目錄
前言:
1 部分簡單函數的實現
2 push_back和pop_back
3 reserve和resize
4 Print_vector
5 insert和erase
6 拷貝構造
7 構造
8 賦值
9 memcpy的問題
10 迭代器失效
前言:
繼上文模擬實現了string之后,接著就模擬實現vector,因為有了使用string的基礎之后,vector的使用就易如反掌了,所以這里直接就模擬實現了,那么實現之前,我們先看一下源代碼和文檔:
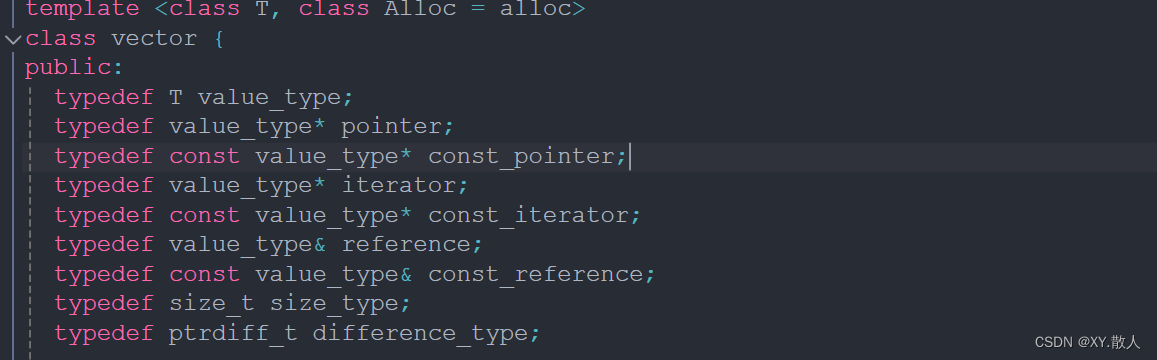
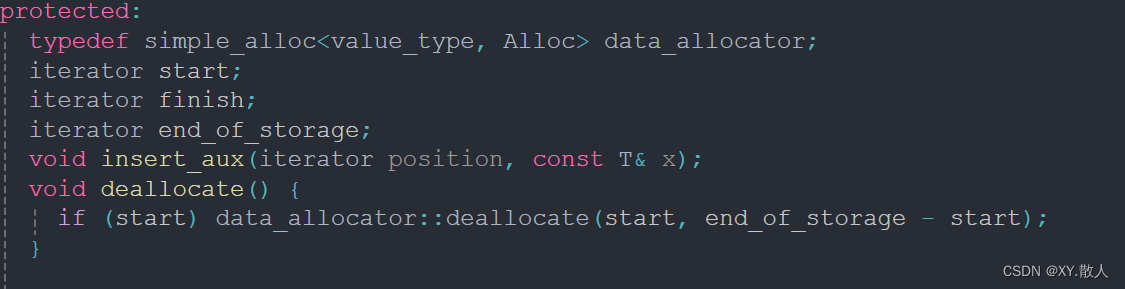
源碼不多看,因為很容易繞暈進去,我們從這兩個部分得到的信息就夠了,首先,vector是一個類模板,即我們可以往里存放許多不同的數據,比如實現一個二維數組,我們可以用vector里面套一個vector,就實現了一個二維數組,為什么說二維數組是一維數組的集合,因為vector的每個空間的start指針指向的空間又是一塊連續的空間,即這就是二維數組的構造。
在public的下面有一堆的typedef,這也是不要多看源碼的一個原因,很容易繞進去的,比如vector的成員變量的類型是iterator,我們看到value_type*是重命名為iterator了,那么value_type又是T的重命名,即start的類型就是T*,現在我們搞懂了一個問題即模擬實現vector的時候成員變量的類型是模板指針。
那么現在就需要搞懂三個成員變量是什么?
