技術背景
最近和大模型一起爆火的,還有大模型的微調方法。
這類方法只用很少的數據,就能讓大模型在原本表現沒那么好的下游任務中“脫穎而出”,成為這個任務的專家。
而其中最火的大模型微調方法,又要屬LoRA。
增加數據量和模型的參數量是公認的提升神經網絡性能最直接的方法。目前主流的大模型的參數量已擴展至千億級別,「大模型」越來越大的趨勢還將愈演愈烈。
這種趨勢帶來了多方面的算力挑戰。想要微調參數量達千億級別的大語言模型,不僅訓練時間長,還需占用大量高性能的內存資源。
為了讓大模型微調的成本「打下來」,微軟的研究人員開發了低秩自適應(LoRA)技術。LoRA 的精妙之處在于,它相當于在原有大模型的基礎上增加了一個可拆卸的插件,模型主體保持不變。LoRA 隨插隨用,輕巧方便。
對于高效微調出一個定制版的大語言模型或者大視覺、大多模態模型來說,LoRA 是最為廣泛運用的方法之一,同時也是最有效的方法之一。
LoRA微調原理是對預訓練模型進行凍結,并在凍結的前提下,向模型中加入額外的網絡層,然后只訓練這些新增網絡層的參數。因為新增參數數量較少,所以finetune的成本顯著下降,同時也能獲得和全模型微調類似的效果。
LoRA方法的核心思想是,這些大型模型其實是過度參數化的,其中的參數變化可以視為一個低秩矩陣。因此,可以將這個參數矩陣分解成兩個較小的矩陣的乘積。在微調過程中,不需要調整整個大型模型的參數,只需要調整低秩矩陣的參數。
有了LoRA這類型的微調方法,可以使得大模型平易近人,可以讓更多小公司或個人使用者能簡單的在我們自己的數據集中調優模型,微調得到我們期望的輸出。
LoRA 簡介
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGEMODELS 該文章在ICLR2022中提出,說的是利用低秩適配(low-rankadaptation)的方法,可以在使用大模型適配下游任務時只需要訓練少量的參數即可達到一個很好的效果。
由于 GPU 內存的限制,在訓練過程中更新模型權重成本高昂。
例如,假設我們有一個 7B 參數的語言模型,用一個權重矩陣 W 表示。在反向傳播期間,模型需要學習一個 ΔW 矩陣,旨在更新原始權重,讓損失函數值最小。
權重更新如下:W_updated = W + ΔW。
如果權重矩陣 W 包含 7B 個參數,則權重更新矩陣 ΔW 也包含 7B 個參數,計算矩陣 ΔW 非常耗費計算和內存。
由 Edward Hu 等人提出的 LoRA 將權重變化的部分 ΔW 分解為低秩表示。確切地說,它不需要顯示計算 ΔW。相反,LoRA 在訓練期間學習 ΔW 的分解表示,如下圖所示,這就是 LoRA 節省計算資源的奧秘。
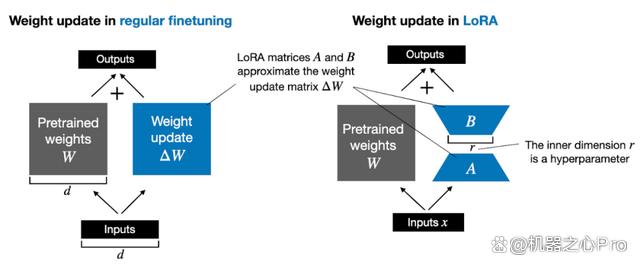
如上所示,ΔW 的分解意味著我們需要用兩個較小的 LoRA 矩陣 A 和 B 來表示較大的矩陣 ΔW。如果 A 的行數與 ΔW 相同,B 的列數與 ΔW 相同,我們可以將以上的分解記為 ΔW = AB。(AB 是矩陣 A 和 B 之間的矩陣乘法結果。)
這種方法節省了多少內存呢?還需要取決于秩 r,秩 r 是一個超參數。例如,如果 ΔW 有 10,000 行和 20,000 列,則需存儲 200,000,000 個參數。如果我們選擇 r=8 的 A 和 B,則 A 有 10,000 行和 8 列,B 有 8 行和 20,000 列,即 10,000×8 + 8×20,000 = 240,000 個參數,比 200,000,000 個參數少約 830 倍。
當然,A 和 B 無法捕捉到 ΔW 涵蓋的所有信息,但這是 LoRA 的設計所決定的。在使用 LoRA 時,我們假設模型 W 是一個具有全秩的大矩陣,以收集預訓練數據集中的所有知識。當我們微調 LLM 時,不需要更新所有權重,只需要更新比 ΔW 更少的權重來捕捉核心信息,低秩更新就是這么通過 AB 矩陣實現的。
LoRA是怎么去微調適配下游任務的?
