文章目錄
- 一、泛型算法
- 1.泛型算法的分類
- 2.迭代器分類
- 二、bind與lambda表達式
- 1.bind
- 2.lambda表達式
- 三、泛型算法的改進--ranges(c++20)
一、泛型算法
??C++中的泛型算法是標準模板庫(STL)的一部分(這里重點討論 C++ 標準庫中定義的算法,而非自定義的算法),它們能夠對不同類型的數據執行操作,而不需要編寫針對每種類型的特定代碼。泛型算法之所以強大,是因為它們可以處理任何類型的數據,只要這些數據滿足某些基本要求,比如迭代器支持。泛型算法通常使用模板來實現,這意味著它們可以在編譯時自動適應傳入的數據類型。泛型算法可以用于操作容器中的元素,而不需要關心容器的具體類型。
C++11標準中定義的泛型算法可參考《C++標準庫》第二版這本書
-
為什么要引入泛型算法而不采用方法(容器中支持的方法)的形式?
??泛型算法(Generic Algorithms)是一種編程范式,它允許算法的實現獨立于數據類型,從而使得同一個算法可以應用于多種不同的數據類型。泛型算法的引入主要基于以下幾個原因:
-
內建數據類型不支持方法:
內建的數據類型(如數組、基本數據類型等)并不支持方法的直接定義。泛型算法不需要關心數據存儲的具體類型,從而可以應用于任何類型的容器或數據結構。
-
計算邏輯存在相似性:
很多算法在本質上是相似的,比如排序、搜索等。如果為每種數據類型都編寫一個特定的算法實現,將會導致代碼的重復和冗余。泛型算法通過抽象化算法的實現,使得相同的邏輯可以重用于不同的數據類型。
-
避免重復定義:
泛型算法可以用于多種數據類型,避免了為每種數據類型重復編寫相同或類似的代碼。這不僅減少了開發時間,還減少了出錯的可能性。
-
提高代碼的可重用性:
通過泛型算法,開發者可以創建高度可重用的代碼,這些代碼可以在不同的項目和應用程序中使用,而不需要針對每種數據類型進行修改。
-
簡化維護和擴展:當算法需要修改或擴展時,泛型算法只需要修改一次,所有使用該算法的數據類型都會自動受益于這些更改。這使得維護和擴展變得更加簡單和高效。
-
-
泛型算法如何實現支持多種類型:
使用迭代器作為算法與數據的橋梁。迭代器是一種設計模式,它提供了一種方式來順序訪問容器中的元素而不需要暴露容器的內部結構。
迭代器如何作為算法與數據結構之間的橋梁來實現泛型算法的步驟:
-
定義迭代器接口:迭代器通常具有幾個基本操作,如
begin()(返回開始迭代的迭代器)、end()(返回結束迭代的迭代器,通常是一個不指向任何元素的迭代器)、next()(移動到下一個元素)和value()(獲取當前元素的值)。這些操作是算法與數據結構交互的基礎。 -
算法與迭代器解耦:泛型算法不直接操作數據結構中的元素,而是通過迭代器來訪問和操作這些元素。這意味著算法的實現與數據結構的具體類型無關,算法只關心如何通過迭代器訪問元素。
-
使用模板或泛型編程:在支持泛型編程的編程語言中(如C++),可以通過模板或泛型來定義算法。這些模板或泛型參數可以是任何類型的迭代器。
-
算法實現中的迭代器使用:在算法的實現中,使用迭代器接口來遍歷容器中的元素。例如,一個簡單的遍歷算法可能如下所示:
//traverse 函數就可以正確地遍歷從 begin 到 end 的所有元素,并在每次迭代中調用 process 函數來處理當前元素。 template<typename Iterator> void traverse(Iterator begin, Iterator end) {while (begin != end) {process(*begin); // 處理當前元素begin.next(); // 移動到下一個元素} } -
適配不同數據結構:不同的數據結構可以實現相同的迭代器接口,這樣同一個算法就可以應用于不同的數據結構。例如,數組、鏈表、樹等都可以提供符合迭代器接口的實現。
-
算法的泛化:通過迭代器,算法可以被泛化,使其能夠處理任何提供相應迭代器的數據結構。這大大增強了算法的靈活性和重用性。
-
類型安全:使用迭代器和泛型編程還可以保證類型安全。編譯器可以在編譯時檢查類型匹配,避免運行時錯誤。
C++的模板允許編譯時計算,這意味著泛型算法可以在編譯時進行類型檢查和優化,從而減少運行時的開銷。
-
簡化算法實現:開發者可以專注于算法的邏輯實現,而不需要關心數據結構的細節,這簡化了算法的編寫和理解。
通過這種方式,泛型算法能夠以一種類型無關的方式實現,從而支持多種數據類型。迭代器作為算法與數據結構之間的橋梁,使得算法能夠以統一的方式處理不同的數據集合。
-
-
泛型算法通常來說設計都不復雜,但優化足夠好
-
泛型算法庫主要包括以下幾個頭文件:
-
<algorithm>:這是最常用的泛型算法庫,包含了排序、搜索、復制、變換等基本操作。例如,std::sort、std::find、std::copy等。 -
<numeric>:這個頭文件包含了一些數值算法,主要用于執行數值計算,如累加、乘積、最小/最大值查找等。例如,std::accumulate、std::inner_product等。 -
<ranges>:這是C++20中引入的新特性,提供了對范圍(range)的支持,使得算法可以更自然地應用于各種范圍對象。它提供了范圍基的算法,如std::ranges::find、std::ranges::sort等,這些算法可以直接作用于std::ranges::range對象。
-
-
一些泛型算法與方法(容器中支持的方法)同名,實現功能類似,此時建議調用方法而非算法。
