
前言
系列專欄:【深度學習:算法項目實戰】??
涉及醫療健康、財經金融、商業零售、食品飲料、運動健身、交通運輸、環境科學、社交媒體以及文本和圖像處理等諸多領域,討論了各種復雜的深度神經網絡思想,如卷積神經網絡、循環神經網絡、生成對抗網絡、門控循環單元、長短期記憶、自然語言處理、深度強化學習、大型語言模型和遷移學習。
情感分析是指利用自然語言處理、文本分析、計算語言學和生物統計學,系統地識別、提取、量化和研究情感狀態和主觀信息。
語言模型通過學習來預測單詞序列的概率。但為什么我們需要學習單詞的概率呢?讓我們通過一個例子來理解。我相信你一定用過谷歌翻譯。出于不同的原因,我們都會用它將一種語言翻譯成另一種語言。這是一個流行的 NLP 應用的例子,叫做機器翻譯。在 “機器翻譯 ”中,你需要從一種語言中輸入一堆單詞,然后將這些單詞轉換成另一種語言。現在,系統可能會給出許多潛在的翻譯,您需要計算每種翻譯的概率,以了解哪種翻譯最準確。
目錄
- 1. 根據預訓練模型訓練文本分類器
- 1.1 使用高級應用程序接口
- 1.2 使用數據塊應用程序接口
- 2. ULMFiT 方法
- 2.1 微調 IMDb 上的語言模型
- 2.2 訓練文本分類器
我們將使用《學習詞向量進行情感分析》一文中的 IMDb 數據集,該數據集包含數千條電影評論。
1. 根據預訓練模型訓練文本分類器
我們將嘗試使用預訓練模型來訓練分類器,為了準備好數據,我們將首先使用高級 API:
1.1 使用高級應用程序接口
我們可以使用以下命令下載數據并解壓:
from fastai.text.all import *
path = untar_data(URLs.IMDB)
path.ls()
(#5) [Path('/home/sgugger/.fastai/data/imdb/unsup'),Path('/home/sgugger/.fastai/data/imdb/models'),Path('/home/sgugger/.fastai/data/imdb/train'),Path('/home/sgugger/.fastai/data/imdb/test'),Path('/home/sgugger/.fastai/data/imdb/README')]
(path/'train').ls()
(#4) [Path('/home/sgugger/.fastai/data/imdb/train/pos'),Path('/home/sgugger/.fastai/data/imdb/train/unsupBow.feat'),Path('/home/sgugger/.fastai/data/imdb/train/labeledBow.feat'),Path('/home/sgugger/.fastai/data/imdb/train/neg')]
數據按照 ImageNet 風格組織,在 train 文件夾中,我們有兩個子文件夾:pos 和 neg(分別用于正面評論和負面評論)。我們可以使用 TextDataLoaders.from_folder 方法收集數據。我們唯一需要指定的是驗證文件夾的名稱,即 “test”(而不是默認的 “valid”)。
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
然后,我們可以使用 show_batch 方法查看數據:
dls.show_batch()