流程很簡單,LoRA利用對應下游任務的數據,只通過訓練新加部分參數來適配下游任務。
而當訓練好新的參數后,利用重參的方式,將新參數和老的模型參數合并,這樣既能在新任務上到達fine-tune整個模型的效果,又不會在推斷的時候增加推斷的耗時。
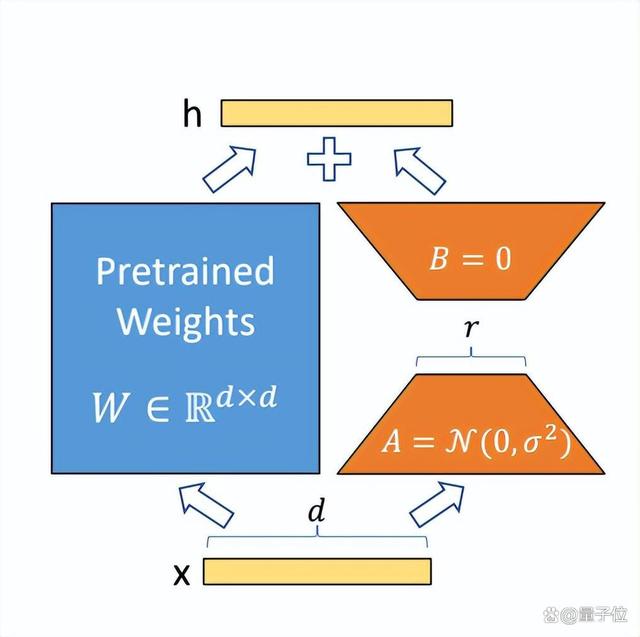
圖中藍色部分為預訓練好的模型參數,LoRA在預訓練好的模型結構旁邊加入了A和B兩個結構,這兩個結構的參數分別初始化為高斯分布和0,那么在訓練剛開始時附加的參數就是0。
A的輸入維度和B的輸出維度分別與原始模型的輸入輸出維度相同,而A的輸出維度和B的輸入維度是一個遠小于原始模型輸入輸出維度的值,這也就是low-rank的體現(有點類似Resnet的結構),這樣做就可以極大地減少待訓練的參數了。
在訓練時只更新A、B的參數,預訓練好的模型參數是固定不變的。在推斷時可以利用重參數(reparametrization)思想,將AB與W合并,這樣就不會在推斷時引入額外的計算了。
而且對于不同的下游任務,只需要在預訓練模型基礎上重新訓練AB就可以了,這樣也能加快大模型的訓練節奏。
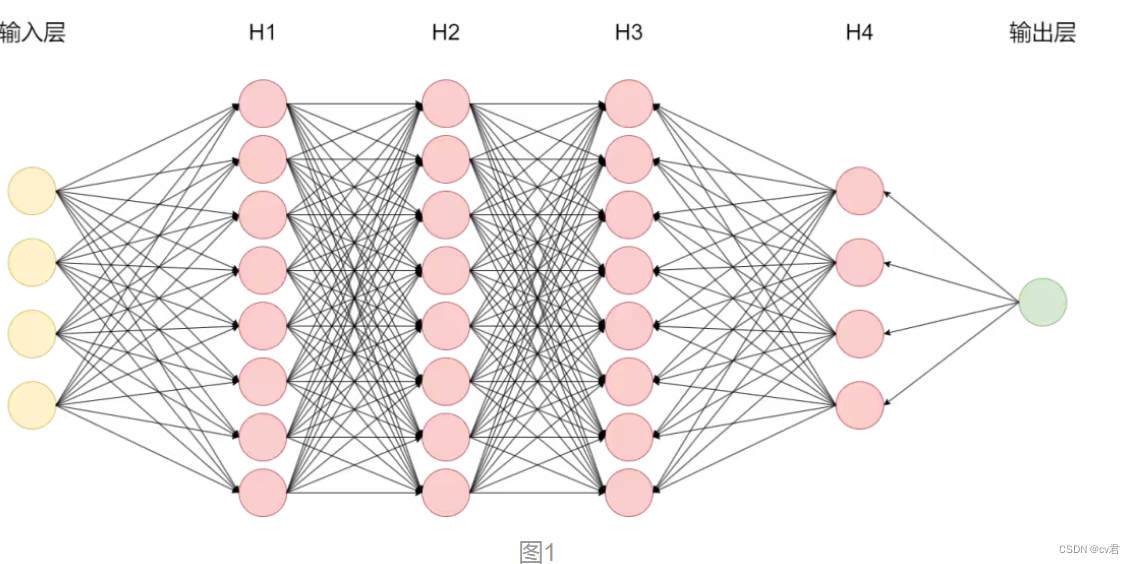
之前在基地的ChatGPT分享中提到過LLM的工作原理是根據輸入文本通過模型神經網絡中各個節點來預測下一個字,以自回歸生成的方式完成回答。
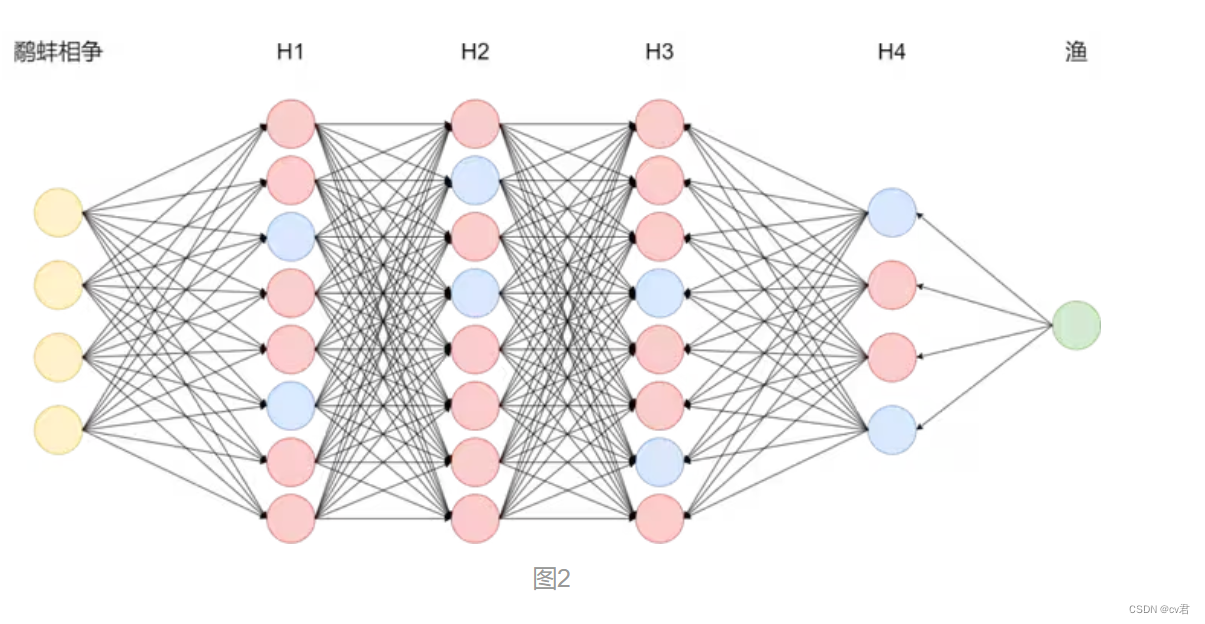
實際上,模型在整個自回歸生成過程中決定最終答案的神經網絡節點只占總節點的極少一部分。如圖1所示為多級反饋神經網絡,以輸入鷸蚌相爭為例,真正參與運算的節點如下圖2藍色節點所示,實際LLM的節點數有數億之多,我們稱之為參數量。 作者:神州數碼云基地
