背景
B站作為國內領先的內容分享平臺,其核心功能之一便是支持UP主們創作并分享各類視頻內容。UP主稿件系統作為B站內容生產的關鍵環節,承擔著從內容創作到發布的全過程管理。為了滿足不同創作者的需求,B站提供了多種投稿渠道,包括移動端的粉大加號、必剪APP,以及Web端和PC端的上傳方式,確保創作者可以隨時隨地上傳自己的作品。同時,B站的內容來源多樣化,既有用戶生成內容(UGC),也有專業生成內容(PGC),以及商業合作稿件等。這些內容通過分區品類、話題和標簽等多維度進行分類,以滿足不同用戶的興趣和需求。這就要求B站必須具備一套高效、穩定的稿件生產系統,以確保內容的順利上傳、處理和分發。
隨著業務的快速發展,技術團隊面臨著組織變革、業務需求快速迭代以及系統劣化的挑戰。在此過程中,技術債務逐漸累積。技術債務主要源于為了迅速適應市場變化而采取的臨時解決方案,或者是已經過時的歷史技術架構,這些問題若不及時解決,將會導致系統維護難度加大、系統復雜性提升和性能下降,進而影響用戶體驗和業務的持續發展。
作為負責稿件生產鏈路的業務團隊,我們致力于優化系統服務,提高系統的穩定性和可用性。我們通過持續的技術改進和創新,努力減少技術債務,確保B站的稿件生產系統能夠穩定、高效地服務于廣大UP主和用戶,支持B站內容生態的繁榮發展。本文會介紹下B站稿件生產的服務架構,并從系統可觀測性和服務高可用優化兩個角度分享技術實踐上的經驗和思考。
問題和挑戰
歷史債之重
B站于2009年6月26日創建,B站的第一個稿件( https://www.bilibili.com/video/av2/)也是2009年6月26日創建提交的,稿件技術服務從09年以來已經有15年,歷經多輪負責人的變更和多次技術架構迭代,演變為了如今較為復雜的微服務體系。如果將鏈路上所有模塊系統統計在內,代碼行數達到百萬行規模。得益于業務的增速,稿件數量增長也非常快,在近兩年多內增長了幾倍,各類數據總和有千億級別,分布在多個存儲系統。
歷史債只要迭代就會存在,甚至代碼本身不迭代,外部環境組件隨著時間前進,性能劣化也會產生技術債務需要治理。需要直面的現實是,很多技術優化都是線上問題驅動型,通過問題暴露“水面下的風險”。
Out of Maintance:老舊的組件/平臺/SDK已經不適用不維護不迭代,需要做遷移/重構/重新選型
No Owner:維護人員離職或者轉崗,導致老舊的業務邏輯無人認領熟悉,維護成本極高;No Owner + Out of Maintance的服務,需要更新組件版本更迭接口版本時,往往會遇到較大阻力
Dirty Code:代碼本身在歷次迭代重構中“妥協”或者不充分的技術設計,導致的dirty code甚至dirty data
?業務之重要
稿件生產在公司業務的定位,創作業務入口?+?中臺能力支持。
承接:粉版、Web、必剪、H5、OGV、課堂、開放平臺、直播、地方電視臺、動態、商業化等10多個業務方,技術穩定性意味著業務穩定性,投稿不可用、轉碼開放延遲、稿件數據同步失敗導致不可觀看,都會引起極大的社區輿情、客訴反饋、商業化行為的損失。
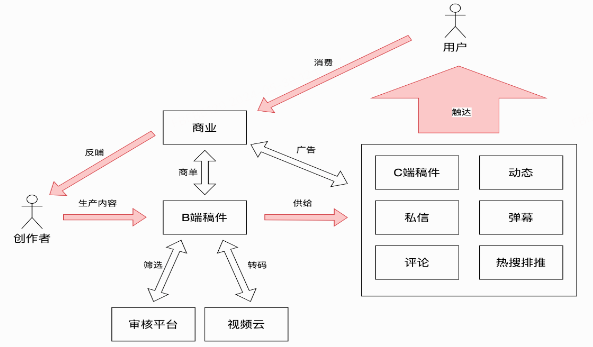
鏈路之復雜
整個稿件生產從投稿到開放鏈路涉及環節眾多,分四個大步驟:創作工具(剪輯/直傳)、發布上傳、稿件生產、數據開放。下圖是一張簡化版的端到端流程圖。
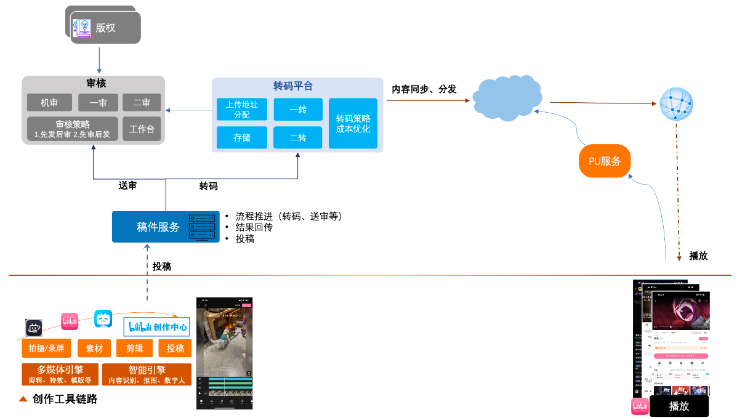
涉及到的業務/團隊有:
-
工具客戶端、H5&Web端
-
稿件服務/內容生產系統
-
審核
-
AI工程與模型
-
轉碼調度/計算/存儲
-
CDN,稿件媒體元信息刷新
-
C端服務
-
...
這些鏈路上一些核心依賴的不可用就會導致稿件生產阻塞,進而影響稿件開放的時長,比如假設:
-
生產工具App核心場景打開持續crash或白屏,將在生產源頭阻塞用戶,無法產生投稿行為
-
原片上傳有問題,將阻塞視頻上傳,導致用戶投稿失敗
-
生產系統有問題,將無法驅動業務調度開展工作流,影響稿件開放時間
-
審核系統有問題,將在待審通道阻塞堆積大量稿件對象,影響稿件開放時間
-
轉碼系統有問題,將在轉碼隊列中阻塞堆積大量視頻對象,影響稿件開放時間
-
CDN刷新視頻元數據有問題,將導致稿件狀態已更新為開放但是視頻無法觀看,引起UP主和用戶的客訴輿情
-
...
以上這些Case都會直接影響稿件生產的業務北極星指標,直接引起客訴,更甚會引發大規模輿情。簡單的數學公式:SLA(Biz)?= SLA(Core System1)?* SLA(Core System2)?* SLA(Core System3)?* SLA(Core System4)?* ...,因此整個鏈路上的強依賴模塊都需要做到高可用。
系統架構介紹
先介紹一些技術名詞解釋和概念,后續再介紹系統架構時可以更方便理解。
名詞解釋
| archive | 稿件 |
| video | 視頻,一個稿件可以有多個視頻,一個視頻內部成為1P |
| aid | 內部系統流轉的稿件ID |
| bvid | 用戶可見的稿件ID |
| cid | 視頻ID |
| mid | 用戶ID |
| filename | 用戶上傳媒體文件唯一編號 |
| upfrom | 投稿渠道,業務來源標識 |
