?
🤵?♂? 個人主頁:@艾派森的個人主頁
?🏻作者簡介:Python學習者
🐋 希望大家多多支持,我們一起進步!😄
如果文章對你有幫助的話,
歡迎評論 💬點贊👍🏻 收藏 📂加關注+
目錄
1.項目背景
2.數據集介紹
3.技術工具
4.導入數據
5.數據可視化
6.建模分類
源代碼
1.項目背景
一、引言
????????隨著信息技術的快速發展和互聯網的普及,人們的生活方式發生了巨大的變化。特別是在餐飲行業,越來越多的消費者選擇通過在線平臺進行食品訂購,這種趨勢使得在線食品訂單數據呈現出爆炸式的增長。這些數據中蘊含著豐富的消費者行為、市場趨勢和商家運營策略等信息,對于餐飲企業和研究機構來說,具有重要的價值。因此,本研究旨在通過對在線食品訂單數據進行可視化分析和建模分類,以揭示其中的潛在規律和價值,為餐飲行業的發展提供有力支持。
二、研究背景
1.在線食品訂購市場的快速增長
????????近年來,隨著移動互聯網的普及和消費者生活節奏的加快,在線食品訂購市場呈現出迅猛的增長態勢。越來越多的消費者選擇通過手機或電腦進行食品訂購,享受便捷、快速的用餐體驗。這種趨勢使得在線食品訂單數據呈現出大規模、高頻率的特點,為數據分析和挖掘提供了豐富的素材。
2.數據驅動決策成為餐飲行業的重要趨勢
????????在數字化時代,數據已經成為企業決策的重要依據。對于餐飲企業來說,通過對在線食品訂單數據的分析,可以深入了解消費者的點餐偏好、消費習慣和市場趨勢,從而制定更加精準的營銷策略和運營策略。同時,數據分析還可以幫助餐飲企業優化菜品組合、定價策略和服務質量,提升競爭力和盈利能力。
3.數據可視化與建模分類技術的廣泛應用
????????數據可視化與建模分類技術是現代數據分析的重要工具。通過數據可視化,可以將復雜的數據以直觀、易懂的方式呈現出來,幫助用戶快速識別數據中的模式和趨勢。而建模分類技術則可以對數據進行深入挖掘和分析,發現數據之間的關聯性和規律性,為決策提供有力支持。這些技術在各個行業都得到了廣泛的應用,包括金融、醫療、零售等,但在餐飲行業的應用還處于起步階段,具有廣闊的研究空間和應用前景。
三、研究意義
????????本研究的意義在于通過在線食品訂單數據的可視化分析和建模分類,為餐飲行業的發展提供新的視角和思路。具體來說,本研究可以幫助餐飲企業更好地了解消費者需求和市場趨勢,優化菜品組合和定價策略,提升服務質量和用戶體驗。同時,本研究還可以為餐飲行業的監管和政策制定提供科學依據,促進行業的健康發展。
2.數據集介紹
本實驗數據集來源于Kaggle
在線食品訂單數據集
描述:該數據集包含一段時間內從在線訂餐平臺收集的信息。它包含與職業、家庭規模、反饋等相關的各種屬性。
屬性:
Age:顧客的年齡。
Gender:客戶的性別。
Marital Status:客戶的婚姻狀況。
Occupation:客戶的職業。
Monthly Income:客戶的月收入。
