- 回歸類型數據挖掘任務
基于ARIMA和多層神經網絡模型的地鐵站點日客流量預測。有鄭州市2015年8月-11月各地鐵閘機刷卡數據集。對每日各地鐵站的客流量進行分析并進行可視化。基于上一步的分析結果,分別采用ARIMA模型和多層神經網絡模型對數據進行建模,訓練優化模型并分別給出評估指標。
原始數據如下所示,共分為4個文件,近15GB。


2.1總體流程

2.2數據分析
2.2.1讀取數據
使用pandas讀取下列文件,并將讀取到的DataFrame進行合并。
acc_08_final_mini.csv
acc_09_final_mini.csv
acc_10_final_mini.csv
acc_11_final_mini.csv
得到的DataFrame如圖所示:
代碼:
import pandas as pd
# 創建一個空的DataFrame列表來存儲所有讀取的DataFrame
df_list = [] # 循環讀取所有CSV文件
for year in range(8, 12): # 從2008年到2011年 filename = fr'C:\Users\zjl15\PycharmProjects\pythonProject1\shixundata\2\acc_{year:02d}_final_mini.csv' # 注意fr的使用 df = pd.read_csv(filename) # 讀取CSV文件 df_list.append(df) # 將讀取的DataFrame添加到列表中 # 使用concat函數進行縱向合并(堆疊)
combined_df = pd.concat(df_list, ignore_index=True) # 顯示合并后的DataFrame
print(combined_df) 
特征含義:
| 特征名 | TRADE_TYPE | TRADE_ADDRESS | TRADE_DATE |
| 含義 | 交易類型 21:進站 22:出站 | 交易站點 | 交易時間 |
2.2.2分析數據
2.2.2.1日期處理
提取TRADE_DATE中的日期部分作為新的TRADE_DATE的內容。
建議使用pandas庫的apply函數。
2.2.2.2分組統計
統計各個站點每天的客流量,并將客流量數據作為1列加入到原數據中,列名為COUNT。建議使用pandas庫的groupby函數和transform函數。
2.2.2.3刪除TRADE_TYPE列
因本次分析不考慮交易類型這個因素,因此要刪掉TRADE_TYPE列。建議使用pandas庫的drop函數。
2.2.2.4排序去重
將數據按照TRADE_ADDRESS和TRADE_DATE兩列進行排序,并進行去重處理。建議使用pandas庫的sort_values函數和drop_duplicates函數。
# 將 TRADE_DATE 列轉換為 datetime 類型
combined_df['TRADE_DATE'] = pd.to_datetime(combined_df['TRADE_DATE'], format='%Y-%m-%d-%H.%M.%S.%f')
# 使用 apply 函數提取日期部分并創建新的列
combined_df['DATE_ONLY'] = combined_df['TRADE_DATE'].apply(lambda x: x.date())
#去除TRADE_DATE列
df=combined_df.drop(columns=['TRADE_DATE'])
# 使用 groupby 和 transform 計算每個站點每天的交易數量并將結果作為新列加入原數據
df['COUNT'] = df.groupby(['DATE_ONLY', 'TRADE_ADDRESS'])['TRADE_TYPE'].transform('count')
#去除TRADE_TYPE列
df=df.drop(columns=['TRADE_TYPE'])
# 按照 TRADE_ADDRESS 和 DATE_ONLY 進行排序
df_sorted = df.sort_values(by=['TRADE_ADDRESS', 'DATE_ONLY'])
# 去重處理
df_unique = df_sorted.drop_duplicates(subset=['TRADE_ADDRESS', 'DATE_ONLY'])
# 根據日期和站點對數據進行分組,并計算客流量總和
grouped_data = df_unique.groupby(['DATE_ONLY', 'TRADE_ADDRESS'])['COUNT'].sum().unstack()?
