九、數據庫的設計規范
- 9.1 范式的概念
- 9.1.1 范式概述
- 9.1.2 鍵和相關屬性
- 9.2 常見的范式
- 9.2.1 第一范式
- 9.2.2 第二范式
- 9.2.3 第三范式
- 9.2.4 第四范式
- 9.2.5 第五范式(域鍵范式)
- 9.3 反范式化
- 9.3.1 概述
- 9.3.2 舉例
- 9.3.3 反范式化新問題
- 9.3.4 通用場景
- 9.4 巴斯-科德范式(BCNF)
- 9.5 ER模型
- 9.5.1 ER模型三要素
- 9.5.2 關系的類型
- 9.6 數據表的設計原則
- 9.7 數據庫對象的編寫建議
- 9.7.1 關于庫
- 9.7.2 關于表、列
- 9.7.3 關于索引
- 9.7.4 SQL 編寫
良好的數據庫設計可以節省數據的存儲空間、能夠保證數據的完整性、方便進行數據庫應用系統的開發。總之,在一開始設置數據庫的時候,就需要重視數據表的設計。為了建立冗余較小、結構合理的數據庫,設計數據庫時必須遵循一定的規則,這個規則就稱為范式
9.1 范式的概念
9.1.1 范式概述
在關系型數據庫中,關于數據表設計的基本原則、規則就稱為范式。可以理解為,一張數據表的設計結構需要滿足的某種設計標準的級別。要想設計一個結構合理的關系型數據庫,就必須滿足一定的范式(Normal Form,簡稱:NF)。范式是關系數據庫理論的基礎,也是我們在設計數據庫結構過程中所要遵循的規則和指導方法。
目前關系型數據庫有六種常見范式,按照范式級別,從低到高分別是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF,又稱完美范式)。
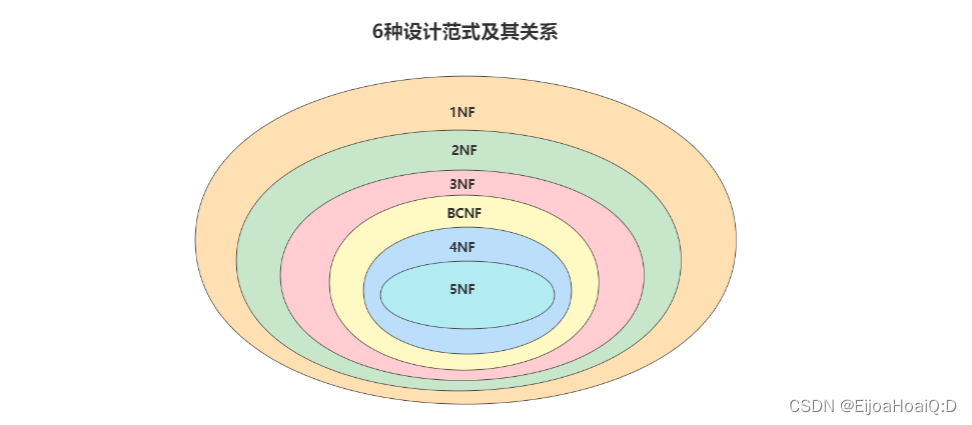
數據庫的范式設計越高階,冗余度就越低,同時高階的范式一定符合低階范式的要求。一般在關系型數據庫的設計中,最高就遵循到 BCNF,普遍還是 3NF,但并不是絕對的,有時候為了提高某些查詢性能,還需要破壞范式規則,進行反范式化。
9.1.2 鍵和相關屬性
- 超鍵:能唯一標識元組的屬性集叫做超鍵。它可以是一個或多個屬性的集合,只要它能確定唯一一行就可以(主鍵、主鍵 + 任意字段、任何組合屬性能唯一確定一個實體)。
- 候選鍵:不包含有多余屬性的超鍵稱為候選鍵。也就是說,在候選鍵中,如果再刪除屬性,就不是鍵了。
- 主鍵:從候選鍵中選出來的一個鍵就是主鍵。主鍵是候選鍵之一,用于唯一標識元組。
- 外鍵:數據表 R1 中的某屬性集不是 R1 的主鍵,而是另一數據表 R2 的主鍵,則此屬性集就是數據表 R1 的外鍵。
- 主屬性:包含在任一候選鍵中的屬性稱為主屬性。
- 非主屬性:與主屬性相對,指的是不包含在任何一個候選鍵中的屬性。
通常,我們也將候選鍵成為 “碼”,把主鍵稱為 “主碼”。因為鍵可能是由多個屬性組成的,針對單個屬性,我們可以用主屬性和非主屬性來進行區分。
舉例:
有兩張表:
- 球員表(player):球員編號、姓名、身份證號、年齡、球隊編號。
- 球隊表(team):球隊編號、主教練、球隊所在地。
- 超鍵:對于球員表來說,超鍵就是包括球員編號或身份證號的任意組合。(球員編號)、(身份證號)、(球員編號、姓名)、(身份證號,年齡)等組合都叫做超鍵。
- 候選鍵:就是最小的超鍵。對于球員表來說,候選鍵就是(球員編號)或(身份證號)。
- 主鍵:主鍵是從候選鍵中選擇一個,根據實際情況決定。(球員編號)或(身份證號)都可以作為主鍵。
- 外鍵:球員表中的球隊編號就是一個外鍵。
