1、hvie的SerDe機制
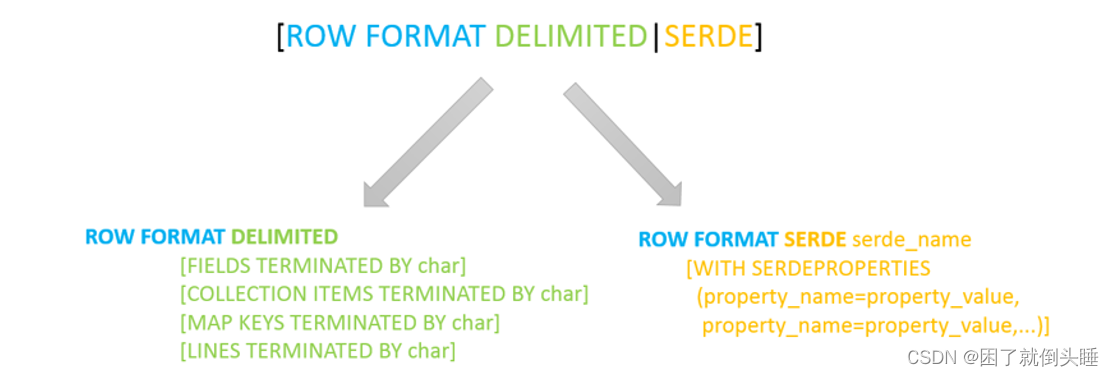
其中ROW FORMAT是語法關鍵字,DELIMITED和SERDE二選其一。本次我們主要學習DELIMITED關鍵字相關知識點
如果使用delimited: 表示底層默認使用的Serde類:LazySimpleSerDe類來處理數據。
如果使用serde:表示指定其他的Serde類來處理數據,支持用戶自定義SerDe類。
Hive默認的序列化類: LazySimpleSerDe
包含4種子語法,分別用于指定字段之間、集合元素之間、map映射 kv之間、換行的分隔符號。
在建表的時候可以根據數據的類型特點靈活搭配使用。
COLLECTION ITEMS TERMINATED BY '分隔符' : 指定集合類型(array)/結構類型(struct)元素的分隔符
MAP KEYS TERMINATED BY '分隔符' : 表示映射類型(map)鍵值對之間用的分隔
2、復雜類型
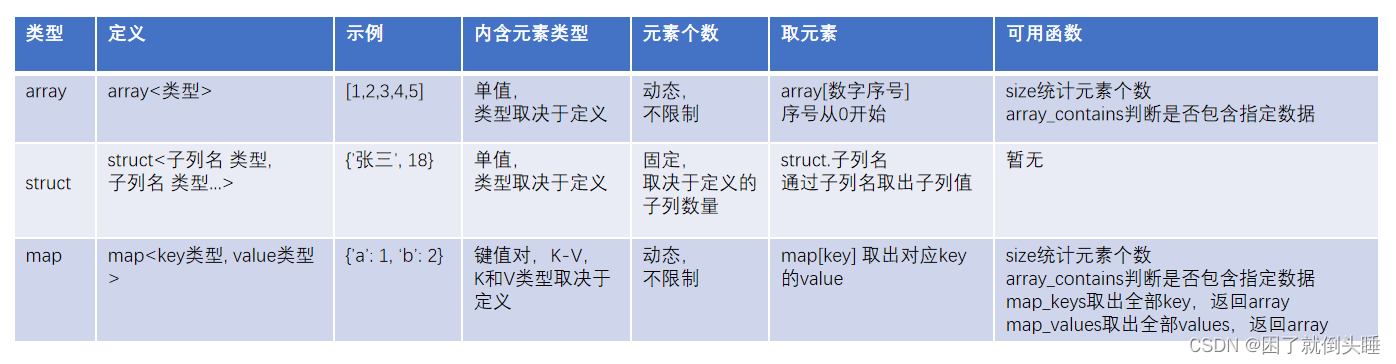
復雜類型建表格式: ... [row format delimited] # hive的serde機制[fields terminated by '字段分隔符'] # 自定義字段分隔符固定格式[collection ITEMS terminated by '集合分隔符'] # 自定義array同類型集合和struct不同類型集合[map KEYS terminated by '鍵值對分隔符'] # 自定義map映射kv類型[lines terminated by '\n'] # # 默認即可 ...; ? hive復雜類型: array struct map ? array類型: 又叫做數組類型。用來存儲相同類型的數據集合建表指定類型: array<元素的數據類型>取值: 字段名[索引/下標/角標]。