二叉樹
引言
在計算機科學中,數據結構是算法設計的基石,而二叉樹(Binary Tree)作為一種基礎且廣泛應用的數據結構,具有重要的地位。無論是在數據庫索引、內存管理,還是在編譯器實現中,二叉樹都扮演著關鍵角色。本文將帶你深入了解二叉樹的基本概念、性質,以及如何在C語言中實現一個完整的二叉樹。
首先,我們將探討二叉樹的定義和基本特性,包括其節點、子節點、以及樹的高度和深度等基本概念。接著,我們會逐步介紹如何使用C語言構建二叉樹,涉及節點的定義、樹的初始化、節點的插入與刪除等基本操作。最后,我們還將討論一些常見的二叉樹遍歷算法,如前序遍歷、中序遍歷和后序遍歷,并提供相應的代碼示例。
通過這篇文章,你不僅能掌握二叉樹的基本理論,還能學會如何在C語言中靈活運用這一數據結構,為解決實際編程問題提供有力的工具和方法。讓我們一起開啟這段探索二叉樹世界的旅程吧!
本篇文章重點在4. 二叉樹的鏈式結構及實現,有需要的小伙伴可以直接點擊目錄進行跳轉
目錄
- 二叉樹
- 引言
- 1. 樹的概念及表示方法
- 1.1 樹的概念
- 1.2 樹的表示
- 2. 二叉樹的概念及性質
- 2.1 二叉樹的概念
- 2.2 特殊的二叉樹
- 2.3 二叉樹的性質
- 3. 二叉樹的順序結構及實現
- 3.1 堆的概念及結構
- 3.2 堆的實現
- 3.2.1 定義堆的結構體
- 3.2.2 堆的初始化
- 3.2.3 堆的銷毀
- 3.2.4 數據交換函數
- 3.2.5 向上調整函數
- 3.2.6 堆的插入
- 3.2.7 向下調整算法
- 3.2.8 堆的刪除
- 3.2.9 取堆頂的數據
- 3.2.10 堆的判空
- 3.2.11 堆的數據個數
- 3.3 建堆的時間復雜度
- 3.4 堆的應用
- 3.4.1 堆排序
- 3.4.2 Top-k 問題
- 4. 二叉樹的鏈式結構及實現
- 4.1 二叉樹的實現
- 4.1.1 二叉樹的前序遍歷
- 4.1.2 二叉樹的中序遍歷
- 4.1.3 二叉樹的后序遍歷
- 4.1.4 根據數組創建二叉樹
- 4.1.5 二叉樹的銷毀
- 4.1.6 二叉樹的節點個數
- 4.1.7 二叉樹葉子節點個數
- 4.1.8 二叉樹第k層節點個數
- 4.1.9 二叉樹查找值為x的節點
- 4.1.10 層序遍歷
- 4.1.11 判斷二叉樹是否是完全二叉樹
1. 樹的概念及表示方法
在這一部分我會簡單的介紹一下樹的相關概念,不會太詳細,因為這篇文章著重介紹的是二叉樹,所以默認讀者是對樹這種結構有一定了解了,如果給您帶來不便,還請見諒。
1.1 樹的概念
樹是一種非線性的數據結構,它是由n(n>=0)個有限結點組成一個具有層次關系的集合。把它叫做樹是因為它看起來像一棵倒掛的樹,也就是說它是根朝上,而葉朝下的。
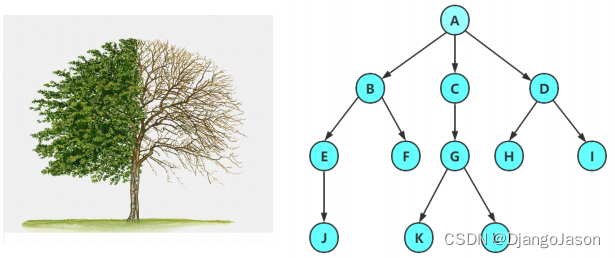
注意:樹型結構中,子樹之間不能有交集,否則就不是樹形結構

重點

1.2 樹的表示
樹結構相對線性表就比較復雜了,要存儲表示起來就比較麻煩了,既要保存值域,也要保存結點和結點之間的關系,實際中樹有很多種表示方式如:雙親表示法,孩子表示法、孩子雙親表示法以及孩子兄弟表示法等。我們這里就簡單的了解其中最常用的孩子兄弟表示法。
typedef int DataType;
struct Node
{struct Node* firstChild1; // 第一個孩子結點struct Node* pNextBrother; // 指向其下一個兄弟結點DataType data; // 結點中的數據域
};

