前言
當我們談論關于APP用戶分析與電子商務之間的聯系時,機器學習在這兩個領域的應用變得至關重要。App用戶分析和電子商務之間存在著密切的關聯,因為用戶行為和偏好的深入理解對于提高用戶體驗、增加銷售以及優化產品功能至關重要。故本文基于K-近鄰模型、貝葉斯模型和自適應提升模型對:基于已爬取的APP數據(例如:APP類型、APP安裝人數、APP評論內容等等)的分析來預測該APP是否為一個好的APP。
數據介紹與預處理
從前,手機app少,但經典,現在,app多了,但混雜(多仿品),有很多因素影響用戶去下載app,評分就是很重要的參考。那么問題來了:在無法參透某平臺app評分算法的奧義之前,能否預測一下app的評分呢(簡化之,app好評是1,差評為0)?
train.csv:訓練集,7728 rows × 10 columns, 列屬性包含:App, Category, Reviews, Size, Installs(安裝量), Type, Price, ContentRating(評論的人員), Last Updated(上次更新的日期), Y(是否為好評,1為好評,0為非好評), 行為7728個APP樣本。
首先導入數據分析必要的包:



隨后通過發現有的特征數據格式或者單位沒有統一,特征變量全部為object,故要做進一步處理。
針對“Size”變量的單位不統一的原因,故定義一個條件判斷函數,將其單位統一:

觀察變量,繼續進行預處理:

處理完成之后再次查看數據情況:

隨后進行描述性統計分析

從上圖中可以看出,對于訓練集的和測試集描述性統計,對各個特征變量的計數、均值、標準差、最大最小值,以及分位數均進行了展示。
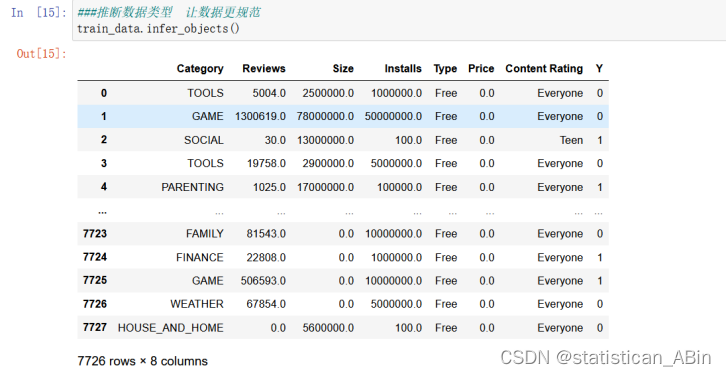
隨后推斷數據類型,讓數據更規范以及查看數據的基礎信息,結果如下(仍是以訓練數據集為例),這一步是為了對特征分析和模型建立作準備。
接下來對數據缺失值進行確認,首先導入缺失值可視化missingno包,該包可以很直觀的看出每個特征的缺失程度,故可以很好的對特征進行篩選,可視化結果如下,在每個特征中白色越多就表明數據越缺失。由于在上文中在進行了數據缺失值的處理,故在下面的可視化中只是更直觀的確認一下訓練集和測試集(測試集在此不作展示)中是否還有缺失值的存在。

然后需要對數據進一步細化處理,要把數據分為數值型和其他類型來看。分布進行處理,例如對于分類型變量,則通過獨熱編碼進行處理。
首先查看數值型變量數據:

 填充缺失值,缺失值有很多填充方式,可以用中位數,均值,眾數。也可以就采用那一行前面一個或者后面一個有效值去填充空的。
填充缺失值,缺失值有很多填充方式,可以用中位數,均值,眾數。也可以就采用那一行前面一個或者后面一個有效值去填充空的。
 通過探索性數據分析,我們對字符類型特征值與數字類型特征值與Y的關系有了較深的了解,同時觀察到投資收入與投資損失的數據特征,因此在進行模型構造前,首先需要對特征值進行一定的處理以實現機器學習算法的高效利用。
通過探索性數據分析,我們對字符類型特征值與數字類型特征值與Y的關系有了較深的了解,同時觀察到投資收入與投資損失的數據特征,因此在進行模型構造前,首先需要對特征值進行一定的處理以實現機器學習算法的高效利用。
在處理完特征變量之后,對響應變量的分布也要考察,若存在異常值的情況也會對模型的泛化能力有影響,在此畫出響應變量的箱線圖、直方圖和和核密度圖,如下圖:

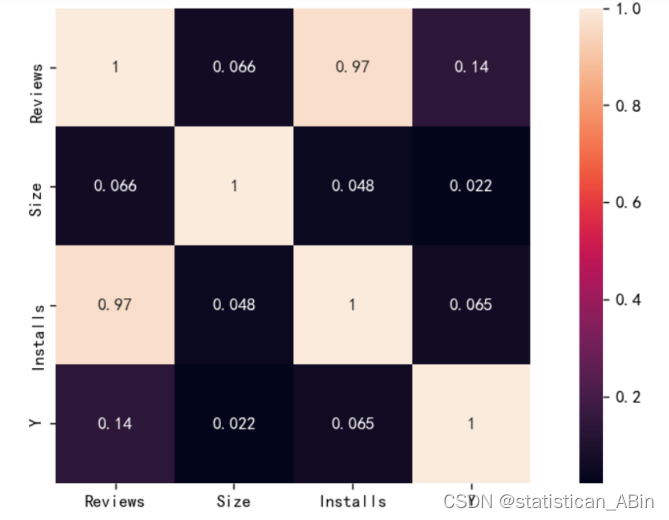
隨后對特征變量進行相關系數的計算以及熱力圖的展示,如下圖:
機器學習預測

選取數據集的80%為訓練集,20%為測試集進行下一步的預測與檢驗,為了保證程序每次運行都分割一樣的訓練集和測試集,設置random_state為0。


結論
本文基于探索性數據分析對APP評分的預測問題進行數據加載、數據清洗以及數據可視化操作。其中預處理包括處理數據的格式問題,以及統一數據的單位,填充數據的缺失值問題,通過數據預處理工作之后,整體數據變為較為整潔。上述數據分析完成了機器學習中的數據預處理部分,數據分析所得結論具有應用意義。....
部分代碼
?
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #負號df=pd.read_csv('train.csv')
df.head()
df.info()df=df.fillna(method='pad') #前一個有效值進行填充
df.loc[df[df['Type']=='0'].index,'Type']=df['Type'].mode() #異常值使用眾數填充def check(x):if "M" in str(x):x = float(str(x).replace("M", "")) * 1000000elif "K" in str(x):x = float(str(x).replace("K", "")) * 1000elif "k" in str(x):x = float(str(x).replace("k", "")) * 1000elif "Varies with device" in str(x):x = 0else:return float(x)return x/1000y.value_counts(normalize=True)# 查看y的分布
#分類問題
plt.figure(figsize=(4,2),dpi=128)
plt.subplot(1,2,1)
y.value_counts().plot.bar(title='響應變量柱狀圖圖')
plt.subplot(1,2,2)
y.value_counts().plot.pie(title='響應變量餅圖')
plt.tight_layout()
plt.show()#查看特征變量的箱線圖分布
dis_cols = 3 #一行幾個
dis_rows = 2
plt.figure(figsize=(3*dis_cols, 2*dis_rows),dpi=128)
for i in range(5):plt.subplot(dis_rows,dis_cols,i+1)sns.kdeplot(X[X.columns[i]], color="tomato" ,shade=True)#plt.xlabel((y.unique().tolist()),fontsize=12)plt.ylabel(df.columns[i], fontsize=18)
plt.tight_layout()
plt.show()#貝葉斯
model1 = BernoulliNB(alpha=1)
#K近鄰
model2 = DecisionTreeClassifier()
#自適應提升Adaboost
model3 = RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=123)model_list=[model1,model2,model3]
model_name=['二項樸素貝葉斯(伯努利)','決策樹','隨機森林']數據和代碼
數據代碼和分析報告
創作不易,希望大家多多點贊收藏和評論!
使用AXI-Stream FIFO進行跨時鐘(含代碼))



)


數據技術篇之數據同步)

)
![[JDK工具-6] jmap java內存映射工具](http://pic.xiahunao.cn/[JDK工具-6] jmap java內存映射工具)







的使用)