| UGC | 指用戶生產內容 |
| PGC | 指專業團隊/機構生產內容 |
| 原片 | 原始上傳的數字媒體 |
| preupload | 原片上傳行為的代稱,實際的上傳行為更復雜,會有多種策略決定上傳的Endpoint |
| upos | 原片上傳后的媒資文件存儲服務 |
| DAG | Directed?Acyclic?Graph,有向無環圖,本文代指生產系統的流程圖 |
| 轉碼 | 將原片進行編碼格式轉換,為了優化內容存儲和傳輸效率,提高廣泛用戶群體的播放兼容體驗,會有多路清晰度轉碼的環節 |
| 審核 | 對數字媒體內容進行審核,視生產渠道和稿件類型不同,審核環節也會有差異 |
| 多P稿件 | 包含多個視頻的稿件,多P稿件生產流程比一般稿件復雜,需要等待所有P的視頻內容完成審核與轉碼后才能開放 |
| 合集 | 多個稿件組成的集合 |
一個稿件包含的元素
稿件是一個容器,呈現給用戶的包括:視頻,圖文信息,互動信息等;幕后支撐系統運轉的包括:狀態,流量管控,多媒體相關信息等。
圍繞著稿件大體上分為3類角色:UP、審核和用戶,這三類角色通過各種各樣的系統作用于稿件這個核心實體,并在各種行為中不斷豐富稿件這個核心實體。
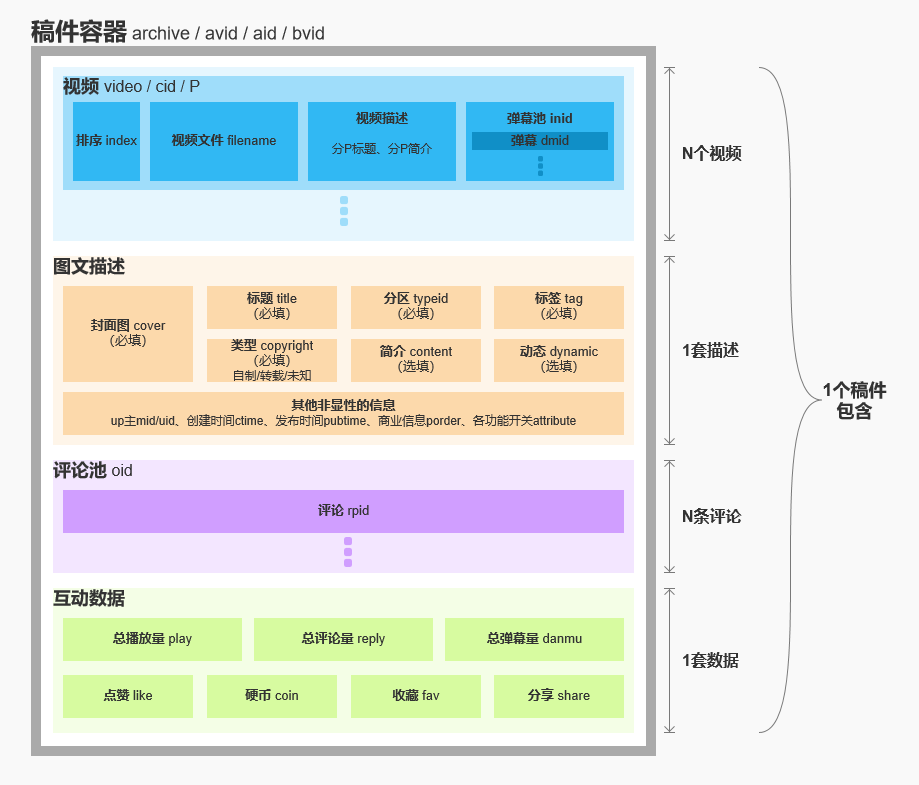
業務架構概覽
在這條復雜的業務路徑中,多個團隊在其中各司其職來確保稿件生產端到端的鏈路穩定性和系統的高可用。將上文介紹復雜性舉例的業務流程圖進行技術模塊的逐層拆解,得到了如下這張架構分層圖。圖中只是簡述了一些關鍵的服務模塊,涉及到的微服務和模塊太多,無法全部羅列在內。

分層解釋:
1.前臺,除了列舉的常規業務入口之外,還包括了內部投稿渠道、運營審核人員使用的后臺,一般會針對渠道進行網關入口隔離(服務部署級別 / 代碼接口級別)。
2.網關,內部稱之為BFF(Backend For Frontend),Client端的接入面,業務CRUD邏輯編排層,包含投稿視頻上傳、投稿接口、稿件列表、稿件編輯,是稿件產生的業務入口,更上游是創作工具(粉/必剪)和其他的投稿業務渠道(商單/OGV/直播/開放平臺...)。
前臺應用到網關之間的流量路徑:Client -> WebCDN -> LB(四層/七層)-> API Gateway -> BFF,在源站SLB上有WAF,APIGW層有內嵌Gaia風控組件,做到統一轉發/風控/限流/降級控制面。
3.業務應用,業務邏輯層Service,微服務部署形式,提供業務功能實現的標準接口;按照生產與消費職能可以分為B端業務域服務和C端業務域服務
外部服務依賴如稿件綁定tag/綁定topic/審核過機審模型等;通用域是基礎服務,承擔了全公司服務的流量調用,如賬號/鑒權等。
4.內容生產平臺,是一個基于DAG實現的調度系統,可以根據不同業務配置的執行調度作業串聯起原子方法進行內容生產流程,支持業務注冊接入并制定生產鏈路流程,審核系統、轉碼系統、版權系統、AI工程等作為能力方,暴露接口被DAG執行調度,節點之間通過同異步方式進行狀態更迭通知與回調,確保節點狀態更迭有序。
稿件系統基于CQRS職責拆分,B端稿件在生產側完成后,內容生產服務會回調稿件服務的原子方法做開放通知Notify,通過Domain Message通知C端稿件服務,更新數據落庫。C端稿件服務上游是稿件消費應用服務和網關,如搜索、推薦、空間、動態、收藏夾等等。
5.元數據存儲,業務模塊都有各自的數據實體對象,如稿件實體、視頻實體等,這些元數據(包括媒資文件)存儲在多個不同的存儲介質中,有傳統的關系型數據庫,也有KV存儲和分布式存儲系統。
生產系統 - 基于DAG的內容加工平臺
內容生產系統支持多業務場景注冊、實現原子能力節點、自定義調度路徑,具備基本的同異步調度、重試降級、failure callback、事件上報觀測等能力,擁有面向研發人員的控制面,具備平臺化能力與職責。
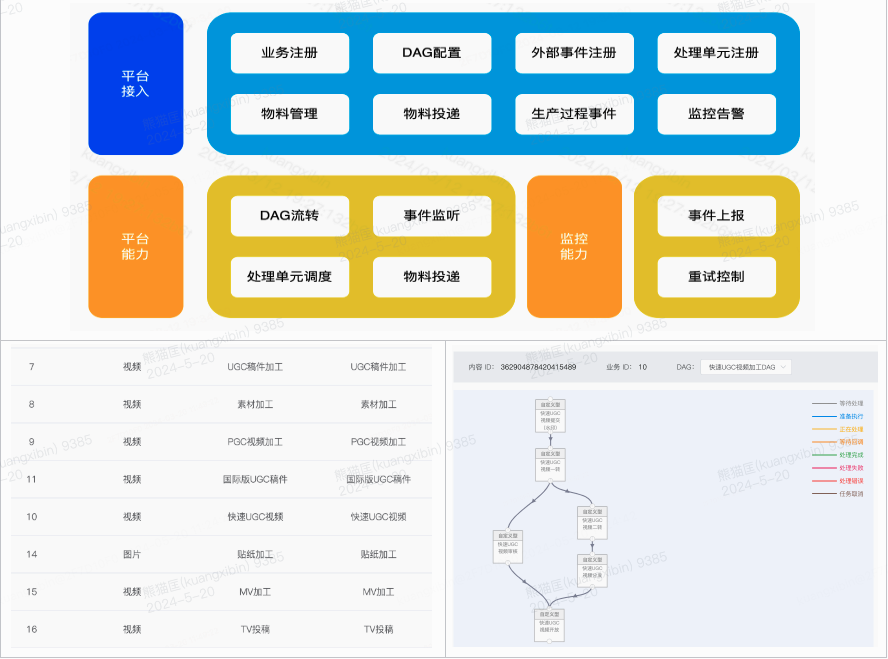
模塊構成上,主要分為DAG管理,DAG調度服務(調度和指派),DAG狀態服務,DAG監聽服務和執行器。
-
DAG管理?,管理DAG和處理單元(創建,編輯,配置)
-
DAG調度服務,分為調度和指派,調度是服務內部自動觸發(資源變化和處理單元執行完成),指派是外部內容管理指定處理單元執行
-
DAG狀態服務,主要是提供查詢,更新和刪除處理單元狀態
-
DAG監聽服務,利用Databus(一個基礎組件,消息隊列的封裝)提供調度消息的緩存
-
執行器,具體執行處理單元,設置隊列提供處理單元的入列出列操作,保障處理單元的有序操作
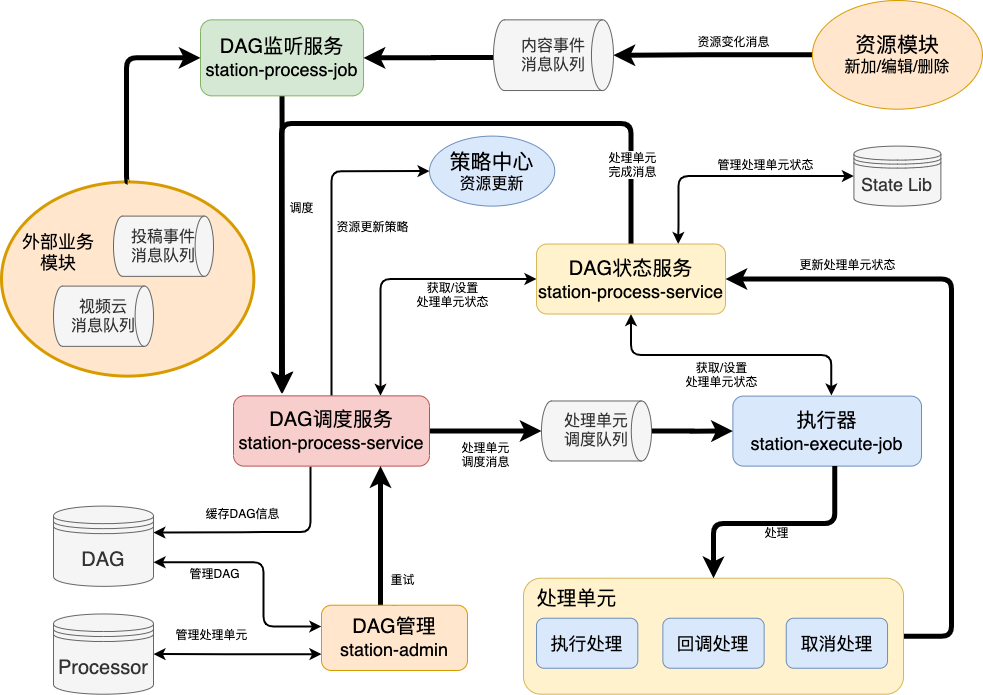
以稿件為例介紹業務是如何在內容生產系統中被執行的。
左側B端稿件生產部分,從端側上傳原片進入服務端邏輯開始,生產系統調度過程中的審核域、流媒體域、版權域、AI模型域等不同系統模塊,系統內部通過消息隊列分發任務并等待任務完成的Callback Notify,進而轉入下一層工作節點。有些節點雖然是并行調度,但是需要歸并等待完成后才能進入下個節點,比如需要完成稿件、視頻審核和視頻的轉碼任務,才能進入開放節點。人群畫像分類、轉碼效率優化、流程調度并行化、提升機審覆蓋率、資源潮汐調度等等都是全局上可以使用幫助提效的技術手段。
