不同點:
順序表和鏈表是兩種常見的數據結構,他們的不同點在于存儲方式和插入、刪除操作、隨機訪問、cpu緩存利用率等方面。
一、存儲方式不同:
順序表:
順序表的存儲方式是順序存儲,在內存中申請一塊連續的空間,通過下標來進行存儲;
鏈表:
鏈表的存儲方式是鏈式存儲,申請的空間是未必連續的,以節點的形式連接,每個節點會有一個next指針,指向下一個節點,通過指針來訪問元素;
二、插入、刪除的效率不同:
順序表:
插入刪除元素時,需要移動元素的位置也就是搬移元素,導致效率低下
鏈表:
插入刪除時只需要修改指針指向。
三、內存利用率:
順序表:
需要擴容,創建空間大小是固定的,當空間不夠時需要進行擴容,以2倍的關系擴增的,你少一個空間,我增大到原來的2倍,還會有多余空間未使用,所以擴容會造成空間浪費的現象。
但是注意我們因為用的realloc擴容,所以擴容本身會有消耗!!👉👉👉
由于realloc擴容的特性,不確定是原地還是異地擴容,這個與編譯器有點關系
原地擴容:擴容的空間地址與原來地址相同
異地擴容:擴容的空間地址與原來地址不同(將原來的數據拷貝過來,還要銷毀原來的空間)
鏈表:
按需申請的空間,不會存在空間浪費現象,利用率極高
四、隨機訪問:
順序表:
支持用下標隨機訪問
鏈表:
不支持,因為空間在物理上就不是連續的,next找到下一個節點,在用該節點的next找一個,找起來比較麻煩
五、緩存利用率:
緩存👉CPU高速緩存🧑?🎓🧑?🎓 內存在帶電的情況下存儲,當斷電后未保存的數據會丟失(就像我們在用畫板時,畫了畫,你給電腦關機,下次進去就找不到了)但其速度快,而硬盤可以不帶電存儲,但是速度慢。
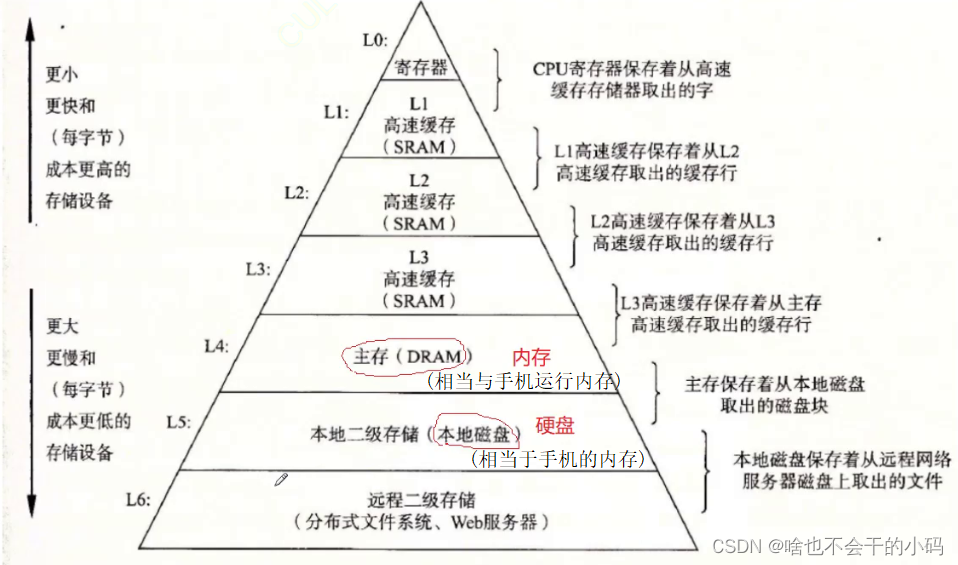
🤔🤔為啥有寄存器和三級緩存??
??主要是cpu的運行速度很快,看不上內存日常不會去訪問內存,但是寄存器和三級緩存的速度還是能入下眼??
我們寫的代碼時,變量存在內存里面,當你要修改變量時會將數據放到寄存器,然后cpu對其接收指令進行修改
看下面代碼的反匯編,mov 是將 i 放到 eax(寄存器)中,然后對寄存器的數據進行inc指令也就是加1, 在講寄存器的數據放到可i中