2.2.2.5繪制所有站點8月1日-11月30日的客流量折線圖
# 繪制折線圖
grouped_data.plot(figsize=(12, 8))
plt.title('Daily Traffic for Each Station')
plt.xlabel('Date')
plt.ylabel('Traffic Count')
plt.legend(title='Station', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()?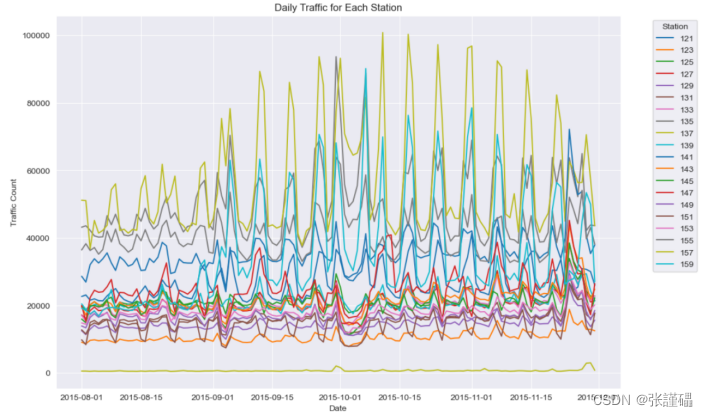
2.3模型構建
2.3.1 ARIMA模型(以121站點為例)
以2.2.2.4步驟中的數據為基礎,篩選出TRADE_ADDRESS=121的行。
以121站點客流量數據為例,使用時間序列分析方法進行建模。
# 從原始數據中篩選出TRADE_ADDRESS=121的行
data_121 = df_unique[df_unique['TRADE_ADDRESS'] == 121]
#重新定義一個變量,將數據備份
data = data_121
#刪除多余的列
data_121 = data_121.drop(columns=['TRADE_ADDRESS','DATE_ONLY'])2.3.1.1劃分訓練集和測試集
共122條記錄,前115條為訓練集,后7條為測試集
# 劃分訓練集和測試集
train_set = data_121.iloc[:115]
test_set = data_121.iloc[115:]2.3.1.2平穩性檢驗
對訓練集進行平穩性檢驗,分別采用時序圖、自相關圖、ADF單位根檢測方法。
(1)繪制時序圖
(2)繪制自相關圖
(3)ADF單位根檢測
通過檢驗,發現該序列為非平穩序列。如想使用ARIMA模型進行建模分析,需處理轉換為平穩序列。
# 繪制時序圖
plt.figure(figsize=(12, 6))
plt.plot(train_set['COUNT'])
plt.title('Traffic Count at Station 121 (Training Set)')
plt.xlabel('Date')
plt.ylabel('Traffic Count')
plt.show()
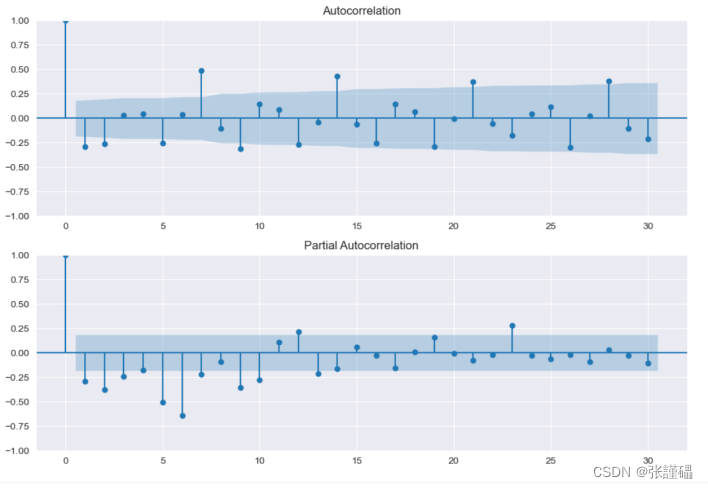
# 繪制自相關圖
fig, ax = plt.subplots(2, 1, figsize=(12, 8))
sm.graphics.tsa.plot_acf(train_set['COUNT'], lags=30, ax=ax[0])
sm.graphics.tsa.plot_pacf(train_set['COUNT'], lags=30, ax=ax[1])
plt.show()
# ADF單位根檢測
result = adfuller(train_set['COUNT'])
print('ADF Statistic:', result[0])
print('p-value:', result[1])
print('Critical Values:', result[4])?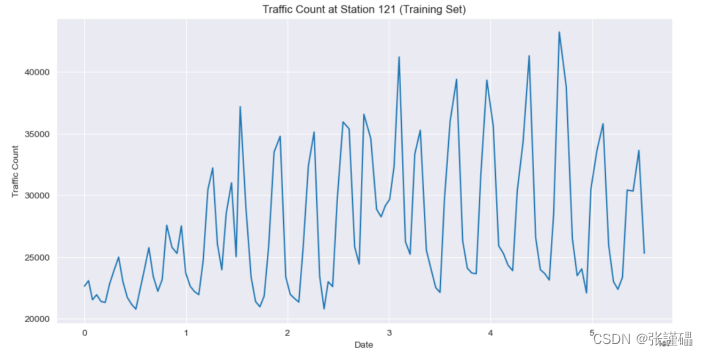
?
