系列篇章💥
AI大模型探索之路-實戰篇4:深入DB-GPT數據應用開發框架調研
AI大模型探索之路-實戰篇5:探索Open Interpreter開放代碼解釋器調研
AI大模型探索之路-實戰篇6:掌握Function Calling的詳細流程
AI大模型探索之路-實戰篇7:Function Calling技術實戰自動生成函數
AI大模型探索之路-實戰篇8:多輪對話與Function Calling技術應用
AI大模型探索之路-實戰篇9:探究Agent智能數據分析平臺的架構與功能
AI大模型探索之路-實戰篇10:數據預處理的藝術:構建Agent智能數據分析平臺的基礎
AI大模型探索之路-實戰篇11: Function Calling技術整合:強化Agent智能數據分析平臺功能
AI大模型探索之路-實戰篇12: 構建互動式Agent智能數據分析平臺:實現多輪對話控制
目錄
- 系列篇章💥
- 一、前言
- 二、本地云盤創建
- 1、創建文件目錄
- 2、doc文檔操作函數定義
- 3、doc內容追加測試
- 三、多輪對話本地云盤存儲功能實現
- 1、定義模型客戶端
- 2、定義工具函數生成器
- 3、兩次大模型API調用封裝
- 4、數據字典讀取
- 5、定義數據庫表信息查詢服務
- 6、定義SQL提取函數
- 7、對話確認機制改造
- 8、多輪對話封裝
- 9、多輪對話測試
- 四、數據分析報告撰寫初探
- 1、學習本公司的數據分析業務知識
- 2、文件內容獲取函數定義
- 3、讀取數據字典信息
- 4、讀取本公司數據分析師業務知識
- 5、撰寫分析報告
- 五、結語
一、前言
在前面篇章中我們實現了多輪對話控制,本文中我們將實現多輪對話內容的云盤記錄,將對話內容記錄存儲到本地云盤文件夾中;之后再基于對話內容,數據字典、數據庫表相關的基本信息實現一個簡單的數據分析報告撰寫功能
二、本地云盤創建
為了持久化存儲對話記錄,我們將創建一個本地文件夾,模擬云盤的功能。
1、創建文件目錄
定義創建文件目錄的函數,作為云盤存儲記錄
import osdef create_directory(directory):"""根據項目創建云盤目錄"""base_path = "/root/autodl-tmp/iquery項目/iquery云盤"full_path = os.path.join(base_path, directory)# 如果目錄不存在,則創建它if not os.path.exists(full_path):os.makedirs(full_path)print(f"目錄 {directory} 創建成功")else:print(f"目錄 {directory} 已存在")創建文件夾目錄
directory = "my_directory"
create_directory(directory)
輸出:

2、doc文檔操作函數定義
安裝依賴pip install python-docx
定義doc文檔操作函數,用于向文檔追加內容
import os
from docx import Documentdef append_in_doc(folder_name, doc_name, qa_string):""""往文件里追加內容@param folder_name=目錄名,doc_name=文件名,qa_string=追加的內容"""base_path = "/root/autodl-tmp/iquery項目/iquery云盤"## 目錄地址full_path_folder=base_path+"/"+folder_name## 文件地址full_path_doc = os.path.join(full_path_folder, doc_name)+".doc"# 檢查目錄是否存在,如果不存在則創建if not os.path.exists(full_path_folder):os.makedirs(full_path_folder)# 檢查文件是否存在if os.path.exists(full_path_doc):# 文件存在,打開并追加內容document = Document(full_path_doc)else:# 文件不存在,創建一個新的文檔對象document = Document()# 追加內容document.add_paragraph(qa_string)# 保存文檔document.save(full_path_doc)print(f"內容已追加到 {doc_name}")
3、doc內容追加測試
# 示例用法
append_in_doc('my_directory', 'example_doc', '天青色等煙雨,而我在等你')

