在Java中
在Java中hash表的底層數據結構與擴容等已經是面試集合類問題中幾乎必問的點了。網上有對源碼的解析已經非常詳細了我們這里還是說說其底層實現。
基礎架構
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {private static final long serialVersionUID = 362498820763181265L;// 默認的初始容量是16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;// 最大容量static final int MAXIMUM_CAPACITY = 1 << 30;// 默認的負載因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 當桶(bucket)上的結點數大于等于這個值時會轉成紅黑樹static final int TREEIFY_THRESHOLD = 8;// 當桶(bucket)上的結點數小于等于這個值時樹轉鏈表static final int UNTREEIFY_THRESHOLD = 6;// 桶中結構轉化為紅黑樹對應的table的最小容量static final int MIN_TREEIFY_CAPACITY = 64;// 存儲元素的數組,總是2的冪次倍transient Node<k,v>[] table;// 一個包含了映射中所有鍵值對的集合視圖transient Set<map.entry<k,v>> entrySet;// 存放元素的個數,注意這個不等于數組的長度。transient int size;// 每次擴容和更改map結構的計數器transient int modCount;// 閾值(容量*負載因子) 當實際大小超過閾值時,會進行擴容int threshold;// 負載因子final float loadFactor;
}本文所有Java代碼均來自JavaGuide(HashMap 源碼分析 | JavaGuide),這里主要就是定義一些必要的常量,被用于哈希表的創建參數,擴容參數等待。
然后就是hash表中的Node節點的數據結構,我們的k-v鍵值對就存儲在一個Node類里面。在jdk1.7前其實與redis中的字典Dictionary數據結構中的hash表十分類似,即采用線性搜索和拉鏈法。在jdk1.8 及以后版本1中,添加了樹化,即當節點數大于8就會將當前節點轉化為紅黑樹,這樣做的目的主要是為了增加搜索效率,紅黑樹的時間復雜度為O(log n)如果沒有樹化鏈表查詢的時間復雜度為O(n) 。接下來就看看JavaGuide中給出的節點類:
鏈表節點:
// 繼承自 Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {final int hash;// 哈希值,存放元素到hashmap中時用來與其他元素hash值比較final K key;//鍵V value;//值// 指向下一個節點Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }// 重寫hashCode()方法public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}// 重寫 equals() 方法public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}
}樹節點:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父TreeNode<K,V> left; // 左TreeNode<K,V> right; // 右TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red; // 判斷顏色TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}// 返回根節點final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}resize()
然后我們來重點講一講resize()擴容這個方法。
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {// 超過最大值就不再擴充了,就只好隨你碰撞去吧if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 沒超過最大值,就擴充為原來的2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in threshold// 創建對象時初始化容量大小放在threshold中,此時只需要將其作為新的數組容量newCap = oldThr;else {// signifies using defaults 無參構造函數創建的對象在這里計算容量和閾值newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {// 創建時指定了初始化容量或者負載因子,在這里進行閾值初始化,// 或者擴容前的舊容量小于16,在這里計算新的resize上限float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {// 把每個bucket都移動到新的buckets中for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)// 只有一個節點,直接計算元素新的位置即可newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)// 將紅黑樹拆分成2棵子樹,如果子樹節點數小于等于 UNTREEIFY_THRESHOLD(默認為 6),則將子樹轉換為鏈表。// 如果子樹節點數大于 UNTREEIFY_THRESHOLD,則保持子樹的樹結構。((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else {Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;// 原索引if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}// 原索引+oldCapelse {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 原索引放到bucket里if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 原索引+oldCap放到bucket里if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}在Java的hashmap中,在jdk1.8以后是通過負載因子的判斷來選擇是否進行resize()方法默認負載因子是0.75。如果存儲數據與當前容量之比為0.75就會進行擴容。同時當我們存儲數據過多時,無論我們的hash算法做了什么樣的優化,一定還是會有hash沖突的存在,所以為了解決沖突,我們使用拉鏈法。在插入數據時,我們采用的方式是將已存在hashmap中的鍵值對的值與插入的值進行比較,如果二者相等就進行覆蓋,如果二者不相等就使用尾加法加載鏈表尾部(在redis5中,使用的是equals()進行比較,因為redis存儲的所有值都是String字符串。)。我們將一個拉鏈稱之為一個哈希桶。但是我們試想如果一個桶的節點過于多了,那么我們查找時遍歷起來是很花費時間的,在hashtable中使用的是線性搜索法加拉鏈法來解決這個問題的,但是如果我們一直盲目使用線性搜索法的話,(我們暫且將線性搜索法占據的hash表數組槽位與hash表當前容量的比值稱為線性搜索負載因子)當線性搜索負載因子過大時,我們的hash表的查找效率會受到極大的影響。所有在jdk1.8后的樹化則很好解決了這個問題,即當拉鏈上的節點樹大于8時,會先對數組容量進行判斷,如果小于64先擴容(hashmap擴容都為2倍擴容),否則進行拉鏈法。(為什么先擴容呢?因為hashmap的hash函數計算與容量有關所以擴容后會得到新的hash值,避免了hash沖突,相較于紅黑樹的遍歷,我們肯定更優先考慮的是這種做法)
在Golang中
基礎架構
type hmap struct {count intflags uint8B uint8noverflow uint16hash0 uint32buckets unsafe.Pointeroldbuckets unsafe.Pointernevacuate uintptrextra *mapextra
}type mapextra struct {overflow *[]*bmapoldoverflow *[]*bmapnextOverflow *bmap
}-
count 表示當前hash表中的元素。
-
B 表示當前hash表持有的 buckets (即桶數組)數量,由于hash表中桶數量都為2的倍數,所以該字段會存儲對數。(這里和redis的hash表一樣,在redis的rehash過程中,需要先創建一個2倍舊數組長度的新數組,然后進行hash桶遷移)。
-
oldbuckets是哈希表在擴容時用于保存之前buckets的字段,它的大小是當前buckets的一半。
在go的hashmap中,我們使用溢出桶來降低擴容頻率,本質上就是預先分配幾個數組空間用于存儲超出容量的k-v

