 標題:基于骨架的動作識別的生成動作描述提示
標題:基于骨架的動作識別的生成動作描述提示
源文鏈接:https://openaccess.thecvf.com/content/ICCV2023/papers/Xiang_Generative_Action_Description_Prompts_for_Skeleton-based_Action_Recognition_ICCV_2023_paper.pdf![]() https://openaccess.thecvf.com/content/ICCV2023/papers/Xiang_Generative_Action_Description_Prompts_for_Skeleton-based_Action_Recognition_ICCV_2023_paper.pdf
https://openaccess.thecvf.com/content/ICCV2023/papers/Xiang_Generative_Action_Description_Prompts_for_Skeleton-based_Action_Recognition_ICCV_2023_paper.pdf
源碼鏈接:GitHub - MartinXM/GAP: official implementation for Language Supervised Training for Skeleton-based Action Recognition![]() https://github.com/MartinXM/GAP
https://github.com/MartinXM/GAP
?發表:ICCV-2023
目錄
摘要
1. 介紹
2. 相關工作
2.1. 基于骨骼的動作識別
2.2. 人體部位先驗
2.3. 多模態表示學習
3. 方法
3.1. 生成式動作提示框架
3.2. 骨架編碼器
3.3. 文本編碼器
3.4. 動作描述學習
3.5 動作描述生成
4實驗
4.1. 數據集
4.2. 實現細節
4.3.?消融實驗
4.4. 與最新技術的比較
4.5. 討論
5. 結論
讀后總結
摘要
骨架動作識別最近受到了廣泛關注。當前的骨架動作識別方法通常被形式化為獨熱編碼分類任務,并未充分利用動作之間的語義關系。例如,“做勝利手勢”和“豎起大拇指”是兩種手勢動作,它們的主要區別在于手部的運動。這些信息在動作類別的獨熱編碼中是不可見的,但可以通過動作描述來揭示。因此,在訓練中利用動作描述可能有助于表示學習。在這項工作中,我們提出了一種用于骨架動作識別的生成式動作描述提示(GAP)方法。更具體地說,我們采用預訓練的大規模語言模型作為知識引擎,自動生成身體部位動作的文本描述,并提出了一種多模態訓練方案,通過利用文本編碼器為不同的身體部位生成特征向量,并監督骨架編碼器進行動作表示學習。實驗表明,我們提出的GAP方法在沒有增加推理階段額外計算成本的情況下,比各種基線模型取得了顯著的改進。GAP在流行的骨架動作識別基準上達到了新的最先進水平,包括NTU RGB+D、NTU RGB+D 120和NW-UCLA。源代碼可在https://github.com/MartinXM/GAP獲取。
1. 介紹
動作識別由于其在人機交互、體育與健康分析、娛樂等方面的廣泛應用,一直是一個活躍的研究課題。近年來,隨著深度傳感器(如 Kinect [44] 和 RealSense [14])的出現,人類身體關節數據變得易于獲取。利用身體關節進行動作識別的方法,即所謂的基于骨架的動作識別,由于其計算效率高以及對光照條件、視角變化和背景噪聲的魯棒性,吸引了大量關注。
大多數之前的基于骨架的動作識別方法集中于建模人體關節之間的關系,采用單模態訓練方案,以一系列骨架坐標作為輸入【41, 15, 27, 9, 28, 4, 25, 40, 30, 36, 35, 22】。受最近圖像和語言多模態訓練成功的啟發【23, 1】,我們提出了一個有趣的問題:動作語言描述能否揭示動作關系并有助于基于骨架的動作識別?遺憾的是,由于缺乏包含骨架-文本對的大規模數據集,構建這樣的數據集將需要大量的時間和財力資源。因此,【23, 11, 39】中描述的訓練方案不能直接應用于基于骨架的動作識別。因此,開發新的多模態訓練范式以解決這一問題是必要的。
我們提出利用以語言提示的形式生成類別級人類動作描述。動作的語言定義包含豐富的先驗知識。例如,不同的動作聚焦于不同身體部位的運動:“做勝利手勢”和“豎起大拇指”描述手部的手勢動作;“劃圈”和“揮動網球拍”描述手臂的運動;“點頭”和“搖頭”是頭部的動作;“跳躍”和“側踢”依賴于腳和腿的運動。一些動作描述了多個身體部位的互動,例如,“戴帽子”和“穿鞋”涉及手和頭、手和腳的動作。這些關于動作的先驗知識可以為表示學習提供細粒度的指導。此外,為了解決收集人類動作提示的繁瑣工作,我們求助于預訓練的大型語言模型(LLM),例如 GPT-3 [1],以便高效地自動生成提示。
具體而言,我們開發了一種新的訓練范式,利用生成式動作提示進行基于骨架的動作識別。我們利用 GPT-3 [1] 作為我們的知識引擎,為動作生成有意義的文本描述,通過精心設計的文本提示,可以生成整個動作以及每個身體部位的詳細文本描述。在圖1中,我們將我們提出的框架(b)和(c)與傳統的單編碼器基于骨架的動作識別框架(a)進行了比較。在我們的框架中,開發了一種多模態訓練方案,其中包含一個骨架編碼器和一個文本編碼器。骨架編碼器將骨架坐標作為輸入,并生成部分特征向量和全局特征表示。文本編碼器將全局動作描述或身體部位描述轉換為整個動作或每個身體部位的文本特征。多部分對比損失(對于(b)為單一對比損失)用于對齊文本部分特征和骨架部分特征,并且交叉熵損失應用于全局特征上。

