文本分析基本概念
官網:Text analysis | Elasticsearch Guide [7.17] | Elastic
? ? ? ? 官網稱為文本分析,這是對文本進行一直分析處理的方式,基本處理邏輯是為按照預先制定的分詞規則,把原本的文檔進行分割成多個小顆粒度的詞項,顆粒度的大小取決于分詞器的配置規則。
不同文本分析結果如下:
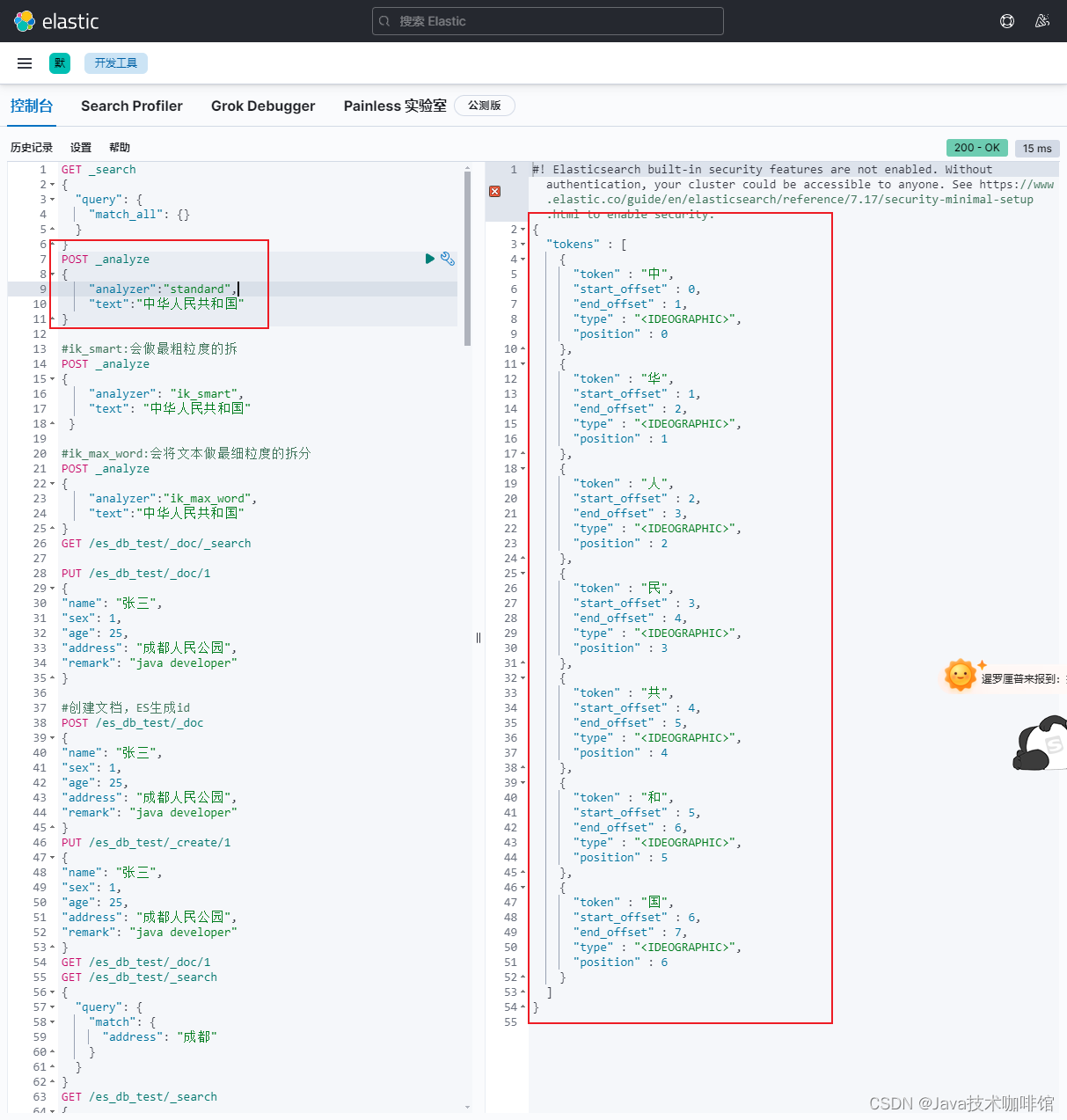
POST _analyze
{"analyzer":"standard","text":"中華人民共和國"
}
#ik_smart:會做最粗粒度的拆
POST _analyze
{"analyzer": "ik_smart","text": "中華人民共和國"}
#ik_max_word:會將文本做最細粒度的拆分
POST _analyze
{"analyzer":"ik_max_word","text":"中華人民共和國"
}
文本分析發生時間
Index and search analysis | Elasticsearch Guide [7.17] | Elastic
文本分析處理發生在 Index Time 和 Search Time 兩個時間。
- Index Time:文本寫入并創建倒排索引時期,其分詞邏輯取決于映射參數analyzer。
- Search Time:搜索執行時期,其分詞僅對搜索詞產生作用。
文本分析構成
Anatomy of an analyzer | Elasticsearch Guide [7.17] | Elastic
- 切詞器(Tokenizer):定義切詞(分詞)邏輯
- 詞項過濾器(Token Filter):分詞之后的單個詞項的處理邏輯
- 字符過濾器(Character Filter):處理單個字符
分詞器:Tokenizer
????????tokenizer 是文本分析的核心組成部分之一,其主要作用是分詞,或稱之為切詞。主要用來對原始文本進行細粒度拆分。拆分之后的每一個部分稱之為一個 Term,或稱之為一個詞項。可以把切詞器理解為預定義的切詞規則。官方內置了很多種切詞器,默認標準切詞器standard。
詞項過濾器:Token Filter
????????詞項過濾器用來處理切詞完成之后的詞項,例如把大小寫轉換,刪除停用詞或同義詞處理等。官方同樣預置了很多詞項過濾器,基本可以滿足日常開發的需要。當然也是支持第三方也自行開發的。
停用詞
在切詞完成之后,會被干掉詞項,即停用詞。停用詞可以自定義
英文停用詞(english):a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on,
or, such, that, the, their, then, there, these, they, this, to, was, will, with。
中日韓停用詞(cjk):a, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, s,
such, t, that, the, their, then, there, these, they, this, to, was, will, with, www。
GET _analyze
{
"tokenizer": "standard",
"filter": ["stop"],
"text": ["how are you"]
}
自定義過濾器
# 自定義 filter
DELETE test_token_filter_stop
PUT test_token_filter_stop
{"settings": {"analysis": {"filter": {"my_filter": {"type": "stop","stopwords": ["you"],"ignore_case": true}}}}
}
GET test_token_filter_stop/_analyze
{"tokenizer": "standard", "filter": ["my_filter"], "text": ["how are you"]
}
同義詞
同義詞定義規則:
- a, b, c => d:這種方式,a、b、c 會被 d 代替。
- a, b, c, d:這種方式下,a、b、c、d 是等價的。
PUT test_token_filter_synonym
{"settings": {"analysis": {"filter": {"my_synonym": {"type": "synonym","synonyms": [ "good, nice => excellent" ] //good, nice, excellent}}}}
}
GET test_token_filter_synonym/_analyze
{"tokenizer": "standard", "filter": ["my_synonym"], "text": ["good"]
}
字符過濾器:Character Filter
分詞之前的預處理,過濾無用字符。
PUT <index_name>
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "<char_filter_type>"}}}}
}type:使用的字符過濾器類型名稱,可配置以下值:
- html_strip
- mapping
- pattern_replace
HTML 標簽過濾器:HTML Strip Character Filter
字符過濾器會去除 HTML 標簽和轉義 HTML 元素,如?、&
PUT test_html_strip_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "html_strip", // html_strip 代表使用 HTML 標簽過濾器"escaped_tags": [ // 當前僅保留 a 標簽 "a"]}}}}
}
GET test_html_strip_filter/_analyze
{"tokenizer": "standard", "char_filter": ["my_char_filter"],"text": ["<p>I'm so <a>happy</a>!</p>"]
}參數:escaped_tags:需要保留的 html 標簽
字符映射過濾器:Mapping Character Filter
通過定義映替換為規則,把特定字符替換為指定字符
PUT test_html_strip_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "mapping", // mapping 代表使用字符映射過濾器"mappings": [ // 數組中規定的字符會被等價替換為 => 指定的字符"滾 => *","垃 => *","圾 => *"]}}}}
}
GET test_html_strip_filter/_analyze
{//"tokenizer": "standard", "char_filter": ["my_char_filter"],"text": "你個垃圾廢物!滾"
}正則替換過濾器:Pattern Replace Character Filter
PUT text_pattern_replace_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "pattern_replace", // pattern_replace 代表使用正則替換過濾器 "pattern": """(\d{3})\d{4}(\d{4})""", // 正則表達式"replacement": "$1****$2"}}}}
}
GET text_pattern_replace_filter/_analyze
{"char_filter": ["my_char_filter"],"text": "手機號是18868686688"
}倒排索引的數據結構
????????當數據寫入 ES 時,數據將會通過?分詞?被切分為不同的?term,ES 將 term 與其對應的文檔列表建立一種映射關系,這種結構就是?倒排索引。