- 主屬性、非主屬性:在球員表中,主屬性就是(球員編號)(身份證號),其他屬性(姓名)、(年齡)、(球隊編號)都是非主屬性。
9.2 常見的范式
9.2.1 第一范式
第一范式主要是確保數據表中每個字段的值必須具有原子性,也就是說數據表中每個字段的值為不可再次拆分的最小數據單元。比如在設計某個字段的時候,對于字段 X 來說,不能把字段 X 拆分成字段 X-1 和字段 X-2。
例如如下 user 表:
| 字段名稱 | 字段類型 | 是否是主鍵 | 說明 |
|---|---|---|---|
| id | INT | 是 | 主鍵id |
| username | VARCHAR(30) | 否 | 用戶名 |
| password | VARCHAR(50) | 否 | 密碼 |
| user_info | VARCHAR(255) | 否 | 用戶信息 (包含真實姓名、電話、住址) |
其中,user_info 字段為用戶信息,可以進一步拆分成更小粒度的字段,不符合數據庫設計對第一范式的要求。將 user_info 拆分后:
| 字段名稱 | 字段類型 | 是否是主鍵 | 說明 |
|---|---|---|---|
| id | INT | 是 | 主鍵id |
| username | VARCHAR(30) | 否 | 用戶名 |
| password | VARCHAR(50) | 否 | 密碼 |
| real_name | VARCHAR(30) | 否 | 真實姓名 |
| phone | VARCHAR(12) | 否 | 聯系電話 |
| address | VARCHAR(100) | 否 | 家庭住址 |
9.2.2 第二范式
第二范式要求,在滿足第一范式的基礎上,還要滿足數據表里的每一條數據記錄,都是可唯一標識的。并且所有的非主鍵字段,都必須完全依賴主鍵,不能只依賴主鍵的一部分。如果知道主鍵的所有屬性的值,就可以檢索到任何元組(行)的任何屬性的任何值。
? 舉例1:
成績表(學號,課程號,成績)關系中,(學號,課程號)可以決定成績,但是學號不能決定成績,課程號也不能決定成績,所以 “(學號,課程號)——>(成績)” 就是完全依賴關系。
? 舉例二:
比賽表 player_game,里面包含球員編號、姓名、年齡、比賽編號、比賽時間和比賽場地等屬性,這里的候選鍵和主鍵都為(球員編號,比賽編號),我們可以通過候選鍵或主鍵決定下面的關系:
(球員編號,比賽編號)——>(姓名,年齡,比賽時間,比賽場地,得分)
但是此表是不滿足第二范式的,因為數據表中的字段之間還存在著如下對應關系:
(球員編號)——>(姓名,年齡)
(比賽編號)——>(比賽時間,比賽場地)
對于非主屬性來說,并非完全依賴候選鍵。這樣會產生一些問題:
- 數據冗余:如果一個球員可以參加 m 場比賽,那么球員的姓名和年齡就重復了 (m - 1) 次。一個比賽也可能會有 n 個球員參加,比賽的時間和地點就重復了 (n - 1) 次。
- 插入異常:如果我們想要添加一場新的比賽,但是這時還沒有確定參加的球員都有誰,那么就無法插入。
- 刪除異常:如果想要刪除某個球員編號,如果沒有單獨保存比賽表的話,就會同時把比賽信息刪除掉。
- 更新異常:如果調整了某個比賽的時間,那么數據表中所有這個比賽的時間都需要進行調整,否則就會出現一場比賽時間不同的情況。
為了避免出現上述的情況,可以把球員比賽表設計為三張表:
| 表名 | 屬性(字段) |
|---|---|
