MagicLens:Self-Supervised Image Retrieval with Open-Ended Instructions
MagicLens: 自監督圖像檢索與開放式指令
- 作者:Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, Ming-Wei Chang
- 單位:Google
- 官網地址:https://open-vision-language.github.io/MagicLens
- 論文地址:https://arxiv.org/abs/2403.19651
- Benchmark:https://mmmu-benchmark.github.io
“MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions” 是一項關于圖像檢索的新研究。這項研究的核心在于,通過使用大型多模態模型和大型語言模型,能夠將圖像對中的隱含關系(如網頁上的"內部視圖")顯式化。MagicLens 是一種自監督的圖像檢索模型,支持開放式指令。這些模型基于一個關鍵的新見解:自然出現在同一網頁上的圖像對包含廣泛的隱含關系,并且可以通過合成指令來使這些關系明確化。
MagicLens 在 36.7M 個(查詢圖像、指令、目標圖像)三元組上進行訓練,這些三元組是從網頁中挖掘的,包含了豐富的語義關系。這些模型在多個圖像檢索任務基準測試中實現了與之前最先進(SOTA)方法可比或更好的結果,并且在多個基準測試中以 50 倍更小的模型大小超越了之前的 SOTA 方法。此外,MagicLens 能夠滿足由開放式指令表達的多樣化搜索意圖。
在數據構建方面,MagicLens 利用大型多模態模型和大型語言模型來構建高質量的三元組(查詢圖像、文本指令、目標圖像)用于模型訓練。模型訓練方面,MagicLens 基于單模態編碼器,這些編碼器是從 CLIP 或 CoCa 初始化的,并使用簡單的對比損失進行訓練。具有雙編碼器架構的 MagicLens 能夠同時處理圖像和文本輸入,以提供 VL 嵌入,從而實現多模態到圖像和圖像到圖像的檢索。此外,底部的單模態編碼器可以重新用于文本到圖像的檢索,獲得性能提升。
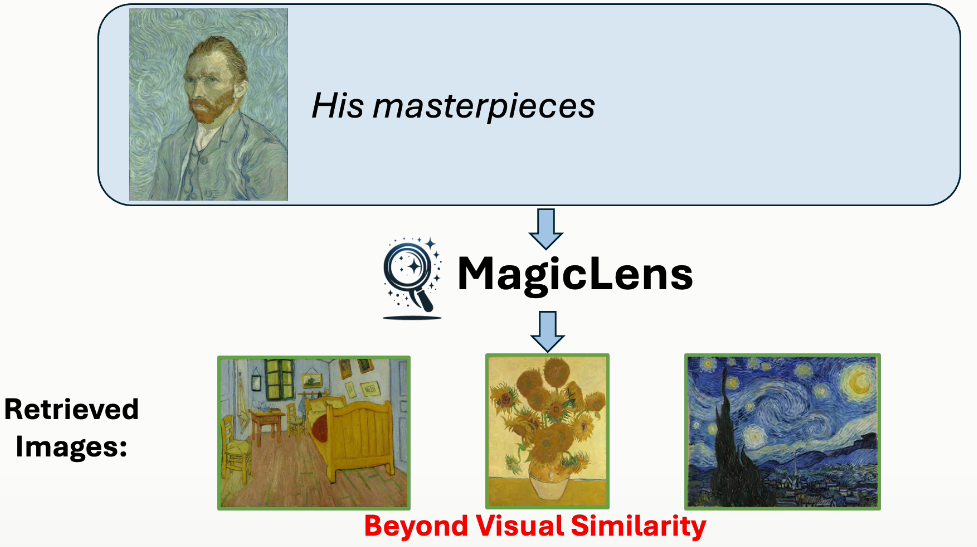
MagicLens 展示了文本指令能夠使圖像檢索具有更豐富的關系,超出了視覺相似性。這項研究證明了即使在模型大小大幅縮小的情況下,文本指令仍然能夠提高圖像檢索的效果。
該項工作的效果確實挺好,在工程應用方面也具有極高的實踐價值,目前尚未開源。這里先詳細閱讀一下該工作的論文全文。
摘要
圖像檢索,即給定參考圖像尋找所需圖像,本質上包含了豐富的、多方面的搜索意圖,這些意圖僅通過基于圖像的度量難以捕獲。最近的工作利用文本指令讓用戶更自由地表達他們的搜索意圖。然而,現有工作主要關注的是視覺上相似的圖像對以及可以由一組預定義關系描述的圖像對。本文的核心論點是,文本指令可以使檢索到的圖像具有超越視覺相似性的更豐富的關系。為了展示這一點,引入了MagicLens,這是一系列支持開放式指令的自監督圖像檢索模型。MagicLens建立在一個關鍵的新見解上:自然出現在同一網頁上的圖像對包含廣泛的隱含關系(例如,內部視圖),可以通過大型多模態模型(LMMs)和大型語言模型(LLMs)合成指令來使這些隱含關系明確化。
在從網頁中挖掘的包含豐富語義關系的三元組(查詢圖像、指令、目標圖像)上進行訓練,MagicLens在八個不同圖像檢索任務基準測試上取得了與先前最先進(SOTA)方法可比或更好的結果。值得注意的是,它在多個基準測試上以50倍更小的模型大小超越了之前的SOTA。此外,對一個未見過的140萬圖像數據集進行的實驗進一步證明了MagicLens支持的搜索意圖的多樣性。
引言
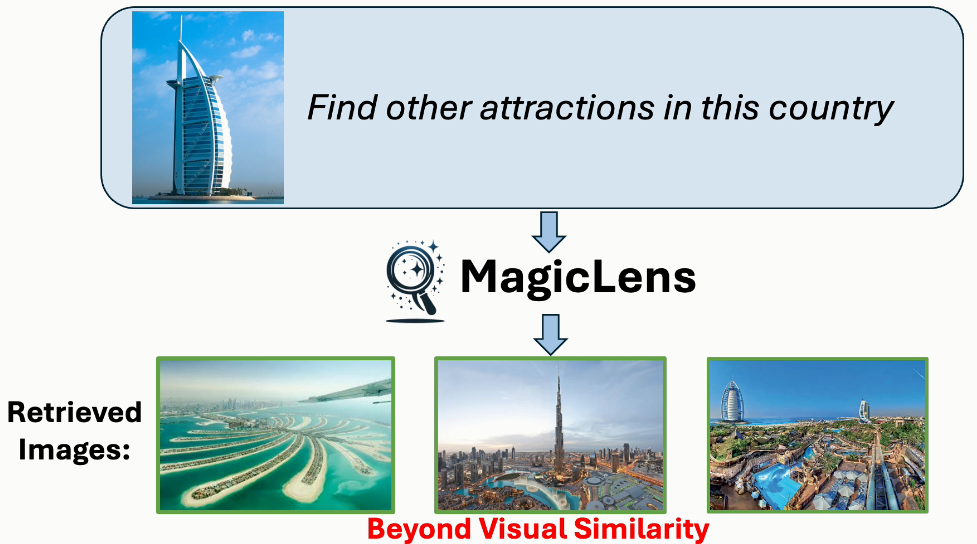
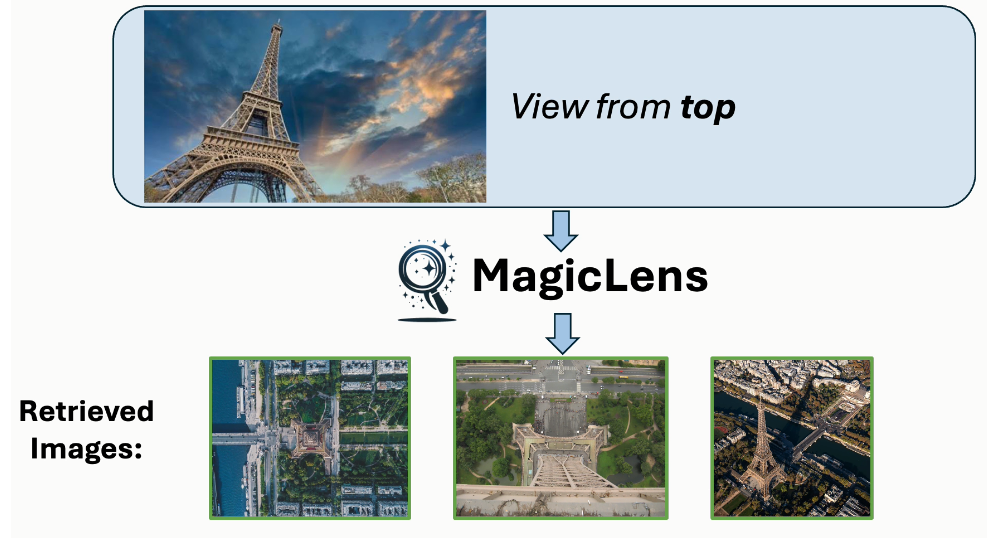
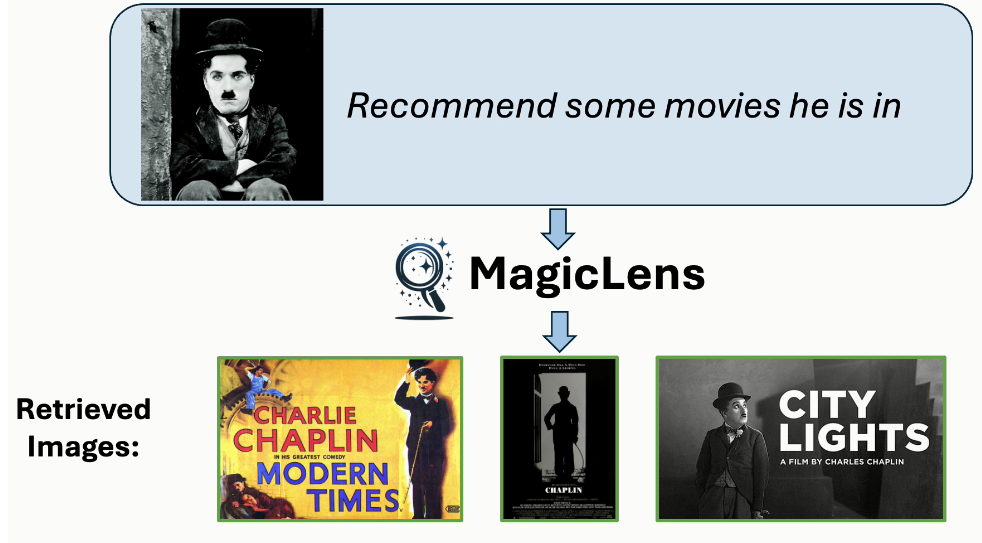
圖像檢索是計算機視覺領域的一個長期存在的問題(Datta等人,2008年;Gordo等人,2016年),具有廣泛的現實世界應用,如視覺搜索、目標定位和重新識別。然而,自其誕生以來,這個任務就因為圖像中封裝的復雜和豐富的內容而受到定義模糊的困擾。相似的圖像可能在關鍵方面有所不同,而不同的圖像可以有共同點。在圖像搜索場景中,用戶經常為單個查詢圖像呈現多個搜索意圖,表明僅憑圖像相關性不足以獲得精確的搜索結果。例如,當用迪拜的Burj Al Arab酒店的圖像進行搜索時(見圖1),用戶可能尋找迪拜的其他景點或內部視圖,每個都與查詢圖像有不同關系。因此,將表達搜索意圖的文本指令融入其中對于提高檢索精度至關重要,也是不可或缺的。理想情況下,模型應該準確捕捉和解釋由開放式文本指令傳達的多樣化的現實世界搜索意圖。
這些開放式搜索指令涵蓋廣泛的主題和概念,反映了用戶與視覺內容互動的多樣方式,要求檢索系統不僅要掌握圖像的視覺特征,還要掌握查詢圖像與期望結果之間在指令中表達的細微語義關系。然而,現有的模型要么針對一個或幾個受限領域進行優化(Vo等人,2019年;Wu等人,2021年;Liu等人,2023年;Baldrati等人,2023年),其中視覺相似性的類型是作為先驗手動定義的,要么調整模型架構和訓練方案以利用圖像-字幕數據(Chen和Lai,2023年;Saito等人,2023年;Baldrati等人,2023年;Gu等人,2024年),或者依賴從預定義指令模板構建的合成數據(Brooks等人,2023年;Gu等人,2023年)。因此,這兩種研究方向都無法有效建模開放式指令,正如圖1所示。

圖1. 使用MagicLens和先前最先進(SOTA)方法(Gu等人,2024年)從包含140萬張圖像的檢索池中檢索到的第一張圖像。盡管先前SOTA方法接受文本指令,但它主要基于查詢圖像的視覺相似性進行檢索,忽略了文本指令的細微差別。相比之下,MagicLens在檢索視覺上相似的圖像以及與文本指令的更深層含義和上下文相符的圖像方面表現出色——即使這些圖像與查詢圖像不相似。例如,如果給定迪拜的Burj Al Arab酒店的查詢圖像和指令“在這個國家尋找其他景點”,MagicLens可以成功定位迪拜棕櫚島的圖像
在這篇論文中,我們介紹了MagicLens,這是一系列在廣泛的(查詢圖像、指令、目標圖像)三元組上進行訓練的自監督圖像檢索模型,這些三元組反映了從網頁中挖掘的自然語義關系,并且使用了最先進的(SOTA)基礎模型進行篩選。具體來說,從同一網頁上自然出現的圖像對中提取圖像對,形成包含豐富但自然的語義關系的正對。然后,應用大型多模態模型(Chen等人,2023b;a)和大型語言模型(Anil等人,2023年)來細化這些開放式語義關系的描述,形成開放式指令。圖2展示了數據構建流程的概述。作為具體例子,一個展示尼康相機圖像和尼康充電器圖像的相機評論網站可能會提供一種有趣且非瑣碎的關系“產品的充電器”,然后通過LMM+LLM管道進行篩選,并產生最終指令“尋找它的充電器”。這個過程產生了描繪超越單純視覺相似性的多樣化語義關系的開放式指令,結果是一個包含36.7M高質量三元組的大規模訓練數據集,覆蓋了廣泛的分布。

