文章目錄
- 概述
- 原理介紹
- BERT模型架構
- 任務1 Masked LM(MLM)
- 任務2 Next Sentence Prediction (NSP)
- 模型輸入
- 下游任務微調
- GLUE數據集
- SQuAD v1.1 和 v2.0
- NER
- 情感分類實戰
- IMDB影評情感數據集
- 數據集構建
- 模型構建
- 核心代碼
- 超參數設置
- 訓練結果
- 注意事項
- 小結
本文涉及的源碼可從BERT論文解讀及情感分類實戰該文章下方附件獲取
概述
本文將先介紹BERT架構和技術細節,然后介紹一個使用IMDB公開數據集情感分類的完整實戰(包含數據集構建、模型訓練微調、模型評估)。
IMDB數據集分為25000條訓練集和25000條測試集,是情感分類中的經典公開數據集,這里使用BERT模型進行情感分類,測試集準確率超過93%。
BERT(Bidirectional Encoder Representations from Transformers)是一種基于Transformer架構的雙向編碼器語言模型,它在自然語言處理(NLP)領域取得了顯著的成果。以下是BERT的架構和技術細節,以及使用BERT在IMDB公開數據集上進行情感分類的實戰介紹。
- BERT架構和技術細節
- 雙向編碼器:BERT模型通過聯合考慮所有層中的左側和右側上下文來預訓練深度雙向表示,這使得BERT能夠在預訓練階段捕獲更豐富的語言特征。
- 預訓練任務
- 掩碼語言模型(MLM):BERT隨機掩蔽詞元并使用來自雙向上下文的詞元以自監督的方式預測掩蔽詞元。在預訓練任務中,BERT將隨機選擇15%的詞元作為預測的掩蔽詞元,其中80%的時間用特殊的
<MASK>詞元替換,10%的時間替換為隨機詞元,剩下的10%保持不變。 - 下一句預測(NSP):為了幫助理解兩個文本序列之間的關系,BERT在預訓練中考慮了一個二元分類任務——下一句預測。在生成句子對時,有一半的時間它們確實是連續的句子,另一半的時間第二個句子是從語料庫中隨機抽取的。
- 掩碼語言模型(MLM):BERT隨機掩蔽詞元并使用來自雙向上下文的詞元以自監督的方式預測掩蔽詞元。在預訓練任務中,BERT將隨機選擇15%的詞元作為預測的掩蔽詞元,其中80%的時間用特殊的
- 模型微調:預訓練的BERT模型可以通過添加少量額外的輸出層來微調,從而適應廣泛的任務,如問答和語言推斷,而無需對模型架構進行大量特定任務的修改。
- 使用BERT在IMDB數據集上進行情感分類的實戰
- 數據集:IMDB公開數據集分為25000條訓練集和25000條測試集,用于情感分類任務。
- 模型訓練與微調
- 加載預訓練的BERT模型。
- 對原始數據進行預處理,使其符合BERT模型的輸入要求。
- 在訓練集上訓練BERT模型,進行微調以適應情感分類任務。
- 模型評估
- 在測試集上評估模型的性能,計算準確率等指標。
- 報告測試集準確率超過93%的結果。
BERT模型在多個自然語言處理任務上取得了新的最先進結果,包括情感分類任務。使用BERT模型進行情感分類能夠取得較好的效果,尤其是在擁有足夠數據量和計算資源的情況下。
