目錄
1-AI帶你認識GRA
📘 一、灰色關聯分析(GRA)簡介
1. 什么是灰色關聯分析?
2. 核心思想(通俗理解):
3. 與熵權法的對比(快速類比):
🧩 二、灰色關聯分析的基本原理
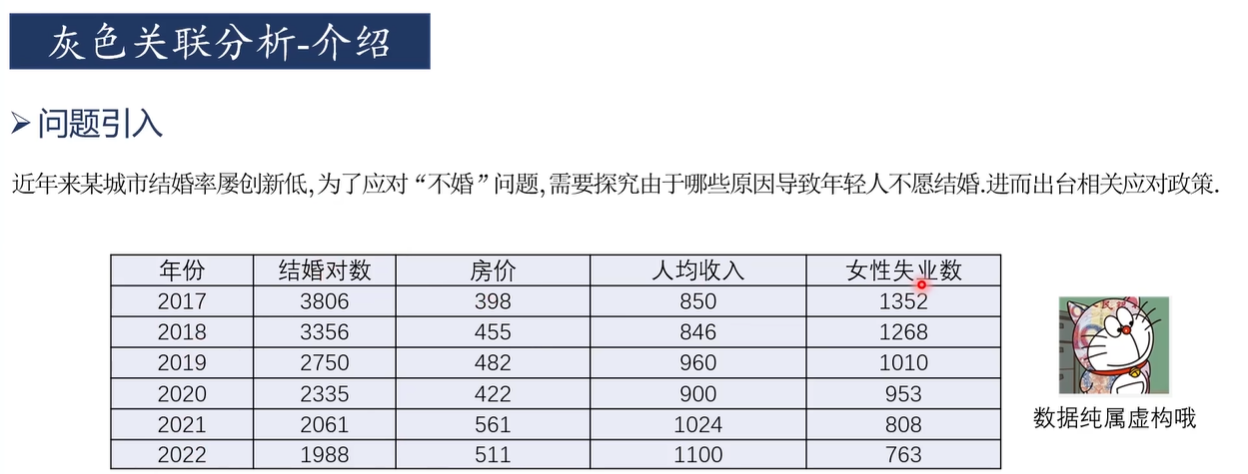
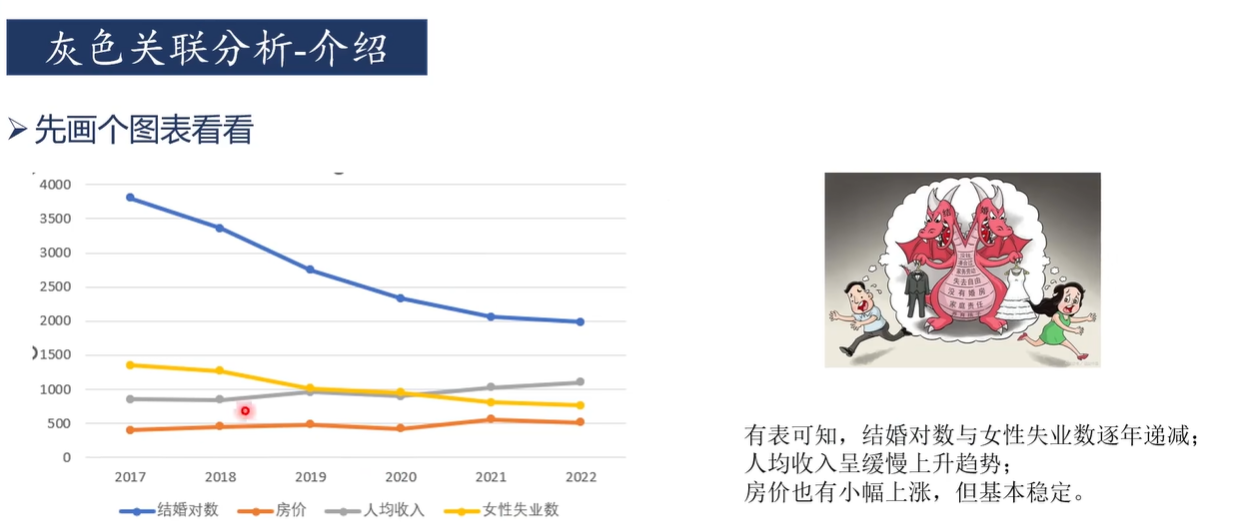
1. 問題背景:
🛠? 三、灰色關聯分析的基本步驟(標準流程)
? 步驟 1:構建原始數據矩陣
? 步驟 2:確定參考序列(理想解/母序列)
? 步驟 3:數據標準化(無量綱化處理)
(1)??均值化法(常用)??:
(2)??初值化法??:
(3)??區間化法(極差標準化)??:
? 步驟 4:計算關聯系數
? 步驟 5:計算關聯度
? 步驟 6:排序與分析
? 四、灰色關聯分析的優點與缺點
? 優點:
? 缺點:
📚 五、灰色關聯分析的典型應用場景
🧠 六、總結一句話:
📘 類比記憶(幫你更好理解):
📝 在數學建模/論文中的表述建議:
2-理論知識
介紹
定義
應用
3-基于excel表格實現灰色關聯分析
1)寫入數據
2)數據預處理
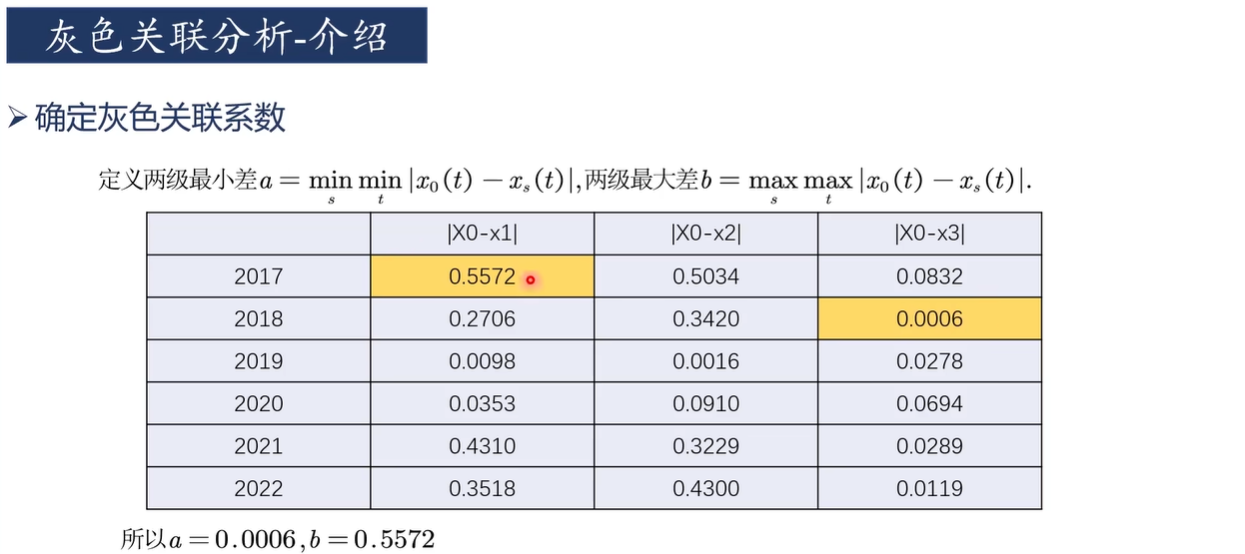
3)求出兩級最小差和兩級最大差
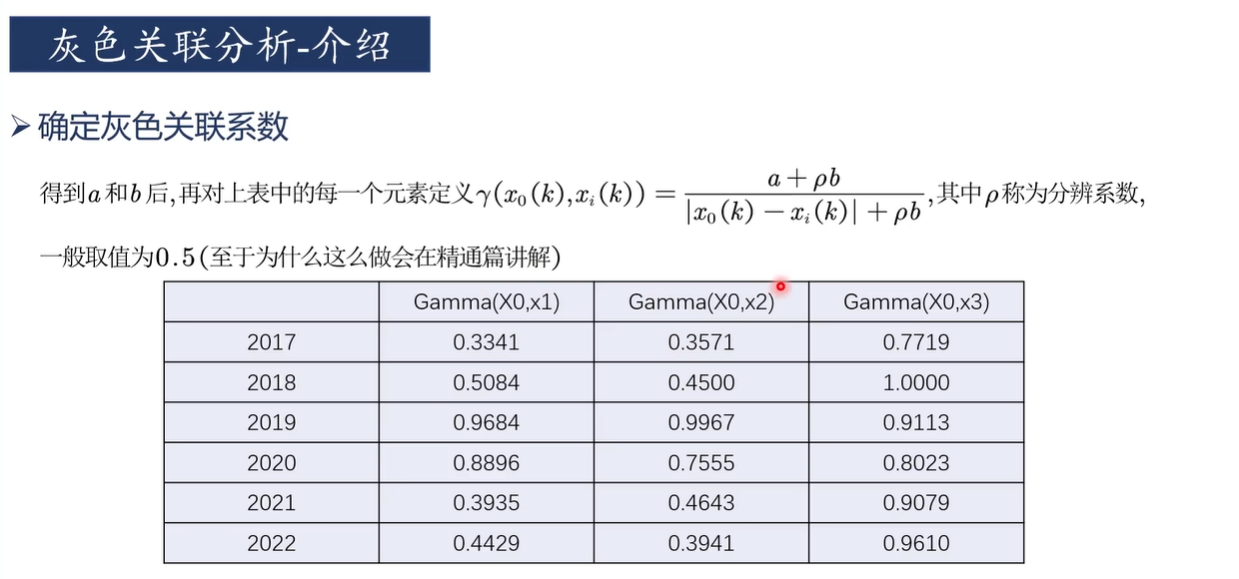
4)確定灰色關聯系數Gamma
計算公式
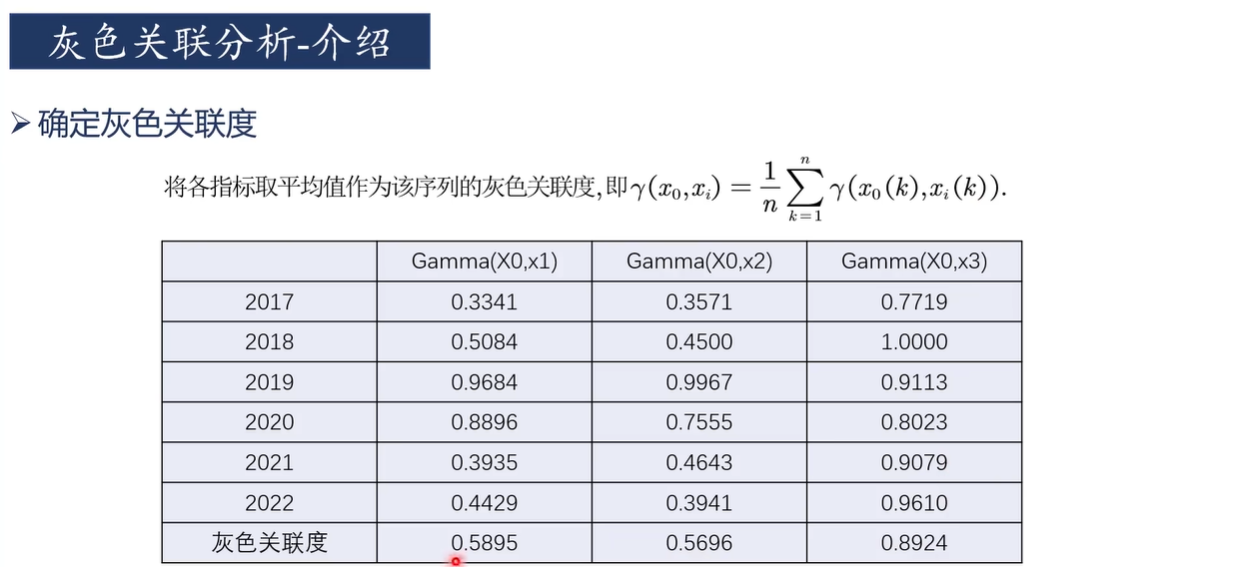
5)求每個指標的灰色關聯系數的平均值
1-AI帶你認識GRA
📘 一、灰色關聯分析(GRA)簡介
1. 什么是灰色關聯分析?