三、多輪對話本地云盤存儲功能實現
將之前的篇章實現的多輪對話等功能,融入文檔記錄的功能
1、定義模型客戶端
import openai
import os
import numpy as np
import pandas as pd
import json
import io
from openai import OpenAI
import inspect
import pymysqlopenai.api_key = os.getenv("OPENAI_API_KEY")client = OpenAI(api_key=openai.api_key)
2、定義工具函數生成器
def auto_functions(functions_list):"""Chat模型的functions參數編寫函數:param functions_list: 包含一個或者多個函數對象的列表;:return:滿足Chat模型functions參數要求的functions對象"""def functions_generate(functions_list):# 創建空列表,用于保存每個函數的描述字典functions = []# 對每個外部函數進行循環for function in functions_list:# 讀取函數對象的函數說明function_description = inspect.getdoc(function)# 讀取函數的函數名字符串function_name = function.__name__system_prompt = '以下是某的函數說明:%s' % function_descriptionuser_prompt = '根據這個函數的函數說明,請幫我創建一個JSON格式的字典,這個字典有如下5點要求:\1.字典總共有三個鍵值對;\2.第一個鍵值對的Key是字符串name,value是該函數的名字:%s,也是字符串;\3.第二個鍵值對的Key是字符串description,value是該函數的函數的功能說明,也是字符串;\4.第三個鍵值對的Key是字符串parameters,value是一個JSON Schema對象,用于說明該函數的參數輸入規范。\5.輸出結果必須是一個JSON格式的字典,只輸出這個字典即可,前后不需要任何前后修飾或說明的語句' % function_nameresponse = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}])json_function_description=json.loads(response.choices[0].message.content.replace("```","").replace("json",""))json_str={"type": "function","function":json_function_description}functions.append(json_str)return functionsmax_attempts = 4attempts = 0while attempts < max_attempts:try:functions = functions_generate(functions_list)break # 如果代碼成功執行,跳出循環except Exception as e:attempts += 1 # 增加嘗試次數print("發生錯誤:", e)if attempts == max_attempts:print("已達到最大嘗試次數,程序終止。")raise # 重新引發最后一個異常else:print("正在重新運行...")return functions
3、兩次大模型API調用封裝
封裝funcation calling中兩次大模型API得調用
def run_conversation(messages, functions_list=None, model="gpt-3.5-turbo"):"""能夠自動執行外部函數調用的對話模型:param messages: 必要參數,字典類型,輸入到Chat模型的messages參數對象:param functions_list: 可選參數,默認為None,可以設置為包含全部外部函數的列表對象:param model: Chat模型,可選參數,默認模型為gpt-3.5-turbo:return:Chat模型輸出結果"""# 如果沒有外部函數庫,則執行普通的對話任務if functions_list == None:response = client.chat.completions.create(model=model,messages=messages,)response_message = response.choices[0].messagefinal_response = response_message.content# 若存在外部函數庫,則需要靈活選取外部函數并進行回答else:# 創建functions對象tools = auto_functions(functions_list)#tools = [{'type': 'function', 'function': {'name': 'sunwukong_function', 'description': '定義了數據集計算過程', 'parameters': {'type': 'object', 'properties': {'data': {'type': 'string', 'description': '表示帶入計算的數據表,用字符串進行表示'}}, 'required': ['data']}}}, {'type': 'function', 'function': {'name': 'tangseng_function', 'description': '該函數定義了數據集計算過程', 'parameters': {'type': 'object', 'properties': {'data': {'type': 'string', 'description': '必要參數,表示帶入計算的數據表,用字符串進行表示'}}, 'required': ['data']}}}]# 創建外部函數庫字典available_functions = {func.__name__: func for func in functions_list}# 第一次調用大模型response = client.chat.completions.create(model=model,messages=messages,tools=tools,tool_choice="auto", )response_message = response.choices[0].messagetool_calls = response_message.tool_callsif tool_calls:messages.append(response_message) for tool_call in tool_calls:function_name = tool_call.function.namefunction_to_call = available_functions[function_name]function_args = json.loads(tool_call.function.arguments)function_response = function_to_call(**function_args)messages.append({"tool_call_id": tool_call.id,"role": "tool","name": function_name,"content": function_response,}) print(messages)## 第二次調用模型second_response = client.chat.completions.create(model=model,messages=messages,) # 獲取最終結果final_response = second_response.choices[0].message.contentelse:final_response = response_message.contentreturn final_response
4、數據字典讀取
# 打開并讀取Markdown文件
with open('/root/autodl-tmp/iquery項目/data/數據字典/iquery數據字典.md', 'r', encoding='utf-8') as f:md_content = f.read()md_content
輸出:

5、定義數據庫表信息查詢服務
def sql_inter(sql_query):"""用于獲取iquery數據庫中各張表的有關相關信息,\核心功能是將輸入的SQL代碼傳輸至iquery數據庫所在的MySQL環境中進行運行,\并最終返回SQL代碼運行結果。需要注意的是,本函數是借助pymysql來連接MySQL數據庫。:param sql_query: 字符串形式的SQL查詢語句,用于執行對MySQL中iquery數據庫中各張表進行查詢,并獲得各表中的各類相關信息:return:sql_query在MySQL中的運行結果。"""mysql_pw = "iquery_agent"connection = pymysql.connect(host='localhost', # 數據庫地址user='iquery_agent', # 數據庫用戶名passwd=mysql_pw, # 數據庫密碼db='iquery', # 數據庫名charset='utf8' # 字符集選擇utf8)try:with connection.cursor() as cursor:# SQL查詢語句sql = sql_querycursor.execute(sql)# 獲取查詢結果results = cursor.fetchall()finally:connection.close()return json.dumps(results)functions_list = [sql_inter]
6、定義SQL提取函數
import astdef extract_sql(str):# 使用literal_eval將字符串轉換為字典dict_data = ast.literal_eval(json.dumps(str))# 提取'sql_query'的值sql_query_value = dict_data['sql_query']+""# 提取并返回'sql_query'的值return sql_query_value
7、對話確認機制改造
def check_code_run(messages, functions_list=None, model="gpt-3.5-turbo",auto_run = True):"""能夠自動執行外部函數調用的對話模型:param messages: 必要參數,字典類型,輸入到Chat模型的messages參數對象:param functions_list: 可選參數,默認為None,可以設置為包含全部外部函數的列表對象:param model: Chat模型,可選參數,默認模型為gpt-3.5-turbo:return:Chat模型輸出結果"""# 如果沒有外部函數庫,則執行普通的對話任務if functions_list == None:response = client.chat.completions.create(model=model,messages=messages,)response_message = response.choices[0].messagefinal_response = response_message.content# 若存在外部函數庫,則需要靈活選取外部函數并進行回答else:# 創建functions對象tools = auto_functions(functions_list)# 創建外部函數庫字典available_functions = {func.__name__: func for func in functions_list}# 第一次調用大模型response = client.chat.completions.create(model=model,messages=messages,tools=tools,tool_choice="auto", )response_message = response.choices[0].messagetool_calls = response_message.tool_callsif tool_calls:messages.append(response_message) for tool_call in tool_calls:function_name = tool_call.function.namefunction_to_call = available_functions[function_name]function_args = json.loads(tool_call.function.arguments)if auto_run == False:print("SQL字符串的數據類型")print(type(function_args))sql_query = extract_sql(function_args)res = input('即將執行以下代碼:%s。是否確認并繼續執行(1),或者退出本次運行過程(2)' % sql_query)if res == '2':print("終止運行")return Noneelse:print("正在執行代碼,請稍后...")function_response = function_to_call(**function_args)messages.append({"tool_call_id": tool_call.id,"role": "tool","name": function_name,"content": function_response,}) ## 第二次調用模型second_response = client.chat.completions.create(model=model,messages=messages,) # 獲取最終結果final_response = second_response.choices[0].message.contentelse:final_response = response_message.contentdel messagesreturn final_response
8、多輪對話封裝
import tiktokendef chat_with_inter(functions_list=None, prompt="你好呀", model="gpt-3.5-turbo", system_message=[{"role": "system", "content": "你是一個智能助手。"}], auto_run = True):print("正在初始化外部函數庫")# 創建函數列表對應的參數解釋列表functions = auto_functions(functions_list)print("外部函數庫初始化完成")project_name = input("請輸入當前分析項目名稱:")folder_name = create_directory(project_name)print("已完成數據分析文件創建")doc_name = input("請輸入當前分析需求,如數據清理,數據處理,數據分析段等:")doc_name += '問答'print("好的,即將進入交互式分析流程")# 多輪對話閾值# 多輪對話閾值if 'gpt-4' in model:tokens_thr = 6000elif '16k' in model:tokens_thr = 14000else:tokens_thr = 3000messages = system_message## 完成給用戶輸入的問題賦值user_input = promptmessages.append({"role": "user", "content": prompt})## 計算token大小embedding_model = "text-embedding-ada-002"# 模型對應的分詞器(TOKENIZER)embedding_encoding = "cl100k_base"encoding = tiktoken.get_encoding(embedding_encoding)tokens_count = len(encoding.encode((prompt + system_message[0]["content"])))while True: answer = check_code_run(messages, functions_list=functions_list, model=model, auto_run = auto_run)print(f"模型回答: {answer}")#####################判斷是否記錄文檔 start#######################while True:record = input('是否記錄本次回答(1),還是再次輸入問題并生成該問題答案(2)')if record == '1':Q_temp = 'Q:' + user_inputA_temp = 'A:' + answerappend_in_doc(folder_name=project_name, doc_name=doc_name, qa_string=Q_temp)append_in_doc(folder_name=project_name, doc_name=doc_name, qa_string=A_temp)# 記錄本輪問題答案messages.append({"role": "assistant", "content": answer})breakelse:print('好的,請再次輸入問題')user_input = input()messages[-1]["content"] = user_inputanswer = check_code_run(messages, functions_list=functions_list, model=model, auto_run = auto_run) print(f"模型回答: {answer}")########################判斷是否記錄文檔 stop ######################## 詢問用戶是否還有其他問題user_input = input("您還有其他問題嗎?(輸入退出以結束對話): ")if user_input == "退出":del messagesbreak# 記錄新一輪問答messages.append({"role": "assistant", "content": answer})messages.append({"role": "user", "content": user_input})# 計算當前總token數tokens_count += len(encoding.encode((answer + user_input)))# 刪除超出token閾值的對話內容while tokens_count >= tokens_thr:tokens_count -= len(encoding.encode(messages.pop(1)["content"]))
函數列表查看
functions_list