圖1:我們提出的生成式動作描述提示(GAP)框架(雙編碼器)與其他骨架識別方法(單編碼器)的比較。除了分類損失外,我們提出的方法還包含額外的對比損失。請注意,文本編碼器僅在訓練階段使用,GPT-3 用于離線動作描述生成。對于每個給定的動作查詢,GPT-3 生成帶有提示模板的動作文本描述,然后將該動作描述用于多模態訓練。
我們的貢獻總結如下:
- 據我們所知,這是第一項利用生成式提示進行基于骨架的動作識別的工作,該方法將LLM作為知識引擎,并精心利用文本提示自動生成不同動作的整體動作和身體部位運動的詳細文本描述。
- 我們提出了一種新的多模態訓練范式,利用生成式動作提示指導基于骨架的動作識別,通過利用動作和人體部位的知識增強了表示。這種方法在推理階段不增加任何計算成本,可提高模型性能。
- 借助所提出的訓練范式,我們在幾個流行的基于骨架的動作識別基準上取得了最先進的性能,包括NTU RGB+D、NTU RGB+D 120和NW-UCLA。
2. 相關工作
2.1. 基于骨骼的動作識別
近年來,通過設計高效有效的模型架構,針對基于骨架的動作識別提出了各種方法。在[9, 28, 41]中,RNN被應用于處理人體關節的序列。HBRNN [9] 使用端到端的分層RNN來建模時間骨架序列的長期上下文信息。VA-LSTM [41] 設計了一個視角自適應的RNN,使網絡能夠端到端地適應最合適的觀察視角。受CNN在圖像任務中的成功啟發,基于CNN的方法[42, 37] 被用來建模關節之間的關系。在[37]中提出了一個純CNN架構,名為拓撲感知CNN(TA-CNN)。由于人體關節可以自然地表示為圖節點,并且關節連接可以用鄰接矩陣描述,因此基于GCN的方法[38, 4, 25, 2, 30]引起了很多關注。例如,ST-GCN [38] 應用了時空GCN來模擬人體關節在空間和時間維度上的關系。CTR-GCN [2] 提出了一種通道級圖卷積用于精細的關系建模。Info-GCN [6] 在GCN中采用了信息瓶頸。隨著視覺Transformer [8]的近期流行,基于Transformer的方法[22, 26, 35] 也被用于骨架數據的研究。所有先前的方法都采用了單模態訓練方案。據我們所知,我們的工作是第一個將多模態訓練方案應用于基于骨架的動作識別的工作。
2.2. 人體部位先驗
在先前的工作中,為了基于骨架的動作識別,已經通過設計特殊的模型架構使用了人體部位先驗[32, 29, 35, 10]。PB-GCN [32] 將骨架圖劃分為四個子圖,并使用基于部位的圖卷積網絡學習識別模型。PA-ResGCN [29] 計算了人體各部位的注意力權重,以提高特征的判別能力。PL-GCN [10] 提出了一個部位級別的圖卷積網絡,自動學習部位劃分策略。IIP-transformer [35] 應用了Transformer來學習部位間和部位內的關系。與先前的方法相比,我們直接使用部分語言描述來指導多部分對比損失訓練過程中的表示學習。我們沒有設計任何復雜的部位建模模塊,因此在推理階段不會增加額外的計算成本。
2.3. 多模態表示學習
多模態表示學習方法,如CLIP [23] 和 ALIGN [11],已經表明,視覺-語言聯合訓練可以為零樣本學習、圖像描述生成、文本-圖像檢索等下游任務學習強大的表示。UniCL [39] 使用了一種統一的對比學習方法,將圖像標簽視為圖像-文本-標簽數據,以學習通用的視覺-語義空間。然而,這些方法需要一個大規模的圖像-文本配對數據集進行訓練。ActionCLIP [34] 遵循了CLIP的訓練方案進行視頻動作識別,使用了預訓練的CLIP模型,并添加了Transformer層來對視頻數據進行時間建模。至于動作描述,標簽名稱直接作為文本提示,前綴和后綴不包含太多語義意義,例如,“一個關于[action name]的視頻”,“人類動作[action name]”等。相比之下,我們使用LLM(GPT-3)作為知識引擎,生成動作中人體運動的描述,為表示學習提供細粒度的指導。此外,我們在身體部位上采用多部分對比損失,學習精細的骨架表示。