| 球員 player 表 | 球員編號、姓名和年齡等字段 |
| 比賽 game 表 | 比賽編號、比賽時間和比賽場地等屬性 |
| 球員比賽關系 player_game 表 | 球員編號、比賽編號和得分等屬性 |
1NF 是要確保字段屬性是原子性的;2NF 是要確保一張表就是一個獨立的對象,一張表只表達一個意思。
9.2.3 第三范式
第三范式是在第二范式的基礎上,確保數據表中的每一個非主鍵字段都和主鍵字段直接相關。也就是說,要求數據表中的所有非主鍵字段不能依賴于其他非主鍵字段,所有非主鍵屬性之間不能有依賴關系,必須相互獨立。
不能存在非主屬性 A 依賴于非主屬性 B,非主屬性 B 依賴于主鍵 C 的情況,即不能存在 “A—>B—>C” 的關系。
? 舉例一:
部門信息表:每個部門有部門編號(dept_id)、部門名稱、部門簡介等信息。
員工信息表:每個員工有員工編號、姓名、部門編號。列出部門編號后就不能再將部門名稱、部門簡介等與部門有關的信息再加入員工信息表中了。
? 舉例二:
球員 player 表:球員編號、姓名、球隊名稱、球隊主教練。有如下依賴關系:
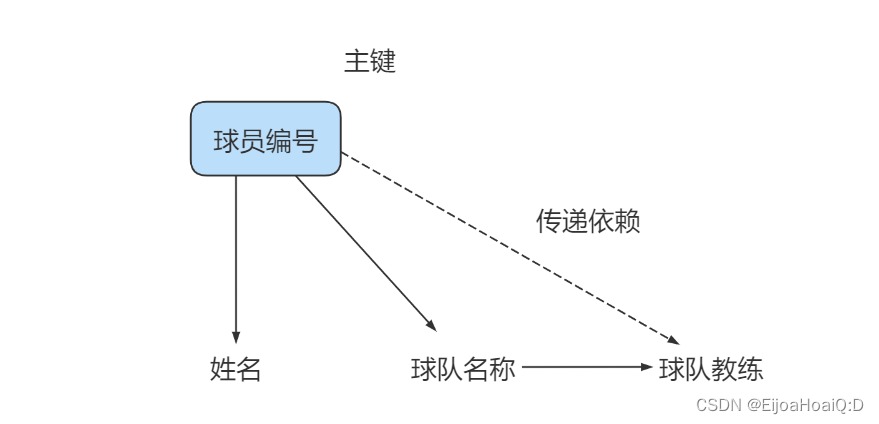
球員編號決定了球隊名稱,同時球隊名稱決定了球隊主教練,非主屬性球隊主教練就會傳遞依賴于球員編號,所以不符合 3NF 的要求。
如果要達到 3NF 的要求,需要把數據表拆成這樣:
| 表名 | 屬性(字段) |
|---|---|
| 球員表 | 球員編號、姓名和球隊名稱 |
| 球隊表 | 球隊名稱、球隊主教練 |
每個非主鍵屬性依賴于主鍵,依賴于整個主鍵,并且除了主鍵別無他物。
第一范式要求列不可再分;第二范式要求不能部分依賴;第三范式要求不能傳遞依賴,而是直接依賴。
9.2.4 第四范式
- 多值依賴:即屬性之間的一對多關系,記為 K——>A。
- 函數依賴:事實上是單值依賴,所以不能表達屬性值之間的一對多關系。
- 平凡的多值依賴:全集 U = K + A,一個 K 可以對應于多個 A,即 K——>A。此時整個表就是一組一對多關系。
- 非平凡的多值依賴:全集 U = K + A + B,一個 K 可以對應于多個 A,也可以對應于多個 B,A 與 B 互相獨立,即 K——>A,K——>B。整個表有多組一對多關系,且有 “一部分是相同的屬性集合,多部分是互相獨立的屬性集合”。
第四范式在滿足巴斯-科德范式(BCNF)的基礎上,消除非平凡且非函數依賴的多值依賴(即把同一表內的多對多關系刪除)。
? 舉例一:
職工表(職工編號,職工孩子姓名,職工選修課程)。
在這個表中,同一個職工可能會有多個職工孩子姓名。同樣,同一個職工也可能會有多個職工選修課程,即這里存在著多值事實,不符合第四范式。
如果要符合第四范式,只需要將此表分為兩個表,使它們只有一個多值事實:職工表一(職工編號,職工孩子姓名),職工表二(職工編號,職工選修課程),兩個表都只有一個多值事實,所以符合第四范式。
? 舉例二
現建立課程、教師、教材的模型,規定每門課程有對應的一組教師,每門課程也有對應的一組教材,一門課程使用的教材和教師沒有關系。建立如下關系表:
(課程 ID,教師 ID,教材 ID)三列作為聯合主鍵。
| Course | Teacher | Book |
|---|---|---|
| 英語 | Bill | 人教版英語 |
| 英語 | Bill | 美版英語 |
| 英語 | Jay | 美版英語 |
| 高數 | William | 人教版高數 |
