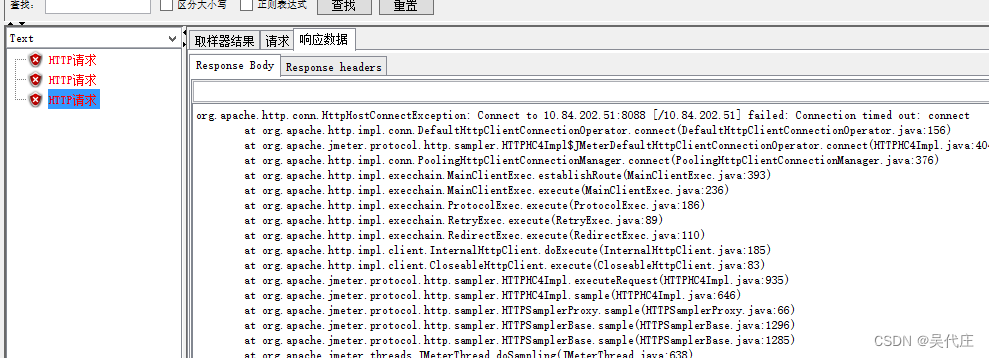
在優化接口并重新投入市場后,我們面臨著一項關鍵任務:確保其在高壓環境下穩定運行。于是,我們啟動了一輪針對該接口的性能壓力測試,利用JMeter工具模擬高負載場景。然而,在測試進行約一分鐘之后,頻繁出現了“連接超時”的錯誤信息,即“Failed: Connection timed out”。這不僅阻礙了我們構建一個持續穩定的壓力測試環境,還對準確評估系統承載能力帶來了挑戰。
問題排查與解決方案概覽:
nginx問題排查
端口耗盡問題是一種常見的網絡資源瓶頸,特別是在高并發的測試或生產環境中。當一個服務器在短時間內需要處理大量的網絡連接時,如果可用端口數量不足,就會導致新的連接請求無法得到及時響應,從而引發服務延遲或失敗。
-
端口耗盡問題的初步分析:
- 在這個問題中,初步分析指出錯誤源于JMeter客戶端無法及時與服務器建立TCP連接。JMeter是一款常用的性能測試工具,它通過模擬多個用戶同時訪問服務器來測試系統的性能。
- 監控工具的檢測顯示,部署了nginx的服務器端口占用量達到了6萬個,接近了TCP/IP協議定義的端口上限(65535個)。這表明服務器正在處理大量的網絡連接,端口資源變得非常緊張。
-
解決端口耗盡問題的措施:
- 減少并發線程數:通過降低JMeter發起的并發連接數,可以減少同時向服務器發起的連接請求,從而減輕對端口資源的壓力。
- 調整nginx配置:將nginx配置調整到8核16GB的資源,可以增加服務器處理連接的能力。這可能包括增加工作進程數、優化內存和CPU使用等。
- 成功緩解端口資源緊張的問題:通過上述措施,服務器的端口資源得到了更有效的管理,減少了端口耗盡的風險。
-
監控端口使用狀況:
- 使用命令查看端口使用狀況:
netstat -nat|grep -i 8080|wc -l命令可以幫助我們查看特定端口(如8080)的使用情況。這個命令會列出所有與8080端口相關的網絡連接狀態,并通過wc -l計算連接數。 - 如果發現連接數在6萬左右,那么很可能是端口號已經用盡。這種情況下,需要采取措施減少并發連接數或者增加服務器的處理能力,以防止端口耗盡導致的服務不可用。
- 使用命令查看端口使用狀況:
網絡排查
-
網絡與資源監控優化是一個持續的過程,需要對系統的各個方面進行細致的觀察和調整。在本例中,我們對業務服務器狀態進行了深入調查,發現了一些關鍵的問題和解決方案。
-
問題診斷:
- 初步調查發現,網絡流量的激增與數據庫查詢活動有關。特別是,健康檢查接口的設計導致了頻繁的數據庫加載,這個接口為了監測是否有遺漏的訂單,不斷地加載所有活躍訂單。這種設計在高并發的環境下會導致大量的數據庫查詢操作,從而引起網絡流量的顯著增加。
- 由于健康檢查接口的操作,CPU和內存的使用率急劇上升,給服務器帶來了巨大的壓力。這種資源的過度使用不僅影響了服務的穩定性,還可能導致性能下降和其他服務的故障。
-
解決措施:
- 關閉健康檢查接口中的監控功能:通過關閉或者優化這部分功能,減少了不必要的數據庫查詢,從而降低了網絡流量和系統負載。
- 盡管采取了上述措施,測試的穩定性有所改善,但是系統中仍然存在超時現象。這表明可能需要進一步的優化措施,比如優化數據庫索引、調整查詢算法或者增加更多的服務器資源。
-
性能監控工具的應用:
- 網絡分析:使用
iftop -i eth1 -P命令可以實時監控指定網絡接口(如eth1)的流量情況,幫助快速識別流量異常的根源。 - CPU分析:使用
top命令可以實時顯示系統中各個進程的CPU使用情況,幫助我們找出消耗CPU資源最多的進程。 - JVM內存分析:使用
jstat -gc [pid] 時間間隔單位毫秒 次數,例如jstat -gc 189 1000 10,可以監控指定Java進程(如pid=189)的垃圾收集情況,幫助我們了解內存的使用和垃圾收集的頻率。
- 網絡分析:使用
GC排查
內存管理與GC(垃圾收集)優化是確保Java應用性能和穩定性的關鍵因素。在本例中,我們使用了Arthas工具來追蹤和診斷性能問題,并采取了有效的優化措施。
-
問題診斷:
- 使用Arthas工具追蹤發現,發送訂單到Cep服務的過程耗時較長。Arthas是一個Java診斷工具,能夠幫助開發者即時查看和診斷運行中的Java程序,無需重啟或修改代碼。
- 問題的原因在于Cep服務雖然配置了5GB內存,但實際可用內存僅為2GB。這種差異可能是由于JVM內存分配不當或者系統其他部分占用了過多內存導致的。
- 由于可用內存較低,導致在處理大量訂單時頻繁觸發Full GC(全面垃圾收集)。Full GC會暫停所有應用線程,直至垃圾收集完成,這會嚴重影響應用的響應時間和吞吐量。
-
解決措施:
- 我們通過限制存活訂單數不超過20萬來避免內存溢出。這個限制減少了同時在內存中處理的訂單數量,從而降低了內存的使用量。
- 清理部分訂單后,測試恢復正常。這意味著通過釋放不再需要的對象所占用的內存,我們能夠減少GC的頻率和持續時間,提高應用的性能。
-
內存管理和GC優化的一般原則:
- 合理配置JVM內存:根據應用的需求和服務器的資源情況,合理設置堆內存(-Xmx)和非堆內存(-XX:MaxMetaspaceSize等)的大小,避免內存不足或過度分配。
- 代碼優化:優化代碼以減少不必要的對象創建和長時間持有大對象,可以使用對象池或軟引用等技術來管理對象生命周期。
- GC策略調整:選擇合適的垃圾收集器(如CMS、G1等),并根據應用的特點調整GC參數,比如增大年輕代比例、調整晉升閾值等。
- 性能監控:使用各種性能監控工具(如Arthas、JVisualVM、PerfMa等)實時監控系統的內存和GC狀態,及時發現并解決問題。
連接管理策略
連接管理策略是確保應用能夠在高并發環境下穩定運行的關鍵因素之一。在本例中,我們通過分析JMeter的默認行為和調整配置,解決了連接管理的問題。
-
問題診斷:
- 使用JMeter進行性能測試時,我們發現默認情況下JMeter使用的是短連接模式。這意味著每次請求完成后,TCP連接會被立即關閉,而不是被重新用于后續的請求。
- 由于未啟用KeepAlive選項,端口在釋放后不會被立即回收。在TCP協議中,KeepAlive是一種檢測和控制空閑連接的機制,它能夠確保連接在關閉后快速釋放占用的資源。
- 這種端口未立即回收的情況影響了后續連接的建立,因為在TCP/IP網絡中,一個端口在一段時間內只能被一個連接使用。如果端口未能及時釋放,新的連接請求就會被阻塞,導致性能下降或超時錯誤。
-
解決措施:
- 我們通過修改JMeter的配置,開啟了KeepAlive選項。這個選項使得TCP連接在關閉后能夠更快地被系統回收,從而減少了端口資源的消耗。
- 開啟KeepAlive后,端口的使用效率得到了顯著提升,后續連接建立的延遲和失敗率都大幅降低。這不僅提高了性能測試的效率,也使得測試結果更加準確和可靠。
-
連接管理策略的一般原則:
- 長連接與短連接的選擇:根據應用的實際需求選擇適合的連接模式。長連接可以減少連接建立和關閉的開銷,但需要更復雜的連接管理機制來處理異常和空閑狀態。
- KeepAlive的配置:在可能的情況下啟用KeepAlive,以便及時檢測和釋放不再需要的連接。但需要注意,KeepAlive不適合所有場景,比如移動網絡環境下可能會增加電池消耗。
- 資源調優與監控:合理配置線程池、數據庫連接池等資源池的大小,監控資源使用情況,及時調整參數以適應不同的負載情況。
- 適應性與容錯性:設計適應性強和容錯性高的系統,能夠處理網絡波動、服務不可用等異常情況,保證系統的穩定運行。
總結與啟示:
- 性能優化是個系統工程,需綜合考慮網絡、硬件資源、軟件配置及測試工具設置。
- 細致監控與診斷是關鍵,借助專業工具(如arthas、iftop)定位瓶頸。
- 資源管理至關重要,合理分配內存和線程數,避免資源過度消耗。
- 連接策略調整,如啟用KeepAlive,能有效提升連接效率和測試穩定性。
通過這一系列排查與優化措施,我們不僅解決了JMeter測試中的超時問題,還提升了系統的整體性能和穩定性,為網格交易功能的高效運行打下了堅實的基礎。分享此經驗,希望能為遇到類似問題的開發者提供參考與幫助。
)





Tkinter筆記(九):用【Button()】功能按鈕實現人機交互)
)
)




)


)