2. 二叉樹的概念及性質
2.1 二叉樹的概念
一棵二叉樹是結點的一個有限集合,該集合或者為空,或者由一個根結點加上兩棵別稱為左子樹和右子樹的二叉樹組成。
二叉樹的特點:
- 二叉樹不存在度大于2的結點
- 二叉樹的子樹有左右之分,次序不能顛倒,因此二叉樹是有序樹
注意:對于任意的二叉樹都是由以下幾種情況復合而成的:

2.2 特殊的二叉樹
- 滿二叉樹:一個二叉樹,如果每一個層的結點數都達到最大值,則這個二叉樹就是滿二叉樹。也就是說,如果一個二叉樹的層數為
K,且結點總數是(2^k)-1,則它就是滿二叉樹。 - 完全二叉樹:完全二叉樹是效率很高的數據結構,完全二叉樹是由滿二叉樹而引出來的。對于深度為
K的,有n個結點的二叉樹,當且僅當其每一個結點都與深度為K的滿二叉樹中編號從1至n的結點一一對應時稱之為完全二叉樹。 要注意的是滿二叉樹是一種特殊的完全二叉樹。
對于完全二叉樹的概念介紹大家可能還不能深刻理解什么是完全二叉樹,我來給大家總結一下,我們可以對著下面的圖片進行理解。

假設樹的高度為h,前h-1層都是滿的,最后一層不滿,但是最后一層一定是從左往右連續分布的,不能有空節點。這就是完全二叉樹。
2.3 二叉樹的性質
- 若規定根結點的層數為
1,則一棵非空二叉樹的第i層上最多有2^(i-1)個結點. - 若規定根結點的層數為1,則深度為
h的二叉樹的最大結點數是(2^h)-1. - 對任何一棵二叉樹, 如果度為
0其葉結點個數為n0, 度為2的分支結點個數為n2,則有n0 = n2 +1的關系.
下邊附上性質3的證明
/*
* 假設二叉樹有N個結點
* 從總結點數角度考慮:N = n0 + n1 + n2 ①
*
* 從邊的角度考慮,N個結點的任意二叉樹,總共有N-1條邊
* 因為二叉樹中每個結點都有雙親,根結點沒有雙親,每個節點向上與其雙親之間存在一條邊
* 因此N個結點的二叉樹總共有N-1條邊
*
* 因為度為0的結點沒有孩子,故度為0的結點不產生邊; 度為1的結點只有一個孩子,故每個度為1的結
點* * 產生一條邊; 度為2的結點有2個孩子,故每個度為2的結點產生兩條邊,所以總邊數為:
n1+2*n2
* 故從邊的角度考慮:N-1 = n1 + 2*n2 ②
* 結合① 和 ②得:n0 + n1 + n2 = n1 + 2*n2 - 1
* 即:n0 = n2 + 1
*/
- 若規定根結點的層數為1,具有
n個結點的滿二叉樹的深度為h,節點數與深度的關系為:h=log2(n+1). (ps:關系式是log以2為底,n+1為對數) - 對于具有
n個結點的完全二叉樹,如果按照從上至下從左至右的數組順序對所有結點從0開始編號,則對于序號為i的結點有:
1.若i>0,i位置結點的雙親序號:(i-1)/2;i=0,i為根結點編號,無雙親結點
2.若2i+1<n,左孩子序號:2i+1,2i+1>=n否則無左孩子
3.若2i+2<n,右孩子序號:2i+2,2i+2>=n否則無右孩
在講二叉樹的存儲結構之前,我先為大家簡單的說明下這兩種存儲結構(順序結構、鏈式結構)。
- 順序存儲
順序結構存儲就是使用數組來存儲,一般使用數組只適合表示完全二叉樹,因為不是完全二叉樹會有空間的浪費。而現實中使用中只有堆才會使用數組來存儲。二叉樹順序存儲結構在物理上是一個數組,在邏輯上是一顆二叉樹。

- 鏈式存儲
二叉樹的鏈式存儲結構是指,用鏈表來表示一棵二叉樹,即用鏈來指示元素的邏輯關系。 通常的方法是鏈表中每個結點由三個域組成,數據域和左右指針域,左右指針分別用來給出該結點左孩子和右孩子所在的鏈結點的存儲地址 。鏈式結構又分為二叉鏈和三叉鏈,當前我們學習中一般都是二叉鏈。

