1. 概述
面部識別系統的開發極大地推動了計算機視覺領域的發展。如今,人們正在積極開發多模態系統,將多種生物識別特征高效、有效地結合起來。
本文介紹了一種名為 IdentiFace 的多模態人臉識別系統。該系統利用基于 VGG-16 架構的模型,將人臉識別與性別、臉型和情緒等重要生物特征信息結合起來,但不同子系統之間略有改動。
在從 FERET 數據庫收集的數據上,性別識別準確率達到 99.2%,在作者的數據集上達到 99.4%,在公共數據集上達到 95.15%。在臉形識別方面,作者使用名人臉形數據集取得了 88.03% 的測試準確率;在情緒識別方面,作者使用 FER2013 數據集取得了 66.13% 的測試準確率。這表明性別識別任務相對容易,而面部形狀和情感識別任務則容易在相似類別之間產生混淆。
IdentiFace "多模態面部識別系統可應用于安全、監控和個人身份識別領域。通過利用面部特征,可以實現更高效、更準確的生物識別。
論文地址:https://arxiv.org/ftp/arxiv/papers/2401/2401.01227.pdf
源碼地址:https://github.com/MahmoudRabea13/IdentiFace
2. 數據集
本節將介紹每項任務所使用的數據集。首先,在人臉識別方面,使用了 NIST 的 "Colour FERET"數據集。該數據集包含 994 人的 11,338 張人臉圖像。該數據集包含 13 種不同的人臉方向,每種方向都有指定的面部旋轉度。此外,一些受試者有戴眼鏡和不戴眼鏡的圖像,另一些受試者則有不同發型的圖像。本文使用的是這些圖像的壓縮版本,圖像大小為 256 x 484 像素。之所以選擇這個數據集,是因為它的差異很大,有助于模型學習到較高的泛化性能。此外,四位作者本人也作為新對象被添加到數據庫中,并在不同場景下進行了測試。
