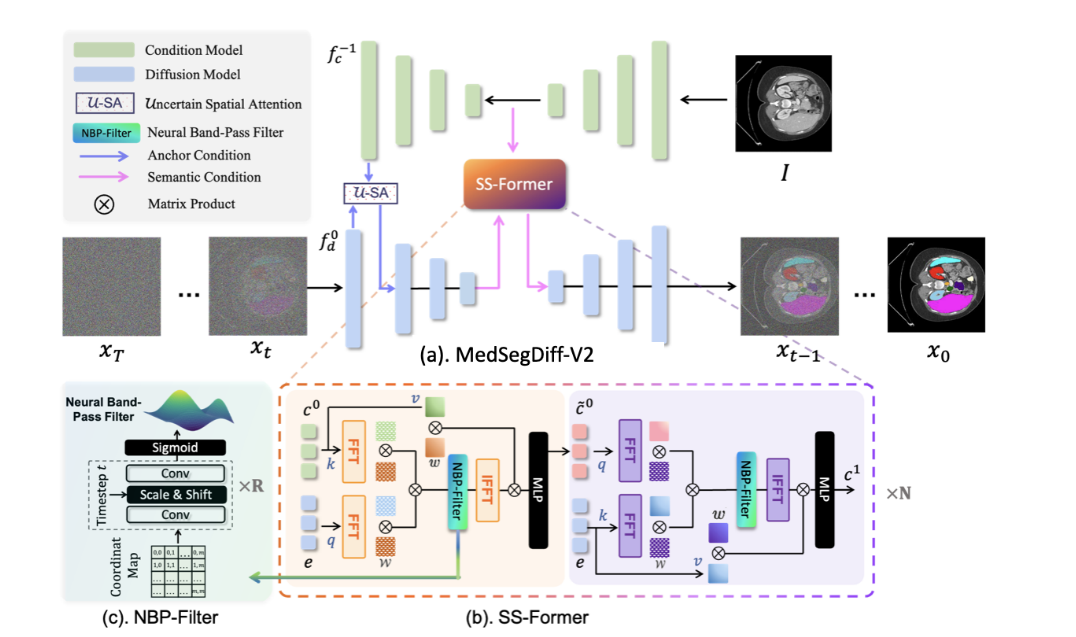
整體流程概述:噪聲掩碼??首先輸入到UNet,稱為?擴散模型(DIffusion Model)。擴散模型通過另一標準的UNet(稱為?條件模型?Condition?Model)從原始圖像中提取的分割特征作為條件。將條件模型的解碼分割特征作為錨點分割特征(先驗特征)集成到擴散模型的編碼特征中(輔助UNet分支解碼器的先驗特征和擴散模型逆恢復特征融合)。這使得擴散模型可以用一個粗略但靜態的參考來初始化,有助于減小擴散方差。然后,將語義條件施加到擴散模型的嵌入中,將條件模型的語義分割嵌入集成到擴散模型的嵌入中(將輔助UNet分支的最底層全局語義特征與擴散模型逆恢復特征融合)。這種條件集成由SS-Former實現,彌合了噪聲和語義嵌入之間的差距,并利用transformer的全局和動態特性的優勢抽象出更強的表示。
輸出結果:依舊是擴散模型中?,只不過這個?
?受到了輔助 UNet 分支的指導,集合了先驗特征和語義特征,使得擴散模型的反向過程更有方向性,會朝著指定的分割區域恢復。
MedSegDiff-V2主要由兩步操作組成:
- 1.?輔助UNet分支解碼器最頂層的先驗特征和擴散模型逆恢復特征融合? ——? U-SA
- 2.?將輔助UNet分支的最底層全局語義特征與擴散模型逆恢復特征融合 —— SS-Former
這兩步操作的作用位置不同,U-SA作用于輔助UNet分支解碼器頂層,以分割特征作為先驗特征對逆恢復特征進行約束。SS-Former作用于輔助UNet分支的最底層,為逆恢復特征融合全局語義。
? ? ?
Q:這種融合方法不會破壞擴散模型的反向過程嗎?畢竟擴散模型的反向過程是依賴于正向過程中的數據分布的,向反向過程中添加正向過程中不存在的數據,不會破壞反向過程的推理嗎?
?
損失函數:MedSegDiff-V2在DPM(Ho、Jain和Abbeel 2020)之后使用標準噪聲預測損失??和監督條件模型的錨點損失?
?進行訓練。
?是soft dice loss?
?和交叉熵損失?