代碼展示二叉樹的結構
typedef int BTDataType;
// 二叉鏈
struct BinaryTreeNode
{struct BinTreeNode* left; // 指向當前結點左孩子struct BinTreeNode* right; // 指向當前結點右孩子BTDataType data; // 當前結點值域
}
3. 二叉樹的順序結構及實現
現實中我們通常把堆(一種二叉樹)使用順序結構的數組來存儲,需要注意的是這里的堆和操作系統虛擬進程地址空間中的堆是兩回事,一個是數據結構,一個是操作系統中管理內存的一塊區域分段。
用數組來存儲就避不開一個問題,當你擁有父節點的下標時,你如何快速的找到左右子節點的下標?

這張圖總結的父子節點下標關系,是大家必須要掌握的,因為后邊在順序存儲結構實現階段會頻繁用到
接下來我們將通過堆來繼續學習順序存儲結構
3.1 堆的概念及結構
堆的概念實在是有點晦澀難懂,在這里我斗膽帶大家通過堆的性質和圖片實例簡單的了解一下什么是堆。
堆主要有兩種類型:大根堆和小根堆。
堆的性質:
- 堆中某個節點的值總是不大于或不小于其父節點的值。
- 堆總是一顆完全二叉樹。

根據上面的信息我們可以看出,最大堆的根節點是所有節點的中最大的,小根堆同理。每個節點都比自己的左右子節點要大或者小。希望大家現在可以對“堆”清晰的認識了。
3.2 堆的實現
3.2.1 定義堆的結構體
typedef int HPDataType;typedef struct Heap
{HPDataType* a; //堆是基于數組結構來實現的int size; //數組下標int capacity; //數組容量
}HP;
3.2.2 堆的初始化
//堆的初始化
void HPInit(HP* php) //傳入數組結構的指針
{assert(php);php->a = NULL; //置空php->size = php->capacity = 0; //歸零
}
3.2.3 堆的銷毀
//堆的銷毀
void HPDestroy(HP* php)
{assert(php);free(php->a);php->a = NULL;php->size = php->capacity = 0;
}
3.2.4 數據交換函數
//數據交換
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}
3.2.5 向上調整函數
//向上調整——可以將數組恢復成堆的順序——小根堆
void AdjustUp(HPDataType* a, int child) //傳入數組的地址和新插入的葉節點的下標
{int parent = (child - 1) / 2; //無論是奇偶子節點,均可以通過數組的下標“-1再/2”來獲得父節點的下標//while (parent >= 0) 為了防止數組的越界訪問,我們不采取這個循環條件while (child > 0){if (a[child] < a[parent]) //如果子節點小于父節點{Swap(&a[child], &a[parent]); //使用交換函數,交換父子的數據child = parent; //子節點位置換到父節點上parent = (child - 1) / 2; //然后父節點通過轉換方法重新指向變換后的子節點的父節點 }else{break; //如果子節點大于父節點就不需要調整了}}
}
3.2.6 堆的插入
示例:先插入一個10到數組的尾上,在進行向上調整算法,直到滿足堆。

//堆的插入
void HPPush(HP* php, HPDataType x)
{assert(php); //傳入的堆不能為空if (php->size == php->capacity) //堆的空間如果不足,則進行擴容{int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a, newcapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity = newcapacity;}php->a[php->size] = x; //將數據x插入,數組下標為size的空間中php->size++;AdjustUp(php->a, php->size - 1); //利用向上調整將插入新數據之后的數組恢復為堆
}3.2.7 向下調整算法
現在我們給出一個數組,邏輯上看做一顆完全二叉樹。我們通過從根結點開始的向下調整算法可以把它調整成一個小堆。向下調整算法有一個前提:左右子樹必須是一個堆,才能調整。
int array[] = {27,15,19,18,28,34,65,49,25,37};

