Twemproxy 架構及應用
Twemproxy 是 Twitter 的一個開源架構,它是一個分片資源訪問的代理組件。如下圖所示,它可以封裝資源池的分布及 hash 規則,解決后端部分節點異常后的探測和重連問題,讓 client 訪問盡可能簡單,同時資源變更時,只要在 Twemproxy 變更即可,不用更新數以萬計的 client,讓資源變更更輕量。最后,Twemproxy 跟后端通過單個長連接訪問,可以大大減少后端資源的連接壓力。
系統架構
接下來分析基于 Twemproxy 的應用系統架構,以及 Twemproxy 組件的內部架構。
如下圖所示, 在應用系統中,Twemproxy 是一個介于 client 端和資源端的中間層。它的后端,支持Memcached 資源池和 Redis 資源池的分片訪問。Twemproxy 支持取模分布和一致性 hash 分布,還支持隨機分布,不過使用場景較少。
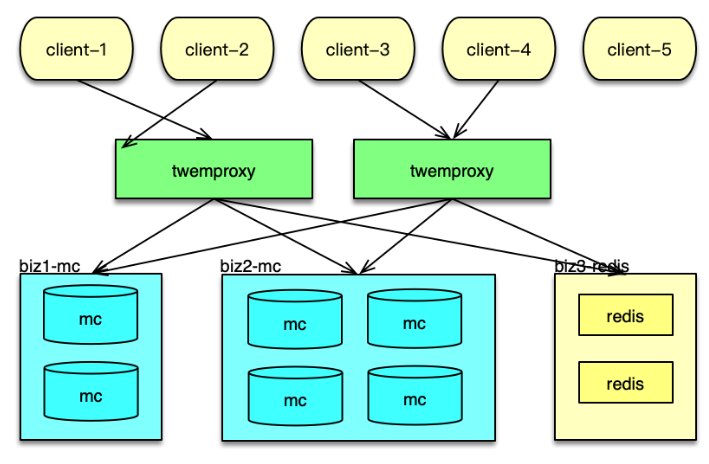
應用前端在請求緩存數據時,直接訪問 Twemproxy 的對應端口,然后 Twemproxy 解析命令得到 key,通過 hash 計算后,按照分布策略,將 key 路由到后端資源的分片。在后端資源響應后,再將響應結果返回給對應的 client。
在系統運行中,Twemproxy 會自動維護后端資源服務的狀態。如果后端資源服務異常,會自動進行剔除,并定期探測,在后端資源恢復后,再對緩存節點恢復正常使用。
組件架構
Twemproxy 是基于 epoll 事件驅動模型開發的,架構如下圖所示。它是一個單進程、單線程組件。核心進程處理所有的事件,包括網絡 IO,協議解析,消息路由等。Twemproxy 可以監聽多個端口,每個端口接受并處理一個業務的緩存請求。Twemproxy 支持 Redis、Memcached 協議,支持一致性 hash 分布、取模分布、隨機分布三種分布方案。Twemproxy 通過 YAML 文件進行配置,簡單清晰,且便于人肉讀寫。
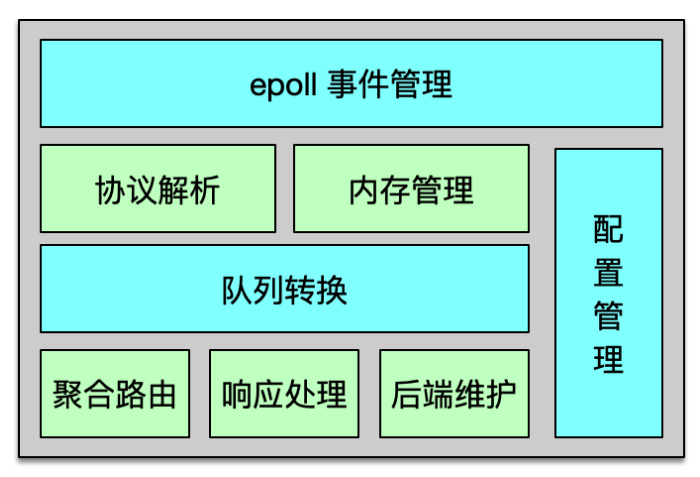
Twemproxy 與后端資源通過單個長連接訪問,在收到業務大量并發請求后,會通過 pipeline 的方式,將多個請求批量發到后端。在后端資源持續訪問異常時,Twemproxy 會將其從正常列表中剔除,并不斷探測,待其恢復后再進行請求的路由分發。