2.3.1.3差分處理
使用2階差分對訓練集進行處理。
對差分處理后的訓練集再次進行平穩性檢驗,分別采用時序圖、自相關圖、ADF單位根檢測方法。
# 對訓練集進行2階差分處理
train_set_diff = train_set['COUNT'].diff().diff().dropna()# 繪制2階差分后的時序圖
plt.figure(figsize=(12, 6))
plt.plot(train_set_diff)
plt.title('Differenced Traffic Count at Station 121 (Training Set)')
plt.xlabel('Date')
plt.ylabel('Differenced Traffic Count')
plt.show()
# 繪制2階差分后的自相關圖
fig, ax = plt.subplots(2, 1, figsize=(12, 8))
sm.graphics.tsa.plot_acf(train_set_diff, lags=30, ax=ax[0])
sm.graphics.tsa.plot_pacf(train_set_diff, lags=30, ax=ax[1])
plt.show()
# ADF單位根檢測(2階差分后)
result_diff = adfuller(train_set_diff)
print('ADF Statistic (after differencing):', result_diff[0])
print('p-value (after differencing):', result_diff[1])
print('Critical Values (after differencing):', result_diff[4])?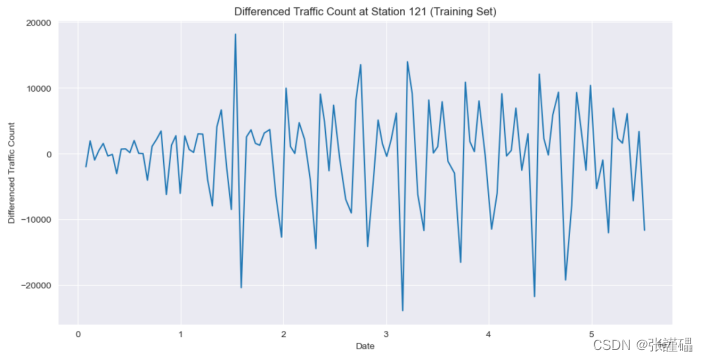
?
2.3.1.4純隨機性檢驗
對差分處理后的訓練集進行純隨機性檢驗。
# 計算自相關系數
acf = sm.tsa.acf(train_set_diff, fft=False)
# 繪制自相關函數圖
plt.figure(figsize=(12, 6))
plt.bar(range(len(acf)), acf)
plt.xlabel('Lag')
plt.ylabel('ACF')
plt.title('Autocorrelation Function')
plt.show()?
2.3.1.5 ARIMA模型建模
選擇合適的參數q和q來構建ARIMA模型。
2.3.1.6 ARIMA模型訓練
- 使用差分處理后的數據對ARIMA模型進行訓練
- 繪制訓練集真實值和預測值對比圖
參考代碼:
# 定義 ARIMA 模型的參數 (p, d, q)
p = 6 # 自回歸階數
d = 2 # 差分階數
q = 6 # 移動平均階數
# 訓練 ARIMA 模型
model = ARIMA(train_set, order=(p, d, q))
model_fit = model.fit()
# 使用訓練好的模型進行預測# 繪制訓練集真實值和預測值對比圖
plt.figure(figsize=(12, 6))
plt.plot(train_set, label='Actual')
plt.plot(forecast, label='Predicted', color='red')
plt.title('Comparison of Actual and Predicted Values')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
2.3.2多層神經網絡模型
2.3.2.1 特征構造
構造多層神經網絡模型所需特征。
- 篩選121站點數據
以2.2.2.4步驟中的數據為基礎,篩選出TRADE_ADDRESS=121的行。
- 刪掉TRADE_ADDRESS列
因所有行均為121站點的數據,所以TRADE_ADDRESS沒有意義,刪掉。建議使用pandas庫的drop函數。
- 從TRADE_DATE列中提取出星期幾數據
對TRADE_DATE列進行計算,根據日期推算出星期幾,然后賦值給新的一列TRADE_DAY。建議使用pandas庫的apply函數。
- 從TRADE_DAY列中提取出周末數據
對TRADE_DAY列進行計算,得出是否為周末,然后賦值給新的一列WEEKEND(1:周末,0:工作日)。建議使用pandas庫的apply函數。
- 從TRADE_DATE列中提取出月份數據
對TRADE_DATE列進行計算,提取出月份信息,然后賦值給新的一列MONTH。建議使用pandas庫的apply函數。
- 從TRADE_DATE列中提取出日數據
對TRADE_DATE列進行計算,提取出日信息,然后賦值給新的一列DAY。建議使用pandas庫的apply函數。
- 刪掉TRADE_DATE列
TRADE_DATE里的信息已經提取完畢,可以刪掉。建議使用pandas庫的drop函數。
- 對數據的列進行重新排序
順序為:['MONTH','DAY','TRADE_DAY','WEEKEND', 'COUNT']
#刪掉TRADE_ADDRESS列
df = data.drop(columns=['TRADE_ADDRESS'])
# 將 DATE_ONLY 列轉換為日期時間類型
df['DATE_ONLY'] = pd.to_datetime(df['DATE_ONLY'])
# 使用 apply 函數計算星期幾,并賦值給新列 DAY_OF_WEEK
df['DAY_OF_WEEK'] = df['DATE_ONLY'].dt.day_name()
# 使用 dt.dayofweek + 1 將星期幾轉換為數字表示,并賦值給新列 DAY_OF_WEEK_NUM
df['DAY_OF_WEEK_NUM'] = df['DATE_ONLY'].dt.dayofweek + 1
#刪除DAY_OF_WEEK
df2 = df.drop(columns=['DAY_OF_WEEK'])
# 將 TRADE_DATE 列轉換為日期時間類型
df2['DATE_ONLY'] = pd.to_datetime(df2['DATE_ONLY'])
# 使用 apply 函數結合 dt.month 提取出月份信息,并賦值給新列 MONTH
df2['MONTH'] = df2['DATE_ONLY'].apply(lambda x: x.month)
# 使用 apply 函數結合 dt.day 提取出日信息,并賦值給新列 DAY
df2['DAY'] = df2['DATE_ONLY'].apply(lambda x: x.day)
#刪除DATE_ONLY
df2 = df2.drop(columns=['DATE_ONLY'])
# 自定義函數來判斷是否為周末
def is_weekend(day_of_week):return 1 if day_of_week >= 6 else 0
# 使用 apply 函數調用自定義函數對 DAY_OF_WEEK_NUM 列進行計算,生成 WEEKEND 列
df2['WEEKEND'] = df2['DAY_OF_WEEK_NUM'].apply(is_weekend)
#按指定順序排好['MONTH', 'DAY', 'DAY_OF_WEEK_NUM', 'WEEKEND', 'COUNT']
df2 = df2[['MONTH', 'DAY', 'DAY_OF_WEEK_NUM', 'WEEKEND', 'COUNT']]- 繪制數據的多變量聯合分布圖
使用seaborn庫的pairplot方法繪制數據的聯合分布圖。
# 繪制多變量聯合分布圖
sns.pairplot(df2)
plt.show()?