Educational Qualifications:客戶的教育資格。
Family size:客戶家庭中的人數。
latitude:客戶所在位置的緯度。
longitude:客戶所在位置的經度。
Pin code:客戶所在位置的 Pin 碼。
Output:訂單的當前狀態(例如,待處理、已確認、已交付)。
Feedback:客戶收到訂單后提供的反饋。
目的:該數據集可用于探索人口統計/位置因素與在線訂餐行為之間的關系,分析客戶反饋以提高服務質量,并可能根據人口統計和位置屬性預測客戶偏好或行為。
3.技術工具
Python版本:3.9
代碼編輯器:jupyter notebook
4.導入數據
首先導入本次實驗用到的第三方庫并加載數據集,打印前五行數據

查看數據大小

原始數據共有388行,13列
查看數據基本信息
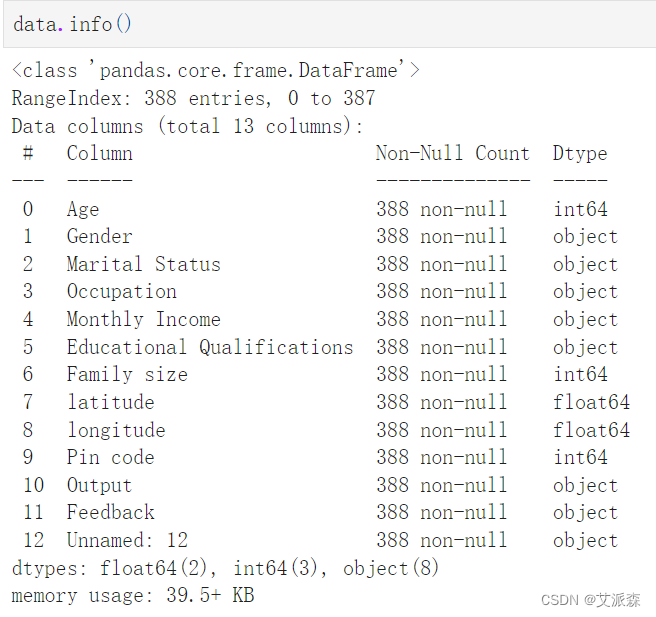
查看數值型變量的描述性統計
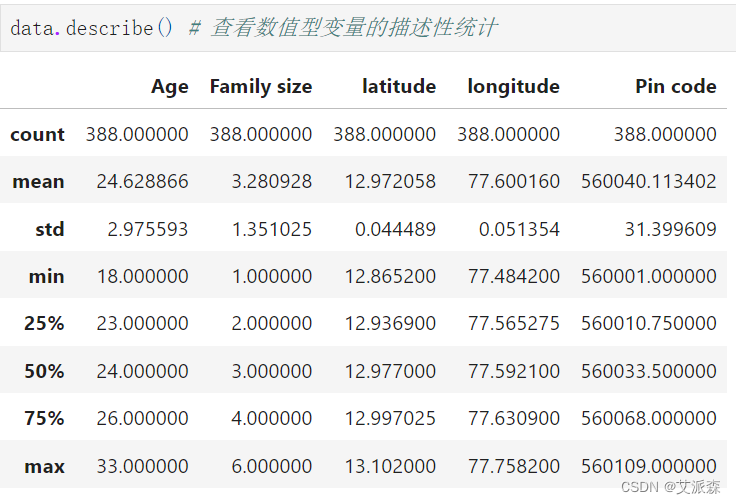
查看非數值型變量的描述性統計
查看數據缺失值情況
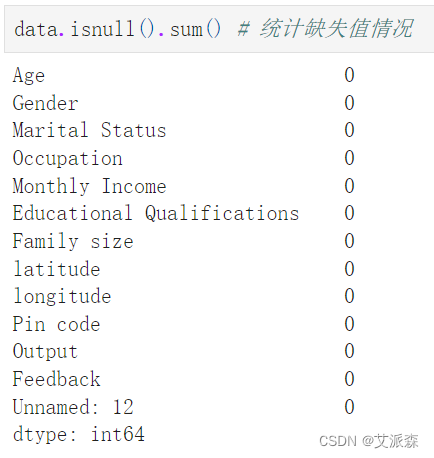
可以發沒有缺失值
查看數據重復值情況
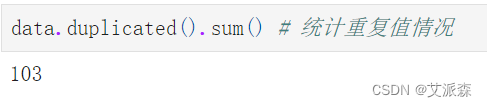
可以發現有103個重復數據,刪除處理

5.數據可視化








6.建模分類

構建隨機森林模型
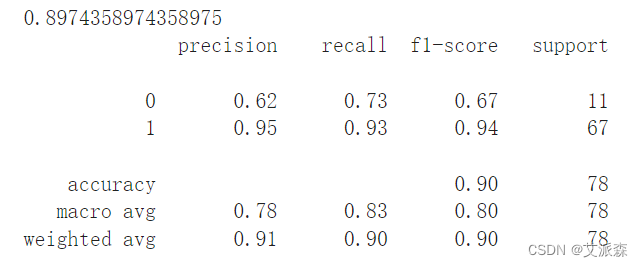
我們可以看到,我們得到了相當不錯的90%的準確率。
源代碼
在線食品訂單數據集
描述:該數據集包含一段時間內從在線訂餐平臺收集的信息。它包含與職業、家庭規模、反饋等相關的各種屬性。屬性:
Age:顧客的年齡。
Gender:客戶的性別。
Marital Status:客戶的婚姻狀況。
Occupation:客戶的職業。
Monthly Income:客戶的月收入。
Educational Qualifications:客戶的教育資格。
Family size:客戶家庭中的人數。
latitude:客戶所在位置的緯度。
longitude:客戶所在位置的經度。
Pin code:客戶所在位置的 Pin 碼。
Output:訂單的當前狀態(例如,待處理、已確認、已交付)。
Feedback:客戶收到訂單后提供的反饋。目的:該數據集可用于探索人口統計/位置因素與在線訂餐行為之間的關系,分析客戶反饋以提高服務質量,并可能根據人口統計和位置屬性預測客戶偏好或行為。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
import warnings
warnings.filterwarnings("ignore", "is_categorical_dtype")