容器的成員函數通常針對特定容器進行了優化,因此可能比泛型算法更快。例如,
std::map::find利用了紅黑樹的特性,提供了對鍵值的快速查找,而std::find則需要遍歷整個容器。std::vector中沒有包含find方法,因為使用std::find已經達到很好的性能了。
1.泛型算法的分類
??在C++中,泛型算法是標準模板庫(STL)的一部分,它們提供了一種高效、靈活的方式來操作數據集合。這些算法通常與容器(如vector, list, array等)一起使用,并且可以對存儲在這些容器中的數據執行各種操作。泛型算法按照它們執行的操作類型可以分為幾個主要類別:
讀算法:
??讀算法用于:給定迭代區間,遍歷容器中的元素并進行計算(讀取它們,但通常不修改它們)。
accumulatefindcount
-
accumulate:用于計算迭代器范圍內所有元素的總和
詳細內容可參考:https://en.cppreference.com/w/cpp/algorithm/accumulate
??
accumulate算法用于計算迭代器范圍內所有元素的總和。它可以接受三個參數:迭代器范圍的開始和結束,以及一個初始值。它會返回迭代器范圍內所有元素的累加結果。也可以接受四個參數:迭代器范圍的開始和結束,一個初始值以及被使用的二元函數對象(可以是函數指針、C++標準庫中定義的函數,也可以是后續討論的bind以及lambda表達式)。類模板一及其實現:
#include <numeric>template< class InputIt, class T > T accumulate( InputIt first, InputIt last, T init );template<class InputIt, class T> constexpr // since C++20 T accumulate(InputIt first, InputIt last, T init) {for (; first != last; ++first)init = std::move(init) + *first; return init; }類模板二及其實現:
#include <numeric>template< class InputIt, class T, class BinaryOp > T accumulate( InputIt first, InputIt last, T init, BinaryOp op );template<class InputIt, class T, class BinaryOperation> constexpr // since C++20 T accumulate(InputIt first, InputIt last, T init, BinaryOperation op) {for (; first != last; ++first)init = op(std::move(init), *first); return init; }示例:
#include <functional> #include <iostream> #include <numeric> #include <string> #include <vector>int main() {std::vector<int> v{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};int sum = std::accumulate(v.begin(), v.end(), 0);int product = std::accumulate(v.begin(), v.end(), 1, std::multiplies<int>());auto dash_fold = [](std::string a, int b){return std::move(a) + '-' + std::to_string(b);};std::string s = std::accumulate(std::next(v.begin()), v.end(),std::to_string(v[0]), // start with first elementdash_fold);// Right fold using reverse iteratorsstd::string rs = std::accumulate(std::next(v.rbegin()), v.rend(),std::to_string(v.back()), // start with last elementdash_fold);std::cout << "sum: " << sum << '\n'<< "product: " << product << '\n'<< "dash-separated string: " << s << '\n'<< "dash-separated string (right-folded): " << rs << '\n'; }運行結果:
sum: 55 product: 3628800 dash-separated string: 1-2-3-4-5-6-7-8-9-10 dash-separated string (right-folded): 10-9-8-7-6-5-4-3-2-1 -
find:用于在迭代器指定的范圍內搜索一個特定的值
詳細內容可參考:https://en.cppreference.com/w/cpp/algorithm/find
??
