目錄
一、關鍵字
二、命名空間
問題引入(問題代碼):
域的問題
1.::域作用限定符 的 用法:
2.域的分類
3.編譯器的搜索原則
命名空間的定義
命名空間的使用
舉個🌰栗子:
1.作用域限定符指定命名空間名稱
2. using 引入命名空間中的成員 即 展開命名空間中某一個
3. usinng namespace 命名空間名稱 展開命名空間
三、C++輸入、輸出
四、缺省參數
概念
全缺省參數
半缺省參數
實踐中的應用場景🌰舉個例子:
聲明和定義分離
回顧 聲明 和定義的概念
再來分析上述程序
理解編譯與鏈接的過程
理解函數與文件的關系
五、函數重載
代碼示例:
C++是如何支持函數重載的?
函數名修飾
一、關鍵字
| asm | do | if | return | try | continue |
|---|---|---|---|---|---|
| auto | double | inline | short | typedef | for |
| bool | dynamic_cast | int | signed | typeid | public |
| break | else | long | sizeof | typename | throw |
| case | enum | mutable | static | union | wchar_t |
| catch | explicit | namespace | static_cast | unsigned | default |
| char | extern | operator | switch | virtual | register |
| const | false | private | template | void | true |
| const_cast | float | protected | this | volatile | while |
| delete | goto | reinterpret_cast |
增加的關鍵字: C++增加了一些關鍵字來支持面向對象編程(如類、繼承、多態等)和模板編程。例如,class,public,protected,private,virtual,friend,template,typename等。這些關鍵字沒有在C語言中。
類型增強:C++增加了一些用于類型安全和方便的關鍵字,如bool,true,false,using,namespace等。
異常處理:為了支持異常處理,C++引入了try,catch,throw等關鍵字。
新的轉換操作符:C++提供了static_cast,dynamic_cast,const_cast和reinterpret_cast等關鍵字進行類型轉換,這是C語言中所沒有的。
增強的存儲類說明符:C++引入了mutable和thread_local等存儲類說明符。
模板編程:為了支持泛型編程,C++增加了template和typename關鍵字。
新增運算符:C++還定義了如new,delete等用于動態內存管理的關鍵字,這些在C中通常通過庫函數如malloc和free來實現。
特殊成員函數關鍵字:C++還有如default和delete等關鍵字,用于特殊成員函數的聲明,這樣設計是為了提供更好的控制。
二、命名空間
問題引入(問題代碼):
下面代碼存在命名沖突 : rand變量 和頭文件<stdlib.h>中聲明的函數 rand() 名字相同 導致沖突。
#include<stdio.h>
#include<stdlib.h> /*rand*/
int rand = 0;
// C語言沒辦法解決類似這樣的命名沖突問題,所以C++提出了namespaceguan來解決
int main()
{printf("%d\n",rand);return 0;
}域的問題
1.::域作用限定符 的 用法:
限定符左邊是哪一個域名 就限定了訪問該變量的范圍
左邊是空 默認是全局域
2.域的分類
-
全局域
-
局部域:如果不用限定符,默認訪問局部域 局部優先
-
命名空間域:為了防止命名沖突 eg.全局定義兩個同名變量 ,防止重定義,C++提出就用關鍵字namespace把他們定義在不同命名空間域中。
-
類域
注意:
全局域、局部域既會影響生命周期,也會影響訪問。命名空間只影響訪問
3.編譯器的搜索原則?
?1??當前局部域 2??全局域 3??如果指定了,直接去指定域搜索
命名空間的定義
正常定義
// 正常的命名空間定義
namespace hhh
{// 命名空間中可以定義變量/函數/類型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};}嵌套定義
舉個栗子🌰:
namespace aaa
{namespace bbb{void Push(){cout<<"zs"<<endl;}}namespace ccc{void Push(){cout<<"yyy"<<endl;}}
}
int main()
{//嵌套定義在命名空間的同名函數 各自調用bit::bbb::Push();bit::ccc::Push();return 0;
}ps:命名空間可以重名,編譯器會把他們合并,只要命名空間內部不沖突就可以
命名空間的使用
命名空間到底該如何使用?
舉個🌰栗子:
namespace yyy
{//命名空間中定義 變量 / 函數 /類型int a = 0;int b= 1;int Add(int left,int right){return left+right;}struct Node{struct Node* next;int val;};
}1.作用域限定符指定命名空間名稱
//指定訪問
int main()
{//::作用域限定符printf("%d\n",yyy::a);return 0;
}2. using 引入命名空間中的成員 即 展開命名空間中某一個
//展開一個
using yyy::b;
int main()
{printf("%d\n",yyy::a);//不可以 因為此時只展開了一個成員變量printf("%d\n",b);
}3. usinng namespace 命名空間名稱 展開命名空間
展開命名空間 影響的是 域的搜索規則。不展開命名空間,默認情況編譯器只會在局部域、全局域搜索。展開命名空間就可以在命名空間里搜索。
//展開全部
using namespace yyy;
int main()
{printf("%d\n",yyy::a);//指定去該命名空間找變量aprintf("%d\n",b)
}注意:
1. 日常練習展開為了方便使用可以展開std,實際工程實踐中慎重使用!
