文章目錄
- 文章導圖
- 什么是CompletableFuture
- CompletableFuture用法總結
- API總結
- 為什么使用CompletableFuture
- 場景總結
- CompletableFuture默認線程池解析:ForkJoinPool or ThreadPerTaskExecutor?
- ForkJoinPool 線程池
- ThreadPerTaskExecutor線程池
- CompletableFuture默認線程池源碼分析
- 源碼流程圖
- 總結
- 注意點
- 設置 ForkJoinPool 并行級別
- 示例
- 補充
- 項目中使用CompletableFuture默認線程池的坑?
- 案例分析
- 如何解決?
- 線程池核心線程數和最大線程數設置指南
- 線程池參數介紹
- 線程數設置考慮因素
- CPU密集型任務的線程數設置
- IO密集型任務的線程數設置
- 實際應用中的線程數計算
- 生產環境中的線程數設置
- 線程池參數設置建議
- 注意事項
線程池系列文章可參考下表,目前已更新3篇,還剩1篇TODO…
| 線程池系列: | 文章 |
|---|---|
| Java基礎線程池 | TODO… |
| CompletableFuture線程池 | 從用法到源碼再到應用場景:全方位了解CompletableFuture及其線程池 |
| SpringBoot默認線程池(@Async和ThreadPoolTaskExecutor) | 探秘SpringBoot默認線程池:了解其運行原理與工作方式(@Async和ThreadPoolTaskExecutor) |
| SpringBoot默認線程池和內置Tomcat線程池 | 你是否傻傻分不清SpringBoot默認線程池和內置Tomcat線程池? |
文章導圖
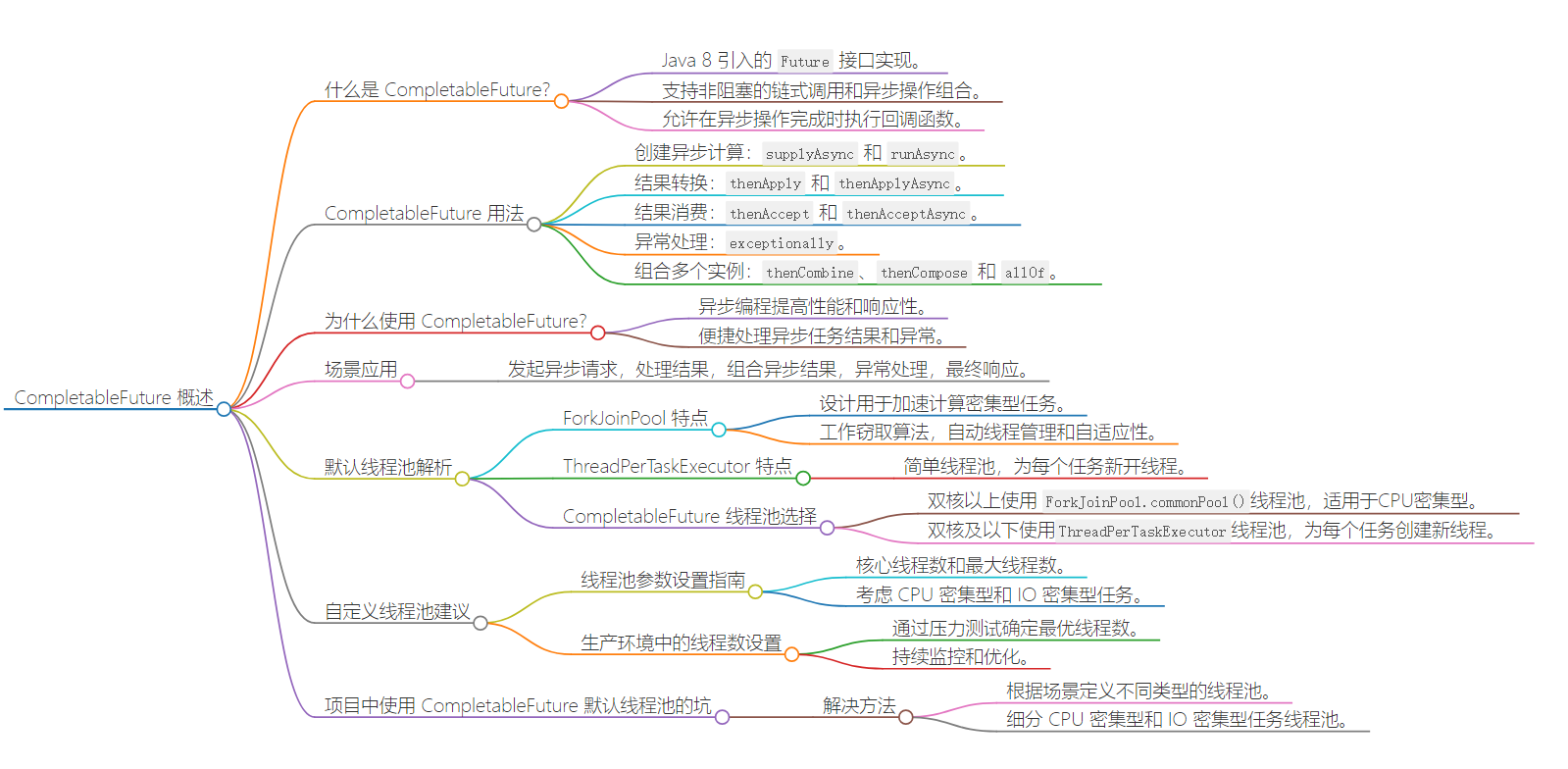
什么是CompletableFuture
JDK中的Future是什么可能大家都知道了,那CompletableFuture呢?從英文看單詞CompletableFuture猜測應該也是和Future有關,具體如下:
CompletableFuture是Java 8引入的一個重要特性,它是Future接口的一個實現,但與傳統的Future相比,提供了更強大、靈活的異步編程模型。CompletableFuture支持非阻塞的鏈式調用、組合多個異步操作以及更優雅地處理異步計算的結果或異常。- 它允許你在異步操作完成時執行回調函數,且這些操作可以并行或串行執行,極大地提高了程序的并發能力和響應速度。