warnings.filterwarnings("ignore", "use_inf_as_na")data = pd.read_csv('onlinefoods.csv')
data.head()
data.shape
data.info()
data.describe() # 查看數值型變量的描述性統計
data.describe(include='O') # 查看非數值型變量的描述性統計
data.isnull().sum() # 統計缺失值情況
data.duplicated().sum() # 統計重復值情況
data.drop_duplicates(inplace=True)
data.duplicated().sum()
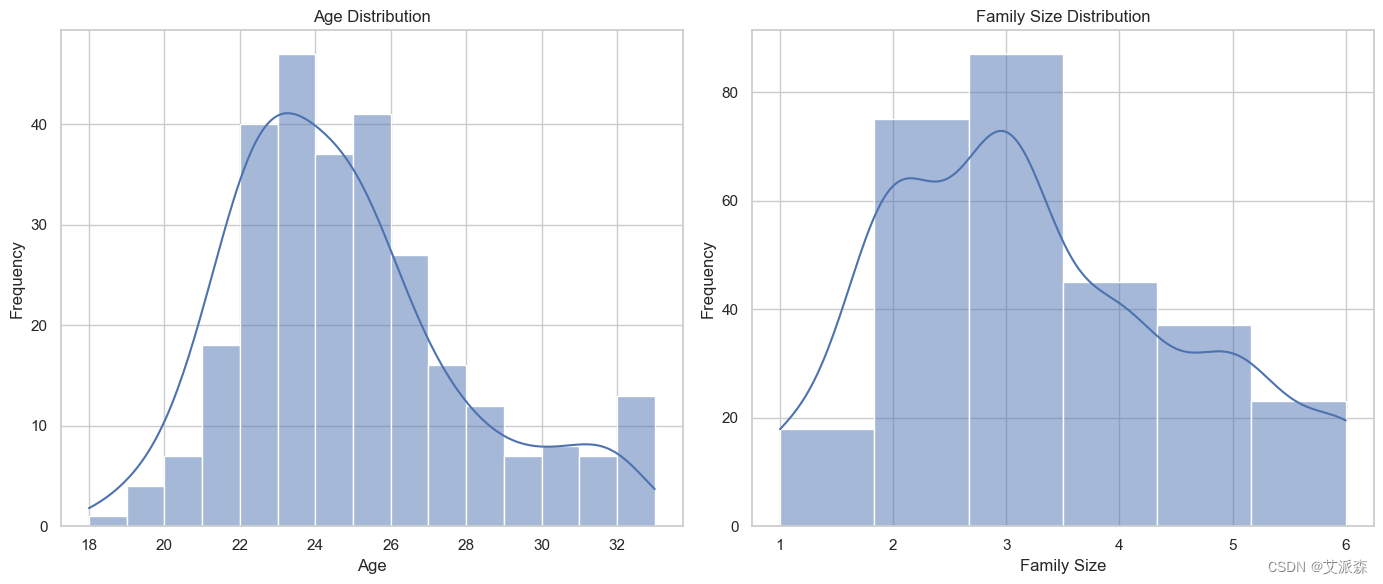
# 年齡和家庭規模的分布
sns.set(style="whitegrid")
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
sns.histplot(data['Age'], bins=15, kde=True, ax=ax[0])
ax[0].set_title('Age Distribution')
ax[0].set_xlabel('Age')
ax[0].set_ylabel('Frequency')
sns.histplot(data['Family size'], bins=6, kde=True, ax=ax[1])
ax[1].set_title('Family Size Distribution')
ax[1].set_xlabel('Family Size')
ax[1].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
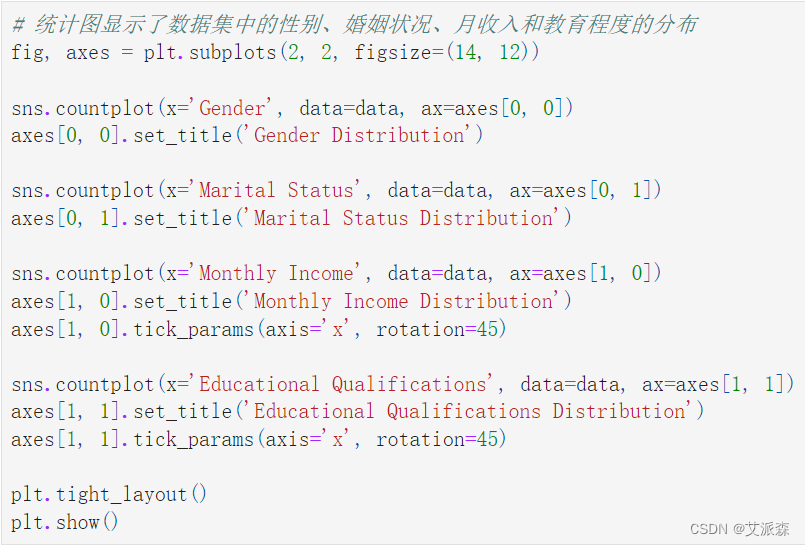
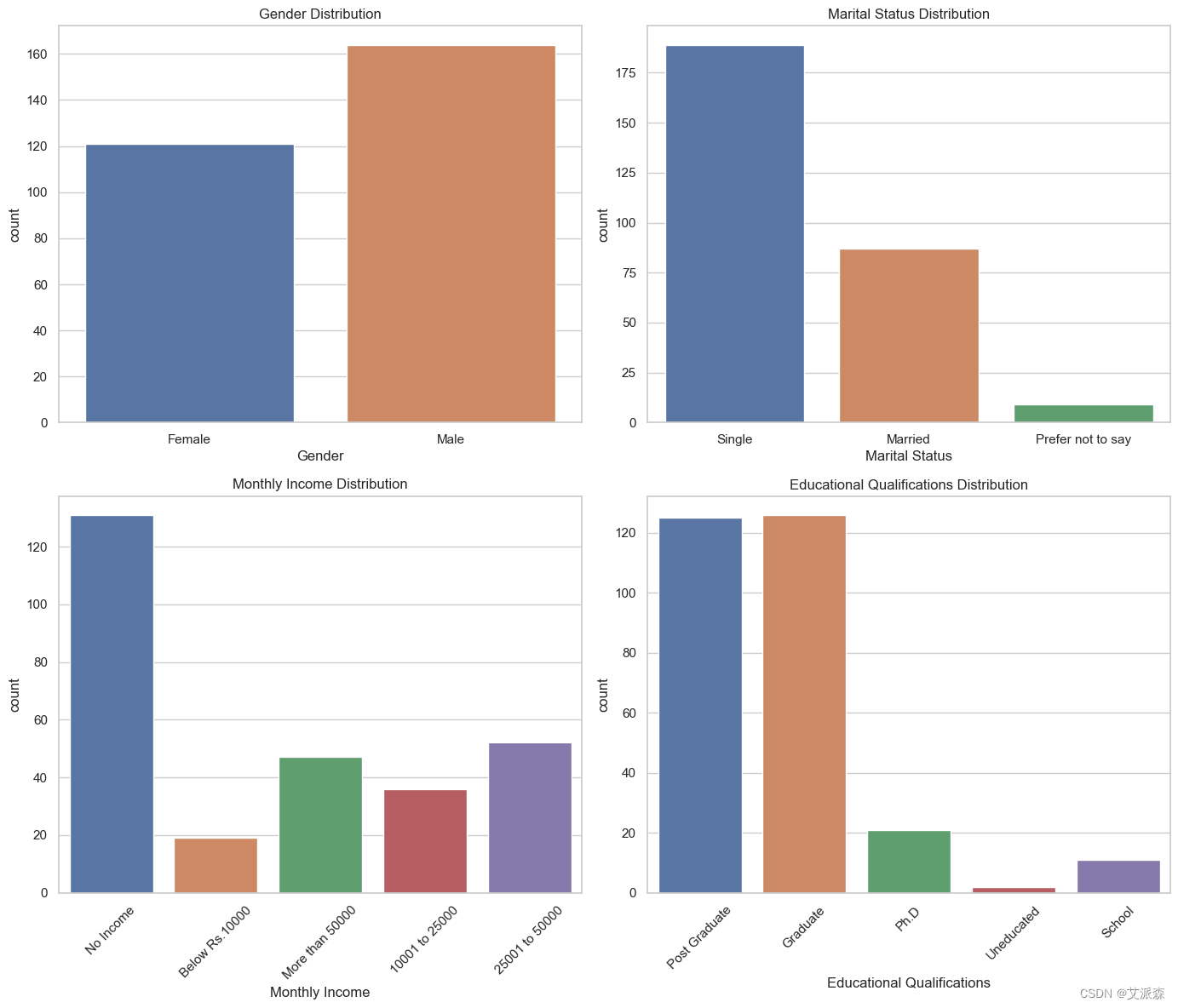
# 統計圖顯示了數據集中的性別、婚姻狀況、月收入和教育程度的分布
fig, axes = plt.subplots(2, 2, figsize=(14, 12))sns.countplot(x='Gender', data=data, ax=axes[0, 0])
axes[0, 0].set_title('Gender Distribution')sns.countplot(x='Marital Status', data=data, ax=axes[0, 1])
axes[0, 1].set_title('Marital Status Distribution')sns.countplot(x='Monthly Income', data=data, ax=axes[1, 0])
axes[1, 0].set_title('Monthly Income Distribution')