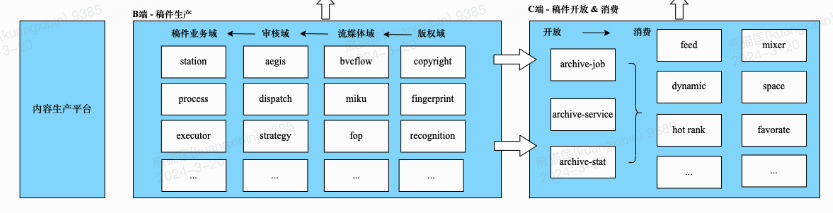
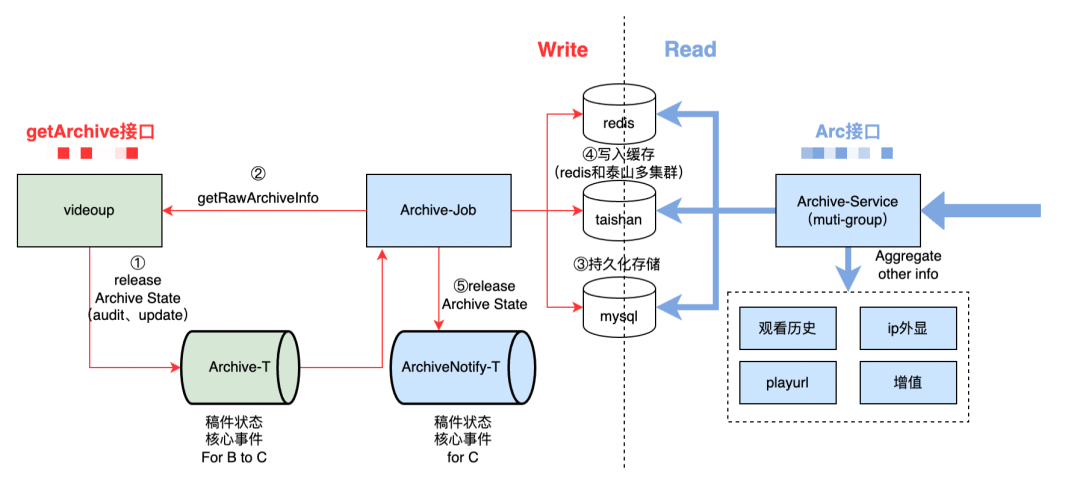
進入開放節點后,右側B->C的指向部分,體現的是稿件生產到開放的CQRS架構實現。CQRS拆分是稿件業務系統在多年前進行的操作,B端范疇的“稿件生產鏈路”,生產完成后基于領域事件消息驅動同步數據到C端稿件服務,由B到C的數據同步機制是經過CQRS思想架構拆分設計而成。技術架構依據組織架構邊界,BC稿件也是兩個團隊在負責的。為了確保數據最終一致性,數據同步消費者有重試措施,并有數據同步對賬腳本進行對比監控。
可觀測性
系統想要高可用,先要了解當前的可用性是什么狀態,期望優化目標是什么,這些都是客觀事實的技術指標來體現,這樣技術優化才能有的放矢。
如果把稿件生產整體視為一個”大黑盒“,首先需要確定這個系統運行的指標是什么,例如:
-
從input/output視角:流入(上傳多少稿件)、流出(開放多少稿件)、吞吐效率(上傳到開放的時延)
-
從端的視角:上傳成功率、接口可用性、接口QPS、RT
接著將這個”大黑盒“拆解,分拆到不同環節模塊下核心的服務、模塊之間的協議、服務之間的數據流轉鏈路,以上這個過程可以不斷迭代演進,可觀測性建設就是幫助感知到系統的運行狀態,構建排查工具協助快速定位問題,更進一步能夠做到業務異動分析。在對一個復雜系統進行拆解優化前,我們需要了解現狀感知異常,因此可觀測性比上來就做優化和重構優先級更高更有價值,這一章節會花一些筆墨來介紹下我們逐步建設的思路。
業務北極星指標
低頭趕路找不到方向的時候,抬頭看看北極星。
稿件生產的北極星指標是“首次開放耗時M90/M95/M99”,稿件可以多次編輯/打回重新提交進入生產流程,因此業務首先關注首次開放耗時。這是一個偏創作體驗的指標,影響這個指標的客觀因素有:原片時長、是否HDR、是否4K、長短視頻占比、轉碼資源潮汐調度、人審耗時波動、黑灰產投稿量等。
這個指標的計算邏輯不復雜,統計每一天所有稿件T = (開放時間 - 投稿時間)的均值分位數,不過需要剔除一些如定時投稿的特殊業務場景。大數據平臺每日任務處理,BI看板體現數據。
其他一些會關注的業務指標有:
-
供給規模:日投稿量、日視頻數、日投稿DAU等
-
創作者規模:新/老/留人群指標、粉絲躍遷等
-
有效消費指標:X日內有效觀看>=Y的稿件數、有效VV數等
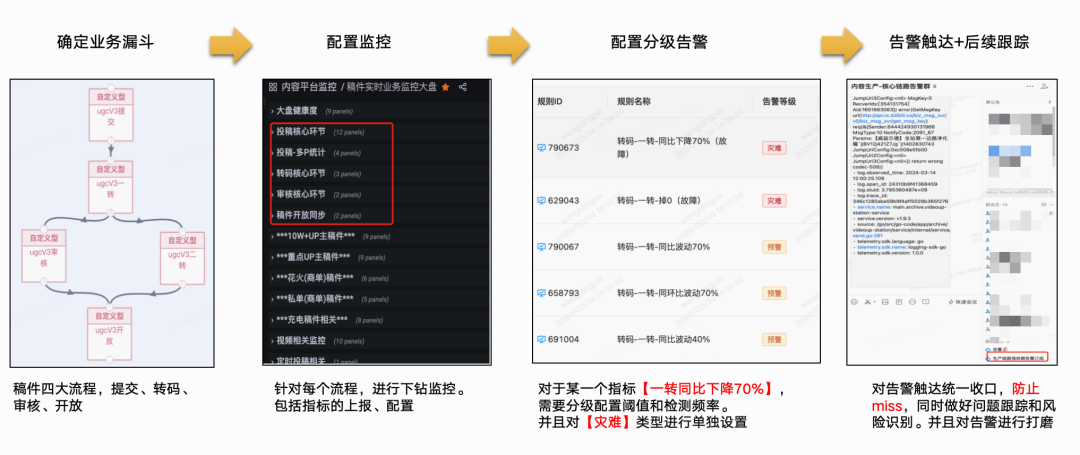
技術系統大盤與監控
業務北極星指標是T+1的,技術服務系統更關注實時的運行狀態,先要知道負責的服務有無系統性風險,了解線上運行健康度,感知異常快速解決問題。
技術系統一般借助Log + Metrics + OpenTelemetry等手段建設系統觀測體系,這三者的數據是以時序為基礎、互為補充信息的參考系。
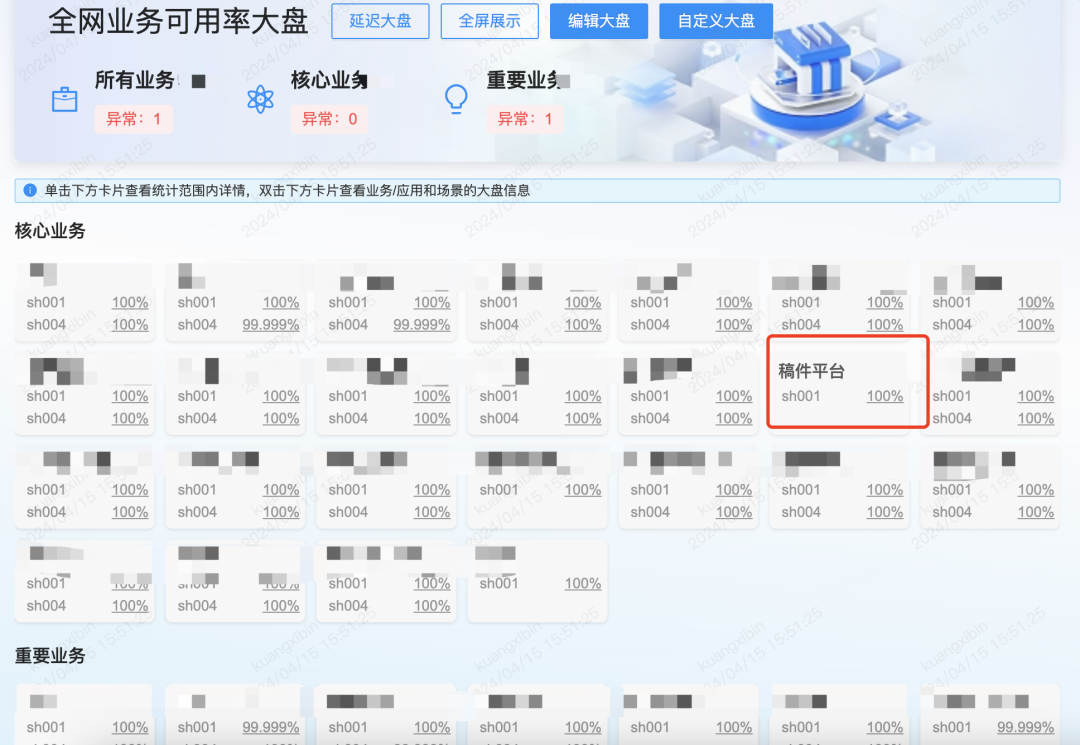
稿件生產鏈路目前已經整體覆蓋【投稿】->【投稿-多P】->【轉碼】->【審核】->【開放】,做到了All Metrics In OnePage,方便一頁可以總覽各個環節的關鍵曲線變化。
技術關鍵指標基本都被囊括在了OnePage中,eg:
-
大盤量的走勢:稿件量、視頻量、創作者PV、創作者UV...
-
錯誤量趨勢:客戶端錯誤量、投稿核心接口錯誤率...
-
成功率趨勢:整體/分渠道/分端投稿成功率、投稿QPS、送審成功數、轉碼完成數、稿件同步開放數...
-
容量大盤:DB、Cache等組件的容量水位線...
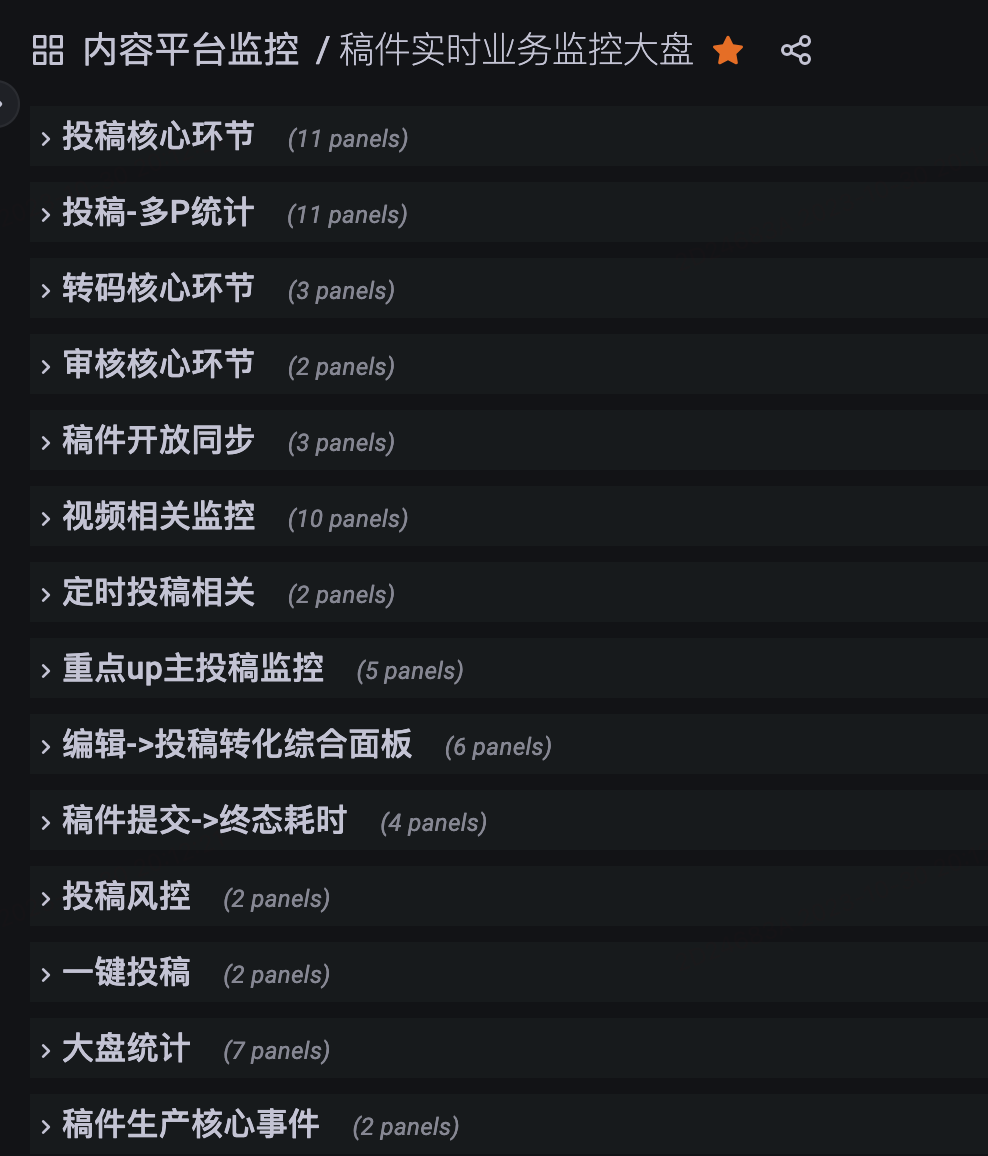
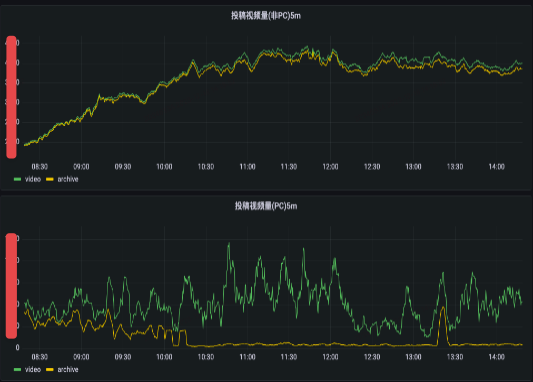
故障召回,1-5-10
研發只要經常觀察監控曲線、日志錯誤數曲線,自然會得到一些經驗值來輔助判斷當前系統的運行情況。不過線上監控抖動也不一定意味著系統發生了故障,我們肯定希望對于系統故障是“高召準”的,因此需要基于已有的、通過不同渠道上報的旁路數據,通過經驗值來制定分層告警規則,并逐步對告警噪音降噪,找到比較合適的配置標準。現有多種故障召回渠道,包括:核心服務SLO下跌召回、監控告警召回、客訴反饋召回等,基本上一個線上問題產生,會按照時序依次在不同渠道體現(研發發現告警、SLO下跌,跟著用戶有感客訴進線)。
我們期望比用戶更早發現與定位問題,做到1-5-10是一個目標。當然實際操作下來也是有一些難度,有很多干擾因素導致無法達成1-5-10,比如第一分鐘的異常發現延遲RT,應盡可能地小,從采集頻率、計算頻率、告警聚合、異常投遞觸達,都可以做優化。假如一些指標的采集窗口就在30s了,置信的告警需要觀察N個窗口的走勢,那么一般都會超過1min。5min定位問題和10min恢復,需要響應夠快(1min感知是第一步)?+?經驗能力(業務熟悉程度、SRE能力、快速止預案、臨場應急指揮調度能力等)?+?平臺工具好用(輔助觀察類Trace/Log/Metrics、快速止損類APIGW、容量轉發/降級/兜底等)?+?運氣成分(比如是否是半夜,懵逼情況下大家狀態都不好)...