這里就明說了,start是空間的起始位置,finish是空間的最后一個數據的下一個位置,end_of_storage是空間的最后一個位置,所以我們實現size(),capacity()的時候就兩兩相減就可以了。
基本類型我們了解了,現在就開始模擬實現吧。
1 部分簡單函數的實現
這里實現以下函數,size(),capacity(),begin(),end()以及const版本,operator[]以及const版本,empty(),析構函數,注意的就是返回值返回類型即可:
iterator begin()
{return _start;
}
iterator end()
{return _finish;
}
const_iterator begin()const
{return _start;
}
const_iterator end()const
{return _finish;
}
size_t size()
{return _finish - _start;
}
size_t capacity()
{return _end_of_storage - _start;
}
T& operator[](size_t pos)
{assert(pos <= _finish);return *(_start + pos);
}
const T& operator[](size_t pos)const
{assert(pos <= _finish);return *(_start + pos);
}
bool empty()
{return _start == _finish;
}
~vector()
{delete[] _start;_start = _finish = _end_of_storage = nullptr;
}因為是[]重載,返回的是可以修改的類型所以用引用,這里模擬實現的時候一般都返回size_t類型,這里文檔里面的原型,最好保持一致。
2 push_back和pop_back
尾插的時候要注意空間的擴容,擴容的判斷條件即是_finish = _end_of_storage的時候,擴容方式和前面實現順序表鏈表的時候沒有什么區別,使用2倍擴容,但是實際上vs下的vector擴容的時候是使用的1.5倍擴容,我們模擬實現的是linux下的vector,在string模擬實現的時候,我們拷貝數據使用的是strcpy,在這里因為是模板,所以不能使用字符串函數,使用內存拷貝,即使用memcpy,當然memset也可以,但是memcpy就可以了,因為不存在空間重疊的問題。
這里有個隱藏的坑,到后面插入string類的時候才會顯式出來,這里先不說,目前插入內置類型是沒有問題的:
void push_back(const T& val){//判斷擴容if (_finish == _end_of_storage){size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();T* tmp = new T[newcapacity];memcpy(tmp, _start, sizeof(T) * size());delete[] _start;_start = tmp;_finish = _start + size();_end_of_storage = tmp + newcapacity;}*_finish = val;_finish++;}好了,實現好了嗎?當然沒有,這里也有個坑,即size()的問題,因為實現size()的時候,實現方式是_finish - _start,但是擴容之后,_start的位置已經改變,所以此時size()的實現變成了原來的_finish - 新的_start了,所以會報錯,解決方式就是把size()先存起來再使用:
void push_back(const T& val){//判斷擴容if (_finish == _end_of_storage){size_t old_size = size();size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();T* tmp = new T[newcapacity];memcpy(tmp, _start, sizeof(T) * size());delete[] _start;_start = tmp;_finish = tmp + old_size;//容易出錯_end_of_storage = tmp + newcapacity;}*_finish = val;_finish++;}這里如果忘了memcpy的使用可以看看文檔。
那么push_back就還有一個坑沒有解決了,欲知后事如何,請看下去咯。
pop_back的實現相對來說就簡單多了,尾刪不代表真正的刪除數據,指針指向的位置改變就是尾刪了,當然,刪除操作想要執行就vector就不能為空:
void pop_back(){assert(!empty());_finish--;}3 reserve和resize
reserve的實現我們剛才其實已經實現過了,reserve即是擴容,push_back的時候我們已經考慮了擴容,所以代碼差不了多少:
void reserve(size_t n)
{if (capacity() < n){size_t old_size = size();T* tmp = new T[n];memcpy(tmp, _start, sizeof(T) * size());delete[] _start;_start = tmp;_finish = tmp + old_size;_end_of_storage = tmp + n;}
}當然,這里的坑和push_back是一樣的,只有在插入自定義類型的時候才會出現,先不急,那么這里的擴容就是把newcapacity換成了n而已,其余的是沒有差別的。
resize模擬實現的時候就要注意了,如果resize實現的是縮容,就直接移動_finish指針就好了,如果實現的是擴容,那么默認參數我們怎么給呢?

文檔里面記錄的缺省值是value_type(),而value_type是typedef之后的T,所以我們可以看成T val = T(),看著是有點奇怪?其實一點都不奇怪,比如:
int main()
{//Test7_vector();int a = int();cout << a;char ch = char();cout << ch;return 0;
}這種代碼運行是完全沒有問題的,這里的a是0,這里的ch是'\0',這是一種初始化方式,所以我們傳參的時候就不能寫成0,因為不是所有的vector都是vevtor<int>類型的,所以這里我們采用文檔的方式,使用這種缺省值,那么擴容的時候多余的空間就給上這個缺省值就好了:
void resize(size_t n, const T& val = T())
{if (size() < n){//擴容reserve(n);while (_finish < _start + n){*_finish = val;_finish++;}}else{//刪減_finish = _start + n;}
}實際上我們也可以一直尾插T(),但是我們既然知道了我們要多少空間,我們不如直接把空間開完,然后進行賦值就好了,賦值的循環條件是_finish指針到最后擴容的指針的位置,也是比較好理解的。
4 Print_vector
當插入和擴容操作都完成了,下一步就是打印了,當然會有人說初始化怎么辦,不急,我們先構造一個空的vector就可以了:
vector()