axes[1, 0].tick_params(axis='x', rotation=45)sns.countplot(x='Educational Qualifications', data=data, ax=axes[1, 1])
axes[1, 1].set_title('Educational Qualifications Distribution')
axes[1, 1].tick_params(axis='x', rotation=45)plt.tight_layout()
plt.show()
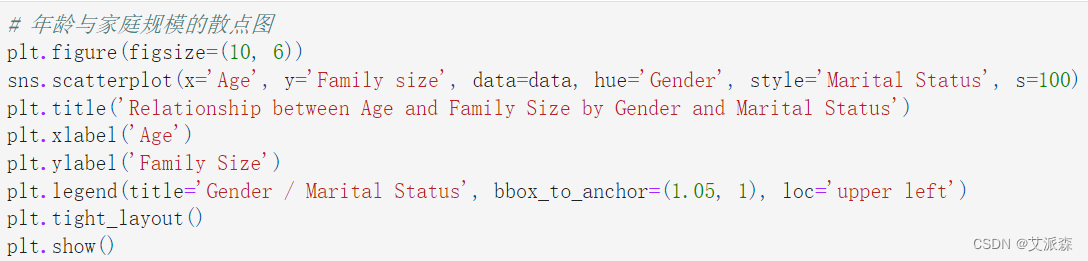
# 年齡與家庭規模的散點圖
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Age', y='Family size', data=data, hue='Gender', style='Marital Status', s=100)
plt.title('Relationship between Age and Family Size by Gender and Marital Status')
plt.xlabel('Age')
plt.ylabel('Family Size')
plt.legend(title='Gender / Marital Status', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
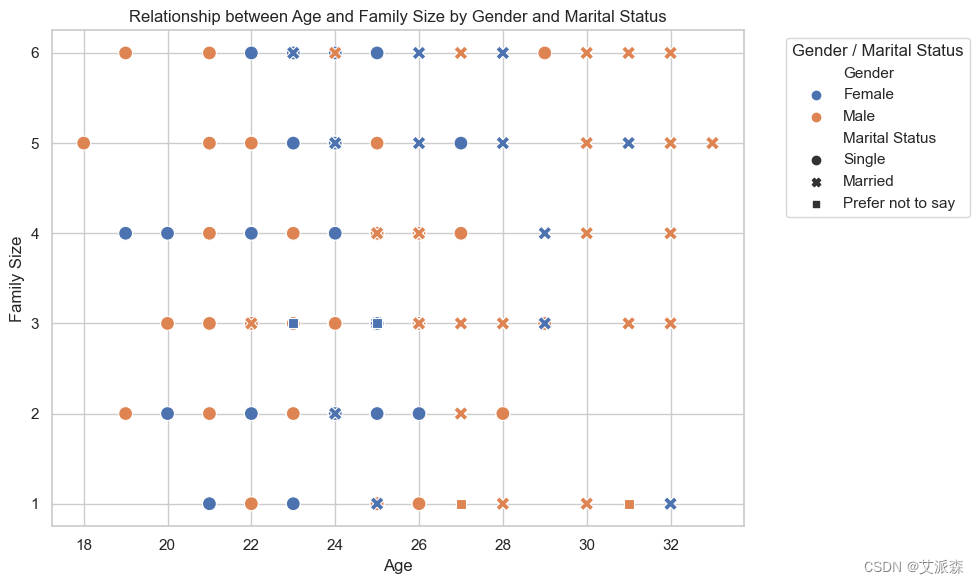
# 該圖表顯示了不同收入階層的人下的訂單數量
plt.figure(figsize=(12, 6))
sns.countplot(x='Monthly Income', hue='Output', data=data)
plt.title('Income Level vs. Online Ordering Behavior')
plt.xlabel('Monthly Income')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Ordered Online')
plt.tight_layout()
plt.show()
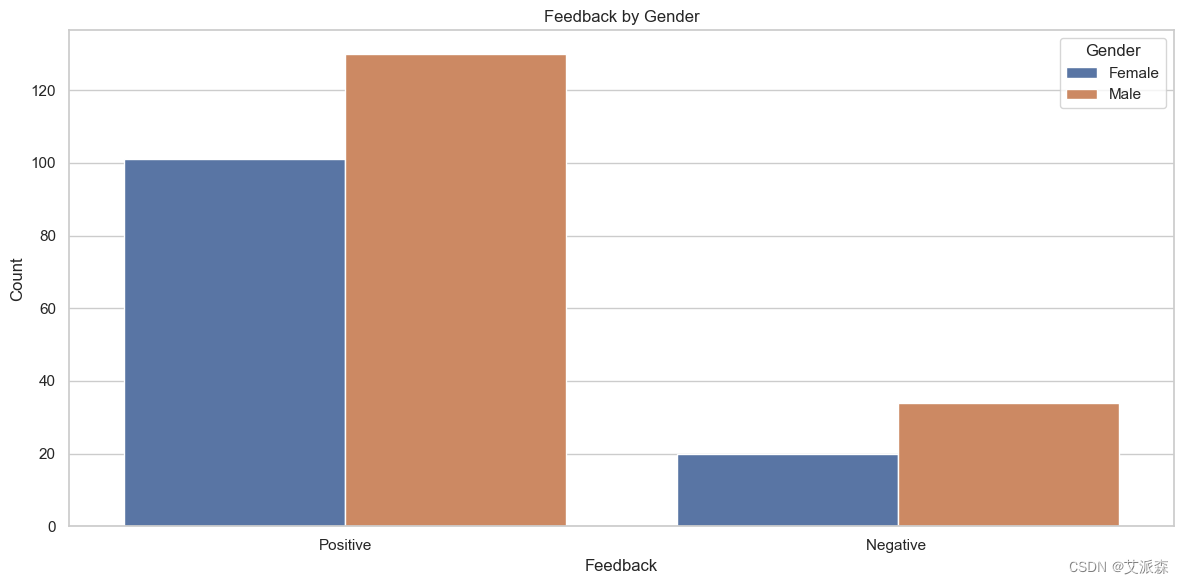
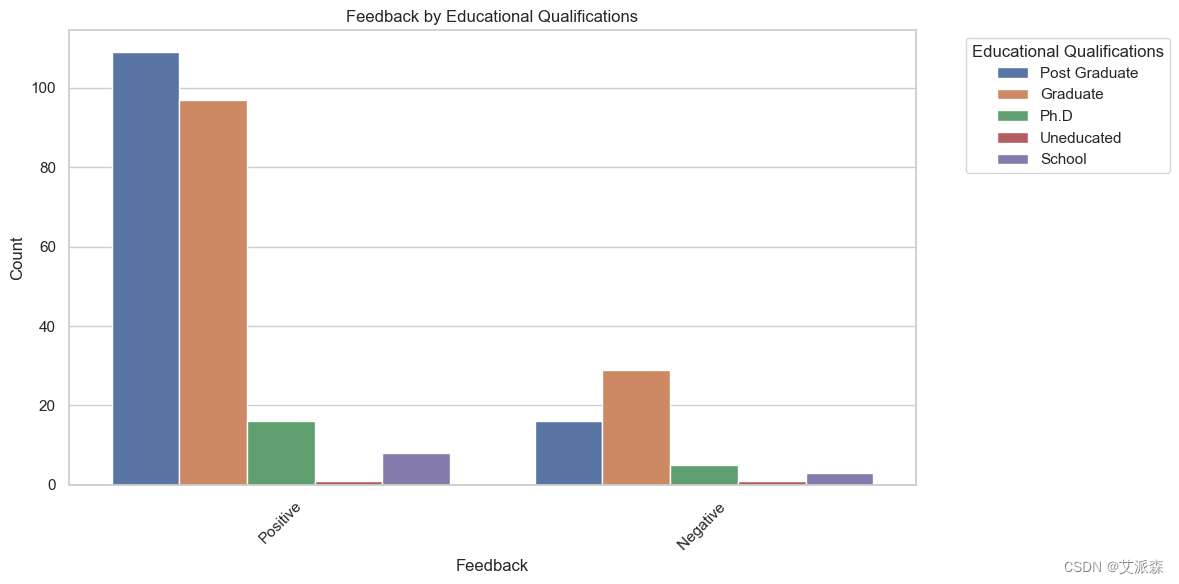
# 圖表顯示,根據他們的反饋,不同性別的人數以及根據他們的反饋,不同教育程度的人數
plt.figure(figsize=(12, 6))
sns.countplot(x='Feedback', hue='Gender', data=data)
plt.title('Feedback by Gender')
plt.xlabel('Feedback')