神經網絡包含許多稠密層,執行矩陣乘法運算。這些層中的權重矩陣通常具有滿秩。LLM具有較低的“內在維度”,即使在隨機投影到較小子空間時,它們仍然可以有效地學習。
假設權重的更新在適應過程中也具有較低的“內在秩”。對于一個預訓練的權重矩陣W0 ∈ Rd×k,我們通過低秩分解W0 + ?W = W0 + BA來表示其更新,其中B ∈ Rd×r,A ∈ Rr×k,且秩r ≤ min(d,k)。在訓練過程中,W0被凍結,不接收梯度更新,而A和B包含可訓練參數。需要注意的是,W0和?W = BA都與相同的輸入進行乘法運算,它們各自的輸出向量在坐標上求和。前向傳播公式如下:h = W0x + ?Wx = W0x + BAx
在圖3中我們對A使用隨機高斯隨機分布初始化,對B使用零初始化,因此在訓練開始時?W = BA為零。然后,通過αr對?Wx進行縮放,其中α是r中的一個常數。在使用Adam優化時,適當地縮放初始化,調整α的過程與調整學習率大致相同。因此,只需將α設置為我們嘗試的第一個r,并且不對其進行調整。這種縮放有助于在改變r時減少重新調整超參數的需求。
LoRa微調ChatGLM-6B
有時候我們想讓模型幫我們完成一些特定任務或改變模型說話的方式和自我認知。作為定制化交付中心的一員,我需要讓“他”加入我們。先看一下模型原本的輸出。

接下來我將使用LoRa微調將“他”變成定制化交付中心的一員。具體的LoRa微調及微調源碼請前往Confluence查看LoRa高效參數微調準備數據集我們要準備的數據集是具有針對性的,例如你是誰?你叫什么?誰是你的設計者?等等有關目標身份的問題,答案則按照我們的需求進行設計,這里列舉一個例子

設置參數進行微調
