note
文章目錄
- note
- 論文
- 1. 論文試圖解決什么問題
- 2. 這是否是一個新的問題
- 3. 這篇文章要驗證一個什么科學假設
- 4. 有哪些相關研究?如何歸類?誰是這一課題在領域內值得關注的研究員?
- 5. 論文中提到的解決方案之關鍵是什么?
- 6. 論文中的實驗是如何設計的?
- 7. 用于定量評估的數據集是什么?代碼有沒有開源?
- 8. 論文中的實驗及結果有沒有很好地支持需要驗證的科學假設?
- 9. 這篇論文到底有什么貢獻?
- 10. 下一步呢?有什么工作可以持續深入?
- Reference
論文

新加坡-南洋理工大學發的paper,2023年12月
我們還是從十大問題分析這篇論文,但由于是綜述,可能沒有實驗環節詳細的部分。
1. 論文試圖解決什么問題
- 一篇關于Visual Instruction Tuning 視覺指令微調任務的綜述,Visual Instruction Tuning是為了讓多模態LLM擁有指令遵循能力
- 文章介紹傳統CV局限性(需要針對不同任務訓練不同模型,缺乏交互能力),如下圖左側
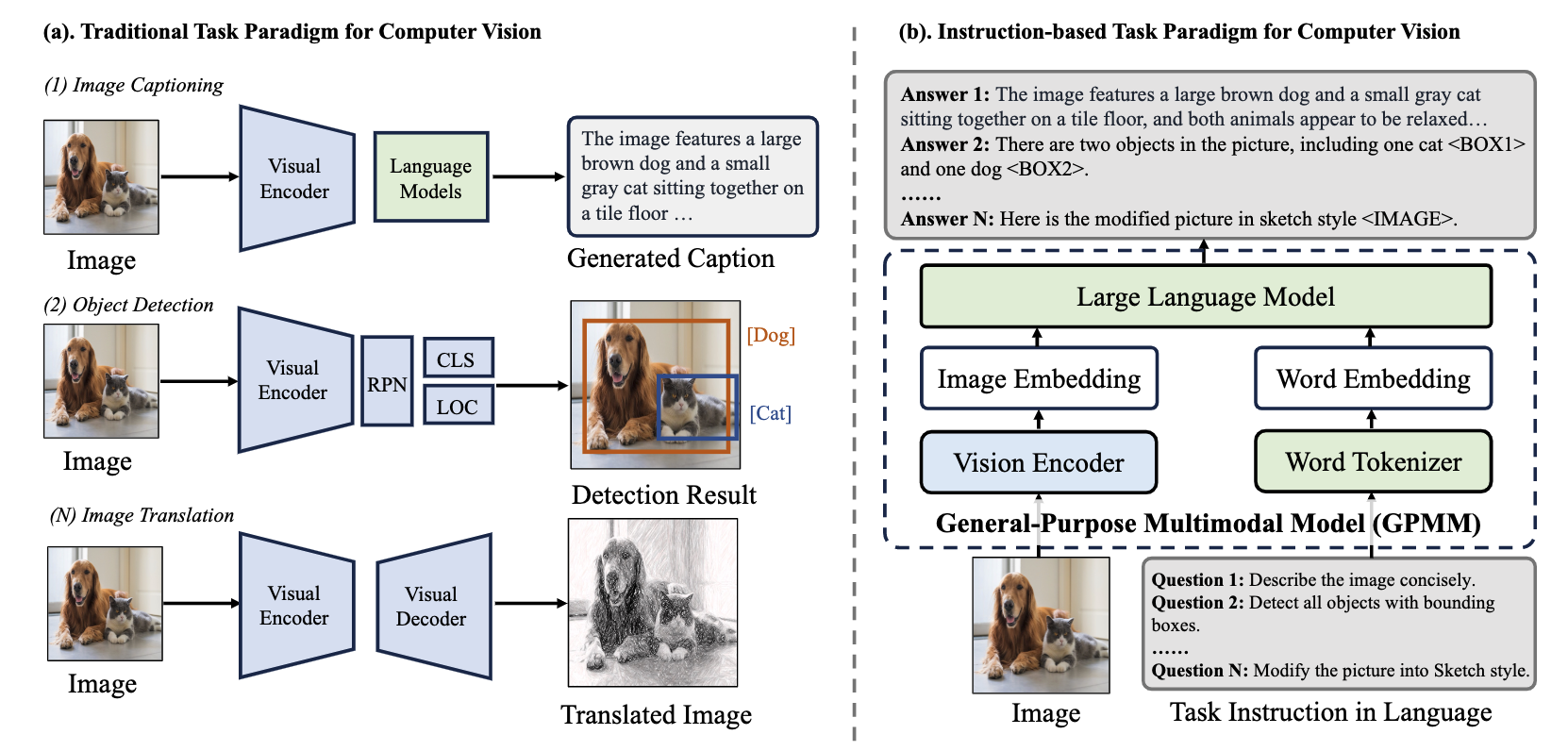
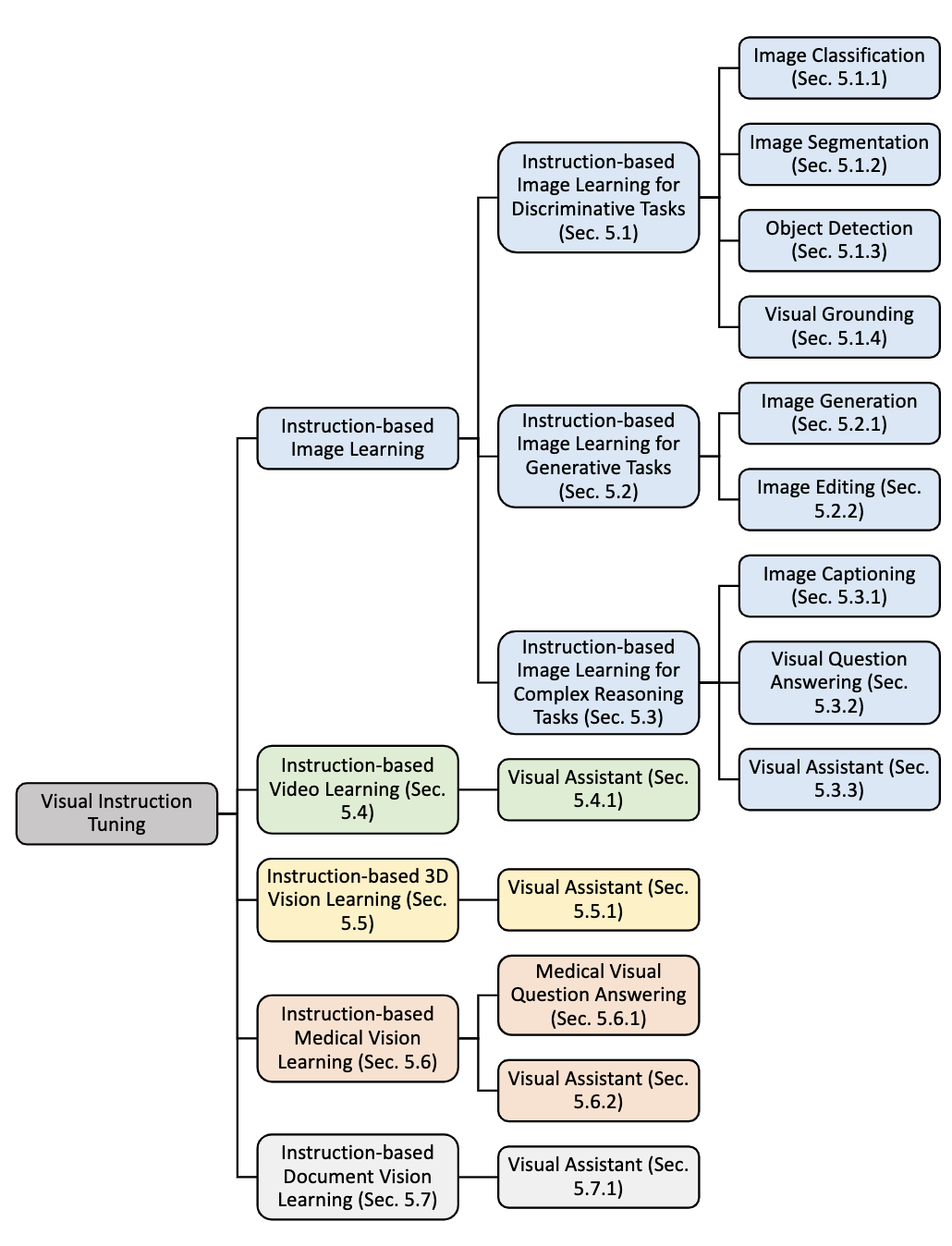
- 文章從三方面介紹Visual Instruction Tuning的發展過程:單語言(英語)到多語言、圖片輸入從單一到多元(從圖片到視頻/3D圖像等)、任務復雜化(從基本的圖片分類到VQA視覺問答、圖像生成等難任務)
2. 這是否是一個新的問題
去年年底到今年,類似的綜述還是不少的。
3. 這篇文章要驗證一個什么科學假設
4. 有哪些相關研究?如何歸類?誰是這一課題在領域內值得關注的研究員?