CompletableFuture用法總結
使用CompletableFuture需要掌握其核心方法,以下是一些常用方法的總結:
// 創建一個完成的CompletableFuture
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("Hello");// 運行異步計算
CompletableFuture<Void> runAsyncFuture = CompletableFuture.runAsync(() -> {// 異步執行的代碼
});// 異步執行,并返回結果
CompletableFuture<String> supplyAsyncFuture = CompletableFuture.supplyAsync(() -> {return "Result";
});// 轉換和計算結果
CompletableFuture<String> transformFuture = supplyAsyncFuture.thenApply(result -> {return result.toUpperCase();
});// 組合兩個獨立的CompletableFuture
CompletableFuture<String> combinedFuture = transformFuture.thenCombine(CompletableFuture.completedFuture(" World"),(s1, s2) -> s1 + s2
);// 當CompletableFuture完成時執行某操作
supplyAsyncFuture.thenAccept(result -> {System.out.println("Result: " + result);
});// 異常處理
CompletableFuture<String> exceptionFuture = supplyAsyncFuture.exceptionally(ex -> {return "Error occurred: " + ex.getMessage();
});
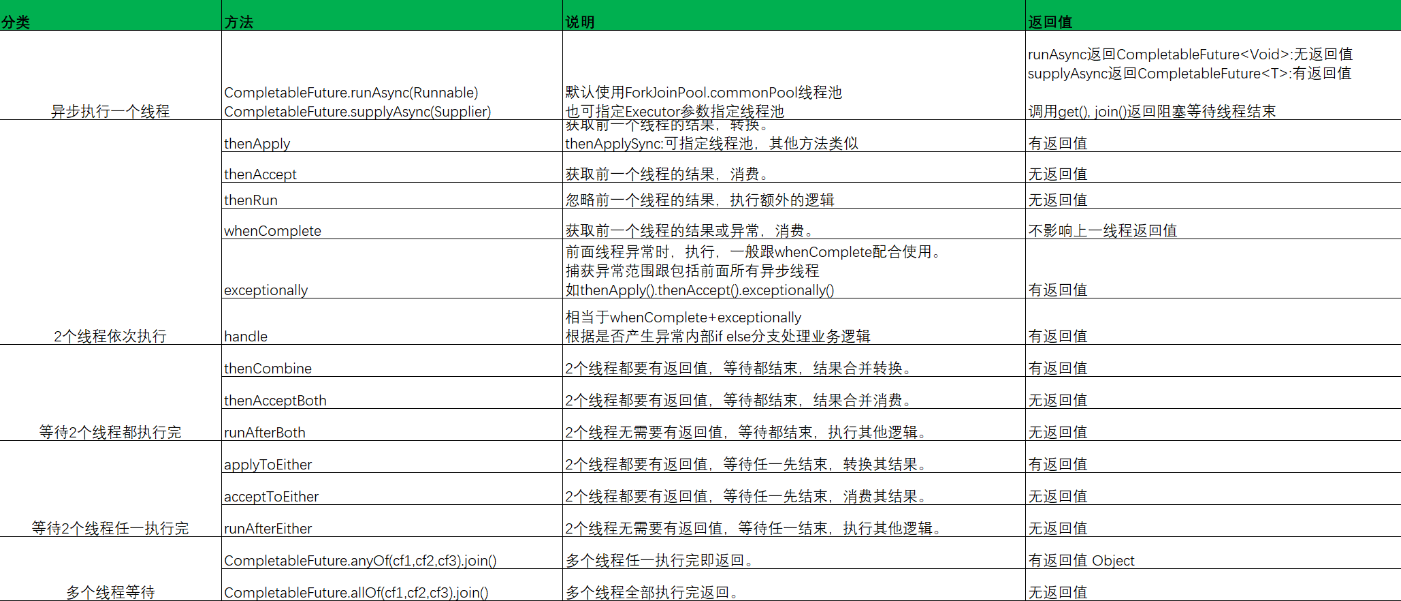
API總結
CompletableFuture提供了多種方法來創建、操作和組合CompletableFuture實例:
- 創建異步計算:
supplyAsync和runAsync是兩個創建異步計算任務的靜態方法,它們分別對應有返回值和無返回值的異步任務。 - 結果轉換:
thenApply和thenApplyAsync方法允許對異步計算的結果進行轉換。 - 結果消費:
thenAccept和thenAcceptAsync允許你對結果進行消費,如打印結果。 - 異常處理:
exceptionally方法提供了異常處理的能力,允許你為CompletableFuture的執行定義一個回調,用于處理異常情況。 - 多個CompletableFuture的組合:
thenCombine、thenCompose和allOf等方法允許將多個CompletableFuture組合起來,創建更為復雜的異步流程。
更為詳細的可以查看下表:
為什么使用CompletableFuture
異步編程模式可以幫助提高應用的響應性和吞吐量,特別是在處理長時間運行的任務時。使用CompletableFuture的幾個關鍵優勢包括:
異步編程:
- 提高程序性能:異步操作不會阻塞主線程,允許同時執行多個任務。
- 增加程序響應性:將耗時操作放入異步任務,保持主線程響應性。
異步結果處理:
- 便捷處理異步任務結果:通過
thenApply(),thenAccept(),thenCombine()等方法處理任務結果,實現流式編程。 - 處理異常情況:
exceptionally(),handle()等方法處理異步任務執行中產生的異常。
場景總結
從上面的用法總結,我們也可以發現使用CompletableFuture通常用于解決以下類似場景的問題:
- 發起異步請求:當用戶請求一個產品詳情頁時,后端服務可以同時發起對三個數據源的異步請求,這可以通過創建三個
CompletableFuture實例來實現,每個實例負責一個數據源的請求。 - 處理異步結果:一旦這些異步請求發出,它們就可以獨立地執行,主線程可以繼續處理其他任務,當某個
CompletableFuture完成時,它會包含一個結果(或者是執行過程中的異常)。 - 組合異步結果:使用
CompletableFuture的組合方法(如thenCombine、thenAcceptBoth或allOf),可以等待所有異步操作完成,并將它們的結果組合在一起,比如,可以等待產品基本信息、價格和庫存以及用戶評價都返回后,再將這些數據整合到一個響應對象中,返回給前端。 - 異常處理:如果在獲取某個數據源時發生異常,
CompletableFuture允許以異步的方式處理這些異常,比如通過exceptionally方法提供一個默認的備選結果或執行一些清理操作。 - 最終響應:一旦所有數據源的數據都成功獲取并組合在一起,或者某個數據源發生異常并得到了妥善處理,服務就可以將最終的產品詳情頁響應發送給前端用戶。
CompletableFuture默認線程池解析:ForkJoinPool or ThreadPerTaskExecutor?