索引是從0開始獲取長度: size(字段名)判斷是否包含某個數據: array_contains(字段名) ? struct類型:又叫做結構類型。可以存儲不同了類型的數據集合建表指定類型: struct<字段名稱1:數據類型,字段名稱2:數據類型...>取值: 字段名.key鍵的名稱map類型: 又叫做映射類型。存儲的是key-value鍵值對數據建表指定類型: map<key的類型,value的類型>取值: 字段名[key的名稱]獲取長度: size(字段名),實際獲取的是key-value鍵值對的對數獲取所有key: map_keys(字段名)獲取所有value: map_values(字段名)
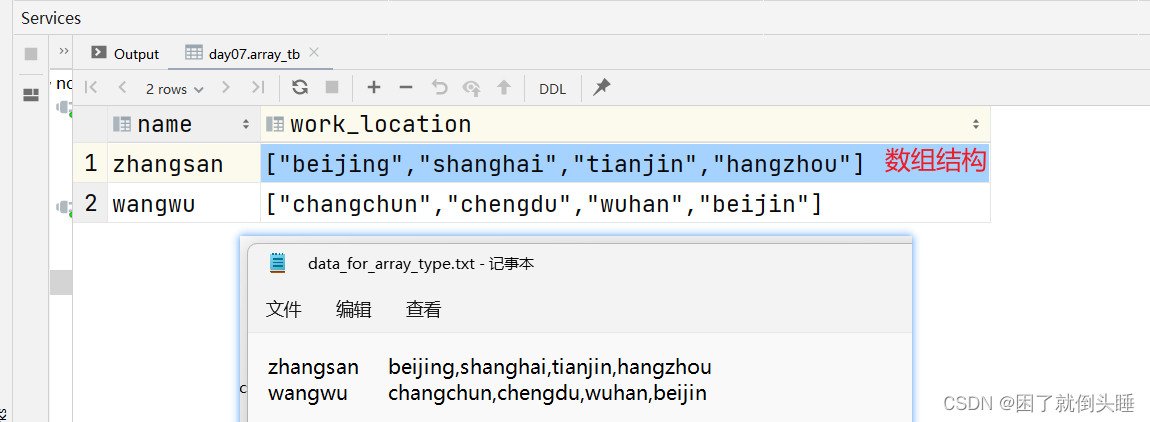
3、array示例
需求: 已知data_for_array_type.txt文件,存儲了學生以及居住過的城市信息,要求建hive表把對應的數據存儲起來
use day07; ? -- 創建表 create table array_tb(name string,work_location array<string> ) row format delimited fields terminated by '\t' collection items terminated by ','; -- 指定array數組中元素間的分隔符 ? ? -- load加載數據 load data inpath '/dir/data_for_array_type.txt' into table array_tb; ? -- 驗證數據 select * from array_tb; ? -- array專有的操作 -- 函數:具備特殊功能的代碼,例如size -- size(work_location) 統計數組中有多少個元素。該案例中也就是統計你去多少個城市工作過 select name,size(work_location) as city_cnt from array_tb; ? -- 數組字段名稱[索引/下標/角標]。