9、多輪對話測試
chat_with_inter(functions_list=functions_list, prompt="介紹一下iquery數據庫中的表的情況", model="gpt-3.5-turbo-16k", system_message=[{"role": "system", "content": md_content}], auto_run = False)
對話效果
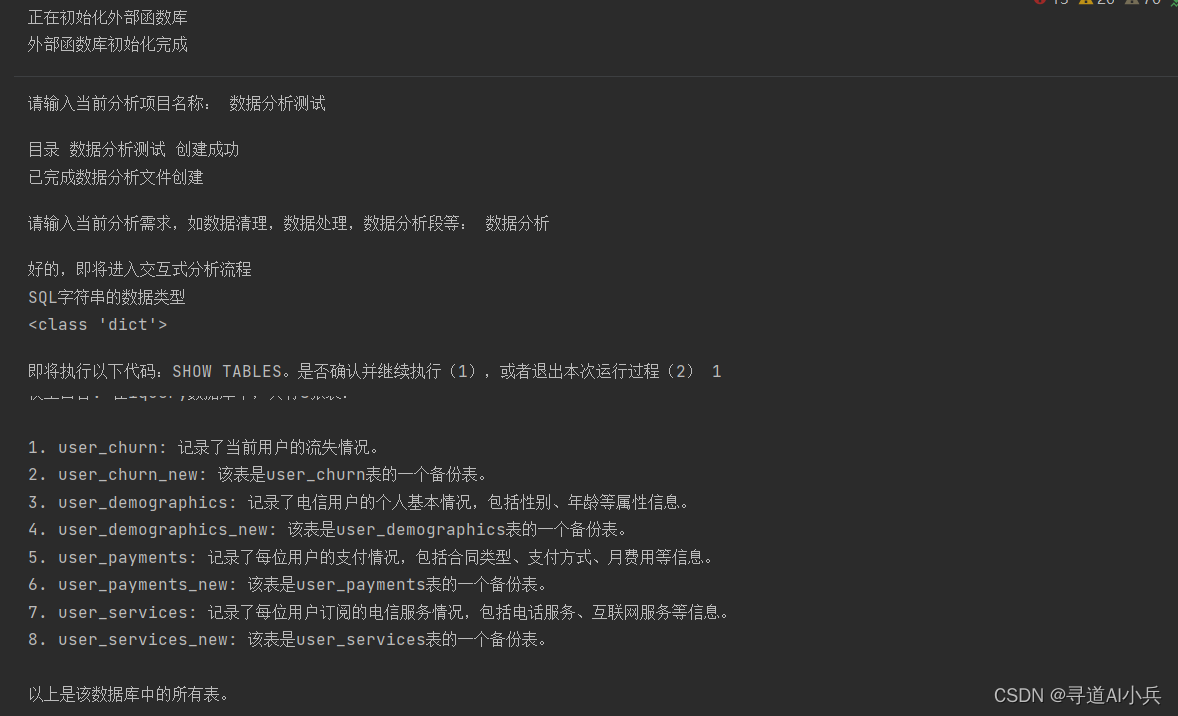
四、數據分析報告撰寫初探
1、學習本公司的數據分析業務知識
# 讀取業務知識文檔
with open('/root/autodl-tmp/iquery項目/data/業務知識/本公司數據分析師業務介紹.md', 'r', encoding='utf-8') as f:da_instruct = f.read()
from IPython.display import display, Markdown, Codedisplay(Markdown(da_instruct))
2、文件內容獲取函數定義
實現一個根據項目和文件獲取文件內容的方法
## 實現根據項目和文件獲取文件內容的方法from docx import Document
import osdef get_file_content(project_name, file_name):"""實現根據項目名和文件名獲取文件內容的方法@param project_name:項目名,file_name:文件名@return 文件內容"""# 構建文件的完整路徑base_path = "/root/autodl-tmp/iquery項目/iquery云盤"file_path = os.path.join(project_name, file_name)full_path = os.path.join(base_path, file_path)+".doc"print("打印文件路徑:"+full_path)# 確保文件存在if not os.path.exists(full_path):return "文件不存在"try:# 加載文檔doc = Document(full_path)content = []# 遍歷文檔中的每個段落,并收集文本for para in doc.paragraphs:content.append(para.text)# 將所有段落文本合并成一個字符串返回return '\n'.join(content)except Exception as e:return f"讀取文件時發生錯誤: {e}"file_content = get_file_content('電信用戶行為分析', '數據分析問答')
輸出:

display(Markdown(file_content))
3、讀取數據字典信息
# 讀取數據字典
with open('/root/autodl-tmp/iquery項目/data/數據字典/iquery數據字典.md', 'r', encoding='utf-8') as f:md_content = f.read()
# 讀取問答結果
file_content = get_file_content('電信用戶行為分析', '數據分析問答')
輸出:

4、讀取本公司數據分析師業務知識
# 讀取業務知識文檔
with open('/root/autodl-tmp/iquery項目/data/業務知識/本公司數據分析師業務介紹.md', 'r', encoding='utf-8') as f:da_instruct = f.read()
5、撰寫分析報告
基于讀取到的字典信息,本公司數據分析師業務知識,以及問答內容;都給到大模型,讓大模型編寫報告
messages=[{"role": "system", "content": da_instruct}, {"role": "system", "content": 'iquery數據庫數據字典:%s' % md_content}, {"role": "system", "content": '數據探索和理解階段問答文本:%s' % file_content}, {"role": "user", "content": "請幫我編寫電信用戶行為分析的分析報告中的數據探索和理解部分內容"}]response = client.chat.completions.create(model="gpt-3.5-turbo-16k",messages=messages,)display(Markdown(response.choices[0].message.content))
五、結語
在本文中,我們不僅建立了一個能夠記錄多輪對話的本地“云盤”,而且還初步實現了基于對話內容、數據字典和業務知識的數據分析報告自動撰寫功能。讓我們的Agent智能數據分析平臺擁有了,報告生成的能力;這也標志著我們向著完全自動化的數據分析平臺又邁進了一大步。

🎯🔖更多專欄系列文章:AIGC-AI大模型探索之路
😎 作者介紹:我是尋道AI小兵,資深程序老猿,從業10年+、互聯網系統架構師,目前專注于AIGC的探索。
📖 技術交流:建立有技術交流群,可以掃碼👇 加入社群,500本各類編程書籍、AI教程、AI工具等你領取!
如果文章內容對您有所觸動,別忘了點贊、?關注,收藏!加入我,讓我們攜手同行AI的探索之旅,一起開啟智能時代的大門!











)

)