ForkJoinPool 線程池
因為后面的內容有涉及
ForkJoinPool 和ThreadPerTaskExecutor,在解析CompletableFuture默認線程池之前先簡單介紹一下這兩個線程池
ForkJoinPool線程池是Java并發編程中的一個重要組件,專為高效處理具有分治特性的任務而設計。以下是對其多方面的簡單總結:
- 設計目的:旨在通過分治策略(Divide and Conquer)來加速計算密集型任務的執行,將大任務拆分為多個小任務并行處理,最終合并結果。
- 工作竊取(Work-Stealing)算法:ForkJoinPool的核心機制,允許空閑線程從其他線程的任務隊列中“竊取”任務執行,確保線程資源充分利用,減少空閑時間,提高整體效率。
- 任務劃分與合并:任務通過實現
ForkJoinTask接口(或其子類如RecursiveAction和RecursiveTask)來定義,可以被“分叉”(fork)成子任務并行執行,完成后“合并”(join)結果。 - 線程管理:自動管理和調整線程數量,通常默認使用可用處理器數量減一作為核心線程數,以保持良好的CPU利用率同時避免過多的上下文切換開銷。
- 自適應性:根據系統負載動態調整工作線程的數量,適應不同規模和性質的任務,尤其適合高度并行且可分解的任務。
- 常見用途:適用于快速排序、歸并排序、矩陣運算、大規模數據處理、復雜算法并行化等場景,以及在Java 8中并行流(parallel streams)和CompletableFuture的后臺執行中。
- 注意事項:不適合I/O密集型或易阻塞的操作,因為工作竊取機制依賴于線程的快速執行和任務的高效流轉;對于這類任務,應考慮使用專用線程池或結合
ManagedBlocker。 - 資源限制與監控:使用時需注意資源限制,尤其是在共享
ForkJoinPool.commonPool()時,避免因不當使用導致整個應用性能下降。監控工具和日志可以幫助診斷性能瓶頸。
ThreadPerTaskExecutor線程池
ThreadPerTaskExecutor線程池非常簡單,它就是CompletableFuture的一個靜態內部類,在ThreadPerTaskExecutor 中 execute,他會為每個任務新開一個線程,所以相當于就沒有線程池!
static final class ThreadPerTaskExecutor implements Executor {public void execute(Runnable r) { new Thread(r).start(); }}CompletableFuture默認線程池源碼分析
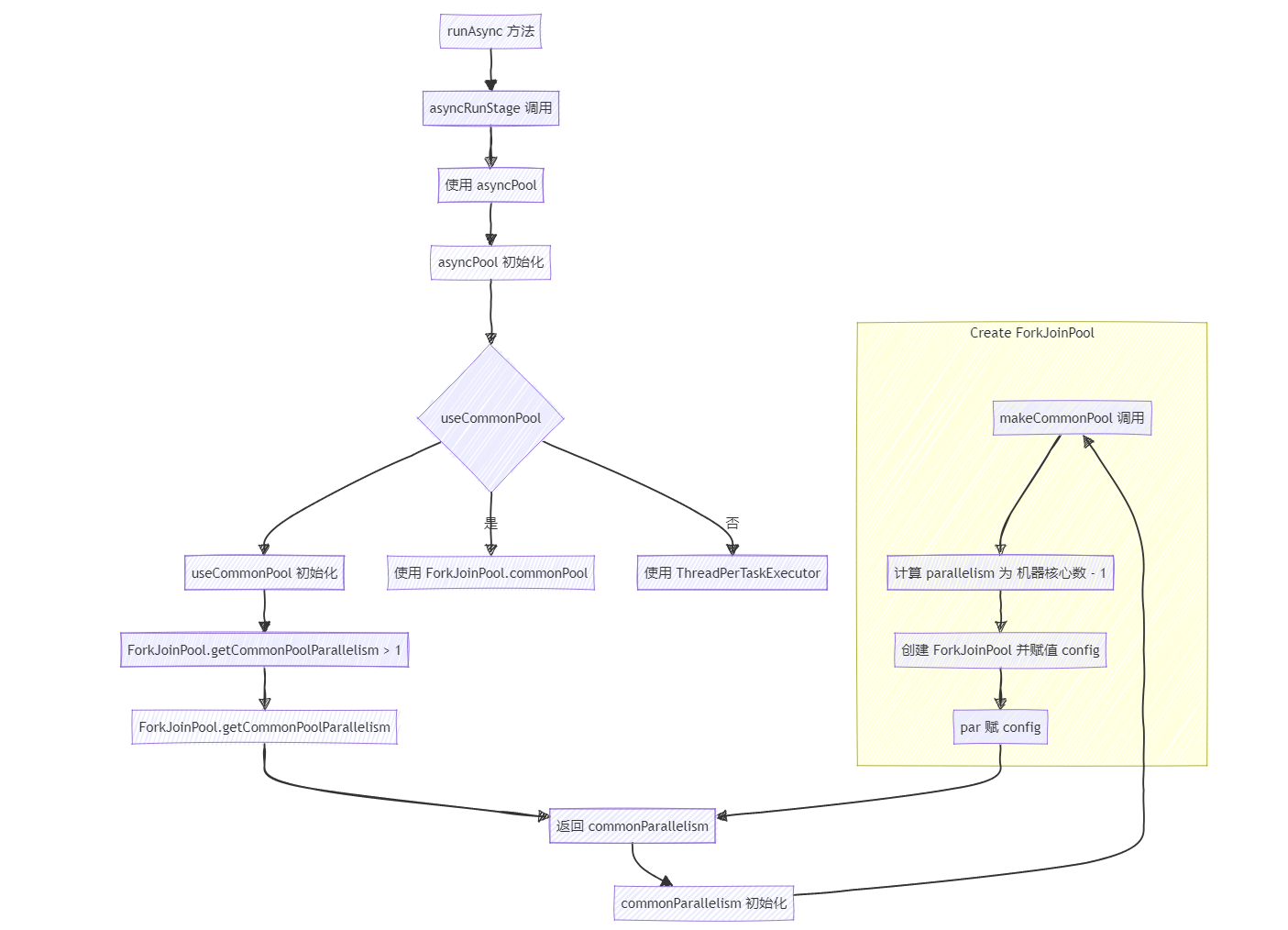
源碼流程圖
整體流程圖大致如下:
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {System.out.println("Running in thread: " + Thread.currentThread().getName());
});
1、從runAsync方法點進去分析源碼,可以看見使用的是asyncPool。
