文章目錄
- 一、什么是模型蒸餾
- 二、如何蒸餾
- 三、實踐
- 四、參考文獻
一、什么是模型蒸餾
Hinton在NIPS2014提出了知識蒸餾(Knowledge Distillation)的概念,旨在把一個大模型或者多個模型ensemble學到的知識遷移到另一個輕量級單模型上,方便部署。簡單的說就是用小模型去學習大模型的預測結果,而不是直接學習訓練集中的label。
在蒸餾的過程中,原始大模型稱為教師模型(teacher),新的小模型稱為學生模型(student),訓練集中的標簽稱為hard label,教師模型預測的概率輸出為soft label,temperature(T)是用來調整soft label的超參數。
蒸餾之所以work,核心是因為好模型的目標不是擬合訓練數據,而是學習如何泛化到新的數據。所以蒸餾的目標是讓學生模型學習到教師模型的泛化能力,理論上得到的結果會比單純擬合訓練數據的學生模型要好。
二、如何蒸餾
之前提到學生模型需要通過教師模型的輸出學習泛化能力,那對于簡單的二分類任務來說,直接拿教師預測的0/1結果會與訓練集差不多,沒什么意義,那拿概率值是不是好一些?于是Hinton采用了教師模型的輸出概率q,同時為了更好地控制輸出概率的平滑程度,給教師模型的softmax中加了一個參數T。
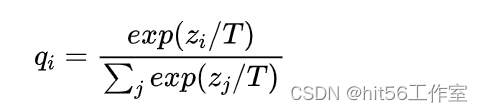
有了教師模型的輸出后,學生模型的目標就是盡可能擬合教師模型的輸出,新loss就變成了:
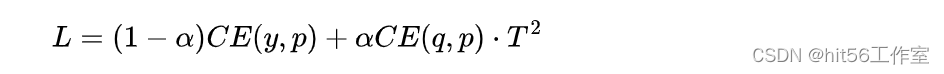
其中CE是交叉熵(Cross-Entropy),y是真實label,p是學生模型的預測結果,是蒸餾loss的權重。這里要注意的是,因為學生模型要擬合教師模型的分布,所以在求p時的也要使用一樣的參數T。另外,因為在求梯度時新的目標函數會導致梯度是以前的 ,所以要再乘上,不然T變了的話hard label不減小(T=1),但soft label會變。
有同學可能會疑惑:如果可以擬合prob,那直接擬合logits可以嗎?
當然可以,Hinton在論文中進行了證明,如果T很大,且logits分布的均值為0時,優化概率交叉熵和logits的平方差是等價的。
三、實踐
四、參考文獻
- BERT蒸餾完全指南|原理/技巧/代碼
)






Linux基本命令)









)