find算法用于在迭代器指定的范圍內搜索一個特定的值。它可以接受三個參數:迭代器范圍的開始和結束,以及一個給定值。如果找到該值,它返回指向該值的迭代器;如果沒有找到,它返回last迭代器。類模板及其實現:
#include <algorithm>template< class InputIt, class T > InputIt find( InputIt first, InputIt last, const T& value );template<class InputIt, class T = typename std::iterator_traits<InputIt>::value_type> InputIt find(InputIt first, InputIt last, const T& value) {for (; first != last; ++first)if (*first == value)return first;return last; }示例:
#include <iostream> #include <vector> #include <algorithm> // 包含 find 函數int main() {std::vector<int> v = {1, 2, 3, 4, 5};auto it = std::find(v.begin(), v.end(), 3);if (it != v.end()) {std::cout << "Found: " << *it << std::endl; // 輸出:Found: 3} else {std::cout << "Value not found" << std::endl;}return 0; } -
count:用于計算迭代器范圍內與給定值匹配的元素數量,并返回這個數量
詳細內容可參考:https://en.cppreference.com/w/cpp/algorithm/count
??
count算法用于計算迭代器范圍內與給定值匹配的元素數量。它可以接受三個參數:迭代器范圍的開始和結束,以及一個給定值。返回值的個數。類模板參數及其實現:
#include <algorithm>template< class InputIt, class T > typename std::iterator_traits<InputIt>::difference_typecount( InputIt first, InputIt last, const T& value );template<class InputIt, class T = typename std::iterator_traits<InputIt>::value_type> typename std::iterator_traits<InputIt>::difference_typecount(InputIt first, InputIt last, const T& value) {typename std::iterator_traits<InputIt>::difference_type ret = 0;for (; first != last; ++first)if (*first == value)++ret;return ret; }示例:
#include <iostream> #include <vector> #include <algorithm> // 包含 count 函數int main() {std::vector<int> v = {1, 2, 2, 3, 2, 4};auto count_of_two = std::count(v.begin(), v.end(), 2);std::cout << "Count of 2: " << count_of_two << std::endl; // 輸出:Count of 2: 3return 0; }
寫算法:
??寫算法用于:給定迭代區間,遍歷容器中的元素并進行修改。
單純寫操作: fill / fill_n/replace
讀 + 寫操作: transpose / copy / copy_if
注意:寫算法一定要保證目標區間足夠大
-
fill:用于使用給定值填充容器中指定范圍內的所有元素
詳細內容可查看:https://en.cppreference.com/w/cpp/algorithm/fill
??
fill算法用于使用給定值填充容器中指定范圍內的所有元素。它可以接受三個參數:迭代器范圍的開始和結束,以及一個給定值。沒有返回值。類模板及其實現:
#include <algorithm>template< class ForwardIt, class T > void fill( ForwardIt first, ForwardIt last, const T& value );template<class ForwardIt,class T = typename std::iterator_traits<ForwardIt>::value_type> void fill(ForwardIt first, ForwardIt last, const T& value) {for (; first != last; ++first)*first = value; }示例:
#include <iostream> #include <algorithm> // 包含 std::fill #include <vector>int main() {std::vector<int> v(5); // 創建一個有5個元素的vectorstd::fill(v.begin(), v.end(), 10); // 將所有元素設置為10// 輸出結果: 10 10 10 10 10for (int elem : v) {std::cout << elem << " ";}return 0; } -
fill_n:
詳細內容可查看:https://en.cppreference.com/w/cpp/algorithm/fill_n
??