| 高數 | Dave | 美版高數 |
此表除了主鍵,就沒有其他字段了,所以肯定滿足巴斯范式,但是卻存在多值依賴導致的異常。
假如下學期想采用一本新的英版高數教材,但是還沒確定具體哪個老師來教,那么就無法在這個表中維護 Course 高數和 Book 英版高數教材的關系。
所以,需要將這個多值依賴的表拆解成 2 個表,分別建立關系:
| Course | Teacher |
|---|---|
| 英語 | Bill |
| 英語 | Jay |
| 高數 | William |
| 高數 | Dave |
| Course | Book |
|---|---|
| 英語 | 人教版英語 |
| 英語 | 美版英語 |
| 高數 | 人教版高數 |
| 高數 | 美版高數 |
9.2.5 第五范式(域鍵范式)
第五范式又稱完美范式或域鍵范式(DKNF)。在滿足第四范式的基礎上,消除不是由候選鍵所蘊含的連接依賴。如果關系模式 R 中的每一個連接依賴均由 R 的候選鍵所隱含,則稱此關系模式符合第五范式。
函數依賴是多值依賴的一種特殊情況,而多值依賴實際上是連接依賴的一種特殊情況。但是連接依賴不像函數依賴和多值依賴可以由語義直接導出,而是在關系連接運算時才反映出來。存在連接依賴的關系模式仍可能遇到數據冗余及插入、修改、刪除異常等問題。
第五范式處理的是無損連接問題,這個范式基本沒有實際意義,因為無損連接很少出現,而且難以察覺。而域鍵范式試圖定義一個終極范式,該范式考慮所有的依賴和約束類型,但是實用價值也是最小的,只存在理論研究中。
9.3 反范式化
9.3.1 概述
有時候不能簡單按照規范要求設計數據表,因為有的數據看起來冗余,但其實對業務來說十分重要。這時就要遵循業務優先的原則,首先滿足業務需求,再盡量減少冗余。
如果數據庫中的數據量比較大,系統的 UV(unique visitor,訪問網站的一臺電腦客戶端即為一個訪客)和 PV(page view,即頁面瀏覽量或點擊量,用戶每次刷新即被計算一次)訪問頻次比較高,則完全按照 MySQL 的三大范式設計數據表,讀數據時會產生大量的關聯查詢,在一定程度上會影響數據庫的讀性能。如果我們想對查詢效率進行優化,反范式優化也是一種優化思路,通過在數據表中增加冗余字段來提高數據庫的讀性能。
規范化 vs 性能
- 為滿足某種商業目標,數據庫性能比規范化數據庫更重要。
- 在數據規范化的同時,要綜合考慮數據庫的性能。
- 通過在給定的表中添加額外的字段,以大量減少需要從中搜索信息所需的時間。
- 通過在給定的表中插入計算列,以方便查詢。
9.3.2 舉例
簡單舉個如下例子:
員工的信息存儲在 employees 表 中,部門信息存儲在 departments 表 中。通過 employees 表中的
department_id 字段與 departments 表建立關聯關系。如果要查詢一個員工所在部門的名稱:
SELECTemployee_id,department_name
FROMemployees eJOIN departments d ON e.department_id = d.department_id;
如果經常需要進行這個操作,連接查詢就會浪費很多時間。可以在 employees 表中增加一個冗余字段
department_name,這樣就不用每次都進行連接操作了。
9.3.3 反范式化新問題
反范式化可以通過空間換時間,提升查詢的效率,但是反范式也會帶來一些新問題:
- 存儲空間變大了。