原理介紹
BERT模型架構
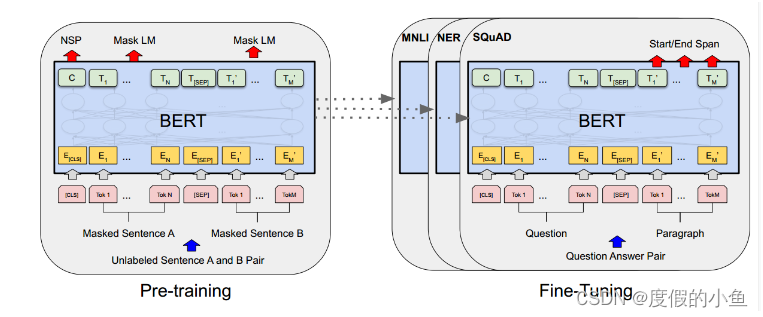
BERT模型就是transformer的encoder堆疊而成,只是訓練方式是有所講究。
BERT能夠在下游任務微調,模型結構也只需要改變輸出層即可方便地適配下游任務。
[CLS]是添加在每個輸入示例前面的一個特殊符號,用于整體信息的表示
[SEP]是一個特殊的分隔符標記(例如分隔問題/答案)
BERT不使用傳統的從左到右或從右到左的語言模型來預訓練。相反,是使用兩個無監督任務預訓練BERT。
任務1 Masked LM(MLM)
直觀地說,我們有理由相信深度雙向模型嚴格地比從左到右模型或從左到左模型和從右到左模型的簡單結合更強大。不幸的是,標準條件語言模型只能從左到右或從右到左進行訓練,因為雙向條件反射允許每個單詞間接地“看到自己”,并且該模型可以在多層上下文中預測目標單詞。
為了訓練深度雙向表示,只需隨機屏蔽一定百分比的輸入令牌,然后預測那些屏蔽的令牌。文章將此過程稱為“masked LM”(MLM)。在這種情況下,被屏蔽的單詞的最終隱藏向量被饋送到詞匯表上的輸出softmax中,然后得出預測。
文章隨機屏蔽每個序列中15%的單詞。然后只預測被屏蔽的單詞。
盡管這能夠獲得雙向預訓練模型,但缺點是在預訓練和微調之間造成了不匹配,因為[MASK]在微調過程中不會出現。為了緩解這種情況,我們并不總是用實際的[MASK]替換“屏蔽”單詞。訓練數據生成器隨機選擇15%的單詞用于預測。在這些單詞中,使用
(1)80%概率的替換為[MASK],即需要進行預測。 這是最常見的掩蓋策略,模型需要學習根據上下文來預測原本的詞匯,這樣的訓練方式使得模型能夠更好地理解詞匯在不同上下文中的含義。
(2)10%概率的替換為隨機單詞。 這種策略增加了訓練數據的多樣性,迫使模型不僅僅依賴于特定的掩蓋詞匯來做出預測。這種隨機性有助于模型學習到更加魯棒的上下文表示,因為它不能簡單地記憶或依賴于特定的掩蓋詞匯。
(3)10%概率單詞不變。 這種策略保留了原始詞匯,不進行掩蓋,這有助于模型學習到詞匯本身的表示,同時也為模型提供了一些直接從輸入中學習的機會,而不是完全依賴于上下文推斷。
任務2 Next Sentence Prediction (NSP)
許多重要的下游任務,如問答(QA)和自然語言推理(NLI),都是基于理解兩句之間的關系,而語言建模并不能直接捕捉到這一點。為了訓練一個理解句子關系的模型,文章讓模型在下一個句子預測任務上進行預訓練,該任務可以從任何單語語料庫中輕松生成。
具體而言,當為每個預訓練示例選擇句子A和B時,50%的概率B是A后面的下一個句子(標記為Is Next),50%的概率B是來自語料庫的隨機句子(標記為Not Next)。
模型輸入
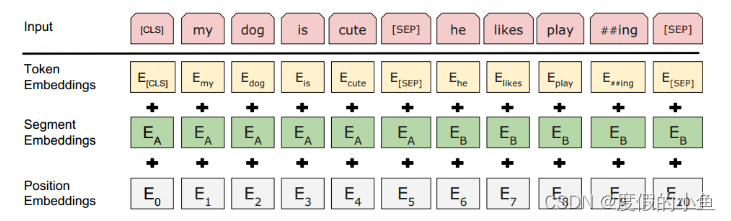
Token Embeddings就是詞的嵌入層表示,只不過句子開頭要加[CLS]不同句子之間要加[SEP]。
[CLS]的用處如下:
句子表示:在預訓練階段,[CLS]標記的最終隱藏狀態(即經過Transformer最后一層的輸出)被用作整個輸入序列的聚合表示(aggregate sequence representation)。這意味著[CLS]的表示捕捉了整個序列的上下文信息。
分類任務:在微調階段,尤其是在句子級別或序列級別的分類任務中,[CLS]的最終隱藏狀態被用來作為分類的輸入特征。例如,在情感分析、自然語言推斷或其他類似的任務中,[CLS]的輸出向量會被送入一個額外的線性層(分類層),然后應用softmax函數來預測類別。
問答任務:在問答任務中,[CLS]也可以用來進行答案的預測。例如,在SQuAD問答任務中,模型會輸出答案的開始和結束位置的概率分布,而[CLS]的表示有助于模型理解問題和段落之間的關系。
[SEP]用處如下:
分隔句子:
當BERT處理由多個句子組成的句子對時(例如,在問答任務中的問題和答案),[SEP]標記用來明確地分隔兩個句子。它允許模型區分序列中的不同部分,尤其是在處理成對的句子時,如在自然語言推斷或問答任務中。
輸入表示:
在構建輸入序列時,句子A(通常是第一個句子或問題)會以[CLS]標記開始,接著是句子A的單詞,然后是[SEP]標記,然后是句子B(通常是第二個句子或答案)的單詞…
通過在句子之間插入[SEP],模型可以明確地知道序列的結構,從而更好地處理和理解輸入的文本。
位置嵌入:
與[CLS]類似,[SEP]也有一個對應的嵌入向量,這個向量是模型學習到的,并且與[CLS]的嵌入向量不同。這個嵌入向量幫助模型理解[SEP]標記在序列中的位置和作用。
注意力機制:
在Transformer模型的自注意力機制中,[SEP]標記使得模型能夠區分來自不同句子的標記,這對于模型理解句子間關系的任務至關重要。
預訓練和微調:
在預訓練階段,[SEP]幫助模型學習如何處理成對的句子,這在NSP(Next Sentence Prediction)任務中尤為重要。在微調階段,[SEP]繼續用于分隔句子對,使得模型能夠適應各種需要處理成對文本的下游任務。
Segment Embeddings 用于標記是否屬于同一個句子。
Position Embeddings 用于標記詞的位置信息
下游任務微調
BERT能夠輕松地適配下游任務,此時使用已經預訓練好的BERT模型就能花很少的資源和時間得到很不錯地結果,而不需要我們從頭開始訓練BERT模型。
接下來就看一下BERT在不同數據集是怎么使用的
GLUE數據集
GLUE(General Language Understanding Evaluation)基準測試是一組不同的自然語言理解任務的集合。任務描述如下:
MNLI(Multi-Genre Natural Language Inference):給定一對句子,預測第二個句子是否是第一個句子的蘊含、矛盾或中立。
QQP(Quora Question Pairs):判斷Quora上的兩個問題是否語義等價。
QNLI(Question Natural Language Inference):基于斯坦福問答數據集的二分類任務,判斷問題和句子是否包含正確答案。
