1.概述:
? ? ? ?Whisper-AT 是建立在 Whisper 自動語音識別(ASR)模型基礎上的一個模型。Whisper 模型使用了一個包含 68 萬小時標注語音的大規模語料庫進行訓練,這些語料是在各種不同條件下錄制的。Whisper 模型以其在現實背景噪音(如音樂)下的魯棒性著稱。盡管如此,其音頻表示并非噪音不變,而是與非語音聲音高度相關。這意味著 Whisper 在識別語音時會依據背景噪音類型進行調整。
主要發現:
-
噪音變化的表示:
- Whisper 的音頻表示編碼了豐富的非語音背景聲音信息,這與通常追求噪音不變表示的 ASR 模型目標不同。
- 這一特性使得 Whisper 能夠在各種噪音條件下通過識別和適應噪音來保持其魯棒性。
-
ASR 和音頻標簽的統一模型:
- 通過凍結 Whisper 模型的骨干網絡,并在其上訓練一個輕量級的音頻標簽模型,Whisper-AT 可以在一次前向傳遞中同時識別音頻事件和語音文本,額外的計算成本不足 1%。
- Whisper-AT 在音頻事件檢測方面表現出色,同時保持了 Whisper 的 ASR 功能。
技術細節:
-
Whisper ASR 模型:
- Whisper 使用基于 Transformer 的編碼器-解碼器架構。
- 其訓練集包括從互聯網上收集的 68 萬小時音頻-文本對,涵蓋了廣泛的環境、錄音設置、說話人和語言。
-
抗噪機制:
- Whisper 的魯棒性并非通過噪音不變性實現,而是通過在其表示中編碼噪音類型。
- 這一機制使得 Whisper 能夠根據背景噪音類型來轉錄文本,從而在嘈雜條件下表現優越。
-
構建 Whisper-AT:
- Whisper-AT 是通過在 Whisper 模型上添加新的音頻標簽層而構建的,未修改其原始權重。
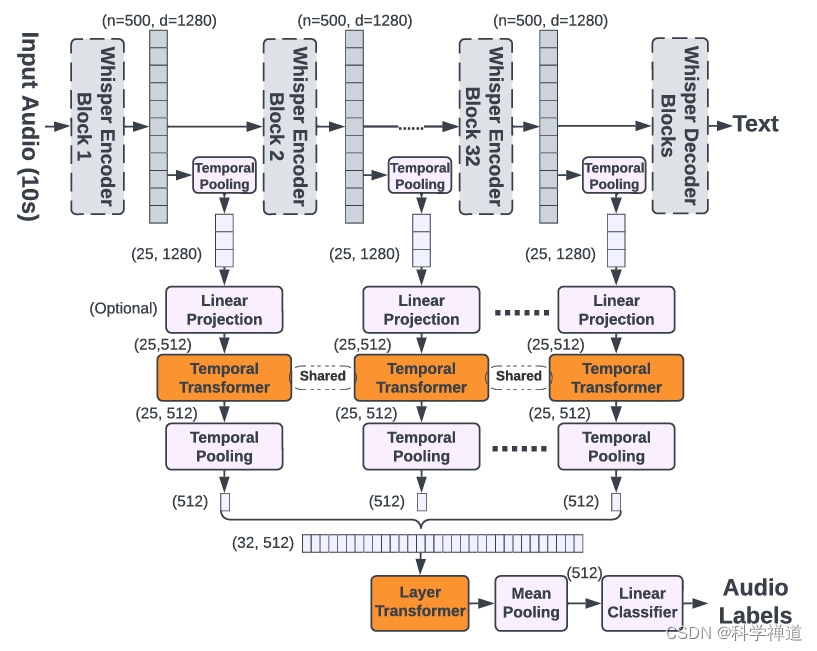
- 探索了不同的音頻標簽層集成方法,包括:
- Last-MLP:對 Whisper 的最后一層表示進行時間均值池化,然后應用線性層。
- WA-MLP:對所有層的表示進行加權平均,然后應用線性層。
- WA-Tr:用時間 Transformer 層替換線性層。
- TL-Tr:使用時間和層次 Transformer 處理所有層的表示。
- Whisper-AT 是通過在 Whisper 模型上添加新的音頻標簽層而構建的,未修改其原始權重。
-
效率考量:
- 為保持計算效率,采用了各種策略,例如減少表示的序列長度,并在應用音頻標簽 Transformer 之前可選地降低維度。
性能:
- Whisper-AT 在 AudioSet 上達到了 41.5 的 mAP,略低于獨立的音頻標簽模型,但處理速度顯著更快,超過 40 倍。
意義:
- 能夠同時執行 ASR 和音頻標簽任務,使得 Whisper-AT 非常適合于視頻轉錄、語音助手和助聽器系統等應用場景,在這些場景中需要同時進行語音文本和聲學場景分析。
2.代碼:
? ? ? ?欲了解詳細的實現和實驗結果,請訪問 GitHub: github.com/yuangongnd/whisper-at.下面是對 Whisper-AT 代碼的詳細解釋。我們將逐步解析其主要組件和功能,幫助理解其工作原理。
安裝和準備
首先,確保你已經安裝了 Whisper 和相關的依賴項:
pip install git+https://github.com/openai/whisper.git
pip install torch torchaudio
pip install transformers datasets
代碼結構
簡要 Whisper-AT 的代碼結構如下所示:
Whisper-AT/
│
├── whisper_at.py
├── train.py
├── dataset.py
├── utils.py
└── README.md
whisper_at.py - Whisper-AT 模型
import torch
import torch.nn as nn
import whisperclass WhisperAT(nn.Module):def __init__(self, model_name="base"):super(WhisperAT, self).__init__()self.whisper = whisper.load_model(model_name)self.audio_tagging_head = nn.Linear(self.whisper.dims, 527) # 527 是 AudioSet 的標簽數def forward(self, audio):# 獲取 Whisper 的中間表示with torch.no_grad():features = self.whisper.encode(audio)# 通過音頻標簽頭audio_tagging_output = self.audio_tagging_head(features.mean(dim=1))return audio_tagging_output
