在平時的操作中,經常使用count進行操作,計算統計的數據。那么具體的原理是如何的?為什么有時候執行count很慢。
count的實現方式
select count(*) from student;
對于MyISAM引擎來說,會把一個表的總行數存儲在磁盤上,因此執行count(*)的時候直接返回,效率高。
但是對于InnoDB引擎來說,執行count ()的時候,需要把數據一行一行從引擎中讀出來,然后累積計數。
但是因為InnoDB支持事務以及并發能力,所以大多數業務都選擇是InnoDB存儲引擎。
為什么數據越來越多的時候,InnoDB不存儲一個總行數直接返回呢,那么因為在不同的隔離級別下,每個事務所看到的數據是不一樣的。
比如針對如下,開啟三個會話,因為MVCC的原因,返回的行數是不一樣的。

會話A:因為當前開始一個事務,回話B、C對于A是不可見的。所以返回1W
會話B:會話C插入一行自動提交,所以當會話B自己在插入一條數據的時候,可以查到2條記錄,所以就是10002行。
會話C:因為會話B沒有提交事務,所以只能看到自己本次的新增記錄,所以就是10001行。
根本原因在于:和InnoDB的事務設計有關系,通過多版本并發控制,每一行記錄需要判斷對自己是否可見,所以只能一行行判斷
做的一點優化
主鍵索引樹保存的是數據,普通索引樹保存的是主鍵值,因此普通索引樹要比主鍵索引樹小很多,所以對于count(*) 來說,遍歷哪個樹結果都是一樣的,為了盡量減少掃描的數據量,會使用最小的那顆樹進行統計遍歷。
Count(主鍵)
在統計count函數多少記錄時,mysql的server層維護一個count的變量。每循環從innodb讀取一行記錄,并且count函數指定的參數不為null ,就將變量count+1。所以當一個表只有主鍵時,會從主鍵索引樹上進行查詢,當主鍵和普通索引都存在時,會從普通索引樹上進行查詢,因為這樣遍歷二級索引的IO成本比遍歷主鍵索引的IO成本小很多。因此優化器優先選擇的是二級索引。


Count(1)
select count(1) from t_order;
統計的是這個表里有多少記錄
count(id) 和 count(1)的 區別其實就是看是否讀取數據的記錄內容,count(1)因為是直接判斷1,所以只需要統計對應有多少記錄就可以,但是count(id) 需要獲取的行記錄的id 并且不為空 才會進行總數計算。
Count(*)
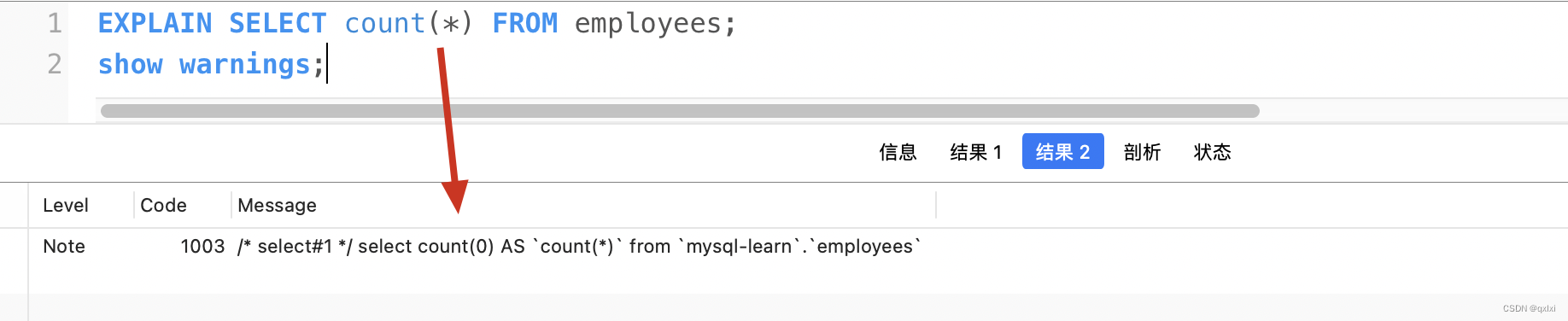
count(*) 其實mysql會將參數 轉換成0來處理
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
翻譯:InnoDB以相同的方式處理SELECT COUNT(*)和SELECT COUNT(1)操作,沒有性能差異。
所以count(1) = count(*) = count(0)
count(字段)
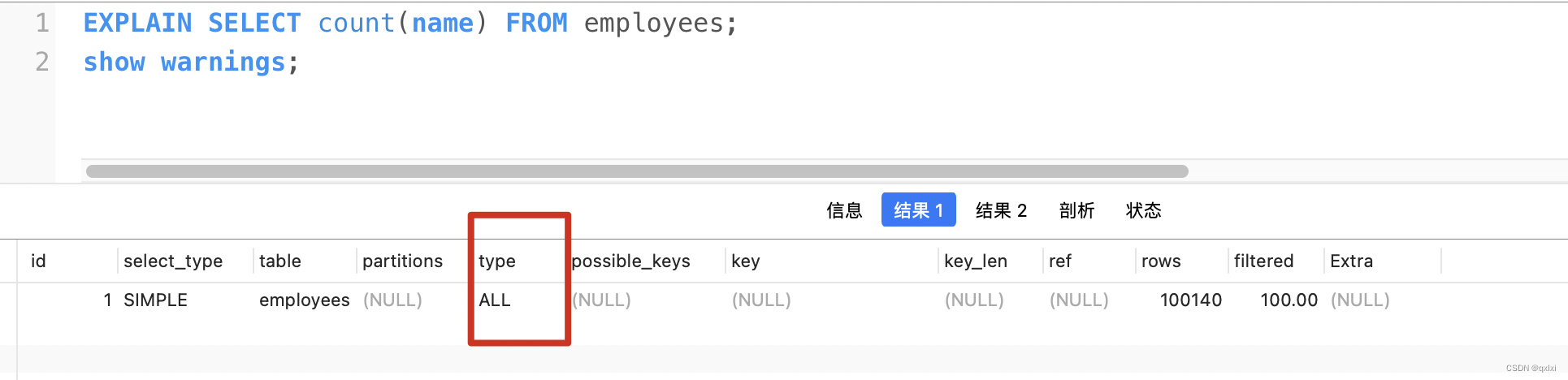
select count(name) from t_order;
統計這個表里有多少行name不為null的記錄。性能最差,會以全表掃描的方式進行處理。

小結
count1、count * 、count(id) 在執行的時候,如果表里有二級索引,優化器優先選擇二級索引進行掃描。
所以,如果要執行 count(1)、 count(*)、 count(主鍵字段) 時,盡量在數據表上建立二級索引,這樣優化器會自動采用 key_len 最小的二級索引進行掃描,相比于掃描主鍵索引效率會高一些。
再來,就是不要使用 count(字段) 來統計記錄個數,因為它的效率是最差的,會采用全表掃描的方式來統計。如果你非要統計表中該字段不為 NULL 的記錄個數,建議給這個字段建立一個二級索引。


的使用)


)









 不顯示頭部的問題)
任務)


memo、useCallback、useMemo Hook)