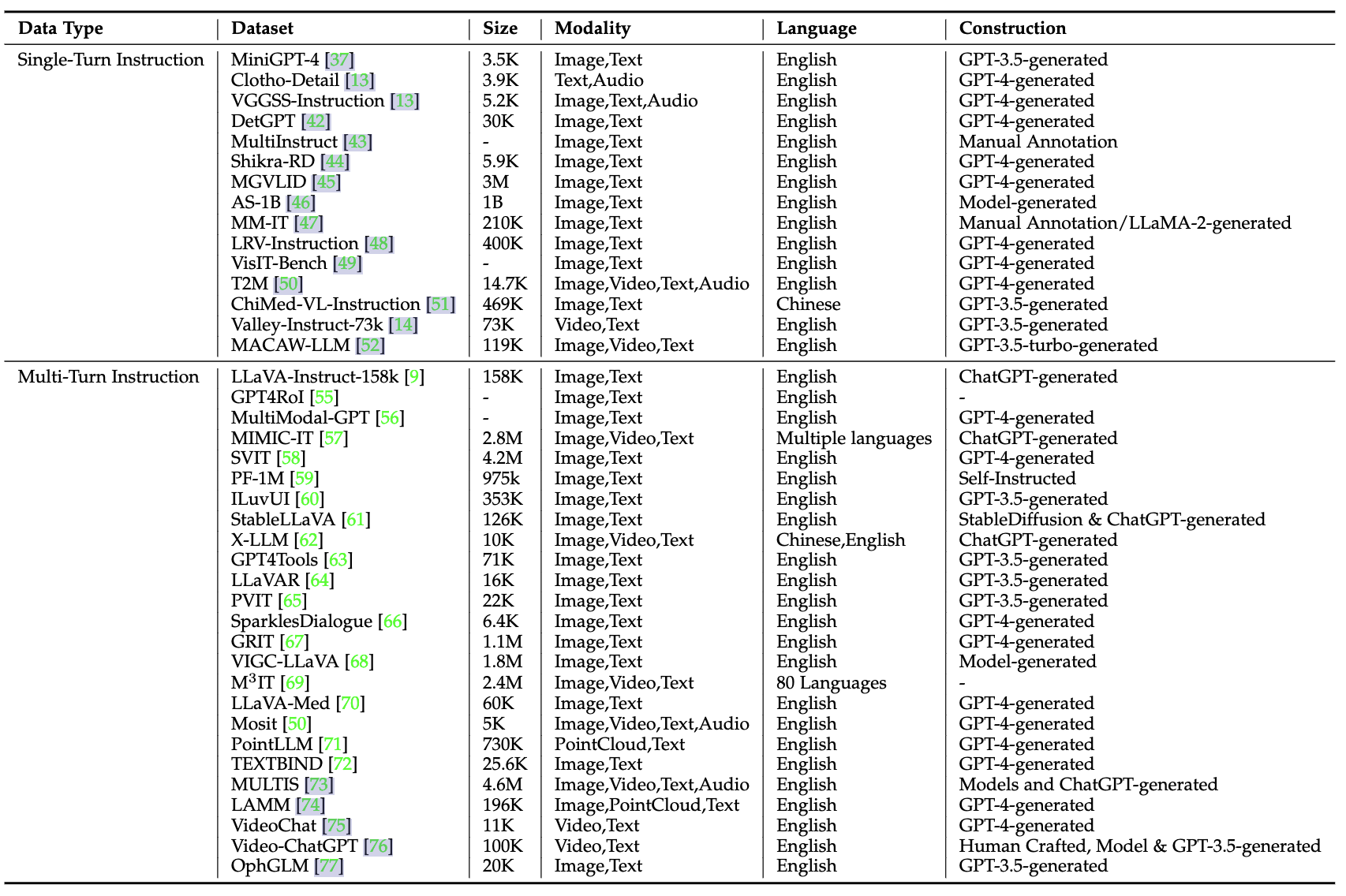
相關的視覺微調 公開數據集如下,大部分是GPT3.5或者GPT4構造的,而且多輪對話的visual SFT數據還不少:
5. 論文中提到的解決方案之關鍵是什么?
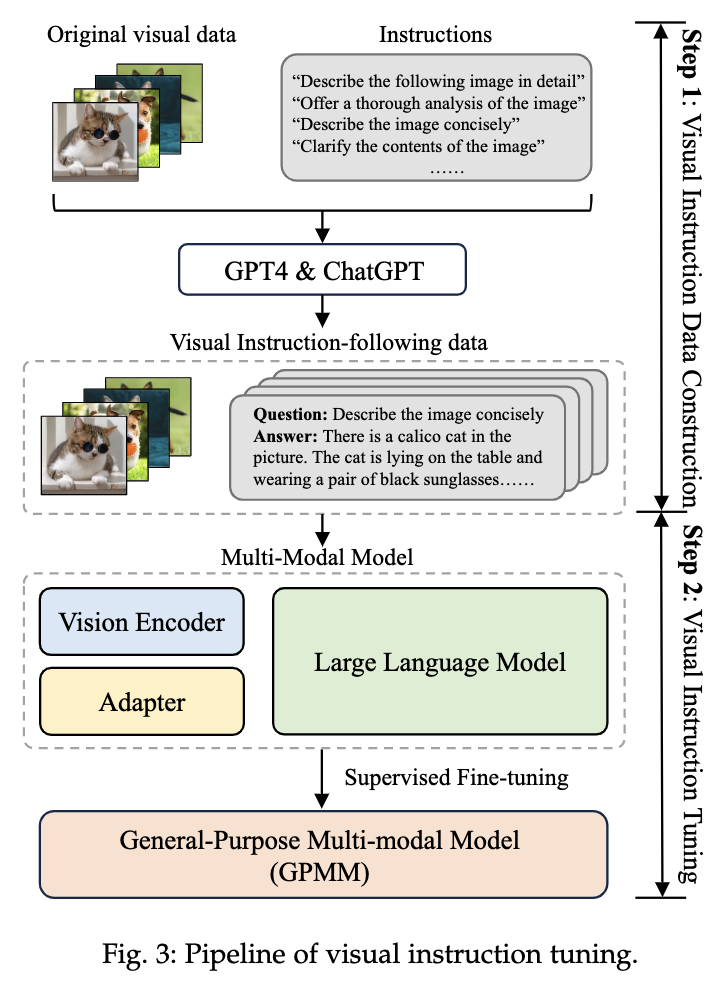
跟進一步,視覺微調的主流過程,基于預訓練的LLM,將視覺特征token化冰對齊到語言空間中,利用語言模型得到多模態LLM的輸出:
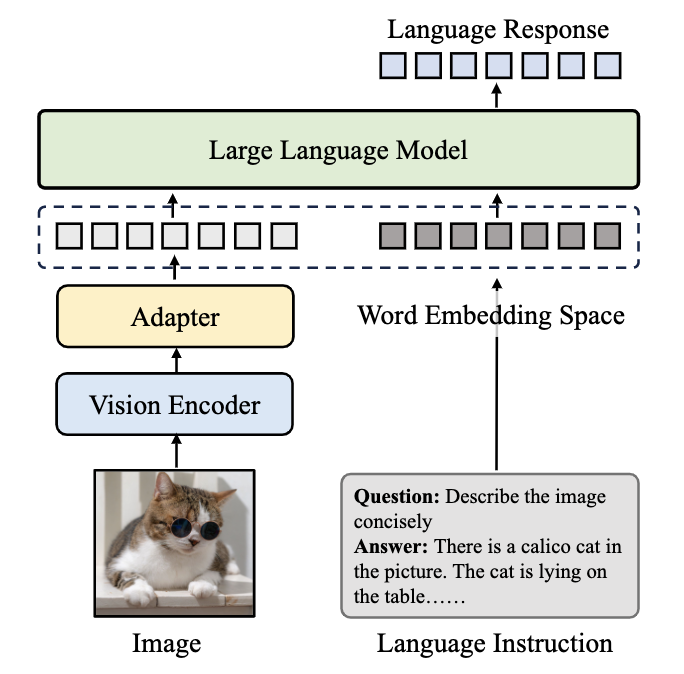
6. 論文中的實驗是如何設計的?