索引是從0開始 select name,work_location[-1] from array_tb; select name,work_location[0] from array_tb; -- 取數組中的第一個元素 select name,work_location[1] from array_tb; -- 取數組中的第二個元素 select name,work_location[10] from array_tb; -- 如果根據索引取不到對應的元素,那么返回的是null空值。null值(你沒有去參加考試)和0(參加考試,但是考了0分)是不一樣 ? -- 判斷數組中是否存在某個元素/數據 -- array_contains:是一個函數,用來判斷元素在數組中是否存在。如果存在返回true;如果不存在返回false select name,array_contains(work_location,"chengdu") from array_tb;
4、struct示例
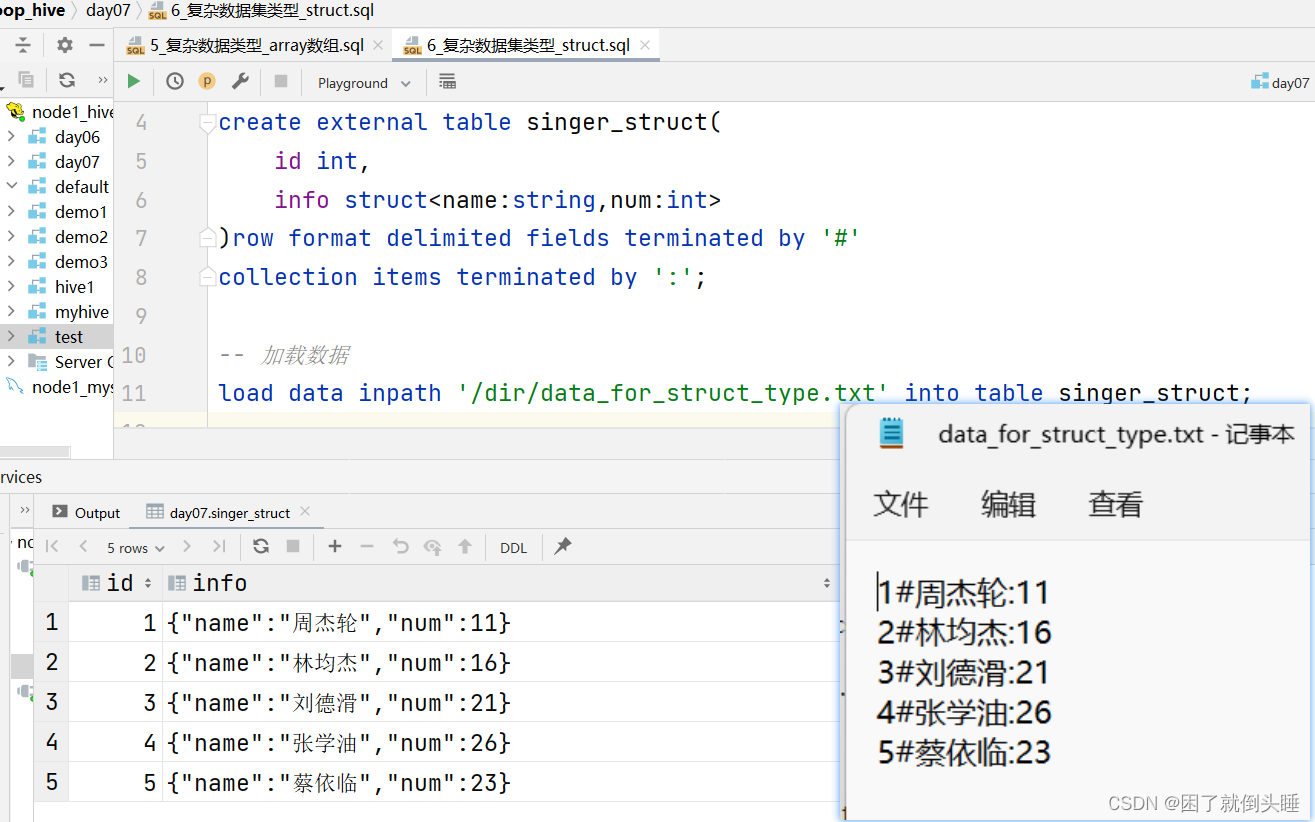
需求: 已知data_for_struct_type.txt文件存儲了用戶姓名和年齡基本信息,要求建hive表把對應的數據存儲起來
use day07; ? -- 創建表 create external table singer_struct(id int,info struct<name:string,num:int> )row format delimited fields terminated by '#' collection items terminated by ':';-- 指定struct中元素間的分隔符 ? -- 加載數據 load data inpath '/dir/data_for_struct_type.txt' into