2.3.2.2劃分訓練集和測試集
- 提取特征x和目標值y
根據2.3.2.1構建出的數據集,提取出特征x和目標值y。
- 劃分訓練集和測試集
共122條記錄,前115條為訓練集,后7條為測試集。
# 提取特征 x
X = df2[['MONTH', 'DAY', 'DAY_OF_WEEK_NUM', 'WEEKEND']] # 選擇需要作為特征的列
# 提取目標值 y
y = df2['COUNT'] # 選擇目標列
# 劃分訓練集和測試集
# 劃分訓練集和測試集
X_train = X[:115] # 前115條作為訓練集
X_test = X[115:] # 后7條作為測試集
y_train = y[:115] # 對應的目標值作為訓練集
y_test = y[115:] # 對應的目標值作為測試集2.3.2.3模型構建
模型參數:

參考代碼
#構建多層神經網絡模型
model = tf.keras.Sequential([tf.keras.layers.Dense(64,activation='relu',input_shape=[len(X_train.keys())]),tf.keras.layers.Dropout(0.3),tf.keras.layers.Dense(64,activation='relu'),tf.keras.layers.Dropout(0.3),tf.keras.layers.Dense(64,activation='relu'),tf.keras.layers.Dropout(0.3),tf.keras.layers.Dense(1)
])
# 編譯模型
model.compile(optimizer='adam', loss='mse', metrics=['mae','mse'])
model.summary()
# 訓練模型并保存歷史數據
history = model.fit(X_train, y_train, epochs=3000, validation_split=0.3)?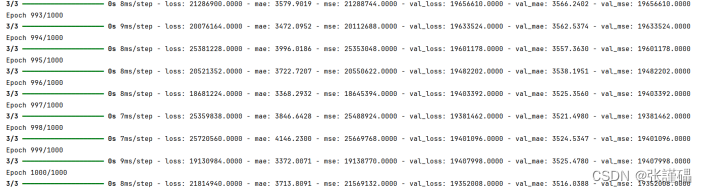
2.3.2.4模型編譯
編譯參數參考:
# 優化器optimizer='adam'# 損失函數loss='mse'# 評估指標metrics=['mae','mse']2.3.2.5模型訓練
使用fit函數對訓練集進行擬合訓練,并將訓練過程中產生的歷史數據history保存至變量中。
訓練參數參考:
# 迭代次數epochs=1000# 驗證集比例validation_split=0.22.3.2.6訓練過程可視化
對history中保存下來的訓練過程中的mae和mse的變化情況進行繪圖。
參考代碼:
# 獲取訓練過程中的指標數值
mae = history.history['mae']
mse = history.history['loss']
val_mae = history.history['val_mae']
val_mse = history.history['val_mse']
#可視化mae、mse
plt.plot(mae, label='MAE')
plt.plot(val_mae, label='Validation MAE')
plt.title('MAE vs')
plt.legend()
plt.show()
plt.plot(mse, label='MSE')
plt.plot(val_mse, label='Validation MSE')
