云計算基礎
作業(問答題)
(1)總結云計算的特點。
- 透明的云端計算服務?
- “無限”多的計算資源,提供強大的計算能力
- 按需分配,彈性伸縮,取用方便,成本低廉
- 資源共享,降低企業IT基礎設施建設維護費用
- 應用部署快速而容易
- 軟件/應用功能更新方便快捷
- 節省能源,綠色環保
- 集計算技術之大成,具有很強的技術性、工程型特點
(2)分析云計算的優勢。
云計算作為現代信息技術的關鍵組成部分,為企業和個人提供了豐富的服務和解決方案,其優勢可以從以下幾個方面深入分析:
1.敏捷性與靈活性:
???- 快速部署:用戶可以即時獲取計算資源,無論是服務器、存儲空間還是應用程序,幾分鐘內就能完成資源的創建和部署,極大地提高了業務上線速度。
???- 靈活擴展:云計算支持按需分配資源,可以根據業務負載自動擴展或縮減資源,滿足業務高峰期和低谷期的需求變化,避免了過度投資和資源閑置。
2.成本節約:
???- 按需付費:云計算采用訂閱或按使用量計費模式,取代了傳統的前期大量資本投入購買硬件和軟件的做法,將固定成本轉化為可變成本,減輕企業的財務壓力。
???- 資源利用率提升:通過多租戶資源共享和高效的資源調度,云計算平臺能夠提高服務器、存儲和其他基礎設施的使用效率,避免了單個組織內部資源的浪費。
3.可擴展性和彈性:
???- 動態擴展:云服務提供商的基礎設施規模巨大,用戶可以無縫地擴大或縮小資源規模,特別是在面對突發流量或項目需求變化時,能夠快速應對而不影響服務質量。
???- 高可用性:云計算通過冗余和分布式架構確保服務高可用,即使部分硬件故障也不會導致服務中斷。
4.安全性與合規性:
???- 數據保護:云服務商通常會采用高級的數據加密技術、多重身份驗證、防火墻以及其他安全措施,提供可能超越傳統本地部署的安全水平。
???- 備份與恢復:云服務自帶災難恢復和數據備份機制,有助于企業在發生意外情況時快速恢復業務運作。
5.全球化部署和協作:
???- 全球覆蓋:云服務允許用戶在全球多個地理位置快速部署應用和服務,支持跨國公司實現全球化的業務拓展。
???- 即時協作:云環境有利于團隊成員之間的遠程協作,無論地理位置如何,都能訪問同一套資源,協同辦公。
6.技術創新和集成:
???- 創新技術便捷接入:云計算平臺上整合了大量的先進技術,如AI、大數據分析、物聯網(IoT)、機器學習等,用戶無需自行研發就能直接利用這些服務。
???- 開發運維一體化(DevOps):云計算促進了持續集成/持續部署(CI/CD)實踐,加速了軟件產品的迭代和上市速度。
綜上所述,云計算憑借其強大的靈活性、經濟高效性、高可用性和安全性等特性,已經成為企業和開發者實施數字化轉型、增強競爭力的戰略工具。
? 云計算將提供一種新的計算模式和服務模式。云計算將是計算技術的一次重大變革,作為今后計算發展的潮流將大大改變現有的計算模式,對計算技術領域本身以及各個應用行業都將帶來重大的影響,提供更多的發展機遇
? 通過云計算人們能獲得前所未有的強大計算能力,并能按需分配,按需付費,提升了本地計算能力但使用成本低廉,而且還能大幅削減不斷升級軟硬件系統的費用
? 通過云計算平臺強大的計算和存儲能力,人們將能完成傳統系統所無法完成的計算和處理,開發出更強大的應用功能,提供更多智能化應用
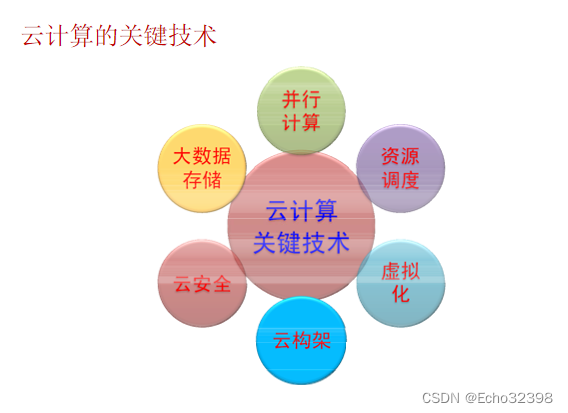