Twemproxy 運行中,會持續產生海量請求及響應的消息流,于是開發者精心設計了內存管理機制,盡可能的減少內存分配和復制,最大限度的提升系統性能。Twemproxy 內部,請求和響應都是一個消息,而這個消息結構體,以及消息存放數據的緩沖都是重復使用的,避免反復分配和回收的開銷,提升消息處理的性能。為了解決短連接的問題,Twemproxy 的連接也是復用的,這樣在面對 PHP client 等短連接訪問時,也可以反復使用之前分配的 connection,提升連接性能。
另外,Twemproxy 對消息還采用了 zero copy(即零拷貝)方案。對于請求消息,只在client 接受時讀取一次,后續的解析、處理、轉發都不進行拷貝,全部共享最初的那個消息緩沖。對于后端的響應也采用類似方案,只在接受后端響應時,讀取到消息緩沖,后續的解析、處理及回復 client 都不進行拷貝。通過共享消息體及消息緩沖,雖然 Twemproxy 是單進程/單線程處理,仍然可以達到 6~8w 以上的 QPS。
Twemproxy 請求及響應
接下來看一下 Twemproxy 是如何進行請求路由及響應的。
Twemproxy 監聽端口,當有 client 連接進來時,則 accept 新連接,并構建初始化一個 client_conn。當建連完畢,client 發送數據到來時,client_conn 收到網絡讀事件,則從網卡讀取數據,并記入請求消息的緩沖中。讀取完畢,則開始按照配置的協議進行解析,解析成功后,就將請求 msg 放入到 client_conn 的 out 隊列中。接下來,就對解析的命令 key 進行 hash 計算,并根據分布算法,找到對應 server 分片的連接,即一個 server_conn 結構體,如下圖。
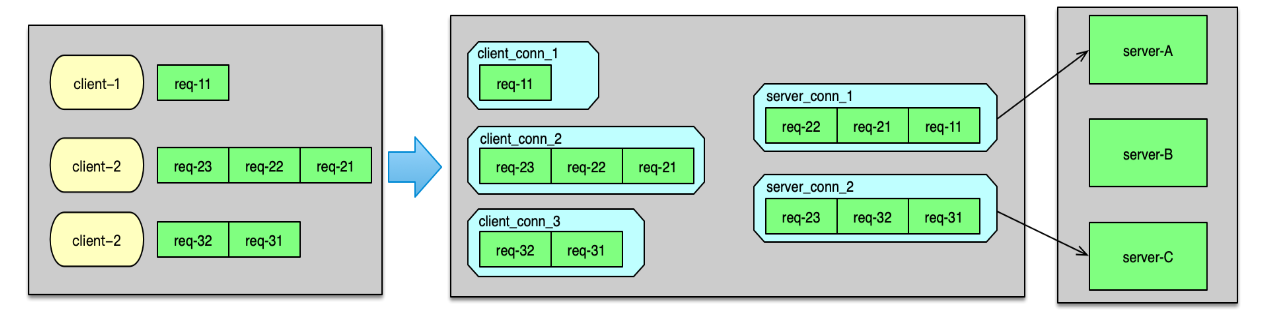
如果 server_conn的 in 隊列為空,首先對 server_conn 觸發一個寫事件。然后將 req msg 存入到 server_conn 的 in 隊列。Server_conn 在處理寫事件時,會對 in 隊列中的 req msg 進行聚合,按照 pipeline 的方式批量發送到后端資源。待發送完畢后,將該條請求 msg 從 server_conn 的 in 隊列刪除,并插入到 out 隊列中。 后端資源服務完成請求后,會將響應發送給 Twemproxy。當響應到 Twemproxy 后,對應的 server_conn 會收到 epoll 讀事件,則開始讀取響應 msg。響應讀取并解析后,會首先將server_conn 中,out 隊列的第一個 req msg 刪除,并將這個 req msg 和最新收到的 rsp msg 進行配對。在 req 和 rsp 匹配后,觸發 client_conn 的寫事件,如下圖。