2.展開命名空間 不是 等同于引入全局變量!
3.展開命名空間 跟 包含頭文件 也有本質區別,包含頭文件 在預處理過程中本質是拷貝頭文件的內容
三、C++輸入、輸出
解釋Hello world代碼
//包含標準輸入輸出流庫
#include<iostream>
// std是C++標準庫的命名空間名,C++將標準庫的定義實現都放到這個命名空間中
using namespace std;int main(){//cout和cin是全局的流對象,細說分別是ostream和istream類型的對象// <<是流插入運算符,>>是流提取運算符//endl是C++符號,表示endline換行//他們都包含在包含<iostream>頭文件中cout<<"Hello world!!!"<<endl;return 0;}說明:使用cout標準輸出對象(控制臺)和cin標準輸入對象(鍵盤)時,必須包含< iostream >頭文件 以及按命名空間使用方法使用std。
補充:std命名空間的使用習慣
1.日常練習:直接展開 using namespace std
2.項目開發:std::cout 使用時指定命名空間 + using std::cout 展開常用庫對象
C++ 輸入輸出 自動識別變量類型?
-
示例代碼:
#include <iostream> using namespace std; int main() {int a;double b;char c;// 可以自動識別變量的類型cin>>a;cin>>b>>c;cout<<a<<endl;cout<<b<<" "<<c<<endl;return 0; }-
說明
-
cin>>a;這行代碼從標準輸入流(鍵盤)中接受一個整數,并將其存儲在變量a中。cin會根據提供的變量類型自動解釋輸入數據。cin>>b>>c;這行代碼首先從標準輸入流中接收一個雙精度浮點數,并將其存儲在變量b中,然后接收一個字符并存儲在c中。?
四、缺省參數
-
概念
聲明或定義函數時為函數的參數指定缺省值。缺省值就是給形參設置一個默認值。調用函數時,如果沒有指定實參,則使用參數的默認值。
缺省值必須是 常量或者全局變量。一般使用常量。
void Func(int a = 0) {cout<<a<<endl; } int main() {Func(); ? ?//沒有傳參 使用參數默認值 Func(10); ?//傳參時 使用指定的實參return 0; } -
全缺省參數
void Func(int a = 10, int b = 20, int c = 30) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; } 調用Func()時,可以這樣給參數int main() {Func(1,2,3);Func(1,2);Func(1);Func();//注意:不可以跳越傳值//Func(,1,2);return 0; } -
半缺省參數
注意:只能從右往左連續給缺省值,這樣調用保證傳的實參順序不存在歧義
void Func(int a, int b = 20, int c = 30) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; } //調用 同樣不能跳越給 int main() {Func(1,2,3);Func(1,2);Func(1); }
實踐中的應用場景🌰舉個例子:
struct Stack
{int* a;int size;int capacity;//...
};
//StackInit()改造為半缺省函數 使得可以適用更多的需要開辟空間的場景
void StackInit(struct Stack* ps,int n=4)
{ps->a=(int*)malloc(sizeof(int)*n);
}
int main()
{struct Stack st1;//缺省參數 使得函數可以適應不同場景 // 1、確定要插入100個數據StackInit(&st1, 100); ?// call StackInit(?)
?// 2、只插入10個數據struct Stack st2;StackInit(&st2, 10); ? // call StackInit(?)