fill_n用于將指定值賦給從first開始都得范圍的前count個元素。它可以接受三個參數:迭代器范圍的開始和元素的數量,以及一個給定值。如果count > 0 時返回指向最后賦值元素后一位置的迭代器,否則返回 first迭代器。類模板及其實現:
#include <algorithm>template< class OutputIt, class Size, class T > OutputIt fill_n( OutputIt first, Size count, const T& value );template<class OutputIt, class Size,class T = typename std::iterator_traits<OutputIt>::value_type> OutputIt fill_n(OutputIt first, Size count, const T& value) {for (Size i = 0; i < count; i++)*first++ = value;return first; }示例:
#include <iostream> #include <algorithm> // 包含 std::fill_n #include <vector>int main() {std::vector<int> v(5); // 創建一個有5個元素的vectorstd::fill_n(v.begin(), 3, 20); // 將前3個元素設置為20// 輸出結果: 20 20 20 0 0for (int elem : v) {std::cout << elem << " ";}return 0; } -
replace:
詳細內容可查看https://en.cppreference.com/w/cpp/algorithm/replace
??
std::replace用于以指定值替換范圍內所有滿足判定標準的元素。它可以接受四個參數:迭代器范圍的開始和結束,要被替換的元素值與用作替換的值。無返回值。類模板及其實現:
#include <algorithm>template< class ForwardIt, class T > void replace( ForwardIt first, ForwardIt last,const T& old_value, const T& new_value );template<class ForwardIt,class T = typename std::iterator_traits<ForwardIt>::value_type> void replace(ForwardIt first, ForwardIt last,const T& old_value, const T& new_value) {for (; first != last; ++first)if (*first == old_value)*first = new_value; }示例:
#include <algorithm> #include <array> #include <functional> #include <iostream>int main() {std::array<int, 10> s{5, 7, 4, 2, 8, 6, 1, 9, 0, 3};// 將出現的所有 8 替換為 88。 std::replace(s.begin(), s.end(), 8, 88);// 將所有小于 5 的值替換為 55。std::replace_if(s.begin(), s.end(),std::bind(std::less<int>(), std::placeholders::_1, 5), 55); } -
transform:變換操作
詳細內容可查看:https://en.cppreference.com/w/cpp/algorithm/transform
??
std::transform用于遍歷一個輸入范圍并將每個元素通過一個給定的函數或函數對象進行變換,然后將結果寫入一個輸出范圍。std::transform可以用于實現各種變換操作,比如數學運算、邏輯操作或自定義的函數。類模板一及其實現:
#include <algorithm>template< class InputIt, class OutputIt, class UnaryOp > OutputIt transform( InputIt first1, InputIt last1,OutputIt d_first, UnaryOp unary_op );template<class InputIt, class OutputIt, class UnaryOp> constexpr //< C++20 起 OutputIt transform(InputIt first1, InputIt last1,OutputIt d_first, UnaryOp unary_op) {for (; first1 != last1; ++d_first, ++first1)*d_first = unary_op(*first1);return d_first; }類模板二及其實現:
#include <algorithm>template< class InputIt1, class InputIt2,class OutputIt, class BinaryOp > OutputIt transform( InputIt1 first1, InputIt1 last1, InputIt2 first2,OutputIt d_first, BinaryOp binary_op );template<class InputIt1, class InputIt2, class OutputIt, class BinaryOp> constexpr //< C++20 起 OutputIt transform(InputIt1 first1, InputIt1 last1, InputIt2 first2,OutputIt d_first, BinaryOp binary_op) {for (; first1 != last1; ++d_first, ++first1, ++first2)*d_first = binary_op(*first1, *first2);return d_first; }模板參數說明:
first1,last1: 輸入范圍的開始和結束迭代器。first2: 第二個輸入范圍的開始迭代器(僅在二元變換中使用)。result: 輸出范圍的開始迭代器。op: 一個一元或二元的操作符,用于對元素進行變換。
返回值:指向最后一個變換的元素的輸出迭代器。
示例:
#include <algorithm> // 包含 std::transform #include <vector> #include <iostream>int main() {std::vector<int> v(5); // 創建一個有5個元素的vectorstd::vector<int> m(5);std::fill(v.begin(), v.end(), 1); // 初始化所有元素為1// 將每個元素乘以2std::transform(v.begin(), v.end(), m.begin(), [](int x) { return x * 2; });// 輸出結果: 2 2 2 2 2for (int elem : m) {std::cout << elem << " ";}return 0; }#include <algorithm> // 包含 std::transform #include <vector> #include <iostream>int main() {std::vector<int> v1(5); // 創建兩個有5個元素的vectorstd::fill(v1.begin(), v1.end(), 1); // 初始化v1的所有元素為1std::vector<int> v2(5); std::fill(v2.begin(), v2.end(), 2); // 初始化v2的所有元素為2std::vector<int> result(5); // 創建一個用于存儲結果的vector// 對v1和v2中的元素進行相加操作,結果存儲在result中std::transform(v1.begin(), v1.end(), v2.begin(), result.begin(),[](int x, int y) { return x + y; });// 輸出結果: 3 3 3 3 3for (int elem : result) {std::cout << elem << " ";}return 0; } -
copy:從一個范圍復制元素到另一個范圍
詳細內容可查看https://en.cppreference.com/w/cpp/algorithm/copy
??