我們可以看到,該程序庫自動處理了所有文本,然后將其拆分成標記符,并添加了一些特殊標記符,如
xxbos表示文本開始xxmaj表示下一個詞被大寫
這樣,我們就可以在一行中定義一個適合文本分類的學習器:
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
我們使用 AWD LSTM 架構,drop_mult 是一個參數,用于控制該模型中所有 dropout 的大小,我們使用準確率來跟蹤我們模型效果。然后,我們就可以對預訓練模型進行微調:
learn.fine_tune(4, 1e-2)
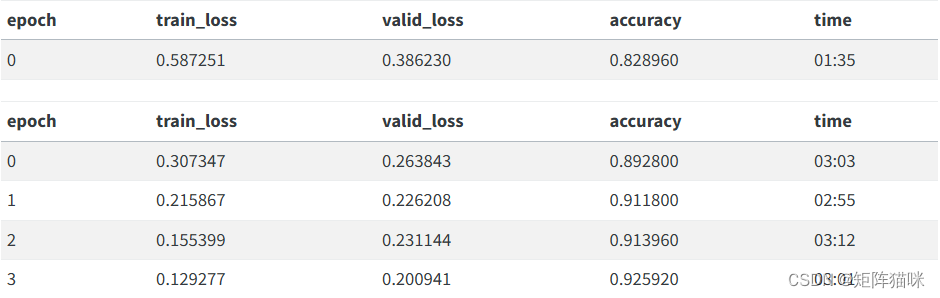
learn.fine_tune(4, 1e-2)
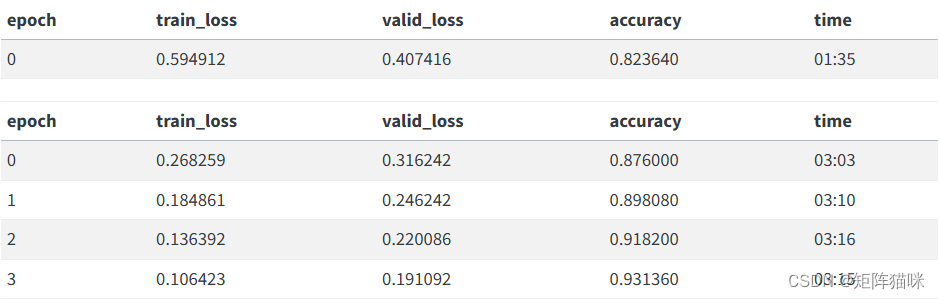
還不錯!我們可以使用 show_results 方法來查看模型的運行情況:
learn.show_results()