????????為了進一步提升索引的效率,ES 在 term 的基礎上利用 term 的前綴或者后綴構建了 term index, 用于對 term 本身進行索引,ES 實際的索引結構如下圖所示:

????????這樣當我們去搜索某個關鍵詞時,ES 首先根據它的前綴或者后綴迅速縮小關鍵詞的在 term dictionary 中的范圍,大大減少了磁盤IO的次數。
- 單詞詞典(Term Dictionary) :記錄所有文檔的單詞,記錄單詞到倒排列表的關聯關系
- 常用字典數據結構:
-
數據結構 優缺點 排序列表Array/List 使用二分法查找,不平衡 HashMap/TreeMap 性能高,內存消耗大,幾乎是原始數據的三倍 Skip List 跳躍表,可快速查找詞語,在lucene、redis、Hbase等均有實現。相對于TreeMap等結構,特別適合高并發 Trie 適合英文詞典,如果系統中存在大量字符串且這些字符串基本沒有公共前綴,則相應的trie樹將非常消耗內存 Double Array Trie 適合做中文詞典,內存占用小,很多分詞工具均采用此種算法 Ternary Search Tree 三叉樹,每一個node有3個節點,兼具省空間和查詢快的優點 Finite State Transducers (FST) 一種有限狀態轉移機,Lucene 4有開源實現,并大量使用
- 倒排列表(Posting List)-記錄了單詞對應的文檔結合,由倒排索引項組成
- 倒排索引項(Posting):
- 文檔ID
- 詞頻TF–該單詞在文檔中出現的次數,用于相關性評分
- 位置(Position)-單詞在文檔中分詞的位置。用于短語搜索(match phrase query)
- 偏移(Offset)-記錄單詞的開始結束位置,實現高亮顯示
Elasticsearch 的JSON文檔中的每個字段,都有自己的倒排索引。
可以指定對某些字段不做索引:
- 優點︰節省存儲空間
- 缺點: 字段無法被搜索


)



的使用)


 函數)