std::copy用于從一個范圍復制元素到另一個范圍。它可以接受三個參數:迭代器范圍的開始和結束,以及目標范圍的起始。返回值為指向目標范圍中最后復制元素的下個元素的輸出迭代器。類模板及其實現:
#include <algorithm>template< class InputIt, class OutputIt > OutputIt copy( InputIt first, InputIt last,OutputIt d_first );template<class InputIt, class OutputIt> OutputIt copy(InputIt first, InputIt last,OutputIt d_first) {for (; first != last; (void)++first, (void)++d_first)*d_first = *first;return d_first; }示例:
#include <algorithm> // 包含 std::copy #include <vector> #include <iostream>int main() {std::vector<int> source = {1, 2, 3, 4, 5};std::vector<int> destination;std::copy(source.begin(), source.end(), std::back_inserter(destination));// 輸出復制后的結果for (int elem : destination) {std::cout << elem << " ";}return 0; } // 輸出結果: 1 2 3 4 5 -
copy_if
詳細內容可參考https://zh.cppreference.com/w/cpp/algorithm/copy
??
std::copy_if用于從源范圍復制滿足特定條件的元素到目標范圍。它將源范圍內滿足給定條件的每個元素復制到目標范圍,并且可以返回一個迭代器,指向它放置最后一個元素的目標范圍之后的位置。類模板為
#include <algorithm>template< class InputIt, class OutputIt, class UnaryPred > OutputIt copy_if( InputIt first, InputIt last,OutputIt d_first, UnaryPred pred );template<class InputIt, class OutputIt, class UnaryPred> OutputIt copy_if(InputIt first, InputIt last,OutputIt d_first, UnaryPred pred) {for (; first != last; ++first)if (pred(*first)){*d_first = *first;++d_first;}return d_first; }模板參數為
first、last:要復制的元素范圍d_first:目標范圍的起始pred:函數對象,用于判斷要復制的元素是否滿足條件
示例:
#include <algorithm> // 包含 std::copy_if #include <vector> #include <iostream>bool isEven(int value) {return value % 2 == 0; }int main() {std::vector<int> source = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};std::vector<int> destination;// 復制源中的偶數到目標auto last = std::copy_if(source.begin(), source.end(), std::back_inserter(destination), isEven);// 輸出復制的元素std::cout << "Even numbers: ";for (int num : destination) {std::cout << num << " ";}std::cout << std::endl;return 0; } // 輸出結果: Even numbers: 2 4 6 8 10
排序算法:
??排序算法用于對容器中的元素進行排序,改變輸入序列中元素的順序(容器中的元素需要支持大小判斷)
- 排序:sort、unique
-
sort:排序
詳細內容可查看:https://zh.cppreference.com/w/cpp/algorithm/sort
??