??灰色關聯分析(Grey Relational Analysis,簡稱 GRA 或 灰色關聯度分析)?? 是一種分析系統中??各因素間關聯程度(相似程度、變化趨勢相似性)的定量方法??,由我國著名學者 ??鄧聚龍教授?? 在 20 世紀 80 年代提出,是灰色系統理論的重要組成部分。
2. 核心思想(通俗理解):
??灰色關聯分析的核心思想是:通過計算各評價對象(或因素)的指標數據序列與“參考序列”(理想或對比基準)之間的“關聯程度”(即相似程度、變化趨勢的相近程度),來判斷它們之間的關聯性強弱,從而進行排序、評價或因素分析。??
你可以把它理解為:
??“誰的變化趨勢跟參考對象最像,誰就跟參考對象的關系最緊密,關聯度就越高。”??
3. 與熵權法的對比(快速類比):
項目
??熵權法??
??灰色關聯分析(GRA)??
??目的??
確定各指標的??客觀權重??
分析各對象或因素與參考序列的??關聯程度(相似性)??
??輸入??
原始數據矩陣(指標值)
原始數據矩陣(指標值),通常也需要參考序列
??輸出??
各指標的??權重值??
各對象與參考對象的??關聯度,用于排序或分析??
??是否排序??
一般不直接排序,常與 TOPSIS 等方法結合使用
??可直接排序,也可用于因素分析??
??主要用途??
多指標綜合評價中確定指標重要性
評價對象優劣排序、因素重要性分析、系統趨勢分析
??特點??
基于信息熵,反映指標的區分度
基于序列間的幾何相似性,反映變化趨勢的相似程度
🧩 二、灰色關聯分析的基本原理
1. 問題背景:
在實際問題中,我們常常需要分析:
- ?
多個??評價對象(如不同城市、企業、方案)??在多個??指標上??的表現;
- ?
或者多個??因素(如經濟指標、環境變量)??之間的相互關系與影響程度;
- ?
但我們往往??缺乏足夠的信息(數據少、信息不完全)??,屬于“??貧信息、小樣本??”問題 → 這正是灰色系統理論擅長處理的領域!
👉 ??灰色關聯分析正是用來解決這類“信息不完全但有一定規律”的問題,通過分析數據序列的相似性(關聯度)來進行評價或分析。??
🛠? 三、灰色關聯分析的基本步驟(標準流程)
假設我們有:
- ?
m 個??評價對象(如方案、城市、企業)??
- ?
n 個??評價指標??
- ?
每個對象在每個指標上都有一個觀測值
我們要分析這些對象與某個??參考對象(理想方案/參考序列)??的關聯程度,或者直接對這些對象進行優劣排序。
? 步驟 1:構建原始數據矩陣
設有 m 個對象,n 個指標,構建原始數據矩陣:
X=?x11?x21??xm1??x12?x22??xm2???????x1n?x2n??xmn???其中,xij?表示第 i 個對象在第 j 個指標上的值。
? 步驟 2:確定參考序列(理想解/母序列)
參考序列可以是:
- ?
??人為指定的最優值(如各指標的最大值/最小值,視指標性質而定)??
- ?
??實際數據中表現最好的那個對象(即某一行數據)??
- ?
或者根據問題背景自定義的參考標準
一般記作:
X0?=(x0?(1),x0?(2),...,x0?(n))如果是??對象間的優劣排序問題??,通常將每個指標的最優值組合成參考序列(類似 TOPSIS 的正理想解);也可以直接把某個對象作為參考對象。
? 步驟 3:數據標準化(無量綱化處理)
由于不同指標的量綱(單位)和數量級不同,通常需要對原始數據進行標準化處理,常用方法有:
(1)??均值化法(常用)??:
xi′?(k)=x(k)xi?(k)?,x(k)=m1?i=1∑m?xi?(k)(2)??初值化法??:
xi′?(k)=xi?(1)xi?(k)?(3)??區間化法(極差標準化)??:
xi′?(k)=max(x(k))?min(x(k))xi?(k)?min(x(k))?推薦使用 ??均值化法?? 或 ??初值化法??,在灰色關聯分析中較為常見。
標準化后得到新的矩陣?X′。
? 步驟 4:計算關聯系數
對于每個評價對象 i 與參考序列在每個指標 k 上的數值,計算它們之間的??關聯系數??:
ξi?(k)=∣x0?(k)?xi′?(k)∣+ρ?imax?kmax?∣x0?(k)?xi′?(k)∣imin?kmin?∣x0?(k)?xi′?(k)∣+ρ?imax?kmax?∣x0?(k)?xi′?(k)∣?其中:
- ?
∣x0?(k)?xi′?(k)∣:參考序列與第 i 個對象在第 k 個指標上的??絕對差??
- ?
imin?kmin?和?imax?kmax?:兩級最小差與最大差(用于規范化和調節)
- ?
ρ:??分辨系數??,一般取 ??0.5??(用于削弱最大差過大帶來的影響)
關聯系數?ξi?(k)反映的是第 i 個對象在第 k 個指標上與參考對象的??相似程度(關聯程度)??,取值范圍為 [0,1],越接近 1 表示關聯越強。
? 步驟 5:計算關聯度
對每個對象 i,在所有指標上的關聯系數求??平均值(或加權平均)??,得到該對象與參考序列的??關聯度??:
ri?=n1?k=1∑n?ξi?(k)如果各指標的重要程度不同,也可以引入權重?wk?,采用加權平均:
ri?=k=1∑n?wk??ξi?(k),k=1∑n?wk?=1
? 步驟 6:排序與分析
- ?
根據關聯度?ri???從大到小排序??
- ?
??關聯度越大,表示該對象與參考對象越相似,綜合表現越好(或關系越緊密)??
- ?
可用于:
- ?
??多對象優劣排序??
- ?
??因素重要性分析??
- ?
??系統動態變化趨勢分析??
? 四、灰色關聯分析的優點與缺點
? 優點:
- 1.
??對數據要求低??:不需要大量數據,適合小樣本、貧信息問題(灰色系統特色)
- 2.
??計算簡單、易于理解和實現??
- 3.
??不需要指標數據服從特定分布??
- 4.
??能反映數據間的變化趨勢與相似性,而不僅是數值大小??
- 5.
??廣泛應用于因素分析、方案排序、政策評價等實際問題??
? 缺點:
- 1.
??分辨系數 ρ 的選取具有一定主觀性??
- 2.
??對參考序列的選取比較敏感,影響最終結果??
- 3.
??只反映關聯程度,不直接給出“優劣”的絕對評價,更多是“相似性”??
- 4.
??一般需結合其他方法(如熵權法、TOPSIS)進行綜合評價??
📚 五、灰色關聯分析的典型應用場景
- ?
??多方案/多對象優劣排序??(如企業績效、城市發展水平、投資方案等)
- ?
??因素重要性分析??(如分析哪些因素對目標影響最大)
- ?
??系統趨勢分析??(如分析某指標與參考目標的變化趨勢是否相近)
- ?
??與 TOPSIS、熵權法等結合使用,構建更強大的綜合評價模型??
🧠 六、總結一句話:
??灰色關聯分析是一種通過計算數據序列之間幾何形狀的相似程度(關聯度),來判斷各評價對象與參考對象之間關聯性強弱的方法,適用于小樣本、多指標、貧信息的綜合評價與因素分析問題。??
