1、為什么要做es集群
單機的elasticsearch做數據存儲,必然面臨兩個問題:海量數據存儲問題、單點故障問題
????????海量數據存儲問題:將索引庫從邏輯上拆分為N個分片(shard),存儲到多個節點
????????單點故障問題:將分片數據在不同節點備份(replica)

2、搭建es集群
? ? ? ? 1、用3個docker容器模擬3個es節點
????????
version: '2.2'
services:es01:image: elasticsearch:7.12.1container_name: es01environment:- node.name=es01- cluster.name=es-docker-cluster- discovery.seed_hosts=es02,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data01:/usr/share/elasticsearch/dataports:- 9200:9200networks:- elastices02:image: elasticsearch:7.12.1container_name: es02environment:- node.name=es02- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data02:/usr/share/elasticsearch/dataports:- 9201:9200networks:- elastices03:image: elasticsearch:7.12.1container_name: es03environment:- node.name=es03- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es02- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data03:/usr/share/elasticsearch/datanetworks:- elasticports:- 9202:9200
volumes:data01:driver: localdata02:driver: localdata03:driver: localnetworks:elastic:driver: bridge????????這是一個使用Docker Compose編排的Elasticsearch集群配置文件。在這個配置中,定義了三個Elasticsearch節點(`es01`、`es02`和`es03`)以及它們共享的網絡、卷和相關設置。
????????- `version: '2.2'`指定了使用的Docker Compose版本。
????????- `services`段定義了各個服務,對應了三個Elasticsearch節點`es01`、`es02`和`es03`。
????????- 每個Elasticsearch節點都基于`elasticsearch:7.12.1`鏡像啟動,指定了節點名稱、集群名稱、發現種子主機、初始主節點和Java虛擬機參數等環境變量配置。
????????- `volumes`段定義了三個數據卷`data01`、`data02`和`data03`用于持久化地存儲Elasticsearch數據。
????????- `ports`指定了將Elasticsearch節點的9200端口(或9200、9201、9202)映射到主機的9200端口(或9201、9202、9203),允許通過主機訪問Elasticsearch服務。
????????- `networks`段指定了每個Elasticsearch節點連接到`elastic`網絡,通過該網絡實現節點之間的通信和互連。
????????- `volumes`部分定義了三個本地驅動的數據卷用于持久化存儲Elasticsearch數據。
????????- `networks`部分定義了一個名為`elastic`的橋接網絡,用于連接Elasticsearch節點。
這個配置文件實現了一個基于Docker容器的Elasticsearch集群,通過定義各節點之間的通信方式、數據存儲方式和網絡連接,使得這些獨立的Elasticsearch節點能夠組成一個工作集群,共同提供Elasticsearch服務。
?
2、設置虛擬機內存
es運行需要修改一些linux系統權限,修改`/etc/sysctl.conf`文件
????????vi /etc/sysctl.conf
添加下面的內容:
????????vm.max_map_count=262144
然后執行命令,讓配置生效:
????????sysctl -p
通過docker-compose啟動集群:
????????docker-compose up -d
? ? ? ? 3、通過cerebro管理集群
? ? ? ? 具體文件見黑馬視頻,需要注意的是java版本的匹配

????????圖中版本我使用的是jdk1.8,實測jdk21會閃退
? ? ? ? 在地址欄中輸入你任意一個es容器地址和端口即可,注意不要忘了http://
????????

es集群的腦裂
????????默認情況下,每個節點都是master eligible節點,因此一旦master節點宕機,其它候選節點會選舉一個成為主節點。當主節點與其他節點網絡故障時,可能發生腦裂問題。
????????為了避免腦裂,需要要求選票超過(eligible節點數量+1)/2才能當選為主,因此eligible節點數量最好是奇數。對應配置項是discovery.zen.minimum master nodes,在es7.0以后,已經成為默認配置,因此一般不會發生腦裂問題
master eligible節點的作用是什么?
????????參與集群選主
????????主節點可以管理集群狀態、管理分片信息、處理創建和刪除索引庫的請求
data節點的作用是什么?
????????數據的CRUD
coordinator節點的作用是什么?
????????路由請求到其它節點
????????合并查詢到的結果,返回給用戶
3、分布式細節