plt.title('MSE')
plt.legend()
plt.show()
print('MAE:', mae)
print('MSE:', mse)?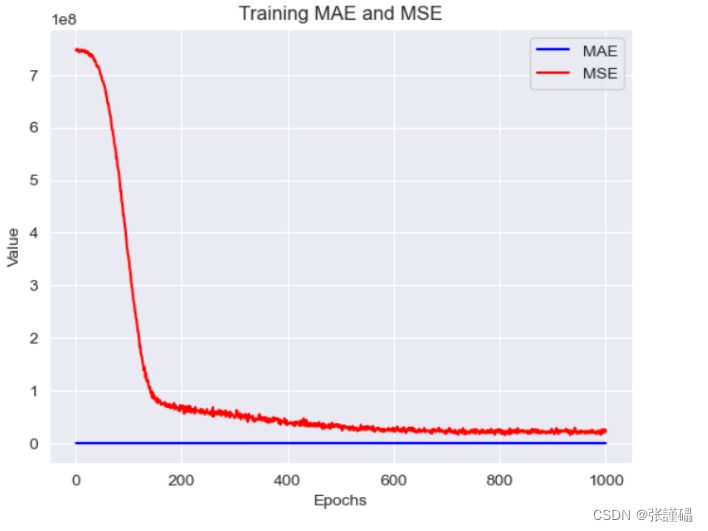
2.4模型評估
2.4.1 ARIMA模型評估
2.4.1.1測試
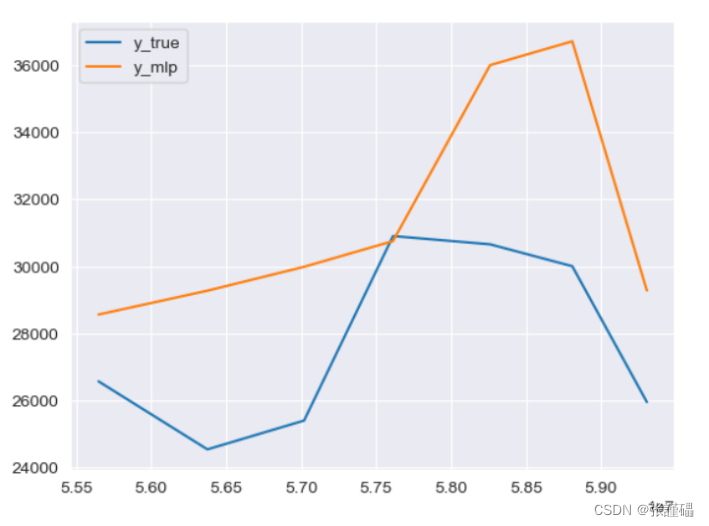
- 繪制測試集真實值和預測值對比圖
- 計算模型在測試集上的MAE,MSE,RMSE,MAPE
# 獲取訓練過程中的指標數值
mae = history.history['mae']
mse = history.history['loss']
val_mae = history.history['val_mae']
val_mse = history.history['val_mse']plt.plot(mae, label='MAE')
plt.plot(val_mae, label='Validation MAE')
plt.title('MAE vs')
plt.legend()
plt.show()
plt.plot(mse, label='MSE')
plt.plot(val_mse, label='Validation MSE')
plt.title('MSE')
plt.legend()
plt.show()# history.plot()
# plt.plot(history)
# plt.show()
print('MAE:', mae)
print('MSE:', mse)y_arima = model_fit.forecast(7)
print('預測未來'+str(len(y_arima))+'天的客流量:\n',y_arima)
y_arima.index = test_set.index
# # # 創建一個新的DataFrame來保存預測值,索引與測試集相同
# test_set = pd.read_csv(r'test.csv')
# print(test_set)
# test_set.to_csv('test_set.xlsx', index=False)
# y_arima = pd.Series(y_arima, index=test_set.index)
test_set['p'] = y_arima
plt.figure()
plt.plot(test_set, label='Actual')
# plt.plot(y_arima, label='Predicted', color='red') plt.legend(['y_true','y_arima'])
plt.show()
?
 ?
?
2.4.2多層神經網絡模型評估
2.4.2.1測試
- 根據測試集的預測結果和真實值、ARIMA模型預測結果進行對比并繪圖
參考代碼:
y_test = pd.DataFrame(y_test)
y_mlp = pd.DataFrame(y_mlp)
y_mlp.index = y_arima.index
y_test['P1']=y_arima
y_test['P2']=y_mlp
print(y_test)
plt.figure()
plt.plot(y_test, label='Actual')
plt.legend(['y_true','y_arima','y_mlp'])
plt.show()?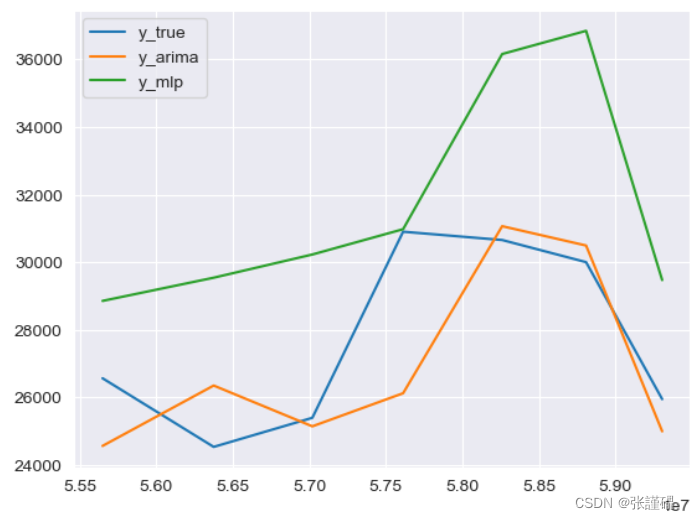
?