?的組合。具體地,總損失函數表示為:
![]()
其中 t ≡ 0 (mod α) 通過超參數 α 控制對條件模型的監督次數,交叉熵損失用超參數 β 加權,分別設為?5 和 10 。?
??
C. Anchor Condition with U-SA?( 錨點條件與U-SA )
問題:沒有卷積層的歸納偏差,transformer塊具有更強的表示能力,但在訓練數據有限的情況下,對輸入方差也更敏感(Naseer et al. 2021)。直接將 transformer 塊添加到擴散模型中會導致每次輸出的方差很大。
方法:為了克服這種負面影響,本文調整了 MedSegDiff?的結構,并將錨點條件操作引入擴散模型。錨點條件從條件模型(輔助UNet分支)中提取出一種粗糙的錨點特征,并將其融入到擴散模型中。這為擴散模型提供了正確的預測范圍,同時也允許它進一步完善結果。
過程:具體地,將條件模型解碼后的分割特征融入擴散模型的編碼器特征中。提出 U-SA 機制(高斯卷積 + 自注意力)進行特征融合,以表示給定條件特征的不確定性本質。形式上,將最后一個條件特征??集成到第一個擴散特征?
?中。U-SA?可以表示為:
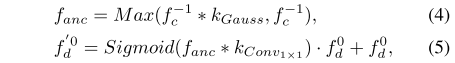
其中,? 表示滑動窗口內核操作,·?表示常規的元素級操作。在方程中,首先在??上應用可學習的高斯核 Kg 來平滑激活,因為?
?用作錨,但可能不完全準確。因此,在平滑后的特征圖和原始特征圖之間選取最大值來保留最相關的信息,從而得到平滑的錨點特征圖 fanc。然后將 fanc 融合到?
?中,得到增強特征?
。(本質上是一個對Key值進行高斯平滑處理的自注意力)
細節:具體地說,首先應用1×1卷積??將錨點特征通道減少到1,并在Sigmoid激活后將其與?
?相乘,然后將其添加到?
?的每個通道,類似于空間注意的實現。?
??
D.?Semantic Condition with SS-Former ( 語義條件和SS-Former )
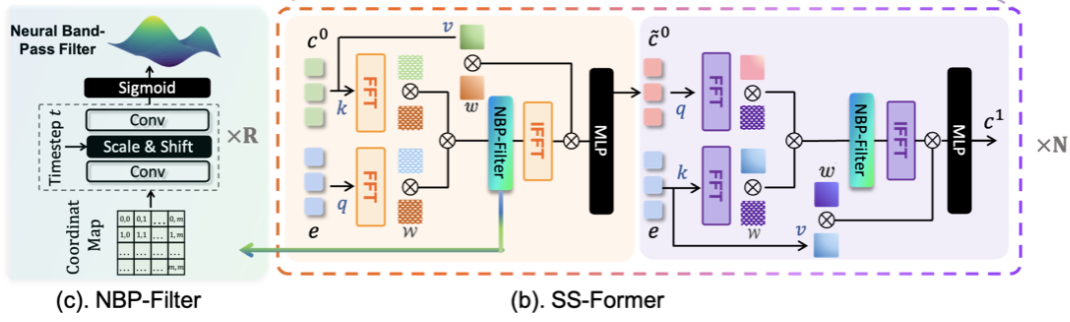
問題:擴散模型從噪聲掩碼輸入中預測冗余噪聲,導致其嵌入與條件分割語義嵌入之間的域間差距(頻域和空間域之間的差距)。當使用矩陣操作時,這種差異會影響性能,例如在一個 transformer 中。
思想:為應對這一挑戰,本文提出一種新的頻譜空間Transformer (SS-Former)。本文的核心思想?是在頻域上學習條件語義特征和擴散噪聲特征的相互作用?。
方法:本文使用一個濾波器,稱為神經帶通濾波器 (NBP-Filter) 來將它們對齊到統一的頻率范圍,即頻譜。NBP-Filter學習通過特定的頻譜,同時約束其他頻譜。以自適應擴散時間步長的方式學習該頻譜,因為噪聲水平 (頻率范圍) 對每個步驟都是特定的。這允許根據頻率親和度混合特征,也可以根據擴散步驟對齊特征。(通過?NBP-Filter?對每一個步長都學習一個特定的頻譜,并將輸入特征對齊到這一統一的頻率范圍)
結構:如圖所示,由共享相同架構的 N 個塊組成。本文中設置 N = 4。每個模塊由兩個類似交叉注意力的模塊組成。
NBP-Filter設計來源:然后,應用?NBP-Filter?來對齊頻率的表示。?中的每個點現在表示一個特定的頻率,由于我們需要控制一個連續的頻率范圍,直觀的是建立一個從特征映射位置到頻率幅度的平滑投影。為了實現這一點,本文使用神經網絡從坐標映射中學習權重映射。通過這樣做,網絡的歸納偏差將促進平滑投影的學習,因為相似的輸入將自然產生相似的輸出(Sitzmann et al. 2020;吳和傅2019)。這種想法被廣泛應用于3D視覺任務中,被稱為神經輻射場(NeRF)(Mildenhall et al. 2020)。
過程:第一步將擴散噪聲嵌入條件語義嵌入中,接下來的對稱模塊將上一個語義嵌入到擴散噪聲嵌入中。這?允許模型學習噪聲和語義特征之間的相互作用 (選取最深層特征的作用),并實現更強的表示。形式上,考慮??是條件模型中?最深的特征嵌入?,e 是擴散模型中?最深的特征嵌入?。
- 首先將?