我們可以很容易地預測新文本:
learn.predict("I really liked that movie!")
('pos', tensor(1), tensor([0.0092, 0.9908]))
在這里,我們可以看到模型認為該評論是正面的。結果的第二部分是 “pos ”在我們的數據詞匯表中的索引,最后一部分是每個類別的概率(“pos ”為 99.1%,“neg ”為 0.9%)。
1.2 使用數據塊應用程序接口
我們還可以使用數據塊 API 在 DataLoaders 中獲取數據。這部分比較高深,如果你還不習慣學習新的 API,可以跳過這部分。
數據庫塊是通過向 fastai 庫提供大量信息而建立的:
通過一個名為 “塊”(block)的參數來確定所使用的類型:這里我們有文本和類別,因此我們傳遞 TextBlock 和 CategoryBlock。為了通知庫我們的文本是文件夾中的文件,我們使用了 from_folder 類方法。
- 如何獲取原始項目,這里使用函數
get_text_files。 - 如何標注這些項目,這里使用父文件夾。
- 如何分割這些項目,此處使用祖文件夾。
imdb = DataBlock(blocks=(TextBlock.from_folder(path), CategoryBlock),get_items=get_text_files,get_y=parent_label,splitter=GrandparentSplitter(valid_name='test'))
這只是提供了一個如何組合數據的藍圖。要實際創建數據,我們需要使用 dataloaders 方法:
dls = imdb.dataloaders(path)
2. ULMFiT 方法
我們在上一節中使用的預訓練模型被稱為語言模型。它是在維基百科上進行預訓練的,任務是在閱讀了前面所有單詞后猜測下一個單詞。我們將這個語言模型直接微調為電影評論分類器,取得了很好的效果,但只要多做一步,我們就能做得更好:維基百科的英語與 IMDb 的英語略有不同。因此,我們可以根據 IMDb 語料庫微調預訓練的語言模型,然后以此為基礎建立分類器,而不是直接跳轉到分類器。
當然,其中一個原因是,了解你正在使用的模型的基礎是很有幫助的。但還有一個非常實用的原因,那就是如果在微調分類模型之前微調(基于序列的)語言模型,就能獲得更好的結果。例如,在 IMDb 情感分析任務中,數據集包含了 50,000 條額外的電影評論,這些評論在 unsup 文件夾中沒有附加任何正面或負面標簽。我們可以使用所有這些影評來微調預訓練的語言模型–這將產生一個特別擅長預測影評下一個單詞的語言模型。相比之下,預訓練模型只在維基百科文章中進行訓練。
這幅圖概括了整個過程: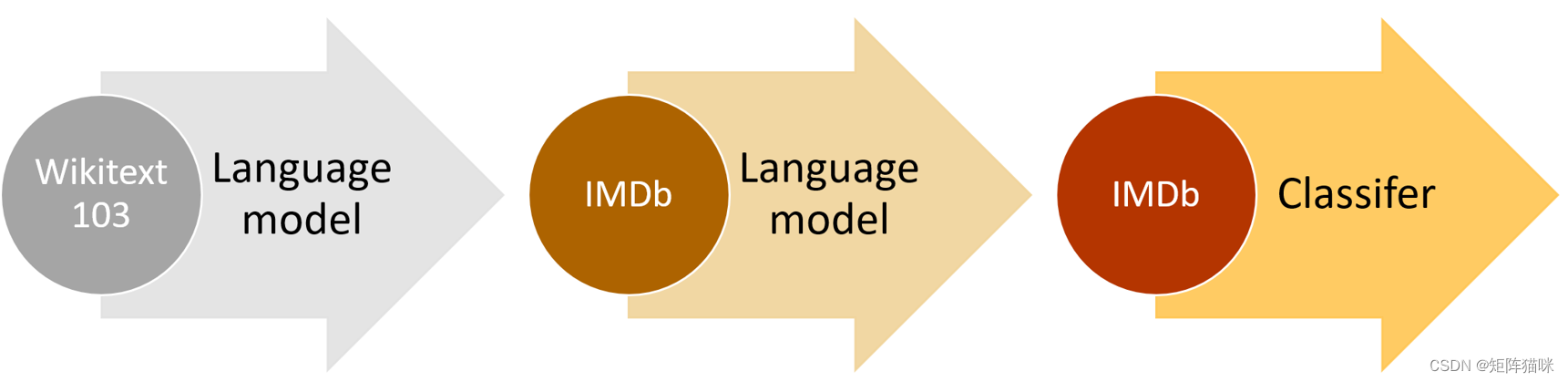
2.1 微調 IMDb 上的語言模型
我們可以很容易地將文本放入適合語言建模的 DataLoaders 中:
dls_lm = TextDataLoaders.from_folder(path, is_lm=True, valid_pct=0.1)
我們需要為 valid_pct 傳遞一些信息,否則該方法將嘗試使用祖文件夾名稱來分割數據。通過傳遞 valid_pct=0.1,我們可以告訴它隨機獲取其中 10%的評論作為驗證集。
我們可以使用 show_batch 查看數據。這里的任務是猜測下一個單詞,因此我們可以看到目標都向右移動了一個單詞。
dls_lm.show_batch(max_n=5)

然后,我們有一個方便的方法,可以像以前一樣使用 AWD_LSTM 架構直接從中抓取一個學習器。我們使用準確率和困惑度作為衡量指標(困惑度是損失的指數),并將默認權重衰減設為 0.1。
learn = language_model_learner(dls_lm, AWD_LSTM, metrics=[accuracy, Perplexity()], path=path, wd=0.1).to_fp16()
默認情況下,預訓練的學習器處于凍結狀態,這意味著只有模型的頭部會進行訓練,而主體則保持凍結。在這里,我們將向你展示 fine_tune 方法背后的內容,并使用 fit_one_cycle 方法來擬合模型:
learn.fit_one_cycle(1, 1e-2)