public static CompletableFuture<Void> runAsync(Runnable runnable) {return asyncRunStage(asyncPool, runnable);
}2、點進asyncPool,useCommonPool是否為true決定了使用 ForkJoinPool線程池還是新建一個線程池ThreadPerTaskExecutor。
private static final Executor asyncPool = useCommonPool ?ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
3、點進useCommonPool,這里判定的是ForkJoinPool common線程池中并行度級別是否大于1。
private static final boolean useCommonPool =(ForkJoinPool.getCommonPoolParallelism() > 1);4、點進 getCommonPoolParallelism() 方法,返回的是commonParallelism這個字段,再往下找。
public static int getCommonPoolParallelism() {return commonParallelism;}發現只有一個地方對這個屬性進行賦值,
//類頂SMASK常量的值
static final int SMASK = 0xffff;
final int config;
static final ForkJoinPool common;//該方法返回了一個commonParallelism的值
public static int getCommonPoolParallelism() {return commonParallelism;}//而commonParallelism的值是在一個靜態代碼塊里被初始化的,也就是類加載的時候初始化
static {//初始化common,這個common即ForkJoinPool自身common = java.security.AccessController.doPrivileged(new java.security.PrivilegedAction<ForkJoinPool>() {public ForkJoinPool run() { return makeCommonPool(); }});//根據par的值來初始化commonParallelism的值int par = common.config & SMASK; // report 1 even if threads disabledcommonParallelism = par > 0 ? par : 1;}
總結一下上面三部分代碼,結合在一起看,這部分代碼主要是初始化了commonParallelism的值,也就是getCommonPoolParallelism()方法的返回值,這個返回值也決定了是否使用默認線程池,接下來看看具體commonParallelism是如何賦值的:
5、commonParallelism-->par-->common-->makeCommonPool()