?// 3、不知道要插入多少個 //這時就可以使用函數定義里提供的 參數缺省值 //不知道插入多少個 可以先初始化四個空間struct Stack st3;StackInit(&st3);
?return 0;
}-
聲明和定義分離
回顧 聲明 和定義的概念
-
函數聲明:告訴編譯器函數的名稱、返回類型以及參數列表(類型、順序和數量),但不涉及函數的具體實現。函數聲明經常出現在頭文件(
.h)中 -
函數定義:提供了函數的實際實現,它包括函數的主體,即函數被調用時將執行的具體代碼。函數定義包含了函數聲明的所有信息,并加上了函數體
//Stack.h 聲明 struct Stack {int* a;int size;int capacity;//... }; void StackInit(struct Stack* ps,int n=4);//*注意 必須在聲明中給出缺省值 void StackPush(struct Stack* ps,int x); //Stack.cpp 定義 void StackInit(struct Stack* ps,int n)//*注意聲明和定義中缺省值不能同時給 {ps->a=(int*)malloc(sizeof(int)*n); } void StackPush(struct Stack* ps , int x) {} //Test.cpp #include"Stack.h" int main() {struct Stack st1;// 1、確定要插入100個數據StackInit(&st1, 100); ?// call StackInit(?)//此時包含了頭文件,Test.cpp只有函數聲明 用這個函數的名字找到該函數的地址 編譯階段會檢查調用該函數是否存在匹配的函數,經過檢查 匹配// 2、只插入10個數據struct Stack st2;StackInit(&st2, 10); ? // call StackInit(?)// 3、不知道要插入多少個 struct Stack st3;StackInit(&st3);return 0; }但是試想一下,1??如果缺省值只在函數定義中給出,編譯階段 無法用這個函數的名字找到該函數的匹配 ,因為調用傳參跟函數聲明并不匹配。另一種情況,2??如果在函數的聲明和定義中都指定了缺省參數編譯器也可能不確定應該使用哪個版本的默認值為了避免這種情況,C++標準規定了缺省參數應當只在一個地方指定:
-
如果函數聲明在頭文件中進行,那么就在頭文件中的聲明處指定缺省參數;
-
如果函數沒有在頭文件中聲明(例如,完全在一個
.cpp文件內定義),那么就在函數定義處指定缺省參數
綜上,
1??在項目中,聲明和定義應當分離,缺省值一定要在函數聲明中給出!因為,編譯階段只有函數聲明,從而保證編譯階段是沒有問題的。
2??聲明和定義分離,導致編譯階段無法找到函數的定義,沒有函數的地址。
-
-
再來分析上述程序
-
理解編譯與鏈接的過程
1??預處理階段 :展開頭文件、宏替換、條件編譯、刪除注釋
對于每個
.c文件,編譯過程從預處理開始。預處理器會處理以#開頭的指令,例如#include "stack.h"會將stack.h中的內容文本上粘貼到stack.c和test.c文件中,這樣stack.c和test.c就可以看到這些函數聲明了2??編譯:檢查語法??生成匯編代碼
編譯器接著編譯每個.c源文件,將它們轉換成目標代碼(通常是機器代碼的一種中間形態,稱為目標文件,擴展名為.o或.obj)。此時,編譯器確保源代碼符合語法規則,對每個源文件進行類型檢查,確保所有函數調用都符合其聲明,但還不解決跨文件的函數引用問題。例如,stack.c被編譯成stack.o,test.c被編譯成test.o
3??匯編:匯編代碼??二進制機器碼
4??鏈接:合并、有些地方要用函數名去其他文件找函數地址
一旦所有的源文件被編譯成目標文件,鏈接器(linker)負責將這些目標文件以及必要的庫文件鏈接成一個單一的可執行文件。在鏈接過程中,如果test.c(對應的是test.o)調用了stack.c中(對應的是stack.o)的函數,鏈接器負責“修補”這些調用,使得test.o中的調用可以正確地連接到stack.o中定義的函數上,鏈接器確保所有外部引用都能正確解析到它們所引用的實體。
-
理解函數與文件的關系
-
在stack.h中聲明的函數,讓其他源文件知道這些函數的存在、它們的參數以及返回值類型。stack.h扮演了接口的角色。
-
stack.c提供了stack.h中聲明的函數的具體實現。test.c作為使用這些函數的客戶端代碼,通過#include "stack.h"能夠調用這些函數。
-
編譯過程中,test.c和stack.c分別被編譯成中間的目標文件。這些目標文件中的函數調用尚未解析到具體的地址
-
在鏈接過程,鏈接器解析這些調用,使得從test.o中的調用可以正確地定位到stack.o中的函數定義,從而生成一個完整的可執行文件,所有的函數調用都被正確地解析和連接,這個地址修正的過程也叫做重定位
-
-

五、函數重載
C語言不允許同名函數
C++允許同名函數。要求:函數名相同,參數不同,構成 函數重載
函數重載:是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數 或 類型 或 類型順序)不同,常用來處理實現功能類似但數據類型不同的問題。
代碼示例:
#include<iostream>using namespace std;// 1、參數類型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}// 2、參數個數不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}// 3、參數類型順序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
int main()
{Add(10, 20);Add(10.1, 20.2);f();f(10);f(10, 'a');f('a', 10);return 0;
}C語言不支持重載 鏈接時,直接用函數名去找地址,有同名函數的情況則區分不開。
-
C++是如何支持函數重載的?
通過函數名修飾實現的,只要函數參數不同,函數名就會被修飾成不同。然后直接用修飾好的名字,去找該函數的地址。
-
函數名修飾
名字修飾是編譯器自動進行的一種處理過程,它將C++源代碼中的函數名和變量名轉換成包含更多信息的唯一標識符。這些信息通常包括函數的參數類型、參數數量等,甚至可能包括所屬的類名(對于類成員函數),通過這種方式,每個重載的函數都會被賦予一個獨一無二的名字,確保鏈接器在最后鏈接程序的時候能夠區分它們
-
Linux下g++的修飾規則簡單易懂,下面我們使 用了g++演示了這個修飾后的名字。 通過下面我們可以看出gcc的函數修飾后名字不變。而g++的函數修飾后變成【_Z+函數長度 +函數名+類型首字母】。
-
采用C語言編譯器編譯后結果
?
