
注意:本模型繼續加入?組合預測模型全家桶?中,之前購買的同學請及時更新下載!
?往期精彩內容:
時序預測:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析與比較-CSDN博客
VMD + CEEMDAN 二次分解,Transformer-BiGRU預測模型-CSDN博客
獨家原創 | 基于TCN-SENet +BiGRU-GlobalAttention并行預測模型-CSDN博客
獨家原創 | BiTCN-BiGRU-CrossAttention融合時空特征的高創新預測模型-CSDN博客
基于LSTM網絡的多步預測模型_pytorch transformer-CSDN博客
基于1DCNN網絡的多步預測模型-CSDN博客
高創新 | CEEMDAN + SSA-TCN-BiLSTM-Attention預測模型-CSDN博客
基于Transformer網絡的多步預測模型-CSDN博客
獨家原創 | 超強組合預測模型!-CSDN博客
基于TCN網絡的多步預測模型-CSDN博客
基于CNN-LSTM網絡的多步預測模型-CSDN博客
時空特征融合的BiTCN-Transformer并行預測模型-CSDN博客
組合預測模型思路:使用復雜模型去預測數據的分量特征,因為復雜模型參數量大,適合預測高頻復雜分量特征,但是低頻分量特征比較簡單,要是還用復雜模型的話,就容易過擬合,反而效果不好,所以對于低頻分量特征?我們采用簡單模型(或者機器學習模型)去預測,然后進行預測分量的重構以實現高精度預測。

創新1:通過CNN卷積池化層降低序列長度,增加數據維度,然后再送入Transformer編碼器層進行特征增強,利用多頭注意力和其優越的網絡結構融合空間特征和時域特征;
創新2:把 CEEMDAN 算法對時間序列分解后的分量通過樣本熵的計算進行劃分,再分別通過 CNN-Transfromer 模型 和 XGBoost 模型進行組合預測,來實現精準預測。
注意:此次產品,我們還有配套的模型講解和參數調節講解!

前言
本文基于前期介紹的電力變壓器(文末附數據集),介紹一種綜合應用完備集合經驗模態分解CEEMDAN與組合預測模型(CNN-Transformer +?XGBoost)的方法,以提高時間序列數據的預測性能。該方法的核心是使用CEEMDAN算法對時間序列進行分解,接著利用CNN-Transformer模型和XGBoost模型對分解后的數據進行建模,最終通過集成方法結合兩者的預測結果。