圖2. 數據構建的概述。收集了同一網頁上自然出現的圖像對,并使用PaLI+PaLM2來生成連接這兩幅圖像的指令
使用構建的數據集,訓練了名為MagicLens的雙編碼器模型,這些模型根據由圖像和指令組成的查詢來檢索圖像。模型在八個基準測試上取得了與先前最先進(SOTA)方法可比或更好的結果,這些基準測試包括各種多模態到圖像和圖像到圖像的檢索任務。此外,MagicLens可以保留甚至顯著提高底層單模態編碼器的文本到圖像檢索性能。與先前SOTA方法相比,MagicLens的模型大小小了50倍,在多個基準測試上取得了更好的成績:CIRCO(Baldrati等人,2023年)、Domain Transfer ImageNet(Saito等人,2023年)和GeneCIS(Vaze等人,2023年)。為了進一步檢驗模型在更現實場景中的能力,構建了迄今為止最大的檢索池,包含140萬未見過的圖像,并使用人類編寫的具有多樣化指令的搜索查詢進行檢索。人類評估發現,MagicLens可以成功滿足復雜且超越視覺搜索意圖的需求,而先前SOTA方法則無法做到這一點。
本文貢獻主要有三個方面:
- 為圖像檢索帶來了新的見解:來自同一網頁的自然出現的圖像對是強大的自監督訓練信號。基于此,提出了一種有效的方法,利用LMMs和LLMs,構建了包含36.7M三元組的訓練數據。
- 引入了MagicLens,這是一系列輕量級雙編碼器,它們共同嵌入圖像和指令對,并在構建的數據集上進行訓練。在多個基準測試中,MagicLens超過了先前最先進(SOTA)方法,但模型大小只有其50分之一。
- 對一個140萬規模的數據集進行了深入的人類評估和分析,這是迄今為止規模最大的。令人印象深刻的高成功率表明,MagicLens能夠很好地捕捉和滿足多樣化的搜索意圖,尤其是復雜和超越視覺意圖。
相關工作
預訓練多模態編碼器。多模態編碼器預訓練(Faghri等人,2017年;Chen等人,2021年;Radford等人,2021年;Yu等人,2022年;Li等人,2021年;Kim等人,2021年;Wang等人,2023年;Li等人,2022年;2023年;Cherti等人,2023年)近年來取得了巨大成功。這些模型在大規模圖像-字幕數據(Zhai等人,2022年;Schuhmann等人,2022年)上進行預訓練,將不同模態的表示對齊到聯合空間中,實現了零樣本跨模態檢索。然而,這些工作主要關注編碼單個模態,而沒有考慮多個模態組合表示。一些后來的工作(Hu等人,2023a;Chen等人,2023c;Wei等人,2023年)試圖通過在預訓練的單模態編碼器頂部微調少量參數來結合文本和圖像嵌入,而沒有大規模聯合預訓練。因此,這種適應策略在對我們感興趣的任務上的表現較差,強調了MagicLens自監督訓練的重要性。
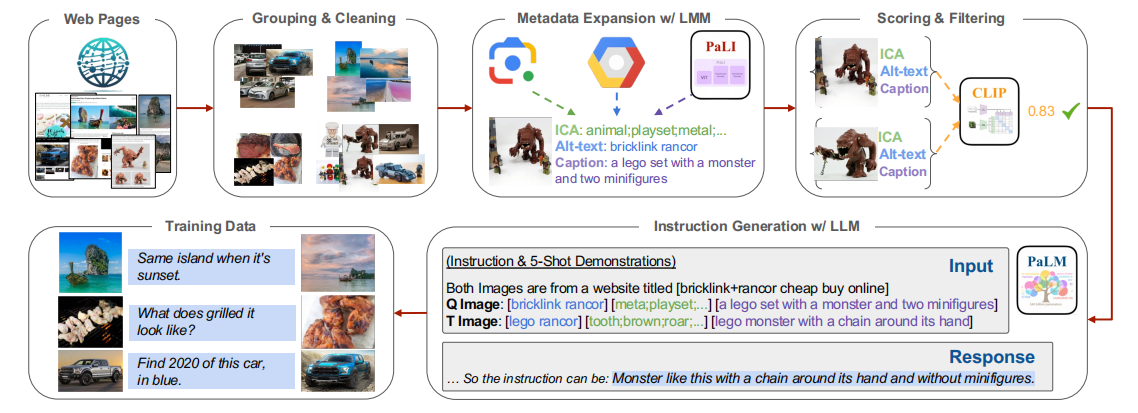
圖3. 數據構建流程。通過以下步驟從網頁中挖掘圖像對:
(1)將同一網頁上的圖像分組并清理;
(2)使用LMM為每張圖像標注元數據;
(3)對不合格的圖像對進行評分和過濾;
(4)使用LLM為剩余的圖像對生成開放式指令;
組合圖像檢索。組合圖像檢索(CIR;Vo等人,2019年)與我們的任務形式相同。然而,所有現有的基準測試(Liu等人,2021年;Baldrati等人,2023年;Wu等人,2021年)都是首先收集視覺上相似的圖像,然后為圖像對編寫指令。這限制了這些基準測試上圖像關系的豐富性以及基于/為它們開發的模型的豐富性。最近的零樣本CIR工作要么設計輕量級的模態轉換,要么調整訓練和模型以使用現有的圖像-字幕數據(Saito等人,2023年;Baldrati等人,2023年;Gu等人,2024年)。CIReVL(Karthik等人,2024年)使用LLM和LMM即時進行CIR,限制了其效率。請參閱附錄B以獲取這些方法的更多細節。在構建訓練數據方面,CompoDiff(Gu等人,2023年)使用LLM和圖像生成模型合成18M三元組,遵循與Brooks等人(2023年)相同的流程。我們數據與他們數據的關鍵區別在于圖像質量和圖像關系。如圖2所示,我們的數據來自同一網頁上發現的自然圖像對。因此,數據覆蓋了廣泛的分布上的開放式圖像關系,包括視覺和非視覺關系。
帶指令的檢索。指令調整(Ouyang等人,2022年)使模型在檢索文本內容(Su等人,2023年;Asai等人,2023年)和多模態內容(Wei等人,2023年)方面具有強大的跨域和零樣本泛化能力。然而,先前的努力主要關注使用手動編寫的指令作為實際查詢的任務前綴,在百級基礎上統一不同的檢索任務。相比之下,本文的方法利用了百萬級的指令,這些指令自然表達了用戶的搜索意圖。
MagicLens
自監督訓練的數據構建
網頁包含多模態上下文,涉及相關主題的交織文本和圖像。通過共現從同一網頁中提取的圖像對通常暗示了圖像與特定關系之間的關聯。這涵蓋了廣泛的圖像關系,范圍從視覺相似性到更微妙的聯系(例如,圖2)。因此,這些自然出現的圖像對為圖像檢索模型提供了優秀的自監督訓練信號。基于這一見解,提出了一種系統的數據構建流程,用于從網頁中挖掘圖像對,并采用LLM生成開放式指令,明確傳達每對圖像內的圖像關系。
從網頁中挖掘圖像對。
-
(1) 組群與清理。從Common Crawl2收集所有具有相同URL的圖像,作為同一網頁上的圖像組,用于可能的配對。由于簡單的組群不可避免地引入了噪聲圖像,移除了重復的、低分辨率的和廣告圖像,以及高度重疊的組群,這導致了大量更密集且本質相連的圖像組。
-
(2) 元數據擴展。為了為后續的LLM提供大量元數據擴展的詳細文本信息,為圖像標注了Alt-texts、圖像內容注釋(ICA)標簽和字幕。如果圖像的Alt-texts不合格,將丟棄這些圖像。對于ICA標簽,為每張圖像標注了如一般物體和活動等實體。對于圖像字幕,采用最先進的LMM-PaLI(Chen等人,2023a)來生成字幕。每種類型的元數據都從不同的角度提供了關于圖像的文本信息。更多細節請參閱附錄A。
-
(3) 評分與過濾。在獲得帶有廣泛元數據的圖像組之后,在同一組內配對圖像,并使用相關性度量的組合來消除不合格的配對。使用CLIP圖像到圖像的評分來評估視覺相關性,以及文本到文本的評分來評估非視覺相關性。那些在兩個方面得分都低的圖像對被排除在考慮之外。為了避免重復圖像和重復關系的過度采樣,為每個組設置最多三對圖像,從而確保訓練數據中圖像和關系的更均勻分布(見圖5)。
開放式指令生成。有了高質量配對圖像的信息豐富的元數據,LLM能夠很好地理解圖像內容(ICA和字幕)及其背景信息(Alt-text)。使用指令(Chung等人,2022年)、少樣本演示(Brown等人,2020年)和鏈式思維提示(Wei等人,2022年)技術,PaLM2(Anil等人,2023年)生成連接配對圖像(imageq, imaget)的開放式指令。圖3展示了生成的指令,附錄10顯示了詳細的提示和演示。最終,獲得了36.7M三元組( i m a g e q , t e x t , i m a g e t image_q, text, image_t imageq?,text,imaget?) 用于自監督圖像檢索訓練。
MagicLens模型