plt.ylabel('Count')
plt.legend(title='Gender')
plt.tight_layout()
plt.show()plt.figure(figsize=(12, 6))
sns.countplot(x='Feedback', hue='Educational Qualifications', data=data)
plt.title('Feedback by Educational Qualifications')
plt.xlabel('Feedback')
plt.ylabel('Count')
plt.legend(title='Educational Qualifications', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
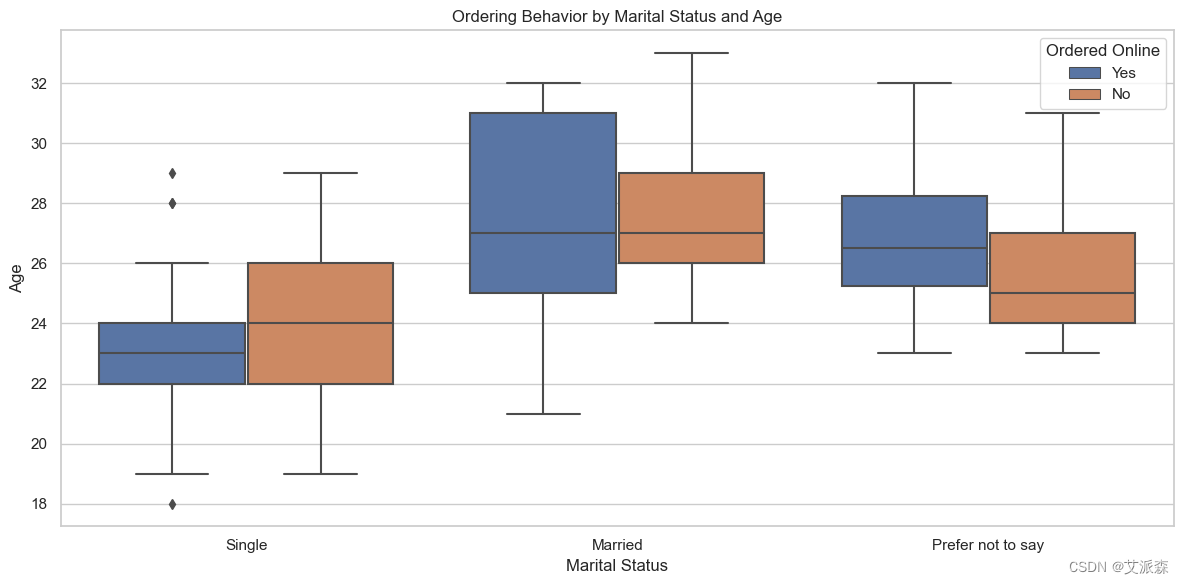
# 盒子圖顯示了不同婚姻狀況和年齡的顧客的訂購行為
plt.figure(figsize=(12, 6))
sns.boxplot(x='Marital Status', y='Age', hue='Output', data=data)
plt.title('Ordering Behavior by Marital Status and Age')
plt.xlabel('Marital Status')
plt.ylabel('Age')
plt.legend(title='Ordered Online')
plt.tight_layout()
plt.show()
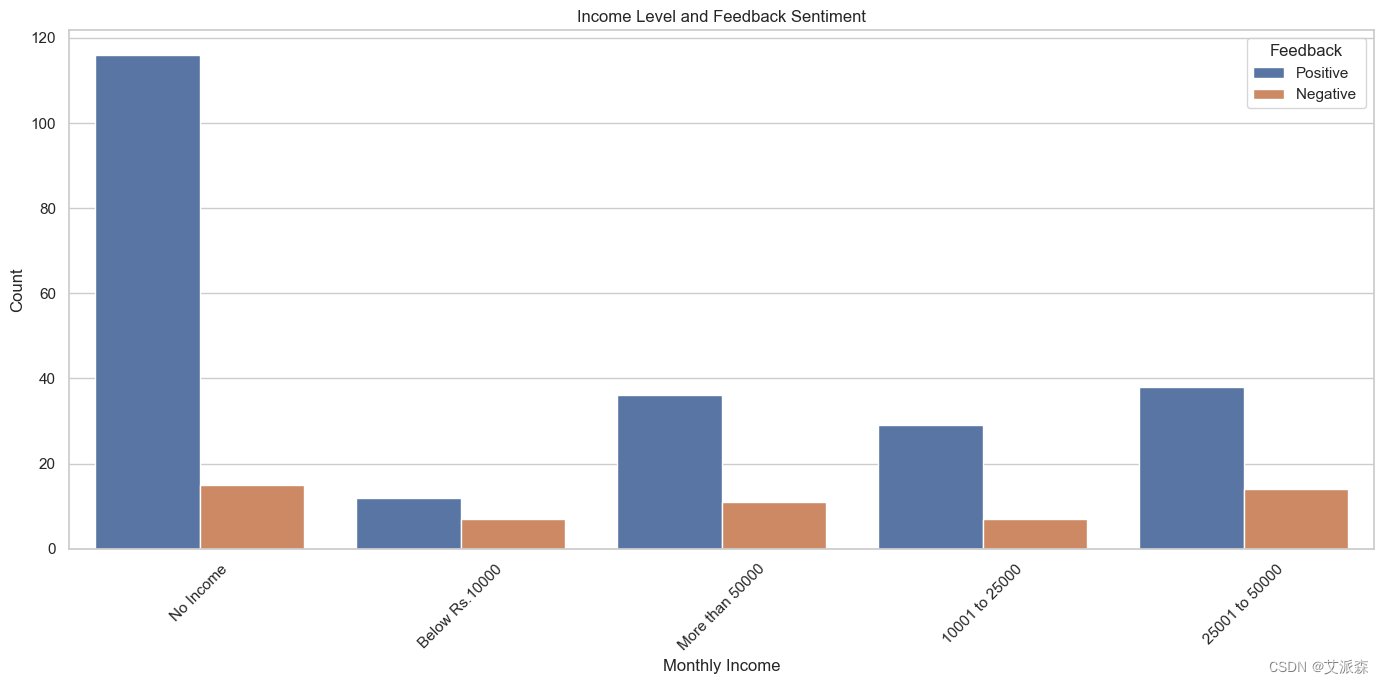
# 該圖表顯示了不同收入水平人群的正面和負面反饋數量
plt.figure(figsize=(14, 7))
sns.countplot(x='Monthly Income', hue='Feedback', data=data)
plt.title('Income Level and Feedback Sentiment')
plt.xlabel('Monthly Income')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Feedback', loc='upper right')
plt.tight_layout()
plt.show()
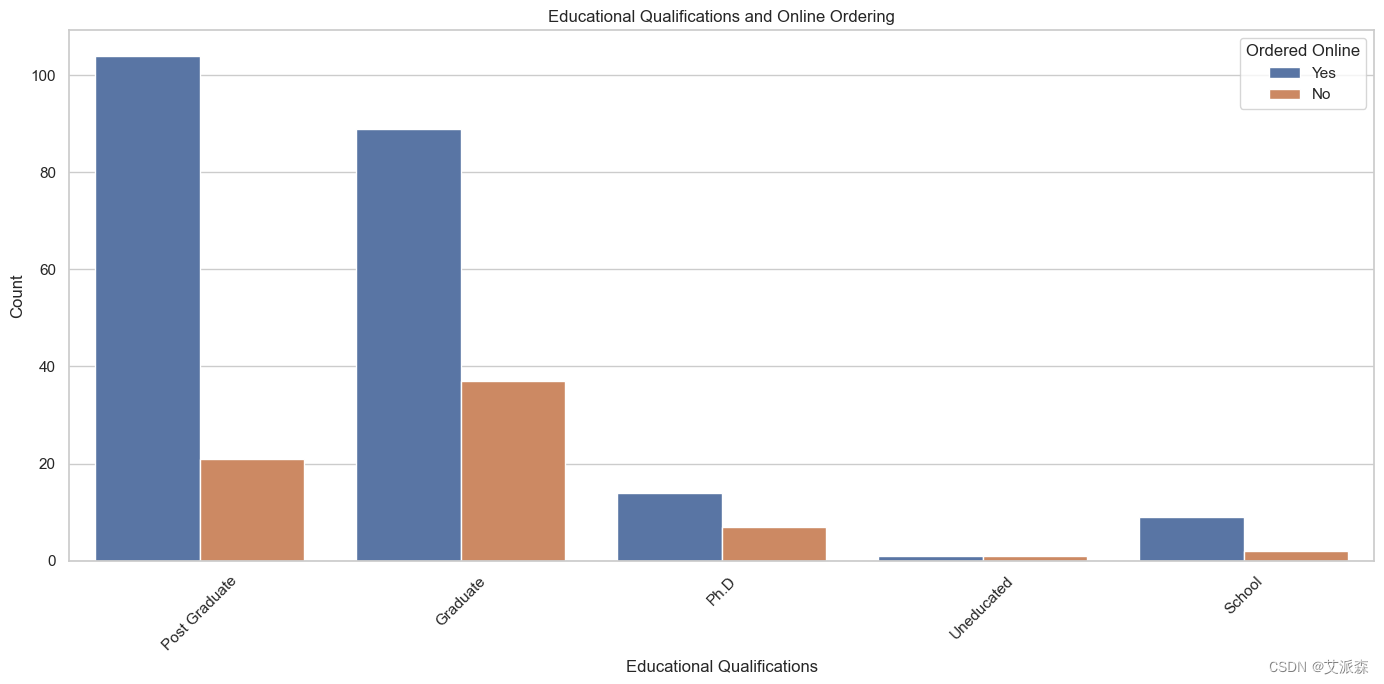
# 圖表顯示了不同學歷的人在網上訂餐的數量
plt.figure(figsize=(14, 7))
sns.countplot(x='Educational Qualifications', hue='Output', data=data)
plt.title('Educational Qualifications and Online Ordering')