- 一個表中字段做了修改,另一個表中冗余的字段也需要做同步修改,否則數據不一致。
- 如果采用存儲過程來支持數據的更新、刪除等額外操作,如果更新頻繁,則會非常消耗系統資源。
- 在數據量小的情況下,反范式化不能體現性能的優勢,可能還會讓數據庫的設計更加復雜。
9.3.4 通用場景
當冗余信息由價值或者能大幅度提高查詢效率時,才會采取反范式化的優化。
? 增加冗余字段的建議
增加冗余字段一定要符合兩個條件,只有滿足這兩個條件,才可以考慮增加冗余字段。
- 這個冗余字段不需要經常進行修改。
- 這個冗余字段查詢時不可或缺。
? 歷史快照、歷史數據的需要
在現實生活中,我們經常需要一些冗余信息,比如訂單中的收貨人信息,包括姓名、電話和地址等。每次發生的訂單收貨信息都屬于歷史快照 ,需要進行保存,但用戶可以隨時修改自己的信息,這時保存這些冗余信息是非常有必要的。
反范式優化也常用在數據倉庫的設計中,因為數據倉庫通常存儲歷史數據 ,對增刪改的實時性要求不
強,對歷史數據的分析需求強。這時適當允許數據的冗余度,更方便進行數據分析。
9.4 巴斯-科德范式(BCNF)
在第三范式的基礎上進行了改進,提出了巴斯范式,也叫做巴斯-科德范式。BCNF 被認為沒有新的設計規范加入,只是對第三范式中設計規范要求更強,使得數據庫冗余度更小。所以被稱為是修正的第三范式,或擴充的第三范式。
舉個例子:
有如下表:
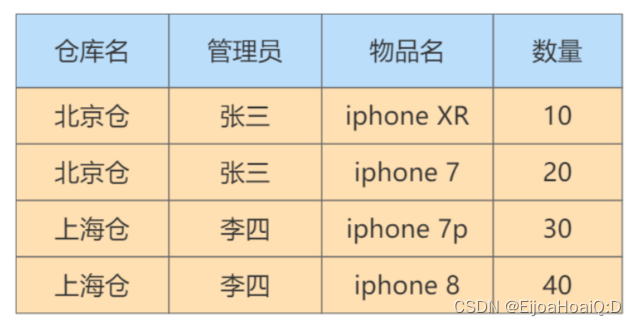
在這個表中,一個倉庫只有一個管理員,同時一個管理員也只管理一個倉庫。首先先來梳理下這些屬性之間的依賴關系:
倉庫名決定了管理員,管理員也決定了倉庫名,同時(倉庫名,物品名)的屬性集合可以決定數量這個屬性。這樣,就可以找到數據表的候選鍵了。
**候選鍵:**是(管理員,物品名)和(倉庫名,物品名),然后從候選鍵中選擇一個作為主鍵 ,比
如(倉庫名,物品名)。
**主屬性:**包含在任一候選鍵中的屬性,也就是倉庫名,管理員和物品名。
**非主屬性:**數量這個屬性。
接下來來判斷該表是否符合三范式:
- 首先,數據表的每個屬性都是原子性的,符合 1NF 的要求;
- 其次,數據表中非主屬性 “數量” 與候選鍵全部依賴,(倉庫名,物品名)決定數量,(管理員,物品名)決定數量。符合 2NF 的要求。
- 最后,數據表中的非主屬性不傳遞依賴于候選鍵,符合 3NF 的要求。
既然此表已經符合了 3NF 的要求,是不是就不存在問題了呢?假如有下面的情況:
- 增加一個倉庫,但是還沒有存放任何物品。根據數據表實體完整性的要求,主鍵不能有空值,因此會出現插入異常。
- 如果倉庫更換了管理員,就可能要修改數據表中的多條記錄了。
- 如果倉庫里的商品都賣空了,那么此時倉庫名和相應的管理員名稱也會隨著被刪除。
由此可見,即使數據表符合 3NF 的要求,同樣可能存在插入、更新和刪除數據的異常情況。
首先需要確認造成異常的原因:主屬性倉庫名對于候選鍵(管理員,物品名)是部分依賴的關系,
這樣就有可能導致上面的異常情況。因此引入BCNF,它在 3NF 的基礎上消除了主屬性對候選鍵的部分依賴或者傳遞依賴關系。
如果在關系 R 中,U 為主鍵,A 屬性是主鍵的一個屬性,若存在 A->Y,Y 為主屬性,則該關系不屬于
BCNF。根據 BCNF 的要求,我們需要把倉庫管理關系 warehouse_keeper 表拆分成下面這樣:
倉庫表 :(倉庫名,管理員)
庫存表 :(倉庫名,物品名,數量)
這樣就不存在主屬性對于候選鍵的部分依賴或傳遞依賴,上面數據表的設計就符合 BCNF。
