前言
首先我們看一下產品的需求背景,這個產品為了解決招聘面試的過程中,線下面試管理效率低,面試過程和結果不方便跟蹤的痛點
招聘管理的系統幾乎是每一家中小公司都需要的產品
我們以校園招聘的面試為例子來做 MVP 產品迭代
首先我們來看一下線下的面試流程,線下面試流程分成三個步驟:
第一個步驟,hr 發出面試評估表,到一面面試官
這個評估表是word格式的模板,hr 通過郵箱發出來到面試官,然后一面面試官登錄到郵箱,下載word模板,為每個學生拷貝一份模板文件,使用學生的名字來重命名面試評估表,在評估表里面錄入學生的名字,學校電話學歷等等
第二個步驟,進行第一輪面試,由一面的面試官來面試
每面完一個候選人,面試官把面試的結論填寫到word格式的評估表中,一名面試官在面完一批學生之后,批量把 word 格式的評估表發送給hr,hr查收下載評估表,匯總結果到 excel,然后發送到技術二面的面試官做復試,通知二面面試官繼續做二面
第三個步驟,二面面試官查收并下載 word 格式的評估記錄,開始二面
二面結束后,同樣的把面試結論追加到 word 格式的面試評估表中,然后再郵件通知hr哪些候選人通過了二面,接下來hr繼續重復前面的操作,做第三輪面試
最后,用Excel匯總,哪些人過了三面,需要通知候選人已經被錄取

面試評估表里面有候選人的基礎信息,包括姓名、手機號、應聘職位、畢業院校,專業筆試的成績,綜合能力測評的成績
也有一面的初始成績,這一輪評估候選人的學習能力和專業能力
然后還有第二輪復試,這一輪評估候選人的追求卓越的能力,溝通能力和抗壓能力等等
以及最終的 hr 復試,hr 復試會評估軟性的數字,包括責任心、溝通能力、邏輯思維,給出最終復試的結論,分成4個等級,最后擇優錄取
MVP 產品迭代思想
看起來面試流程蠻復雜的,要能夠管理候選人有不同的角色,需要錄入不同內容,還要根據狀態來判斷要不要繼續后續面試,這么多的功能怎么樣能夠在一天之內交付可以使用的面試招聘系統
這個就需要使用到產品的迭代思維,我們一起來學習迭代的思維,一起思考怎么樣做 MVP 產品的迭代劃分

MVP 包含了產品的輪廓,核心的功能,能夠讓業務運轉起來的最小功能子集,這個版本我們可以叫它內褲版本
所以如果我們規劃一個版本,開發半年或者一年以上交付一個大而全的產品,往往到最后開發出來的都不是用戶想要的
同時經過了這么長的時間,用戶市場需求都已經變化了很多,我們還在原地踏步
抱著最初認為正確的產品方案在開發,所以長迭代非常可怕,盡量把你的迭代周期控制在周的單位,甚至是天或者小時為單位
MVP 版本開發出來之后,再開始下一個迭代,繼續下一個 MVP 版本,同樣是找出對于當前版本的需求來說最核心最重要的功能放在迭代交付,然后再交付下一個迭代,這個是產品的迭代思維,迭代思維是最強大的產品思維邏輯,也是互聯網唯快不破的秘密
MVP 迭代思想應用
接下來我們一起來看看怎么樣把 MVP 迭代的思想,應用到我們的招聘面試的系統里面來
我們先來看一下產品的用戶場景和功能有哪些:

我們把產品 MVP 迭代的思維應用到了我們面試招聘的系統里面來,幫我們找出系統里面最核心的兩個功能:
一個功能是能夠維護候選人的信息
另外一個功能是能夠去做面試評估,去反饋在系統里面錄入面試評估的結論
數據庫設計原則
現在對我們的系統進行建模,并且講解企業級數據庫設計的10個原則
數據建模圖如下:

我們來講企業級數據庫設計的10個原則:



我們將創建面試評估的應用,然后創建數據庫模型,創建數據庫模型的時候,記得要遵循這些設計原則
創建 interview 應用
實現候選人面試評估表的增刪改功能,并且按照頁面分組來展示不同的內容,如候選人基礎信息,一面,二面的面試結果,HR 的面試結果
我們可以使用 pycharm 上面菜單欄中 Tools 里的 Run manage.py task,這樣就不用每次都輸入前面的命令了
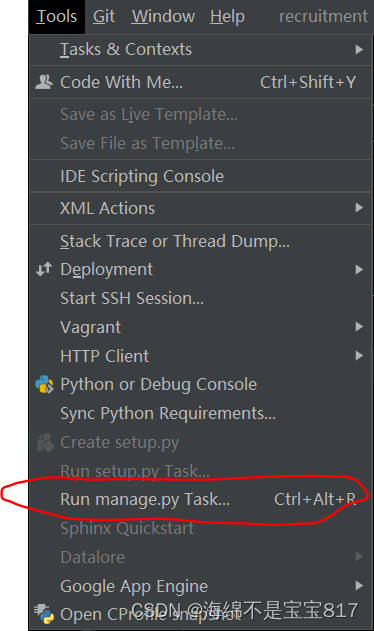
輸入命令 startapp interview

創建完應用后,打開 models.py 文件,開始編寫數據建模代碼
from django.db import models# 第一論面試結果
FIRST_INTERVIEW_RESULT_TYPE = (('建議復試','建議復試'),('待定','待定'),('放棄','放棄'))# 復試面試建議
INTERVIEW_RESULT_TYPE = (('建議錄用','建議錄用'),('待定','待定'),('放棄','放棄'))# 候選人學歷
DEGREE_TYPE = (('本科','本科'),('碩士','碩士'),('博士','博士'))# HR終面結論
HR_SCORE_TYPE = (('S','S'),('A','A'),('B','B'),('C','C'))class Candidate(models.Model):# 基礎信息userid = models.IntegerField(unique=True, blank=True, null=True, verbose_name='應聘者ID')username = models.CharField(max_length=135, verbose_name='姓名')city = models.CharField(max_length=135, verbose_name='城市')phone = models.CharField(max_length=135, verbose_name='手機號碼')email = models.EmailField(max_length=135, blank=True, verbose_name='郵箱')apply_position = models.CharField(max_length=135, blank=True, verbose_name='應聘職位')born_address = models.CharField(max_length=135, blank=True, verbose_name='生源地')gender = models.CharField(max_length=135, blank=True, verbose_name='性別')candidate_remark = models.CharField(max_length=135, blank=True, verbose_name='候選人信息備注')# 學校與學歷信息bachelor_school = models.CharField(max_length=135, blank=True, verbose_name=' 本科學校')master_school = models.CharField(max_length=135, blank=True, verbose_name='研究生學校')doctor_school = models.CharField(max_length=135, blank=True, verbose_name='博士生學校')major = models.CharField(max_length=135, blank=True, verbose_name='專業')degree = models.CharField(max_length=135, choices=DEGREE_TYPE, blank=True, verbose_name='學歷')# 綜合能力測評成績,筆試測評成績test_score_of_general_ability = models.DecimalField(decimal_places=1,null=True,max_digits=3,blank=True,verbose_name='綜合能力測評成績')paper_score = models.DecimalField(decimal_places=1, null=True, max_digits=3, blank=True, verbose_name='筆試成績')# 第一輪面試記錄first_score = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='初始分')first_learning_ability = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='學習能力得分')first_professional_competency = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='專業能力得分')first_advantage = models.TextField(max_length=1024, blank=True, verbose_name='優勢')first_disadvantage = models.TextField(max_length=1024, blank=True, verbose_name='顧慮和不足')first_result = models.CharField(max_length=256, choices=FIRST_INTERVIEW_RESULT_TYPE, blank=True,verbose_name='初試結果')first_recommend_position = models.CharField(max_length=256, blank=True, verbose_name='推薦部門')first_interviewer = models.CharField(max_length=256, blank=True, verbose_name='初試面試官')first_remark = models.CharField(max_length=135, blank=True, verbose_name='初試備注')# 第二輪面試記錄second_score = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='專業復試得分')second_learning_ability = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,verbose_name='學習能力得分')second_professional_competency = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,verbose_name='專業能力得分')second_pursue_of_excellence = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,verbose_name='追求卓越得分')second_communication_ability = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,verbose_name='溝通能力得分')second_pressure_score = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,verbose_name='抗壓能力得分')second_advantage = models.TextField(max_length=1024, blank=True, verbose_name='優勢')second_disadvantage = models.TextField(max_length=1024, blank=True, verbose_name='顧慮和不足')second_result = models.CharField(max_length=256, choices=INTERVIEW_RESULT_TYPE, blank=True,verbose_name='專業復試結果')second_recommend_position = models.CharField(max_length=256, blank=True, verbose_name='建議方向或推薦部門')second_interviewer = models.CharField(max_length=256, blank=True, verbose_name='專業復試面試官')second_remark = models.CharField(max_length=135, blank=True, verbose_name='專業復試備注')# HR終面hr_score = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,verbose_name='HR復試綜合等級')hr_responsibility = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,verbose_name='HR責任心')hr_communication_ability = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,verbose_name='HR坦誠溝通')hr_logic_ability = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,verbose_name='HR邏輯思維')hr_potential = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,verbose_name='HR發展潛力')hr_stability = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,verbose_name='HR穩定性')hr_advantage = models.TextField(max_length=1024, blank=True, verbose_name='優勢')hr_disadvantage = models.TextField(max_length=1024, blank=True, verbose_name='顧慮和不足')hr_result = models.CharField(max_length=256, choices=INTERVIEW_RESULT_TYPE, blank=True,verbose_name='HR面試結果')hr_interviewer = models.CharField(max_length=256, blank=True, verbose_name='HR面試官')hr_remark = models.CharField(max_length=135, blank=True, verbose_name='HR復試備注')creator = models.CharField(max_length=256, blank=True, verbose_name='候選人數據的創建人')created_date = models.DateTimeField(auto_now_add=True, verbose_name="創建時間")modified_date = models.DateTimeField(auto_now_add=True, null=True, blank=True, verbose_name="更新時間")last_editor = models.CharField(max_length=256, blank=True, verbose_name='最后編輯者')class Meta:db_table = 'candidate'verbose_name = '應聘者'verbose_name_plural = '應聘者'def __str__(self):return self.username然后在 admin.py 文件注冊數據模型,并且展示時隱藏一些字段
from django.contrib import admin
from interview.models import Candidateclass CandidateAdmin(admin.ModelAdmin):exclude = ('creator','created_date','modified_date')list_display = ('username','city','bachelor_school','first_score','first_result','first_interviewer','second_result','second_interviewer','hr_score','hr_result','last_editor')admin.site.register(Candidate,CandidateAdmin)再到 setting.py 文件注冊應用
INSTALLED_APPS = ['django.contrib.admin','django.contrib.auth','django.contrib.contenttypes','django.contrib.sessions','django.contrib.messages','django.contrib.staticfiles','jobs','interview'
]最后執行數據庫遷移,還是那兩個命令
makemigrations
migrate?效果圖如下:

頁面分組展示
大家看到這個頁面其實非常長,因為我們的字段實在是太多了,用起來很復雜,所以面試官也好,還是hr也好,他們其實不太清楚哪些內容是他需要填的,所以我們對這個頁面進行優化,把這個頁面的內容分組展示
為了方便,我們使用 pycharm 的代碼編輯器,新建一個文本文檔,把 models.py 里面的字段粘貼過來,然后在這個文件里面去做批量編輯。
首先 ctrl r 來做一個正則表達式的替換,輸入 =.*$
然后點擊星號匹配,再點擊 replace all ,替換掉所有,再刪除一些多余的字段

然后再輸入一個空格,再點擊 replace all ,替換掉所有的空格
然后再輸入 ^ 和 '' ,再點擊 replace all ,替換開頭為 "

然后再輸入? $ 和 '' ,再點擊 replace all ,替換結尾為 "

然后再輸入? $ 和 , ,再點擊 replace all ,替換結尾為 ,

最后點 edit 這里有個 join line,可以把字段都連起來

再刪除一些多余的標點,最后的成果如下
#基礎信息,學校與學歷信息,綜合能力測評成績,筆試測評成績,
"userid", "username", "city", "phone", "email", "apply_position", "born_address", "gender", "candidate_remark", "bachelor_school", "master_school", "doctor_school", "major", "degree", "test_score_of_general_ability", "paper_score",#第一輪面試記錄,
"first_score", "first_learning_ability", "first_professional_competency", "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark",#第二輪面試記錄,
"second_score", "second_learning_ability", "second_professional_competency", "second_pursue_of_excellence", "second_communication_ability", "second_pressure_score", "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark",#HR終面,
"hr_score", "hr_responsibility", "hr_communication_ability", "hr_logic_ability", "hr_potential", "hr_stability", "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark",然后把這些字段添加到 admin.py 文件的函數里,同時在字段之前添加小括號來分小組,讓一行可以展示多個數據
class CandidateAdmin(admin.ModelAdmin):...fieldsets = ((None,{'fields':("userid", ("username", "city"), ("phone", "email"), ("apply_position", "born_address"), ("gender", "candidate_remark"), ("bachelor_school", "master_school", "doctor_school"), ("major", "degree"), ("test_score_of_general_ability", "paper_score"))}),('第一輪面試記錄', {'fields': (("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark")}),('第二輪專業復試記錄', {'fields': (("second_score", "second_learning_ability", "second_professional_competency"), ("second_pursue_of_excellence", "second_communication_ability", "second_pressure_score"), "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark")}),('HR復試記錄', {'fields': (("hr_score", "hr_responsibility", "hr_communication_ability"), ("hr_logic_ability", "hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark")}))刷新界面,發現已經分好組了。這里我就不截圖了,太長。
導入候選人 csv 文件
接下來我們再做進一步優化,一般我們都不會自己去輸入候選人的基本信息,而是會拿到候選人的 excel 表,或者 csv 文件,那么如何導入候選人 csv 文件呢?
我們在 interview 應用下創建文件夾目錄 management/commands ,創建 import_candidates.py 文件,添加如下代碼
import csvfrom django.core.management import BaseCommand
from interview.models import Candidateclass Command(BaseCommand):help = "從csv導入候選人基本信息"def add_arguments(self, parser):parser.add_argument('--path', type=str)def handle(self, *args, **options):path = options['path']#編碼格式選擇合適的with open(path, 'rt',encoding='gbk') as f:#csv分割符選擇合適的,不選默認為','分割#reader = csv.reader(f,dialect='excel',delimiter=';')reader = csv.reader(f, dialect='excel')for row in reader:candidate = Candidate.objects.create(username=row[0],city=row[1],phone=row[2],bachelor_school=row[3],major=row[4],degree=row[5],test_score_of_general_ability=row[6],paper_score=row[7])展示一下 excel 的內容
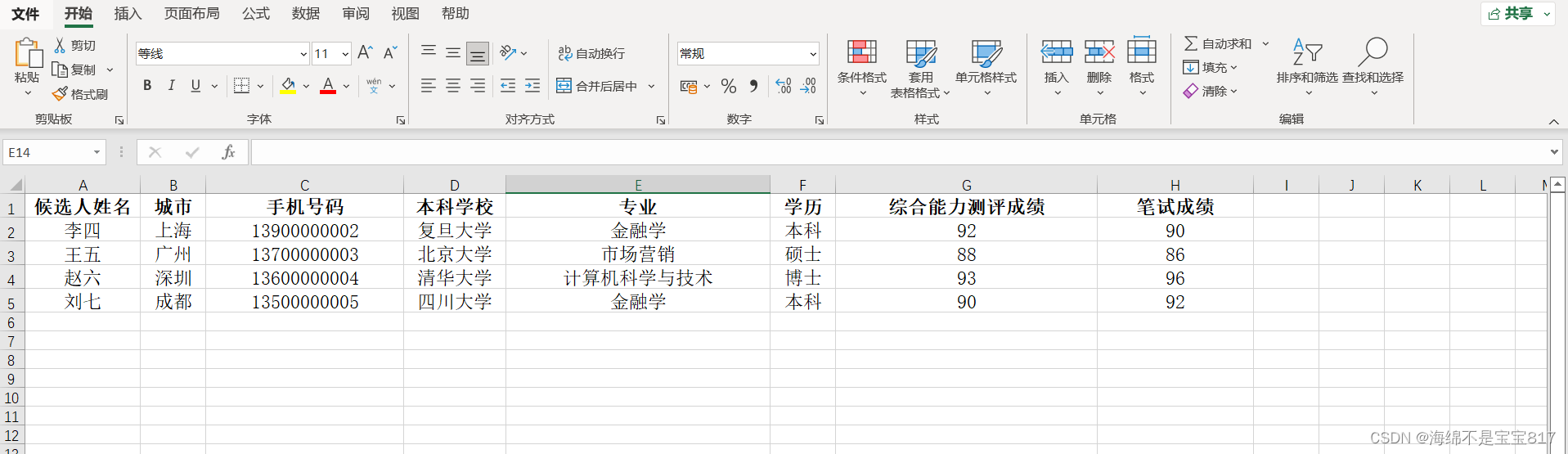
然后把 excel 文件導出為 csv 格式文件,并刪除第一行,如下圖