📘 類比記憶(幫你更好理解):
可以把灰色關聯分析類比為:
“在眾多曲線(各對象的數據序列)中,找出哪一條跟參考曲線(理想/基準序列)的‘走勢’最像,最像的就說明關聯度最高,評價越好。”
📝 在數學建模/論文中的表述建議:
“本文采用灰色關聯分析方法,通過構建標準化數據序列與參考序列,計算各評價對象與參考對象的灰色關聯系數及關聯度,根據關聯度大小對評價對象進行優劣排序或因素重要性分析,從而為決策提供依據。”
2-理論知識
介紹

定義


應用
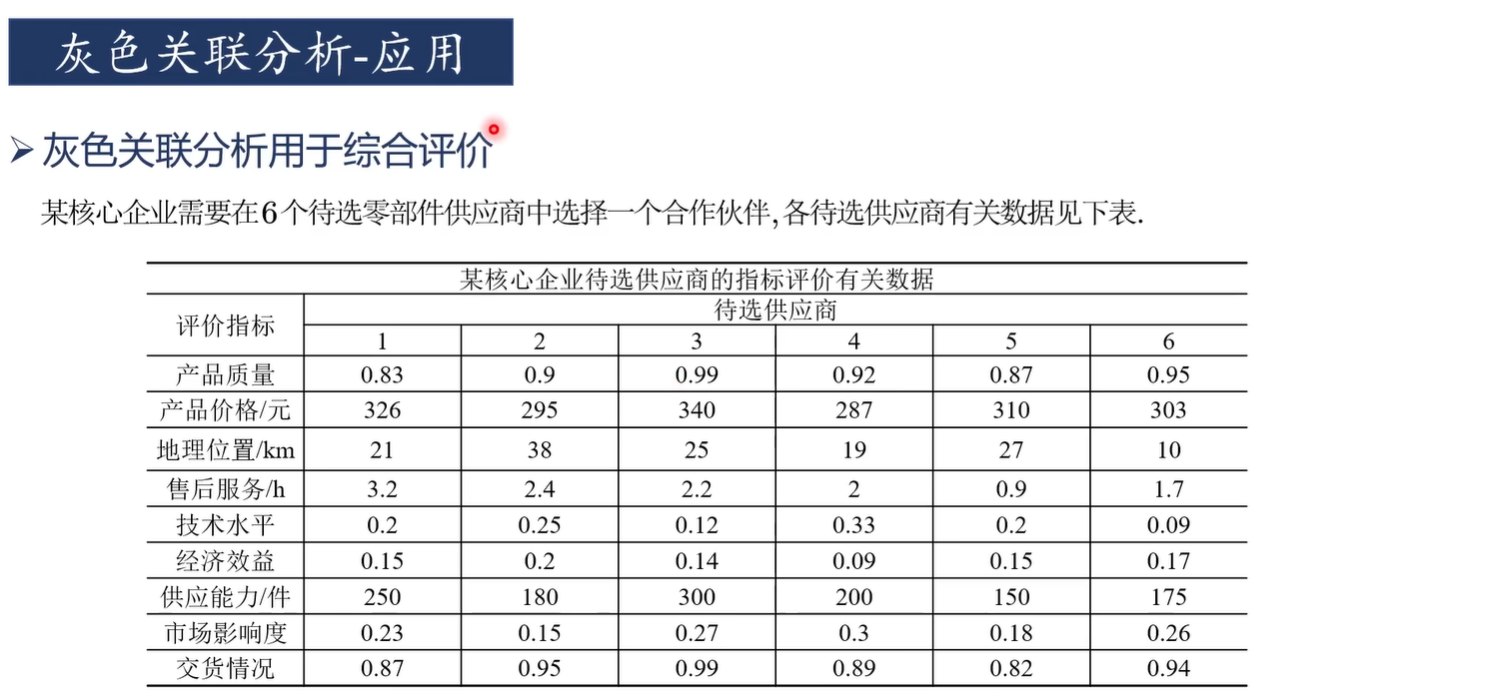
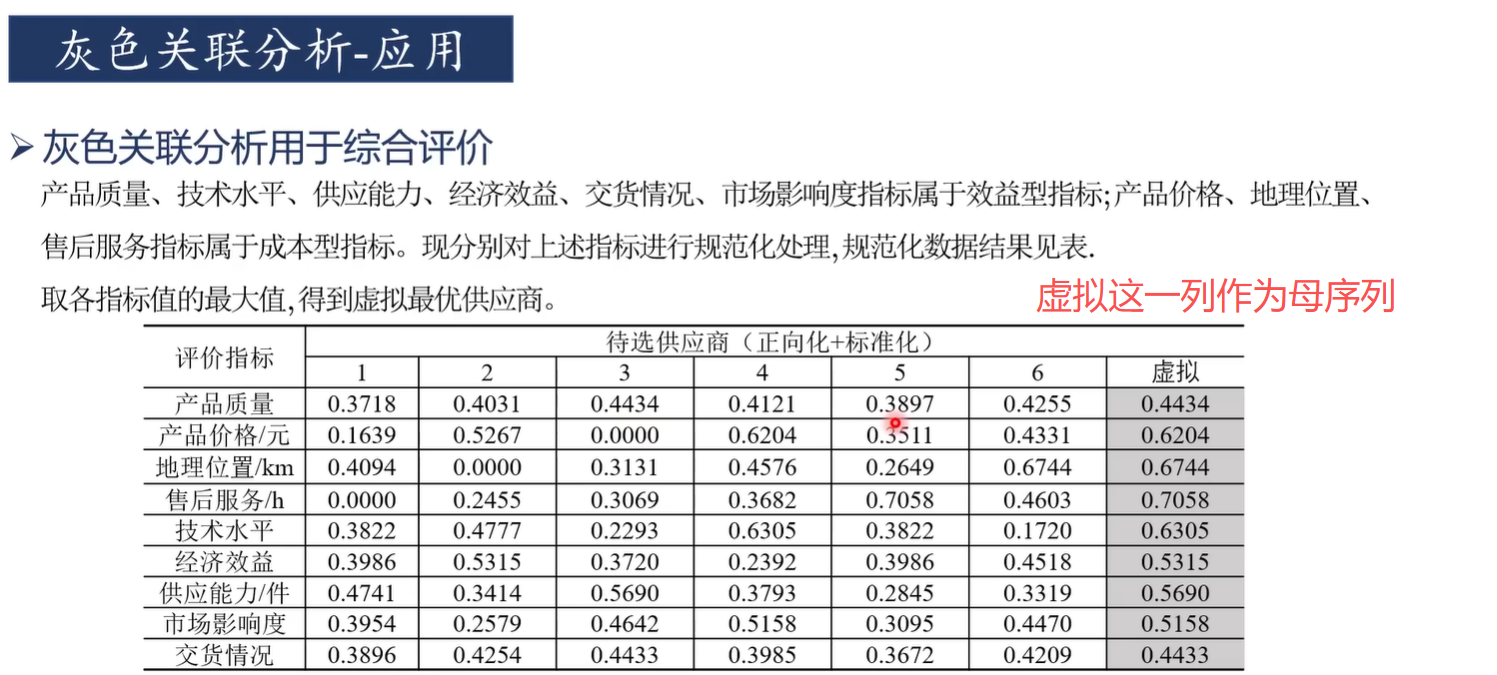
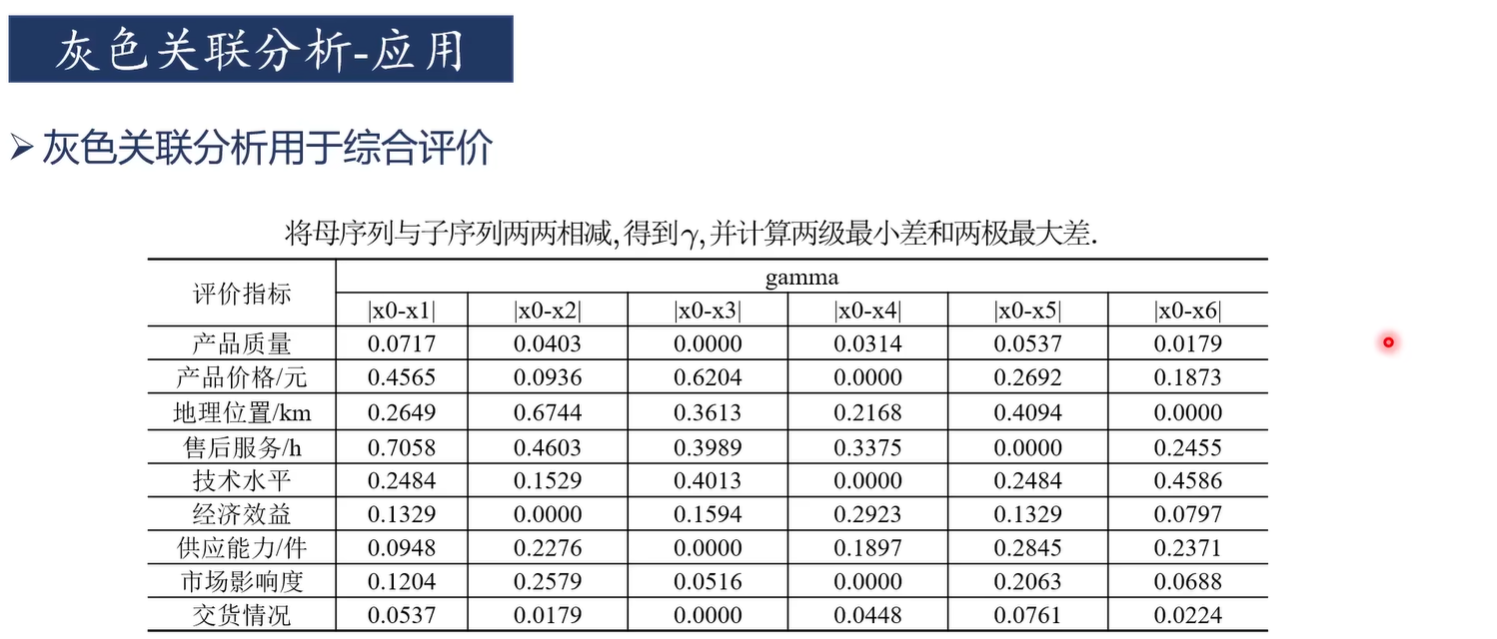
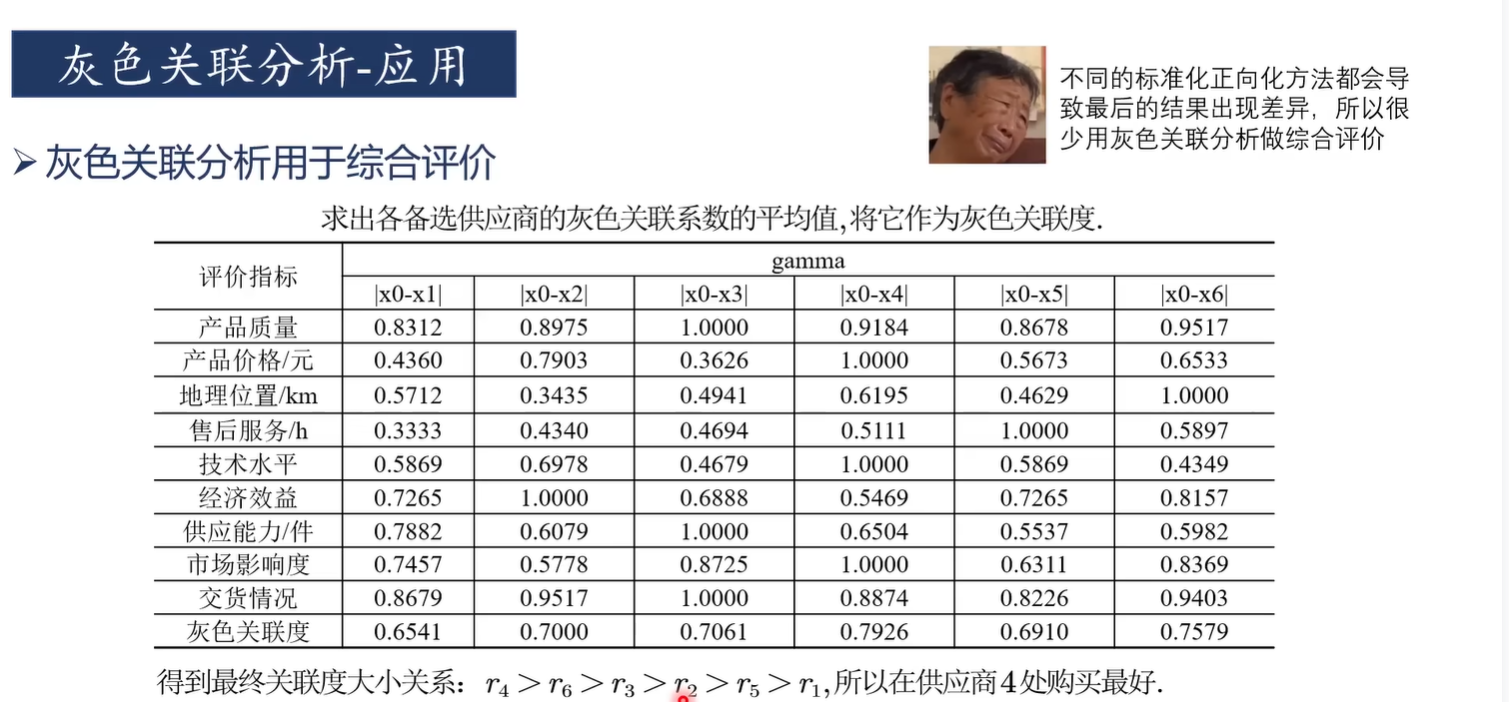
灰色關聯分析適合于判斷"對于因變量而言,哪些自變量是主要因素,哪些自變量是次要因素"
3-基于excel表格實現灰色關聯分析