plt.xlabel('Educational Qualifications')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Ordered Online', loc='upper right')
plt.tight_layout()
plt.show()
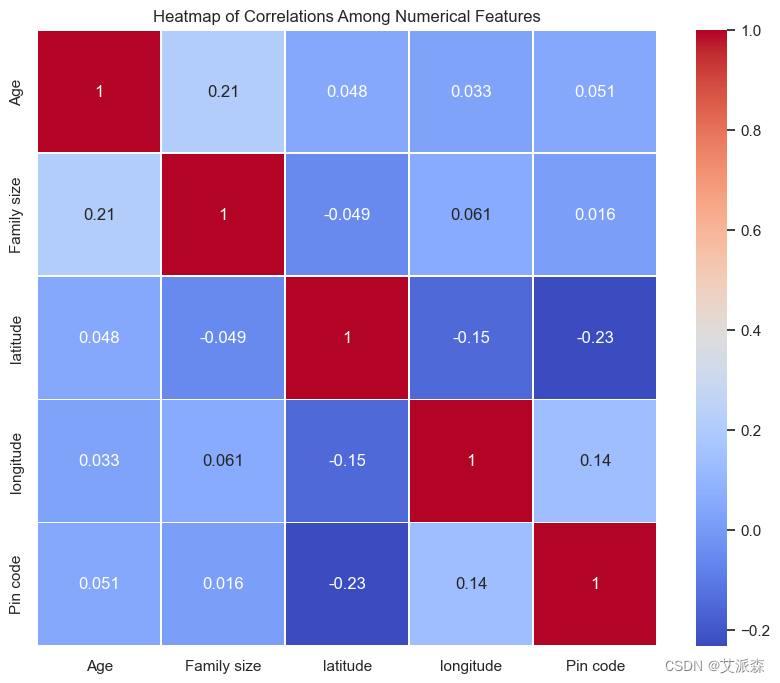
# 數據集中不同特征之間的熱圖
correlation_matrix = data[['Age', 'Family size', 'latitude', 'longitude', 'Pin code']].corr()
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', linewidths=.5)
plt.title('Heatmap of Correlations Among Numerical Features')
plt.show()
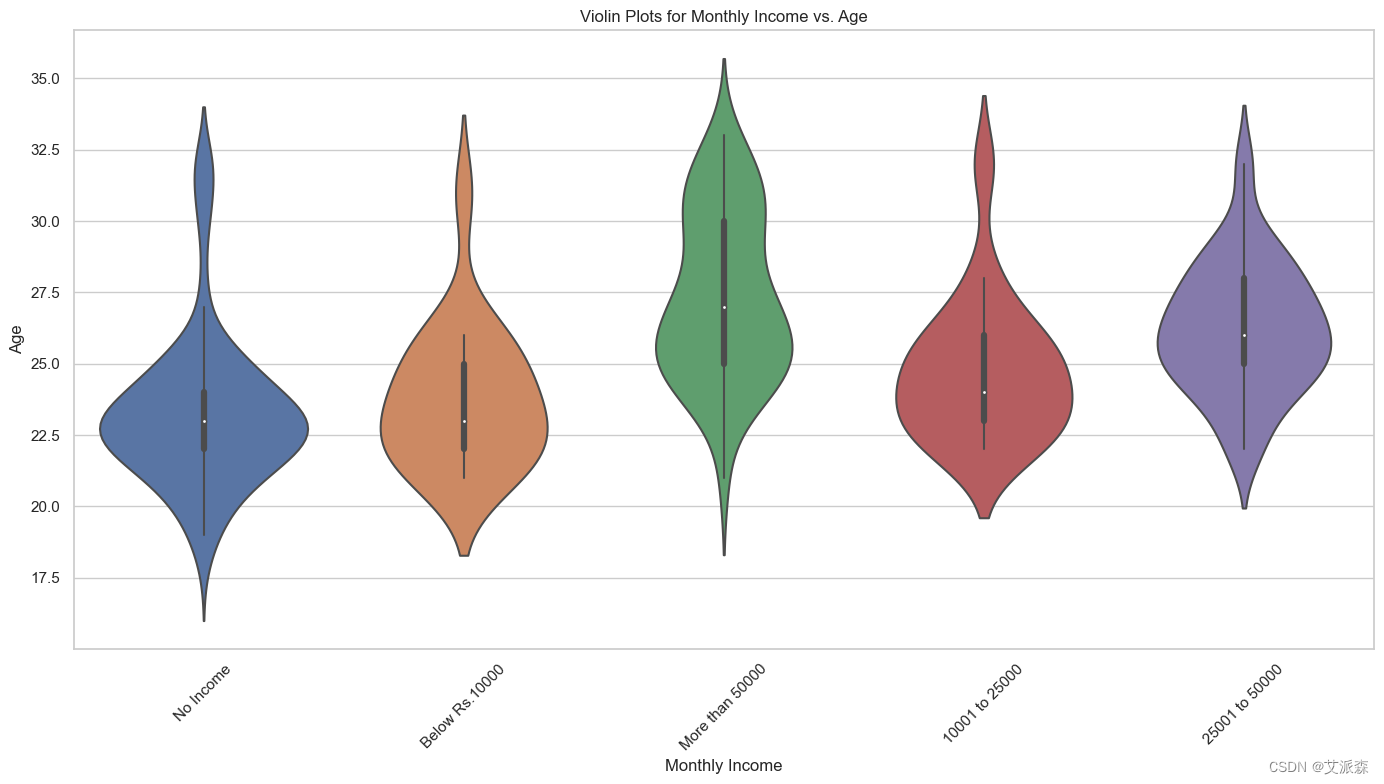
# 小提琴圖顯示月收入與年齡的關系
plt.figure(figsize=(14, 8))
sns.violinplot(x='Monthly Income', y='Age', data=data)
plt.title('Violin Plots for Monthly Income vs. Age')
plt.xlabel('Monthly Income')
plt.ylabel('Age')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
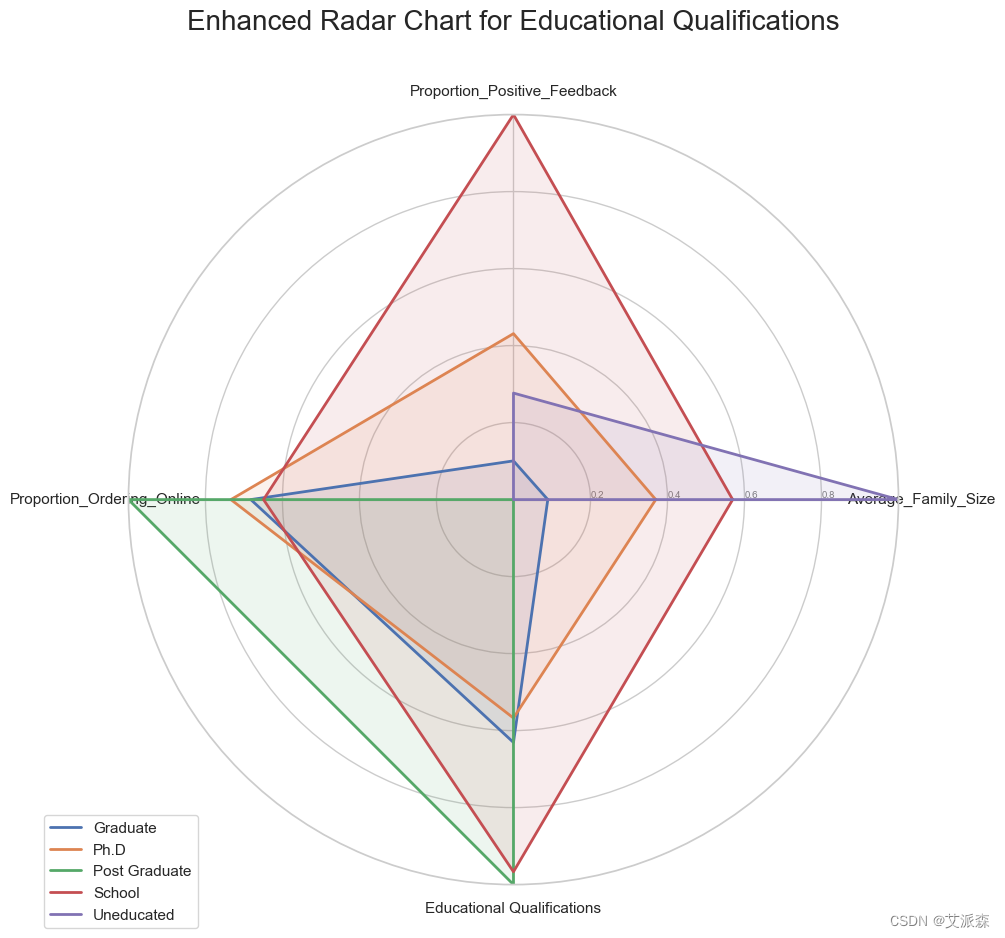
# 雷達圖顯示正面反饋數、負面反饋數、教育程度和平均家庭規模之間的關系
data = pd.read_csv('onlinefoods.csv')
data['Output_Numeric'] = data['Output'].map({'Yes': 1, 'No': 0})data['Positive_Feedback'] = (data['Feedback'] == 'Positive').astype(int)radar_df_new = data.groupby('Educational Qualifications').agg(Average_Age=('Age', 'mean'),Average_Family_Size=('Family size', 'mean'),Proportion_Positive_Feedback=('Positive_Feedback', 'mean'),Proportion_Ordering_Online=('Output_Numeric', 'mean')