電力變壓器數據集的詳細介紹可以參考下文:
電力變壓器數據集介紹和預處理-CSDN博客
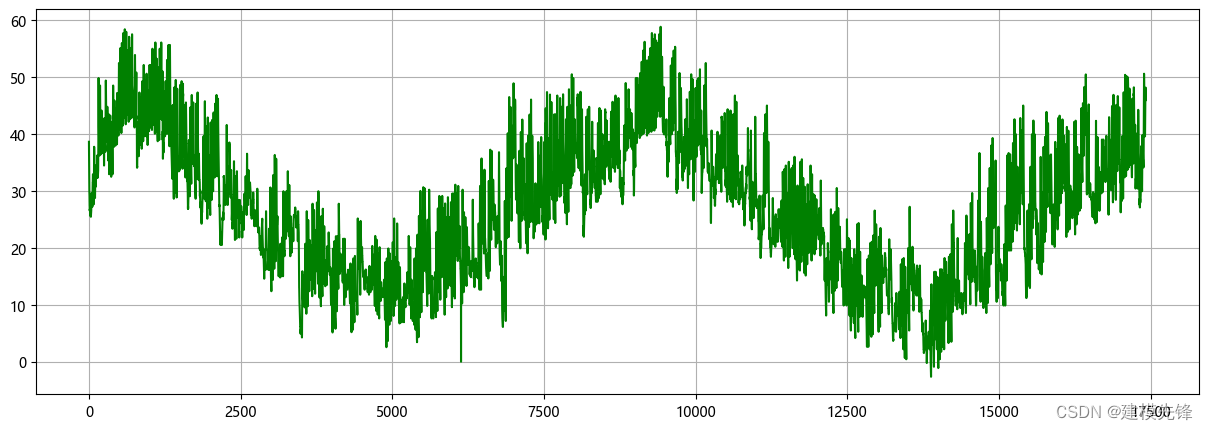
1 電力變壓器數據CEEMDAN分解與可視化
1.1 導入數據
1.2 CEEMDAN分解
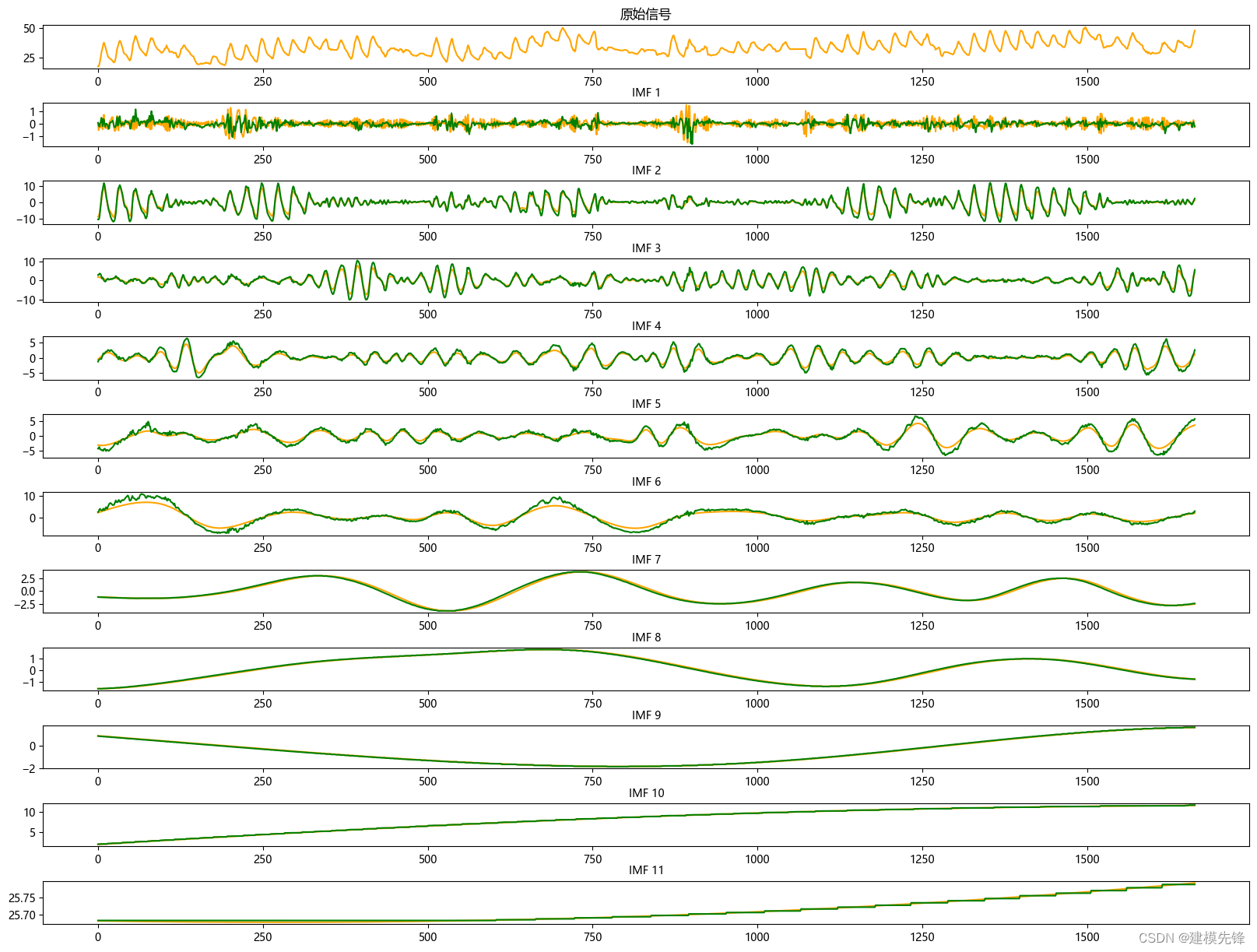
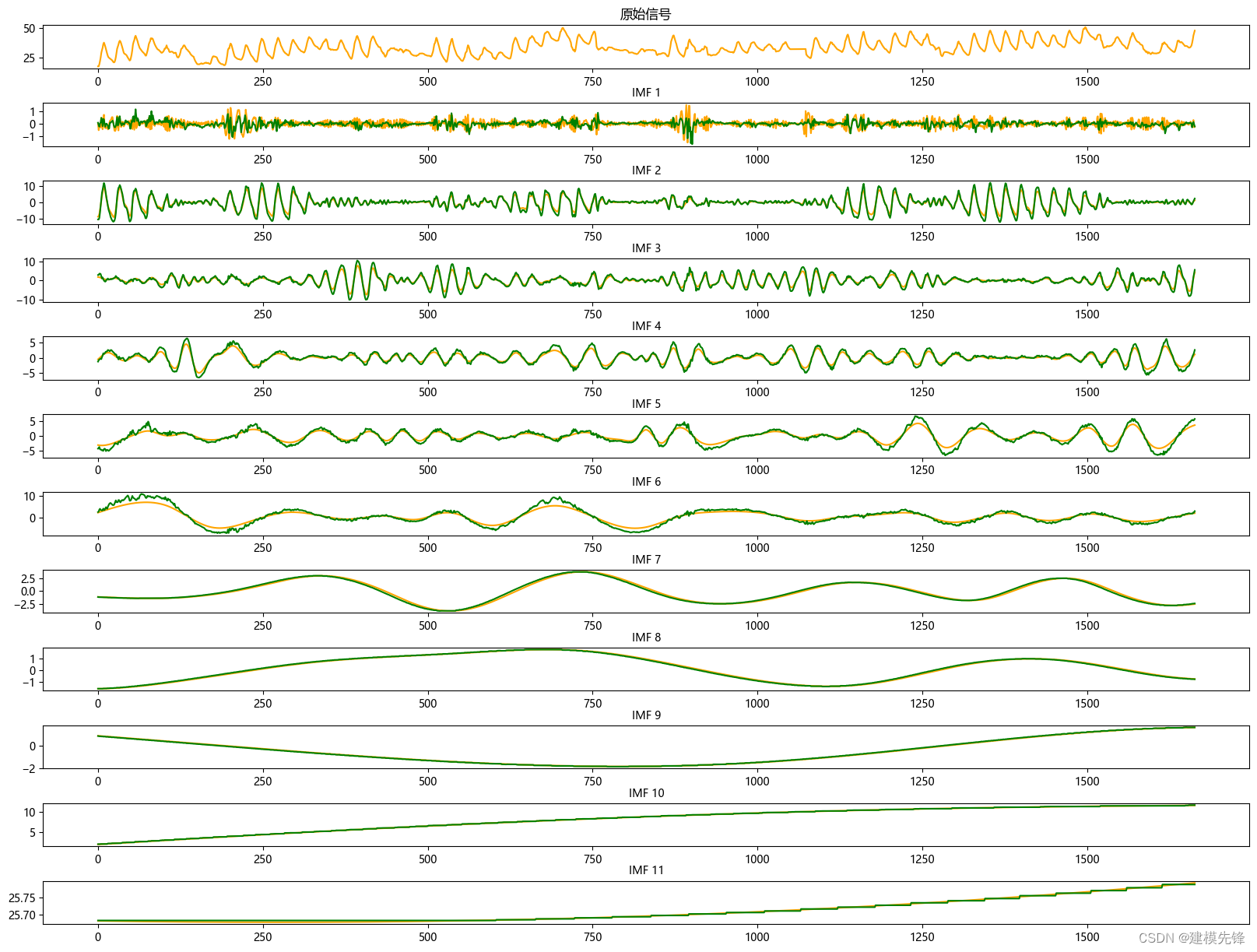
根據分解結果看,CEEMDAN一共分解出11個分量,然后通過計算每個分量的樣本熵值進行分析。
樣本熵是一種用于衡量序列復雜度的方法,可以通過計算序列中的不確定性來評估其復雜性。樣本熵越高,表示序列的復雜度越大。
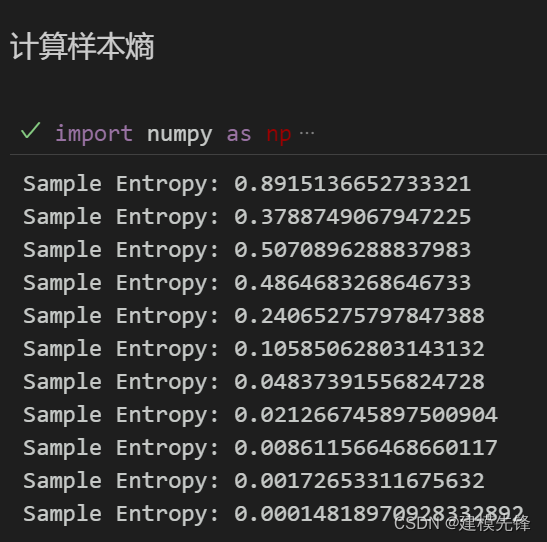
我們大致把前6個高樣本熵值復雜分量作為CNN-Transformer模型的輸入進行預測,后5個低樣本熵值簡單分量作為XGBoost模型的輸入進行預測.