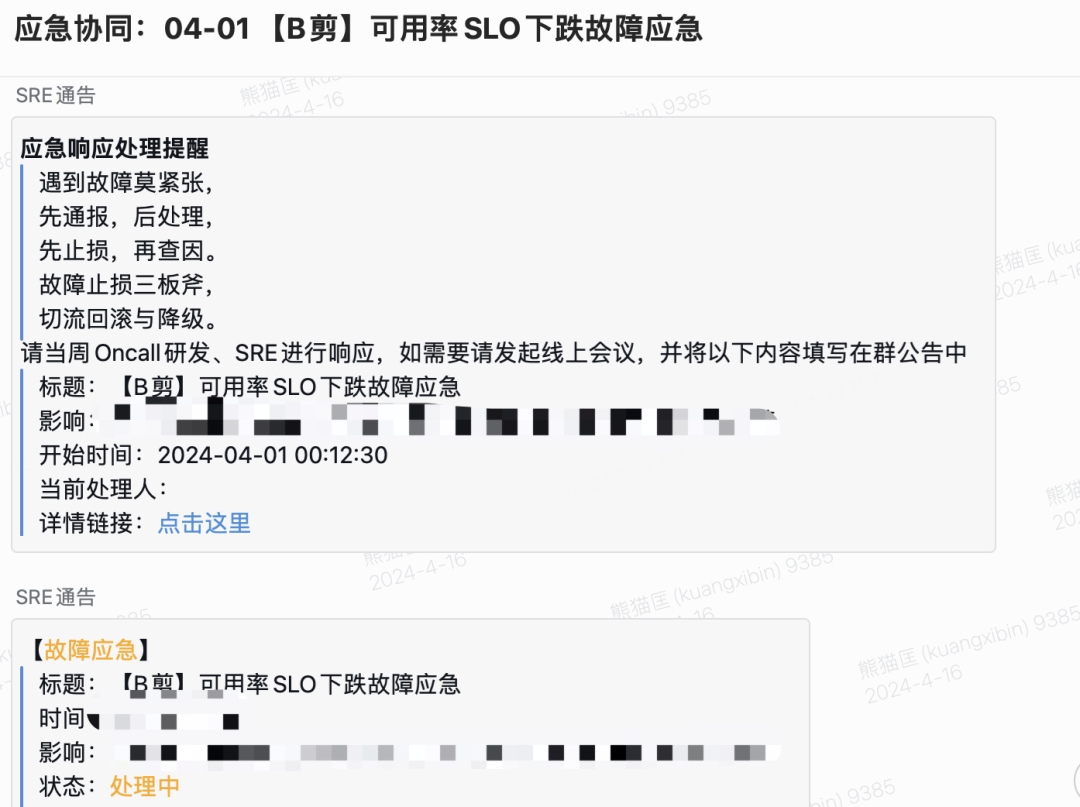
我們借助SLO大盤工具構建了核心業務場景,服務SLO下跌到一定閾值會有SRE Bot自動拉群觸達;同時我們自己設置了多種檔位的告警方式,包括企微Bot、短信、電話告警,根據核心與否和緊急程度逐級上升,業務告警規則List統一訂閱到固定的告警組,規則已覆蓋50+核心子場景,半年內通過這套機制主動發現Case 10+,早發現早解決,將Case升級成為事故的可能性扼殺在搖籃中。
生產效率指標
有了業務大盤北極星指標,服務系統線上運行狀態也可以做到監控了,下一步做什么呢?
如果將整個生產系統想象成一個內容供應鏈,已知每日的供應“貨物”總數,每個“貨物”又有大小輕重之分,大盤指標太籠統,下鉆到供應鏈的子環節看下每個子環節的效率如何,是一個很自然的思考。
在服務系統穩定運行的前提下,我們開始下鉆生產效率指標,首先需要將大盤指標轉化為歸一化的單位指標:
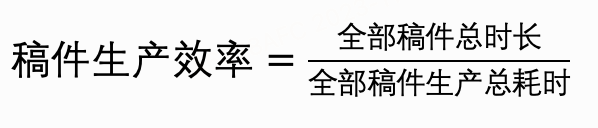
這個公式可以理解為:每一秒可以生產X秒的視頻內容,我們希望通過各種技術手段優化這個效率越高越好(但是會有體驗上的權衡),直至前資源能做到的邊際效應邊界。將以上公式做環節拆解(注意:下述公式最新有一些UPDATE,因為轉碼階段做了優化轉碼措施,不再是串行加法關系,這里可以略加參考):

通過歸一化公式可以統計每天的均值效率指標,再拆分到每個環節的均值效率,輔助判斷每日的效率趨勢,發現一些潛在問題,比如系統資源調度是否存在空轉的問題進而導致效率降低。根據投稿分區、分端、UP主粉絲數圈層、稿件短中長視頻、風險賬戶/高優UP等不同的參數進行數據聚類,再套用以上公式計算效率均值也是常用的觀察業務異動的手段,eg:
-
Video Duration < X min 短視頻的生產效率 VS Video Duration >= Xmin 中長視頻的生產效率
-
風險賬戶投稿效率均值 VS 大盤效率(風險賬戶的效率如果跑贏大盤的效率,那么說明前置風險識別和資源分配的策略上有一些問題)
-
特殊稿件效率 VS 大盤效率
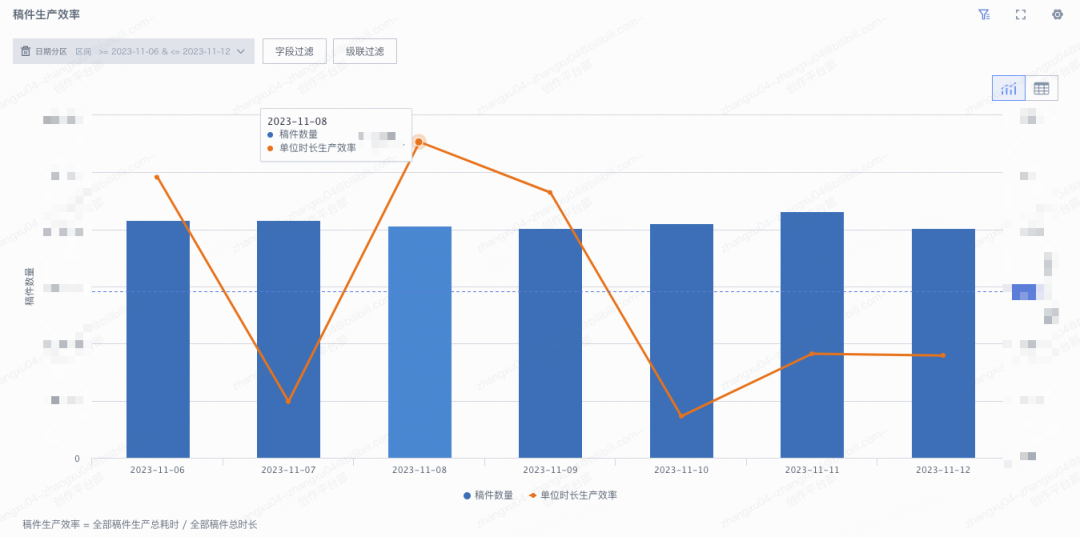
業務全鏈路Trace
以上幾項措施,從北極星到大盤監控再到大盤數據下鉆,是拿已經發生過的數據“以果推因”,我們還需要能夠有一些別的手段,可以在這個“因”發生初期就感知到,串聯起所有主要環節,精確到每一個Case的個例數據。為什么需要如此呢,考慮以下幾個線上實際發生過的案例:
-
就算接口可用性達到了99.99%,損失的0.01%對誰的業務行為會有損,我們能定位到目標群體嗎?
-
To?B型業務就算只有一次失敗,如果是【政務號】、【重要商單】、【S級活動演出】遇到了投稿上傳失敗,那么影響也是很大的
-
UGC創作業務復雜度不斷提升,有一些失敗行為發生在端上有一些則是在服務端,端到端的日常問題排查、用戶行為回溯該怎么做?