commonParallelism的值又是通過par的值來確定的,par的值是common來確定的,而common則是在makeCommonPool()這個方法中初始化的。
6、我們繼續跟進makeCommonPool()方法
private static ForkJoinPool makeCommonPool() {int parallelism = -1;if (parallelism < 0 && // default 1 less than #cores//獲取機器的cpu核心數 將機器的核心數-1 賦值給parallelism 這一段是是否使用線程池的關鍵//同時 parallelism也是ForkJoinPool的核心線程數(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)parallelism = 1;if (parallelism > MAX_CAP)parallelism = MAX_CAP;return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,"ForkJoinPool.commonPool-worker-");}//上面的那個構造方法,可以看到把parallelism賦值給了config變量
private ForkJoinPool(int parallelism,ForkJoinWorkerThreadFactory factory,UncaughtExceptionHandler handler,int mode,String workerNamePrefix) {this.workerNamePrefix = workerNamePrefix;this.factory = factory;this.ueh = handler;this.config = (parallelism & SMASK) | mode;long np = (long)(-parallelism); // offset ctl countsthis.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);}總結一下上面兩段代碼:
- 獲取機器核心數-1的值,賦值給parallelism變量,再通過構造方法把parallelism的值賦值給config變量。
- 然后初始化ForkJoinPool的時候。再將config的值賦值給par變量。如果par大于0則將par的值賦給commonParallelism:
- 如果commonParallelism的值大于1的話,useCommonPool的值就為true,就使用默認的線程池
ForkJoinPool - 否則使用
ThreadPerTaskExecutor線程池,此線程池為每個任務創建一個新線程,也就相當于沒有線程池。
- 如果commonParallelism的值大于1的話,useCommonPool的值就為true,就使用默認的線程池
總結
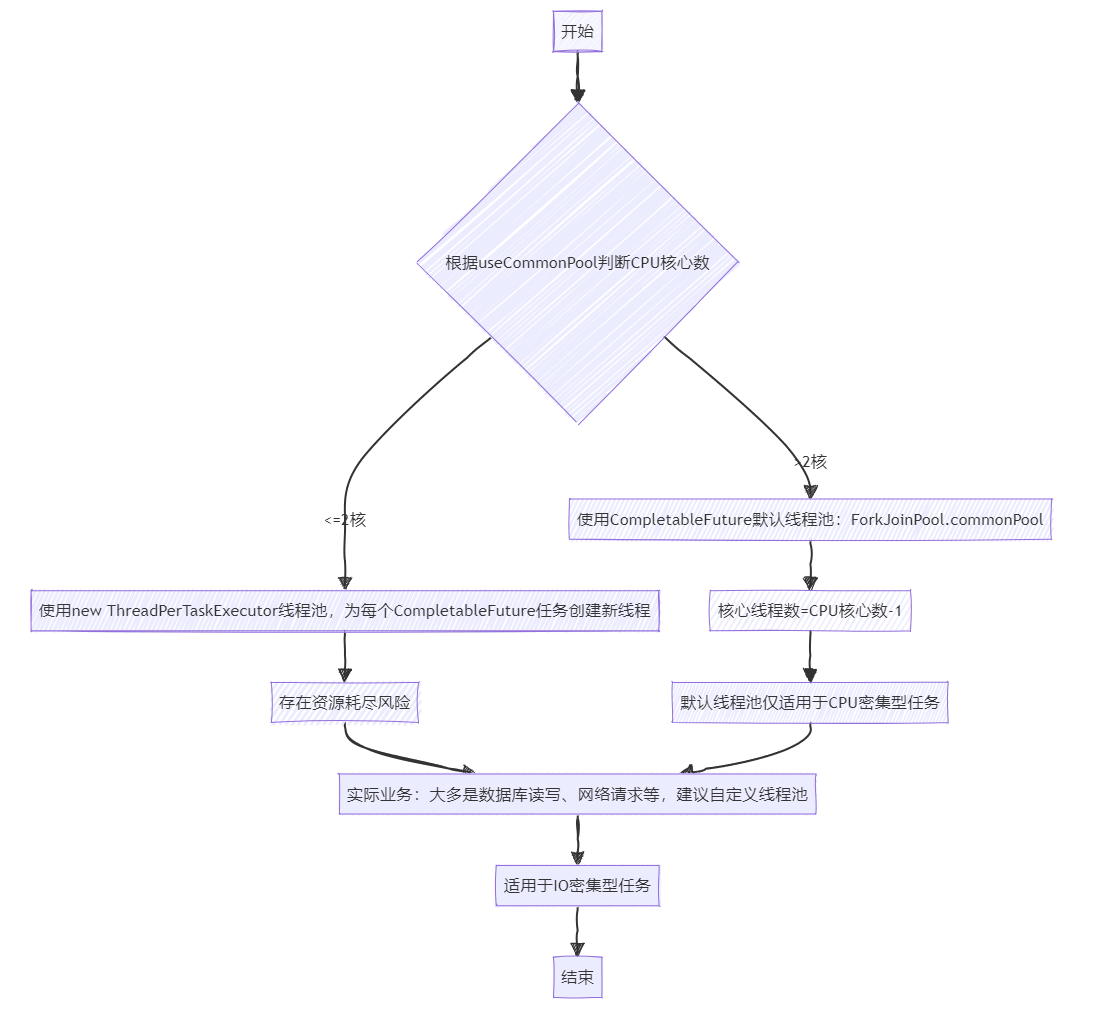
關于CompletableFuture的默認線程池使用情況,其依據及建議可總結如下:
- CompletableFuture是否利用默認線程池,其主要考量因素與計算機的CPU核心數息息相關。僅當CPU核心數減一大于1時,CompletableFuture才會啟用默認線程池,也就是
ForkJoinPool.commonPool;反之,使用new ThreadPerTaskExecutor線程池,為每個CompletableFuture任務創建新線程執行。 - 換言之,CompletableFuture的默認線程池只會在具備雙核以上配置的計算機上啟用。在雙核及以下的計算機環境下,每個任務都會獨立創建新的線程,相當于并未使用線程池,同時存在資源耗盡的潛在風險。
- 因此,強烈建議在使用CompletableFuture時,務必自行定義線程池。即便啟用了默認線程池,池內的核心線程數仍為計算機核心數減一。例如,我們服務器為4核,則最多僅能支持3個核心線程,對于CPU密集型任務而言尚可應對,但在實際業務開發過程中,我們更多地涉及到IO密集型任務,對于此類任務,默認線程池的資源配置顯然不足以滿足需求,可能導致大量的IO任務處于等待狀態,從而大幅降低系統吞吐率,即默認線程池更適合于CPU密集型任務。
注意點
在使用 CompletableFuture 執行異步任務時,有時我們需要根據應用的負載或硬件資源來調整其線程池配置。你可以通過設置JVM參數來實現這一點。具體來說,你可以配置 ForkJoinPool 的并行級別、線程數等參數。
設置 ForkJoinPool 并行級別
ForkJoinPool 是 CompletableFuture 的默認執行器。我們可以通過設置以 java.util.concurrent.ForkJoinPool 開頭的 JVM 系統屬性來調整其行為。
以下是一些常用的 JVM 參數:
- java.util.concurrent.ForkJoinPool.common.parallelism:設置 ForkJoinPool 的并行級別(即最大并行線程數)。
- java.util.concurrent.ForkJoinPool.common.threadFactory:設置自定義的線程工廠。
- java.util.concurrent.ForkJoinPool.common.exceptionHandler:設置未捕獲異常的處理器。
示例
假設我們希望將 ForkJoinPool 的并行級別設置為 4,可以在啟動 JVM 時添加以下參數:
java -Djava.util.concurrent.ForkJoinPool.common.parallelism=4 -jar YourApplication.jar
這樣,ForkJoinPool 的最大并行線程數將限制為4。
補充
所以對上面的流程加以補充一下就是
-
無JVM參數前提下:
-
若服務器的核心數小于等于2,commonParallelism 則為1,即useCommonPool 為false,new 一個線程池
ThreadPerTaskExecutor。 -
若服務器的核心數大于2,commonParallelism 則為 核心數 - 1,即useCommonPool 為true,使用
ForkJoinPool線程池。
-
-
有JVM參數,以設置參數為準。大于1小于等于32767。和上面判斷一致。
項目中使用CompletableFuture默認線程池的坑?