2 數據集制作與預處理
2.1 劃分數據集
按照9:1劃分訓練集和測試集, 然后再按照前6后5劃分分量數據。
在處理LSTF問題時,選擇合適的窗口大小(window size)是非常關鍵的。選擇合適的窗口大小可以幫助模型更好地捕捉時間序列中的模式和特征,為了提取序列中更長的依賴建模,本文把窗口大小提升到48,運用CCEMDAN-CNN-Transformer模型來充分提取前6個分量序列中的特征信息。
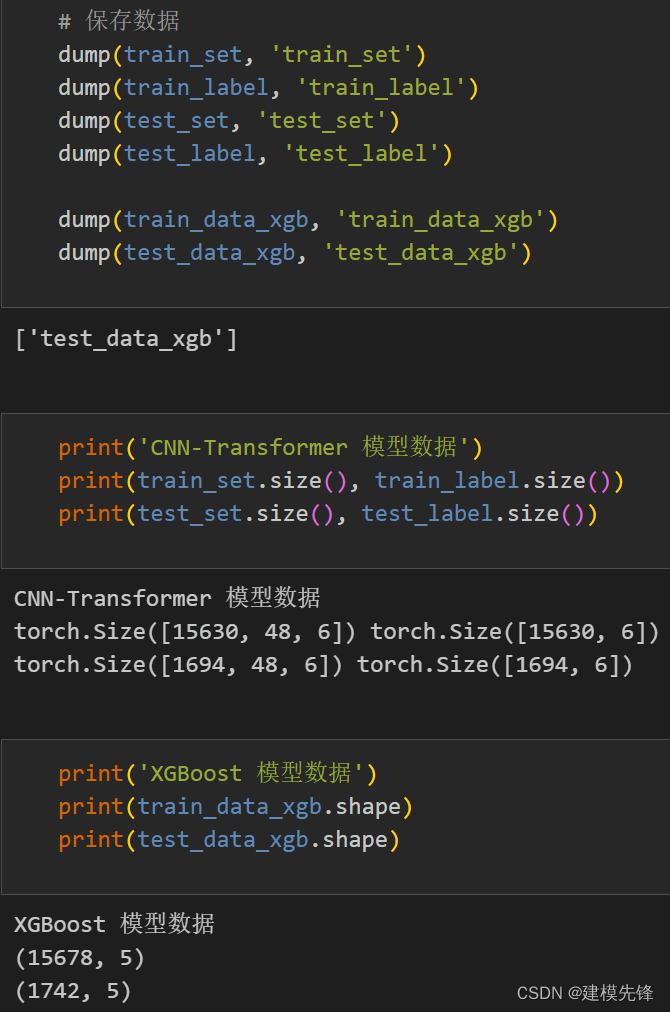
分批保存數據,用于不同模型的預測
3 基于CEEMADN的組合預測模型
3.1?定義CNN-Transformer網絡模型

3.2 設置參數,訓練模型

50個epoch,MSE 為0.002122,CNN-Transformer預測效果顯著,模型能夠充分提取時間序列的時序特征和空間特征,收斂速度快,性能優越,預測精度高,適當調整模型參數,還可以進一步提高模型預測表現。