1)寫入數據
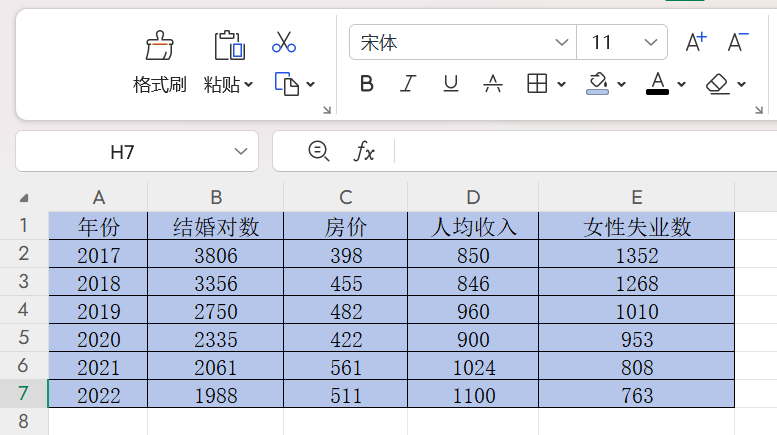
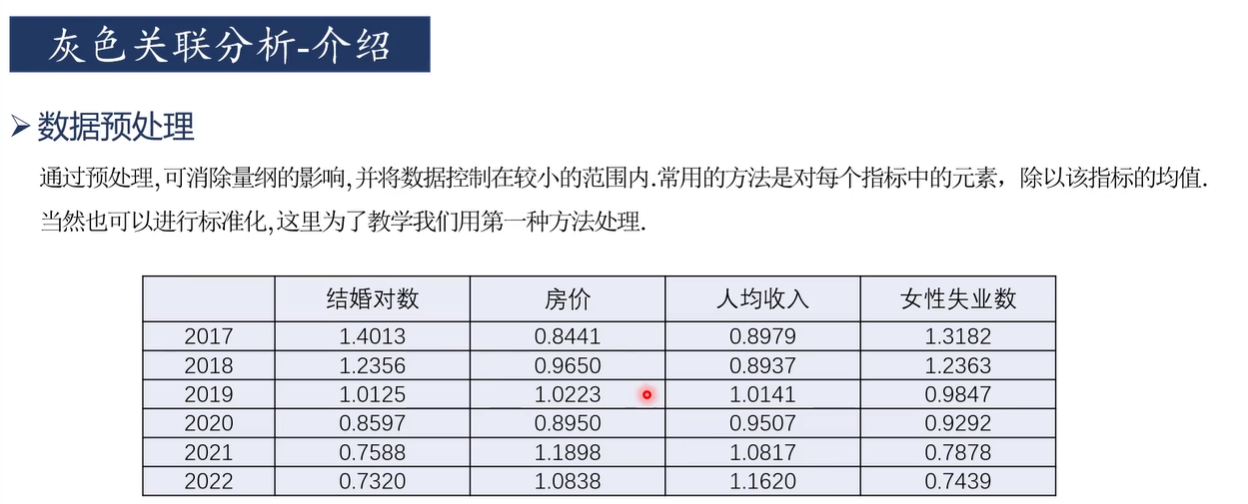
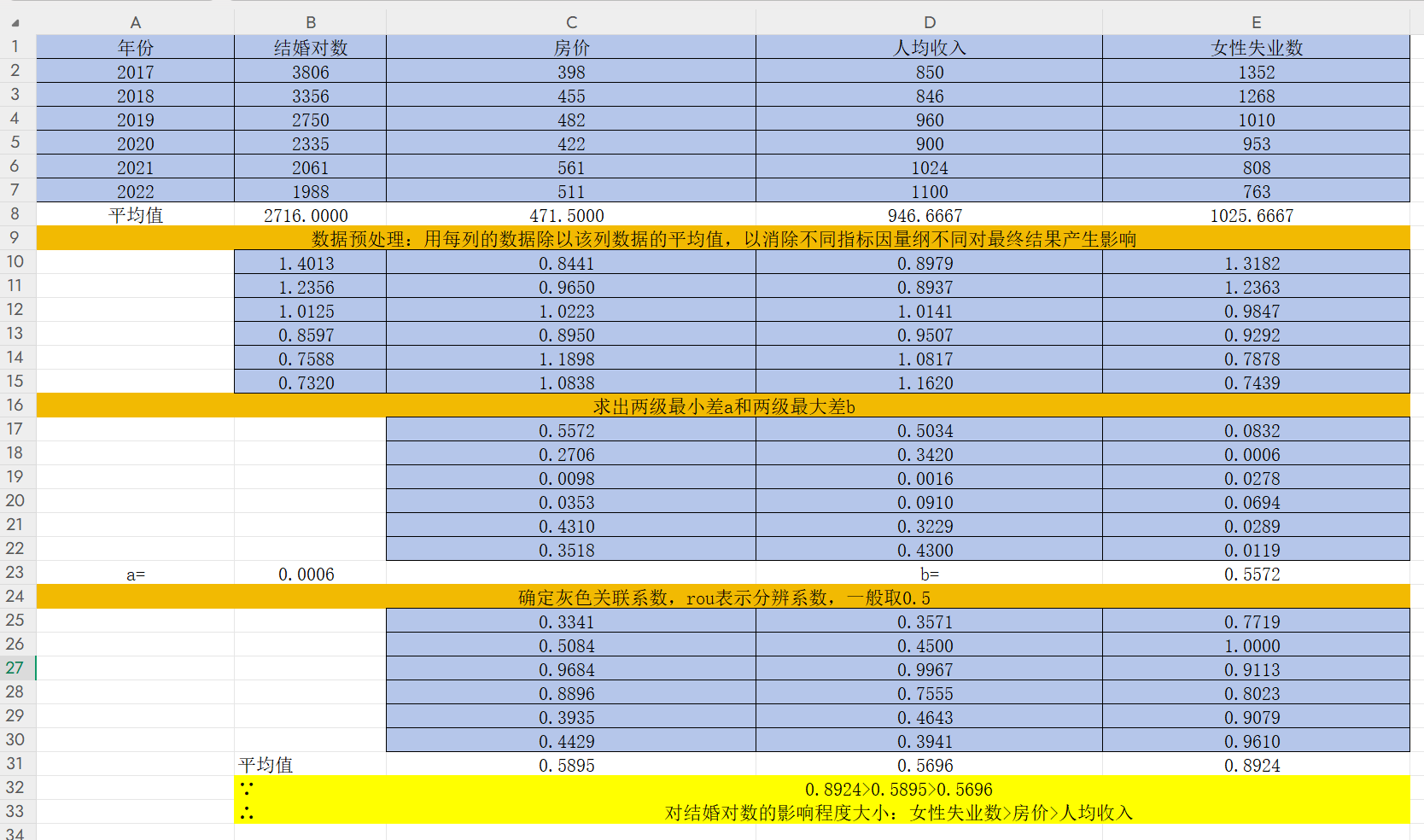
2)數據預處理
第一步,先求出平均值
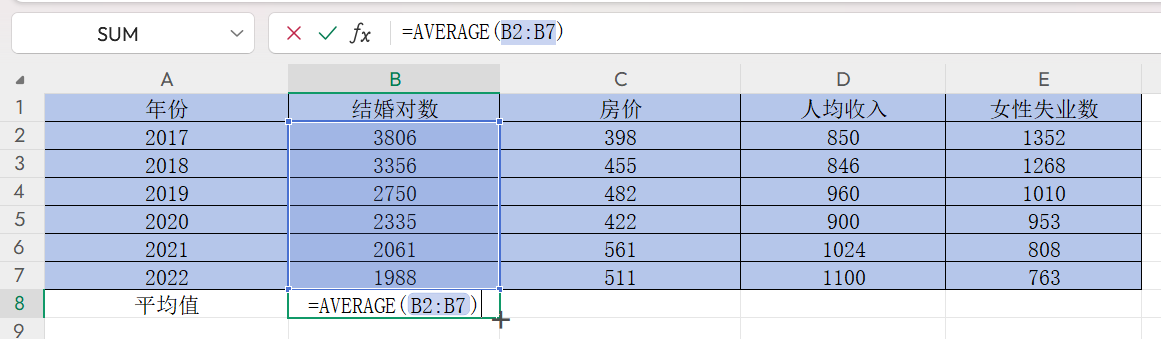
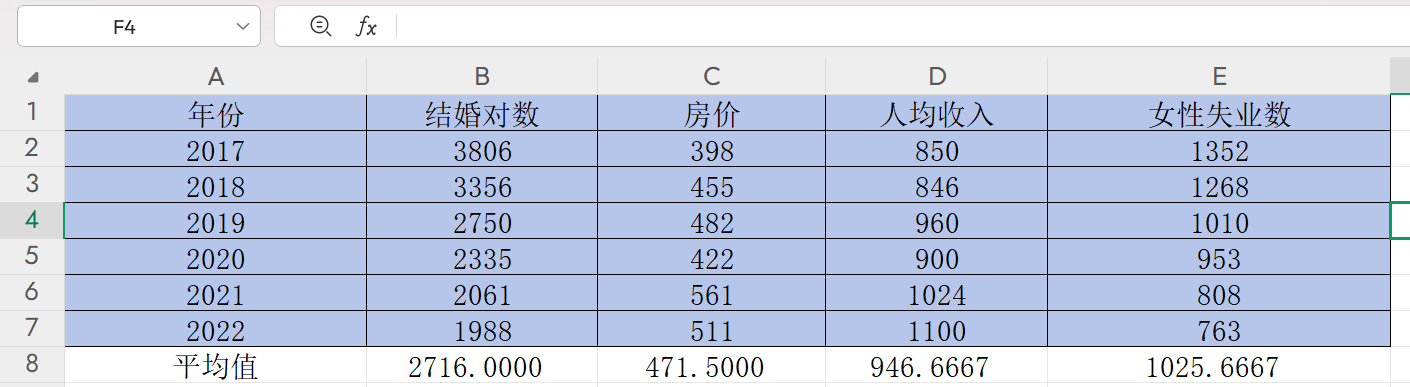
在B8單元格雙擊輸入“=”,輸入求平均數公式AVERAGE,選中B2:B7并回車得到結婚對數平均值
然后點擊右下角的黑色“+”,往右邊拖到E8,按回車,即可獲得另外三列的平均值,如下
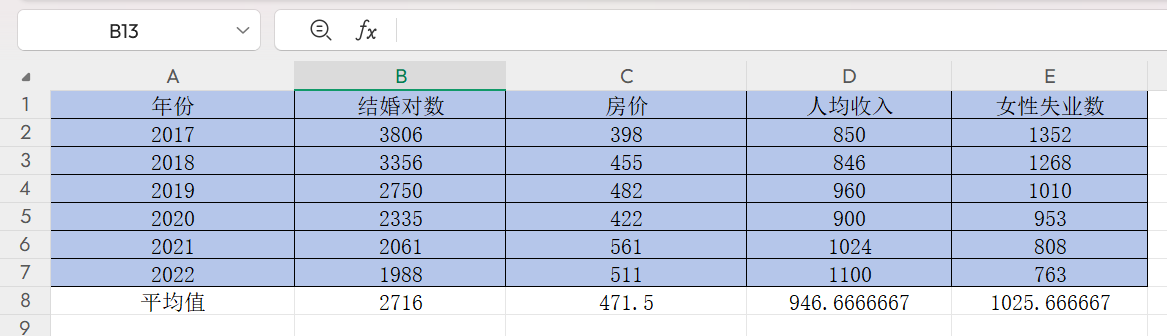
可以點擊下面這個地方,改變小數位數
選中B8,C8,D8,E8,點擊![]() ,增加或減少單元格中數值的小數位數
,增加或減少單元格中數值的小數位數