Prompt Learning(PL)[46, 45, 12] 方法旨在通過引入可學習的提示向量解決零樣本學習和少樣本學習帶來的挑戰。雖然PL已經展示了有希望的結果,但學習到的提示向量的可解釋性仍然是一個挑戰。最近,[20] 應用LLM生成零樣本圖像分類的描述。STALE [21] 使用并行分類和定位/分類架構進行零樣本動作檢測。MotionCLIP [31] 旨在將動作潛在空間與CLIP潛在空間對齊,用于3D人體動作生成。ActionGPT [13] 使用LLM生成詳細的動作描述進行動作生成。我們的研究是同時進行且獨立進行的。所有這些方法在推理期間都需要一個文本編碼器,而我們提出的框架僅在訓練階段施加開銷,在測試期間不增加任何計算或內存成本。
3. 方法
在本節中,我們詳細介紹提出的生成式動作描述提示(GAP)框架。GAP旨在利用自動生成的動作描述增強骨架表示學習,并且可以嵌入到現有的主干網絡中。因此,GAP可以與各種骨架和語言編碼器配合使用。在接下來的章節中,我們首先概述GAP框架,然后詳細介紹骨架編碼器、文本編碼器以及GAP的主要組成部分。
3.1. 生成式動作提示框架
我們的GAP方法的綜合框架如圖2所示。它由一個骨架編碼器Es和一個文本編碼器Et組成,分別用于生成骨架特征和文本特征。訓練損失可以表示為:
其中,Lcls是交叉熵分類損失,是多部分對比損失。骨架輸入
,其中B是批量大小,3是坐標參數數量,N和T分別是關節數量和序列長度。λ是可學習的權衡參數。T是LLM生成的文本描述。
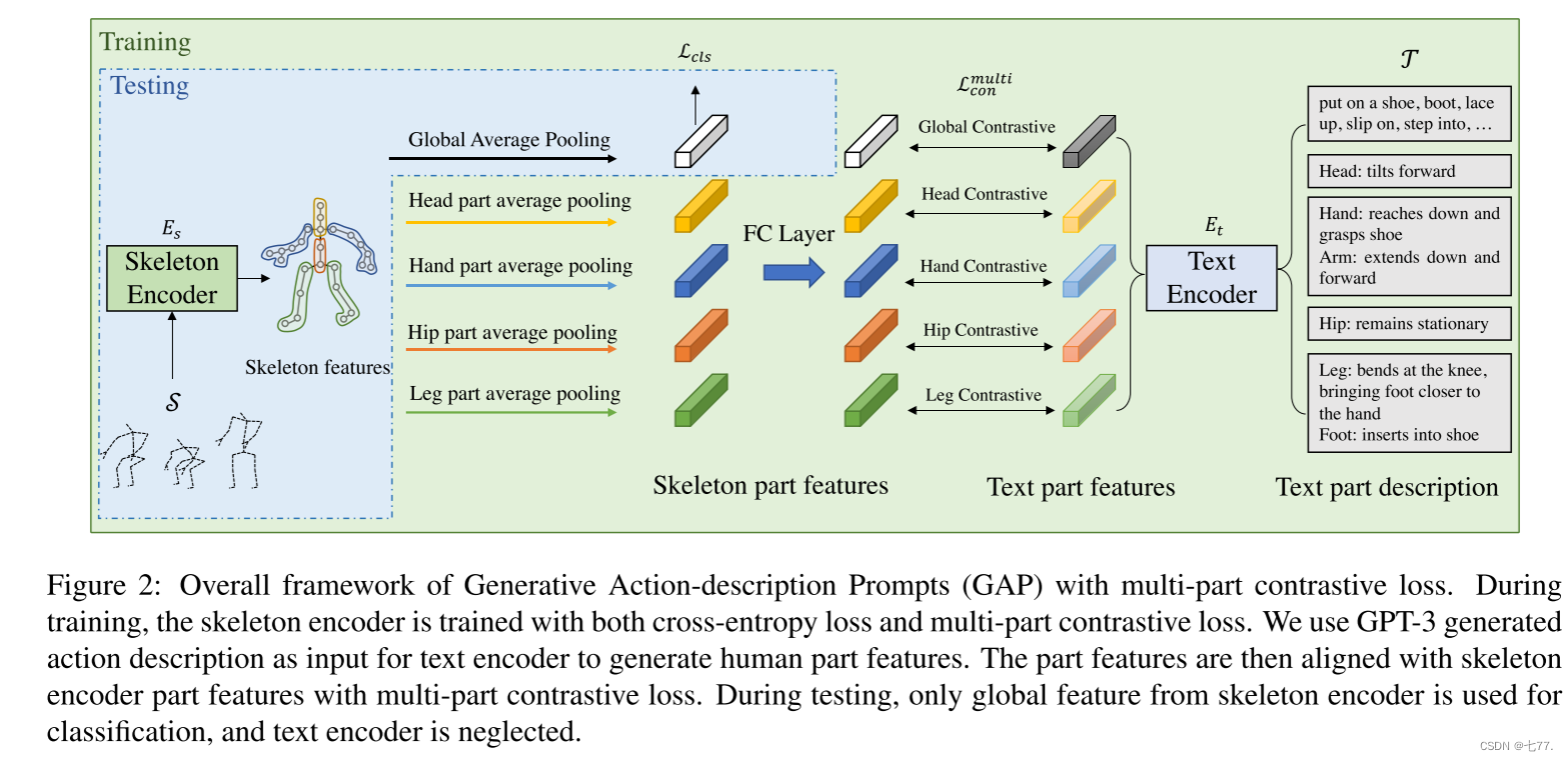
圖2:具有多部分對比損失的生成式動作描述提示(GAP)的總體框架。在訓練期間,骨架編碼器同時使用交叉熵損失和多部分對比損失進行訓練。我們使用GPT-3生成的動作描述作為文本編碼器的輸入,以生成人體部位特征。然后,利用多部分對比損失將部位特征與骨架編碼器的部位特征對齊。在測試期間,只使用來自骨架編碼器的全局特征進行分類,文本編碼器被忽略。
在訓練期間,Es 使用交叉熵損失和多部分對比損失進行訓練,其中部分文本描述作為額外的指導。全局骨架特征通過對所有關節點進行平均池化生成,部分骨架特征通過對各個節點組的特征進行平均池化生成。骨架部分特征通過全連接層(FC層)映射,以保持與文本特征相同的特征維度。文本部分描述由LLM離線生成,并在訓練期間由Et編碼以生成文本部分特征。在測試階段,我們直接使用骨架編碼器的全局特征進行動作概率預測。因此,與先前僅使用骨架編碼器的方法相比,我們的GAP框架在推理時不會增加額外的內存或計算成本。
3.2. 骨架編碼器
由于其高效性和強大性能,圖卷積網絡(GCN)在骨架動作識別中普遍存在。因此,我們在GAP框架中采用GCN作為骨架網絡的主干。我們的骨架編碼器由多個GC-MTC塊組成,每個塊包含一個圖卷積(GC)層和一個多尺度時間卷積(MTC)模塊。
圖卷積。人體骨架可以表示為圖G = {V, E},其中V是人體關節點的集合,|V| = N,E是邊的集合。記為第l層的人體關節特征,特征維度為F。圖卷積可以表述如下:
其中是度矩陣(度表示與該節點相連的邊的數量),A是表示關節連接的鄰接矩陣,
是第l層的可學習參數,σ是激活函數。
這個圖卷積公式是基于譜圖卷積(Spectral Graph Convolution)的理論推導得來的。在這個公式中:
- H_l 是輸入圖的節點特征矩陣,H_{l+1}? 是輸出圖的節點特征矩陣。
- A 是圖的鄰接矩陣,表示節點之間的連接關系。
- D 是度矩陣,是一個對角矩陣,其對角線上的元素是每個節點的度數。
- W_l? 是可學習的參數矩陣,用于將輸入特征轉換到輸出特征空間。
- \sigma是激活函數。這個公式的推導基于拉普拉斯矩陣的譜分解。通過度矩陣D的逆平方根和鄰接矩陣 A 的乘積,實現了對節點特征的歸一化處理,這有助于處理圖結構中不同節點度數的影響。然后,通過乘以參數矩陣W_l,將歸一化后的特征進行線性變換。最后,通過激活函數\sigma 進行非線性變換,生成輸出特征矩陣? H_{l+1}。