模型設計。如圖4所示,采用一個簡單的雙編碼器架構,共享參數,并使用CoCa(Yu等人,2022年)或CLIP(Radford等人,2021年)初始化視覺和語言編碼器。為了實現深度的模態集成,引入了多個自注意力層,并設計了一個單多頭注意力池化器,將多模態輸入壓縮成一個單一的嵌入 r r r,用于后續匹配。此外,由于檢索目標僅包含圖像而不包括伴隨文本,使用空文本占位符“ ”將目標轉換為多模態輸入。用 r q r_q rq?表示多模態查詢( i m a g e q , t e x t image_q, text imageq?,text)的嵌入,用 r t r_t rt?表示目標( i m a g e t image_t imaget?, “ ”)的嵌入。考慮到效率,提出了MagicLens-B和MagicLens-L,分別使用基礎和大型檢查點進行初始化。
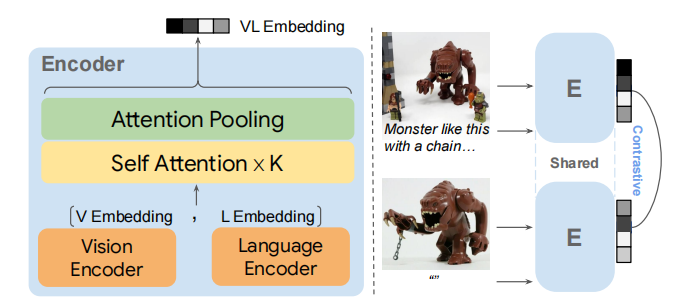
圖4. MagicLens編碼器(E)的模型架構和訓練,它將視覺和語言嵌入作為序列輸入到自注意力層中進行模態集成
模型訓練。使用一個簡單的對比損失來訓練MagicLens,模型通過在訓練批次中對比配對的查詢-目標與其他目標來進行更新。特別是,由于查詢圖像本身( i m a g e q image_q imageq?)可以作為多模態查詢( i m a g e q , t e x t image_q, text imageq?,text)的具有挑戰性的硬負樣本,將查詢圖像本身和空文本組合起來編碼( i m a g e q , “” image_q, “ ” imageq?,“”)以得到 r t ′ r'_t rt′?作為額外的查詢負樣本。為了增加負樣本的數量,對于每個查詢圖像,使用同一批次中的所有查詢負樣本和其他目標負樣本。正式地,對于第 i i i個訓練示例,損失函數 L i L_i Li?定義為:
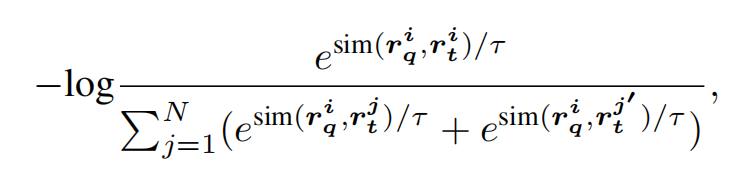
其中 s i m ( , ) sim(,) sim(,)表示余弦相似度函數, r q T r t ∣ ∣ r q ∣ ∣ ? ∣ ∣ r t ∣ ∣ \frac{rq^Tr_t}{||r_q||·||r_t||} ∣∣rq?∣∣?∣∣rt?∣∣rqTrt?? , N N N指代采樣的批次大小, τ τ τ是對數縮放中的溫度超參數。更多實現細節請參閱附錄A。
實驗
實驗設置
基準測試和指標。為了全面評估MagicLens的多模態到圖像檢索能力,在零樣本、一個檢查點設置中考慮了三個相關任務:
- (1)組合圖像檢索(CIR)
- (2)領域遷移檢索
- (3)條件圖像相似性
每個任務都有不同的但有限的圖像關系集合。表2顯示了五個基準測試的詳細統計數據。

表2. 五個評估基準測試的統計數據。平均了子任務(例如,FIQ)中的查詢數量。# Index代表所有查詢共享的檢索池的大小,# Subset Index是每個查詢專用的子集的平均大小
組合圖像檢索。考慮了一個領域特定的基準和一個開放域基準,以評估模型的領域適應性和其在真實世界自然圖像上的能力。FIQ(Wu等人,2021年)是一個時尚領域的基準,包含三個獨立的檢索子任務:連衣裙、襯衫和T恤。遵循之前的工作(Saito等人,2023年;Baldrati等人,2023年;Gu等人,2024年),在其驗證集上進行評估,并報告子任務平均召回率。CIRR(Liu等人,2021年)是第一個基于自然圖像(Suhr等人,2019年)構建的數據集,其中查詢圖像和目標圖像之間有九個預定義的關系。它還設計了一個子集檢索設置,其中模型從每個查詢的專用小子集中檢索目標圖像。然而,除了檢索池的大小有限外,它還受到假陰性問題的困擾,正如Baldrati等人(2023年)所指出的。使用召回率(R和Rs)來評估標準檢索和子集檢索。相比之下,為了更好地與現實世界的大規模檢索對齊,CIRCO為每個查詢標注了多個真值,并使用超過120K的自然圖像(Lin等人,2014年)作為索引集。因此,視CIRCO為主要的基準。由于每個查詢都有多個目標,采用平均平均精度(mAP)作為評估指標。
領域遷移檢索。域遷移ImageNet(DTIN;Saito等人,2023年)旨在從另一個域中檢索與查詢圖像中顯示的相同概念對象相關的圖像。它由ImageNet(Deng等人,2009年)中的自然圖像和ImageNet-R(Hendrycks等人,2021年)中的其他域中的圖像構建而成。例如,**給定一個域關鍵詞“卡通”和一個真實馬的圖像作為查詢,模型期望從多個域的索引集中檢索到卡通馬的圖像。**它覆蓋了4個域、10K個對象和超過16K張圖像作為索引集。遵循先前的工作(Saito等人,2023年;Karthik等人,2024年),報告子任務平均召回率。
條件圖像相似性。GeneCIS(Vaze等人,2023年)是一個關鍵詞條件下的圖像相似度測量基準。它有四個子任務,涉及改變或聚焦給定圖像的屬性或對象。對于每個查詢圖像和關鍵詞,模型需要從平均有13.8張圖像的專用小子集中找到與查詢圖像最相似的圖像,條件是給定的關鍵詞。例如,在帶有關鍵詞“汽車”和一張圖像的變化-對象子任務中,模型需要找到另一張圖像,但其中包含額外的汽車。
Baseline基線。考慮了幾個基線:(1)PALARVA(Cohen等人,2022年),(2)Pic2Word(Saito等人,2023年),(3)SEARLE(Baldrati等人,2023年),(4)ContextI2W(Tang等人,2024年),(5)LinCIR(Gu等人,2024年),(6)CIReVL(Karthik等人,2024年)(7)CompoDiff(Gu等人,2023年)和(8)PLI(Chen & Lai,2023年)。這些方法的詳細描述見附錄B。
多模態到圖像檢索
表1顯示了三個任務在五個基準測試上的結果,從中可以得出以下觀察結果:
- 首先,在可比的模型大小下,基于CLIP和CoCa的MagicLens在四個開放域基準測試上大幅超越了先前最先進模型,尤其是CoCa基礎的MagicLens-L在具有挑戰性的CIRCO(mAP@5從12.6提高到34.1)和DTIN(R@10從12.9提高到48.2)上的表現,這顯示了MagicLens的強大能力。在附錄C中提供了完整結果,并在第5.2節中進行了詳細的參數效率分析。
- 其次,通過比較MagicLens-L和MagicLens-B,發現在五個基準測試上普遍存在性能提升。這表明構建的數據質量很高,可以受益于更大的模型。此外,這一觀察結果還顯示了得益于簡單雙編碼器模型架構和對比損失的可擴展性。
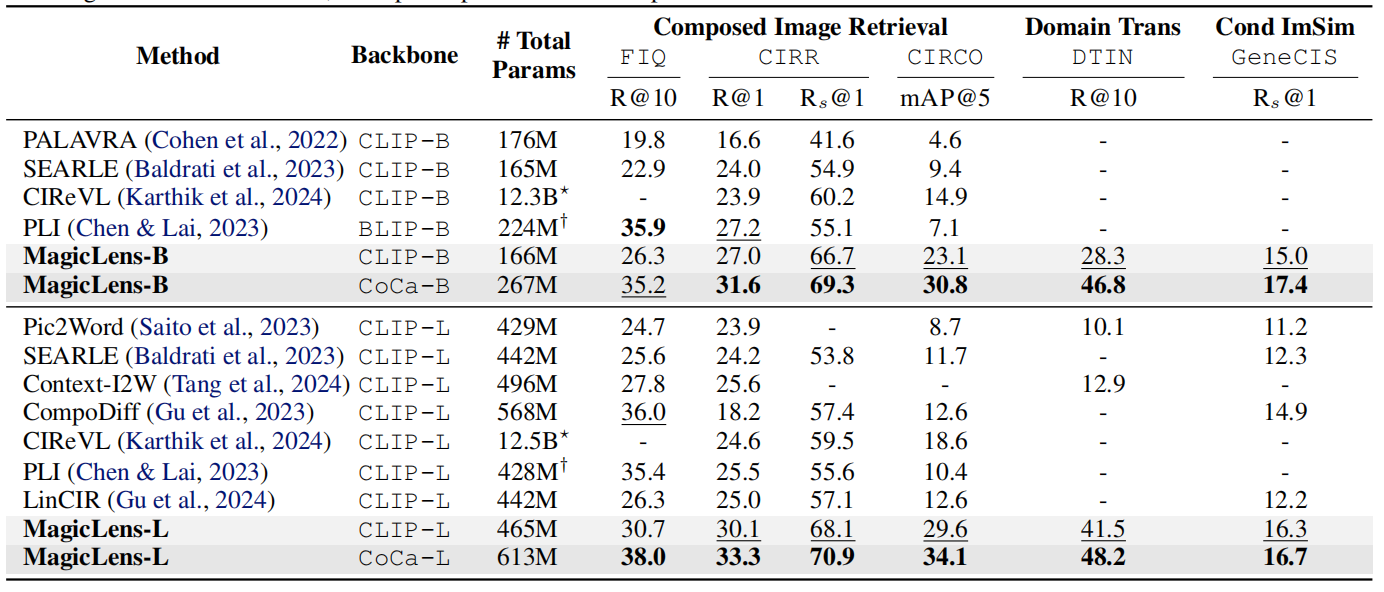
表1. 在三個多模態到圖像檢索任務上的五個基準測試上的性能比較。基線的成果來自原始論文。在最佳結果上使用粗體標記,在第二佳結果下劃線。?CIReVL使用包括ChatGPT在內的多個模型組件進行檢索,報告了已知大小的組件的參數數量。?PLI沒有發布代碼,所以只進行了估計
圖像到圖像檢索