這里我們保留小數點后4位
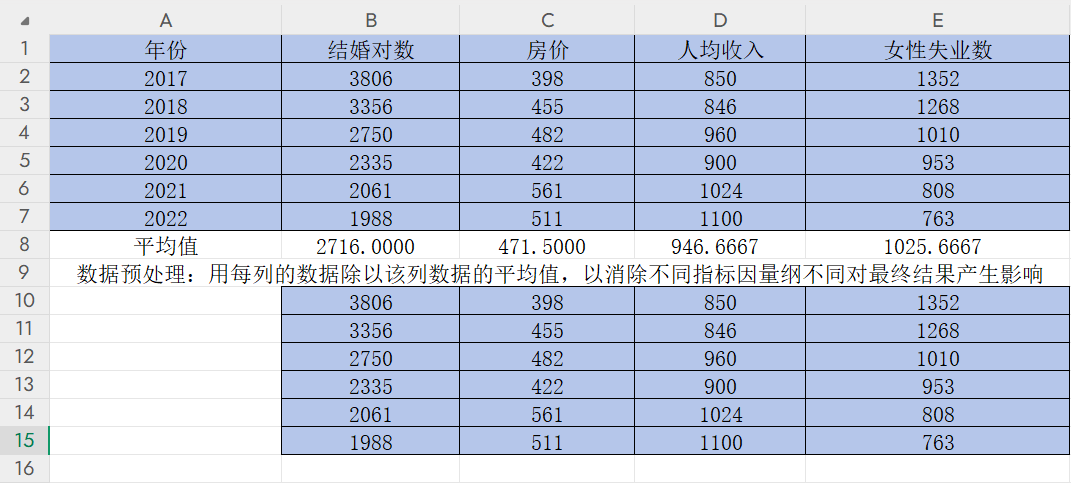
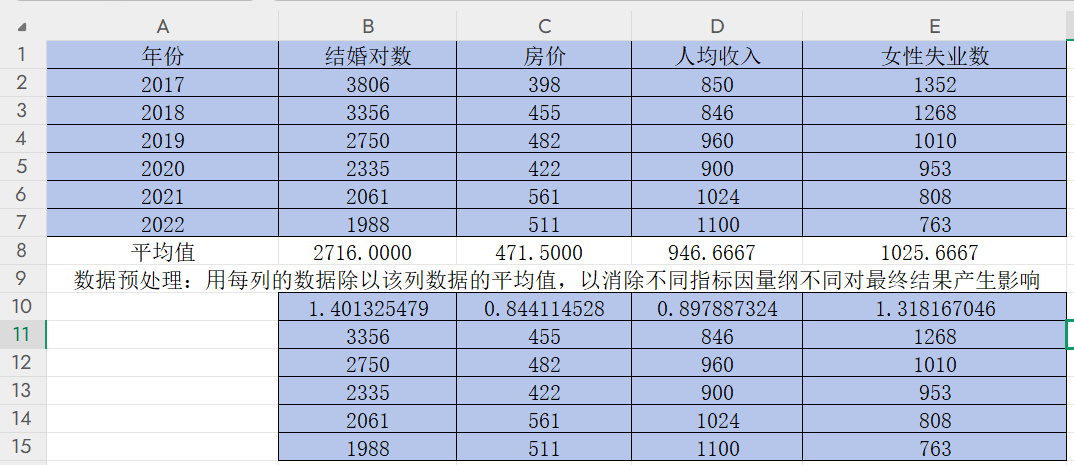
第二步,用每列的數據除以該列數據的平均值,以消除不同指標因量綱不同最終產生的影響
先復制一份上述表格數據
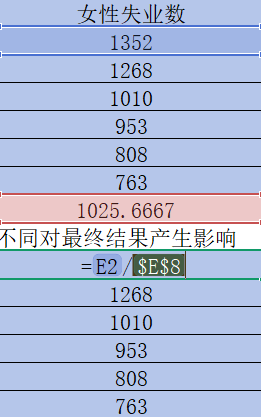
在B10雙擊單元格輸入“=B2/B8”,回車得到B2/B8的值
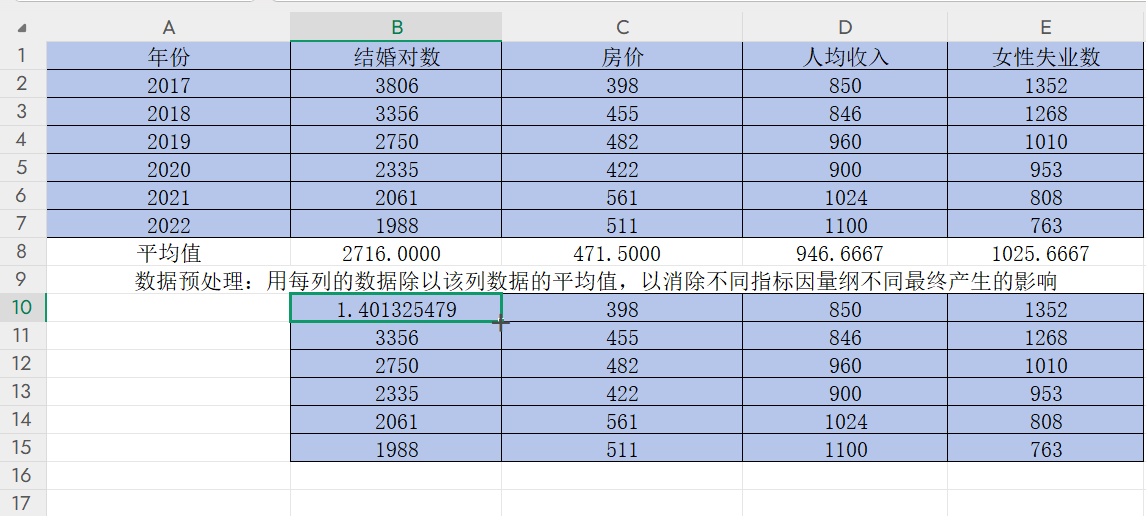
按住B10右下角的“+”并往右拉,得到該年份其他指標數據除以該指標平均值的結果
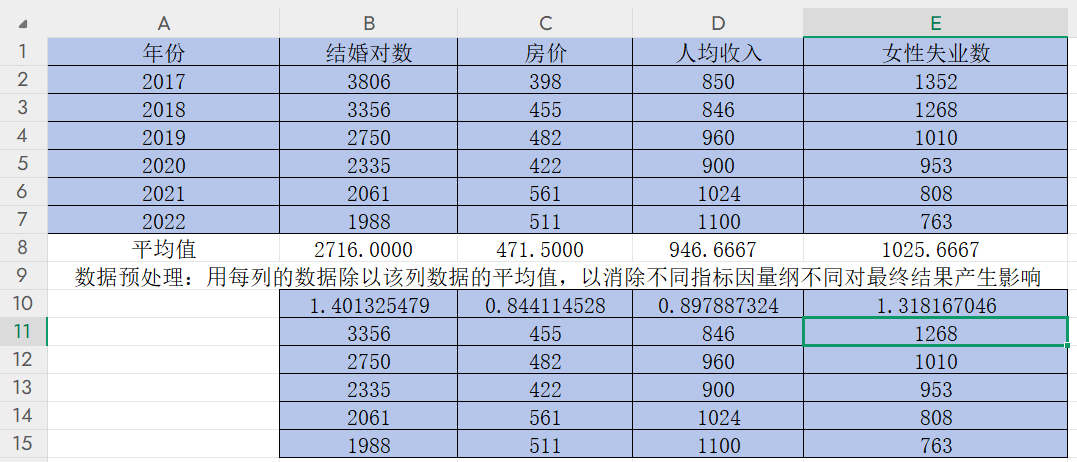
雙擊B10,C10,D10,E10單元格,在分母B8,C8,D8,E8中間依次按F4,固定住分母,回車
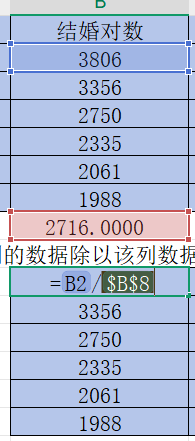