多尺度時間建模。為了對不同時間尺度下的動作進行建模,我們利用[19, 2]中的多尺度時間卷積模塊進行時間建模。該模塊包括四個不同的分支,每個分支都包含一個1 × 1卷積來減少通道維度。其中有兩個具有不同擴張率(1和2)的時間卷積分支,以及一個最大池化分支,第四個分支僅包含1 × 1卷積。四個分支的輸出被連接起來以產生最終結果。
骨架分類。基于骨架的動作識別方法將人體骨架數據映射到動作標簽的獨熱編碼,這些標簽通過交叉熵損失進行訓練:
其中, y 是獨熱編碼的真實動作標簽, x 是全局骨架特征,是預測的概率分布。
3.3. 文本編碼器
考慮到最近Transformer模型在自然語言處理領域取得的成功,我們采用一個預訓練的基于Transformer的語言模型作為我們的文本編碼器,例如BERT [7] 或 CLIP-text-encoder [23]。輸入以文本的形式呈現,并經過標準的分詞處理。隨后,特征通過一系列Transformer模塊進行處理。最終的輸出是一個表示文本描述的特征向量。對于不同的人體部位,我們使用不同的部位描述作為文本編碼器的輸入。
3.4. 動作描述學習
骨架語言對比學習。相較于骨架分類中的獨熱標簽監督,骨架語言對比學習利用自然語言進行監督。它采用了雙編碼器設計,包括骨架編碼器 和文本編碼器
,分別用于編碼骨架數據和動作描述。這兩個雙編碼器通過在批次內的兩個方向上(從骨架到文本的方向(s→t)和從文本到骨架的方向(t→s))對比骨架-文本對進行聯合優化:
其中,s, t 分別是骨架和文本的編碼特征,sim(s, t) 是余弦相似度, 是溫度參數, B ?是批次大小。與CLIP中的圖像-文本對是一對一映射不同,在我們的設置中,可能存在多個正匹配,不同類別的動作形成負對,因此,我們不使用交叉熵損失,而是使用KL散度作為骨架-文本對比損失:
其中,D 是整個數據集,和
是真實標簽相似度分數,對于負對其概率為0,對于正對其概率為1。ps→t?(s) 是從骨架到文本的方向上的匹配概率分布。
在訓練過程中,對于給定的一對骨架和文本,可能存在多個動作類別的文本描述與之匹配,這些被匹配的文本描述都被認為是正匹配。但是,同時也可能存在其他動作類別的文本描述與該骨架特征形成負對,因為它們與骨架特征的語義不匹配,這些被匹配的文本描述都被認為是負匹配。因此,在這種情況下,對于同一個骨架特征,可能存在多個正匹配和多個負匹配的文本描述。
在這個設置中,每個骨架可以與多個文本描述相匹配,這與 CLIP 中的圖像-文本對是一對一映射不同。這種情況下,采用交叉熵損失可能會帶來一些問題:
多樣性匹配: 對于同一個骨架,可能存在多個動作描述與之相關聯,因此不存在唯一的“正確答案”。在交叉熵損失中,每個樣本只有一個正確的標簽,但在這種情況下,很難確定哪一個是“正確”的標簽。
負樣本處理: 除了存在多個正匹配之外,還可能存在不匹配的負樣本,即來自不同動作類別的文本描述。在交叉熵損失中,負樣本通常被視為來自其他類別,但在這種設置中,負樣本可能與骨架存在某種相似性,因此不適合簡單地將其視為負樣本。
因此,選擇使用 KL 散度作為骨架-文本對比損失的主要原因是,它能夠更好地適應這種多對多的匹配情況,并更準確地衡量模型預測與實際匹配之間的差異。KL 散度損失考慮了匹配概率分布的相對關系,能夠更好地反映模型預測與地面實況之間的相似度。
多部分對比學習。考慮到人體部位的先驗知識,骨架可以被劃分為多個組。我們在圖1(c)中展示了這個框架。我們對不同部位的特征以及全局特征應用對比損失,并提出了多部分對比損失。部分特征可以通過部分匯聚獲得,其中同一組內的關節特征被聚合以生成部分表示。更具體地說,我們選擇最終分類層之前的特征進行部分特征匯聚。在圖3中,我們展示了不同的部分劃分策略。對于兩個部分劃分,整個身體被分為上半身和下半身兩組。對于四個部分劃分,身體被分為四組:頭部、手臂、臀部、腿部。對于六個部分劃分,頭部、手部、臂部、髖部、腿部和腳部分別分組。多部分對比損失的損失函數可以表示為:
其中,K 是骨架被分成的不同部分或組的數量。