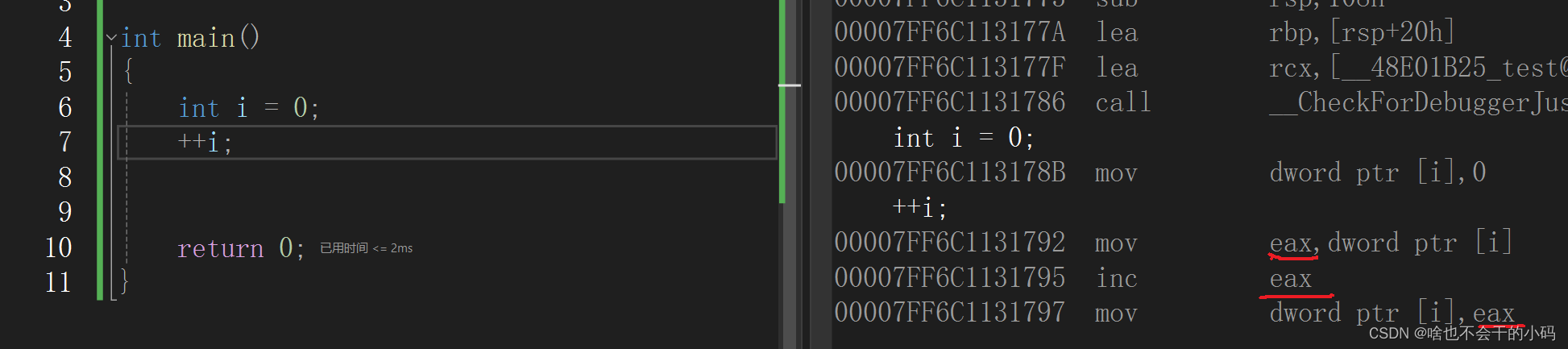
但是寄存器個數有限,一般對于4個 8個字節會放到寄存器,數據比較大會加載到緩存,( 緩存里面還要涉及到三級緩存的調用,有點深奧,不講這么難的,可以自己去查資料)
cpu訪問數據會先訪問數據是否在緩存中,在---》緩存命中,直接訪問。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 不在---》不命中,先將數據加載到緩存中,再進行訪問。
🤔怎么加載到緩存的??
cpu會按cpu字長去讀,會認為你訪問當前數據后面(連續在一起的)都不在緩存中,給它加載進去
舉個例子:數組為例子,下面的20個人就是一個數組。度假村相當于緩存,領導是cpu,大巴車也是cpu,cpu給你加載到緩存,再訪問

注意:緩存有一定的范圍,新進來的過多,放不下了,就給舊的清理掉!
對于鏈表了,你的物理空間是不連續,拉的數據太多,會把緩存區之前的一些數據排擠走了
順序表:
?CPU緩存利用率高。
鏈表:
CPU緩存利用率低。
六、總結:
| 不同點 | 順序表 | 單鏈表 |
| 存儲空間 | 物理上一定連續(底層是數組) | 只是邏輯上連續,物理上并不連續 |
| 隨機訪問 | 下標訪問 O(1) | 不支持:要遍歷O(N) |
| 任意位置的增刪 | 需要搬運元素,效率低O(N) | 無需搬運,只需要修改指針指向 |
| 插入 | 動態順序表,需要擴容(成倍擴容,可能會造成空間浪費) | 按需申請,沒有擴容這一說法 |
| 應用場景 | 元素的高效存儲+頻繁的訪問 | 任意位置插入+刪除頻繁 |
| CPU緩存利用率 | 緩存利用率高 | 緩存利用率低 |
鏈表和順序表各有優勢,互相彌補各自的缺點
總之,順序表用于數據元素較少、讀取操作頻繁的場景,而鏈表更適用于數據元素較多、插入、刪除操作頻繁的場景。
? ?就到? ? ? ? ? ? ? ?這吧? ??🫰
?就到? ? ? ? ? ? ? ?這吧? ??🫰




)


事務消息,惰性隊列,優先隊列)











計算機網絡在信息時代對的作用 計算機網絡的定義和分類 三種交換方法)