擴容方法
-
開放尋址法
-
其實就是線性搜索法。簡而言之就是依次探測和比較數組中的元素以判斷目標鍵值對是否存在于哈希表,當我們向當前哈希表寫入新數據時,如果發生了沖突,就會將鍵值對寫入下一個索引不為空的位置。開放尋址法中對性能影響最大的是裝載因子,它是數組中元素數量與數組大小的比值。隨著裝 載因子的增加,線性探測的平均用時會逐漸增加,這會影響哈希表的讀寫性能。當裝載率超過70% 之后,哈希表的性能就會急劇下降,而一旦裝載率達到100%,整個哈希表就會完全失效,這時查找 和插入任意元素的時間復雜度都是
O(n),我們需要遍歷數組中的全部元素,所以在實現哈希表時一 定要關注裝載因子的變化。
-
-
拉鏈法
-
和jdk 1.7 一樣,就不做過多解釋。
-
在go中的k-v添加我們需要注意的是當插入的k-v小于25時會以如下方式插入:
hash := make(map[string]int, 3)
hash["1"] = 1
hash["2"] = 2
hash["3"] = 3如若大于25個,就會分別創建兩個數組,分別存儲k 和 v,然后以遍歷形式插入。
言歸正傳,在go的hashmap中擴容條件為:裝在因子超過6.5 || 哈希表使用太多溢出桶。
同時由于在go的hashmap的擴容不是原子性的所以需要判斷以避免二次擴容(這和redis也一樣,增刪改查需要判斷當前數據庫的hash表是否在進行rehash)。
擴容數據結構
說了這么多,接下來我們就來重點介紹go的hashmap擴容的數據結構變化。runtime. evacuate會將一個舊桶中的數據分流到兩個新桶,所以它會創建兩個用于保存分配 上下文的runtime.evacDst結構體,這兩個結構體分別指向了一個新桶。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))newbit := h.noldbuckets()if !evacuated(b) {var xy [2]evacDstx := &xy[0]x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))x.k = add(unsafe.Pointer(x.b), dataOffset)x. v = add(x.k, bucketCnt*uintptr(t.keysize))y := &xy[1Jy. b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))y.k = add(unsafe.Pointer(y.b), dataOffset)y.v = add(y.k, bucketCnt*uintptr(t.keysize))
}go中的hashamp擴容分為等量擴容和翻倍擴容,如果是前者就只初始化一個桶,如果是翻倍擴容,就會初始化兩個桶。會把一個鏈表數據分到新表兩個位置,將8個節點分流到兩個桶中(這里獲取桶位置采用取模或者位運算來得到數據存儲的桶位置),然后將k的指針指向兩個桶位置。
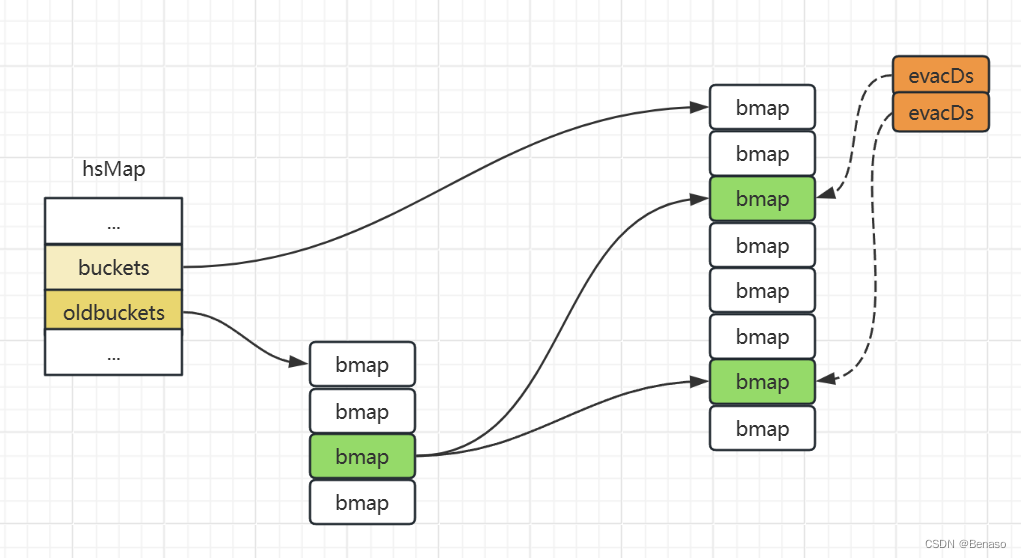
在數據查詢時,會先判斷是否在進行分流,如果在進行,就先會從舊桶中讀取數據。相較于Java的hashmap它不會一次性將所有的元素重新哈希,而是在每次插入元素時,都會將一部分元素移動到新的桶中。這樣可以避免一次性的大量計算,但可能會導致一段時間內的查詢效率稍低。


...)










)