一般的排查姿勢是讓用戶在客戶端嘗試復現路徑,然后點擊本地日志上報?+?多個業務服務觀察從SLB到Service的一連串日志和trace去定位原因,這個方式可以work但是不夠高效,有些偶發性問題也不一定能夠再復現,持續追查的資源投入比較高。
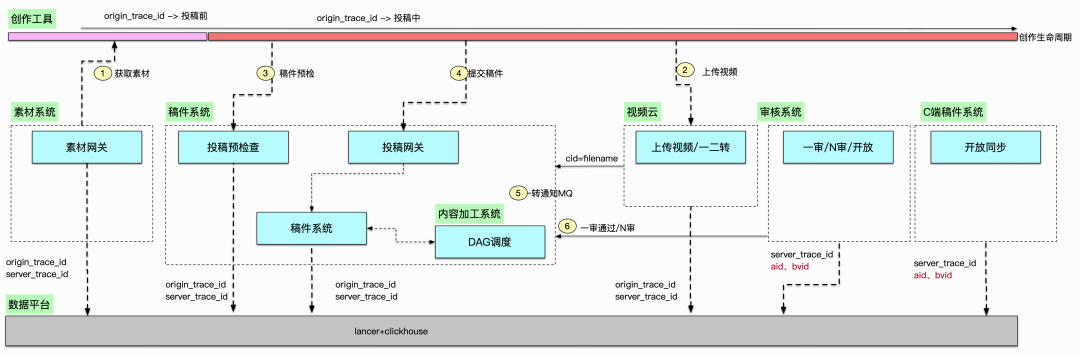
因此我們聯合客戶端和其他相關團隊引入了業務全鏈路Trace能力,通過定義創作業務關鍵事件鏈路,并聚合串聯客戶端埋點,業務服務端 context trace傳遞,實現用戶視角的全鏈路事件Trace。全鏈路Trace通過定義關鍵事件行為,做到端到端可串聯、定義盡可能詳細、跨多個業務團隊、上報盡可能實時、排查工具盡可能直觀。大致技術方案描述:
-
端到端的全鏈路業務追蹤,客戶端生成?origin_trace_id,和服務端trace_id打通(將客戶端行為事件鏈接起來)
-
服務端復用?Open?Trace?協議(框架層面已有能力),將客戶端的?origin_trace_id?與?服務端的trace_id做映射上報
-
服務端的每個業務系統,通過lancer獨立上報(如果上下游有origin_trace_id,就建立與服務端trace_id關系)到數據平臺
-
建立準實時flink任務,通過查詢數據平臺ck,展現trace-tree
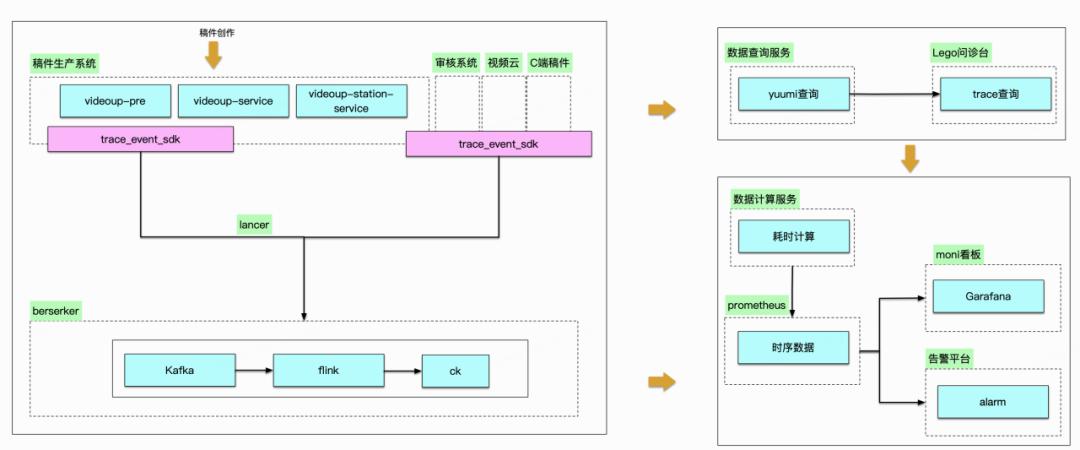
跨多個業務團隊:拆分上報鏈路
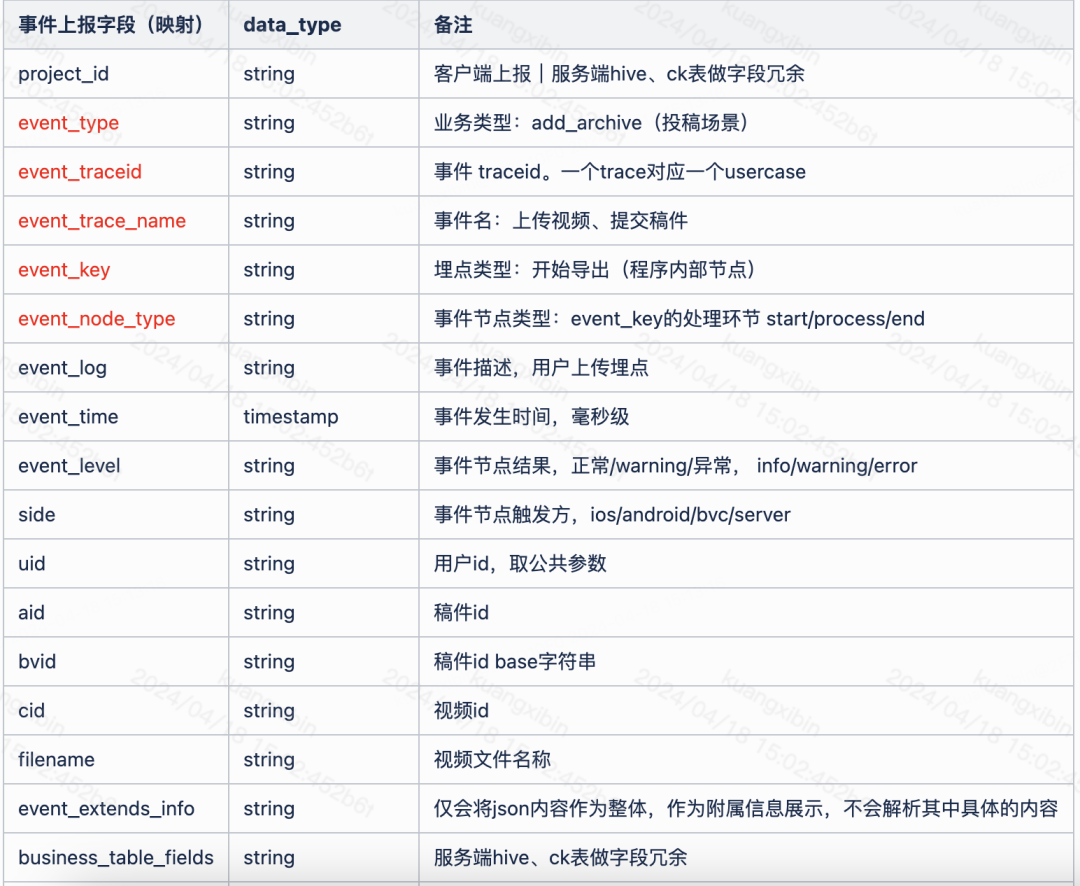
事件盡可能詳細語義通用:約定事件協議
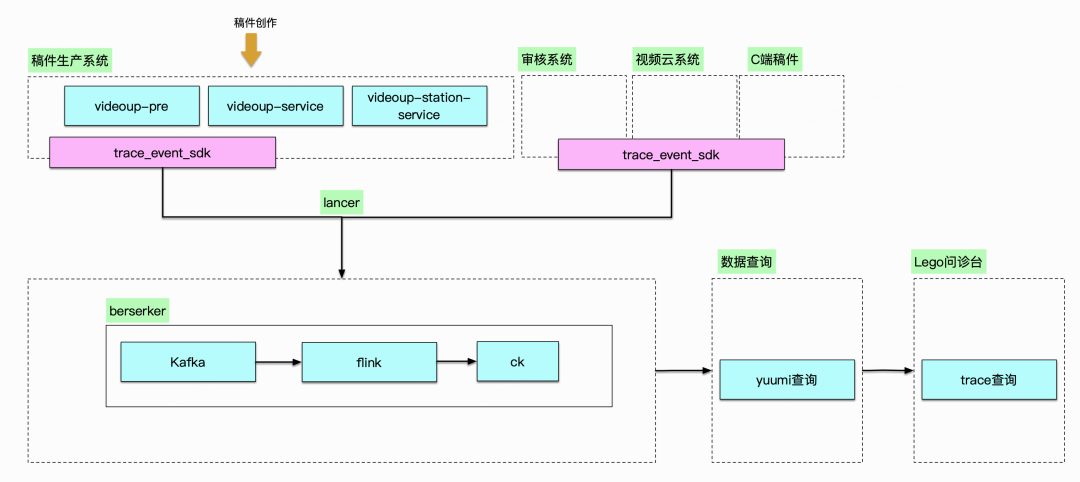
盡可能實時:數據實時入倉流程
工具直觀展示:Lego后臺工具自助搭建
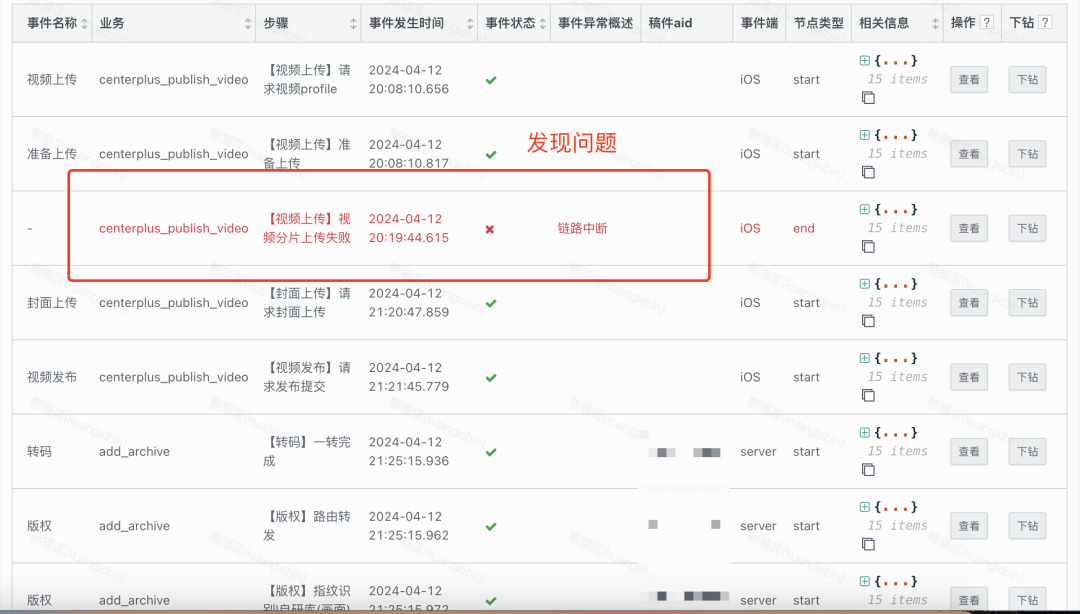
這個工具的好處是,正向的用戶反饋點查(已知用戶id、稿件id)可以快速定位整條鏈路,反向的根據已有上報事件數據,可以主動下鉆排查,讓隱藏在技術指標之下的具體個例可以被感知:
-
pending在某個事件狀態的稿件集合,delay了多久
-
在關鍵事件節點fail的個例可篩查,發現水面下的個例問題,幫助排查代碼中的邊緣bug
-
關鍵事件耗時可視化,排序后可以知道每天耗時較多TOP?N稿件是哪些等等
當前已經做到:
-
基于端到端的數據通道,落地業務全鏈路Trace工具,具備分析全鏈路問題的工具
-
可以下鉆到技術層Trace查看調用,通道可以攜帶非常多的輔助數據,供技術排障使用
-
數據已經覆蓋端上、投稿、視頻上傳、審核、版權、開放,40+?事件定義?日2kw+事件上報
-
通過反向篩查每日輸出報表,發現邊界Case?N例并fix
小結
本節大致將技術和業務兩個視角下的“可觀測性”建設過程介紹了下,在使用觀測系統的過程中,研發日常可以感知到系統的異常狀態,發現了諸如合集異常、延遲稿件開發異常、稿件管理列表頁偶發超時等業務Case;在技術改造是否值得投入執行需要決策時,也是結合了系統的當前指標來決定我們應該從哪些方向去進行優化和重構。下一個章節以幾個案例介紹服務高可用的建設。
高可用建設,負重前行
在一個已經存在了15年的服務系統中,歷史債務一定是比較重的,要面對的不僅是代碼質量劣化本身,還有諸如技術組件老化、技術選型過時、數據協議濫用、維護心智負擔重、迭代效率低等多方面的問題。我們需要在治理債務的同時還需要保障好這個核心業務的穩定性不受損失,做到“邊開飛機邊換引擎”。
存儲優化
稿件服務中使用了多種存儲來應對不同業務場景下的需求,在業務快速發展過程中,我們需要對現有的存儲系統進行全面的風險評估和容量規劃,制定合理的擴容計劃和備份策略,確保存儲系統的穩定性和可靠性。過去的一年多面對線上暴露出來的問題,我們決定先從存儲切入,包括MySQL、TiDB、ES、泰山KV多個存儲組件,涉及到稿件分庫、ES索引分片拆分、TiDB IO尖刺優化、MySQL磁盤容量問題等技改項目。同時系統容量是業務不斷發展帶來的要求,以N年翻M倍的投稿量增長公式來計算,系統的負載吞吐是需要走在業務實際發生之前。除了上述提到技改項目之外,內容生產的性能吞吐優化、稿件ID INT32到INT64位升級、狀態流轉異常自動恢復機制、全鏈路自動化測試,都是必要合理的方式來達成系統穩定這一目標。
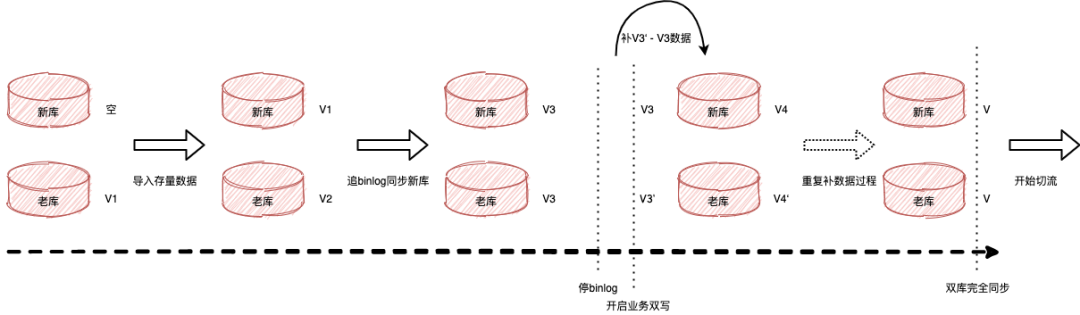
稿件分庫
隨著業務增長投稿量逐漸增多,現有的單Mysql的架構將會成為系統瓶頸,難以支持后續的業務增長,所以需要使用多數據庫來擴大存儲容量和IOPS能力。按照之前測算的數據進行分析,單庫容量剩余50%可用空間,以當時稿件每日增速,到24年底該單庫存儲將到達極限。
為了提前應對將來的危機,對DB進行分庫改造,跟隨業務線性增長的10+表(每張表十億級數據量)拆分到8個邏輯新庫,其余表在老庫不動,邏輯分庫可以根據資源和業務需要部署在N個實際的物理節點上,只要考慮好流量均衡即可。技術復雜點:稿件作為最基礎的底層數據服務,上游依賴服務眾多,數據影響需要逐級擴散梳理,涉及到服務代碼存儲讀寫改動、發號器邏輯修改、歷史數據遷移,同時在數據底層切換操作過程中,要確保核心功能需無損業務無感。項目管理上,整個項目關聯了幾乎公司所有主要技術團隊,從立項之初到灰度放量時間跨度周期長,底層代碼在變更周期內不能阻塞業務代碼的迭代,代碼管理難度大,因此需要有較多的心力放在整體項目風險把控上,要準備好完善的上線和回滾SOP,核心服務不容有失。