接下來,為了進行性別分類,我們從作者的教師中收集了一個數據集。起初,該數據集由 15 名男性和 8 名女性組成,每張圖像都包含多種變化,以增加數據量。然而,后來受試者的數量不斷增加,最終將數據量增加到總圖像數(133 張男性圖像/66 張女性圖像),其中男性 31 張,女性 27 張。訓練/驗證數據沒有在收集過程中進行拆分,而是在預處理階段進行了拆分。為了便于比較,我們還使用了 Kaggle 的 “性別分類數據集”。該數據集的訓練數據每類約分為 23,000 張圖片,驗證數據每類約分為 5,500 張圖片。
由于任務的復雜性,需要人工標注,作者無法收集自己的臉型預測數據集,因此使用了臉型數據集,其中包含最受歡迎的臉型數據集–名人臉型。該數據集于 2019 年發布,只包含女性受試者,五個類別(圓形/橢圓形/方形/矩形/心形)各包含 100 張圖片。
最后,在情緒識別方面,作者軍團最初為這項任務收集了自己的數據集。其中包括 38 名受試者,分為 22 名男性和 16 名女性。每個受試者的每種特定情緒有 7 幅圖像,每類有 38 幅圖像,共計 266 幅圖像。每個類別中的圖像都是人工標注的。有些受試者在多個類別中都有相似的面部表情,這使得圖像標注和分類過程相對具有挑戰性。因此,為了收集一個合適的情感數據集。我們使用了 "FER-2013"數據集。該數據集是公開的,包含 30,000 多張圖片,包含七個類別(憤怒/厭惡/恐懼/快樂/悲傷/驚訝/中立)。所有圖像均轉換為 48x48 灰度圖像,所有類別幾乎均勻分布。
4 .算法架構