是綜述,沒實驗。
7. 用于定量評估的數據集是什么?代碼有沒有開源?
用于多模態視覺微調的評估數據集:
- VQAv2:Visual Question Answering(視覺問答)數據集,廣泛用于評估模型在理解圖像內容并回答問題方面的能力。
- GQA:Graphic Question Answering數據集,包含復雜的視覺問答任務,測試模型的視覺推理能力。
- OKVQA:Open-ended Knowledge Visual Question Answering數據集,需要外部知識來回答視覺問題,評估模型結合視覺和知識推理的能力。
- OCR-VQA:Optical Character Recognition Visual Question Answering數據集,測試模型在圖像中識別和理解文本的能力。
- A-OKVQA:Augmented OKVQA數據集,擴展了OKVQA,包含更多樣的問答對,測試模型在多種情境下的知識推理能力。
- MSCOCO:Microsoft Common Objects in Context數據集,包含豐富的圖像標注信息,廣泛用于圖像識別和分割任務。
- TextCaps:數據集專注于圖像字幕生成,測試模型在理解圖像內容并生成自然語言描述方面的能力。
- RefCOCO、RefCOCO+、RefCOCOg:ReferIt Game數據集的變體,用于評估模型在圖像中定位指定對象的能力。
- Visual Genome:包含圖像、區域標注和關系描述的數據集,廣泛用于視覺問答和圖像理解任務。
- Flickr30K:包含豐富的圖像及其描述的數據集,用于評估圖像字幕生成和圖像理解。
- VizWiz:數據集包含盲人用戶拍攝的圖像和相關問題,用于評估模型在處理實際場景和用戶生成內容方面的能力。
- ScienceQA:針對科學領域的問答數據集,測試模型在結合視覺和科學知識回答問題方面的能力。
8. 論文中的實驗及結果有沒有很好地支持需要驗證的科學假設?
略,綜述沒實驗。
9. 這篇論文到底有什么貢獻?
這篇綜述對Visual Instruction Tuning進行了任務分類:
(1)Discriminative判別式任務:
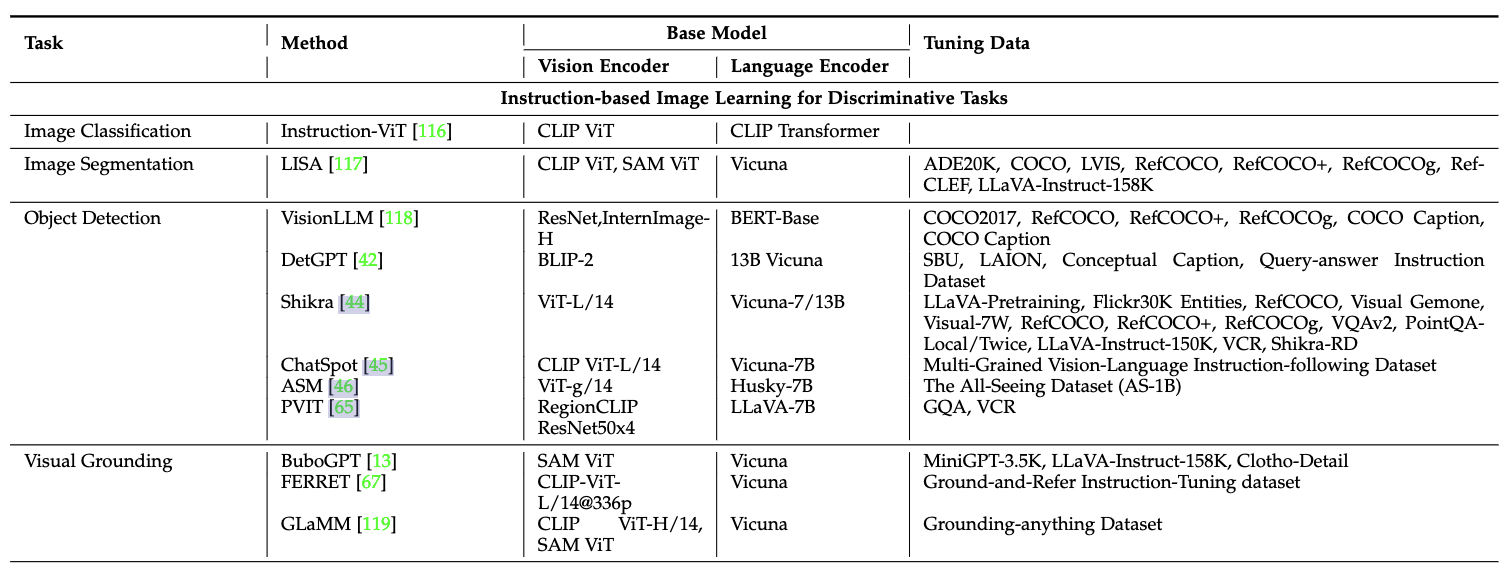
-
圖像分類(Image Classification):利用可學習的