整體項目進行大約1年,截止到去年底DB切換基本完成,DB Proxy Service服務負責收斂所有稿件庫表SQL,代理上游依賴服務對數據庫的讀寫流量,老庫保留雙寫讀已全切新庫,核心庫表已無容量和QPS風險;8個邏輯庫DB Binlog Topic聚合成一個消息Topic,與老庫消息結構體保持一致,陸續推動100+依賴數據源下游切換Topic;大數據平臺實時/離線50+任務全部完成改造。
實踐下來還是不要將業務域內的核心DB Binlog暴露給其他業務,而是暴露重新定義的領域事件Topic,否則數據庫字段增改牽扯下游眾多,不敢輕易DDL,也直接拉長了分庫切換的項目戰線,算是早期系統設計過程中的一個設計缺失。
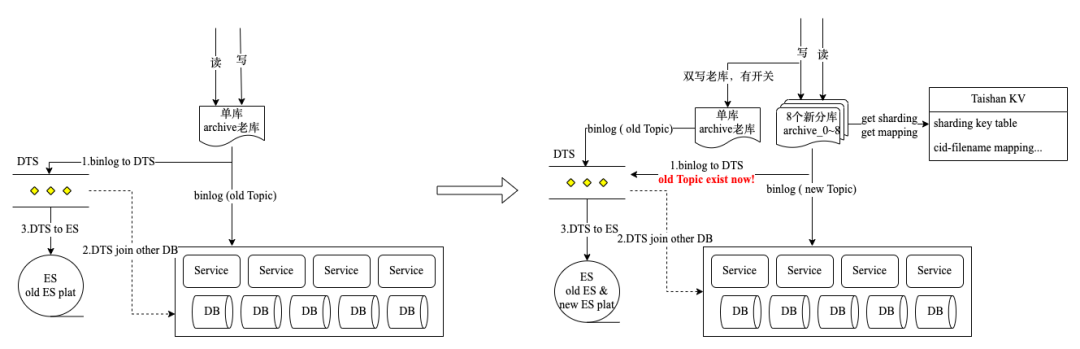
ES索引?&?DTS優化
UP主稿件列表提供搜索過濾和展示用戶名下稿件的能力,是用戶編輯、查看管理自己稿件的重要業務入口,底層使用了ES存儲聚合的寬字段數據。在優化前,稿件列表存在諸多問題:
-
10億+數據單索引16分片,根據doc?id分片,不具備業務routing語義,大部分請求需要全分片檢索,查詢超時長尾效果很明顯
-
舊索引部署在混部集群上,出現過IO競爭導致的查詢接口可用性抖動問題,導致過某一年年報活動,稿件生產完成同步到ES中數據寫入夯住的線上問題
-
UP稿件排序需要觀看、點贊、收藏等C端用戶行為的數據,用戶行為數據量級很大,此類數據刷入ES集群負擔較重,且數據同步流程原先是非標的,走的全量scan?DB同步數據,穩定性較差不是一個好的可擴展的方案
-
稿件分庫改造,需要切換到新的分庫數據源,新老分庫切換涉及30+?ES索引,需在DTS鏈路上切換數據源
優化后獨立集群部署,單索引120分片,根據mid分片,容器化部署ES on K8S,可低成本擴容。性能上根據壓測支持到2000QPS,并可支持水平擴容,性能接近線性提升,PT99超時問題得到了較大緩解。下圖為新舊索引對比監控,新索引60%流量舊索引40%流量,P50持平P80/P90/P99新索引均優于舊索引,其中P99新索引抖動尖刺顯著減少,耗時降為舊索引1/3,P90耗時降為舊索引1/2。B端稿件列表需要互動數據進行粗排序,而全站用戶對稿件互動QPS較高,B端ES集群無法承擔上萬QPS寫入量,最終采用消費互動數據后聚合一段時間再刷新到ES的Delay Merge方案,因為業務上是根據互動指標粗排序,可以容忍數據的更新延遲,還有優化空間。

上文提到的DTS是公司內部的數據傳輸鏈路組件,平臺上支持配置Data Source(比如DB Binlog Topic)、Data Destination(比如ES、KV、Cache等),可以比較方便且可靠地實現異構數據傳輸,鏈路穩定性有保障。DTS支持在數據源事件觸發時,聚合一些其他的數據(Join Other DB/Table,比如商業訂單 Join 稿件表Archive,屬于跨業務域DB Table被Join),組裝數據格式后傳輸到目的存儲。
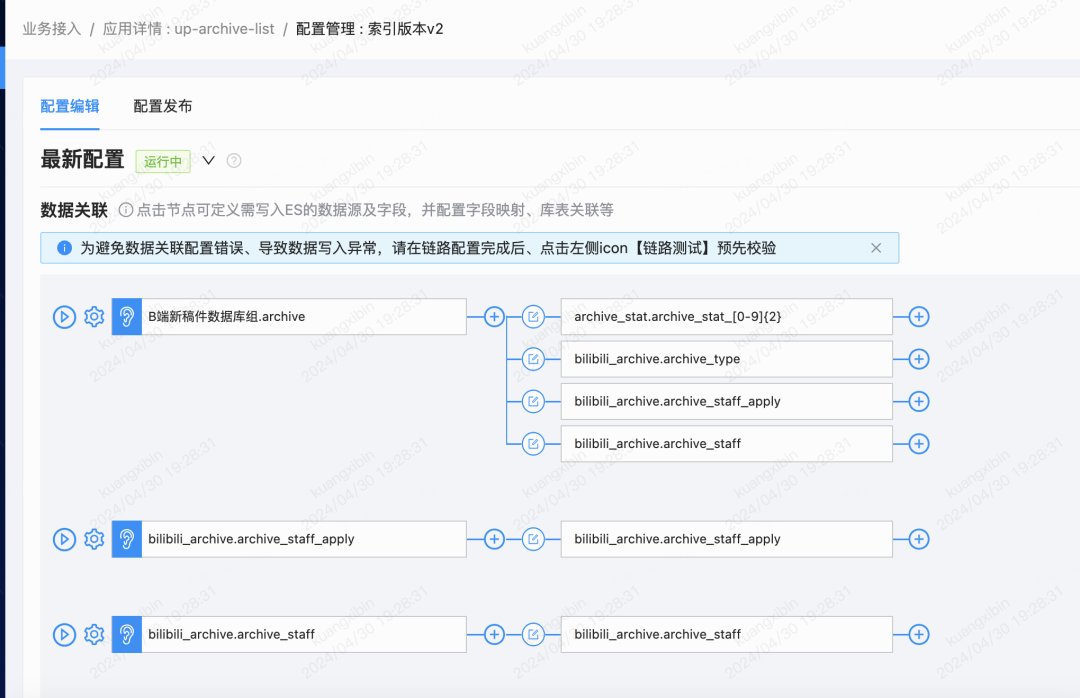
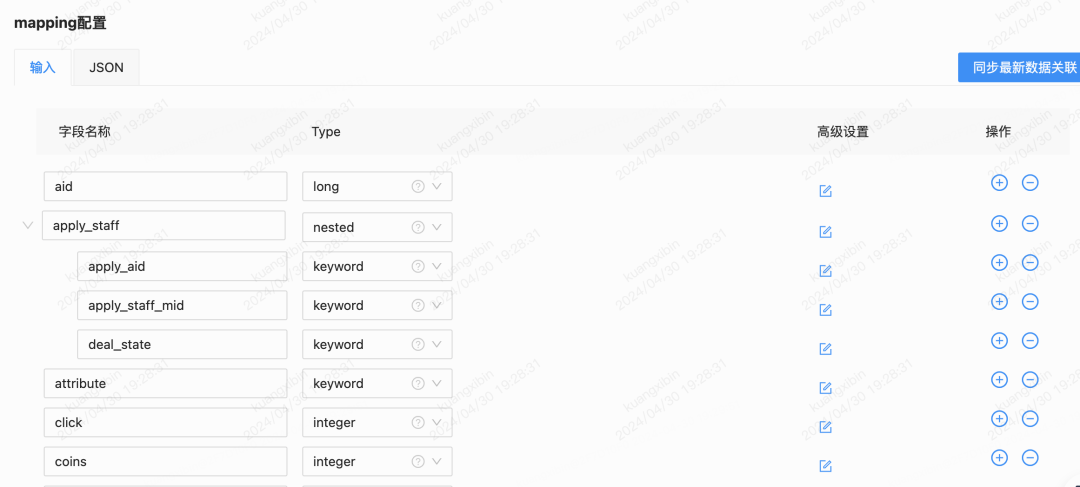
在處理跨DB/跨表Join數據時遇到了邊界的數據不一致問題,假設A表binlog觸發去Join B表時,B表主從同步還未完成導致聚合不到數據,異構數據落ES會缺失字段,數據完整性被破壞了;重試邏輯也很難做,因為DTS不具備業務屬性,無法進入到業務邏輯中去判斷是B表數據就是不存在還是因為某種原因延遲了。當時不得已采用了Delay Join來規避,即配置可延遲觸發Join的時間。另外這種Join的弊端是,就算可以切換到主表Join解決主從一致延遲,DB層面仍然會被各種跨業務域的任務直連查庫,主庫不被保護得暴露會有系統性風險。因此與DTS團隊溝通,平臺迭代來支持從DB Join到API Call,業務提供的Data API中需要自行保障數據完整性,API協議通用化設計,DTS組件本身做好數據傳輸確保高可用一致性的原生職責。以下是一個稿件業務相關索引的DTS配置界面,左邊的表是觸發數據源,右邊的是被Join DB Table,支持DB字段到ES字段的映射Mapping。
ID?INT64升級
歷史上稿件ID(aid)及視頻ID(cid)都是INT32數據類型,最多支撐20億數據量,INT64升級改造改動范圍頗大,但是不得不未雨綢繆提前布局,在項目發起時,按稿件量每年翻倍的業務目標來測算,結合當時稿件ID INT32位剩余數據量預估,僅能再支撐1年多時間急需擴容。擴容成64位后,基本上可以永久使用,不再考慮容量問題。由于aid/cid為公司內部最為核心的ID之二,牽涉面很廣很深,因此需要各條線配合升級改造或兼容,這里也有一個改造過程和灰度放量的觀察周期,注定是一個長線任務。