本文構建了一個單一網絡,通過在每個任務之間對網絡進行微調,該網絡可適應多個與人臉相關的任務。VGGNet 架構被用作多模態系統的主網絡。本文對基本的 VGG-16 進行了試驗,最終將其簡化為只有三個主要區塊,去掉了最后兩個卷積區塊。這樣做主要是為了減少參數數量和模型的整體復雜性,因為該模型在各種任務中的表現已經很好。下表列出了該模型在層數、輸出幾何圖形和參數數量方面的信息。
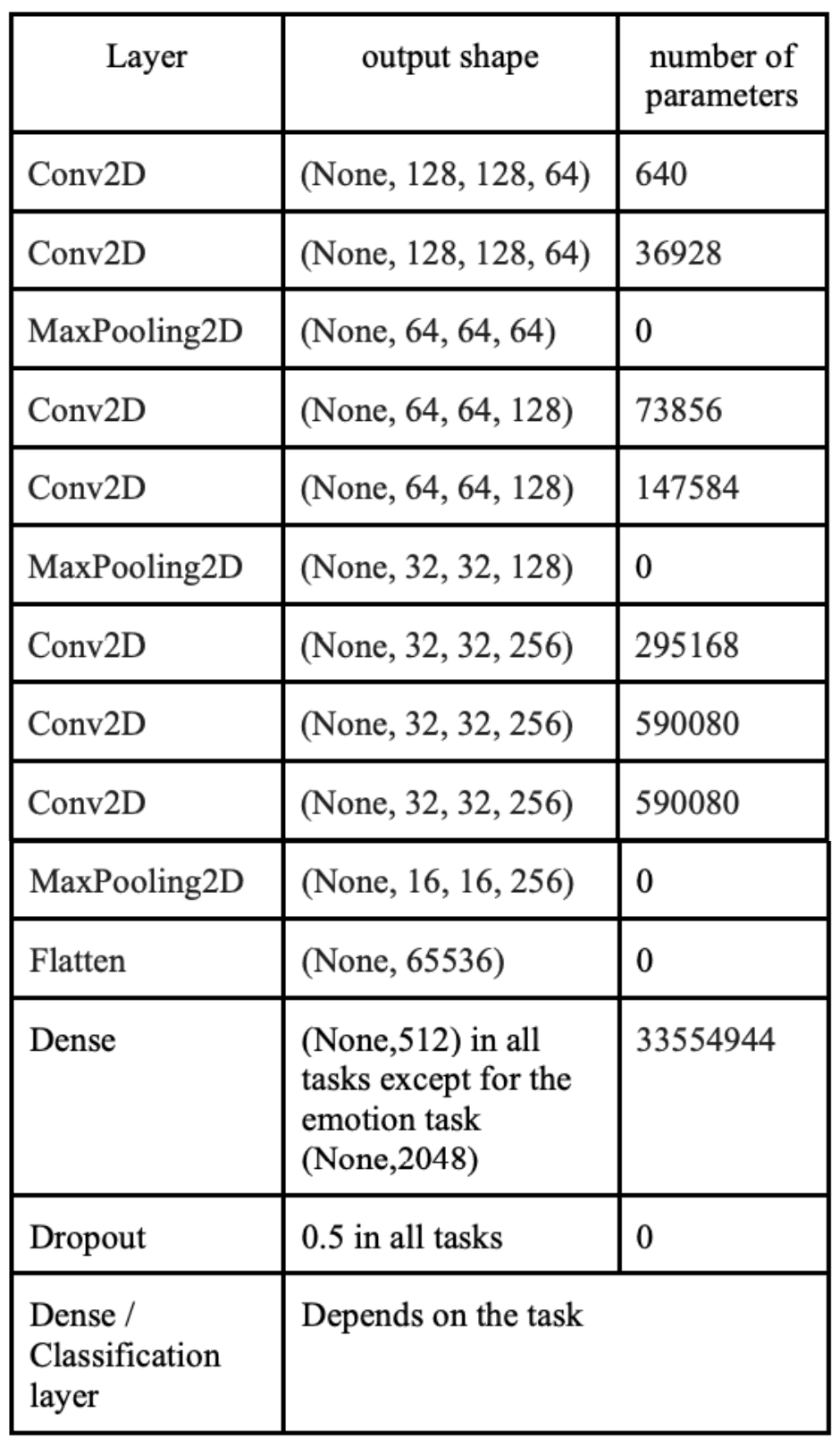
在最終編譯模型時,采用了以稀疏分類交叉熵為損失函數的亞當優化器。此外,還引入了早期停止功能,以防止模型的過度訓練。
此外,人臉識別任務的預處理如下
- 使用 Dlib 基于 CNN 的人臉檢測。
- 對識別出的人臉進行裁剪并轉換成灰度圖像。
- 調整為 128x128 像素。
- 班級數改為 5 個(Hanya、Mahmoud、Nourhan、Sohaila 和其他人)。
除人臉識別外,所有任務都要進行以下預處理
- 使用 Dlib 中的 68 個面部地標進行人臉檢測
- 所有檢測到的人臉都會被裁剪,沒有人臉的圖像會被過濾。
- 臉部尺寸調整為 128 x128,并轉換為灰度
在調整大小后,每個數據集都會按以下方式進行擴展,以確保所有任務的平衡。為確保所有類別的公平分布,僅對不平衡和較小的數據集進行了擴展。
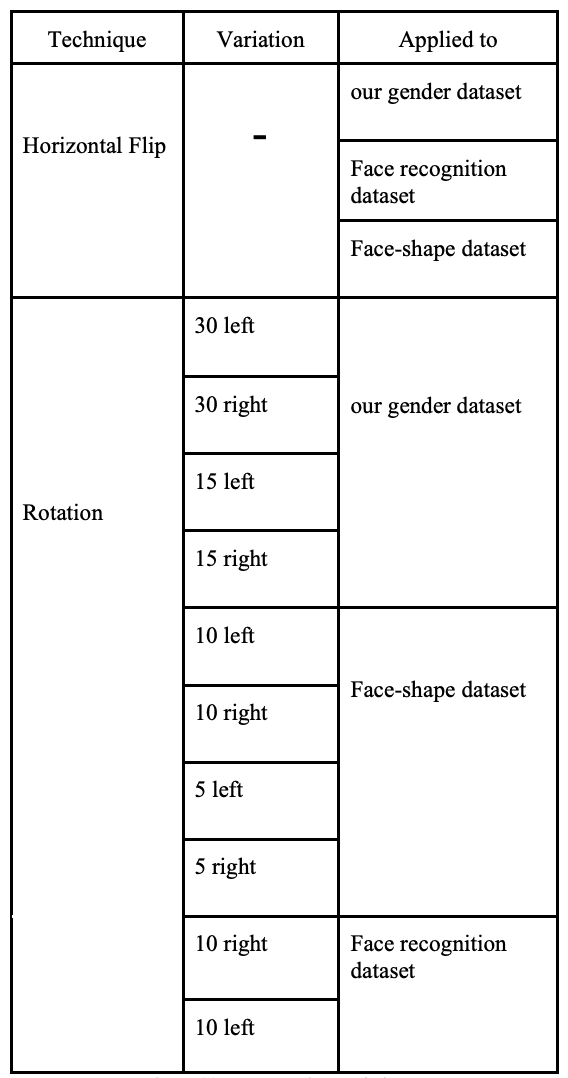
數據擴展后的數據集如下所示。在人臉識別方面,數據集最初包含了來自彩色 FERET 數據集的 11,338 張 "其他 "類圖像,但為了避免過度訓練,數據集減少到了 500 張。有些數據集,如情感識別和性別識別數據集,不需要進行數據擴展,因為每個類別都有很多圖像,而且分布均衡。