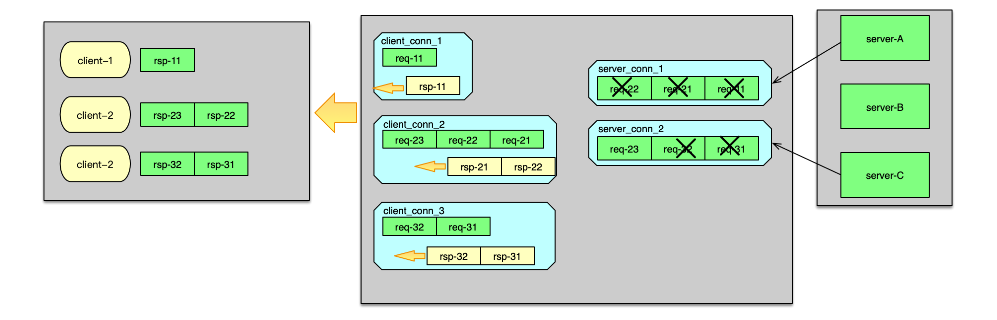
然后 client_conn 在處理 epoll 寫事件時,則按照請求順序,批量將響應發送給 client 端。發送完畢后,將 req msg 從 client 的 out 隊列刪除。最后,再回收消息緩沖,以及消息結構體,供后續請求處理的時候復用。至此一個請求的處理徹底完成。
Twemproxy 安裝和使用
Twemproxy 的安裝和使用比較簡單。首先通過 Git,將 Twemproxy 從 GitHub clone 到目標服務器,然后進入 Twemproxy 路徑,首先執行 $ autoreconf -fvi,然后執行 ./configure ,最后執行 make(當然,也可以再執行 make install),這樣就完成了 Temproxy 的編譯和安裝。然后就可以通過 src/nutcracker -c /xxx/conf/nutcracker.yml 來啟動 Twemproxy 了。
Twemproxy 代理后端資源訪問,這些后端資源的部署信息及訪問策略都是在 YAML 文件中配置。所以接下來,我們簡單看一下 Twemproxy 的配置。如圖所示,這個配置中代理了 2 個業務數據的緩存訪問。一個是 alpha,另一個是 beta。在每個業務的配置詳情里。首先是 listen 配置項,用于設置監聽該業務的端口。然后是 hash 算法和分布算法。Auto_eject_hosts 用于設置在后端 server 異常時,是否將這個異常 server 剔除,然后進行 rehash,默認不剔除。Redis配置項用于指示后端資源類型,是 Redis 還是 Memcached。最后一個配置項 servers,用于設置資源池列表。
以 Memcached 訪問為例,將業務的 Memcached 資源部署好之后,然后將 Mc 資源列表、訪問方式等設到 YAML 文件的配置項,然后啟動 Twemproxy,業務端就可以通過訪問 Twemproxy ,來獲取后端資源的數據了。后續,Mc 資源有任何變更,業務都不用做任何改變,運維直接修改 Twemproxy 的配置即可。