[CLS]token表示全局圖像特征,計算[CLS] token和提示tokens之間的相似性,如下圖
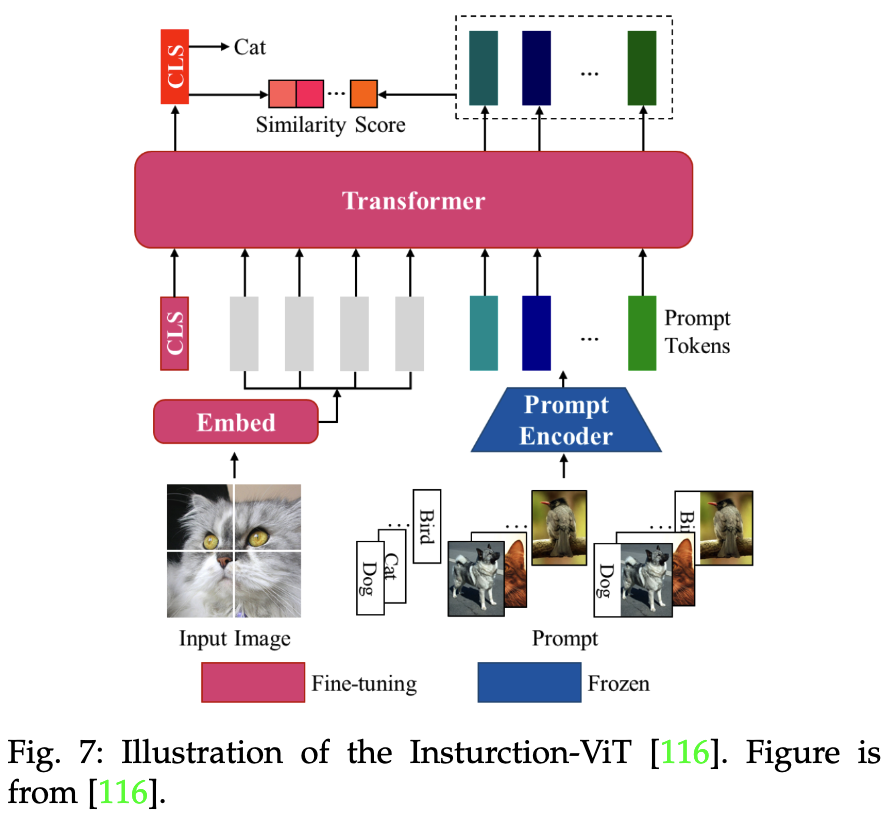
-
語義分割(Image Segmentation):常規的語義分割是像素級別的分類任務,LISA模型是根據復雜的query生成分割掩碼,理解query并在圖像中找到對應的區域(比如找到下面的維C最多的食物并標記),所以這里模型最終生成一張圖。
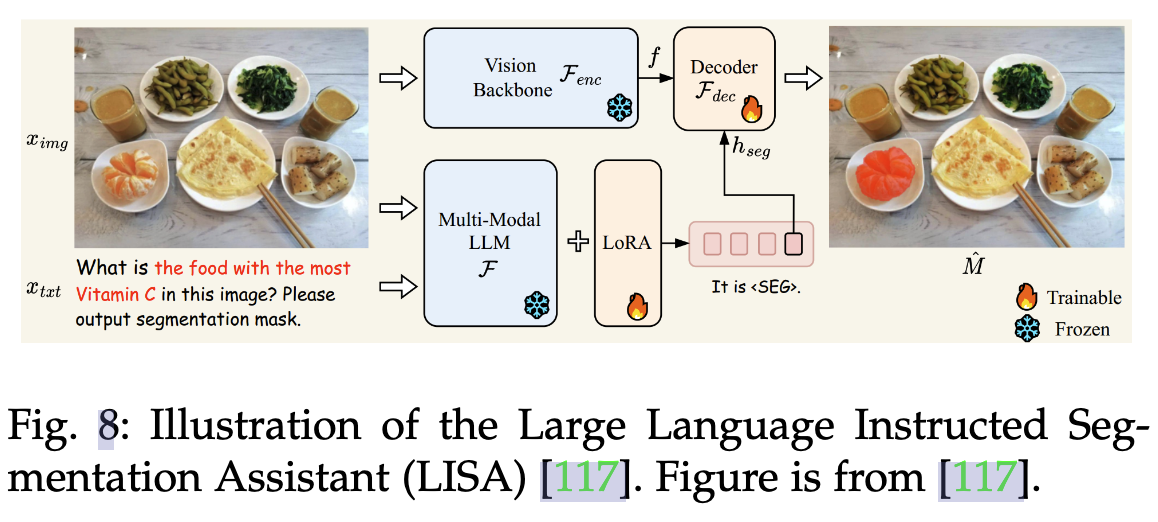
-
目標檢測(Object Detection):下圖是visionLLM的做法,提出一個指令感知圖像分詞器(Instruction-Aware Image Tokenizer)有效理解和解析視覺輸入,總之是讓LLM最終回答出query指向目標的上下左右坐標。VisionLLM 在 COCO 數據集上的目標檢測任務中實現了超過 60% 的平均精度(mAP),這與特定于檢測的模型相當。
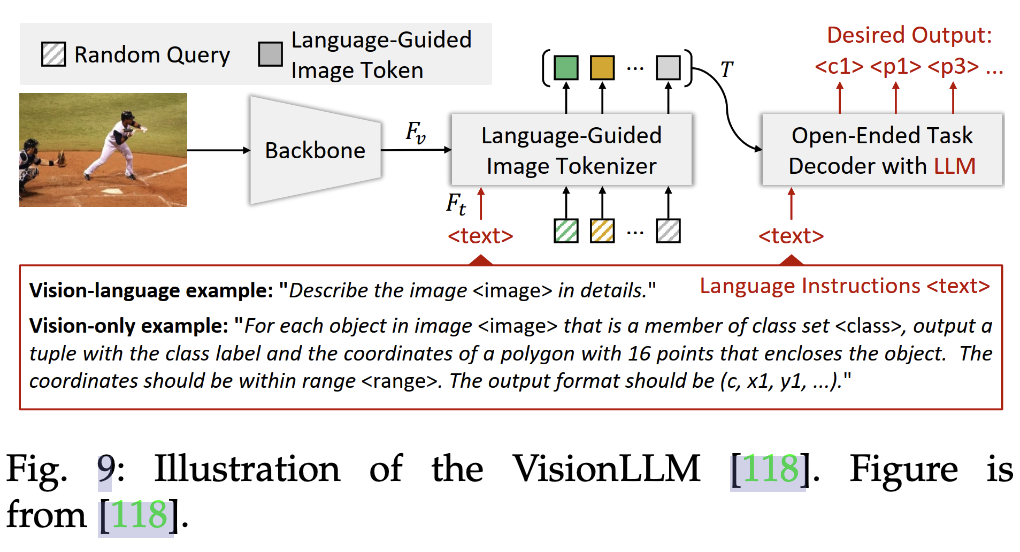
- 視覺定位(Visual Grounding)
(2)生成式任務:
- 圖像生成