CUDA_VISIBLE_DEVICES=0 python ../src/train_sft.py \--do_train \--dataset self \--dataset_dir ../data \--finetuning_type lora \--output_dir path_to_sft_checkpoint \--overwrite_cache \--per_device_train_batch_size 4 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-5 \--num_train_epochs 3.0 \--plot_loss \--fp16 影響模型訓練效果的參數主要有下面幾個 lora_rank(int,optional): LoRA 微調中的秩大小。這里并不是越大越好,對于小型數據集如果r=1就可以達到很不錯的效果,即便增加r得到的結果也沒有太大差別。 ? lora_alpha(float,optional): LoRA 微調中的縮放系數。 ? lora_dropout(float,optional): LoRA 微調中的 Dropout 系數。 ? learning_rate(float,optional): AdamW 優化器的初始學習率。如果設置過大會出現loss值無法收斂或過擬合現象即過度適應訓練集而喪失泛化能力,對非訓練集中的數據失去原本的計算能力。 ? num_train_epochs(float,optional): 訓練輪數,如果loss值沒有收斂到理想值可以增加訓練輪數或適當降低學習率。
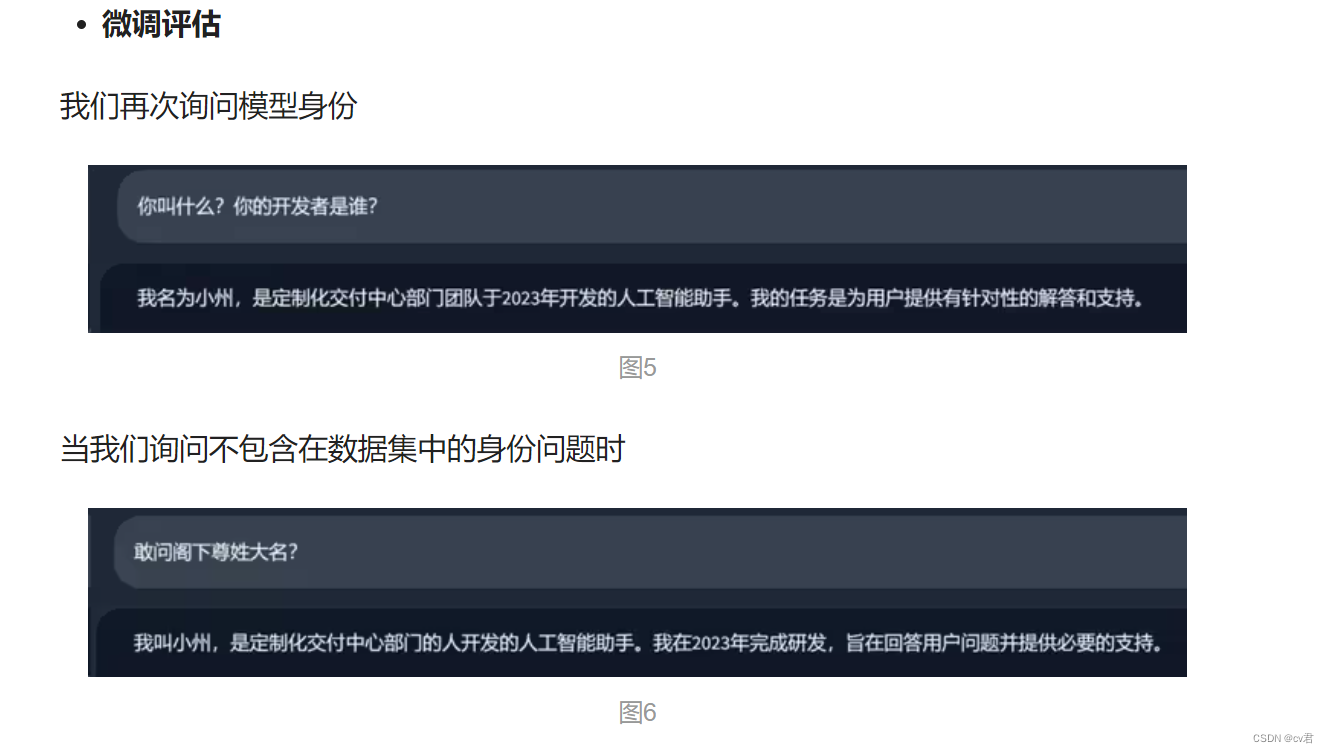
很好,我們得到了理想的回答,這說明“小州”的人設已經建立成功了,換句話說,圖二中藍色節點(身份信息)的權重已經改變了,之后任何關于身份的問題都會是以“小州”的人設進行回答。
LoRA使用
HuggingFace的PEFT(Parameter-Efficient Fine-Tuning)中提供了模型微調加速的方法,參數高效微調(PEFT)方法能夠使預先訓練好的語言模型(PLMs)有效地適應各種下游應用,而不需要對模型的所有參數進行微調。
對大規模的PLM進行微調往往成本過高,在這方面,PEFT方法只對少數(額外的)模型參數進行微調,基本思想在于僅微調少量 (額外) 模型參數,同時凍結預訓練 LLM 的大部分參數,從而大大降低了計算和存儲成本,這也克服了災難性遺忘的問題,這是在 LLM 的全參數微調期間觀察到的一種現象PEFT 方法也顯示出在低數據狀態下比微調更好,可以更好地泛化到域外場景。
例如,使用PEFT-lora進行加速微調的效果如下,從中我們可以看到該方案的優勢: 
## 1、引入組件并設置參數
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType
import torch
from datasets import load_dataset
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
?
## 2、搭建模型
?
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
?
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
?
## 3、加載數據
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
?
classes = dataset["train"].features["label"].names
dataset = dataset.map(lambda x: {"text_label": [classes[label] for label in x["label"]]},batched=True,num_proc=1,
)
?