在 pycharm 的 run manage.py task 輸入命令
import_candidates --path C:/Users/ASUS/Desktop/candidates.csv刷新界面,發現導入成功

提高查詢效率
這個時候系統里面有很多簡歷了,成百上千的簡歷里面要查找特定候選人的簡歷,或者按照狀態來查詢待面試,或者已經面試通過的候選人查找的效率比較低,希望能夠快速查詢跟篩選,接下來我們實現下面的兩個功能。
第一個能夠按照名字、手機號碼學校來查詢候選人
第二個能夠按照初試的結果,HR 復試的結果面試官來篩選,然后也能夠按照復試結果來排序,復試通過的優先排在前面
修改 admin.py 文件為下面的代碼
from django.contrib import admin
from interview.models import Candidate
from datetime import datetimeclass CandidateAdmin(admin.ModelAdmin):exclude = ('creator','created_date','modified_date')list_display = ('username','city','bachelor_school','first_score','first_result','first_interviewer','second_result','second_interviewer','hr_score','hr_result','last_editor')# 篩選條件list_filter = ('city','first_result','second_result','hr_result','first_interviewer','second_interviewer','hr_interviewer')# 查詢字段search_fields = ('username','phone','email','bachelor_school')# 自動排序字段ordering = ('hr_result','second_result','first_result')# 分組展示字段fieldsets = ((None,{'fields':("userid", ("username", "city"), ("phone", "email"), ("apply_position", "born_address"), ("gender", "candidate_remark"), ("bachelor_school", "master_school", "doctor_school"), ("major", "degree"), ("test_score_of_general_ability", "paper_score"))}),('第一輪面試記錄', {'fields': (("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark")}),('第二輪專業復試記錄', {'fields': (("second_score", "second_learning_ability", "second_professional_competency"), ("second_pursue_of_excellence", "second_communication_ability", "second_pressure_score"), "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark")}),('HR復試記錄', {'fields': (("hr_score", "hr_responsibility", "hr_communication_ability"), ("hr_logic_ability", "hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark")}))def save_model(self, request, obj, form, change):obj.last_editor = request.user.usernameif not obj.creator:obj.creator = request.user.usernameobj.modified_date = datetime.now()obj.save()admin.site.register(Candidate,CandidateAdmin)效果圖:

分配權限
添加 hr 和 interviewer 用戶組,分別給 hr 和 面試官不同的權限

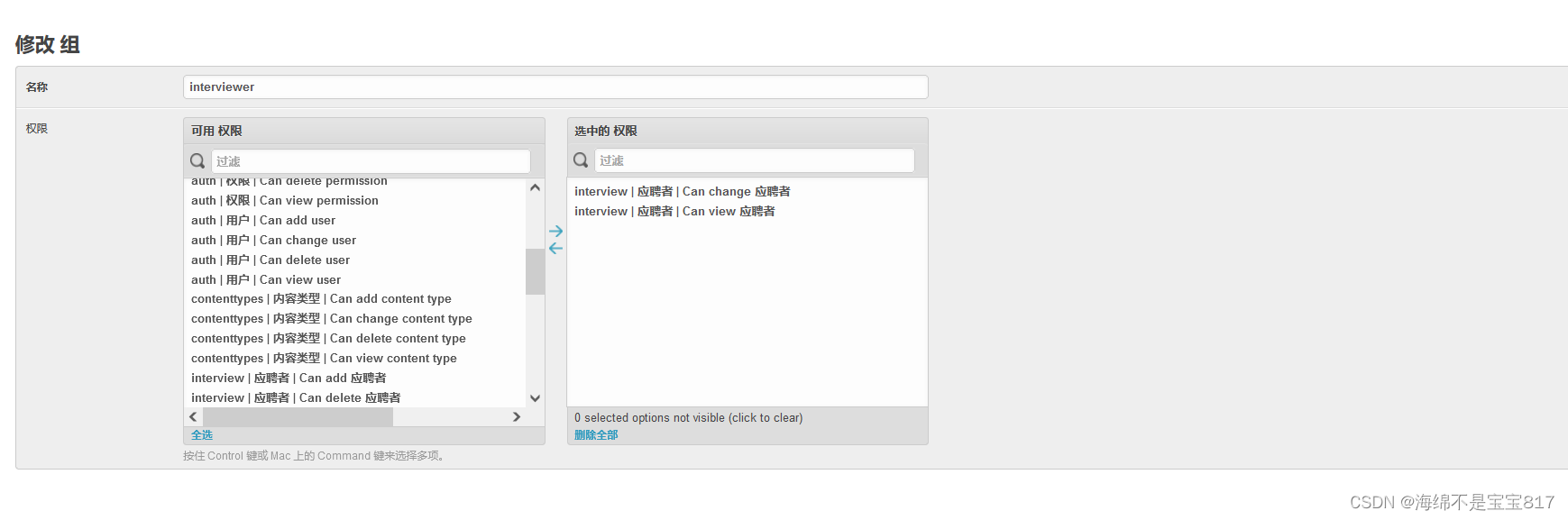
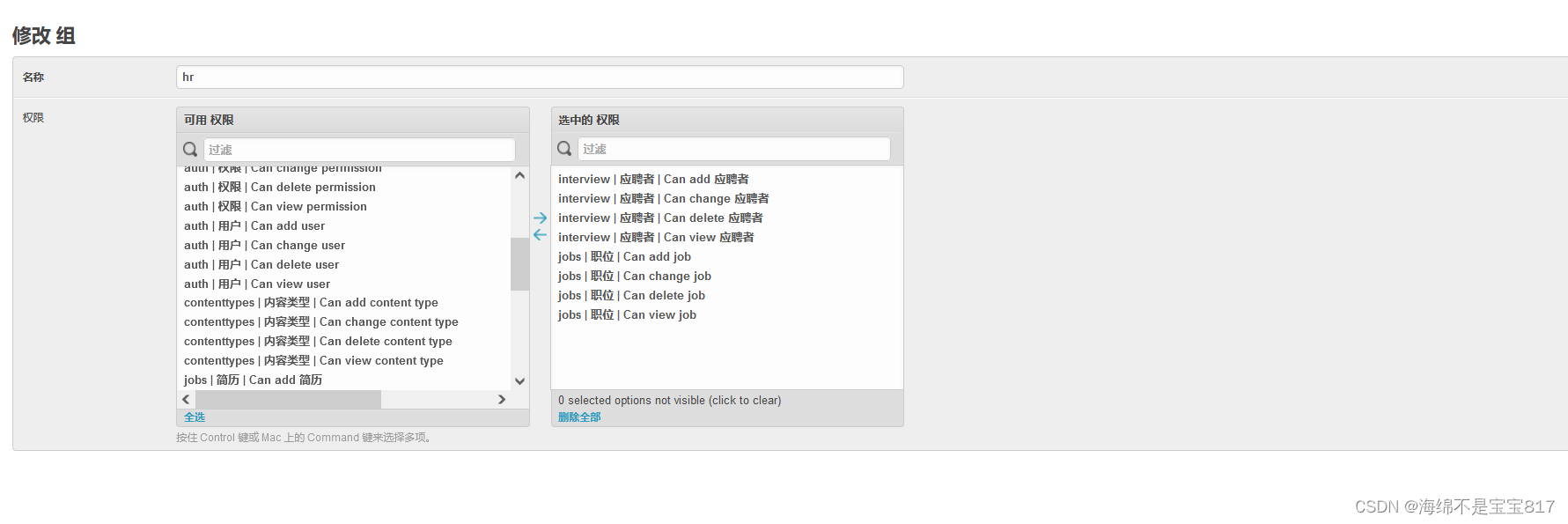
導出候選人面試結果 csv 文件
現在我們再加一個功能,將數據導出為 csv 文件,修改 admin.py 文件如下
from django.contrib import admin
from interview.models import Candidate
from datetime import datetime
from django.http import HttpResponse
import csvexportable_fields = ('username','city',"phone",'bachelor_school','degree','first_result','first_interviewer','second_result','second_interviewer','hr_score','hr_result')def export_model_as_csv(modeladmin,request,queryset):response = HttpResponse(content_type='text/csv')field_list = exportable_fields#可以使用 request 中的 User-Agent 進行客戶端系統判斷,如果用戶的系統是 Windows,那么給導出的文件編碼設置為帶有 BOM 的 UTF-8,否則使用 UTF-8response.charset = 'utf-8-sig' if "Windows" in request.headers.get('User-Agent') else 'utf-8'#Content-Disposition 響應標頭指示回復的內容該以何種形式展示,是以內聯的形式(即網頁或者頁面的一部分),還是以附件的形式下載并保存到本地response['Context-Disposition'] = 'attachment;filename="recruitment-candidates-list-%s.csv"' %(datetime.now().strftime('%Y-%m-%d-%H-%M-%S'))# 寫入表頭print(response['Context-Disposition'])writer = csv.writer(response)writer.writerow([queryset.model._meta.get_field(f).verbose_name.title() for f in field_list])for obj in queryset:# 單行的記錄(各個字段的值),寫入csv文件csv_line_values = []for field in field_list:field_object = queryset.model._meta.get_field(field)field_value = field_object.value_from_object(obj)csv_line_values.append(field_value)writer.writerow(csv_line_values)return response#國際化文本