5. 試驗
對于人臉識別,數據集的訓練與測試比例為 80:20,并使用以下參數訓練模型
- 學習率 (lr) = 0.0001
- 批量大小 = 32
- 測試規模 = 0.2
- 歷時次數 = 100
結果如下


在性別分類中,任務被視為多類分類,將女性受試者標記為 0,男性受試者標記為 1。以下參數用于訓練作者數據集的模型和公共數據集的模型。
- 學習率 (lr) = 0.0001
- 批次大小 = 128
- 測試規模 = 0.2
結果如下

下圖是作者繪制的數據集混淆矩陣圖。

下圖顯示了數據集與公共數據集的混淆矩陣。

在臉型預測中,我們嘗試了兩種不同的模型來完成這項任務:一種是針對所有類別的模型,另一種是只針對三個類別(長方形/正方形/圓形)的模型。這樣做的目的是為了觀察模型在類別重疊最少的情況下是如何工作的,并與其他包含所有類別的模型進行比較。
- 學習率 (lr) = 0.0001
- 批次大小 = 128
- 測試規模 = 0.2
標簽如下

結果如下


支持向量機(SVM)和卷積神經網絡(CNN)已被用于情緒識別。支持向量機(SVM)的結果如下。

卷積神經網絡(CNN)的結果如下。

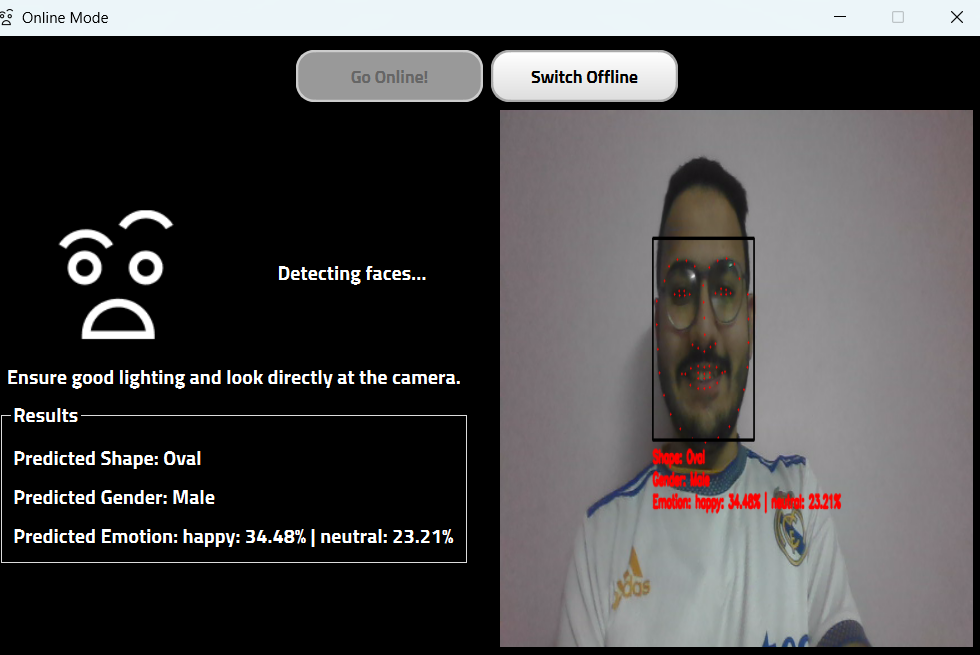
為了實現結果的可視化,正在開發一種名為 "IdentiFace "的多模式面部生物識別系統,作為基于 Pyside 的桌面應用程序。它可以同時在線和離線進行面部生物識別。

6.總結
我們嘗試了不同的方法,并在每項任務中使用了我們自己的數據集以及其他公開可用的數據集,包括人臉識別、性別分類、人臉形狀確定和情感識別。我們還選擇了 VGGNet 模型,因為它在使用這些數據集的所有任務中表現最佳。此外,我們還將所有表現最佳的模型結合起來,開發了一個名為 IdentiFace 的多模態面部生物識別系統。該系統集成了人臉識別、性別分類、面部形狀確定和情感識別于一體。


Hexo7.0+GitHub Pages博客搭建)






)

)

)
_kaic)
![[Nodejs]使用adm-zip和fs-extra壓縮打包后的文件](http://pic.xiahunao.cn/[Nodejs]使用adm-zip和fs-extra壓縮打包后的文件)