SST-2(Stanford Sentiment Treebank):電影評論中句子的情感分類任務。
CoLA(Corpus of Linguistic Acceptability):判斷英語句子是否語法正確。
STS-B(Semantic Textual Similarity Benchmark):判斷句子對在語義上的相似度。
MRPC(Microsoft Research Paraphrase Corpus):判斷句子對是否語義等價。
RTE(Recognizing Textual Entailment):文本蘊含任務,與MNLI類似,但訓練數據更少。
WNLI(Winograd NLI):自然語言推理數據集,但由于構建問題,該數據集的結果未被考慮。
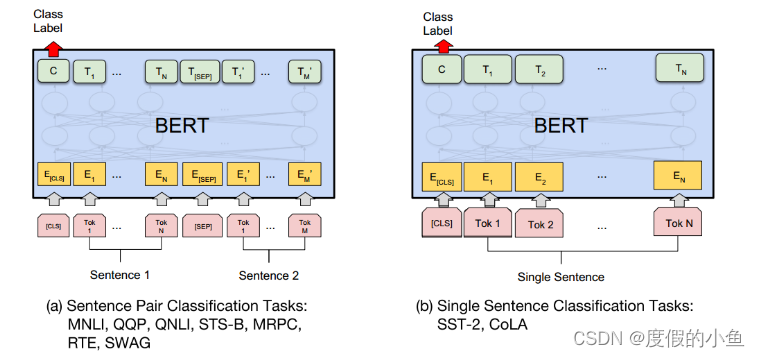
對于多個句子的,輸入形式就是[CLS]+句子1+[SEP]+句子2+…
對于單個句子的就是[CLS]+句子
然后最后一層輸出的[CLS]用來接個全連接層進行分類,適配不同任務需要。
SQuAD v1.1 和 v2.0
SQuAD(Stanford Question Answering Dataset)是問答任務的數據集,包括SQuAD v1.1和SQuAD v2.0兩個版本。任務描述如下:
SQuAD v1.1:給定一個問題和一段文本,預測答案在文本中的位置。
SQuAD v2.0:與SQuAD v1.1類似,但允許問題沒有答案,使問題更具現實性。
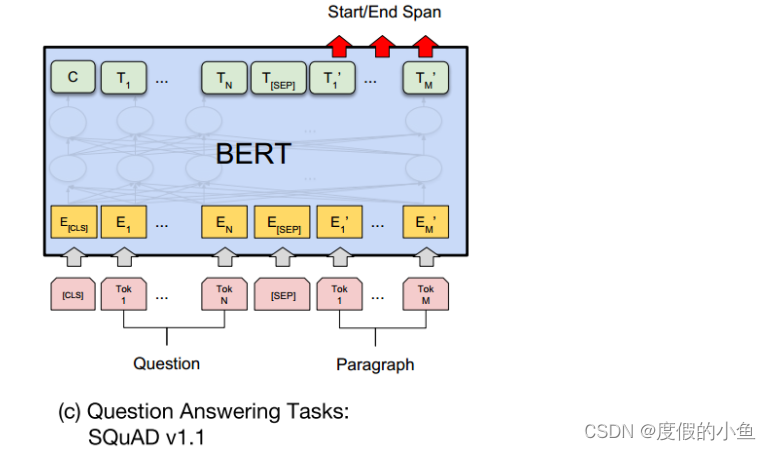
對于SQuAD v1.1,輸入格式為[CLS]+問題+[SEP]+段落信息
因為這個數據集就是問題能夠在段落中找到答案,構造一個得分,得分最大的作為預測值,具體如下:
首先引入S和E兩組可訓練參數,用于計算答案的開始和結束文章

NER
對于命名實體識別的任務,BERT實現起來也是非常簡單。
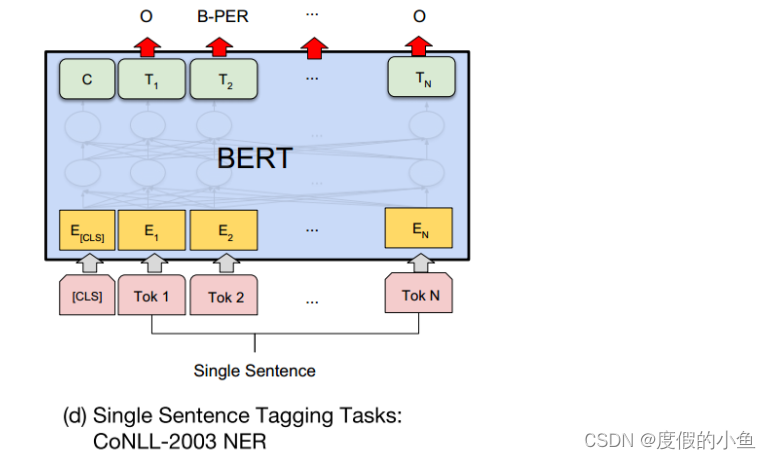
只需要對最后一層的每個單詞預測對于的實體標記即可。
情感分類實戰
IMDB影評情感數據集
IMDb Movie Reviews數據集是一個用于情感分析的標準二元分類數據集,它包含來自互聯網電影數據庫(Internet Movie Database,簡稱IMDB)的50,000條評論,這些評論被標記為正面或負面。
評論數量和平衡性:數據集包含50,000條評論,其中正面和負面評論的數量是相等的,即各占一半。
評分標準:評論是基于10分制的評分進行分類的。負面評論的評分在0到4分之間,而正面評論的評分在7到10分之間。
評論選擇:為了確保數據集中的評論具有高度的兩極性,選擇了評分差異較大的評論。每部電影最多只包含30條評論。
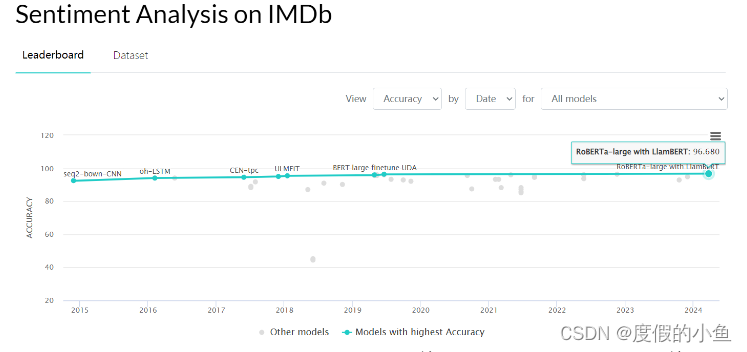
可以看一下榜單,目前在paperwithcode上最高是96.68%,看這模型的名字就不太好惹,但是我們這里簡單使用BERT接個全連接進行二分類,也能達到93%
數據集構建