(3)云計算的關鍵技術有哪些?
主要包括以下關鍵技術
- 虛擬化技術:虛擬機的安裝、設置、調度分配、使用、 故障檢測與失效恢復等
- 云計算構架技術:研究解決適合于云計算的系統軟硬 件構架
- 資源調度技術:解決物理或虛擬計算資源的自動化分 配、調度、配置、使用、負載均衡、回收等資源管理
- 并行計算技術:針對大數據或復雜計算應用,解決數 據或計算任務切分和并行計算算法設計問題
- 大數據存儲技術:解決大數據的分布存儲、共享訪問、 數據備份等問題
- 云安全技術:解決云計算系統的訪問安全性、數據安 全性(包括數據私密性)等問題
- 云計算應用:面向各個行業的、不同形式的云計算應 用技術和系統
- 此外,還有云計算中心的節能和散熱等工程技術問題
(4)什么是大數據?有哪些特征?
什么是大數據
大數據意指一個超大的、難以用現有常規的數據庫管理技術和工具處理的數據集。
大數據技術描述了一種新一代技術和構架,用于以很經濟的方式、以高速的捕獲、發現和分析技術,從各種超大規模的數據中提取價值。
有哪些特征
?
大數據特征:
(1)數據量大(Volume)
???大數據的起始計量單位至少是PB(1 000個TB)、EB(100萬個TB)或ZB(10億個TB)。非結構化數據的超大規模和增長,比結構化數據增長快10~50倍,是傳統數據倉庫的10~50倍。
(2)類型繁多(Variety)
????大數據的類型可以包括網絡日志、音頻、視頻、圖片和地理位置信息等,具有異構性和多樣性的特點,沒有明顯的模式,也沒有連貫的語法和句義,多類型的數據對數據的處理能力提出了更高的要求。
(3)價值密度低(Value)
???大數據價值密度相對較低。如隨著物聯網的廣泛應用,信息感知無處不在,信息海量,但價值密度較低,存在大量不相關信息。因此需要對未來趨勢與模式做可預測分析,利用機器學習、人工智能等進行深度復雜分析。而如何通過強大的機器學習算法更迅速地完成數據的價值提煉,是大數據時代亟待解決的難題。
?(4)速度快、時效高(Velocity)
????處理速度快,時效性要求高,需要實時分析而非批量式分析,數據的輸入、處理和分析連貫性地處理,這是大數據區分于傳統數據挖掘最顯著的特征。
(5)大數據和云計算有什么關系??
?????云計算是基于互聯網的相關服務的增加、使用和交付模式,通常涉及通過互聯網來提供動態易擴展且經常是虛擬化的資源。云是網絡、互聯網的一種比喻說法。狹義云計算指IT基礎設施的交付和使用模式,指通過網絡以按需、易擴展的方式獲得所需資源。廣義云計算指服務的交付和使用模式,指通過網絡以按需、易擴展的方式獲得所需服務;這種服務可以是IT和軟件、互聯網相關,也可以是其他服務;它意味著,計算能力也可作為一種商品通過互聯網進行流通。
????大數據或稱海量數據,指的是所涉及的資料量規模巨大到無法通過目前主流軟件工具,在合理時間內達到擷取、管理、處理并整理成為幫助企業經營決策提供更具參考價值的資訊。大數據的4V特點:Volume、Velocity、Variety、Veracity。
????從技術上看,大數據與云計算的關系就像一枚硬幣的正反面一樣密不可分。大數據必然無法用單臺的計算機進行處理,必須采用分布式計算架構。它的特色在于對海量數據的挖掘,但它必須依托云計算的分布式處理、分布式數據庫、云存儲和虛擬化技術。