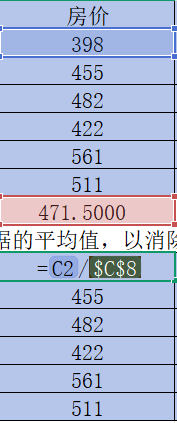
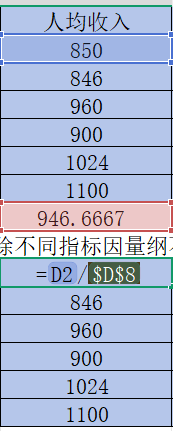
按住B10,C10,D10,E10每個單元格右下角的“+”并往下拉
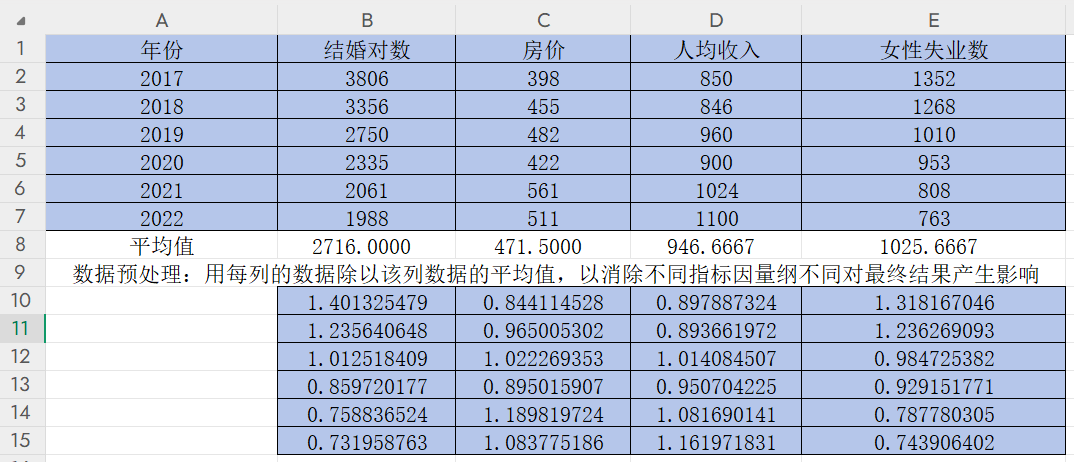
然后和上面一樣改變小數位數,這樣可以得到該年份其他指標數據除以該指標平均值后的結果
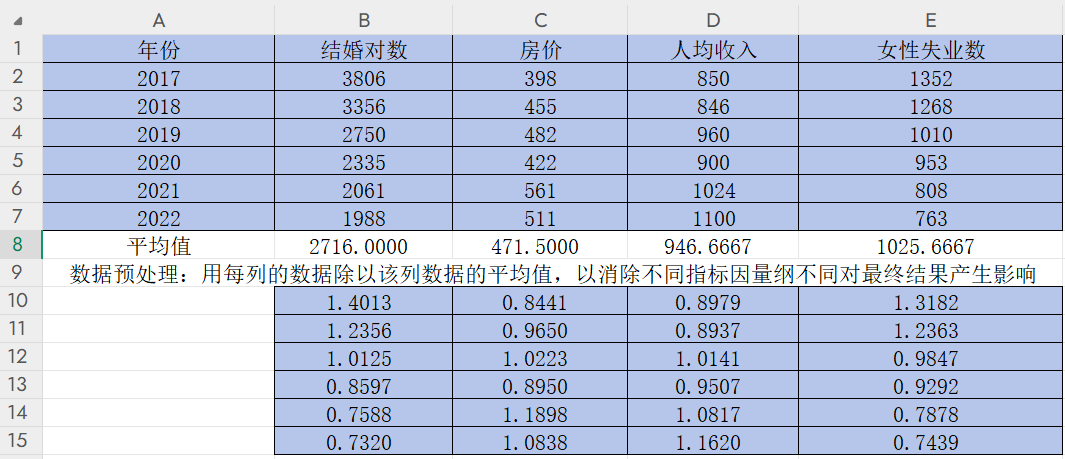
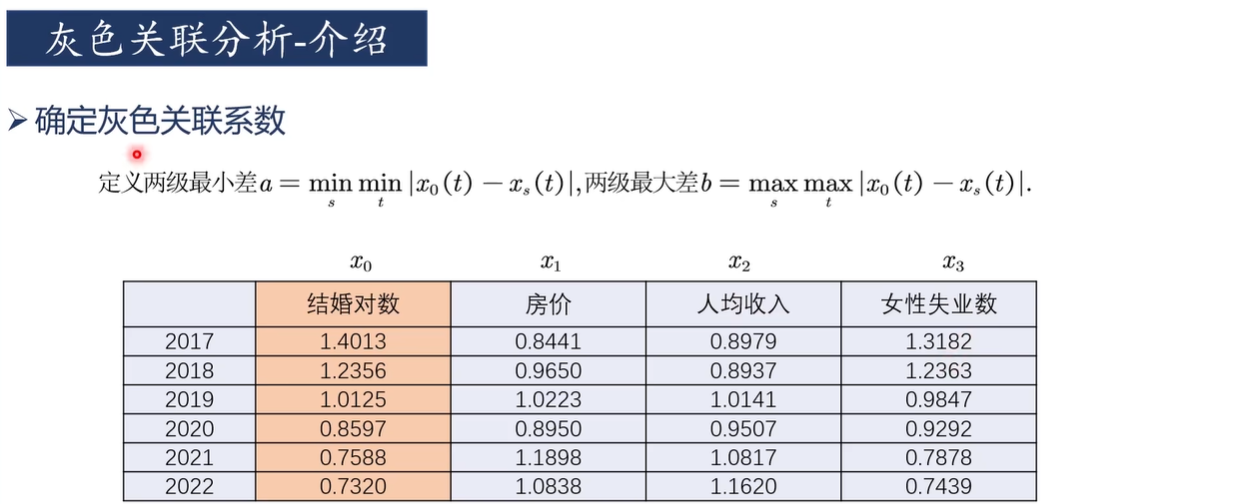
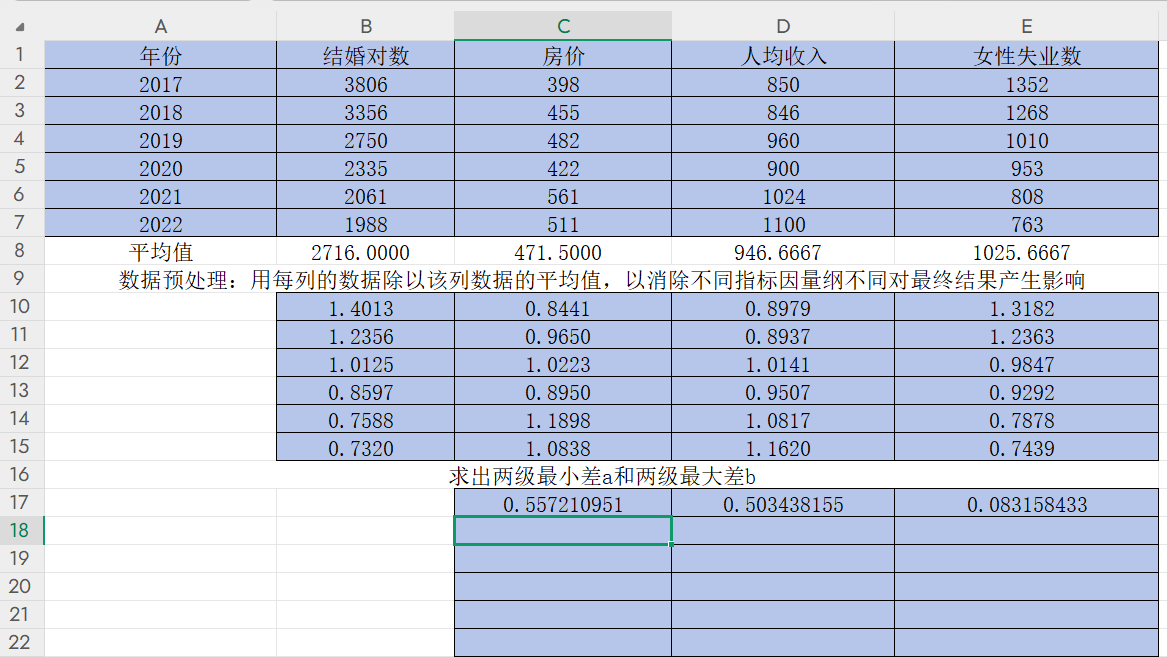
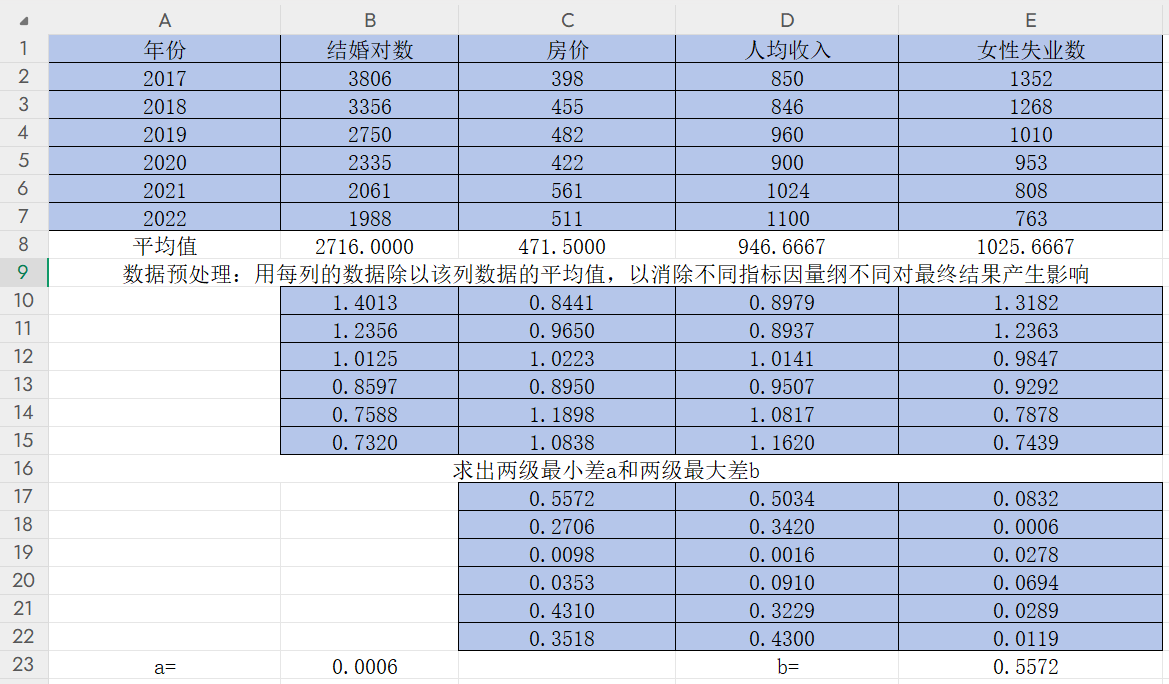
3)求出兩級最小差和兩級最大差
雙擊單元格C17,輸入“=ABS(B10-C10)”,并在B和10之間按F4,固定住母序列(結婚對數)
回車得到(B10-C10)的絕對值
