
一、概念
1、Hive
Apache Hive 是一個分布式的容錯數據倉庫系統,可實現大規模分析和便于使用 SQL 讀取、寫入和管理駐留在分布式存儲中的PB級數據。
Hive是建立在Hadoop之上的數據倉庫框架,它提供了一種類SQL的查詢語言—HiveQL,使得熟悉SQL的用戶能夠在Hadoop上進行數據查詢和分析。
2、Hive Metastore

Hive Metastore(HMS)是Apache Hive的一個組件,它提供了一個中央存儲庫,用于存儲有關Hive表和分區的元數據。這些元數據包括表的結構信息、數據類型、列和表之間的關系以及數據存儲的位置等信息。Hive Metastore是許多數據湖架構的關鍵組成部分,因為它允許客戶端(包括Hive、Impala和Spark)使用metastore服務API訪問這些信息。
Hive Metastore的架構相對簡單,通常包括一個關系型數據庫(如MySQL、Postgres或Derby)來存儲元數據,以及一個Thrift服務,允許客戶端通過網絡訪問這些元數據。盡管它的名字中包含“Hive”,但實際上Hive Metastore與Hive是獨立的,可以與其他系統(如Apache Spark和Presto)一起使用。
二、原理

Hive是一個建立在Hadoop之上的數據倉庫工具,它將SQL查詢轉換成MapReduce任務來執行。這是因為Hive的設計目的是讓熟悉SQL的用戶能夠在Hadoop平臺上進行數據分析,而不需要直接編寫復雜的MapReduce代碼。Hive的工作原理與MapReduce的關系可以概括為以下幾點:
- 查詢轉換:當用戶在Hive中執行一個查詢時,Hive將這個查詢轉換成一個或多個MapReduce任務。
- 執行計劃:Hive的編譯器將SQL語句轉換成一個執行計劃,這個計劃描述了如何將查詢分解成MapReduce的Map和Reduce階段。
- 任務執行:Hive將這些MapReduce任務提交給Hadoop集群執行。Map階段處理輸入數據,生成中間結果;Reduce階段則對這些中間結果進行匯總和處理,以產生最終結果。
- 結果返回:一旦MapReduce任務完成,Hive將處理結果返回給用戶。
這種設計使得Hive能夠利用Hadoop的分布式計算能力來處理大規模數據集,同時為用戶提供了一個更為熟悉和易于使用的SQL接口。然而,這也意味著Hive的查詢性能受限于MapReduce的性能,因此在需要快速響應的場景下可能不是最佳選擇。
三、優缺點
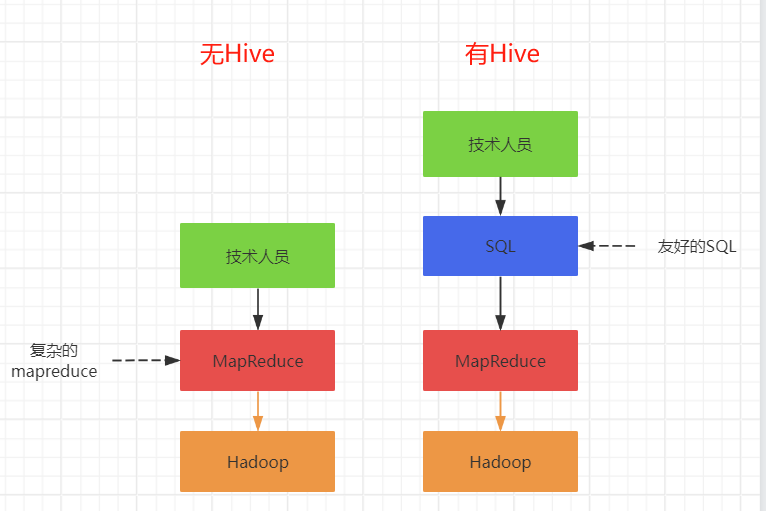
Hive的優缺點如下:
優點:
- 易于使用:提供類SQL查詢語言,減少學習成本。
- 海量數據分析:底層基于MapReduce,適合處理大規模數據集。
- 可擴展性:可以自由擴展集群規模,具有良好的容錯性。
- 自定義函數:支持用戶根據需求實現自定義函數。
缺點:
- 效率問題:Hive生成的MapReduce作業通常不夠智能化,執行延遲較高。
- 表達能力限制:HiveQL的表達能力有限,不擅長迭代式算法和數據挖掘。
- 不支持實時查詢:由于MapReduce任務啟動需要時間,Hive不適合實時數據查詢。




)


)








)
(以Modbus通信為例))