完整代碼:
import pandas as pd
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller
from statsmodels.stats.diagnostic import acorr_ljungbox
from statsmodels.tsa.vector_ar.var_model import VAR
from sklearn import metrics
import numpy as np
import tensorflow as tf
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
import seaborn as sns
#%%
import pandas as pd
# 創建一個空的DataFrame列表來存儲所有讀取的DataFrame
df_list = [] # 循環讀取所有CSV文件
for year in range(8, 12): # 從2008年到2011年 filename = fr'C:\Users\zjl15\PycharmProjects\pythonProject1\shixundata\2\acc_{year:02d}_final_mini.csv' # 注意fr的使用 df = pd.read_csv(filename) # 讀取CSV文件 df_list.append(df) # 將讀取的DataFrame添加到列表中 # 使用concat函數進行縱向合并(堆疊)
combined_df = pd.concat(df_list, ignore_index=True) # 顯示合并后的DataFrame
print(combined_df) #%%
# #如果你需要將合并后的DataFrame保存到新的CSV文件
# combined_df.to_csv('combined_final_mini.csv')
#%%
# 將 TRADE_DATE 列轉換為 datetime 類型
combined_df['TRADE_DATE'] = pd.to_datetime(combined_df['TRADE_DATE'], format='%Y-%m-%d-%H.%M.%S.%f')# 使用 apply 函數提取日期部分并創建新的列
combined_df['DATE_ONLY'] = combined_df['TRADE_DATE'].apply(lambda x: x.date())# 打印結果
print(combined_df)#%%
df=combined_df.drop(columns=['TRADE_DATE'])
print(df)
#%%
# 使用 groupby 和 transform 計算每個站點每天的交易數量并將結果作為新列加入原數據
df['COUNT'] = df.groupby(['DATE_ONLY', 'TRADE_ADDRESS'])['TRADE_TYPE'].transform('count')# 打印結果
print(df)
#%%
df=df.drop(columns=['TRADE_TYPE'])
print(df)
#%% md#%%
# 按照 TRADE_ADDRESS 和 DATE_ONLY 進行排序
df_sorted = df.sort_values(by=['TRADE_ADDRESS', 'DATE_ONLY'])# 去重處理
df_unique = df_sorted.drop_duplicates(subset=['TRADE_ADDRESS', 'DATE_ONLY'])# 打印結果
print(df_unique)#%%
# 根據日期和站點對數據進行分組,并計算客流量總和
grouped_data = df_unique.groupby(['DATE_ONLY', 'TRADE_ADDRESS'])['COUNT'].sum().unstack()# 繪制折線圖
grouped_data.plot(figsize=(12, 8))
plt.title('Daily Traffic for Each Station')
plt.xlabel('Date')
plt.ylabel('Traffic Count')
plt.legend(title='Station', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()#%%
# 從原始數據中篩選出TRADE_ADDRESS=121的行
data_121 = df_unique[df_unique['TRADE_ADDRESS'] == 121]
data = data_121
print(data_121)
data_121 = data_121.drop(columns=['TRADE_ADDRESS','DATE_ONLY'])
print(data_121)
#%%
# 劃分訓練集和測試集
train_set = data_121.iloc[:115]
test_set = data_121.iloc[115:]print("訓練集:")
print(train_set)
print("\n測試集:")
print(test_set)#%%
# 繪制時序圖
plt.figure(figsize=(12, 6))
plt.plot(train_set['COUNT'])
plt.title('Traffic Count at Station 121 (Training Set)')
plt.xlabel('Date')
plt.ylabel('Traffic Count')
plt.show()# 繪制自相關圖
fig, ax = plt.subplots(2, 1, figsize=(12, 8))
sm.graphics.tsa.plot_acf(train_set['COUNT'], lags=30, ax=ax[0])
sm.graphics.tsa.plot_pacf(train_set['COUNT'], lags=30, ax=ax[1])
plt.show()# ADF單位根檢測
result = adfuller(train_set['COUNT'])
print('ADF Statistic:', result[0])
print('p-value:', result[1])
print('Critical Values:', result[4])#%%
# 對訓練集進行2階差分處理
train_set_diff = train_set['COUNT'].diff().diff().dropna()# 繪制2階差分后的時序圖
plt.figure(figsize=(12, 6))
plt.plot(train_set_diff)
plt.title('Differenced Traffic Count at Station 121 (Training Set)')
plt.xlabel('Date')
plt.ylabel('Differenced Traffic Count')
plt.show()# 繪制2階差分后的自相關圖
fig, ax = plt.subplots(2, 1, figsize=(12, 8))
sm.graphics.tsa.plot_acf(train_set_diff, lags=30, ax=ax[0])
sm.graphics.tsa.plot_pacf(train_set_diff, lags=30, ax=ax[1])
plt.show()# ADF單位根檢測(2階差分后)
result_diff = adfuller(train_set_diff)