Twemproxy 在實際線的使用中,還是存在不少問題的。首先,它是單進程/單線程模型,一個 event_base 要處理所有的事件,這些事件包括 client 請求的讀入,轉發請求給后端 server,從 server 接受響應,以及將響應發送給 client。單個 Twemproxy 實例,壓測最大可以到 8w 左右的 QPS,出于線上穩定性考慮,QPS 最多支撐到 3~4w。而 Memcached 的線上 QPS,一般可以達到 10~20w,一個 Mc 實例前面要掛 3~5 個 Twemproxy 實例。實例數太多,就會引發諸如管理復雜、成本過高等一系列問題。
其次,基于性能及預防單點故障的考慮,Twemproxy 需要進行多實例部署,而且還需要根據業務訪問量的變化,進行新實例的加入或冗余實例的下線。多個 Twemproxy 實例同時被訪問,如果 client 訪問策略不當,就會出現有些 Twemproxy 壓力過大,而有些卻很空閑,造成訪問不均的問題。
再次,后端資源在 Twemproxy 的 YAML 文件集中配置,資源變更的維護,比直接在所有業務 client 端維護,有了很大的簡化。但在多個 Twemproxy 修改配置,讓這些配置同時生效,也是一個復雜的工作。
最后,Twemproxy 也無法支持 Mc 多副本、多層次架構的訪問策略,無法支持 Redis 的Master-Slave 架構的讀寫分離訪問。
為此,你可以對 Twemproxy 進行擴展,以更好得滿足業務及運維的需要。
Twemproxy 擴展
多進程改造
性能首當其沖。首先可以對 Twemproxy 的單進程/單線程動刀,改為并行處理模型。并行方案可以用多線程方案,也可以采用多進程方案。由于 Twemproxy 只是一個消息路由中間件,不需要額外共享數據,采用多進程方案會更簡潔,更適合。
多進程改造中,可以分別構建一個 master 進程和多個 worker 進程來進行任務處理,如下圖所示。每個進程維護自己獨立的 epoll 事件驅動。其中 master 進程,主要用于監聽端口,accept 新連接,并將連接調度給 worker 進程。
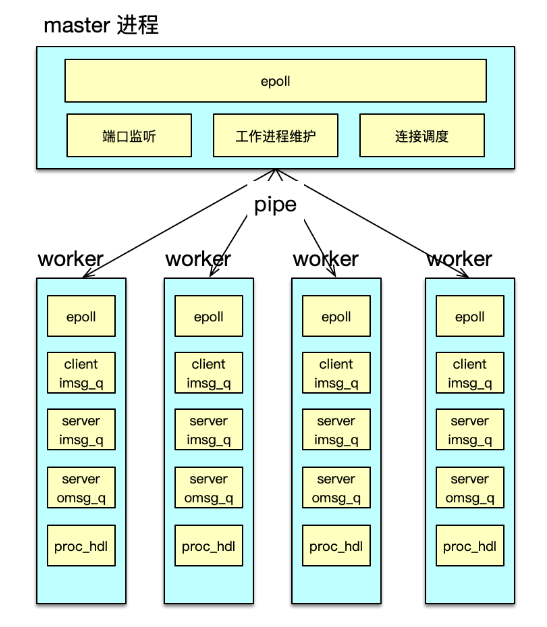
而 worker 進程,基于自己獨立的 event_base,管理從 master 調度給自己的所有 client 連接。在 client 發送網絡請求到達時,進行命令讀取、解析,并在進程內的 IO 隊列流轉,最后將請求打包,pipeline 給后端的 server。
在 server 處理完畢請求,發回響應時。對應 worker 進程,會讀取并解析響應,然后批量回復給 client。
