字符串在 Redis 中是很常用的,鍵值對中的鍵是字符串類型,值有時也是字符串類型。
Redis 是用 C 語言實現的,但是它沒有直接使用 C 語言的 char* 字符數組來實現字符串,而是自己封裝了一個名為簡單動態字符串(simple dynamic string,SDS)的數據結構來表示字符串,也就是 Redis 的 String 數據類型的底層數據結構是 SDS。
既然 Redis 設計了 SDS 結構來表示字符串,肯定是 C 語言的 char* 字符數組存在一些缺陷。
要了解這一點,得先來看看 char* 字符數組的結構。
1. C 語言字符串的缺陷
C 語言的字符串其實就是一個字符數組,即數組中每個元素是字符串中的一個字符。
比如:
char* name = "abc"字符數組的結構對應為:
a,b,c,\0在 C 語言里,對字符串操作時,char * 指針只是指向字符數組的起始位置,而字符數組的結尾位置就用“\0”表示,意思是指字符串的結束。
因此,C 語言標準庫中的字符串操作函數就通過判斷字符是不是“\0”來決定要不要停止操作,如果當前字符不是“\0”,說明字符串還沒有結束,可以繼續操作,如果當前字符是“\0”則說明字符串結束了,就要停止操作。
舉個例子,C 語言獲取字符串長度的函數 strlen,就是通過字符數組中的每一個字符,并進行計數,等遇到字符為"\0"后,就會停止遍歷,然后返回已統計到的字符個數,即為字符串長度。
很明顯,C 語言獲取字符串長度的時間復雜度是 O(N) (這是一個可以改進的地方)。
C 語言字符串用“\0”字符作為結尾標記有個缺陷。假設有個字符串中有個“\0”字符,這時在操作這個字符串時就會提早結束,比如“ab\0c“字符串,計算字符串長度的時候則會是 4。
因此,除了字符串的末尾之外,字符串里面不能還有“\0”字符,否則最先被程序讀入的“\0”字符將被誤認為是字符串結尾,這個限制使得 C 語言的字符串只能保存文本數據,不能保存像圖片、音頻、視頻這樣的二進制數據 (這也是一個可以改進的地方)。
另外,C 語言標準庫中字符串的操作函數是很不安全的,對程序員很不友好,稍微一不注意,就會導致緩沖區溢出。
舉個例子,strcat 函數是可以將兩個字符串拼接在一起。
// 將 src 字符串拼接到 dest 字符串后面
char *strcat(char *dest, const char* src);C 語言的字符串是不會記錄自身緩沖區大小的,所以 strcat 函數假定程序員在執行這個函數時,已經為 dest 分配了足夠多的內存,可以容納 src 字符串中的所有內容,而一旦這個假定不成立,就會發生緩沖區溢出可能會造成程序運行終止 (這也是一個可以改進的地方)。
好了,通過以上的分析,我們可以得知 C 語言的字符串不足之處以及可以改進的地方:
-
獲取字符串長度的時間復雜度為 O(N);
-
字符串的結尾是以“\0”字符表示,字符串中不能包含有“\0”字符,因此不能保存二進制數據;
-
字符串操作函數不高效且不安全,比如有緩沖區溢出的風險,有可能會造成程序運行終止;
Redis 實現的 SDS 的結構就把上面的這些問題解決了,我們看看 Redis 是如何解決的。
2. SDS 結構設計
下面是 Redis 5.0 的 SDS 數據結構:

結構中的每個成員變量分別是:
-
len,記錄了字符串長度。這樣獲取字符串長度的時候,只需要返回這個成員變量值就行,時間復雜度只需要 O(1)。
-
alloc,分配給字符數組的空間長度。這樣在修改字符串的時候,可以通過
alloc - len計算出剩余的空間大小,可以用來判斷空間是否滿足修改需求,如果不滿足的話,就會自動將 SDS 的空間擴展至執行修改所需要的大小,然后才執行實際的修改操作,所以使用 SDS 既不需要手動修改 SDS 的空間大小,也不會出現前面所說的緩沖區溢出的問題。 -
flags,用來表示不同類型的 SDS。一共設計了 5 種類型,分別是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面再說明區別之處。
-
buf[],字符數組,用來保存實際數據。不僅可以保存字符串,也可以保存二進制數據。
總的來說,Redis 的 SDS 結構在原本字符數組之上,增加了三個元數據:len、alloc、flags,用來解決 C 語言字符串的缺陷。
2.1 O(1)復雜度獲取字符串長度
C 語言的字符串長度獲取 strlen 函數,需要通過遍歷的方式來統計字符串長度,時間復雜度是 O(N)。
而 Redis 的 SDS 結構因為加入了 len 成員變量,那么獲取字符串長度的時候,直接返回這個成員變量的值就行,所以復雜度只有 O(1)。
2.2 二進制安全
因為 SDS 不需要用 “\0”字符來表示字符串結尾了,而是有個專門的 len 成員變量來記錄長度,所以可存儲包含 “\0”的數據。但是 SDS 為了兼容部分 C 語言標準庫的函數,SDS 字符串結尾還是會加上 “\0” 字符。
因此,SDS 的 API 都是以處理二進制的方式來處理 SDS 存放在 buf[] 里的數據,程序不會對其中的數據做任何限制,數據寫入的時候是什么樣的,它被讀取時就是什么樣的。
通過使用二進制安全的 SDS,而不是 C 字符串,使得 Redis 不僅可以保存文本數據,也可以保存任意格式的二進制數據。
2.3 不會發生緩沖區溢出
C 語言的字符串標準庫提供的字符串操作函數,大多數(比如 strcat 追加字符串函數)都是不安全的,因為這些函數把緩沖區大小是否滿足操作需求的工作交由開發者來保證,程序內部并不會判斷緩沖區大小是否足夠用,當發生了緩沖區溢出就有可能造成程序異常結束。
所以,Redis 的 SDS 結構里引入了 alloc 和 len 成員變量,這樣 SDS API 通過 alloc - len計算,可以算出剩余可用的空間大小,這樣在對字符串做修改操作的時候,就可以由程序內部判斷緩沖區大小是否足夠用。
而且,當判斷出緩沖區大小不夠用時,Redis 會自動擴大 SDS 的空間大小,以滿足修改所需的大小。
SDS 擴容的規則代碼如下:
hisds hi_sdsMakeRoomFor(hisds s, size_t addlen)
{... ...// s 目前的剩余空間已足夠,無需擴展,直接返回if (avail >= addlen)return s;// 獲取目前 s 的長度len = hi_sdslen(s);sh = (char *)s - hi_sdsHdrSize(oldtype);// 擴展之后,s 至少需要的長度newlen = (len + addlen);// 根據新長度,為 s 分配新空間所需的大小if (newlen < HI_SDS_MAX_PREALLOC)// 新長度 < HI_SDS_MAX_PREALLOC 則分配所需空間 *2 的空間newlen *= 2;else// 否則,分配長度為目前長度 +1 MBnewlen += HI_SDS_MAX_PREALLOC;...
}-
如果所需的 sds 長度小于 1 MB,那么最后的擴容是按照翻倍擴容來執行的,即 2 倍 的 newlen
-
如果所需的 sds 長度超過 1 MB,那么最后的擴容長度應該是 newlen + 1MB。
在擴容 SDS 空間之前,SDS API 會優先檢查未使用空間是否足夠,如果不夠的話,API 不僅會為 SDS 分配修改所必須要的空間,還會給 SDS 分配額外的【未使用空間】。
這樣的好處是,下次再操作 SDS 時,如果 SDS 空間夠的話,API 就會直接使用【未使用空間】,而無須執行內存分配,有效的減少內存分配次數。
所以,使用 SDS 既不需要手動修改 SDS 的空間大小,也不會出現緩沖區溢出的問題。
2.4 節省內存空間
SDS 結構中有個 flags 成員變量,表示的是 SDS 類型。
Redis 一共設計了 5 種類型,分別是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
這 5 中類型的主要區別就在于,它們數據結構中的 len 和 alloc 成員變量的數據類型不同。
比如 sdshdr16 和 sdshdr32 這兩個類型,它們的定義分別如下:
struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len;uint16_t alloc; unsigned char flags; char buf[];
};
?
?
struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len;uint32_t alloc; unsigned char flags;char buf[];
};可以看到:
-
sdshdr16 類型的 len 和 alloc 的數據類型都是 uint16_t,表示字符數組長度和分配空間大小不能超過 2 的 16 次方。
-
sdshdr32 則都是 uint32_t,表示字符數組長度和分配空間大小不能超過 2 的 32 次方。
之所以 SDS 設計不同類型的結構體,是為了能靈活保存不同大小的字符串,從而有效節省內存空間。比如,在保存小字符串時,結構頭占用空間也比較小。
除了設計不同類型的結構體,Redis 在編程上還使用了專門的編譯優化來節省內存空間,即在 struct 聲明了 __attribute__ ((packed)) ,它的作用是:告訴編譯器取消結構體在編譯過程中的優化對齊,按照實際占用字節數進行對齊。
比如,sdshdr16 類型的 SDS,默認情況下,編譯器會按照 2 字節對齊的方式給變量分配內存,這意味著,即使一個變量的大小不到 2 個字節,編譯器也會給它分配 2 個字節。
舉個例子,假設下面這個結構體,它有兩個成員變量,類型分別是 char 和 int,如下所示:
#include <stdio.h>
?
struct test1 {char a;int b;} test1;int main() {printf("%lu\n", sizeof(test1));return 0;
}這個結構體大小計算出來是 8:

這是因為默認情況下,編譯器是使用【字節對齊】的方式分配內存,雖然 char 類型只占一個字節,但是由于成員變量有 int 類型,它占用 4 個字節,所以在成員變量為 char 類型分配內存時,會分配 4 個字節,其中這多余的 3 個字節是為了字節對齊而分配的,相當于有 3 個字節被浪費掉了。
如果不想編譯器使用字節對齊的方式進行分配內存,可以采用 __attribute__((packed)) 屬性定義結構體,這樣一來,結構體實際占用多少內存空間,編譯器就分配多少空間。
比如,我用 __attribute__ ((packed)) 屬性定義下面的結構體 ,同樣包含 char 和 int 兩個類型的成員變量,代碼如下所示:
#include <stdio.h>
?
struct __attribute__((packed)) test2 {char a;int b;} test2;int main() {printf("%lu\n", sizeof(test2));return 0;
}這是打印的結果是 5 (1 個字節 char + 4 字節 int)。
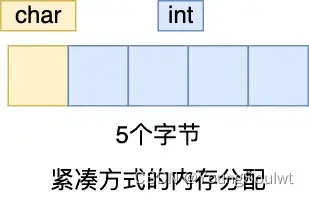
可以看得出,這是按照實際占用字節數進行分配內存的,這樣可以節省內存空間。
內存對齊:
是一種典型的“空間換時間”,通過犧牲一部分內存空間(通過填充來保持數據對齊),可以顯著提高 CPU 訪問內存的效率。


win10、11鏡像文件)
![PS Mac Photoshop 2024 for Mac[破]圖像處理軟件[解]PS 2024安裝教程[版]](http://pic.xiahunao.cn/PS Mac Photoshop 2024 for Mac[破]圖像處理軟件[解]PS 2024安裝教程[版])









)
)
——DQL分組查詢)


 QLineEdit介紹)
