題目來源:京東
目錄
- 1 題目
- 2 建表語句
- 3 題解
1 題目
已知有數據 A 如下,請分別根據 A 生成 B 和 C。
數據A
+-----+-------+
| id | name |
+-----+-------+
| 1 | aa |
| 2 | aa |
| 3 | aa |
| 4 | d |
| 5 | c |
| 6 | aa |
| 7 | aa |
| 8 | e |
| 9 | f |
| 10 | g |
+-----+-------+
數據B
+-----+-----------------+
| id | name |
+-----+-----------------+
| 7 | aa|aa|aa|aa|aa |
| 4 | d |
| 5 | c |
| 8 | e |
| 9 | f |
| 10 | g |
+-----+-----------------+
數據C
+-----+-----------+
| id | name |
+-----+-----------+
| 3 | aa|aa|aa |
| 4 | d |
| 5 | c |
| 7 | aa|aa |
| 8 | e |
| 9 | f |
| 10 | g |
+-----+-----------+
- 希望對
name相同的數據進行合并處理,name相同的合并到一起用'|'進行拼接,id取組內最大值; - 希望對相鄰
name相同的數據進行合并,name相同的合并到一起用'|'進行拼接,id取組內最大值;
2 建表語句
CREATE TABLE IF NOT EXISTS t_jd_idname_concat (id bigint, --idname STRING -- name
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS ORC;insert into t_jd_idname_concat(id, name) values
(1,'aa'),
(2,'aa'),
(3,'aa'),
(4,'d'),
(5,'c'),
(6,'aa'),
(7,'aa'),
(8,'e'),
(9,'f'),
(10,'g');
3 題解
1. 生成B
第一步:使用聚合函數開窗,給每行數據添加最大ID,作為新的分組ID。
selectid,name,max(id) over (partition by name) as new_id
from t_jd_idname_concat;
結果如下:
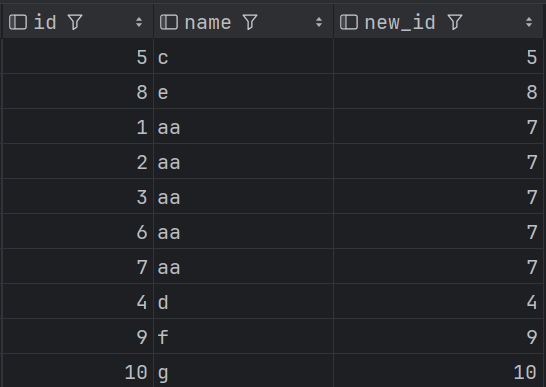
第二步:根據 new_id 分組,拼接 name,得到結果
selectnew_id as id,concat_ws('|',collect_list(name)) as name
from(selectid,name,max(id) over (partition by name) as new_idfrom t_jd_idname_concat) t
group by new_id;
結果如下:
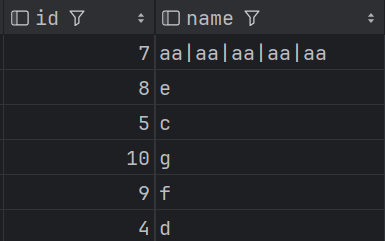
2. 生成C
該小問屬于是連續問題上進行數據拼接,所以我們先要對數據進行分組處理。
第一步:增加標識列,確認是否與上一行相同,如果相同則給0,不同給1。
select id,name,if(name = lag(name, 1, name) over (order by id), 0, 1) as flag
from t_jd_idname_concat;
結果如下:
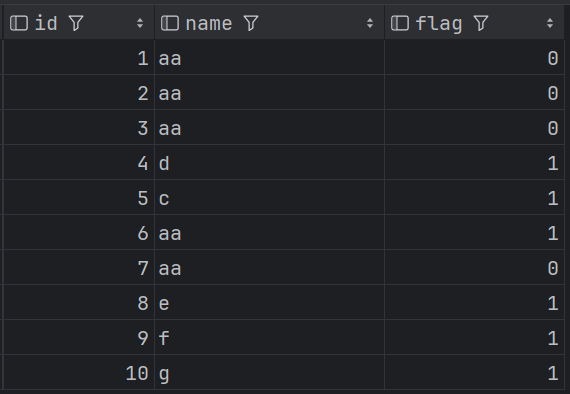
第二步:對 flag 累積求和,得到分組標志。
注意,第一步給flag 相同為0 不同為 1,疊加本步驟累積求和是一個常見解決連續問題的方式。
selectid,name,flag,sum(flag)over(order by id) as grp
from(selectid,name,-- 這里要注意if語句中0,1的位置不能互換(核心)if(name = lag(name,1,name)over(order by id),0,1) as flagfrom t_jd_idname_concat) t;
結果如下:
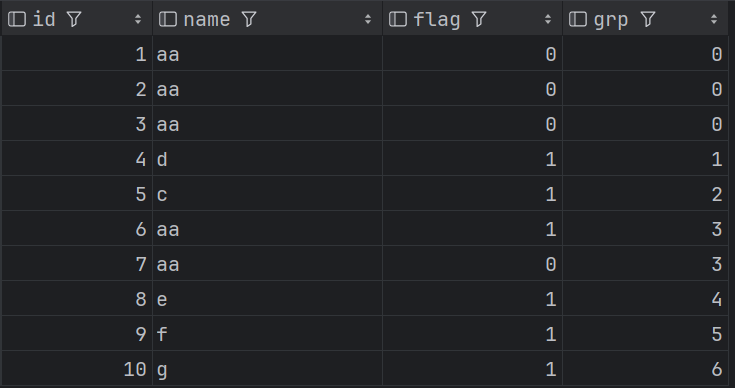
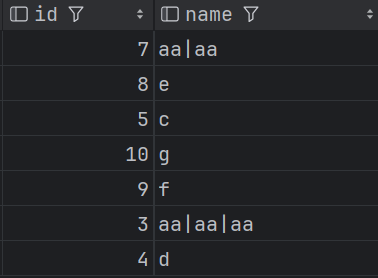
第三步:求分組內的最大值,完成拼接。
selectid,concat_ws('|',collect_list(name)) as name
from
(selectgrp,name,max(id) over(partition by grp) as id
from
(selectid,name,flag,sum(flag)over(order by id) as grp
from(selectid,name,-- 這里要注意if語句中0,1的位置不能互換(核心)if(name = lag(name,1,name)over(order by id),0,1) as flagfrom t_jd_idname_concat) t ) tt ) ttt
group by id;
結果如下:








)






)


)