//向下調整——可以將數組恢復成堆的順序——小根堆
void AdjustDown(HPDataType* a, int n, int parent) //傳入數組的地址和數組的總大小還有根的下標
{ //傳入根位置的下標是因為需要調整的元素的位置就是根位置// 先假設左孩子小——利用假設法int child = parent * 2 + 1; //第一次先找到根節點下面的子節點while (child < n) // child >= n說明孩子不存在,調整到葉子了{// 找出小的那個孩子if (child + 1 < n && a[child + 1] < a[child]){++child;}if (a[child] < a[parent]) {Swap(&a[child], &a[parent]); //將小的子節點和父節點交換數據parent = child; //父節點位置換到子節點上child = parent * 2 + 1; //然后子節點通過轉換方法重新指向變換后的父節點的子節點 }else{break; //如果最小的節點都大于父節點了,就說明不需要調了}}
}
堆的創建
下面我們給出一個數組,這個數組邏輯上可以看做一顆完全二叉樹,但是還不是一個堆,現在我們通過向下調整算法,把它構建成一個堆。從倒數的第一個非葉子結點的子樹開始調整,一直調整到根結點的樹,就可以調整成堆。
int a[] = {1,5,3,8,7,6};
圖片中的是調整為大根堆,思路是一樣的,代碼只有些許不同

3.2.8 堆的刪除
刪除堆是刪除堆頂的數據,將堆頂的數據跟最后一個數據一換,然后刪除數組最后一個數據,再進行向下調
整算法。

//堆頂的刪除
void HPPop(HP* php)
{assert(php);assert(php->size > 0);Swap(&php->a[0], &php->a[php->size - 1]);//要想刪除堆頂元素,需要先將堆頂元素與數組最后一個元素交換位置php->size--; //這樣可以保持除堆頂以外的元素仍然能保持堆的順序,可以大大提升效率 AdjustDown(php->a, php->size, 0); //利用向下調整將刪除數據之后的數組恢復為堆
}
3.2.9 取堆頂的數據
//取堆頂的數據
HPDataType HPTop(HP* php)
{assert(php);assert(php->size > 0);return php->a[0];
}
3.2.10 堆的判空
//堆的判空
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}
3.2.11 堆的數據個數
//堆的數據個數
int HPSize(HP* php)
{assert(php);return php->size;
}
3.3 建堆的時間復雜度
因為堆是完全二叉樹,而滿二叉樹也是完全二叉樹,此處為了簡化,使用滿二叉樹來證明(時間復雜度本來看的就是近似值,多幾個結點不影響最終結果):


3.4 堆的應用
3.4.1 堆排序
堆排序即利用堆的思想來進行排序,總共分為兩個步驟:
- 建堆
升序:建大堆
降序:建小堆 - 利用堆刪除思想來進行排序
建堆和堆刪除中都用到了向下調整,因此掌握了向下調整,就可以完成堆排序。

//堆排序 0(N*logN)
void HeapSort(int* a, int n)
{for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}
3.4.2 Top-k 問題
TOP-K問題:即求數據結合中前K個最大的元素或者最小的元素,一般情況下數據量都比較大。
比如:專業前10名、世界500強、富豪榜、游戲中前100的活躍玩家等。
對于Top-K問題,能想到的最簡單直接的方式就是排序,但是:如果數據量非常大,排序就不太可取了(可能數據都不能一下子全部加載到內存中)。最佳的方式就是用堆來解決,基本思路如下:
- 用數據集合中前K個元素來建堆
前k個最大的元素,則建小堆
前k個最小的元素,則建大堆 - 用剩余的N-K個元素依次與堆頂元素來比較,不滿足則替換堆頂元素
將剩余N-K個元素依次與堆頂元素比完之后,堆中剩余的K個元素就是所求的前K個最小或者最大的元素。
粗略講解圖

為了方便測試Top-k方法,我們寫一個造數據的函數
//造數據
void CreateNDate()
{// 造數據int n = 100000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (int i = 0; i < n; ++i){int x = (rand() + i) ;fprintf(fin, "%d\n", x);}fclose(fin);
}Top-k方法實現
//Top-k方法
void Topk()
{int k;printf("請輸入k>:");scanf("%d", &k);int* kminheap = (int*)malloc(sizeof(int) * k);if (kminheap == NULL){perror("malloc fail");return;}const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen error");return;}// 讀取文件中前k個數for (int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]);}// 建K個數的小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(kminheap, k, i);}// 讀取剩下的N-K個數int x = 0;while (fscanf(fout, "%d", &x) > 0){if (x > kminheap[0]){kminheap[0] = x;AdjustDown(kminheap, k, 0);}}printf("最大前%d個數:", k);for (int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");
}
4. 二叉樹的鏈式結構及實現
學習二叉樹結構,最簡單的方式就是遍歷。所謂二叉樹遍歷(Traversal)是按照某種特定的規則,依次對二叉樹中的結點進行相應的操作,并且每個結點只操作一次。訪問結點所做的操作依賴于具體的應用問題。 遍歷是二叉樹上最重要的運算之一,也是在二叉樹上進行其它運算的基礎。
按照規則,二叉樹的遍歷有:前序/中序/后序的遞歸結構遍歷:
- 前序遍歷(Preorder Traversal 亦稱先序遍歷)——訪問根結點的操作發生在遍歷其左右子樹之前。
- 中序遍歷(Inorder Traversal)——訪問根結點的操作發生在遍歷其左右子樹之中(間)。
- 后序遍歷(Postorder Traversal)——訪問根結點的操作發生在遍歷其左右子樹之后。
這3種遍歷方式均是深度優先遍歷
由于被訪問的結點必是某子樹的根,所以N(Node)、L(Left subtree)和R(Right subtree)又可解釋為根、根的左子樹和根的右子樹。NLR、LNR和LRN分別又稱為先根遍歷、中根遍歷和后根遍歷。
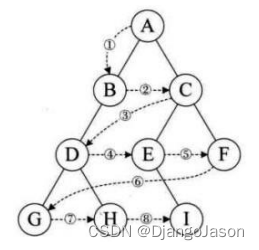
下面主要分析前序遞歸遍歷,中序與后序都是同理,大家可以自行分析。
前序遍歷遞歸圖解