注意調整參數:
-
可以適當增加CNN層數和每層的維度,微調學習率;
-
調整Transformer編碼器層數、多頭注意力頭數、注意力維度數,增加更多的 epoch (注意防止過擬合)
-
可以改變滑動窗口長度(設置合適的窗口長度)
保存訓練結果和預測數據,以便和后面XGBoost模型的結果相組合。
4 基于XGBoost的模型預測
傳統機器學習模型 XGBoost 教程如下:
超強預測算法:XGBoost預測模型-CSDN博客
數據加載,訓練數據、測試數據分組,5個分量,劃分5個數據集
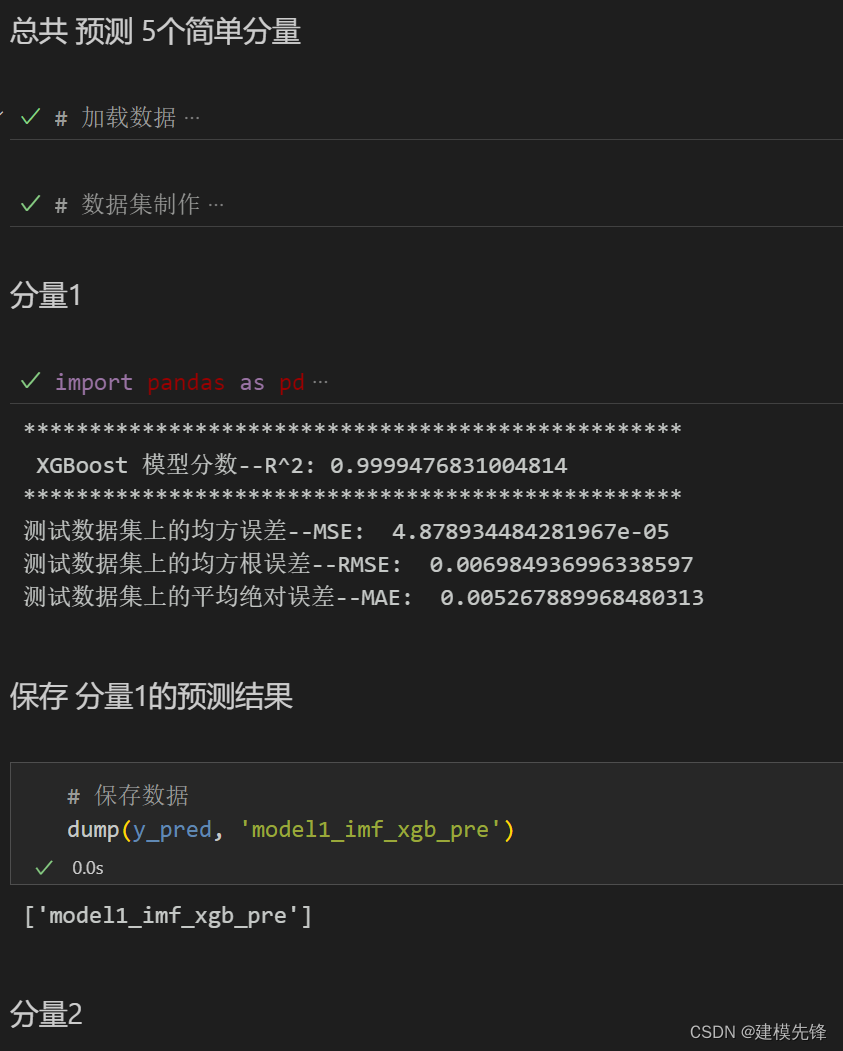
保存預測的數據,其他分量預測與上述過程一致,保留最后模型結果即可。
5 結果可視化和模型評估
5.1 分量預測結果可視化
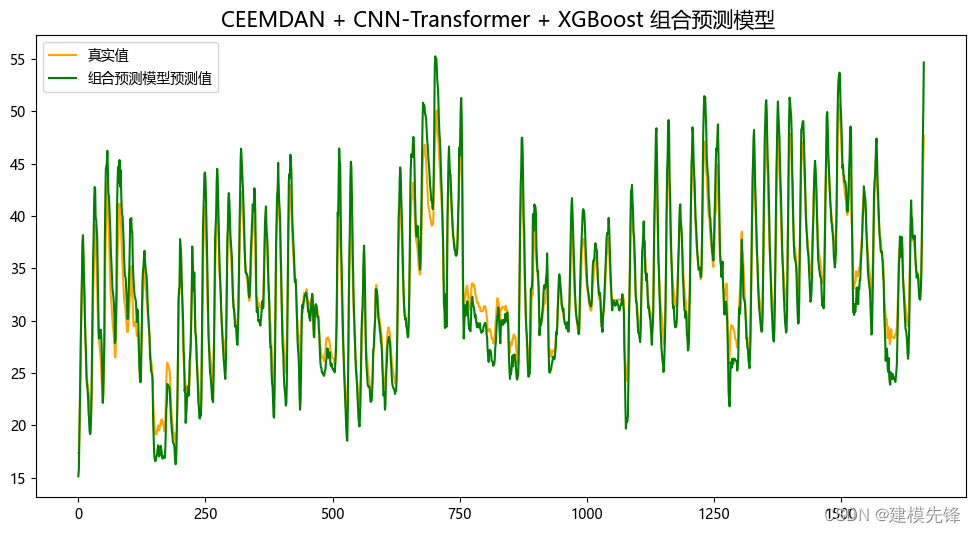
5.2 組合預測結果可視化