3.5 動作描述生成
對于文本編碼器的動作描述 T 在 GAP 中起著至關重要的作用。在這里,我們探討了幾種不同的描述生成方法。圖 4 展示了不同方法生成的動作“穿鞋子”的文本描述。

標簽名稱Label Name。一種直接的方法是直接使用標簽名稱。許多方法 [34] 使用這種類型的文本描述,帶有前綴和后綴,如“[動作]的人類動作”,“[動作],一個動作的視頻”等。雖然這些提示可以提升零樣本和少樣本問題的性能,但在我們的監督學習案例中,由于這些提示不包含關于動作的具有辨別性的語義信息,因此這種方法并沒有帶來顯著的性能改進(正如我們的消融研究所示)。
HAKE部分狀態。 HAKE [17]數據集包含人-物互動的注釋部分狀態。 對于每個樣本,手動注釋了六個身體部位的運動(頭部、手、臂、臀部、腿、腳),總共有93個部分狀態。 為了避免對每個樣本進行繁瑣的注釋,我們應用了一個自動化流程,其中包含兩個步驟:1)使用預訓練的變壓器文本編碼器分別為標簽名稱和 HAKE 部分狀態生成文本特征;2)通過在 HAKE 部分狀態特征空間中,找到動作標簽名稱的 K 個最近鄰(與動作標簽名稱的文本特征最相似的k個)來生成文本描述。 最接近動作標簽名稱的那些 HAKE 部分狀態被選中作為動作描述。 然后我們使用這個生成的部分描述進行 GAP。
手動描述。我們要求標注者按照動作的時間順序寫下身體部位移動的描述。這些描述由預定義的基本動作組成。我們要求標注者專注于最顯著的部分運動。
大型語言模型。我們使用大規模語言模型(例如,GPT-3)來生成文本描述。我們設計文本提示,以便它可以生成我們期望的動作描述。文本描述可以通過三種方式生成。a)段落:一整段可以詳細描述動作的描述;b)同義詞:我們收集動作標簽的10個同義詞;c)部分描述:我們為每個動作收集不同身體部位的描述。身體分區策略遵循前一節的圖3。我們以“穿鞋子”為例,并在圖5中展示了用于生成不同描述的提示。