4.1 二叉樹的實現
因為二叉樹的遞歸結構,可能會有些繞,我也盡量能配圖的我就配圖幫助大家理解,在二叉樹中,大家自己的反復畫圖,和邏輯推理也是不能少的,只有足夠的耐心才能掌握二叉樹。
4.1.1 二叉樹的前序遍歷
// 二叉樹前序遍歷
void BinaryTreePrevOrder(BTNode* root)
{//先判空if (root == NULL){return;}//打印根節點printf("%c",root->data);//向下遞歸此根節點的左子樹和右子樹BinaryTreePrevOrder(root->left);BinaryTreePrevOrder(root->right);
}
后面在實現結構的時候我們會經常遇到這段代碼
//先判空if (root == NULL){return;}
它的作用,我大概總結有以下幾點,希望大家能夠牢記
//開頭的判空可以防止空指針的解引用
//遞歸遍歷都需要先判空,因為這是“歸”的條件
//當“遞”到葉子節點的子節點的時候,一定為空,這時候需要return往回歸
4.1.2 二叉樹的中序遍歷
// 二叉樹中序遍歷
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL) {return;}BinaryTreeInOrder(root->left);printf("%c", root->data);BinaryTreeInOrder(root->right);
}

4.1.3 二叉樹的后序遍歷
// 二叉樹后序遍歷
void BinaryTreePostOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreePrevOrder(root->left);BinaryTreePrevOrder(root->right);printf("%c", root->data);
}
4.1.4 根據數組創建二叉樹
// 通過前序遍歷的數組"ABD##E#H##CF##G##"構建二叉樹
//定義一個構造二叉樹函數,將前序遍歷的字符串用節點全部構建出來
//傳入字符串和一個下標變量(此變量需要地址來改變,防止同時傳給左右子樹相同下標導致數組中數據覆蓋)
BTNode* BinaryTreeCreate(char* a, int* pi)
{//首先先判空if (a[*pi] == '#') {(*pi)++;return NULL;}//前序遍歷保存根節點BTNode* root = (BTNode*)malloc(sizeof(BTNode));root->data = a[(*pi)++];//對左右子樹進行遞歸root->left = BinaryTreeCreate(a, pi);root->right = BinaryTreeCreate(a, pi);return root;
}