盡管MagicLens模型是針對 ( i m a g e q , t e x t ) → i m a g e t (image_q, text)→ imaget (imageq?,text)→imaget任務格式進行訓練的,但它們可以通過為所有 i m a g e q image_q imageq?提供固定的文本指令自然地覆蓋 i m a g e q → i m a g e t image_q → image_t imageq?→imaget?任務。作為一個案例研究,考慮了零樣本素描基礎圖像檢索(ZS-SBIR)任務,其中模型需要根據素描檢索自然圖像。簡單地為所有查詢圖像使用“找到它的自然圖像”指令,MagicLens可以執行這樣的任務。
遵循這個領域之前的零樣本SOTA方法(Liu等人,2019年;Lin等人,2023年),考慮了三個基準測試,分別是TU-Berlin(Zhang等人,2016年)、Sketchy(Yelamarthi等人,2018年)和QuickDraw(Dey等人,2019年)。
- TU-Berlin包含30個類別、2,400個素描查詢和27,989張自然圖像作為索引集;
- Sketchy包含21個在ImageNet-1K中未見的類別和12,694個查詢,索引集包含12,553張自然圖像
- QuickDraw包含30個類別、92,291個查詢和54,146個大小的索引集。
對于每個數據集,都報告了先前SOTA工作(Lin等人,2023年)中使用的mAP和精度指標。
值得注意的是,與之前使用針對每個數據集單獨訓練的檢查點并在上述保留測試集上進行評估的零樣本方法不同,在所有基準測試上使用相同的檢查點進行評估。結果報告在表4中,可以發現本文提出的模型在保持單一檢查點設置的情況下顯著優于先前的SOTA方法,這展示了MagicLens模型的強大泛化能力和它們能夠覆蓋的多樣性任務。
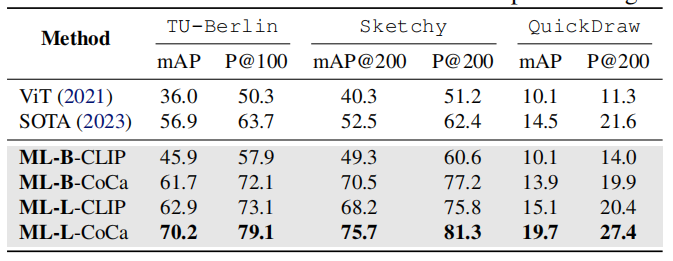
表4. 在三個圖像到圖像檢索基準測試上的結果。基線的成果來自Lin等人(2023年),每個基準測試使用單獨的檢查點,而MagicLens(ML)模型在單一檢查點設置下跨基準測試進行評估
文本到圖像檢索
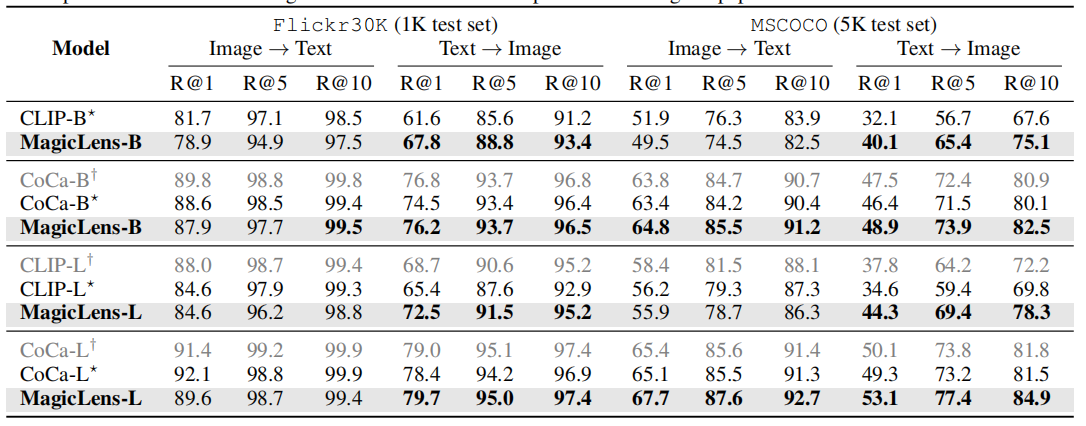
由于MagicLens模型基于視覺和語言編碼器構建,這些編碼器在訓練后仍然可以用于圖像→文本和文本→圖像檢索任務。因此,在Flickr30k(Plummer等人,2015年)和MSCOCO(Chen等人,2015年)上評估MagicLens的編碼器,使用與先前工作(Radford等人,2021年;Yu等人,2022年)相同的數據集劃分和評估指標。
表3顯示了原始編碼器與經過MagicLens訓練更新的編碼器之間的比較。對于文本→圖像任務,可以觀察到在兩個數據集上所有指標的一致性和非瑣碎的改進。對于圖像→文本任務,觀察到輕微的下降。這些觀察結果表明,本文的訓練方案可以增強文本到圖像檢索的編碼器,也可以得出同樣的結論關于CLIP,詳細見表17。改進可能源于多模態到圖像訓練任務需要深入理解文本指令,從而改善了語言編碼器。這些文本到圖像的結果表明,MagicLens可以成功處理三種圖像檢索任務形式,并取得了所有強結果,考慮到上述其他任務的表現。
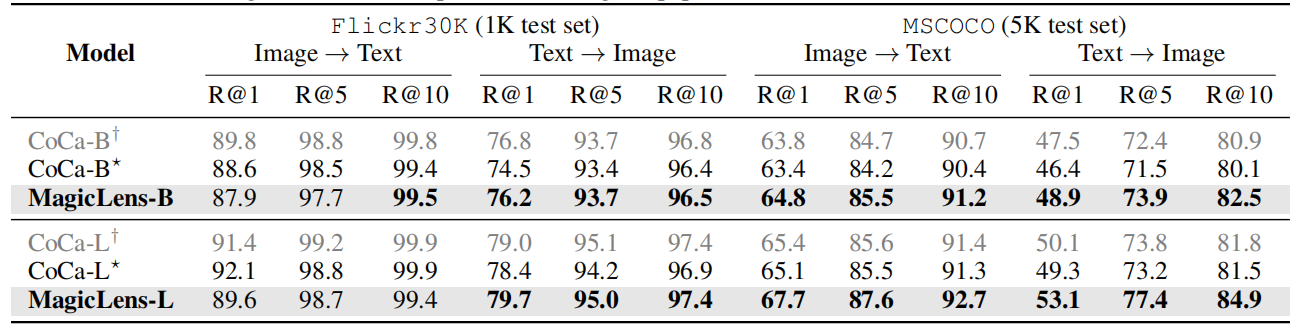
表3. 零樣本圖像-文本檢索結果。如果它們比初始化檢查點更好,則結果用粗體標記。?CoCa重新制作并用于MagicLens。?CoCa在原始論文中報告
分析
數據分析
與現有訓練數據的比較。先前的數據構建方法,包括CompoDiff(Gu等人,2023年)和InstructPix2Pix(IP2P;Brooks等人,2023年),使用合成的圖像對和本質上基于模板的指令來訓練圖像檢索模型。考慮到數據可用性和CompoDiff采用與IP2P類似的創建流程,本文使用IP2P數據作為基線,探索不同訓練數據對下游模型的影響。將一個基于CoCa的MagicLens-B模型,該模型在所有IP2P數據(1M)上訓練,與一個在相同大小的下采樣數據上訓練的模型進行比較,使用相同的訓練方案。表5顯示,MagicLens + Ours在所有五個基準測試上均優于使用IP2P數據的其變體(MagicLens + IP2P)。這證明了我們的數據,包括自然圖像和無模板指令,可以實現更強大的圖像檢索模型。詳細比較請參閱附錄C。

圖5. IP2P數據和我們的數據的Word分布
此外,將這兩種模型與IP2P訓練的CompoDiff進行比較,CompoDiff是一種專門為使用合成圖像設計的檢索模型。盡管CompoDiff具有特定的設計,但MagicLens + IP2P仍然優于CompoDiff + IP2P。此外,它在CIRCO、DTIN和GeneCIS上的結果優于先前可比大小的SOTA基線。這表明了我們的訓練方案的優勢,因為模型即使在使用次優數據訓練時也能取得相當不錯的結果。
為了提供更多見解,在圖5中分別可視化了IP2P和我們的數據中的指令詞匯。正如所看到的,IP2P數據由于其基于模板的性質,具有大量如“turn”和“make”的指令關鍵詞。此外,它還有很多“photograph”和“painting”這樣的粗粒度關鍵詞。相比之下,由于從一個網頁中控制采樣(如第3.1節所述),數據具有更多樣化和均勻分布的關鍵詞,覆蓋了如“brand”這樣的細粒度標簽。
數據擴展。為了探究數據規模對模型的影響,在隨機采樣的0.2M、0.5M、1M、5M、10M、25M和整個36.7M三元組上訓練CoCa-based MagicLens-B。五個基準測試及其平均性能的結果在圖6中展示。隨著數據大小的增加,MagicLens的平均性能得到提升,尤其是在達到10M之前。這表明了擴展數據的有效性。
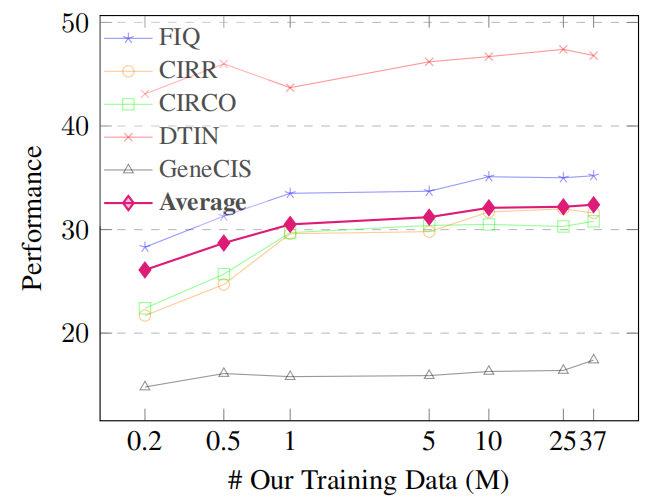
圖6.基于coca的magiclen-b在不同大小的數據訓練時的性能
訓練期間指令的影響。之前工作中使用的指令(Brooks等人,2023年;Gu等人,2023年)是基于模板的,而我們的指令是無模板的。為了探究不同指令對下游模型的影響,也為在第3.1節中收集的自然出現的圖像對合成基于模板的指令。具體來說,由于每張圖像都有大量信息豐富的元數據,利用LLM確定關鍵元數據來填充預定義的句子結構。對于無模板指令,LLM被特別引導以生成多樣且連貫的指令,不遵循任何固定的模板。在附錄中的圖10中展示了不同指令的具體例子。
表6比較了兩個基于CoCa的MagicLens-B模型的性能。它們都使用1M三元組進行訓練,使用相同的圖像對,但上述提到的不同指令。無模板指令明顯導致更強的模型,如在所有基準測試上相對于其他模型的結果一致更好所證明的。這表明自然表達和多樣的指令可以更好地激發模型理解圖像關系并遵循指令。

表6. 使用基于模板和無模板指令訓練的CoCa-based MagicLens-B在1M規模的結果
模型分析
模型大小與性能。先前最先進的方法(Gu等人,2024年;2023年)考慮使用更大型的視覺和語言編碼器(Cherti等人,2023年)或實時使用LMMs和LLMs(Karthik等人,2024年)以獲得性能收益。然而,在實際部署中還應考慮模型大小和相關效率。在圖7中,可視化了各種模型在GeneCIS、CIRCO和DTIN基準測試上的模型大小與性能之間的關系。
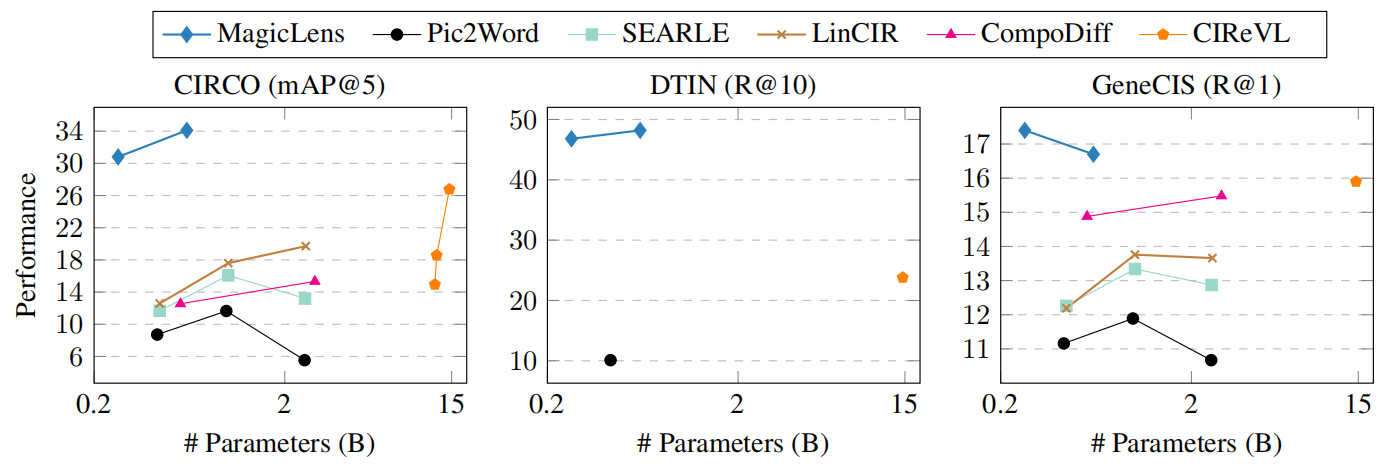