這個模型的訓練需要一段時間,所以這是一個很好的機會來討論保存中間結果的問題。
您可以像這樣輕松保存模型的狀態:
learn.save('1epoch')
它會在 learn.path/models/ 中創建一個名為 “1epoch.pth ”的文件。如果您想在以同樣方式創建學習器后在另一臺機器上加載模型,或稍后繼續訓練,您可以通過以下方式加載該文件的內容:
learn = learn.load('1epoch')
我們可以在解凍后對模型進行微調:
learn.unfreeze()
learn.fit_one_cycle(10, 1e-3)
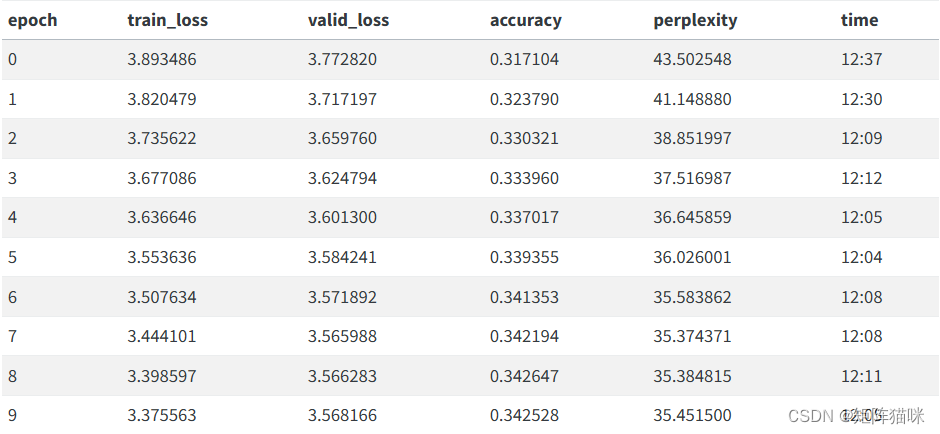
完成后,我們就可以保存模型的全部內容,但最后一層除外,該層將激活度轉換為選取詞匯表中每個標記的概率。不包括最后一層的模型稱為編碼器。我們可以用 save_encoder 保存它:
learn.save_encoder('finetuned')
術語:Encoder(編碼器): 不包括特定任務最終層的模型。在應用于視覺 CNN 時,其含義與 body 大致相同,但更多用于 NLP 和生成模型。
在利用這一點對評論分類器進行微調之前,我們可以使用我們的模型來生成隨機評論:因為它經過訓練可以猜測句子的下一個單詞是什么,所以我們可以用它來編寫新的評論:
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
preds = [learn.predict(TEXT, N_WORDS, temperature=0.75) for _ in range(N_SENTENCES)]
print("\n".join(preds))
i liked this movie because of its story and characters . The story line was very strong , very good for a sci - fi film . The main character , Alucard , was very well developed and brought the whole story
i liked this movie because i like the idea of the premise of the movie , the ( very ) convenient virus ( which , when you have to kill a few people , the " evil " machine has to be used to protect
2.2 訓練文本分類器
我們幾乎可以像以前一樣收集數據進行文本分類:
dls_clas = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test', text_vocab=dls_lm.vocab)
主要區別在于,我們必須使用與微調語言模型時完全相同的詞匯,否則學習到的權重將毫無意義。我們用 text_vocab 傳遞這個詞匯。
然后,我們就可以像之前一樣定義文本分類器了:
learn = text_classifier_learner(dls_clas, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
所不同的是,在訓練之前,我們先加載之前的編碼器:
learn = learn.load_encoder('finetuned')
最后一步是使用辨別學習率和漸進解凍進行訓練。在計算機視覺中,我們通常會一次性解凍模型,但對于 NLP 分類器,我們發現每次解凍幾層會帶來真正的不同。
learn.fit_one_cycle(1, 2e-2)

只用了一個歷元,我們就得到了與第一節中的訓練相同的結果,不算太差!我們可以向 freeze_to 傳遞 -2 以凍結除最后兩個參數組之外的所有參數:
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2))

然后我們可以再解凍一些,繼續訓練:
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3))

最后是整個模型!
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3))

![[vue3后臺管理二]首頁和登錄測試](http://pic.xiahunao.cn/[vue3后臺管理二]首頁和登錄測試)
)



 E. Tensor(思維題-交互))




與PersistentVolumeClaim(PVC)詳解)







系統架構之系統能力的執行隔離)