4.1.5 二叉樹的銷毀
// 二叉樹銷毀 使用后序遍歷的思想從后往前銷毀每一個節點
void BinaryTreeDestory(BTNode* root)
{ //要銷毀二叉樹鏈表就得把鏈表的頭結點的指針的地址傳入if (root == NULL)return;BinaryTreeDestory(root->left);BinaryTreeDestory(root->right);free(root);
}
4.1.6 二叉樹的節點個數
// 二叉樹節點個數
int BinaryTreeSize(BTNode* root)
{return root == NULL ? 0 : BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
} //子樹節點個數等于左右節點個數+根節點(1)個數
4.1.7 二叉樹葉子節點個數
//二叉樹葉子節點個數
int BinaryTreeLeafSize(BTNode* root)
{//先判空if (root == NULL){return 0;}//如果左右子節點都為空就是葉子結點,則返回1.if (root->left == NULL && root->right == NULL){return 1;}return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
} //通過+運算和return可以達到統計的功能
4.1.8 二叉樹第k層節點個數
// 二叉樹第k層節點個數
int BinaryTreeLevelKSize(BTNode* root, int k)
{ //參數部分的k沒有傳地址,是因為需要左右子樹記錄向下遞的層數相同。if (root == NULL){return 0;}//k--,減到1的時候就是第k層了,返回1if (k == 1){return 1;}return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1);
} //通過+運算和return對k層節點數進行統計并返回頂層 //每次遞下去,對k-1,可以達到對應層k為1的效果
4.1.9 二叉樹查找值為x的節點
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{//用前序遍歷思想進行比較,找到就返回地址if (root == NULL){return NULL;}//進行比較,判斷此節點是否為x,不是就向下遞歸if (root->data == x){return root;}//遞歸函數將歸回來的結果傳給變量進行判斷,這樣才能將結果遞歸回去。BTNode* ret1 = BinaryTreeFind(root->left, x);if (ret1) //if的結果只有可能是NULL和值為x的節點指針root{return ret1;}BTNode* ret2 = BinaryTreeFind(root->right, x);if (ret2){return ret2;}//如果下邊都沒有那就向上返回NULL,找到了就返回節點地址return NULL;
}

層序遍歷
層序遍歷:除了先序遍歷、中序遍歷、后序遍歷外,還可以對二叉樹進行層序遍歷。設二叉樹的根結點所在層數為1,層序遍歷就是從所在二叉樹的根結點出發,首先訪問第一層的樹根結點,然后從左到右訪問第2層上的結點,接著是第三層的結點,以此類推,自上而下,自左至右逐層訪問樹的結點的過程就是層序遍歷。
在實現層序遍歷的時候我們需要用到隊列結構,如果有對隊列結構還不熟悉的同學,可以先點擊鏈接跳轉,學習過后再來看,可能也會有更多的收貨。
4.1.10 層序遍歷
//層序遍歷
//層序遍歷不像二叉樹一樣遞歸遍歷,而是用隊列結構通過循環先進先出進行遍歷
//運用上一層根節點出帶動下一層子節點入
void BinaryTreeLevelOrder(BTNode* root)
{Queue Q;QueueInit(&Q); //先初始化隊列結構,實現先進先出的功能,進行一個層序遍歷if (root) //根不為空的時候,就入對列開始遍歷 { //如果為空,直接跳到函數的最后銷毀QueuePush(&Q, root);}while(!QueueEmpty(&Q)) //隊列不為空就一直循環{BTNode* front = QueueFront(&Q);//需要創建一個指針,指向隊頂的元素,防止Pop出隊頂元素,找不到其子節點QueuePop(&Q); //排出上一層的子節點printf("%c", front->data);//并打印if (front->left) //帶入下一層的節點(只要不為空){QueuePush(&Q, front->left);}if (front->right){QueuePush(&Q, front->right);}}QueueDestroy(&Q);
}
4.1.11 判斷二叉樹是否是完全二叉樹
// 判斷二叉樹是否是完全二叉樹
//當所有非空節點都出隊列的時候,判定隊列是否為空,即可判斷其是否為完全二叉樹
bool BinaryTreeComplete(BTNode* root)
{Queue Q;QueueInit(&Q); //先初始化隊列結構,實現先進先出的功能,進行一個層序遍歷if (root) //根不為空的時候,就入對列開始遍歷 { //如果為空,直接跳到函數的最后銷毀,并返回falseQueuePush(&Q, root);}while (!QueueEmpty(&Q)) //隊列不為空就一直循環{BTNode* front = QueueFront(&Q);//需要創建一個指針,指向隊頂的元素,防止Pop出隊頂元素,找不到其子節點QueuePop(&Q); //排出上一層的子節點//空節點也入隊列,所以需要if語句來判斷何時結束循環if (front == NULL)//如果前面的非空節點都Pop掉了,后面就應該全部是空節點了{ break; //所以break跳出循環,進入下一個循環來判斷}//帶入下一層的節點QueuePush(&Q, front->left);QueuePush(&Q, front->right);}while (!QueueEmpty(&Q)){BTNode* front = QueueFront(&Q);QueuePop(&Q);//如果進入了if語句,就說明此節點為非空節點,也就證明了此二叉樹不是完全二叉樹if (front){QueueDestroy(&Q);return false;}}//如果隊列剩下的節點均為空節點,就可以銷毀隊列,并返回true了QueueDestroy(&Q);return true;
}












)