通過多進程改造,Twemproxy 的 QPS 可以從 8w 提升到 40w+。業務訪問時,需要部署的Twemproxy 的實例數會大幅減少,運維會更加簡潔。
增加負載均衡
對于多個 Twemproxy 訪問,如何進行負載均衡的問題。一般有三種方案。
第一種方案,是在 Twemproxy 和業務訪問端之間,再增加一組 LVS,作為負載均衡層,通過 LVS 負載均衡層,你可以方便得增加或減少 Twemproxy 實例,由 LVS 負責負載均衡和請求分發,如下圖。
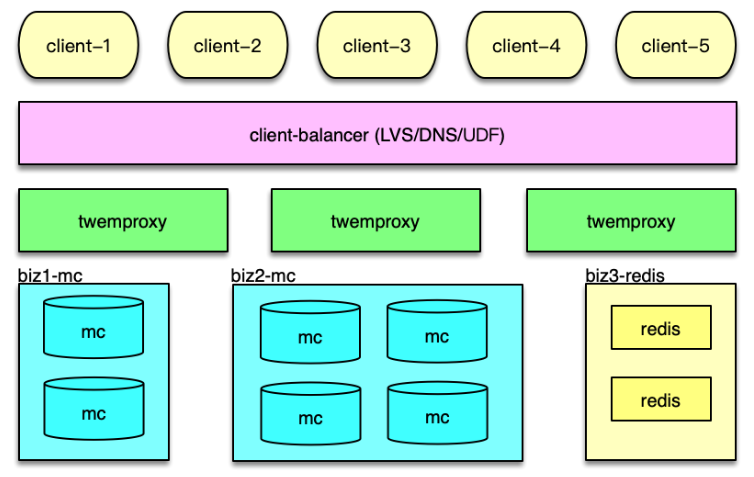
第二種方案,是將 Twemproxy 的 IP 列表加入 DNS。業務 client 通過域名來訪問 Twemproxy,每次建連時,DNS 隨機返回一個 IP,讓連接盡可能均衡。
第三種方案,是業務 client 自定義均衡策略。業務 client 從配置中心或 DNS 獲取所有的Twemproxy 的 IP 列表,然后對這些 Twemproxy 進行均衡訪問,從而達到負載均衡。
方案一,可以通過成熟的 LVS 方案,高效穩定的支持負載均衡策略,但多了一層,成本和運維的復雜度會有所增加。方案二,只能做到連接均衡,訪問請求是否均衡,無法保障。方案三,成本最低,性能也比前面 2 個方案更高效。推薦使用方案三,微博內部也是采用第三種方案。
增加配置中心
對于 Twemproxy 配置的維護,可以通過增加一個配置中心服務來解決。將 YAML 配置文件中的所有配置信息,包括后端資源的部署信息、訪問信息,以配置的方式存儲到配置中心,如下圖。
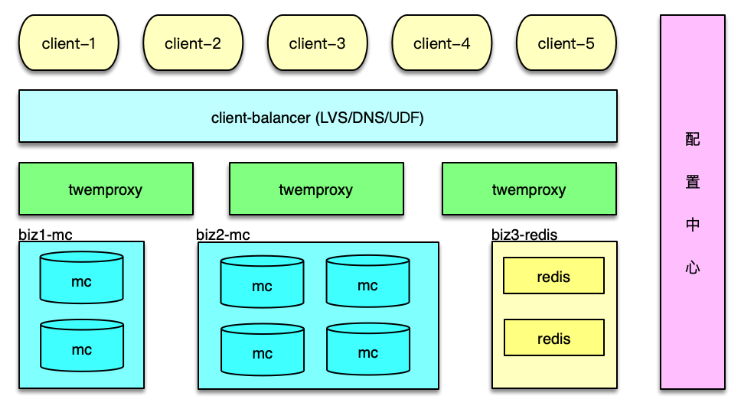
Twemproxy 啟動時,首先到配置中心訂閱并拉取配置,然后解析并正常啟動。Twemproxy 將自己的 IP 和監聽端口信息,也注冊到配置中心。業務 client 從配置中心,獲取Twemproxy 的部署信息,然后進行均衡訪問。
在后端資源變更時,直接更新配置中心的配置。配置中心會通知所有 Twemproxy 實例,收到事件通知,Twemproxy 即可拉取最新配置,并調整后端資源的訪問,實現在線變更。整個過程自動完成,更加高效和可靠。
支持 M-S-L1 多層訪問
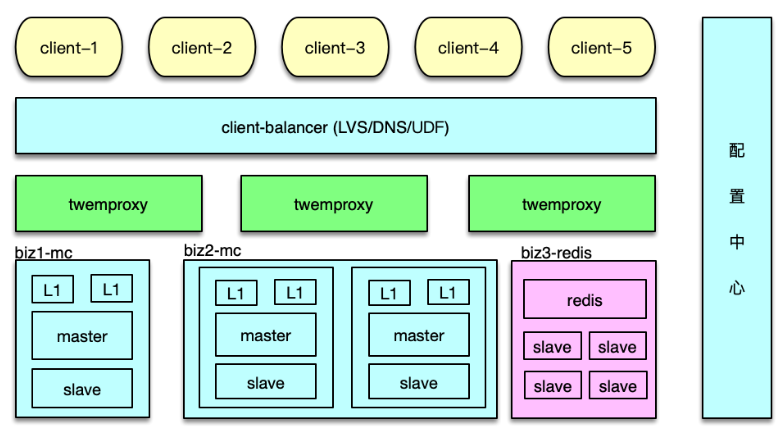
前面提到,為了應對突發洪水流量,避免硬件局部故障的影響,對 Mc 訪問采用了Master-Slave-L1 架構。可以將該緩存架構體系的訪問策略,封裝到 Twemproxy 內部。實現方案也比較簡單。首先在 servers 配置中,增加 Master、Slave、L1 三層,如下圖。