段落:Q段:描述一個人“穿鞋”的細節。A:這個人正在穿鞋。他正彎下腰,把腳伸進鞋里。他正在系鞋帶。他做得又快又有效率。
同義詞Q:建議10個“穿鞋”的同義詞a:靴子,系上鞋帶,穿上,步入,系上帶子,系上領帶,塞進,拉上拉鏈,穿上,系緊
部分描述:Q:描述“穿鞋”時身體部位的動作:頭、手、手臂、臀部、腿、腳。A:頭部微微前傾;手伸下去,抓住鞋子;手臂向前向下伸展;髖部保持靜止;腿在膝蓋處彎曲,使腳更靠近手;腳插入鞋中。
4實驗
4.1. 數據集
NTU RGB+D [24] 是用于基于骨架的人體動作識別的廣泛使用的數據集。它包含 56,880 個骨架動作序列。有兩個用于評估的基準,包括跨主體(X-Sub)和跨視角(X-View)設置。對于 X-Sub,訓練集和測試集來自兩個不相交的集合,每個集合有 20 個主體。對于 X-View,訓練集包含由攝像機視圖 2 和 3 拍攝的 37,920 個樣本,測試集包括由攝像機視圖 1 拍攝的 18,960 個序列。
NTU RGB+D 120 [18] 是 NTU RGB+D 數據集的擴展,增加了 57,367 個額外的骨架序列和 60 個額外的動作類別。總共有 120 個動作類別。作者建議了兩種基準評估方法,包括跨主體(X-Sub)和跨設置(X-Setup)設置。
NW-UCLA [33] 數據集由三個不同視角的 Kinect V1 傳感器錄制。骨架包含 20 個關節和 19 條骨連接。它包括 1,494 個視頻序列,涵蓋了 10 個動作類別。
4.2. 實現細節
對于 NTU RGB+D 和 NTU RGB+D 120,每個樣本被調整為 64 幀,并采用 [43, 6] 的代碼進行數據預處理。對于 NW-UCLA,我們遵循 [5, 2, 6] 中的數據預處理流程。對于我們的消融研究,我們使用單尺度時間卷積的 CTR-GCN,考慮到其在性能和效率之間的良好平衡。對于具有 ST-GCN 骨干網絡的消融研究,請參閱補充材料。與其他方法進行比較時,我們采用 CTR-GCN 與多尺度時間卷積,因為它產生了最好的結果。對于文本編碼器,我們使用 CLIP 或 BERT 的預訓練文本變壓器模型,并在訓練過程中微調其參數。對比損失的溫度設置為 0.1。至于 GPT-3 生成的動作描述的非確定性,我們在訓練過程中通過采樣有效地利用了生成的結果。例如,在我們的同義詞場景中,我們生成了大量的同義詞,并隨機選擇其中一些進行訓練。
對于 NTU RGB+D 和 NTU RGB+D 120,我們將模型訓練總輪數設置為 110 輪,批大小為 200。我們在前 5 輪采用熱身策略。初始學習率設為 0.1,并在第 90 和 100 輪時減小 10 倍,權重衰減設為 5e-4,遵循 [6] 中的策略。對于 NW-UCLA,批大小、輪數、學習率、權重衰減、減小步長、熱身輪數分別設置為 64、110、0.2、4e-4、[90,100]、5。
4.3.?消融實驗
在本節中,我們進行實驗評估不同組件的影響。實驗在 NTU120 RGB+D 數據集的聯合模態和 X-Sub 設置上進行。更多的消融研究請參考補充材料。
分區策略。我們測試了不同的身體分區策略用于 GAP,并將結果顯示在表1a中。“全局”代表使用動作的全局描述和單一對比損失,相比基線提高了0.6%。使用更多的部分和多部分對比損失可以穩定地提高性能,當使用4個部分時,性能飽和至85.4%。