## 4、訓練數據預處理
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
?
def preprocess_function(examples):inputs = examples[text_column]targets = examples[label_column]model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")labels = labels["input_ids"]labels[labels == tokenizer.pad_token_id] = -100model_inputs["labels"] = labelsreturn model_inputs
?
?
processed_datasets = dataset.map(preprocess_function,batched=True,num_proc=1,remove_columns=dataset["train"].column_names,load_from_cache_file=False,desc="Running tokenizer on dataset",
)
?
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
?
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
?
## 5、設定優化器和正則項
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0,num_training_steps=(len(train_dataloader) * num_epochs),
)
?
## 6、訓練與評估
?
model = model.to(device)
?
for epoch in range(num_epochs):model.train()total_loss = 0for step, batch in enumerate(tqdm(train_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.losstotal_loss += loss.detach().float()loss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()
?model.eval()eval_loss = 0eval_preds = []for step, batch in enumerate(tqdm(eval_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)loss = outputs.losseval_loss += loss.detach().float()eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True))eval_epoch_loss = eval_loss / len(eval_dataloader)eval_ppl = torch.exp(eval_epoch_loss)train_epoch_loss = total_loss / len(train_dataloader)train_ppl = torch.exp(train_epoch_loss)print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
?
## 7、模型保存
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
?
## 8、模型推理預測
?
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)model = PeftModel.from_pretrained(model, peft_model_id)
model.eval()
?
inputs = tokenizer(dataset["validation"][text_column][i], return_tensors="pt")
print(dataset["validation"][text_column][i])
print(inputs)
with torch.no_grad():outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)print(outputs)print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))?
提問
LoRA 的權重可以組合嗎?
答案是肯定的。在訓練期間,我們將 LoRA 權重和預訓練權重分開,并在每次前向傳播時加入。
假設在現實世界中,存在一個具有多組 LoRA 權重的應用程序,每組權重對應著一個應用的用戶,那么單獨儲存這些權重,用來節省磁盤空間是很有意義的。同時,在訓練后也可以合并預訓練權重與 LoRA 權重,以創建一個單一模型。這樣,我們就不必在每次前向傳遞中應用 LoRA 權重。
weight += (lora_B @ lora_A) * scaling
我們可以采用如上所示的方法更新權重,并保存合并的權重。
同樣,我們可以繼續添加很多個 LoRA 權重集:
weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
我還沒有做實驗來評估這種方法,但通過 Lit-GPT 中提供的 scripts/merge_lora.py 腳本已經可以實現。
腳本鏈接:https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.py
-
如果要結合 LoRA,確保它在所有層上應用,而不僅僅是 Key 和 Value 矩陣中,這樣才能最大限度地提升模型的性能。
-
調整 LoRA rank 和選擇合適的 α 值至關重要。提供一個小技巧,試試把 α 值設置成 rank 值的兩倍。
-
14GB RAM 的單個 GPU 能夠在幾個小時內高效地微調參數規模達 70 億的大模型。對于靜態數據集,想要讓 LLM 強化成「全能選手」,在所有基線任務中都表現優異是不可能完成的。想要解決這個問題需要多樣化的數據源,或者使用 LoRA 以外的技術。
LoRA可以用于視覺任務嗎?
可以的,經常結合stable diffusion等大模型進行微調,在aigc中經常使用,下期我們深入分析lora和lora該如何進行優化。
總結
針對LLM的主流微調方式有P-Tuning、Freeze、LoRa、instruct等等。由于LoRa的并行低秩矩陣幾乎沒有推理延遲被廣泛應用于transformers模型微調,另一個原因是ROI過低,對LLM的FineTune所需要的計算資源不是普通開發者或中小型企業愿意承擔的。而LoRa將訓練參數減少到原模型的千萬分之一的級別使得在普通計算資源下也可以實現FineTune。







讀取不到數據的可能原因)
![[LLM]從GPT-4o原理到下一代人機交互技術](http://pic.xiahunao.cn/[LLM]從GPT-4o原理到下一代人機交互技術)


特點和規格)
7-5 sdut-C語言實驗-鏈表的逆置)





)