).reset_index()scaler = MinMaxScaler()
radar_df_normalized = pd.DataFrame(scaler.fit_transform(radar_df_new.iloc[:, 1:]), columns=radar_df_new.columns[1:])
radar_df_normalized['Educational Qualifications'] = radar_df_new['Educational Qualifications']categories_new = list(radar_df_normalized)[1:]
N_new = len(categories_new)angles_new = [n / float(N_new) * 2 * 3.14159265359 for n in range(N_new)]
angles_new += angles_new[:1]fig, ax = plt.subplots(figsize=(10, 10), subplot_kw=dict(polar=True))plt.xticks(angles_new[:-1], categories_new)ax.set_rlabel_position(0)
plt.yticks([0.2, 0.4, 0.6, 0.8], ["0.2", "0.4", "0.6", "0.8"], color="grey", size=7)
plt.ylim(0,1)for i, row in radar_df_normalized.iterrows():data = radar_df_normalized.loc[i].drop('Educational Qualifications').tolist()data += data[:1]ax.plot(angles_new, data, linewidth=2, linestyle='solid', label=radar_df_normalized['Educational Qualifications'][i])ax.fill(angles_new, data, alpha=0.1)plt.title('Enhanced Radar Chart for Educational Qualifications', size=20, y=1.1)
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))plt.show()
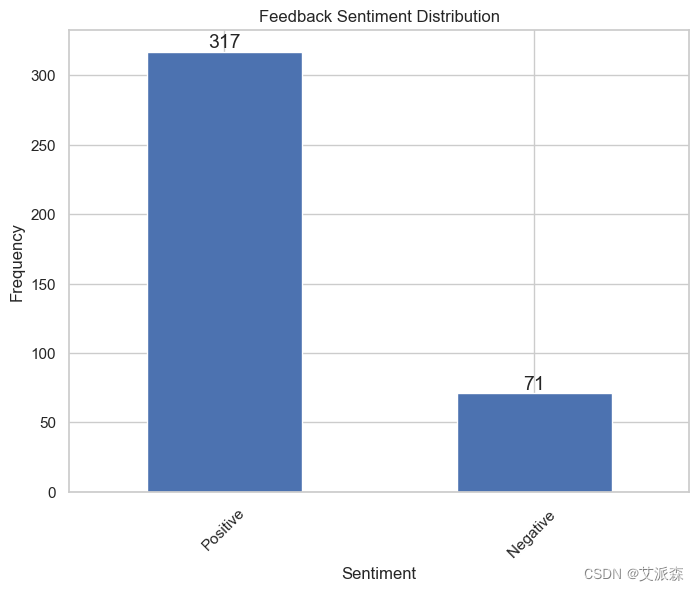
# 下面的條形圖顯示了正面和負面反饋的數量
data = pd.read_csv('onlinefoods.csv')
sentiment_counts = data['Feedback'].value_counts()plt.figure(figsize=(8, 6))