其他知識點
什么是云計算
通過集中式遠程計算資源池 ,以按需分配方式 ,為終端用戶提供強大而廉價的計算服務能力
- 工業化部署、商業化運作的大規模計算能力
- 一種新的 、可商業化的計算和服務模式
- 計算能力像水電煤氣 一樣,按需分配使用
- 資源池物理上對用戶透明 就像在云端一樣
云計算的分類?
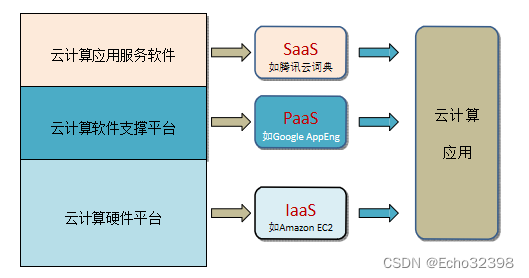
按云計算服務層面進行分類
- SaaS:Software as a Service 提供各種應用軟件服務
- PaaS:Platform as a Service 提供軟件支撐平臺服務
- IaaS:Infrastructure as a Service 提供接近于裸機(物理機或虛擬機)的計算資源 和基礎設施服務

?按云計算系統類型進行分類
公用云、私有云、社區云、混合云
大數據的類型
? 結構特征
????????– 結構化數據
????????– 非結構化/半結構化數據
? 獲取和處理方式
????????– 動態(流式/增量式/線上)/實時數據
????????– 靜態(線下數據)/非實時數據
? 關聯特征
????????– 無關聯/簡單關聯數據(鍵值記錄型數據)
????????– 復雜關聯數據(圖數據)
大數據其他知識點


并行計算基礎
作業(問答題)
總結和分析MapReduce工作原理
MapReduce是一種編程模型和相關的實現,用于處理和生成大型數據集。用戶指定一個map函數,處理一個鍵值對,生成一組中間鍵值對,以及一個redce函數,合并與同一個中間鍵相關聯的所有中間值。
MapReduce的工作原理可以總結為將大規模的數據處理任務分解為多個小的子任務,并在分布式集群上并行執行這些子任務。通過將計算任務分布到多個機器上,MapReduce能夠實現高效的數據處理和計算,并具有容錯性和可伸縮性。
工作原理包括以下關鍵步驟和組件:1. Map階段:在MapReduce中,輸入數據被分割成多個小的數據塊,并由多個Map任務并行處理。每個Map任務將輸入數據塊作為輸入,并生成一系列鍵值對作為輸出。2. Shuffle階段:在Shuffle階段,Map任務的輸出被重新分區和排序,以便將具有相同鍵的鍵值對發送到同一個Reduce任務。這個階段的目的是將相同鍵的數據進行合并和分組。3. Reduce階段:在Reduce階段,每個Reduce任務接收到一組具有相同鍵的鍵值對,并對它們進行處理。Reduce任務可以對這些數據進行聚合、計算或其他操作,并生成最終的輸出結果。
?其他知識點
?
為什么需要并行計算?
- 貫穿整個計算機技術發展的核心目標:提高計算性能!
- 提高計算機性能的主要手段:提高處理器字長、提高集成度、流水線等微體系結構技術、提高處理器頻率
- 單核處理器性能接近極限:1.VLSI集成度不可能無限制提高 2.處理器的指令級并行度提升接近極限?3.處理器速度和存儲器速度差異越來越大?4.功耗和散熱大幅增加超過芯片承受能力
- 單處理器向多核并行計算發展成為必然趨勢
- 應用領域計算規模和復雜度大幅提高
上述問題的解決方案:并行計算
越來越多的研究和應用領域將需要使用并行計算技術、并行計算技術將對傳統計算技術產生革命性的影響
并行計算技術的分類?
按數據和指令處理結構:
弗林(Flynn)分類
按并行類型
按存儲訪問構架
按系統類型
按計算特征
按并行程序設計模型/方法






并行計算的主要技術問題?
多核/多處理器網絡互連結構技術 ?
存儲訪問體系結構 ?
分布式數據與文件管理 ?
并行計算任務分解與算法設計 ?
并行程序設計模型和方法 ?
數據同步訪問和通信控制 ?
可靠性設計與容錯技術 ?
并行計算軟件框架平臺 ?
系統性能評價和程序并行度評估
?MPI并行程序設計
MPI主要功能 ? ?
用常規語言編程方式,所有節點運行同一個程序,但處理不同的數據 ? ?
提供點對點通信(Point-point communication)
????????提供同步通信功能(阻塞通信)
????????提供異步通信功能(非阻塞通信) ? ?
提供節點集合通信(Collective communication)
????????提供一對多的廣播通信
????????提供多節點計算同步控制
????????提供對結果的規約(Reduce)計算功能 ? ?
提供用戶自定義的復合數據類型傳輸
MPI的特點和不足
MPI的特點
- 靈活性好,適合于各種計算密集型的并行計算任務
- 獨立于語言的編程規范,可移植性好
- 有很多開放機構或廠商實現并支持
MPI的不足
- 無良好的數據和任務劃分支持
- 缺少分布文件系統支持分布數據存儲管理
- 通信開銷大,當計算問題復雜、節點數量很大時,難以處理,性能大幅下降
- 無節點失效恢復機制,一旦有節點失效,可能導致計算過程無效
- 缺少良好的構架支撐,程序員需要考慮以上所有細節問題,程序設計較為復雜?
為什么需要大規模數據并行處理?
為什么需要海量數據并行處理技術?
海量數據及其處理已經成為現實世界的急迫需求
處理數據的能力大幅落后于數據增長,需要尋找有效的數據密集型并行計算方法
海量數據隱含著更準確的事實
為什么需要MapReduce?
并行計算技術和并行程序設計的復雜性?
海量數據處理需要有效的并行處理技術
MapReduce是目前面向海量數據處理最為成功的技術
















)
)
)
)