{}iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_storage = nullptr;先使用上缺省值,方便測試即可。
Print_vector是用來打印vector的,這里其實變相的考了遍歷方式,遍歷就是三件套:
void Print_vector(const T& t)
{for (auto e : t){cout << e << " ";}cout << endl;//typename 告訴編譯器這是個類型typename vector<T>::iterator it = v.begin();while (it != v.end()){cout << *it << " ";it++;}for (int i = 0;i < size();i++){cout << v[i] << " ";}
}這是三種遍歷方式,下標訪問和迭代器使用都是沒有問題的,唯獨需要注意的是typename那里,如果那里我們使用auto it = v.begin()是沒有問題的,但是如果我們使用vector<T>::iterator it = v.begin()就會有問題了,這里是因為編譯器不知道這里的vector<T>::iterator是類型還是變量了,編譯器的原則是不會去類模板里面找東西,而這里使用了模板,那么從編譯器的角度出發,它不知道這個究竟是個類型還是變量,所以使用typename。
5 insert和erase
push_back和pop_back是尾插尾刪,想要任意位置插入就需要用到insert和erase,文檔里面erase有刪除一段區間的,這里我們就實現任意位置刪除一個數據即可,因為刪除一段區間的原理是一樣的,因為是任意位置刪除和插入,所以實現了之后在push_back和pop_back上也可以復用
insert實現的原理很簡單,挪動數據添加數據即可,當然要注意是否要擴容:
void insert(iterator pos, const T& val)
{assert(pos <= _finish);assert(pos >= _start);if (_finish == _end_of_storage){size_t len = pos - _start;reserve(capacity() == 0 ? 4 : 2 * capacity());pos = len + _start;//易錯點}iterator it1 = _finish - 1;while (it1 >= pos){*(it1 + 1) = *it1;it1--;}*pos = val;_finish++;
}當然,為了位置的合法性,這里使用assert斷言一下,然后就是判斷擴容,但是這里和push_back的size是一個道理,一旦發生擴容,那么pos位置就會變化,while循環的判斷就會出問題,所以我們擴容后要更新一下pos的位置,這樣才能保證循環的進行。
這里相對string還有一個很好的地方就是我們不用擔心end >= pos的那種隱式類型轉換比較的發生。
erase的實現原理是一樣的,把刪除位置的數據往后移動即可。
iterator erase(iterator pos)
{assert(pos <= _finish);assert(pos >= _start);iterator it1 = pos + 1;while (it1 < _finish){*(it1 - 1) = *it1;it1++;}_finish--;return pos;
}那么這里的復用就是:
void push_back(const T& val)
{insert(end(), val);
}
void pop_back()
{assert(!empty());_finish--;
}
6 拷貝構造
這里的拷貝構造沒有string拷貝那么復雜了,不用想深拷貝的問題,開空間一直插入就可以了:
vector(const vector<T>& v)
{reserve(capacity());for (auto& e : v){push_back(e);}
}拷貝構造的最基本要求不能忘記,參數必須是const 的引用類型,不然會發生無限遞歸的問題。
7 構造
構造是最終boss。

第一個構造,即構造一個空的順序表,我們可以專門寫個函數:
vector():_start(nullptr),_finish(nullptr),_end_of_storage(nullptr)
{}當然,沒有必要,我們給上三個缺省值就可以了,這是一個構造重載。
第二個重載是給n個element,也很好操作,一直尾插就好了:
vector(size_t n, const vector<T>& val = T())
{reserve(n);for (int i = 0;i < n;i++){push_back(val);}
}第二個也沒多大問題,再來看第三個區間構造,實際上第三個重載的最后一個參數可以完全不用管的,沒有多大意義,區間構造會再用到一個模板,即類模板的成員函數也可以是個模板:
template<class InputIterator>vector(InputIterator first,InputIterator last){while (first != last){push_back(*first);first++;}}以為結束了?還沒有,看這段代碼:
vector<int> v3 = { 1,2,3,4,5,6 };
這個構造是不是覺得有點奇怪,好像對不上上面三個構造中的任何一個,因為花括號里面的類型是initializer_list

這是一個類,它的成員變量也就幾個迭代器和size,但是這是c++11引進的,即c++11準許如下的初始化方式:
void Test_vector()
{//有關initializer_listint a = 1;int b = { 1 };int c{ 1 };//上面寫法均正確 但是不推薦后面兩種vector<int> v1 = { 1,2,3,4,5,6 };//隱式類型轉化vector<int> v2({ 1,2,3,4,5,6,7,8 });//直接構造
}但是不推薦這種方式,代碼可讀性沒那么高,但是我們看到這種初始化方式應該知道這是使用的initializer_list類型來初始化的,這里的初始化也是涉及到了隱式類型轉換,先構造一個臨時對象,再拷貝構造這個臨時對象,那么編譯器會優化為直接構造。
所以構造就是這樣構造的:
vector(initializer_list<T> il)
{reserve(il.size());for (auto& e : il){push_back(e);}
}但是,這里會出問題了:
vector(initializer_list<T> il)
{reserve(il.size());for (auto& e : il){push_back(e);}
}vector(size_t n, const vector<T>& val = T())
{reserve(n);for (int i = 0;i < n;i++){push_back(val);}
}void Test()
{vector<int> v(10,1);vector<int> v(10u,1);vector<int> v(10,'a');
}下面的兩個構造就不會出問題,第二個的u是無符號的標志,即size_t,第一個會出問題,因為10和1默認的類型是int,那你說,調用上面的沒問題吧?調用下面的,雖然第一個的參數類型是size_t,但是將就將就吧也可以,那你說,編譯器調用哪個?