案例分析
1、假如我們有一個MQ消費者處理,然后采用CompletableFuture.runAsync處理消息,
@Component
public class MessageHandler {@RabbitListener(queues = "messageQueue")public void handleMessage(byte[] message){//新啟動線程處理復雜業務消息CompletableFuture.runAsync(() -> {//復雜業務處理...});}
}
2、同時我們在另外一個地方也用到了CompletableFuture.runAsync處理CPU密集型任務
public void handleComplexCalculations(){CompletableFuture.runAsync(() -> {//新啟動線程處理復雜的計算任務...});}
根據上面我們分析的源碼,如果生產假設都是4核,它們兩個實際走的都是是默認線程池ForkJoinPool.commonPool(),但是這個是靜態全局共享的!!!
static final ForkJoinPool common;public static ForkJoinPool commonPool() {// assert common != null : "static init error";return common;}
所以可想而知,假設在生產環境的情況,很可能高并發或者消息堆積一下子就會把這個默認的ForkJoinPool.commonPool()線程池打滿,此時我們另外一個地方計算復雜任務計算的地方就會卡死,因為獲取不到線程啊,都被MQ消費那邊占用了!
而這種情況很可能在開發和測試環境都復現不了,因為我們不做壓測的話,并發也不高,普通點點肯定也沒問題,這種問題生產才會復現!
如何解決?
那么如何解決上述問題呢?答案無疑是進行自定義!
- 理想的做法是根據具體場景來定義不同類型的線程池,也就是線程池隔離!例如CPU密集型、IO密集型等等。
- 即便在同屬CPU密集型場景下,也可根據實際情況細分為不同類別,如上文所述的MQ場景可獨設一個線程池,以避免在高并發場景下由于線程池過載而導致其他地方發生阻塞乃至癱瘓。
至于如何進行自定義,以下指南可供參考。
線程池核心線程數和最大線程數設置指南
線程池參數介紹
- 核心線程數:線程池中始終活躍的線程數量。
- 最大線程數:線程池能夠容納同時執行的最大線程數量。
線程數設置考慮因素
- CPU密集型任務:依賴CPU計算的任務,如循環計算等。
- IO密集型任務:任務執行過程中涉及等待外部操作,如數據庫讀寫、網絡請求、磁盤讀寫等。
CPU密集型任務的線程數設置
- 推薦設置:核心數 + 1。
- 原因:避免線程切換開銷,同時允許一定程度的線程中斷恢復。
IO密集型任務的線程數設置
- 推薦設置:2 * CPU核心數。
- 原因:IO操作期間,CPU可執行其他線程任務,提高資源利用率。
實際應用中的線程數計算
- 使用工具(如Java的Visual VM)來監測線程的等待時間和運行時間。
- 計算公式:(線程等待時間 / 線程總運行時間)+ 1 * CPU核心數。
生產環境中的線程數設置
- 理論值與實際值可能存在差異,需要通過壓力測試來確定最優線程數。
- 壓力測試:調整線程數,觀察系統性能,找到最優解。
線程池參數設置建議
- 核心業務應用:核心線程數設置為壓力測試后的數值,最大線程數可以適當增加。
- 非核心業務應用:核心線程數設置較低,最大線程數設置為壓力測試結果
注意事項
- 線程數設置需根據實際業務需求和系統環境進行調整。
- 持續監控和優化是保證系統性能的關鍵。

用戶注冊——控制反轉以及Hibernate Validator數據驗證)



![[JAVASE] 類和對象(六) -- 接口(續篇)](http://pic.xiahunao.cn/[JAVASE] 類和對象(六) -- 接口(續篇))
)





)


)