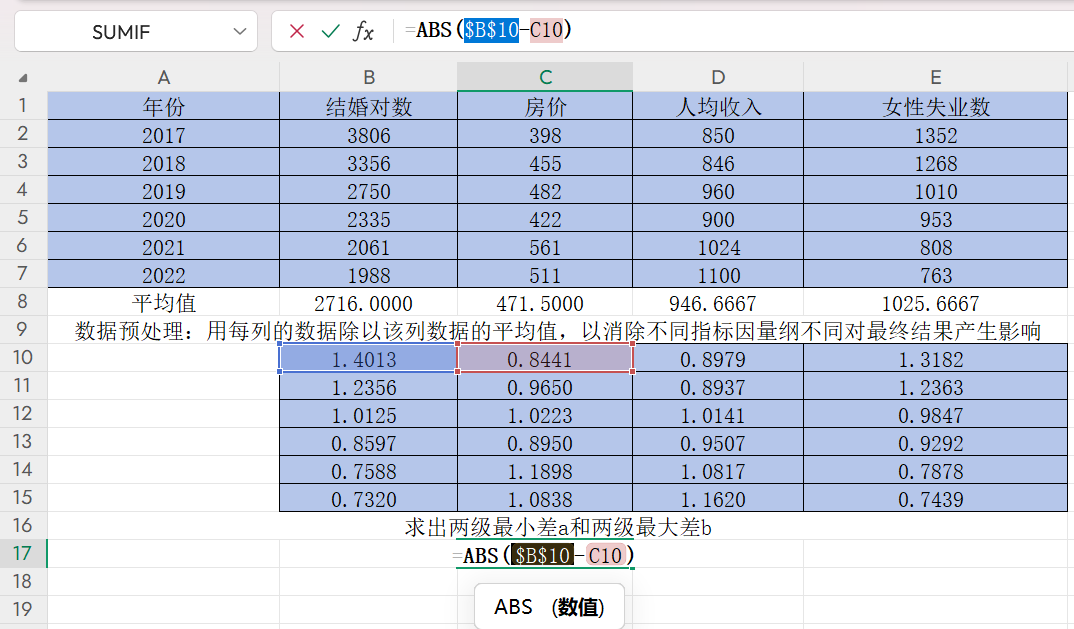
然后按住右下角的“+”往右拉
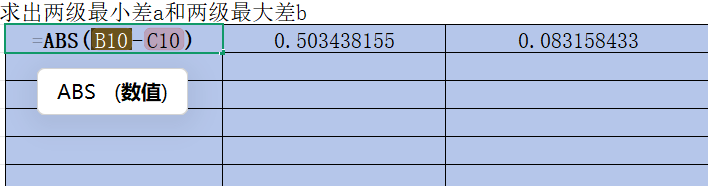
雙擊單元格C17,D17,E17,對分子再按幾次F4直到沒有"$"符號,即不固定任何一列

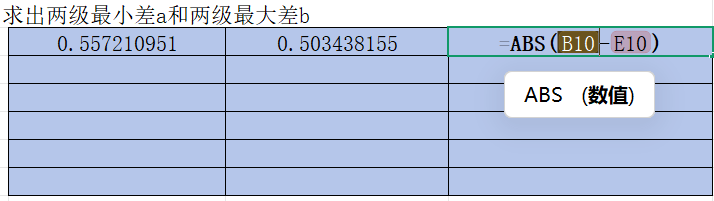
再點C17,D17,E17右下角的“+”往下拉
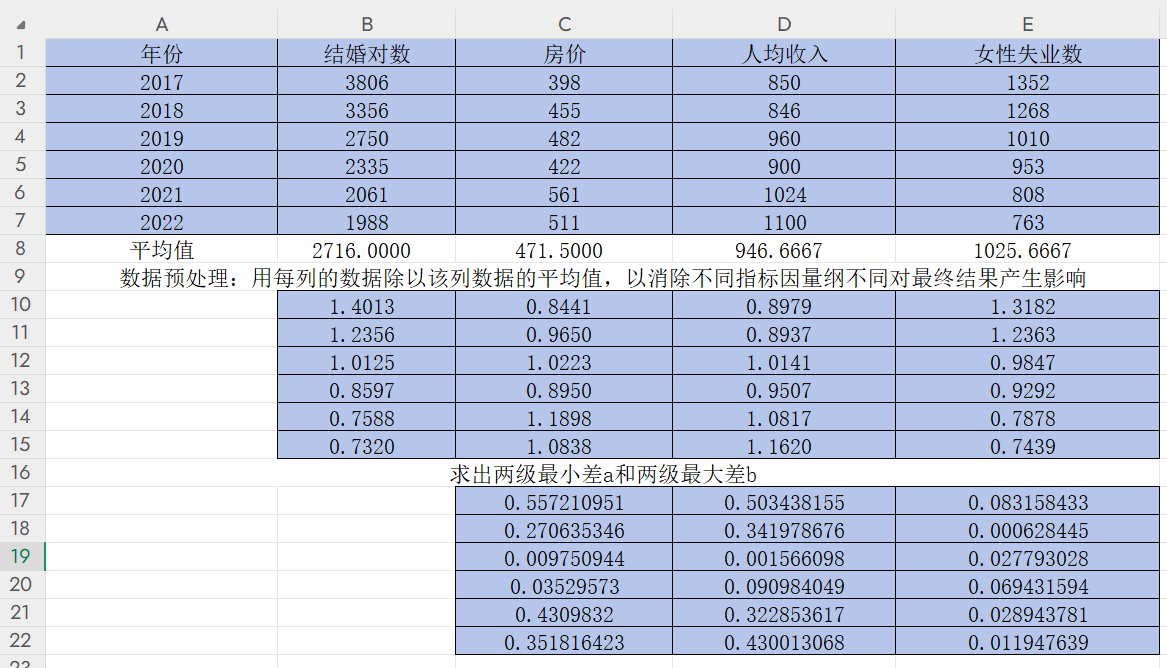
然后改變小數點位數
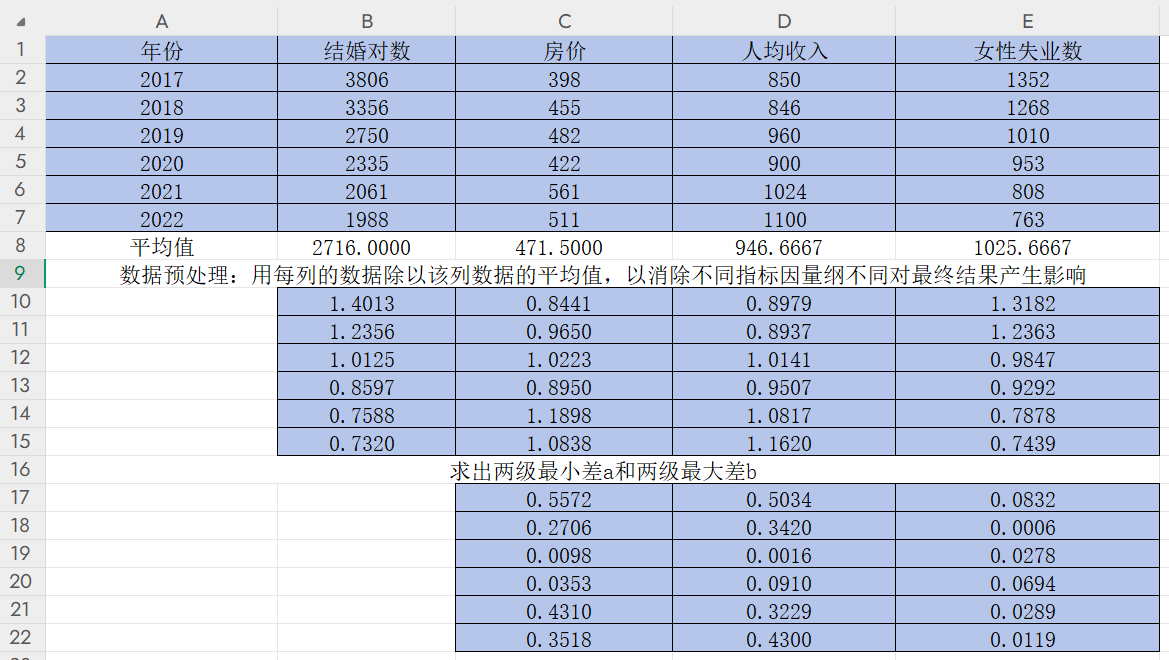
求出兩級最小差a和兩級最大差b,即找出CDE三列,17-22行數據中的最值
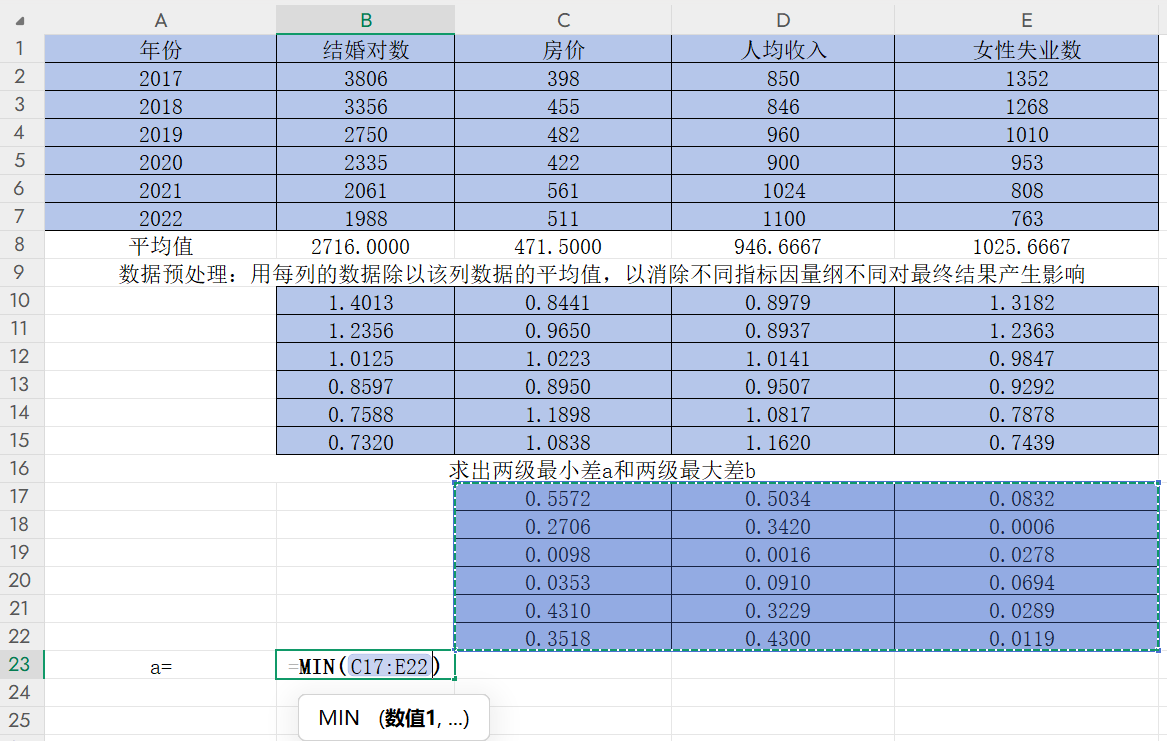
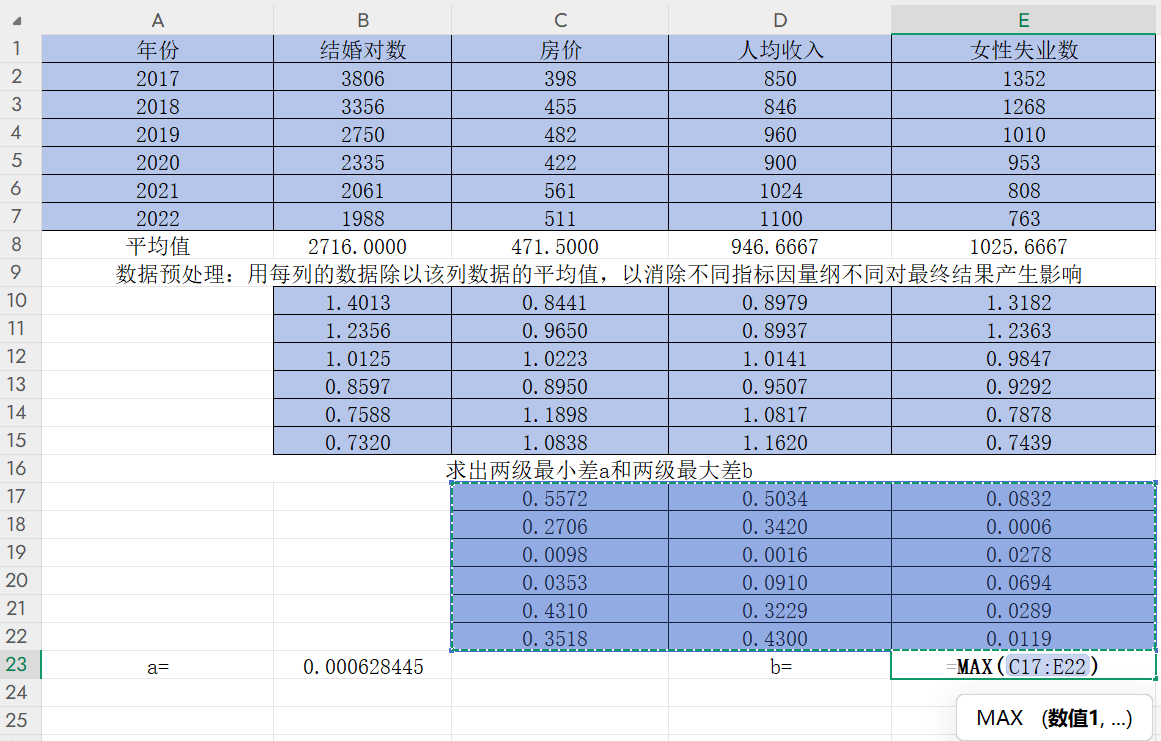
回車后再改變小數位數得到a=0.0006和b=0.5572