內部改造:數據源頭的改造,理論上INT64最大使用空間[-9,223,372,036,854,775,808, 9,223,372,036,854,775,807],但由于JS默認的Number使用的是64位雙精度的IEE754浮點數,導致JS只能識別最大整數位2^53-1, 剩余的位保留給指數部分,因此采用不大于51位INT64的發號器產出數據ID。
外部改造:由于稿件系統龐大歷史悠久,下游很多,采用廣度優先的方法推進,
1、稿件業務根據接口監控,找出一級下游,并確定一級下游服務的負責人與對應業務負責人
2、每個下游服務/業務的負責人,如果依賴的下游與aid/cid有關,則需要找到自己依賴下游的負責人并推動其改造,并向項目組報備自己的相關下游
3、根據資源和排期情況,各個業務方制定計劃及Milestone,會定期同步各業務方的進度
改造梳理模版:按照樹狀結構自頂向下傳遞,需要每個業務模塊同時梳理自己的?傳輸、應用、存儲?三大方面。開發工具檢查代碼倉庫中的Proto定義、Codebase中的代碼字段、DB/HIVE中的字段Schema,檢索出來一批可以快速定位需要修改的范圍。如果字段有特殊別名,比如aid被別名為object_id作為存儲字段,那么需要單獨拉出來所有INT32字段并梳理確認。這一步基本可以覆蓋95%的業務場景,在面對剩余5%“我不知道我不知道”的case里,在測試環境定時構造INT64 ID數據下發來嘗試發現問題,測試環境一直有業務在日常回歸使用,構造的數據流會不斷流轉直至遇到問題,如端字段未兼容導致Crash、服務端未兼容導致Server Error。
灰度方案:涉及客戶端更改需要新版本覆蓋率達到一定閾值后進行放量,灰度需要確保可以隨時回退到INT32的發號器邏輯,通過開關控制大的新舊切換邏輯。再使用諸如內部人群號碼包、粉絲段分層MID取尾號逐步灰度(如:<100粉人群MID取余,做百分比例灰度)等放量手段逐步驗證觀察。
?全鏈路寫壓測
年報是每年年末固定會開展的重點業務項目,總結一年觀看B站的數據化表達,并引導轉化為投稿。這種一鍵投稿業務形態就決定了會有短時的高峰投稿行為產生,加上日常進行的代碼治理、存儲短板優化等技術改造,也希望通過寫壓測來觀察線上系統的真實負載情況。
為了在線上環境做寫入壓測,這就要求我們把線上真實流量數據和存儲數據完全分開,基架提供了很好的壓測平臺能夠支持,支持在計算層通過Context打標識,在存儲層通過影子表,MQ也有影子Topic,這樣就把計算流量到存儲完全隔離開,業務研發可以很方便的進行壓測。
全鏈路壓測的目標是檢驗線上服務的抗壓能力,包括代碼邏輯及配置等。因此,壓測流量途徑的應用都是線上的應用,但資源都是影子資源。難點在于,投稿都是異步化流程,且過程中有異構語言(C++/Python/Lua)無法全程串聯起壓測流量標識Mirror標記,只能在部分階段做Mirror Mock來繞過無法串聯的服務。特別地,需要確保Mirror流量是正確按照配置走入到Shadow DB & Cache,否則會污染線上存儲。
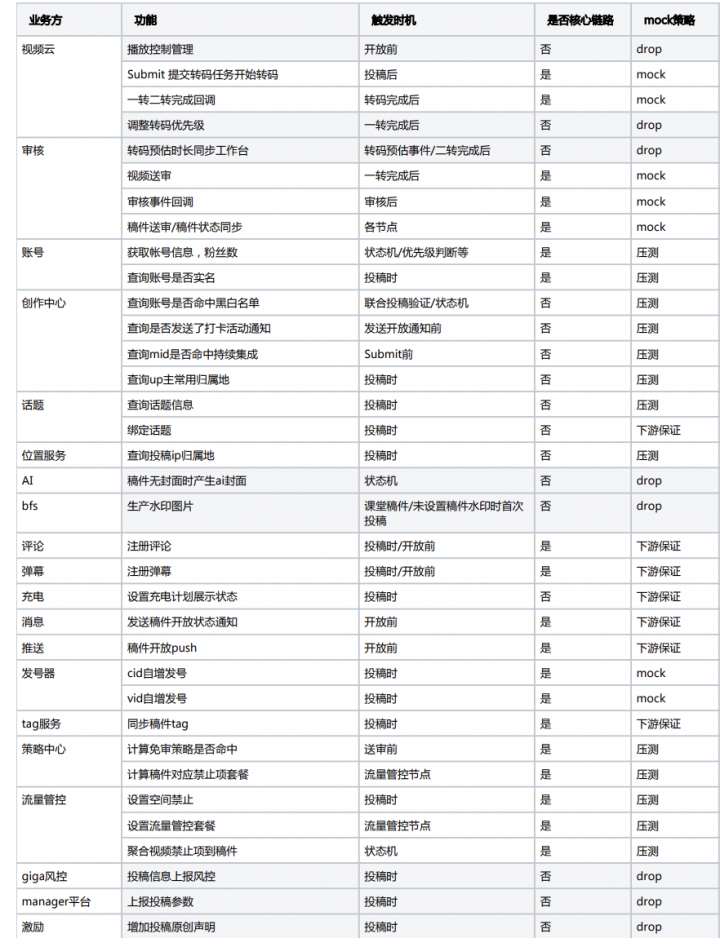
投稿涉及到的上下游節點非常多,從賬號、話題、評論、標簽到風控、審核、Push等。投稿是寫操作(當然也包含很多數據讀取),我們要把對下游服務的寫入全部Mock掉(這些下游依賴服務應該定期完成自己業務內的壓測,來對上游輸出可信賴的服務SLA標準,這是微服務系統內的契約精神),避免模擬的壓測流量對下游服務造成干擾。所以我們對整條鏈路做了詳細的梳理,并做了多次code review確保萬無一失。下圖是投稿壓測涉及到的系統:
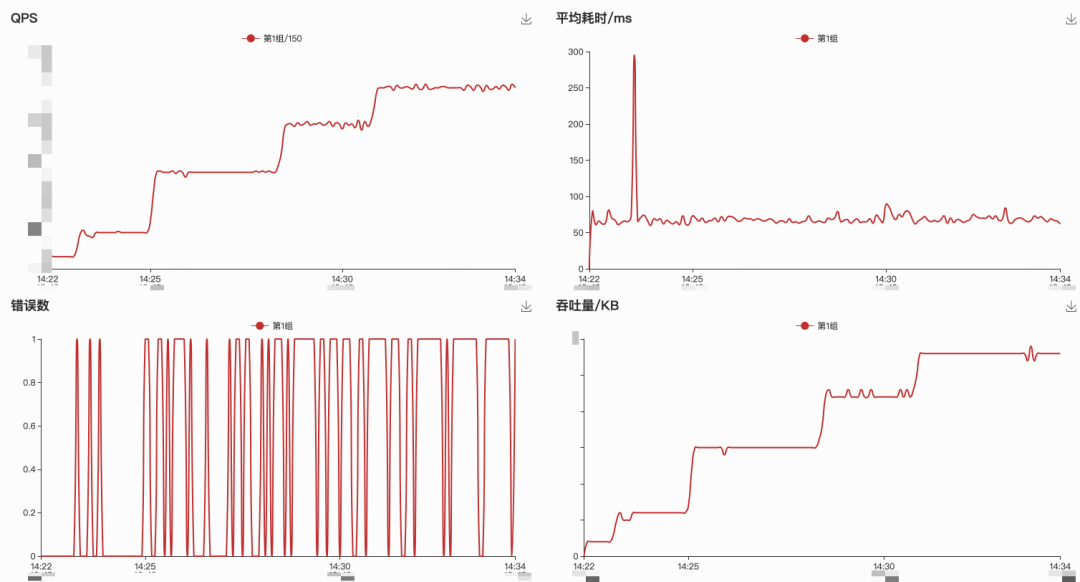
我們對在高負載的情況下,稿件系統可能出現的瓶頸點做了埋點:如MQ的積壓、多線程隊列的積壓、常規硬件資源監控、各存儲引擎的監控等。異步任務場景,MQ積壓通過通用的基礎組件Metrics比較容易發現,不過如果在代碼中有使用本地內存隊列,需要對內存隊列進行積壓埋點觀測,避免因為內存fanout隊列削峰,壓測時以為接口可以承載大量QPS,但是其實在內存中有大量任務堆積,影響對于接口的QPS的誤判,所以也要把內存隊列積壓情況作為指標納入看板中。
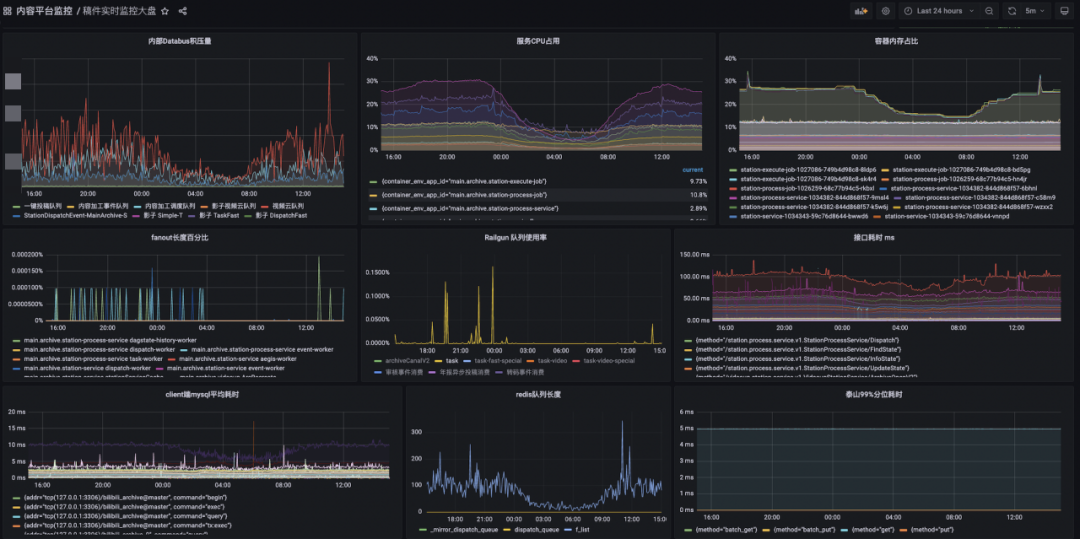
我們通過基架的Melloi壓測平臺發起多輪壓測并回收數據結果,過程中發現并優化了如服務間Context丟失、MQ消費端并發讀不夠、內存隊列并發度不夠、TIDB LSM-Tree寫放大性能抖動、限流不正確導致數據丟失等等問題,最終這些瓶頸優化后稿件系統生產能力QPS吞吐上升了5倍。
了解線上服務的負載極限,也有助于設置合理的業務限流Quota,可以對下游核心服務做好保護;堆積的投稿生產任務可以慢慢消費,確保數據最終可以處理。另外通過壓測的實操演練,沉淀了通用壓測方案,支撐未來大型活動上線前的服務能力巡檢。未來針對大型投稿活動,我們根據相應的預期流量峰值方便的在線上進行壓測回歸。
混沌工程演練
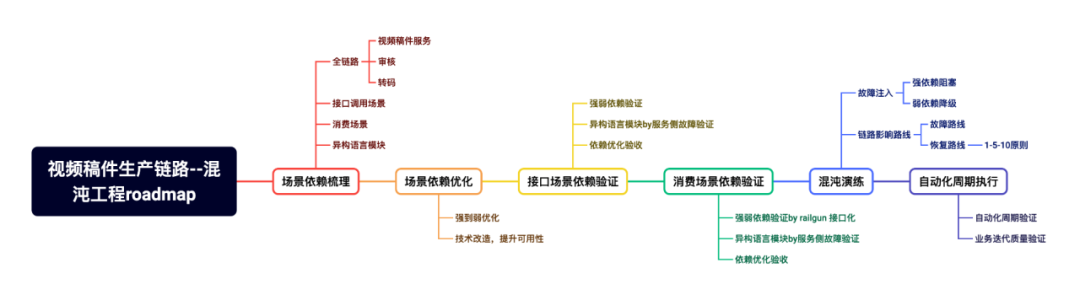