export_model_as_csv.short_description = '導出為CSV文件'class CandidateAdmin(admin.ModelAdmin):actions = [export_model_as_csv]exclude = ('creator','created_date','modified_date')list_display = ('username','city','bachelor_school','first_score','first_result','first_interviewer','second_result','second_interviewer','hr_score','hr_result','last_editor')# 篩選條件list_filter = ('city','first_result','second_result','hr_result','first_interviewer','second_interviewer','hr_interviewer')# 查詢字段search_fields = ('username','phone','email','bachelor_school')# 自動排序字段ordering = ('hr_result','second_result','first_result')# 分組展示字段fieldsets = ((None,{'fields':("userid", ("username", "city"), ("phone", "email"), ("apply_position", "born_address"), ("gender", "candidate_remark"), ("bachelor_school", "master_school", "doctor_school"), ("major", "degree"), ("test_score_of_general_ability", "paper_score"))}),('第一輪面試記錄', {'fields': (("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark")}),('第二輪專業復試記錄', {'fields': (("second_score", "second_learning_ability", "second_professional_competency"), ("second_pursue_of_excellence", "second_communication_ability", "second_pressure_score"), "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark")}),('HR復試記錄', {'fields': (("hr_score", "hr_responsibility", "hr_communication_ability"), ("hr_logic_ability", "hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark")}))def save_model(self, request, obj, form, change):obj.last_editor = request.user.usernameif not obj.creator:obj.creator = request.user.usernameobj.modified_date = datetime.now()obj.save()admin.site.register(Candidate,CandidateAdmin)效果圖:

點擊執行成功下載,打開文件效果如下
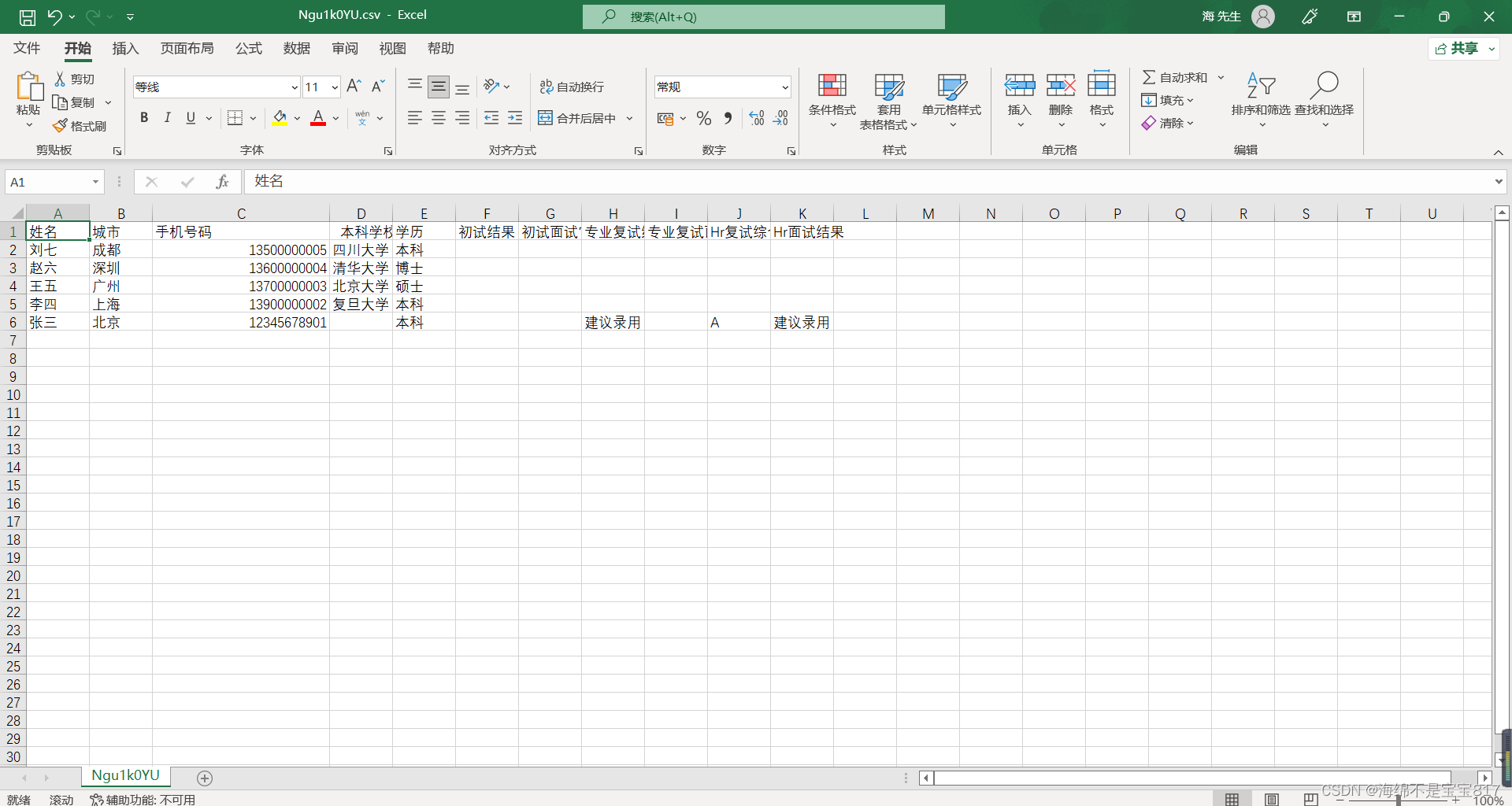
目前這個導出 csv 文件的文件名會顯示亂碼,并不能輸出我們期望的文件名,暫時我并沒有找到解決方法,如果有寫出來的大佬,務必私信我,感謝!!!
第四階段完成!




)
)
——DQL分組查詢)


 QLineEdit介紹)





)