4)確定灰色關聯系數Gamma
計算公式
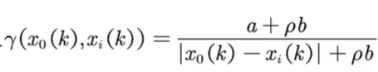
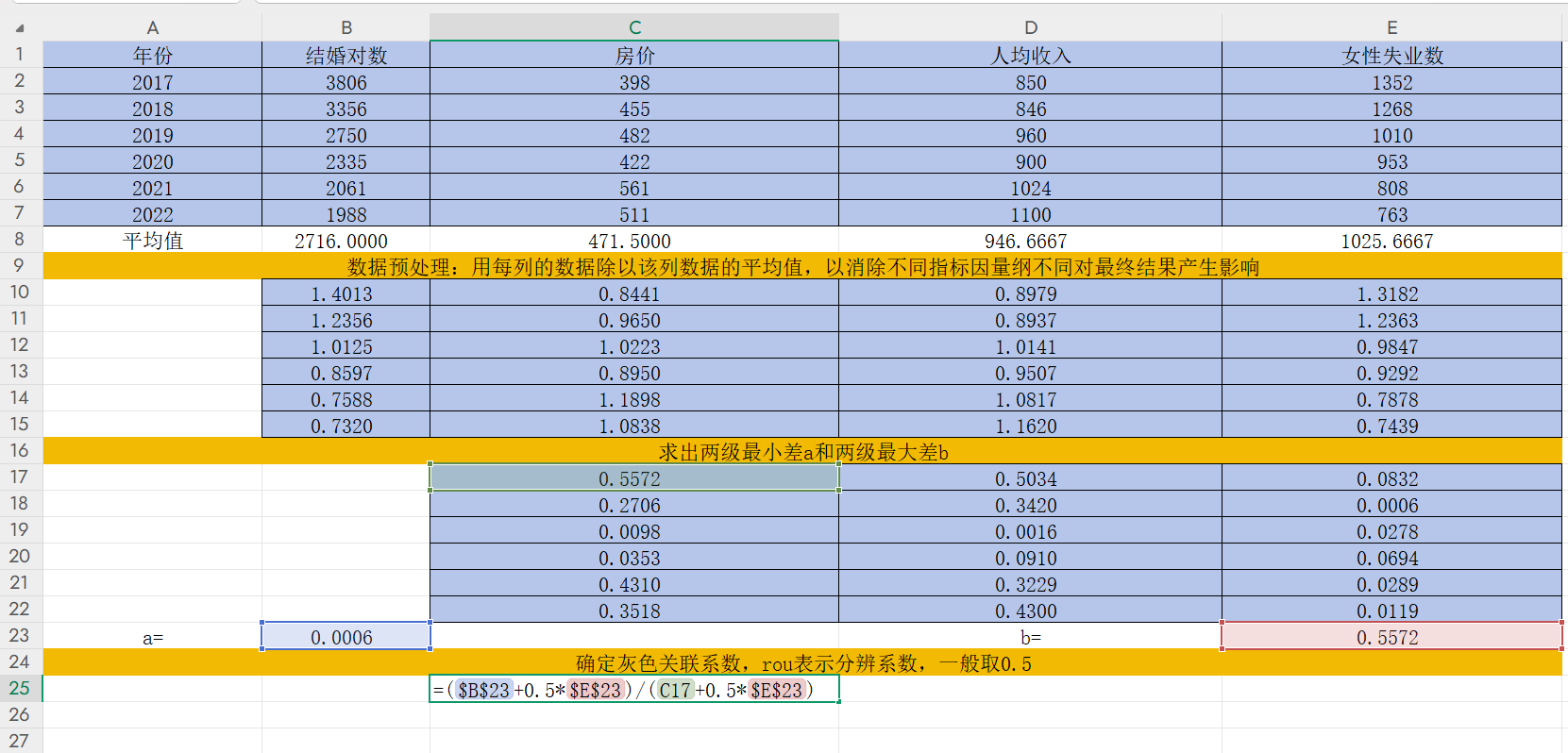
雙擊單元格C25輸入"=($B$23+0.5*$E$23)/(C17+0.5*$E$23)"后回車
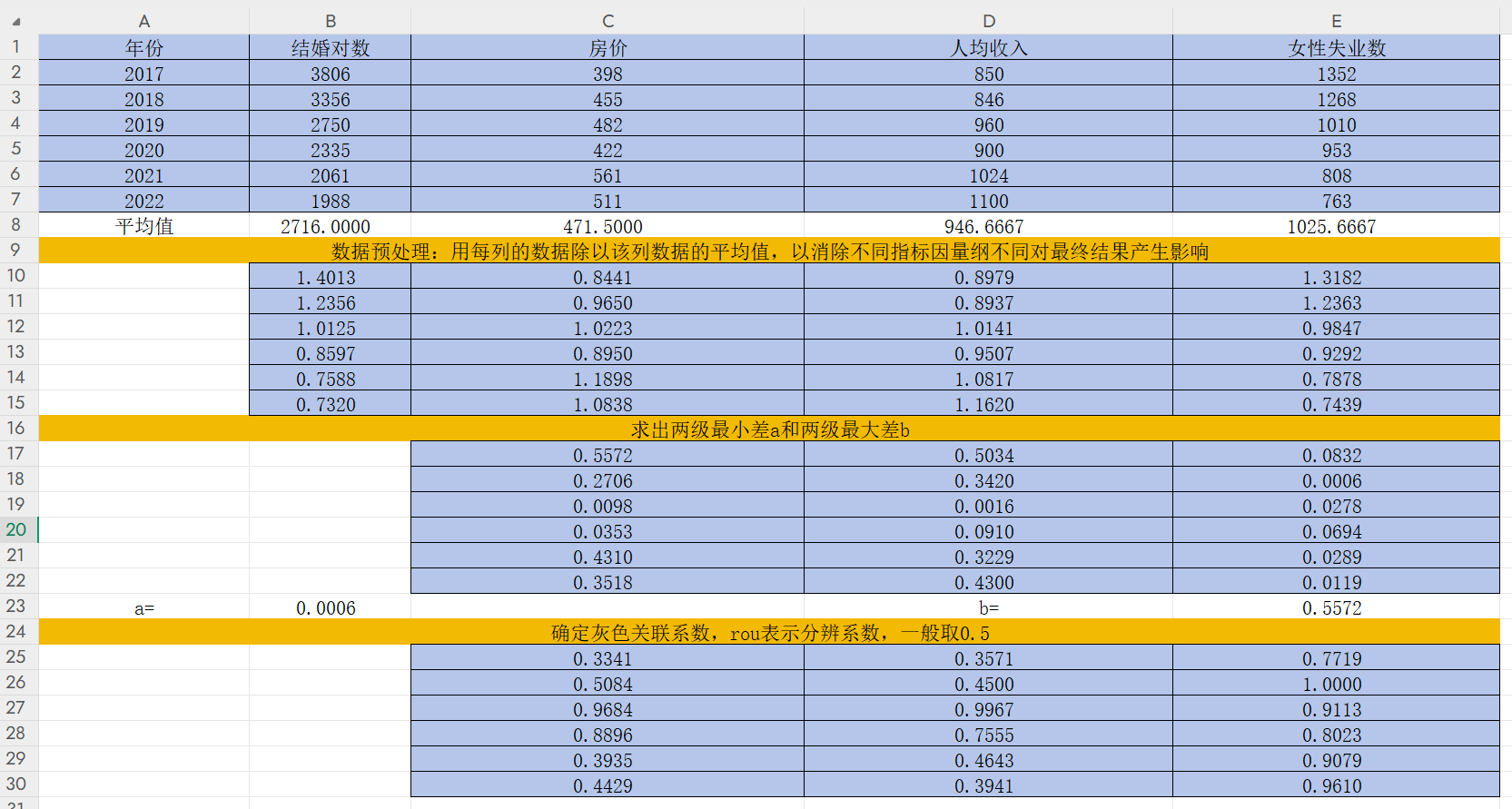
按住C25右下角的“+”往右拉2格,往下拉5格,然后改變小數位數
5)求每個指標的灰色關聯系數的平均值
雙擊單元格C31輸入“=AVERAGE(C25:C30)”后回車得到房價灰色關聯系數平均值

然后往右拉兩個得到人均收入和女性失業數的灰色關聯系數平均值
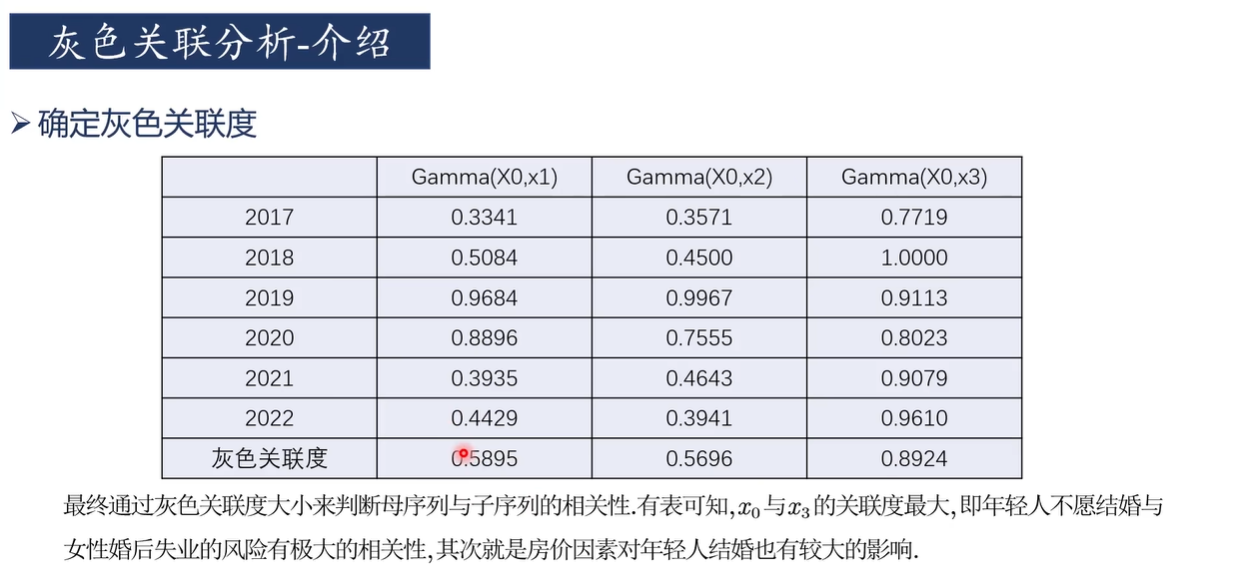
再進行排序得到最終結論:女性失業數是影響結婚對數的主要因素


基本控件應用)






)



之 文章向量搜索——仙盟創夢IDE)