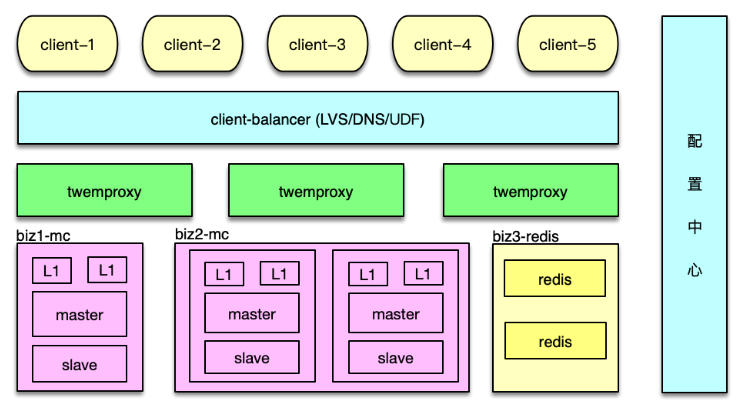
Twemproxy 啟動時,每個 worker 進程預連所有的 Mc 后端,當收到 client 請求時,根據解析出來的指令,分別采用不同訪問策略即可。
- 對于 get 請求,首先隨機選擇一個 L1 來訪問,如果 miss,繼續訪問 Master 和 Slave。中間在任何一層命中,則回寫。
- 對于 gets 請求,需要以 master 為準,從 master 讀取。如果 master 獲取失敗,則從 slave獲取,獲取后回種到 master,然后再次從 master 獲取,確保得到 cas unique id 來自 master。
- 對于 add/cas 等請求,首先請求 master,成功后,再將 key/value 通過 set 指令,寫到 slave 和所有 L1。
- 對于 set 請求,最簡單,直接 set 所有資源池即可。
- 對于 stats 指令的響應,由 Twemproxy 自己統計,或者到后端 Mc 獲取后聚合獲得。
Redis 主從訪問
Redis 支持主從復制,為了支持更大并發訪問量,同時減少主庫的壓力,一般會部署多個從庫,寫操作直接請求 Redis 主庫,讀操作隨機選擇一個 Redis 從庫。這個邏輯同樣可以封裝在Twemproxy 中。如下圖所示,Redis 的主從配置信息,可以用域名的方式,也可以用 IP 端口的方式記錄在配置中心,由 Twemproxy 訂閱并實時更新,從而在 Redis 增減 slave、主從切換時,及時對后端進行訪問變更。
本課時,講解了大數據時代下大中型互聯網系統的特點,訪問 Memcached 緩存時的經典問題及應對方案;還講解了如何通過分拆緩存池、Master-Slave 雙層架構,來解決 Memcached 的容量問題、性能瓶頸、連接瓶頸、局部故障的問題,以及 Master-Slave-L1 三層架構,通過多層、多副本 Memcached 體系,來更好得解決突發洪峰流量和局部故障的問題。
本節課重點學習了基于 Twemproxy 的應用系統架構方案,學習了 Twemproxy 的系統架構和關鍵技術,學習了 Twemproxy 的部署及配置信息。最后還學習了如何擴展 Twemproxy,從而使 Twemproxy 具有更好的性能、可用性和可運維性。
可以參考下面的思維導圖,對這些知識點進行回顧和梳理。
)






)


)



)


)