9.5 ER模型
9.5.1 ER模型三要素
ER 模型中有三個要素,分別是實體、屬性和關系。
- 實體 ,可以看做是數據對象,往往對應于現實生活中的真實存在的個體。在 ER 模型中,用 矩形 來表示。實體分為兩類,分別是
強實體和弱實體。強實體是指不依賴于其他實體的實體;弱實體是指對另一個實體有很強的依賴關系的實體。 - 屬性 ,是指實體的特性。比如超市的地址、聯系電話、員工數等。在 ER 模型中用 橢圓形 來表示。
- 關系 ,是指實體之間的聯系。比如超市把商品賣給顧客,就是一種超市與顧客之間的聯系。在 ER 模型中用 菱形 來表示。
注意:實體和屬性不容易區分。這里提供一個原則:要從系統整體的角度出發去看,可以獨立存在的是實體,不可再分的是屬性。也就是說,屬性不能包含其他屬性。
9.5.2 關系的類型
在 ER 模型的三個要素中,關系又可以分為三種類型,分別是一對一、一對多、多對多。
- 一對一 :
指實體之間的關系是一一對應的,比如個人與身份證信息之間的關系就是一對一的關系。一個人只能有一個身份證信息,一個身份證信息也只屬于一個人。 - 一對多 :
指一邊的實體通過關系,可以對應多個另外一邊的實體。相反,另外一邊的實體通過這個關系,則只能對應唯一的一邊的實體。比如說,我們新建一個班級表,而每個班級都有多個學生,每個學生則對應一個班級,班級對學生就是一對多的關系。 - 多對多 :
指關系兩邊的實體都可以通過關系對應多個對方的實體。比如在進貨模塊中,供貨商與超市之間的關系就是多對多的關系,一個供貨商可以給多個超市供貨,一個超市也可以從多個供貨商那里采購商品。再比如一個選課表,有許多科目,每個科目有很多學生選,而每個學生又可以選擇多個科目,這就是多對多的關系。
9.6 數據表的設計原則
數據表的設計原則一般概括為 “三少一多”。
-
數據表的個數越少越好
RDBMS 的核心在于對實體和聯系的定義,也就是 E-R 圖,數據表越少,證明實體和聯系設計的越簡潔,既方便理解又方便操作。
-
數據表中的字段個數越少越好
字段個數越多,數據冗余的可能性越大。設置字段個數少的前提是各個字段互相獨立,而不是某個字段的取值可以由其他字段計算出來。當然這里的字段個數少是相對的,通常需要在數據冗余和檢索效率中進行平衡。 -
數據表中聯合主鍵的字段個數越少越好
設置主鍵是為了確定唯一性,當一個字段無法確定唯一性的時候,就需要采用聯合主鍵的方式(也就是用多個字段來定義一個主鍵)。
聯合主鍵中的字段越多,占用的索引空間越大,不僅會加大理解難度,還會增加運行時間和索引空間,所以聯合主鍵的字段個數越少越好。 -
使用主鍵和外鍵越多越好
數據庫的設計實際上就是定義各種表,以及各種字段之間的關系。這些關系越多,證明這些實體之間的冗余度越低,利用度越高。這樣做的好處在于不僅保證了數據表之間的獨立性,還能提升相互之間的關聯使用率。
"三少一多" 原則的核心就是簡單可復用。簡單是指用更少的表、更少的字段、更少的聯合主鍵字段來完成數據表的設計。可復用是通過主鍵、外鍵的使用來增強數據表之間的復用率。因為一個主鍵可以理解是一張表的代表。鍵設計的越多,證明它們之間的利用率越高。
注意:這個原則并不是絕對的,有時候需要犧牲數據的冗余度來換取數據處理的效率。
9.7 數據庫對象的編寫建議
9.7.1 關于庫
-
【強制】庫的名稱必須控制在 32 個字符以內,只能使用英文字母、數字和下劃線,建議以英文字
母開頭。 -
【強制】庫名中英文
一律小寫,不同單詞采用下劃線分割。須見名知意。 -
【強制】庫的名稱格式:業務系統名稱_子系統名。