# 定義數據集類
class SentenceDataset(Dataset):def __init__(self, sentences, labels, tokenizer, max_length=512):self.sentences = sentencesself.labels = labelsself.tokenizer = tokenizerself.max_length = max_lengthdef __len__(self):return len(self.sentences)def __getitem__(self, idx):# 對文本進行編碼encoded = self.tokenizer.encode_plus(self.sentences[idx],add_special_tokens=True,max_length=self.max_length,return_token_type_ids=False,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')# 獲取編碼后的數據和注意力掩碼input_ids = encoded['input_ids']attention_mask = encoded['attention_mask']# 返回編碼后的數據、注意力掩碼和標簽return input_ids, attention_mask, self.labels[idx]
因為BERT是WordPiece嵌入的,所以需要使用他專門的切詞工具才能正常使用,因此在數據預處理的過程中,可以切好詞轉化為bert字典中的id,這樣直接喂入bert就能得到我們要的句子bert向量表示了,然后就可以用來分類了。
模型構建
使用transformers中預訓練好的BERT模型(bert-base-uncased)
我們可以先來看一下bert模型的輸入輸出:
from transformers import BertTokenizer, BertModel# 初始化分詞器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')sentences = ["Hello, this is a positive sentence."]# 對句子進行編碼
encoded_inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt', max_length=512)
outputs = model(**encoded_inputs)
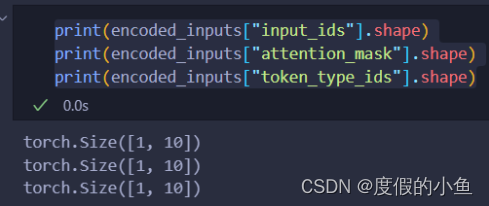
可以看到分詞器的輸出encoded_inputs由三部分組成,維度都是[batch_size, seq_len]
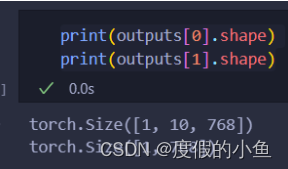
可以看到bert模型的輸出為:
outputs[0]是[batch_size, seq_len, hidden_size]
