
1.背景
23年以來,隨著OpenAI公司的ChatGPT橫空出世,大模型一詞開始火爆全球。國內外以OpenAI、Google、百度、阿里、字節等大廠為代表,相繼推出一系列大模型及其應用,涉及社交、問答、代碼助手等多個方面。
目前主流的大模型及產品:
- OpenAI:GPT3.5、GTP4系列,以及Lora等文生圖模型,代表產品:ChatGPT
- Google:Gemini
- 百度:文心一言3.0、4.0系列,代表產品:文心一言、文心一格
- 阿里:通義大模型,代表產品:通義千問
- 百川:百川大模型
- 騰訊:混元大模型
- 字節:豆包大模型
大模型究竟是什么,和基礎的垂類模型/多模態模型有何差異?為什么可以基于大模型來構建一系列垂類應用,以及可以使用大模型構建什么應用?
2.LLM基本原理
大模型又被稱為大語言模型(Large Language Model)或大規模預訓練語言模型(Large Pretrained Language Model)。
對于小模型(垂類模型):每個小模型對打標數據集識別進行訓練,比如專注識別貓狗圖片的圖片模型、并在對應的數據集上評估,給出模型產物。小模型的特點是“專注”,每一個小模型訓練出來就是為了識別某類特定目標。
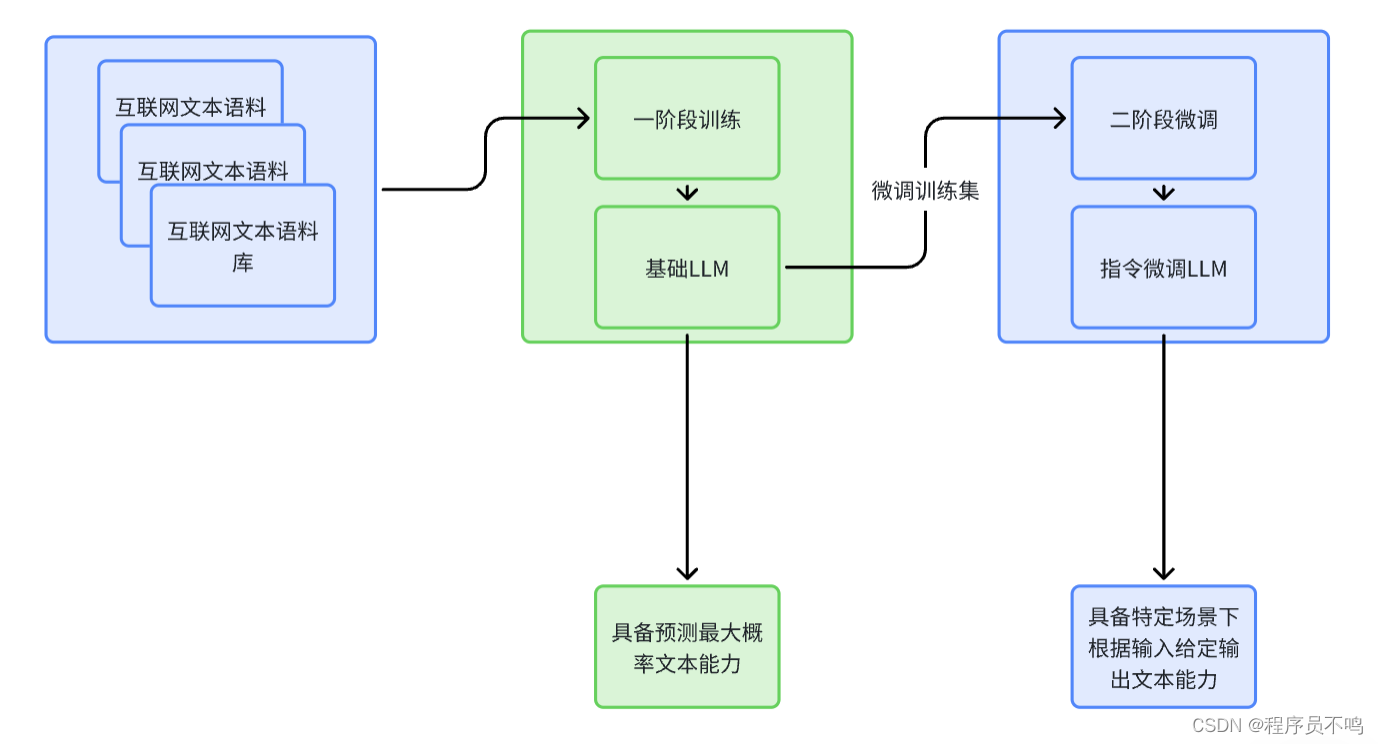
對于大模型來說,其需要具備大量的語料參數以及很好的理解能力,其訓練分為兩個階段:
- 一階段預訓練:在大量的文本語料數據集(待標數據)中進行訓練,提取特征。經過預訓練后的大模型具有大量參數和強大的語料理解能力,它能識別輸入的文本,并且預測出下一個最大概率的文本,一階段訓練后產出的大模型為基礎LLM。
- 二階段指令微調:由于一階段產出的基礎LLM只能做到從輸入的文本預測下一個最有可能的文本,比如輸入“中國的首都”,那么預測輸出為“中國”,但如果我們想讓大模型“思考”,如輸入“你知道中國的首都是北京嗎?”,那么大模型的預測輸出可能不符合預期。所以對于使用場景,需要對一階段基礎LLM進行微調,通過指令微調給定輸入,并且明確告訴LLM需要基于該輸入,得到什么樣的結果,讓LLM學習這個過程,已得到二階段的指令微調LLM。比如ChatGPT使用大模型的就是由GPT基礎LLM經過微調后得到的。
對于算法架構,LLM主要是采用了Transformer架構來增強大模型對語料的上下文理解能力,可以做到長序列理解及推理。
3.LLM應用場景
基礎LLM具有千億級別參數及語料,具有很好的文本理解能力,通過二階段指令微調可以讓基礎LLM在特定場景下做到更準確的輸出判斷,目前LLM應用場景十分廣泛,包括:
- 社交領域
- 智能對話
- 虛擬人
- 編程領域
- 代碼理解
- 潛在BUG掃描
- 代碼生成
- 風控領域
- 智能審核
- 風險判別
- 工業/醫學領域
- 系統檢修判斷
- 醫學輔助診斷
- 生成式創造
- 文生圖
- 文生視頻
- 圖片/視頻擴展














實現偽閉包延長連接生命周期)