-
【強制】庫名禁止使用關鍵字(如 type、order 等)。
-
【強制】創建數據庫時必須 顯式指定字符集 ,并且字符集只能是 utf8 或者 utf8mb4。
# 創建數據庫SQL舉例: CREATE DATABASE crm_fund DEFAULT CHARACTER SET 'utf8' ; -
【建議】對于程序連接數據庫賬號,遵循
權限最小原則。使用數據庫賬號只能在一個 DB 下使用,不準跨庫。程序使用的賬號原則上不準有 drop 權限 。
-
【建議】臨時庫以 tmp_ 為前綴,并以日期為后綴;
備份庫以 bak_ 為前綴,并以日期為后綴。
9.7.2 關于表、列
-
【強制】表和列的名稱必須控制在 32 個字符以內,表名只能使用英文字母、數字和下劃線,建議
以 英文字母開頭 。 -
【強制】 表名、列名一律小寫 ,不同單詞采用下劃線分割。須見名知意。
-
【強制】表名要求有模塊名強相關,同一模塊的表名盡量使用 統一前綴 。比如:crm_fund_item
-
【強制】創建表時必須 顯式指定字符集 為 utf8 或 utf8mb4。
-
【強制】表名、列名禁止使用關鍵字(如 type、order 等)。
-
【強制】創建表時必須 顯式指定表存儲引擎 類型。如無特殊需求,一律為 InnoDB。
-
【強制】建表必須有 comment。
-
【強制】字段命名應盡可能使用表達實際含義的英文單詞或 縮寫 。如:公司 ID,不要使用
corporation_id, 而用 corp_id 即可。 -
【強制】布爾值類型的字段命名為 is_ 描述 。如 member 表上表示是否為 enabled 的會員的字段命
名為 is_enabled。 -
【強制】禁止在數據庫中存儲圖片、文件等大的二進制數據。
通常文件很大,短時間內造成數據量快速增長,數據庫進行數據庫讀取時,通常會進行大量的隨
機 IO 操作,文件很大時,IO 操作很耗時。通常存儲于文件服務器,數據庫只存儲文件地址信息。 -
【建議】建表時關于主鍵:
表必須有主鍵。① 強制要求主鍵為 id,類型為 int 或 bigint,且為 auto_increment 建議使用 unsigned 無符號型。 ② 標識表里每一行主體的字段不要設為主鍵,建議設為其他字段。如 user_id,order_id等,并建立 unique key 索引。因為如果設為主鍵且主鍵值為隨機插入,則會導致 InnoDB 內部頁分裂和大量隨機 I/O,性能下降。
-
【建議】核心表(如用戶表)必須有行數據的
創建時間字段(create_time)和最后更新時間字段(update_time),便于查問題。 -
【建議】表中所有字段盡量都是 NOT NULL 屬性,業務可以根據需要定義 DEFAULT值 。 因為使用 NULL 值會存在每一行都會占用額外存儲空間、數據遷移容易出錯、聚合函數計算結果偏差等問
題。 -
【建議】所有存儲相同數據的
列名和列類型必須一致(一般作為關聯列,如果查詢時關聯列類型
不一致會自動進行數據類型隱式轉換,會造成列上的索引失效,導致查詢效率降低)。 -
【建議】中間表(或臨時表)用于保留中間結果集,名稱以 tmp_ 開頭。備份表用于備份或抓取源表快照,名稱以 bak_ 開頭。中間表和備份表定期清理。
-
【建議】創建表時,可以使用可視化工具。這樣可以確保表、字段相關的約定都能設置上。
實際上,我們通常很少自己寫 DDL 語句,可以使用一些可視化工具來創建和操作數據庫和數據表。可視化工具除了方便,還能直接幫我們將數據庫的結構定義轉化成 SQL 語言,方便數據庫和數據表結構的導出和導入。