sentiment_counts.plot(kind='bar')
plt.title('Feedback Sentiment Distribution')
plt.xlabel('Sentiment')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
for a,b in zip(range(2),sentiment_counts.values):plt.text(a,b,'%d'%b,ha='center',va='bottom',fontsize=14)
plt.show()
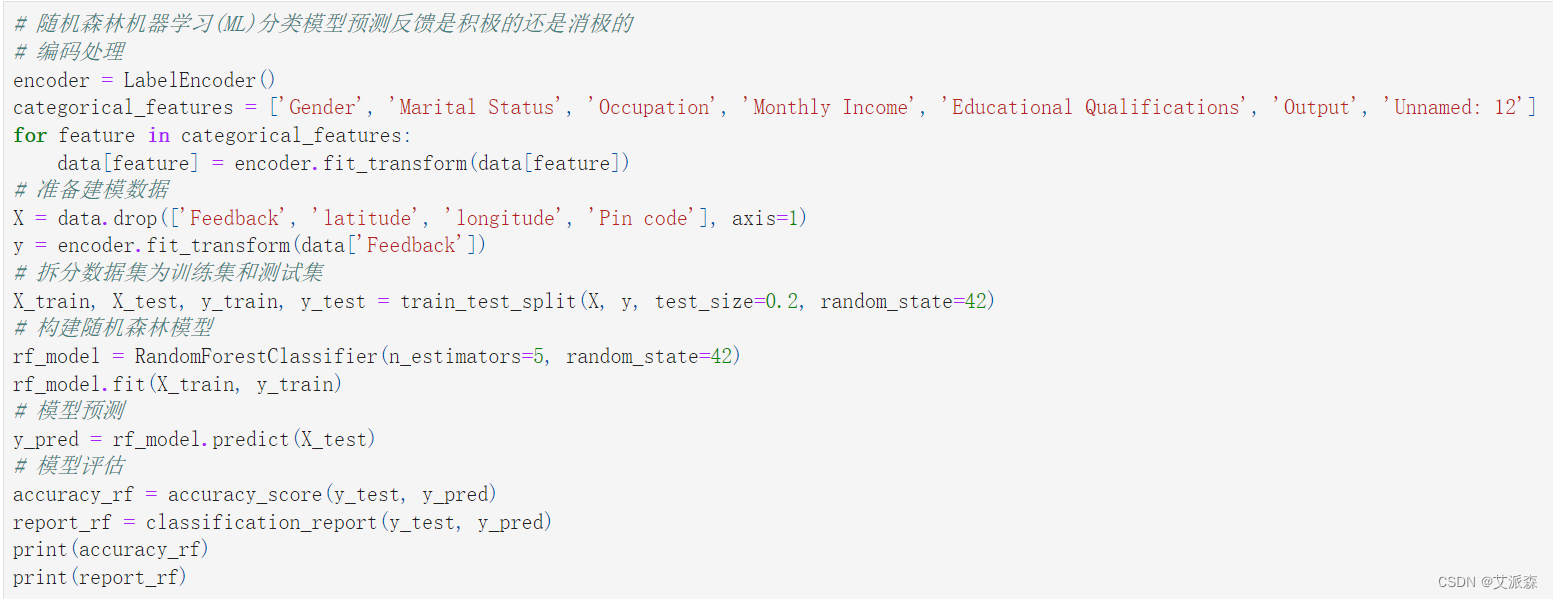
# 隨機森林機器學習(ML)分類模型預測反饋是積極的還是消極的
# 編碼處理
encoder = LabelEncoder()
categorical_features = ['Gender', 'Marital Status', 'Occupation', 'Monthly Income', 'Educational Qualifications', 'Output', 'Unnamed: 12']
for feature in categorical_features:data[feature] = encoder.fit_transform(data[feature])
# 準備建模數據
X = data.drop(['Feedback', 'latitude', 'longitude', 'Pin code'], axis=1)
y = encoder.fit_transform(data['Feedback'])
# 拆分數據集為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 構建隨機森林模型
rf_model = RandomForestClassifier(n_estimators=5, random_state=42)
rf_model.fit(X_train, y_train)
# 模型預測
y_pred = rf_model.predict(X_test)
# 模型評估
accuracy_rf = accuracy_score(y_test, y_pred)
report_rf = classification_report(y_test, y_pred)
print(accuracy_rf)
print(report_rf)
我們可以看到,我們得到了相當不錯的90%的準確率資料獲取,更多粉絲福利,關注下方公眾號獲取


![[羊城杯 2021]BabySmc](http://pic.xiahunao.cn/[羊城杯 2021]BabySmc)



)



—— 預編碼算法)




京東訂單數據分析案例-維度下鉆)


學法)