結論:在linux下,采用gcc編譯完成后,函數名字的修飾沒有發生改變。
-
采用C++編譯器編譯后結果
?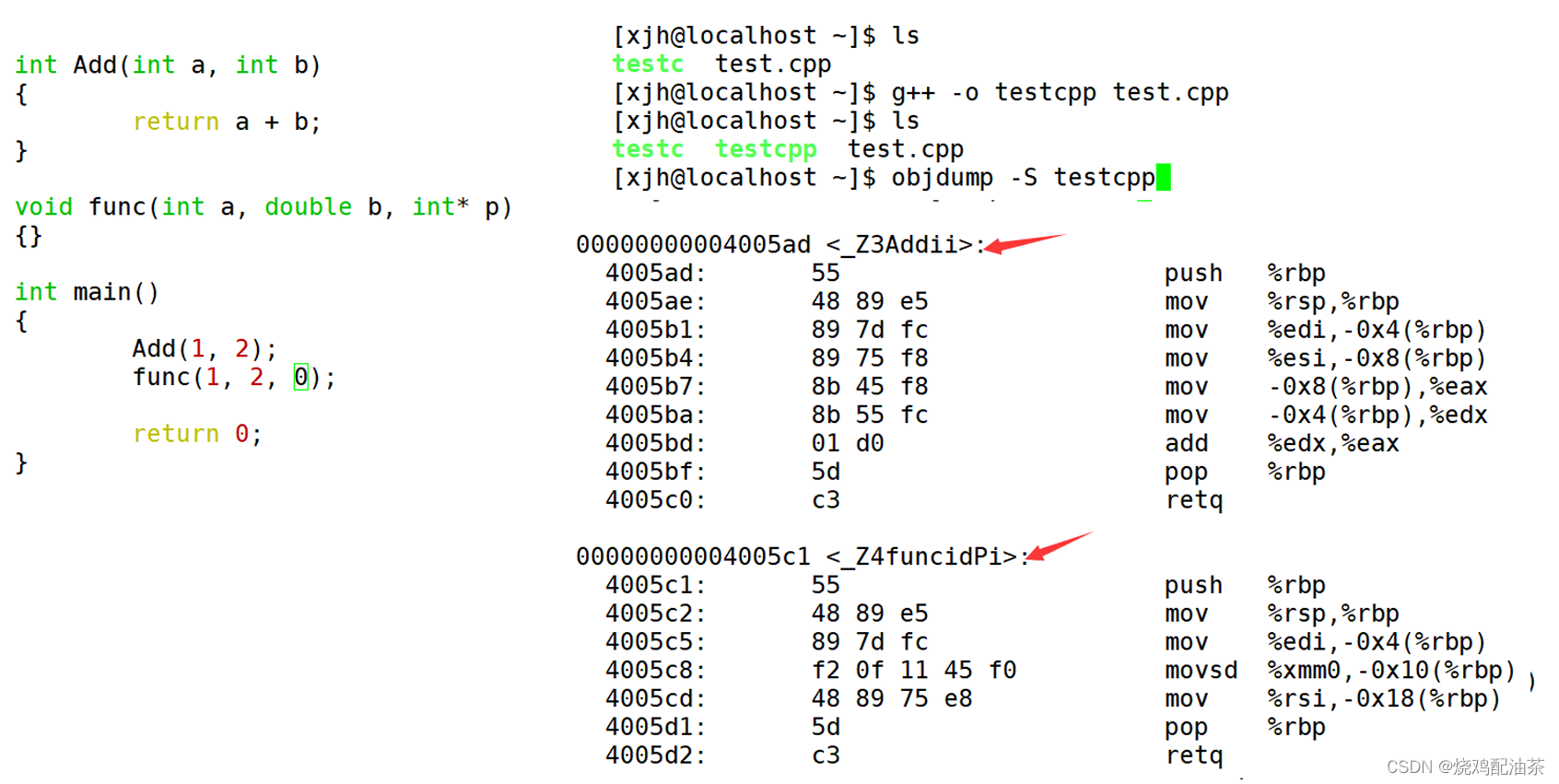
結論:在linux下,采用g++編譯完成后,函數名字的修飾發生改變,編譯器將函數參數類型信息添加到修改后的名字中。
通過以上這里就理解了C語言沒辦法支持重載,因為同名函數沒辦法區分。而C++是通過函數修 飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。



)






)

)