圖7. 模型大小與性能。MagicLens-B在三個任務上優于SOTA CIReVL,即使模型大小小50倍
GeneCIS和CIRCO的結果來自Gu等人(2024年;2023年),使用了CLIP-Large、OpenCLIP-Huge和OpenCLIP-Giant后端(Radford等人,2021年;Cherti等人,2023年)。CIReVL(Karthik等人,2024年)在DTIN和GeneCIS上的結果并未被作者完全報告。省略了ChatGPT的大小,只計算CIReVL的其他模型組件的參數(例如,BLIP2-FLANT5-XXL + OpenCLIP-Giant)。
盡管CoCa-based MagicLens-B(267M)的模型大小比其他基線(例如,CIReVL為14.6B)小50倍,但它在這些基準測試上取得了更好的性能,尤其是在DTIN上有顯著優勢。這一觀察結果證明了我們的模型中參數共享設計引入的高參數效率以及我們的數據在實現性能強大而參數小型模型方面的強大優勢。詳細結果見附錄表14、15和16。
對比損失Contrastive Loss的消融實驗。與標準對比損失相比,在訓練期間將查詢圖像作為硬負樣本。為了探究這一設計的影響,訓練了一個不包含這些硬負樣本的CoCa-based MagicLens-B,并在表7中報告了結果。可以看到,沒有查詢負樣本時,MagicLens在所有基準測試上的性能都下降了,在CIRR、CIRCO和DTIN基準測試上的下降尤為顯著。此外還發現,在很多情況下,這個模型在檢索時傾向于將查詢圖像本身排在其他圖像之前,無論給定的指令是什么。這表明,區分緊密相似的圖像對于提高模型的指令理解能力至關重要。重要的是,盡管使用查詢負樣本似乎限制了MagicLens找到相同圖像的能力,但圖1中的第一個例子顯示,MagicLens可以泛化到在訓練期間未見的指令,并成功檢索到相同圖像。

表7. 在訓練期間將查詢圖像作為負樣本的CoCa-based MagicLens-B的消融研究(Qry Neg)
模型架構的消融實驗。在表8中提供了探索的其他模型架構的結果。在CrossAttn模型架構中,探索了各種形式的交叉注意力,報告了使用文本嵌入來關注串聯的圖像和文本嵌入的最佳變體。然而,即使這個架構的最佳變體也無法在大多數基準測試上達到自注意力性能。
還探索了在訓練過程中凍結從CoCa(Yu等人,2022年)初始化的主干編碼器的影響。FrozenEnc的結果始終不如完全訓練的MagicLens。這證明了僅僅在單模態編碼器的頂部訓練額外層是不夠的,無法產生最強大的模型。
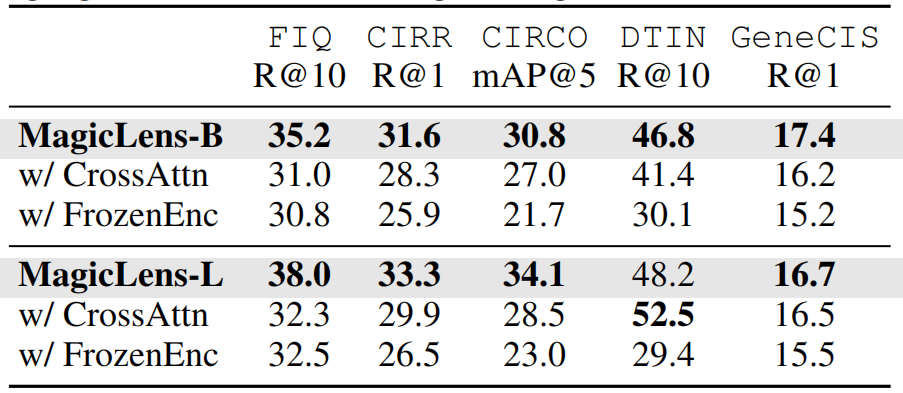
表8. MagicLens變體的結果。CrossAttn表示使用交叉注意力而不是自注意力進行模態集成的模型。FrozenEnc表示在訓練期間凍結主干視覺和語言編碼器的模型
在1.4M開放域圖像語料庫上的檢索
為了模擬更現實的圖像檢索場景,保留了140萬未見的圖像作為索引集,使其成為迄今為止最大的檢索池。然后收集了150張圖像,并將它們分為三組不同的手工編寫指令:簡單、復雜和超越視覺。簡單和復雜的指令都用于搜索視覺上相似的圖像,但它們在復雜性上有所不同。簡單指令僅描述給出的圖像中唯一的視覺差異(例如,同一產品不同顏色),而復雜指令有多處差異(例如,圖8中的汽車和包的例子)。超越視覺的指令旨在找到與查詢圖像沒有視覺相似性的圖像(例如,在圖1中“找到其他景點”的指令)。
表9比較了CoCa-based MagicLens-L和代碼可用的先前最佳模型(LinCIR;Gu等人,2024年),兩者都使用ViT-L后端。對于每個查詢,應用一對一的人類評估來選擇完全滿足指令的模型檢索的圖像。如果兩個模型都成功或都不成功,評估者會將它們標記為平局。可以觀察到LinCIR可以處理簡單指令,但在復雜指令上表現不佳,在超越視覺的指令上幾乎完全失敗。相比之下,我們的方法可以滿足所有種類指令表達的多樣化搜索意圖,尤其在復雜(61.3對24.0)和超越視覺(80對4.7)指令上表現突出。

表9. 在包含140萬圖像的保留索引集上的一對一比較(勝率)。每個設置有50個帶有手工編寫指令的查詢。結果是三位評估者的平均值
定性研究
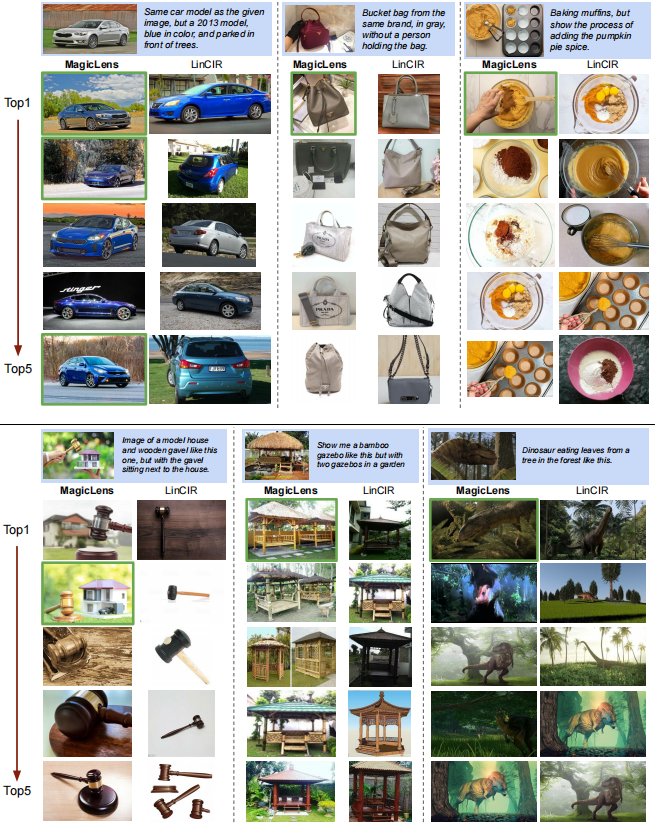
圖8展示了在包含140萬圖像的保留索引集上的top-1檢索結果。即使是在包含多個條件的復雜指令(例如汽車和包的例子)下,MagicLens仍然能夠準確理解搜索意圖并檢索所需圖像。蛋糕的例子展示了MagicLens可以理解圖像之間復雜的時序關系,這要歸功于自然出現的圖像對引入的關系多樣性。然而,給定3D解剖查詢時,MagicLens檢索的圖像可能不是普遍首選,因為指令以頭部為例。這表明當指令表達不清晰時,我們的模型可能會返回合格而非完美的示例。更多定性研究請參閱附錄D中的圖11。
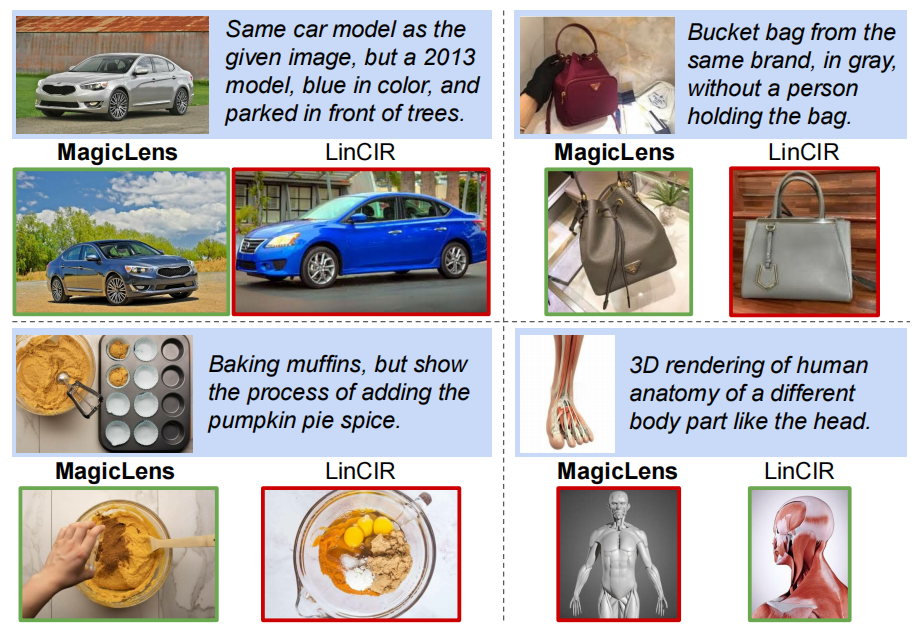
圖8. CoCa-based MagicLens-L和LinCIR在包含140萬圖像的保留索引集上的top-1檢索圖像。帶有藍色背景的查詢,而正確和錯誤的檢索圖像分別用綠色和紅色輪廓標記。LinCIR未能正確檢索汽車、包和蛋糕查詢的結果,即使考慮其top-5結果(見附錄中的圖11)
圖9展示了使用DTIN基準的域轉移檢索的視覺案例研究。每個域中呈現的文本指令是“在{域}中找到這個對象”,其中使用了相同的查詢圖像。所有top-2檢索結果都是正確的,突出了MagicLens在理解概念圖像關系方面的有效性。
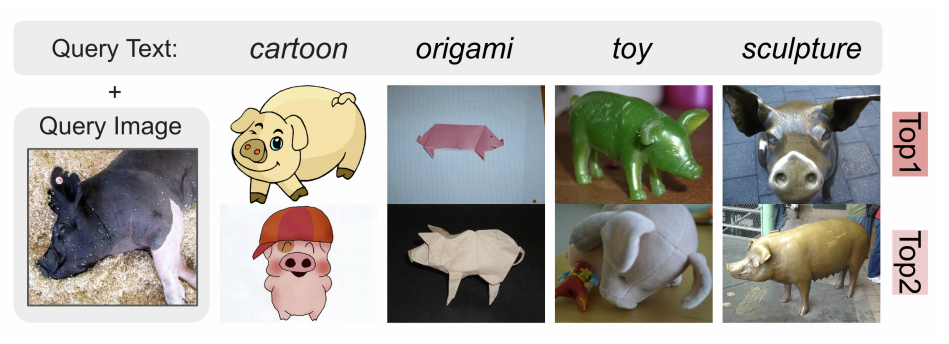
圖9. 在DTIN基準上,對同一查詢圖像在四個域上的top-2檢索結果
結論
本文介紹了MagicLens,這是一系列遵循開放式文本指令進行自監督訓練的圖像檢索模型。盡管MagicLens的模型大小是先前最先進(SOTA)方法的50分之一,但在包括CIRCO、GeneCIS和DTIN在內的多個基準測試上,MagicLens取得了更好的結果。在140萬檢索圖像庫的人類評估顯示,MagicLens能夠很好地滿足由開放式指令表達的多樣化搜索意圖,尤其是復雜和非視覺意圖,這表明MagicLens在實際搜索場景中具有強大的能力和潛力。支持開放式指令的檢索模型可能會對其他視覺-語言任務(如視覺問答(Antol等人,2015年;Chen等人,2023c年))和其他增強的多模態檢索模型(Chen等人,2022年;Hu等人,2023b年)產生潛在益處。更重要的是,希望構建大規模合成自監督訓練數據的方法可以為其他研究方向,如多模態檢索、多模態表示學習等提供啟示。
影響聲明
本研究通過挖掘自然出現的圖像對,為自監督訓練信號提供了新的見解,并開發了遵循開放式指令的圖像檢索模型,以滿足多樣化的搜索意圖。它可能使各種搜索場景成為可能,并具有實際應用的潛力,通過為用戶提供更準確的搜索結果。因此,我們不認為我們的工作與重大倫理或社會問題相關。
致謝
感謝Jinhyuk Lee、William Cohen、Jonathan Berant、Kristina Toutanova、Boqing Gong以及其他來自Google DeepMind成員給予的建設性反饋。
參考