所以這里會報錯,那么源代碼里面解決的就很簡單粗暴:
vector(int n, const vector<T>& val = T())
{reserve(n);for (int i = 0;i < n;i++){push_back(val);}
}類型轉換一下~?
8 賦值
這里的賦值我們可以直接采用現代寫法,不用傳統的先開空間,再進行數據拷貝,我們利用swap函數,可以達到很好的效果:
void swap(const vector<T>& v){std::swap(_start,v._start);std::swap(_finish,v._finish);std::swap(_end_of_storage,v._end_of_storage);}這里需要注意到的是swap的調用需要用到域名訪問限定符,不然編譯器會調用離函數最近的函數,即它本身,而我們使用的是std庫里面的交換函數,所以需要使用::。
有了交換,我們構造一個臨時對象,再進行交換即可:
vector<int>& operator=(vector<T> v)
{swap(v);return *this;
}我們提及到過連續賦值的條件是返回值應該是賦值過后的值,所以我們需要返回賦值之后的對象。
9 memcpy的問題
先看這樣一段代碼:
void Test5_vector()
{vector<string> v;v.push_back("11111"); v.push_back("22222");v.push_back("33333");v.push_back("44444");v.push_back("55555");for (auto& e : v){cout << e << " ";}cout << endl;
}如果我們只存入4個或者及以下的數據是沒有問題的,但是存入5個數據之后,就會存在訪問出錯的問題,這一切都是因為memcpy,也就是在擴容,尾插的時候會涉及到的問題。
我們了解memcpy的底層之后,就知道memcpy拷貝的方式是逐字節的拷貝,所以當_start指向的空間是自定義類型的時候,經過擴容之后,就會導致_start指向的空間被銷毀,但是拷貝過來的指針依舊是指向那塊被銷毀的空間的,我們再次訪問自然就會報錯。
所以這里我們最好的方法就是進行賦值:
void reserve(size_t n)
{if (capacity() < n){size_t old_size = size();T* tmp = new T[n];//memcpy(tmp, _start, sizeof(T) * size());for (int i = 0; i < old_size; i++){tmp[i] = _start[i];}delete[] _start;_start = tmp;_finish = tmp + old_size;_end_of_storage = tmp + n;}
}本質就是拷貝構造一個臨時對象,就不會導致越界訪問的問題。
10 迭代器失效
void Test6_vector()
{vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);v1.push_back(6);v1.push_back(7);v1.push_back(8);vector<int>::iterator it = v1.begin() + 3;v1.insert(it, 40);Print_vector(v1);//it = v1.begin() + 3;cout << *it << endl;
}當我們多次插入之后,伴隨著擴容的發生,所以it的位置會發生改變,it指向的是原來的空間位置,所以此時我們打印it的值的時候就會打印出來錯誤的值,所以如果發生了空間的改變導致迭代器失效,如果我們還要使用迭代器,我們就需要重置迭代器-》即那段注釋。
void Test7_vector()
{vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(4);v1.push_back(5);v1.push_back(4);vector<int>::iterator it = v1.begin();while (it != v1.end()){if (*it % 2 == 0){v1.erase(it);it++;}}for (auto e : v1){cout << e << " ";}cout << endl;
}且看這段刪除偶數的代碼,好像沒有問題?有以下幾種情況就會出錯了,11252,1223。
因為刪除之后會有移動數據的發生,比如1223,刪除了第一個2,第二個2往前面移動,然后再pos位置的指針往后移動,就相當于it指針移動了兩次,所以會錯過,那么如果最后一個是偶數,即11252,就會完美錯過end,那么循環條件就無法結束,就會死循環了。
解決方法也很簡單,讓it刪除之后原地踏步就好了:
while (it != v1.end())
{if (*it % 2 == 0){it = v1.erase(it);//解決方法}else{++it;}
}這也是為什么erase的返回值是iterator的原因,整個代碼都是前后呼應的。
感謝閱讀!




)