分布式存儲
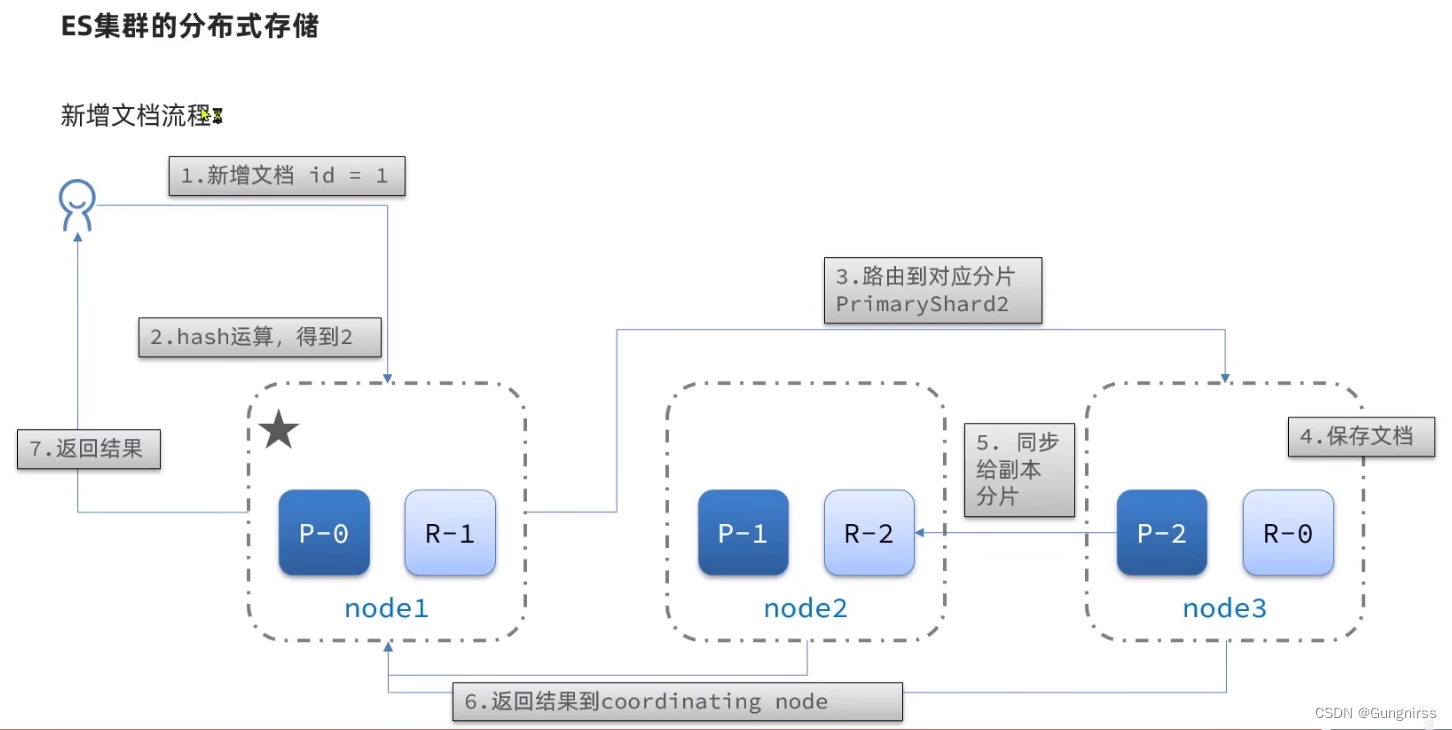
分布式查詢

其中的coordinating node也可以是其中節點的任意一個
總結:
????????分布式新增如何確定分片?
????????????????coordinating node根據id做hash運算,得到結果對shard數量取余,余數就是對應的分片
????????
????????分布式查詢:
????????????????分散階段:coordinating node將查詢請求分發給不同分片
????????????????收集階段:將查詢結果匯總到coordinatingnode,整理并返回給用戶
4、故障轉移
????????集群的master節點會監控集群中的節點狀態,如果發現有節點宕機,會立即將宕機節點的分片數據遷移到其它節點,確保數據安全,這個叫做故障轉移。
????????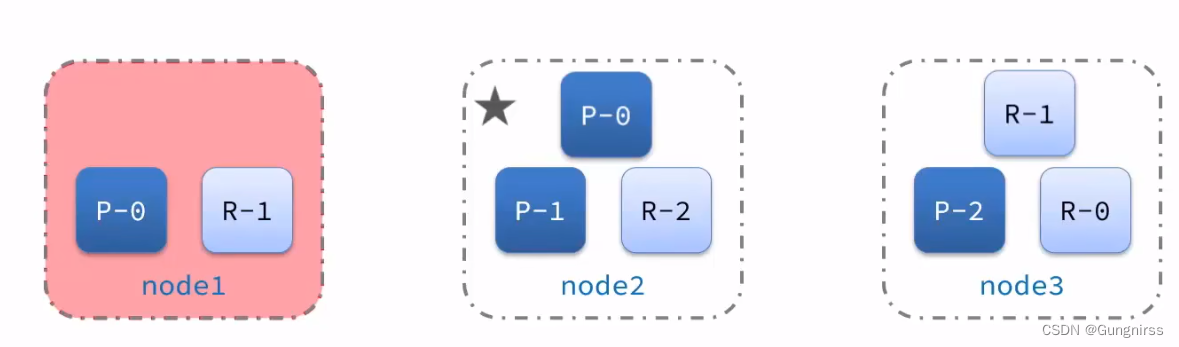
? ? ? ? 主節點掛了就選個新的主節點,然后數據遷移,其他節點掛了就直接數據遷移
故障轉移:
????????master容機后,EligibleMaster選舉為新的主節點:
????????master節點監控分片、節點狀態,將故障節點上的分片轉移到正常節點,確保數據安全。
)

)
)
實現通用音頻事件標記(Audio Tagger))








)
)


希爾排序)
Java程序設計高級(一))