?和 e 轉移到傅里葉空間(FFT操作),分別記為?
?和?
?。請注意,特征圖都是按照標準的vision transformer方法進行拼接和線性投影的。然后,以e為查詢,
?,其中?
?和?
?是傅里葉空間中可學習的查詢權重和鍵權重。( 傅里葉空間變換 + ViT )
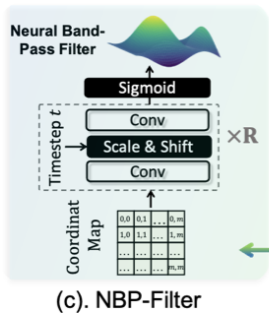
- 然后,應用?NBP-Filter?來對齊頻率的表示。但與原始的NeRF不同,本文進一步用時間步長信息對其進行條件化。具體來說,該網絡以一個坐標圖(coordinate map)作為輸入,并產生一個注意力圖作為過濾器,兩者都具有相同的大小 m。簡單堆疊卷積塊和中間層歸一化來實現它。為了用時間步信息來調節網絡,使用擴散模型的時間步嵌入來縮放和移動歸一化特征。使用兩個 MLP 層將當前時間步嵌入投影到表示均值和方差的兩個值,分別用于縮放和移動。堆疊總共 6 個這樣的塊和一個 Sigmoid 函數來產生最終的濾波器。最后,將濾波器與親和性矩陣逐元素相乘。
- 然后,將經過過濾的親和力圖 M' 使用逆快速傅里葉變換 (?IFFT?) 轉換回歐幾里得空間,并應用 value 值 中的條件特征:
,其中
是可學習的 value 權重 (卷積) 。還使用一個 MLP 進一步細化注意力結果,獲得最終特征
。接下來的注意力模塊與第一個模塊對稱,但使用組合特征
Q:坐標圖(coordinate map)怎么獲得的?由親和度矩陣轉化而來的嗎?
?
? ??
五、實驗
A. Dataset( 數據集 )
在五個不同的數據集上進行了實驗。使用兩個數據集來驗證?通用分割性能?,分別是包含16種解剖結構的AMOS2022公開數據集和包含12種被標注用于腹部多器官分割的解剖結構的BTCV公開數據集。另外使用四個公共數據集(包括:眼底圖像的光學杯分割、MRI圖像的腦腫瘤分割、超聲圖像的甲狀腺結節分割)、BraTs-2021數據集、ISIC數據集和TNMIX數據集驗證其?在多模態圖像上的分割性能。(五種數據集,驗證通用分割和多模態分割任務)
??
B. Implementation Details( 實驗細節 )
實驗設備:所有實驗均使用PyTorch平臺進行,并在4個NVIDIA A100圖形處理器上進行培訓/測試。
預處理:所有圖像都被均勻地調整到256×256像素的分辨率。
優化器和批量大小:使用AdamW優化器以端到端的方式訓練網絡,批次大小為32。初始學習速率設置為1×10^?4。
擴散步數和執行次數:采用100個擴散步驟進行推理。為了集成,運行模型10次,這比MedSegDiff中的25次要少得多。然后使用STAPLE算法對不同的樣本進行融合;
評價指標:通過Dice score,IoU,HD95指標對分割性能進行評估。
C.?Main Results ( 主要結果 )
驗證 MedSegDiff-V2 與SOTA方法在多器官分割數據集AMOS和BTCV上的分割性能。?