- Anil, R., Dai, A. M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., Shakeri, S., Taropa, E., Bailey, P., Chen, Z.,Chu, E., Clark, J. H., Shafey, L. E., Huang, Y., MeierHellstern, K., Mishra, G., Moreira, E., Omernick, M.,Robinson, K., Ruder, S., Tay, Y., Xiao, K., Xu, Y., Zhang, Y., Abrego, G. H., Ahn, J., Austin, J., Barham, P., Botha, J., Bradbury, J., Brahma, S., Brooks, K., Catasta, M., Cheng, Y., Cherry, C., Choquette-Choo, C. A., Chowdhery, A., Crepy, C., Dave, S., Dehghani, M., Dev, S., Devlin, J., D′?az, M., Du, N., Dyer, E., Feinberg, V., Feng,F., Fienber, V., Freitag, M., Garcia, X., Gehrmann, S., Gonzalez, L., Gur-Ari, G., Hand, S., Hashemi, H., Hou,L., Howland, J., Hu, A., Hui, J., Hurwitz, J., Isard, M., Ittycheriah, A., Jagielski, M., Jia, W., Kenealy, K., Krikun,M., Kudugunta, S., Lan, C., Lee, K., Lee, B., Li, E., Li, M., Li, W., Li, Y., Li, J., Lim, H., Lin, H., Liu, Z., Liu,F., Maggioni, M., Mahendru, A., Maynez, J., Misra, V., Moussalem, M., Nado, Z., Nham, J., Ni, E., Nystrom, A.,Parrish, A., Pellat, M., Polacek, M., Polozov, A., Pope, R., Qiao, S., Reif, E., Richter, B., Riley, P., Ros, A. C.,Roy, A., Saeta, B., Samuel, R., Shelby, R., Slone, A., Smilkov, D., So, D. R., Sohn, D., Tokumine, S., Valter,D., Vasudevan, V., Vodrahalli, K., Wang, X., Wang, P., Wang, Z., Wang, T., Wieting, J., Wu, Y., Xu, K., Xu, Y.,Xue, L., Yin, P., Yu, J., Zhang, Q., Zheng, S., Zheng, C., Zhou, W., Zhou, D., Petrov, S., and Wu, Y. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
-
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C. L., & Parikh, D. (2015). VQA: Visual Question Answering. In Proceedings of ICCV.
-
Asai, A., Schick, T., Lewis, P., Chen, X., Izacard, G., Riedel, S., Hajishirzi, H., & Yih, W.-t. (2023). Task-aware Retrieval with Instructions. In Findings of ACL.
-
Baldrati, A., Agnolucci, L., Bertini, M., & Del Bimbo, A. (2023). Zero-shot Composed Image Retrieval with Textual Inversion. In Proceedings of ICCV.
-
Brooks, T., Holynski, A., & Efros, A. A. (2023). Instructpix2pix: Learning to Follow Image Editing Instructions. In Proceedings of CVPR.
-
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D. (2020). Language Models are Few-Shot Learners. In Proceedings of NeurIPS.
-
Chen, J. & Lai, H. (2023). Pretrain like your Inference: Masked Tuning Improves Zero-Shot Composed Image Retrieval. arXiv preprint arXiv:2311.07622.
-
Chen, J., Hu, H., Wu, H., Jiang, Y., & Wang, C. (2021). Learning the Best Pooling Strategy for Visual Semantic Embedding. In Proceedings of CVPR.
-
Chen, W., Hu, H., Chen, X., Verga, P., & Cohen, W. W. (2022). Murag: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text. In Proceedings of EMNLP.
-
Chen, X., Fang, H., Lin, T.-Y., Vedantam, R., Gupta, S., Dollar, P., & Zitnick, C. L. (2015). Microsoft Coco Captions: Data Collection and Evaluation Server. arXiv preprint arXiv:1504.00325.
-
Chen, X., Djolonga, J., Padlewski, P., Mustafa, B., Changpinyo, S., Wu, J., Ruiz, C. R., Goodman, S., Wang, X., Tay, Y., et al. (2023a). Pali-x: On Scaling up a Multilingual Vision and Language Model. arXiv preprint arXiv:2305.18565.