9.7.3 關于索引
- 【強制】InnoDB 表必須主鍵為 id int/bigint auto_increment,且主鍵值
禁止被更新。 - 【強制】InnoDB 和 MyISAM 存儲引擎表,索引類型必須為 B+Tree。
- 【建議】主鍵的名稱以 pk_ 開頭,唯一鍵以 uni_ 或 uk_ 開頭,普通索引以 idx_ 開頭,一律
使用小寫格式,以字段的名稱或縮寫作為后綴。 - 【建議】多單詞組成的 columnname,取前幾個單詞首字母,加末單詞組成 column_name。如:
sample 表 member_id 上的索引:idx_sample_mid。 - 【建議】
單個表上的索引個數不能超過6個。 - 【建議】 在建立索引時,多考慮建立聯合索引 ,并把區分度最高的字段放在最前面。
- 【建議】在多表 JOIN 的 SQL 里,保證被驅動表的連接列上有索引,這樣JOIN 執行效率最高。
- 【建議】建表或加索引時,保證表里互相不存在 冗余索引 。 比如:如果表里已經存在 key(a,b),
則 key(a) 為冗余索引,需要刪除。
9.7.4 SQL 編寫
-
【強制】程序端
SELECT 語句必須指定具體字段名稱,禁止寫成 *。 -
【建議】程序端
INSERT 語句指定具體字段名稱,不要寫成 INSERT INTO t1 VALUES(…)。 -
【建議】除靜態表或小表(100行以內),DML 語句必須有 WHERE 條件,且使用索引查找。
-
【建議】INSERT INTO…VALUES(XX),(XX),(XX)… 這 里XX 的值不要超過 5000 個。值過多雖然上線很快,但會引起主從同步延遲。
-
【建議】SELECT 語句
不要使用 UNION,推薦使用 UNION ALL(MySQL 5.6 之后 UNION ALL 不會使用到臨時表),并且 UNION 子句個數限制在 5 個以內。 -
【建議】線上環境,多表 JOIN 不要超過5個表。
-
【建議】減少使用 ORDER BY,和業務溝通能不排序就不排序,或將排序放到程序端去做。ORDER BY、GROUP BY、DISTINCT 這些語句較為耗費 CPU,數據庫的 CPU 資源是極其寶貴的。
-
【建議】包含了 ORDER BY、GROUP BY、DISTINCT 這些查詢的語句,WHERE 條件過濾出來的結果集請保持在1000 行以內,否則 SQL 會很慢。
-
【建議】
對單表的多次 alter 操作必須合并為一次。對于超過 100W 行的大表進行 alter table,必須經過 DBA 審核,并在業務低峰期執行,多個 alter 需整合在一起。 因為 alter table 會產生表鎖 ,期間阻塞對于該表的所有寫入,對于業務可能會產生極
大影響。 -
【建議】批量操作數據時,需要控制事務處理間隔時間,進行必要的 sleep。
-
【建議】
事務里包含 SQL 不超過 5 個。因為過長的事務會導致鎖數據較久,MySQL 內部緩存、連接消耗過多等問題。
-
【建議】事務里更新語句盡量基于主鍵或 UNIQUE KEY,例如 UPDATE… WHERE id=XX; 否則會產生間隙鎖,內部擴大鎖定范圍,導致系統性能下降,產生死鎖。



)



)
框架軟件小白入門教程(九))



)
ref 轉發-forwardRef)


實現內網穿刺)
使用tripple協議進行通信)
)
)