table singer_struct; ? -- 驗證數據 select * from singer_struct; ? -- struct中特有的操作 -- 如果想要看struct中的具體信息,需要通過 struct字段名稱.key鍵 select id,info.name,info.num from singer_struct; select id,info.name,info.num,info.aaaa from singer_struct; ? -- struct中不支持size()函數 -- select id,size(info) from singer_struct;
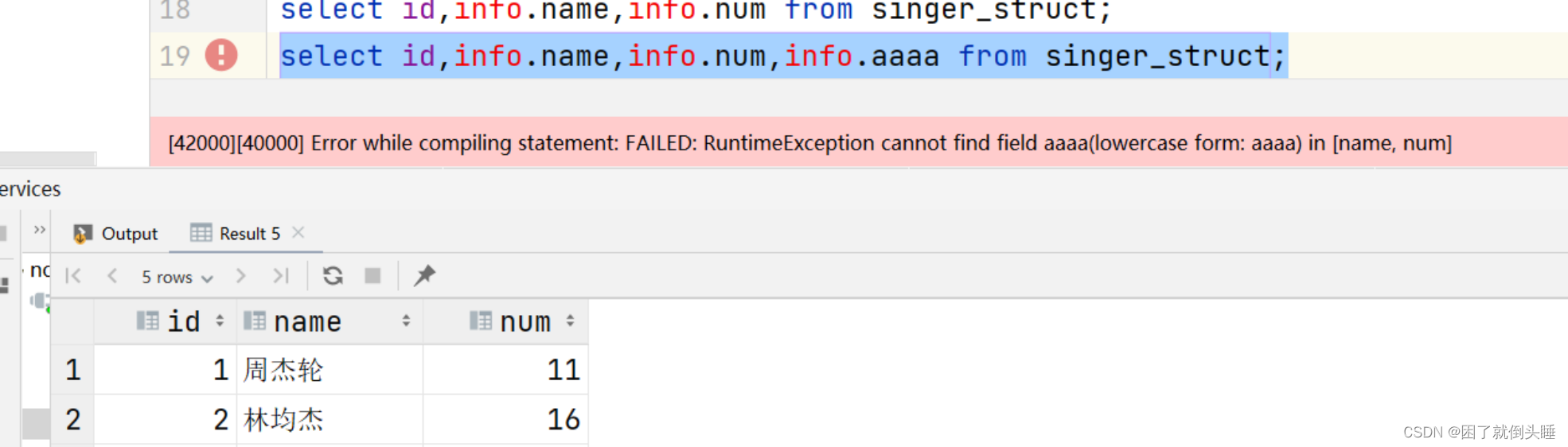
原因: 如果訪問struct中不存在的key會報如上的問題。
5、map示例
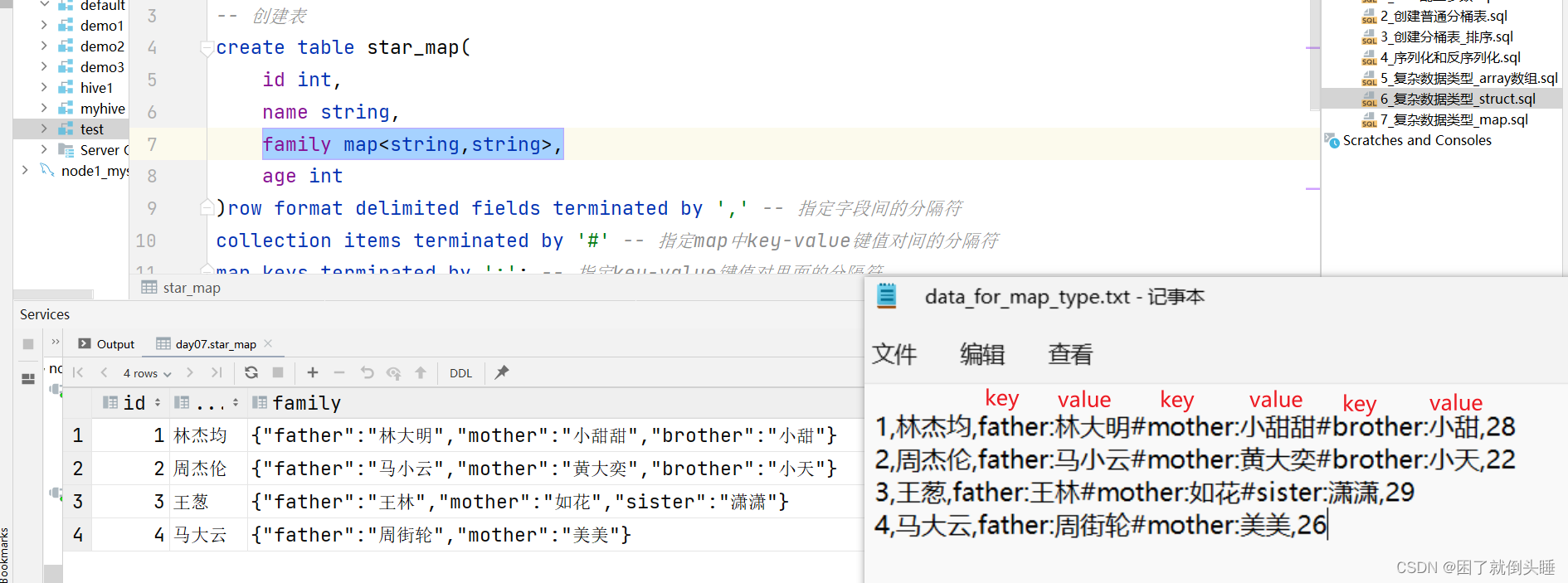
需求: 已知data_for_map_type.txt文件存儲了每個學生詳細的家庭信息,要求建hive表把對應數據存儲起來
use day07; ? -- 創建表 create table star_map(id int,name string,family map<string,string>, -- 前面的string是key的數據類型,后面的string是value的數據類型age int )row format delimited fields terminated by ',' -- 指定字段間的分隔符 collection items terminated by '#' -- 指定map中key-value鍵值對間的分隔符 map keys terminated by ':'; -- 指定key-value鍵值對里面的分隔符 ? -- load導入數據到Hive表中 load data inpath '/dir/data_for_map_type.txt' into table star_map; ? -- 數據驗證 select * from star_map; ? -- map數據類型的特殊操作 select id,name,age,family['father'] as father,family['mother'] as mother from star_map; ? -- 獲取map中所有key的信息 select id,name,age,map_keys(family) as keys from star_map; ? -- 獲取map中所有key的信息,之后,再通過array獲取數據的方式,獲取指定索引的元素值 select id,name,age,map_keys(family),map_keys(family)[1] as keys from star_map; ? ? -- 獲取map中所有value的信息 select id,name,age,map_values(family) as keys from star_map; -- 獲取map中所有value的信息,之后,再通過array獲取數據的方式,獲取指定索引的元素值 select id,name,age,map_values(family),map_values(family)[2] as keys from star_map; ? -- size函數:在map中,是用來獲取key-value鍵值對的對數 select id,name,age,size(family) from star_map; ? -- array_contains函數 select id,name,age,map_keys(family),array_contains(map_keys(family),"brother") from star_map;










新特性概覽(二):解構賦值、擴展與收集、class類全面解析)




)


)