train.py - 訓練腳本
import torch
from torch.utils.data import DataLoader
from dataset import AudioSetDataset
from whisper_at import WhisperAT
import torch.optim as optim
import torch.nn.functional as Fdef train():# 加載數據集train_dataset = AudioSetDataset("path/to/training/data")train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)# 初始化模型model = WhisperAT()model.train()# 定義優化器optimizer = optim.Adam(model.parameters(), lr=1e-4)for epoch in range(10): # 假設訓練10個epochfor audio, labels in train_loader:optimizer.zero_grad()# 前向傳播outputs = model(audio)# 計算損失loss = F.binary_cross_entropy_with_logits(outputs, labels)# 反向傳播和優化loss.backward()optimizer.step()print(f"Epoch {epoch}, Loss: {loss.item()}")if __name__ == "__main__":train()
dataset.py - 數據集處理
import torch
from torch.utils.data import Dataset
import torchaudioclass AudioSetDataset(Dataset):def __init__(self, data_path):self.data_path = data_pathself.audio_files = [...] # 這里假設你有一個包含所有音頻文件路徑的列表self.labels = [...] # 這里假設你有一個包含所有對應標簽的列表def __len__(self):return len(self.audio_files)def __getitem__(self, idx):# 加載音頻audio, sample_rate = torchaudio.load(self.audio_files[idx])# 獲取對應標簽labels = torch.tensor(self.labels[idx])return audio, labels
utils.py - 輔助功能
import torchdef save_model(model, path):torch.save(model.state_dict(), path)def load_model(model, path):model.load_state_dict(torch.load(path))model.eval()
詳細解釋
-
Whisper-AT 模型 (
whisper_at.py):WhisperAT類繼承自nn.Module,初始化時加載 Whisper 模型,并在其上添加一個線性層用于音頻標簽任務。forward方法首先調用 Whisper 模型的encode方法獲取音頻特征,然后將這些特征傳遞給音頻標簽頭(線性層)以生成標簽輸出。
-
訓練腳本 (
train.py):train函數中,數據集被加載并傳遞給 DataLoader。- 模型實例化并設置為訓練模式。
- 定義了 Adam 優化器和二進制交叉熵損失函數。
- 在訓練循環中,音頻輸入通過模型生成輸出,計算損失并執行反向傳播和優化。
-
數據集處理 (
dataset.py):AudioSetDataset類繼承自Dataset,實現了音頻數據和標簽的加載。__getitem__方法加載音頻文件并返回音頻張量和對應標簽。
-
輔助功能 (
utils.py):- 包含保存和加載模型狀態的函數,方便模型的持久化和恢復。
? ? ? ?通過以上代碼結構和解釋,可以幫助理解 Whisper-AT 的實現和訓練流程。可以根據需要擴展這些代碼來適應具體的應用場景和數據集。








)
)


希爾排序)
Java程序設計高級(一))