-
Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A., Padlewski, P., Salz, D., Goodman, S., Grycner, A., Mustafa, B., Beyer, L., Kolesnikov, A., Puigcerver, J., Ding, N., Rong, K., Akbari, H., Mishra, G., Xue, L., Thapliyal, A. V., Bradbury, J., Kuo, W., Seyedhosseini, M., Jia, C., Ayan, B. K., Ruiz, C. R., Steiner, A. P., Angelova, A., Zhai, X., Houlsby, N., & Soricut, R. (2023b). PaLI: A jointly-scaled multilingual language-image model. In Proceedings of ICLR.
-
Chen, Y., Hu, H., Luan, Y., Sun, H., Changpinyo, S., Ritter, A., & Chang, M. (2023c). Can pre-trained vision and language models answer visual information-seeking questions? In Proceedings of EMNLP.
-
Cherti, M., Beaumont, R., Wightman, R., Wortsman, M., Ilharco, G., Gordon, C., Schuhmann, C., Schmidt, L., & Jitsev, J. (2023). Reproducible scaling laws for contrastive language-image learning. In Proceedings of CVPR.
-
Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., Webson, A., Gu, S. S., Dai, Z., Suzgun, M., Chen, X., Chowdhery, A., Castro-Ros, A., Pellat, M., Robinson, K., Valter, D., Narang, S., Mishra, G., Yu, A., Zhao, V., Huang, Y., Dai, A., Yu, H., Petrov, S., Chi, E. H., Dean, J., Devlin, J., Roberts, A., Zhou, D., Le, Q. V., & Wei, J. (2022). Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
-
Cohen, N., Gal, R., Meirom, E. A., Chechik, G., & Atzmon, Y. (2022). “this is my unicorn, fluffy”: Personalizing frozen vision-language representations. In Proceedings of ECCV.
-
Datta, R., Joshi, D., Li, J., & Wang, J. Z. (2008). Image retrieval: Ideas, influences, and trends of the new age. ACM Comput. Surv..
-
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In Proceedings of CVPR.
-
Dey, S., Riba, P., Dutta, A., Llados, J., & Song, Y.-Z. (2019). Doodle to search: Practical zero-shot sketch-based image retrieval. In Proceedings of CVPR.
-
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2021). An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of ICLR.
-
Faghri, F., Fleet, D. J., Kiros, J. R., & Fidler, S. (2017). Vse++: Improving visual-semantic embeddings with hard negatives. arXiv preprint arXiv:1707.05612.
-
Gordo, A., Almazán, J., Revaud, J., & Larlus, D. (2016). Deep image retrieval: Learning global representations for image search. In Proceedings of ECCV.
-
Gu, G., Chun, S., Kim, W., Jun, H., Kang, Y., & Yun, S. (2023). Compodiff: Versatile composed image retrieval with latent diffusion. arXiv preprint arXiv:2303.11916.
-
Gu, G., Chun, S., Kim, W., Kang, Y., & Yun, S. (2024). Language-only training of zero-shot composed image retrieval. In Proceedings of CVPR.
-
Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., Song, D., Steinhardt, J., & Gilmer, J. (2021). The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of ICCV.
-
Hu, H., Luan, Y., Chen, Y., Khandelwal, U., Joshi, M., Lee, K., Toutanova, K., & Chang, M.-W. (2023a). Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities. In Proceedings of CVPR.
-
Hu, Z., Iscen, A., Sun, C., Wang, Z., Chang, K.-W., Sun, Y., Schmid, C., Ross, D. A., & Fathi, A. (2023b). Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory. In Proceedings of CVPR.
-
Jia, C., Yang, Y., Xia, Y., Chen, Y.-T., Parekh, Z., Pham, H., Le, Q., Sung, Y.-H., Li, Z., & Duerig, T. (2021). Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of ICML.
-
Karthik, S., Roth, K., Mancini, M., & Akata, Z. (2024). Vision-by-language for training-free compositional image retrieval. In Proceedings of ICLR.
-
Kim, W., Son, B., & Kim, I. (2021). Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of ICML.
-
Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., & Hoi, S. C. H. (2021). Align before fuse: Vision and language representation learning with momentum distillation. In Proceedings of NeurIPS.
-
Li, J., Li, D., Xiong, C., & Hoi, S. (2022). BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of ICML.
-
Li, J., Li, D., Savarese, S., & Hoi, S. (2023). BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of ICML.
-
Lin, F., Li, M., Li, D., Hospedales, T., Song, Y.-Z., & Qi, Y. (2023). Zero-shot everything sketch-based image retrieval, and in explainable style. In Proceedings of CVPR.
-
Lin, T., Maire, M., Belongie, S. J., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft COCO: Common objects in context. In Proceedings of ECCV.
-
Liu, Q., Xie, L., Wang, H., & Yuille, A. (2019). Semantic-aware knowledge preservation for zero-shot sketch-based image retrieval. In Proceedings of ICCV.
-
Liu, Z., Rodriguez-Opazo, C., Teney, D., & Gould, S. (2021). Image retrieval on real-life images with pre-trained vision-and-language models. In Proceedings of ICCV.