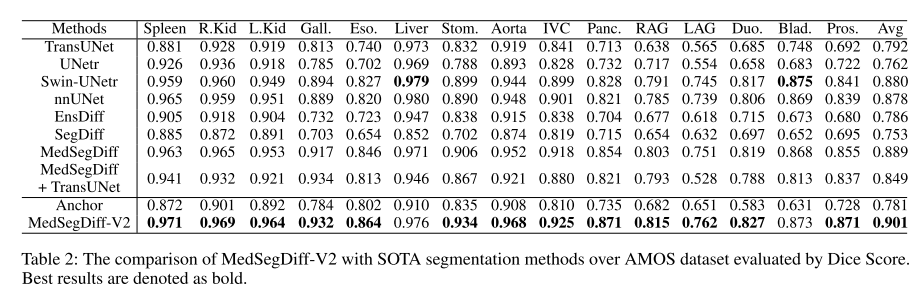
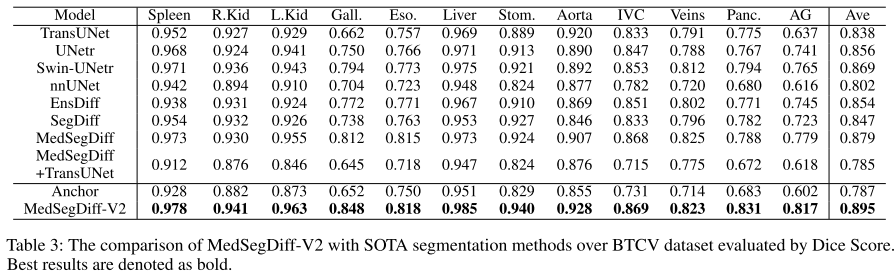

對比方法:?基于cnn的方法nnUNet,基于transformer的方法TransUNet、UNetr、Swin-UNetr以及基于擴散的方法EnsDiff、SegDiff、MedSegDiff。
結果分析:網絡體系結構本身并不是性能的決定因素。例如,設計良好的基于 cnn 的模型 nnUNet 在表中大大優于基于 transformer 的模型 TransUNet 和 UNetr。對于基于擴散的模型也是如此。可以看到,直接采用擴散模型進行醫學圖像分割,即 EnsDiff 和 SegDiff ,其性能比 UNetr 和 Swin-UNetr 差。transformer和擴散模型的簡單組合,即MedSegDiff + TransUNet,獲得的性能甚至比標準MedSegDiff更差。
改進方法:通過引入錨定條件和SS-Former,MedSegDiff-v2克服了這些挑戰,并表現出優越的性能。本文還在進行了定性比較。可以觀察到,MedSegDiff-v2預測的分割圖具有更精確的細節,即使在低對比度或模糊的區域。
D.?Ablation Study ( 消融實驗 )
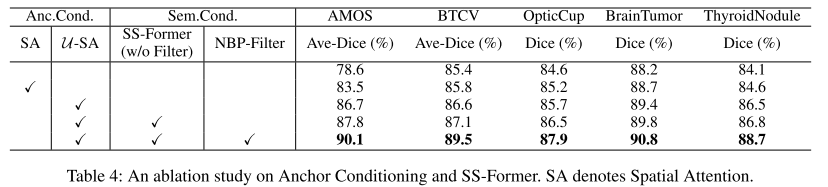
進行了全面的消融研究,以驗證所提出模塊的有效性。Anc.Cond. 和 Sem.Cond. 分別表示錨點條件和語義條件。如表所示:
- 錨點條件顯著改善了基本的擴散模型,所提出的U-SA在所有數據集上的表現都優于之前的空間注意力。
- 在語義條件中,單獨使用SS-Former只提供了微小的改進,但將其與NBP-Filter相結合則帶來了顯著的改進,證明了所提出的SS-Former設計的有效性。?
??
六、結論
主要工作:在本文中,通過將 transformer 機制加入到原始的 UNet 主干中來增強基于擴散的醫學圖像分割框架,稱為 MedSegDiff-V2 。為了學習噪聲和語義特征之間的交互作用,本文提出了一種新的?SS-Former?結構。
實驗效果:對比實驗表明,在20種不同圖像形態的醫學圖像分割任務中,本文的模型優于以往的SOTA方法。
展望:作為第一個用于醫學圖像分割的基于 transformer 的擴散模型,相信MedSegDiff-V2將作為未來研究的基準






)