outputs[1]是[batch_size, hidden_size]
outputs[0]就是每個詞的表示
outputs[1]就是[CLS],可以看成這句話的表示
對于我們的任務,就是實現情感分類,因此直接使用outputs[1]接全連接就行了
核心代碼
# 定義一個簡單的全連接層來進行二分類
class BertForSequenceClassification(nn.Module):def __init__(self, bert, num_labels=2):super(BertForSequenceClassification, self).__init__()self.bert = bert #BERT模型self.classifier = nn.Linear(bert.config.hidden_size, num_labels)def forward(self, input_ids, attention_mask):outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)pooled_output = outputs[1]logits = self.classifier(pooled_output)return logits
代碼就是非常簡潔,當然,如果想要更好地效果,可以直接加個LSTM、BiLSTM+Attention等來更好地進行語義編碼,操作空間還是很大地。
超參數設置

batch_size=64 需要50多G顯存才能跑起來,現存小的話可以開4
lr=2e-5就是微調大模型的常用學習率
epoch=2 其實結果已經很不錯了,這可能就是微調的魅力
num_labels = 2因為數據集是二分類任務
因為這個實戰是個簡潔版本,所以超參數也設定的很少,代碼也是很簡潔,適合初學者參考學習
訓練結果
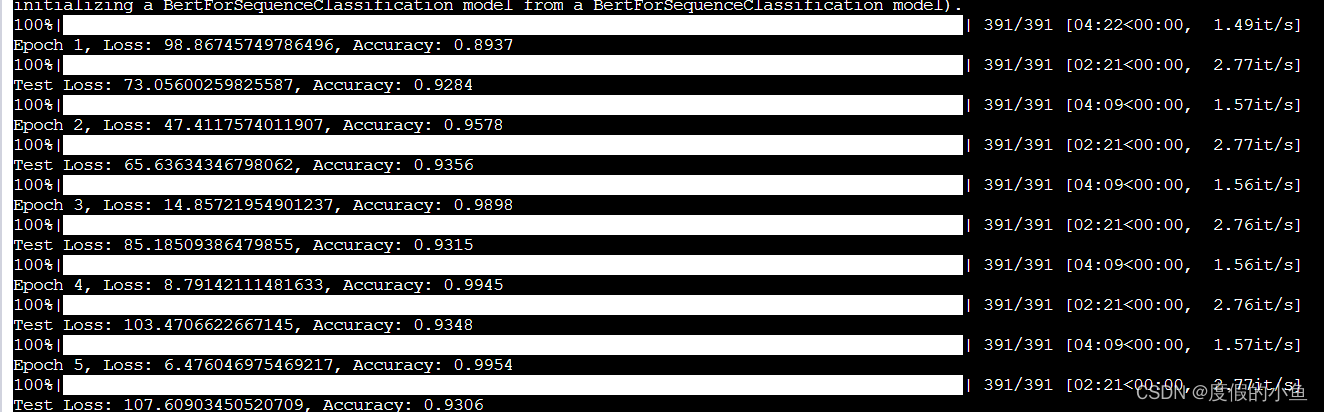
可以看到測試集的準確率最高為93.56%
還是很不錯的
不過我并沒有固定隨機種子
可能多跑幾次能夠還有望超越93.56%
注意事項
train_sentences, train_labels = get_data(r'./data/train_data.tsv')
test_sentences, test_labels = get_data(r'./data/test_data.tsv')
# 初始化BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertModel.from_pretrained('bert-base-uncased').to(device)
模型和數據附件中都有,運行的適合需要將模型和數據的路徑修改為自己的路徑
小結
使用BERT在IMDB數據集上進行情感分類的實戰取得了令人滿意的結果。通過本次實戰,我們深入了解了BERT模型的工作原理和訓練方法,并獲得了寶貴的實踐經驗。






)




; // 創建逆運動學求解器)



)

 |深入解析客戶端緩存與服務器緩存:HTTP緩存控制頭字段及優化實踐)