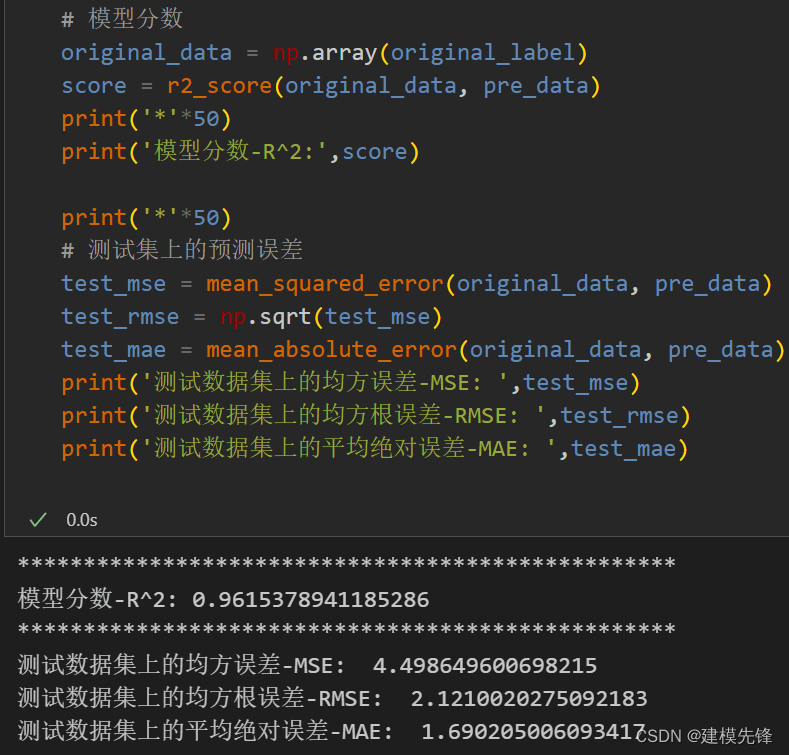
5.3 模型評估
由分量預測結果可見,前6個復雜分量在CNN-Transformer預測模型下擬合效果良好,后5個簡單分量在XGBoost模型的預測下,擬合程度特別好,組合預測效果顯著!
代碼、數據如下:
對數據集和代碼感興趣的,可以關注最后一行
# 加載數據
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 參數與配置
torch.manual_seed(100) # 設置隨機種子,以使實驗結果具有可重復性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#代碼和數據集:https://mbd.pub/o/bread/mbd-ZZ6ZmJtq

 |深入解析客戶端緩存與服務器緩存:HTTP緩存控制頭字段及優化實踐)











 | 最佳聚類數的判定)




)