文本提示的影響。文本提示的設計對模型性能有很大影響。我們在表1b中展示了不同文本提示的影響。通過直接使用標簽名稱(帶前綴或后綴)作為 GAP 中的文本提示,模型的性能僅略優于基線模型(0.2%),因為這并沒有為訓練帶來額外的信息。利用標簽名稱的同義詞列表或全局描述段落可以大大提高性能(0.6%),因為它豐富了每個動作類別的語義含義。使用部分描述提示會帶來強大的性能,提高了0.8%。通過將標簽名稱的同義詞和身體部位描述結合起來作為提示,實現了最佳性能,準確率達到了85.5%。

文本編碼器的影響。在表1c中,我們展示了文本編碼器的影響。我們發現,無論是XFMR(來自CLIP [23]的文本編碼器)還是BERT都能取得良好的性能,表明骨架編碼器可以受益于具有不同預訓練來源(圖像-語言或純語言)的文本編碼器。考慮到XFMR-32在效率和準確性之間的良好平衡,我們將其作為默認的文本編碼器。

GAP對不同的骨架編碼器的影響。我們提出的GAP與網絡架構解耦,可以用來改進不同的骨架編碼器。在表1d中,我們展示了將GAP應用于ST-GCN [38]、CTR-baseline和CTR-GCN [2]的實驗結果。GAP在推理階段沒有額外的計算成本,帶來了一致的改進(0.6-1.2%),表明了GAP的有效性和泛化能力。

描述方法的比較。我們在表1e中比較了幾種獲取文本編碼器文本提示的不同方法,包括:手動描述;HAKE部分狀態;使用GPT-3生成文本提示。對于手動描述和 HAKE 結果,我們將它們用作 GAP 的全局描述。在這些方法中,GPT-3 可以通過精心設計的文本提示提供非常詳細的人體部分描述,生成的部分文本描述實現了最佳性能。我們還實現了一個部分池化分類基線用作參考,該基線對每個池化的部分特征應用分類頭。由于部分特征可能不足以預測動作類別,這個基線效果不佳。

與提示學習方法的比較。在表1f中,我們將GAP與使提示可學習的PL方法進行了比較。PL在固定或調整了文本編碼器(TE)參數的情況下均優于基線。GAP進一步比PL提高了0.3%,這表明了生成提示和多部分范式的有效性。