-
OpenAI. (2022). ChatGPT. URL https://openai.com/blog/chatgpt.
-
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell,
附錄
A. 實現細節
圖像清理和配對。使用通用爬蟲,并將具有相同URL的圖像視為來自同一網站的圖像。如果兩張圖像的CLIP圖像嵌入分數超過0.98,將其視為相同圖像并移除。如果兩個組有高比例的重復圖像(80%),隨機移除其中一個組。保留的最小分辨率是288x288,這與使用的CoCa模型的輸入大小相匹配。用于過濾的具體閾值,設置了0.82作為CLIP圖像到圖像相似性的閾值和0.9作為文本到文本相似性(基于字幕)的閾值。此外,為了確保圖像的獨特性,目標圖像必須具有與自身高度相似(0.32)且與查詢圖像低相似(0.18)的獨特ICA標簽。只有滿足這些要求的圖像對才會被保留用于指令生成階段。
指令生成。通過使用各種工具和LMMs為LLM提供大量元數據擴展,包括Alt-texts、圖像內容注釋(ICA)標簽和圖像字幕。具體來說,類似于Sharma等人(2018年)的方法,使用Google自然語言API對候選Alt-texts進行詞性、情感和色情標注。如果圖像的Alt-texts僅包含稀有標記,或者被情感/色情檢測器觸發,將丟棄這些圖像。對于ICA標簽,利用Google視覺API為每張圖像標注實體,如一般物體、位置和活動。平均而言,每張圖像有25.2個精細的ICA標簽。此外,在表10中為指令生成提供了指令和兩個詳細的演示。
| 指令 | 為了演示如何根據提供的ALT文本、文本標簽和字幕創建一個有趣的文本查詢,可以假設有兩張不同的圖像,并基于這些圖像的元數據來生成查詢。 圖像1: - ALT文本:一個正在滑雪的人 - 文本標簽:滑雪,戶外,冬季活動 - 字幕:滑雪者在雪山上的照片 圖像2: - ALT文本:一個在沙灘上曬太陽的人 - 文本標簽:海灘,曬太陽,休閑 - 字幕:一個人在沙灘上享受陽光 基于上述信息,可以創建一個查詢,例如: “找到一張圖像,其中有人在滑雪,而不是在沙灘上曬太陽。” 這個查詢結合了通用和不太具體的相似性(滑雪)和目標圖像獨有的所有差異(不是在沙灘上曬太陽)。這樣的查詢既簡潔又具有指導性,可以幫助用戶找到與源圖像相似但內容不同的圖像。 |
| 演示 | 根據提供的示例,可以看到兩個圖像都是關于保時捷汽車的定制插畫,源圖像是一幅保時捷Cayman GT4的插畫,目標圖像則是一幅1972年保時捷911藍色的插畫。因此,查詢應該專注于圖像的類型(保時捷汽車的定制插畫),同時具體指明不同的車型和年份(1972年的保時捷911)以及顏色(藍色)。查詢可以是: “尋找一幅以相同插畫風格展示的藍色1972年保時捷911的圖像。” 同樣,第二個例子中的兩個圖像都是關于Rapunzel的涂色頁,源圖像展示了Rapunzel在船上的場景,而目標圖像則展示了Rapunzel與Flynn和頭上的花朵。因此,查詢應該專注于圖像的類型(Rapunzel的涂色頁),同時具體指明不同的場景(Rapunzel與Flynn和頭上的花朵,而不是在船上,沒有燈籠)。查詢可以是: “尋找一幅關于Rapunzel的涂色頁,但不含船或燈籠,且角色頭發中的花朵更加清晰。” 通過這樣的查詢,用戶可以利用源圖像的信息,同時通過文本指令指導搜索,找到與源圖像相似但內容不同的圖像。 |
Table 10. 使用PaLM2 (Anil et al., 2023)生成查詢的詳細提示
模型。在提出的數據構建流程中,最終收集了36,714,118個三元組用于預訓練。對于模型架構,在視覺和語言編碼器之上設計了4個隨機初始化的自注意力層。此外,使用了一個注意力池化層(Yu等人,2022年)來獲取最終的嵌入。遵循Jia等人(2021年)和Yu等人(2022年)的方法,在CoCa-based MagicLens的訓練過程中,將圖像分辨率設置為288×288,補丁大小為18×18。對于CLIP-based MagicLens,將圖像分辨率設置為224×224,并使用ViT-B16和ViT-L14。對于CLIP和CoCa,使用對比圖像嵌入和對比文本嵌入,這些將作為自注意力層中固定長度為2的序列進行拼接。新添加的自注意力層的數量為4, τ τ τ是可學習的,初始化為0.07。將批量大小設置為2048,并在Adafactor(Shazeer和Stern,2018年)和早停EarlyStop機制下訓練模型,最大訓練步數為50,000步。對于新引入的參數和重新使用的CLIP或CoCa參數,學習率分別設置為2e-5和2e-6。在64和128個TPU上分別訓練基礎模型和大模型。兩個模型的訓練過程持續了六小時,并基于CIRR和CIRCO的驗證集性能選擇最佳檢查點。
B.基線
考慮了各種基線,并詳細描述如下:
- (1) PALARVA (Cohen等人,2022年)
- (2) Pic2Word (Saito等人,2023年)
- (3) SEARLE (Baldrati等人,2023年)
- (4) ContextI2W (Tang等人,2024年)
- (5) LinCIR (Gu等人,2024年) 訓練了一個額外的映射網絡,將給定的參考圖像編碼為偽詞令牌。然后,它可以與實際的查詢文本結合,用于文本到圖像的檢索。這些方法依賴于圖像-字幕對來訓練映射網絡。此外,LinCIR引入了僅文本數據以提高映射能力。
- (6) CIReVL (Karthik等人,2024年) 是一種訓練自由的方法,使用BLIP-2和FLANT5-XXL (Li等人,2023年) 進行查詢圖像字幕生成,使用ChatGPT (OpenAI,2022年) 進行目標圖像字幕生成,使用CLIP (Radford等人,2021年;Cherti等人,2023年) 進行最終的文本到圖像檢索。這樣的復雜檢索流水線可能會限制它們的推理速度和在現實世界場景中的潛在實用性。
- (7) CompoDiff (Gu等人,2023年) 將查詢文本視為條件,以指導圖像嵌入的生成,并在18M合成數據上訓練模型。
- (8) PLI (Chen & Lai,2023年) 在圖像-字幕數據中損壞圖像,并將原始圖像視為目標,以在預訓練階段模擬CIR任務。
C.所有結果
在五個多模態到圖像基準測試上的結果
表12、13和14展示了三個CIR基準測試(Wu等人,2021年;Liu等人,2021年;Baldrati等人,2023年)的完整結果。在表15和表16上報告了各種模型在DT和GeneCIS上的性能。一些先前的方法可能使用了更大的編碼器(Gu等人,2023年;2024年)并開發了一個包括LLMs(OpenAI,2022年)和LMMs(Li等人,2023年)的檢索流水線以獲得性能提升。盡管如此,他們的結果仍然不如MagicLens,進而支持了圖7中聲稱的參數效率。

表11. 在相同1M規模下,使用IP2P數據和構建數據訓練的CoCa-based MagicLens-B的詳細性能。
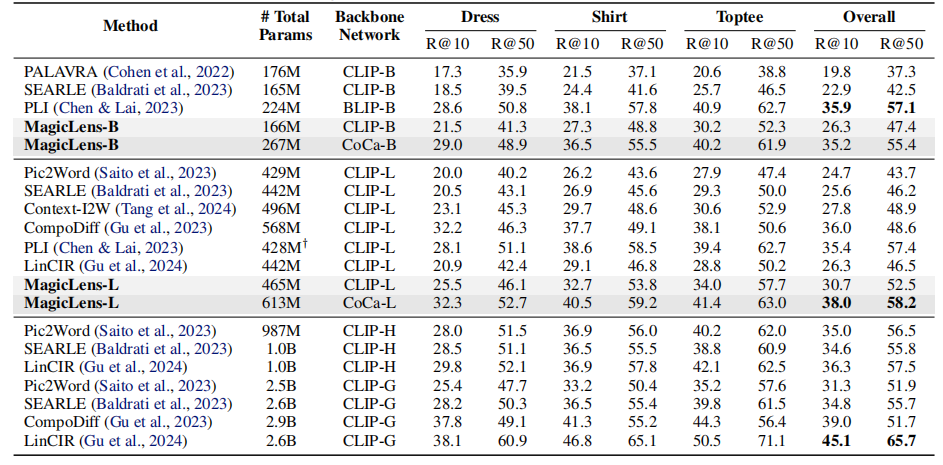
表12. FIQ基準測試(Wu等人,2021年)的完整結果。? PLI沒有發布代碼,所以只進行了估計
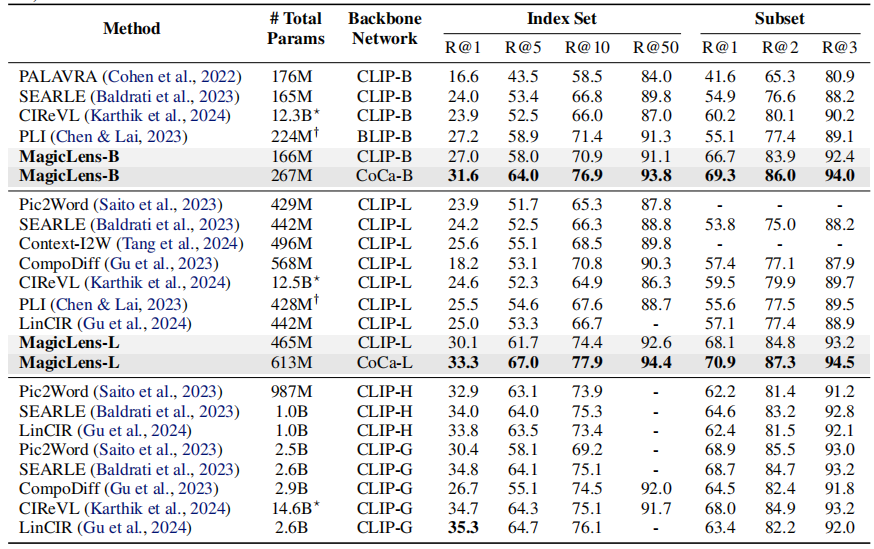
表13. CIRR基準測試(Liu等人,2021年)的完整結果。CLIP-H和CLIP-G是OpenCLIP(Cherti等人,2023年)的檢查點。?CIReVL使用多個模型組件,我們省略了ChatGPT并報告其他組件的參數數量(例如,BLIP2-FLANT5-XXL + CLIP-G)。?PLI沒有發布代碼,所以只進行了估計
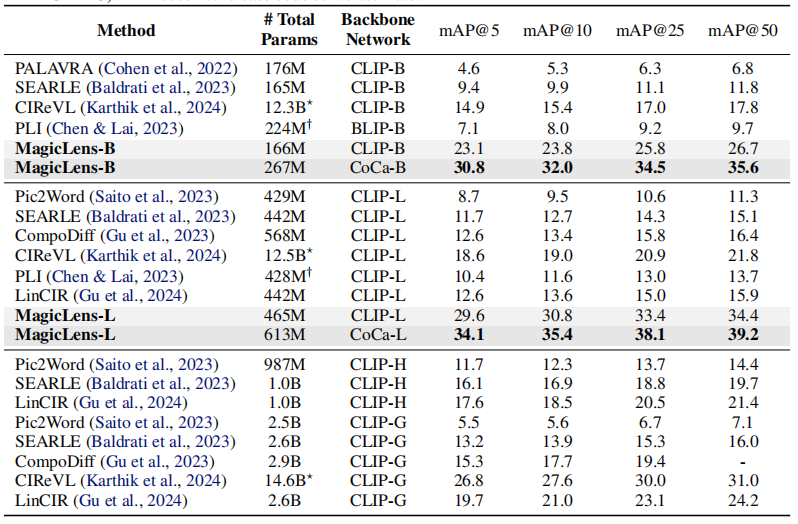
表14. CIRCO基準測試(Baldrati等人,2023年)的完整結果。CLIP-H和CLIP-G是OpenCLIP(Cherti等人,2023年)的檢查點。?CIReVL使用多個模型組件,我們省略了ChatGPT并報告其他組件的參數數量(例如,BLIP2-FLANT5-XXL + CLIP-G)。?PLI沒有發布代碼,所以進行了估計
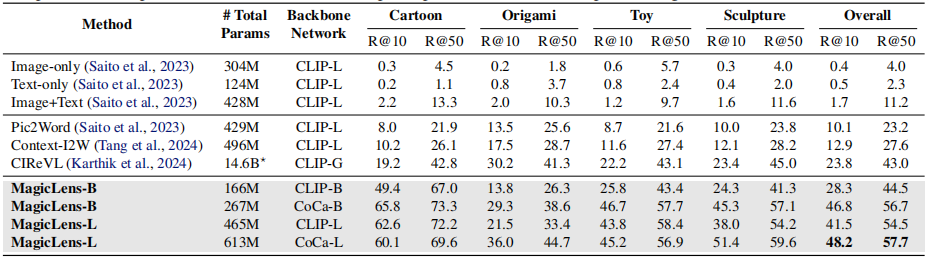
表15. DTIN基準測試(Saito等人,2023年)的完整結果。CLIP-G是OpenCLIP(Cherti等人,2023年)的檢查點。?CIReVL使用多個模型組件,省略了ChatGPT并報告其他組件的參數數量(例如,BLIP2-FLANT5-XXL + CLIP-G)
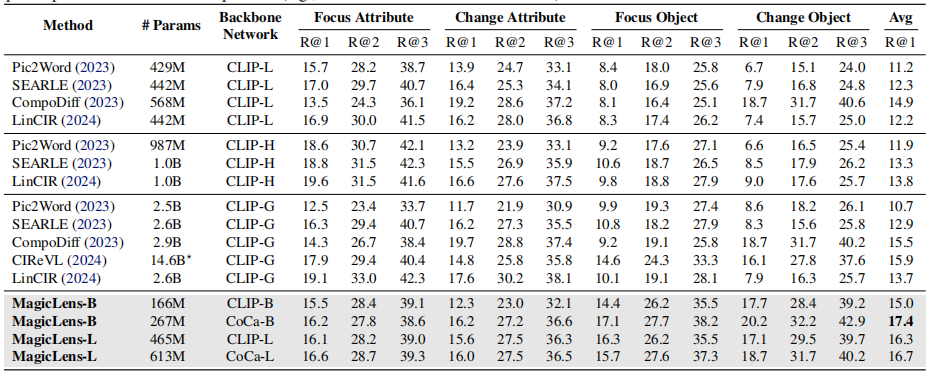
表16. GeneCIS基準測試(Vaze等人,2023年)的完整結果。?CIReVL使用多個模型組件,我們省略了ChatGPT并報告其他組件的參數數量(例如,BLIP2-FLANT5-XXL + CLIP-G)
數據訓練比較
表11詳細比較了使用IP2P數據和數據訓練的CoCa-based MagicLens-B。
文本到圖像檢索與基于CLIP的MagicLens
在表17中列出了原始CLIP和MagicLens更新后的主干CLIP編碼器的文本到圖像檢索結果。在基礎和大模型上,文本到圖像檢索性能顯著提升,而圖像到文本檢索能力略有下降。這與第4.4節中關于CoCa的結論相一致。
表格17. 零樣本圖像-文本檢索結果。如果結果比初始化檢查點更好,則用粗體標記。?CLIP和CoCa重新制作并用于MagicLens。?CLIP和CoCa在原始論文中報告。
基于模板的指令示例
在圖10中提供了同一圖像對上不同指令的具體示例。

圖10. 同一圖像對上基于模板和無模板指令的示例
D. 更多定性研究
展示基于CoCa的MagicLens-L和代碼可用的最先進LinCIR(Gu等人,2024年)的詳細top-5檢索結果,如圖11所示。
-
- 對于包查詢,MagicLens可以檢索同一品牌的包(第三和第四張圖像),即使它們與查詢圖像沒有共享的視覺線索(品牌標志)。
-
- 給定房子和法槌查詢,模型成功找到了一個有趣的現實世界場景,并在前兩個結果中找到了完美的示例,但LinCIR未能滿足查詢。這可能源于單個偽令牌對具有多個對象的圖像的有限表示能力。
-
- 在涼亭示例上的成功表明,MagicLens可以理解簡單的數字關系。


)



:QStyle和自定義樣式)


數據庫的設計規范)



)



)
框架軟件小白入門教程(九))