- 圖像編輯

(3)復雜推理任務:
- Image Captioning:圖像描述,可以用如MiniGPT-4、Clever Flamingo等模型
- Visual Question Answering:即VQA視覺問答,可以用如MiniGPT-v2、instructBLIP等模型
- Visual Assistant:視覺助手,可以用如LLaVA、Qwen-VL(多任務預訓練數據很好)等模型
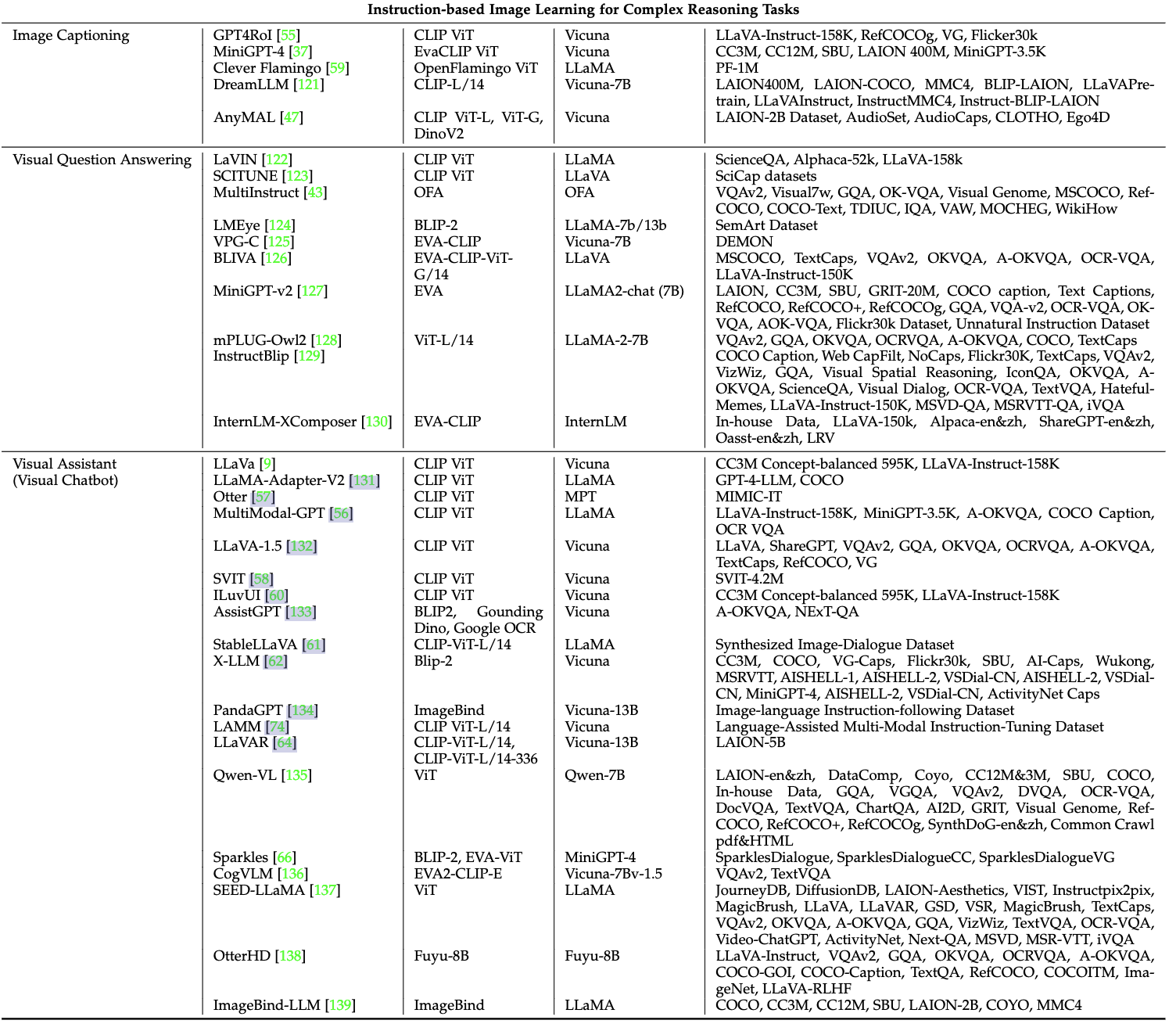
(4)視頻學習的微調:視頻理解、視頻生成、視頻字幕生成等
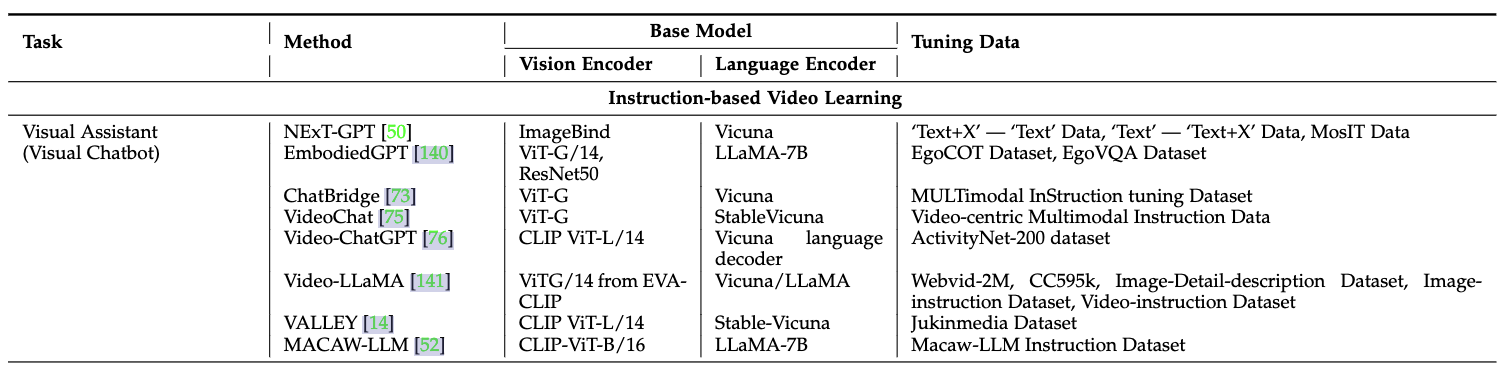
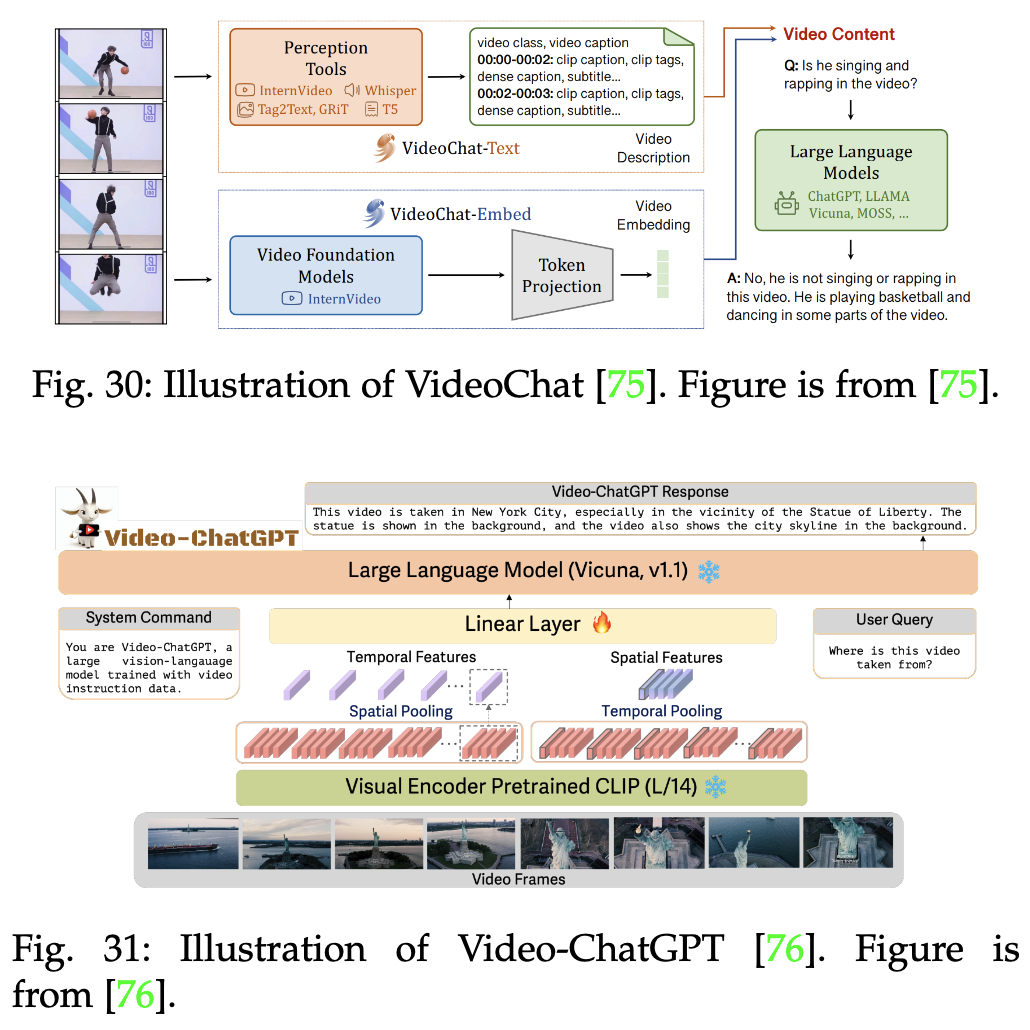
如video-chatgpt模型(如下),視頻具有時序特性,Video-ChatGPT使用預訓練的視頻編碼器將視頻分割成多個幀,并提取每一幀的視覺特征。這些視覺特征再經過時序編碼,生成包含時序信息的特征向量。用戶可以對視頻進行提問:
(5)文檔學習的視覺微調:

如mPLUG-DocOwl模型:
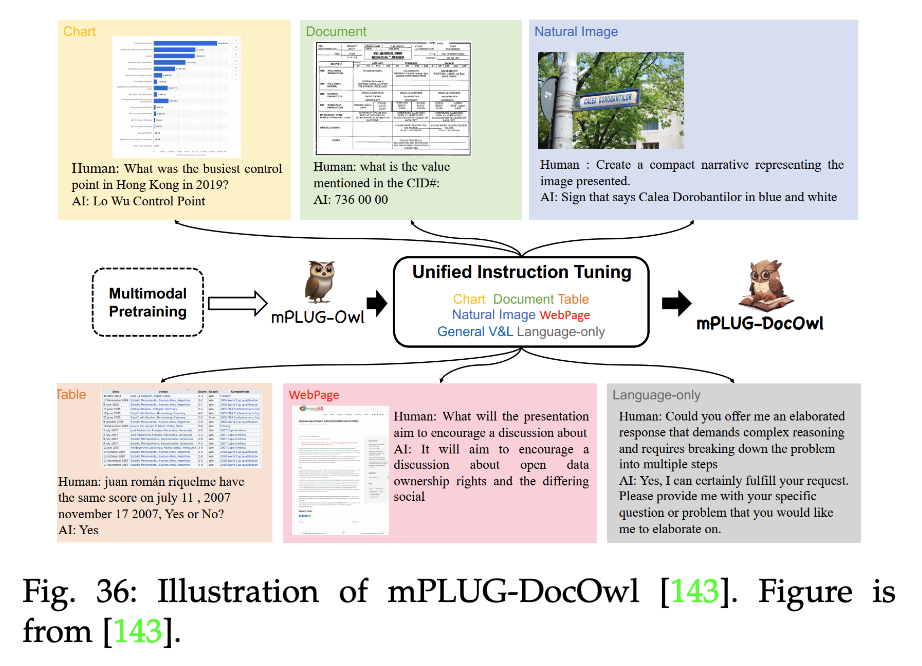
(6)3D Vision Learning的視覺微調:包括depth estimation, 3D reconstruction(3D重建), object recognition, and scene comprehension(場景理解)等具體任務。
10. 下一步呢?有什么工作可以持續深入?
- 增強模型在視覺和語言之間的對齊能力
- 動態場景理解:比如視頻、實時流媒體的多模態輸入
- 用于幫助藝術家、設計師進行圖像、視頻編輯;用于教育領域等
Reference
[1] Visual Instruction Tuning towards General-Purpose Multimodal Model: A Survey


)
![[初始計算機]——計算機網絡的基本概念和發展史及OSI參考模型](http://pic.xiahunao.cn/[初始計算機]——計算機網絡的基本概念和發展史及OSI參考模型)



)


)

SpringBoot整合,可靠性投遞,死信隊列,延遲隊列,消費端限流,消息超時)


H100性能及應用場景)
:待機喚醒實驗)


 + 負載均衡))