λ選擇的影響。λ 的選擇對模型性能有著重要的影響。為了研究在公式 1 中的權衡參數 λ 的影響,我們在 {1.0, 0.8, 0.5, 0.2} 中進行了搜索,并采用了 5 折交叉驗證。模型的性能分別為 85.4%,85.5%,85.3% 和 85.2%。我們發現 λ = 0.8 取得了最佳性能;因此,我們將其作為我們默認的 λ 值,并在不同基準數據集的所有實驗中使用它。
4.4. 與最新技術的比較
我們將我們的方法與之前的最新技術進行比較,結果如表2、3和4所示。為了公平比較,我們采用了4個合奏策略(Joint、Joint-Motion、Bone、Bone-Motion),因為大多數先前的方法都采用了這種策略。結果是5次運行的平均值,標準偏差約為0.1。如表2所示,在NW-UCLA數據集上,GAP的表現優于CTR-GCN約0.7%。它還優于最近的工作Info-GCN[6]約0.6%,后者使用了自注意層和信息瓶頸。考慮到該數據集上模型的性能已經非常高,我們認為這樣的改進是顯著的。在NTU RGB+D數據集上,GAP在交叉主體和交叉視圖設置上分別比CTR-GCN[2]高出0.5%和0.2%,在這兩種設置上,它分別比Info-GCN高出0.2%和0.1%。如表4所示,在最大的數據集NTU RGB+D 120上,我們的方法在交叉主體設置上比CTR-GCN大幅領先(1.0%),在交叉設置上領先0.5%。Info-GCN在這個數據集上也取得了很好的表現,而GAP仍然比它分別高出0.5%和0.4%。總的來說,GAP在NW-UCLA、NTU RGB+D和NTU RGB+D 120數據集上的表現始終優于最新技術,在不同設置下驗證了其有效性和魯棒性。



4.5. 討論
為了更深入地討論所提出的GAP方法,我們利用了在NTU RGB+D 120交叉主體模式數據集上使用聯合模態訓練的模型。在圖6中,我們展示了在NTU120數據集中,使用GAP和不使用GAP之間存在超過4%絕對準確度差異的動作類別。對于動作類別如“寫字”、“打開盒子”、“吃飯”和“使用刀具”等,GAP都帶來了顯著的好處,這是因為語言模型為這些動作生成了詳細的身體部位運動描述。另一方面,對于“剪紙”、“自拍”、“玩魔方”和“玩手機/平板電腦”等動作類別,GAP的表現較差。我們的分析揭示了這些表現不佳的動作與表現良好的動作之間的主要區別在于前者與物體相關,這使得使用骨架數據來識別它們變得具有挑戰性。此外,數據集中存在的類別偏差也可能導致我們提出的方法在NTU120中對與物體相關的動作的性能變化。例如,在分析“剪紙”時,我們發現它與“擦手”(也出現在NTU120中)之間的主要區別在于有物體被拿著,比如紙和剪刀。相反,雖然“打開一個盒子”也是一個與物體相關的動作,但在NTU120數據集中沒有其他與物體相關的相似動作,比如“展開衣服”。有關更多討論和可視化結果,請參閱補充材料。

5. 結論
我們提出了一種新穎的生成式動作描述提示(GAP)框架,用于基于骨架的動作識別。據我們所知,這是首個利用動作知識先驗進行骨架動作識別的工作。我們利用大規模語言模型作為知識引擎,自動生成詳細的身體部位描述,無需繁瑣的手工注釋。GAP利用知識提示來引導骨架編碼器,并通過關于動作與人體部位關系的知識增強了學到的表示。廣泛的實驗表明,GAP是一個通用的框架,可以與各種骨干網絡相結合,以增強表示學習。GAP在NTU RGB+D、NTU RGB+D 120和NW-UCLA基準數據集上取得了新的最先進水平。
讀后總結
出發點:獨熱編碼無法表示動作之間的相似性和差異性,模型只能通過大量數據學習動作的區分特征,而無法利用潛在的語義信息進行指導。這可能導致對相似動作區分不清,對語義相關的動作無法有效識別。
創新點:提出一種用于骨架動作識別的生成式動作描述提示(GAP)方法,通過在訓練中利用動作描述,來輔助骨架信息,通過兩個編碼器(骨架編碼器、文本編碼器),骨架編碼器部分,生成全局平均特征和部分平均特征;文本編碼器部分,首先通過大語言模型生成適配標簽的文本,再通過文本編碼器生成全局和部分特征;最后將骨架編碼器的特征和文本編碼器的特征進行對齊,通過文本編碼器的特征輔助骨架編碼器特征,使得骨架編碼器能夠學習到更加豐富和準確的特征,通過計算骨架特征與文本特征之間的相似度(使用對比損失),模型能夠更好地理解和區分不同的動作。






)



)
![[vue3后臺管理二]首頁和登錄測試](http://pic.xiahunao.cn/[vue3后臺管理二]首頁和登錄測試)
)



 E. Tensor(思維題-交互))