print('ADF Statistic (after differencing):', result_diff[0])
print('p-value (after differencing):', result_diff[1])
print('Critical Values (after differencing):', result_diff[4])#%%
# 計算殘差序列
residuals = train_set_diff # 這里填入差分處理后的訓練集數據的殘差序列
# 進行Ljung-Box檢驗
lb_test_stat, lb_p_value = acorr_ljungbox(residuals, lags=1)
# 輸出檢驗結果
print("Ljung-Box test statistic:", lb_test_stat)
print("P-values:", lb_p_value)
#%%
# 定義 ARIMA 模型的參數 (p, d, q)
p = 6 # 自回歸階數
d = 2 # 差分階數
q = 6 # 移動平均階數# 訓練 ARIMA 模型
model = ARIMA(train_set, order=(p, d, q))
model_fit = model.fit()print(model_fit.summary())# 使用訓練好的模型進行預測
forecast = model_fit.predict(typ='levels')
print(forecast)
# 繪制訓練集真實值和預測值對比圖
plt.figure(figsize=(12, 6))
plt.plot(train_set, label='Actual')
plt.plot(forecast, label='Predicted', color='red')
plt.title('Comparison of Actual and Predicted Values')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()#%% md#%%
y_arima = model_fit.forecast(7)
print('預測未來'+str(len(y_arima))+'天的客流量:\n',y_arima)
y_arima.index = test_set.index
# # # 創建一個新的DataFrame來保存預測值,索引與測試集相同
# test_set = pd.read_csv(r'test.csv')
# print(test_set)
# test_set.to_csv('test_set.xlsx', index=False)
# y_arima = pd.Series(y_arima, index=test_set.index)
test_set['p'] = y_arima
plt.figure()
plt.plot(test_set, label='Actual')
# plt.plot(y_arima, label='Predicted', color='red') plt.legend(['y_true','y_arima'])
plt.show()#%%
# (2)刪掉TRADE_ADDRESS列
df = data.drop(columns=['TRADE_ADDRESS'])
print(df)
#%%
# 將 DATE_ONLY 列轉換為日期時間類型
df['DATE_ONLY'] = pd.to_datetime(df['DATE_ONLY'])# 使用 apply 函數計算星期幾,并賦值給新列 DAY_OF_WEEK
df['DAY_OF_WEEK'] = df['DATE_ONLY'].dt.day_name()# 使用 dt.dayofweek + 1 將星期幾轉換為數字表示,并賦值給新列 DAY_OF_WEEK_NUM
df['DAY_OF_WEEK_NUM'] = df['DATE_ONLY'].dt.dayofweek + 1# 顯示結果
print(df)
#%%
df2 = df.drop(columns=['DAY_OF_WEEK'])print(df2)
#%%
# 將 TRADE_DATE 列轉換為日期時間類型
df2['DATE_ONLY'] = pd.to_datetime(df2['DATE_ONLY'])# 使用 apply 函數結合 dt.month 提取出月份信息,并賦值給新列 MONTH
df2['MONTH'] = df2['DATE_ONLY'].apply(lambda x: x.month)
# 使用 apply 函數結合 dt.day 提取出日信息,并賦值給新列 DAY
df2['DAY'] = df2['DATE_ONLY'].apply(lambda x: x.day)
# 顯示結果
print(df2)
#%%
df2 = df2.drop(columns=['DATE_ONLY'])
print(df2)
#%%
# 自定義函數來判斷是否為周末
def is_weekend(day_of_week):return 1 if day_of_week >= 6 else 0# 使用 apply 函數調用自定義函數對 DAY_OF_WEEK_NUM 列進行計算,生成 WEEKEND 列
df2['WEEKEND'] = df2['DAY_OF_WEEK_NUM'].apply(is_weekend)print(df2)
#%%
df2 = df2[['MONTH', 'DAY', 'DAY_OF_WEEK_NUM', 'WEEKEND', 'COUNT']]
print(df2)
#%%
# 繪制多變量聯合分布圖
sns.pairplot(df2)
plt.show()
#%%
from sklearn.model_selection import train_test_split
# 提取特征 x
X = df2[['MONTH', 'DAY', 'DAY_OF_WEEK_NUM', 'WEEKEND']] # 選擇需要作為特征的列# 提取目標值 y
y = df2['COUNT'] # 選擇目標列# 劃分訓練集和測試集
# 劃分訓練集和測試集
X_train = X[:115] # 前115條作為訓練集
X_test = X[115:] # 后7條作為測試集
y_train = y[:115] # 對應的目標值作為訓練集
y_test = y[115:] # 對應的目標值作為測試集
print(X_train)
print(y_train)
print(X_test)
print(y_test)
#%%
#構建模型
model = tf.keras.Sequential([tf.keras.layers.Dense(64,activation='relu',input_shape=[len(X_train.keys())]),tf.keras.layers.Dropout(0.3),tf.keras.layers.Dense(64,activation='relu'),tf.keras.layers.Dropout(0.3),tf.keras.layers.Dense(64,activation='relu'),tf.keras.layers.Dropout(0.3),tf.keras.layers.Dense(1)
])# 編譯模型
model.compile(optimizer='adam', loss='mse', metrics=['mae','mse'])model.summary() # 訓練模型并保存歷史數據
history = model.fit(X_train, y_train, epochs=3000, validation_split=0.3)#%%