通過技術優化和壓測手段了解線上服務系統的性能現狀,這是很常見的思路。然而考慮到整個鏈路依賴的下游繁雜眾多,依賴的強弱程度不同,某個環節出問題可能影響整個鏈路,很難找到所有潛在風險,因此需要一些逆向思路。混沌工程是一種通過在系統中引入可控的故障來測試系統穩定性和彈性的實踐。綜合考慮平臺混沌工具能力和對系統的影響,我們最終決定在測試環境進行混沌演練,下面介紹下混沌工程在業務生產鏈路中的應用,以及它如何幫助我們識別和優化系統中的短板。
我們之所以實踐混沌工程,希望達成三個目標:
-
識別短板:通過混沌工程,可以清晰地識別出生產鏈路中的潛在問題和短板。
-
依賴透明化:依賴關系變得透明,不合理的依賴可以被識別并優化。
-
故障與恢復:通過混沌工程,可以明確故障路線和恢復路線,實現快速響應和恢復。
為了達成目標,首先需要將業務場景的依賴進行梳理,這一步要結合著實際代碼完成,最終對超過220個依賴進行梳理,覆蓋全流程,包括稿件測試、審核測試和視頻云測試等。借助依賴強弱標記的工具,對下游依賴服務接口進行標記,驗證依賴關系,確保系統在面對故障時能夠正確響應。這一步是一個遞歸遞進的過程,在完成大部分的依賴標記后,在測試環境進行模擬故障來測試系統的穩定性和恢復能力。一旦Case可以通過手動制造模擬故障完成,那么接著就需要將演練案例自動化,我們通過在測試環境自動化投遞各類型構造的稿件,并注入Case編寫的下游依賴故障,以提高效率和覆蓋率。
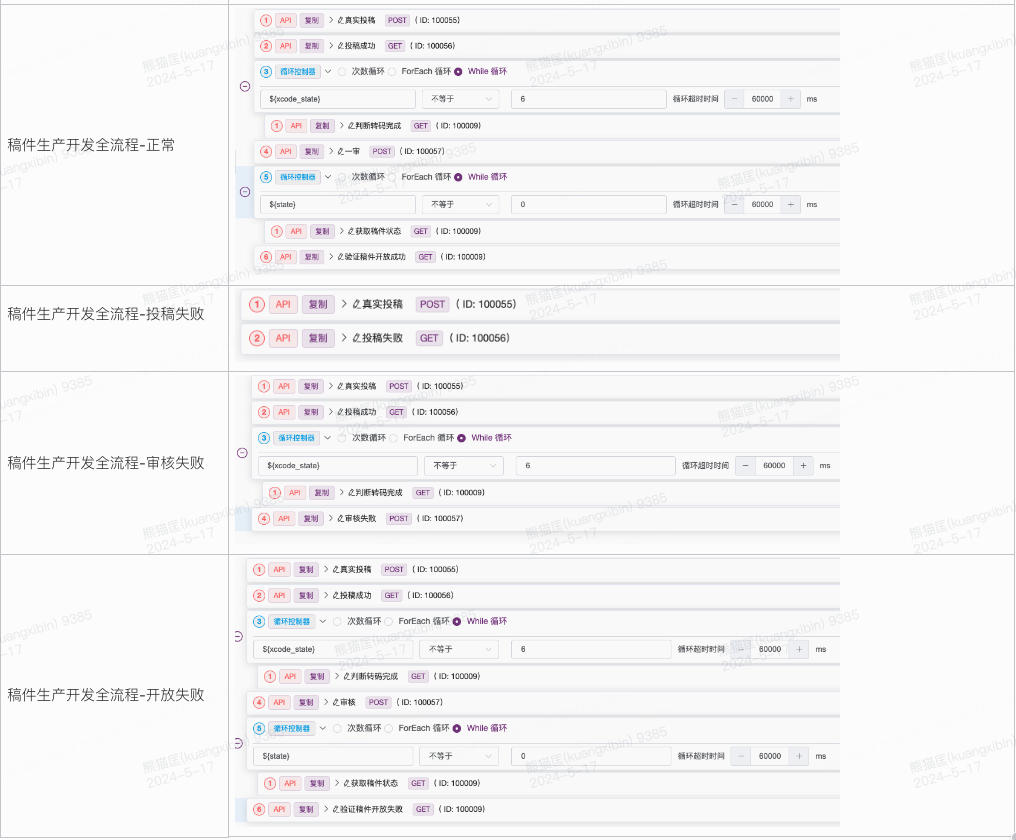
實踐下來,在混沌演練中,我們解決了UAT環境不完整、監控和告警缺失以及數據流和案例依賴驗證的挑戰。復制線上規則,來適配UAT環境,開發了自動投稿審核腳本,實現可控速率,并結合多個平臺,進行多個方案的驗證。
一般的業務場景都是API Call串行流程,接入混沌SDK后,構造下游依賴的case可以驗證API Response,比較直觀。但是投稿鏈路都是異步環節,投稿請求完成后,后續審核、轉碼、同步都是異步的,基于事件驅動的消費行為,比較難以注入故障點,而且MQ里無法攜帶故障信息。eg:"API Call,構造DB Query Block/Timeout" VS "投稿完成,需要構造一審完成回調失敗這個case,應該往哪個實例去注入這個Case?繼續下鉆,回調失敗可能是審核DB寫失敗回調Block,也可能Databus異常回調Block"。
復雜的寫讀,同步異步消息混合場景,當時平臺工具還不支持,因此研發測試一起做了技術攻堅,嘗試多種方案,最終采用場景化方案來做依賴驗證和混沌演練。從幾十個Case抽象成四種通用Case。分階段拆開來,構造不同階段的故障Case(審核、bvcflow、開放)然后去查看稿件狀態是否符合預期。
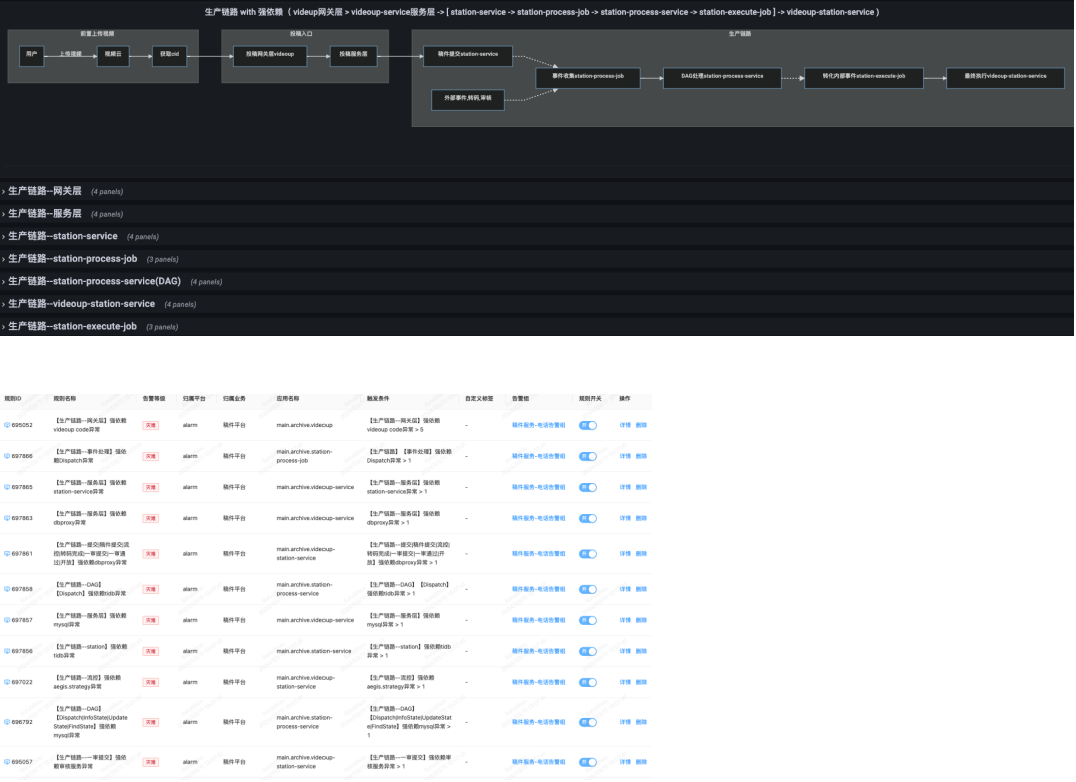
通過混沌工程,我們補齊了生產場景中的空缺,梳理出全鏈路依賴,實現了全鏈路故障監控和規則告警。這不僅提高了系統的穩定性,還幫助我們快速定位故障并制定恢復SOP,實現了1-5-10的快速響應和恢復目標。
投稿業務多活
以上的優化手段針對服務高可用進行,如果并非是服務單點而是機房單點故障導致業務不可用,那業務連續性將會受到直接影響,因此投稿核心業務的多活部署就需要開始著手實施。
將稿件產生到開放瀏覽整個流程劃分為四個步驟,分別是創作、上傳、生產、開放,其中創作&上傳視為一階段,當前我們正在與SRE、DBA、基架、測試等團隊一起合作進行一階段的多活技術方案梳理。階段一的核心目標是:保障用戶可以打開工具,上傳視頻成功,接受有限程度的生產開放延遲。eg:30分鐘不能投稿,直接返回“投稿失敗” vs 可以上傳視頻投稿成功但是30分鐘稿件開放延遲,是不同等級的事故損失。
下圖藍色模塊當前優先規劃需要完成多活,B站當前主體機房是兩地兩中心,首先梳理網絡流量調用,將Zone1部署的、與創作工具&投稿上傳有關的服務進行多活部署到Zone2;流量讀寫上考慮寫回源讀多活策略,用戶的入口流量可以通過CDN&APIGW進行調度。階段一的難點是投稿是個寫行為,并非簡單地將讀流量切Zone就可以解決問題,用戶上傳視頻文件存儲上就需要做到多活,只有原片上傳這一步做到高可用,階段一的多活才算是達成目標的,即上傳不因機房問題而阻塞,上傳后的后續轉碼審核等步驟可以慢慢消費處理。
我們當前正在與視頻云團隊一起梳理視頻上傳和存儲的架構,需要向云原生/混合云部署的架構演進,這樣才可以更方便的對后續的架構進行擴展,比如存算分離,原片上傳后應該盡可能地標準化存儲,與后續業務行為可解耦。多活正在進行中,到目前也已經經過多輪討論和方案共識,本文篇幅有限不在這里做過多贅述了,后續完整執行落地后可以單獨出文介紹。

結語
整個稿件生產鏈路是B站內容產生源頭的大動脈,涉及環節與團隊眾多,肯定無法在一個篇幅中說明,高可用建設之路還有很多TODO要做,比如投稿架構的混合云云原生架構演進、多活完全落地實現、全鏈路自動化測試覆蓋等重點項目。本文是拋磚引玉,主要圍繞生產側的業務架構做了一些系統高可用建設的分享,可以期待下后續其他環節的技術文章。另文章如有錯漏請指出,感謝各位閱讀。
-End-
作者丨熊貓匡










)