#model.save('roch_classification2_cnn.keras')
#%%
# 獲取訓練過程中的指標數值
mae = history.history['mae']
mse = history.history['loss']
val_mae = history.history['val_mae']
val_mse = history.history['val_mse']plt.plot(mae, label='MAE')
plt.plot(val_mae, label='Validation MAE')
plt.title('MAE vs')
plt.legend()
plt.show()
plt.plot(mse, label='MSE')
plt.plot(val_mse, label='Validation MSE')
plt.title('MSE')
plt.legend()
plt.show()# history.plot()
# plt.plot(history)
# plt.show()
print('MAE:', mae)
print('MSE:', mse)
#%%
y_mlp = model.predict(X_test)
#%%
y_test = pd.DataFrame(y_test)
y_mlp = pd.DataFrame(y_mlp)
y_mlp.index = y_arima.index
y_test['P1']=y_arima
y_test['P2']=y_mlp
print(y_test)
plt.figure()
plt.plot(y_test, label='Actual')
plt.legend(['y_true','y_arima','y_mlp'])
plt.show()
#%%
# 計算MAE,MSE,RMSE,MAPE
from sklearn import metrics
import math
MAE = metrics.mean_absolute_error(X_test.iloc[:,0],X_test.iloc[:,1])
MSE = metrics.mean_squared_error(X_test.iloc[:,0],X_test.iloc[:,1])
RMSE = math.sqrt(MSE)
MAPE = metrics.mean_absolute_percentage_error(X_test.iloc[:,0],X_test.iloc[:,1])
print('MAE:',MAE)
print('MSE:',MSE)
print('RMSE:',RMSE)
print('MAPE:',MAPE)
#%%
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.metrics import mean_squared_error
# 初始化隨機森林回歸器
rf_regressor = RandomForestRegressor(n_estimators=2500,max_depth=100,random_state=42)
# 訓練隨機森林模型
rf_regressor.fit(X_train, y_train)
# 使用訓練好的模型進行預測
y_regressor_pred = rf_regressor.predict(X_test)
print(y_regressor_pred)
y_regressor_pred = pd.DataFrame(y_regressor_pred)
print(y_regressor_pred)
y_regressor_pred.index = y_mlp.index
y_test['P3'] = y_regressor_pred
print(y_test)
plt.figure()
plt.plot(y_test, label='Actual')
plt.legend(['y_true','y_arima','y_mlp','y_regressor_pred'])
plt.show()
# 計算均方誤差
mse = mean_squared_error(y_test['COUNT'], y_test['P3'])
print("Mean Squared Error:", mse)
#%%
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error
# 1. 準備數據集
# 假設數據集已準備好,包含特征和目標變量
# 4. 定義模型
model = XGBRegressor(n_estimators=3000, # 樹的數量max_depth=5, # 樹的最大深度learning_rate=0.3, # 學習率random_state=42
)
# 5. 訓練模型
model.fit(X_train, y_train)
# 6. 模型評估
y_XGBRegressor_pred = model.predict(X_test)
y_XGBRegressor_pred = pd.DataFrame(y_XGBRegressor_pred)
y_XGBRegressor_pred.index = y_mlp.index
y_test['P4'] = y_XGBRegressor_pred
print(y_test)
plt.figure()
plt.plot(y_test, label='Actual')
plt.legend(['y_true','y_arima','y_mlp','y_regressor_pred','y_XGBRegressor_pred'])
plt.show()
# 計算均方誤差
mse = mean_squared_error(y_test['COUNT'], y_test['P3'])
print("Mean Squared Error:", mse)
mse = mean_squared_error(y_test['COUNT'], y_XGBRegressor_pred)
print("Mean Squared Error:", mse)
#%%
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error# 4. 定義模型
model = SVR(kernel='rbf', C=1.0, epsilon=0.1)# 5. 訓練模型
model.fit(X_train, y_train)# 6. 模型評估
y_SVR_pred = model.predict(X_test)
y_SVR_pred = pd.DataFrame(y_SVR_pred)
y_SVR_pred.index = y_mlp.index
y_test['P5'] = y_SVR_pred
print(y_test)
plt.figure()
plt.plot(y_test, label='Actual')
plt.legend(['y_true','y_arima','y_mlp','y_regressor_pred','y_XGBRegressor_pred','y_SVR_pred'])
plt.show()
# 計算均方誤差
mse = mean_squared_error(y_test['COUNT'], y_test['P5'])
print("Mean Squared Error:", mse)
mse = mean_squared_error(y_test['COUNT'], y_SVR_pred)
print("Mean Squared Error:", mse)
#%%

)


【類的6個默認成員函數】 【零散知識點】 (萬字))



,免費參會)









:電容觸摸按鍵實驗)