std::sort用于以指定排序方式(默認為非降序排序)排序范圍中的元素。不保證維持相等元素的順序(不穩定的)。類模板為:
#include <algorithm>template< class RandomIt > void sort( RandomIt first, RandomIt last );template< class RandomIt, class Compare > void sort( RandomIt first, RandomIt last, Compare comp );模板參數說明:
first、last:要排序的元素范圍comp:比較函數對象。如默認的非降序排序,在第一參數小于第二參數時返回true。
示例:
#include <algorithm> #include <array> #include <functional> #include <iostream>bool compare(int a, int b) {return a < b; }int main() {std::array<int, 10> s = {5, 7, 4, 2, 8, 6, 1, 9, 0, 3}; auto print = [&s](const std::string rem){for (auto a : s)std::cout << a << ' ';std::cout << ":" << rem << '\n';};std::sort(s.begin(), s.end());print("用默認的 operator< 排序");std::sort(s.begin(), s.end(), std::greater<int>());print("用標準庫比較函數對象排序");struct{bool operator()(int a, int b) const { return a < b; }}customLess;std::sort(s.begin(), s.end(), customLess);print("用自定義函數對象排序");std::sort(s.begin(), s.end(), [](int a, int b){return a > b;});print("用 lambda 表達式排序");std::sort(s.begin(), s.end(), compare);print("用 自定義比較函數 排序"); }運行結果:
0 1 2 3 4 5 6 7 8 9 :用默認的 operator< 排序 9 8 7 6 5 4 3 2 1 0 :用標準庫比較函數對象排序 0 1 2 3 4 5 6 7 8 9 :用自定義函數對象排序 9 8 7 6 5 4 3 2 1 0 :用 lambda 表達式排序 0 1 2 3 4 5 6 7 8 9 :用 自定義比較函數 排序 -
unique:用于去除連續重復的元素
詳細內容可查看:https://en.cppreference.com/w/cpp/algorithm/unique
??
std::unique用于去除連續重復的元素,并將所有未重復的元素移動到容器的前面,返回指向范圍新結尾的尾后迭代器。如果想移除容器中所有重復元素,需要先排序在去重。調用unique之后通常跟隨調用容器的erase成員函數來從容器中實際移除元素。類模板一及實現:
#include <algorithm>template< class ForwardIt > ForwardIt unique( ForwardIt first, ForwardIt last );template<class ForwardIt> ForwardIt unique(ForwardIt first, ForwardIt last) {if (first == last)return last;ForwardIt result = first;while (++first != last)if (!(*result == *first) && ++result != first)*result = std::move(*first);return ++result; }類模板二及其實現:
#include <algorithm>template< class ForwardIt, class BinaryPred > ForwardIt unique( ForwardIt first, ForwardIt last, BinaryPred p );template<class ForwardIt, class BinaryPredicate> ForwardIt unique(ForwardIt first, ForwardIt last, BinaryPredicate p) {if (first == last)return last;ForwardIt result = first;while (++first != last)if (!p(*result, *first) && ++result != first)*result = std::move(*first);return ++result; }模板參數說明:
first、last:要處理的元素范圍p:若元素應被當作相等則返回true
示例:
#include <algorithm> #include <iostream> #include <vector>int main() {// 含有數個重復元素的 vectorstd::vector<int> v{1, 2, 1, 1, 3, 3, 3, 4, 5, 4};auto print = [&] (int id){std::cout << "@" << id << ": ";for (int i : v)std::cout << i << ' ';std::cout << '\n';};print(1);// 移除相繼(毗鄰)的重復元素auto last = std::unique(v.begin(), v.end());// v 現在保有 {1 2 1 3 4 5 4 x x x},其中 x 不確定v.erase(last, v.end());print(2);// sort 后 unique 以移除所有重復std::sort(v.begin(), v.end()); // {1 1 2 3 4 4 5}print(3);last = std::unique(v.begin(), v.end());// v 現在保有 {1 2 3 4 5 x x},其中 x 不確定v.erase(last, v.end());print(4); }運行結果:
@1: 1 2 1 1 3 3 3 4 5 4 @2: 1 2 1 3 4 5 4 @3: 1 1 2 3 4 4 5 @4: 1 2 3 4 5
C++標準庫中還有其他算法,諸如:
搜索算法:對容器中的元素進行搜索,
如:
binary_search:在已排序的容器中進行二分查找。集合算法:用于執行集合操作
set_union:計算兩個集合的并集。set_intersection:計算兩個集合的交集。數值算法:用于數值計算
inner_product:計算兩個容器中相應元素乘積的累加。partial_sum:計算容器中元素的部分和。
2.迭代器分類
??泛型算法使用迭代器實現元素訪問。泛型算法中的迭代器分類是根據它們能夠執行的操作來定義的,每種迭代器都提供了不同的功能和性能保證。

- 輸入迭代器:可讀,可遞增,典型應用為 find 算法
- 輸出迭代器:可寫,可遞增,典型應用為 copy 算法
- 前向迭代器:可讀寫,可遞增,典型應用為 replace 算法
- 雙向迭代器:可讀寫,可遞增遞減,典型應用為 reverse 算法
- 隨機訪問迭代器:可讀寫,可增減一個整數,典型應用為 sort 算法
一些算法會根據迭代器類別的不同引入相應的優化:如 distance 算法。
distance 算法可查看:https://zh.cppreference.com/w/cpp/iterator/distance
類模板:
#include <iterator>template< class InputIt > typename std::iterator_traits<InputIt>::difference_typedistance( InputIt first, InputIt last );namespace detail {template<class It>constexpr // C++17 起要求typename std::iterator_traits<It>::difference_type do_distance(It first, It last, std::input_iterator_tag){typename std::iterator_traits<It>::difference_type result = 0;while (first != last){++first;++result;}return result;}template<class It>constexpr // C++17 起要求typename std::iterator_traits<It>::difference_type do_distance(It first, It last, std::random_access_iterator_tag){return last - first;} } // namespace detailtemplate<class It> constexpr // C++17 起 typename std::iterator_traits<It>::difference_type distance(It first, It last) {return detail::do_distance(first, last,typename std::iterator_traits<It>::iterator_category()); }模板參數為
first:指向首元素的迭代器last:指向尾元素的迭代器返回兩個迭代器之間所需的自增數
一些特殊的迭代器:
??在C++中,迭代器是訪問容器中元素的一種機制。除了普通的迭代器,還有一些特殊的迭代器,它們提供了特定的功能和用途:
-
插入迭代器:back_insert_iterator / front_insert_iterator / insert_iterator
-
back_insert_iterator:用于在容器末尾插入元素
詳細內容可參考:https://zh.cppreference.com/w/cpp/iterator/back_insert_iterator
示例:
#include <vector> #include <iterator>std::vector<int> v; std::back_insert_iterator<std::vector<int>> it(std::back_inserter(v)); *it = 1; // 在v的末尾插入1 ++it; // 移動插入迭代器 *it = 2; // 在v的末尾插入2 -
front_insert_iterator:用于在容器的開頭插入元素
詳細內容可參考:https://en.cppreference.com/w/cpp/iterator/front_insert_iterator
示例:
#include <list> #include <iterator>std::list<int> lst; std::front_insert_iterator<std::list<int>> it(std::front_inserter(lst)); *it = 1; // 在lst的開頭插入1 ++it; *it = 2; // 在lst的開頭插入2 -
insert_iterator:用于在指定位置插入元素
詳細內容可參考:https://zh.cppreference.com/w/cpp/iterator/insert_iterator
示例:
#include <vector> #include <iterator>std::vector<int> v = {1, 2, 3}; std::vector<int>::iterator pos = v.begin() + 1; std::insert_iterator<std::vector<int>> it(std::inserter(v, pos)); *it = 4; // 在位置pos插入4 ++it; *it = 5; // 在位置pos之后插入5
-
-
流迭代器:istream_iterator / ostream_iterator
-
istream_iterator :用于從輸入流讀取元素
詳細內容可參考:https://en.cppreference.com/w/cpp/iterator/istream_iterator
示例:
#include <iostream> #include <iterator> #include <sstream>int main() {std::istringstream str{"1 2 3 4 5"};std::istream_iterator<int> x{str};std::cout << *x << std::endl; //1++x;std::cout << *x << std::endl; //2 } -
ostream_iterator:用于向輸出流寫入元素
詳細內容可參考:https://zh.cppreference.com/w/cpp/iterator/ostream_iterator
示例:
#include <iostream> #include <iterator> #include <algorithm> #include <numeric>int main() {std::ostream_iterator<char> oo{std::cout};std::ostream_iterator<int> i1{std::cout, ", "};std::fill_n(i1, 5, -1);*oo++ = '\n'; }運行結果:
-1, -1, -1, -1, -1, -
反向迭代器
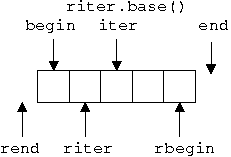
示例:
#include <iostream> #include <vector> #include <iterator> #include <numeric>int main() {std::vector<int> x{1, 2, 3, 4, 5};std::copy(x.rbegin(), x.rend(), std::ostream_iterator<int>(std::cout, ", "));//5,4,3,2,1 } -
移動迭代器:move_iterator
詳細內容可參考:https://zh.cppreference.com/w/cpp/iterator/move_iterator
#include <algorithm> #include <iomanip> #include <iostream> #include <iterator> #include <ranges> #include <string> #include <string_view> #include <vector>void print(const std::string_view rem, const auto& v) {std::cout << rem;for (const auto& s : v)std::cout << std::quoted(s) << ' ';std::cout << '\n'; };int main() {std::vector<std::string> v{"this", "_", "is", "_", "an", "_", "example"};print("vector 的舊內容:", v);std::string concat;for (auto begin = std::make_move_iterator(v.begin()),end = std::make_move_iterator(v.end());begin != end; ++begin){std::string temp{*begin}; // moves the contents of *begin to tempconcat += temp;}// 從 C++17 起引入了類模板實參推導,可以直接使用 std::move_iterator 的構造函數:// std::string concat = std::accumulate(std::move_iterator(v.begin()),// std::move_iterator(v.end()),// std::string());print("vector 的新內容:", v);print("拼接成字符串:", std::ranges::single_view(concat)); }運行結果:
vector 的舊內容:"this" "_" "is" "_" "an" "_" "example" vector 的新內容:"" "" "" "" "" "" "" 拼接成字符串:"this_is_an_example"
-
迭代器與哨兵(C++20):
??哨兵(Sentinel)是C++20中引入的一個新概念,它提供了一種更靈活的方式來指定容器或序列的結束。哨兵可以是一個迭代器,也可以是任何可以與迭代器一起工作以表示范圍結束的對象。
示例:假設有一個容器和一個哨兵,遍歷這個容器直到哨兵指定的位置
#include <iostream>
#include <vector>class Sentinel {
public:Sentinel(size_t limit) : limit_(limit) {}bool operator!=(const size_t& value) const { return value < limit_; }
private:size_t limit_;
};int main() {std::vector<int> v = {1, 2, 3, 4, 5};Sentinel s(3); // 哨兵,表示遍歷到第三個元素為止for (size_t i = 0; s != i; ++i) {std::cout << v[i] << " ";}// 輸出結果: 1 2 3return 0;
}
Sentinel 類定義了一個哨兵,它在遍歷達到限制值時停止。在 main 函數中,我們使用哨兵 s 來控制循環的結束條件。
并發算法(C++17 / C++20):
詳細內容可參考:https://zh.cppreference.com/w/cpp/algorithm/execution_policy_tag_t
??C++并發算法是C++17標準引入的一部分,旨在提供一種更簡便的方式來并行化算法的執行。這些算法可以利用多核處理器的計算能力,提高程序的性能。這些并發策略定義在<execution>頭文件中,并且與標準算法一起使用。下面介紹并發策略
-
std::execution::seq(C++17)這個策略指示算法以順序方式執行,不進行并行化。這是默認的執行策略,即使不顯式指定,算法也會以這種方式執行。
-
std::execution::par(C++17)這個策略指示算法以并行方式執行,但可能使用非順序的內存訪問。這意味著算法可能會在多個線程上同時執行,但不會保證對共享內存的訪問順序。
-
std::execution::par_unseq(C++17)這個策略指示算法以并行方式執行,并且可以完全忽略內存順序。這是最激進的并行策略,算法可以在任何線程上執行任何操作,且不對內存訪問順序做任何保證。
-
std::execution::unseq(C++20)這個策略指示算法可以以未序列化的方式執行,但不一定并行。這意味著算法可能會重疊操作,但不會創建額外的線程。
注意:
在使用并行執行策略時,避免數據競爭和死鎖是程序員的責任。
并發算法的使用需要編譯器支持C++17或更高版本,并可能需要特定的編譯器標志來啟用并發支持。
如在Linux上需要加
-O3與-ltbb
示例:
#include <iostream>
#include <algorithm>
#include <chrono>
#include <random>
#include <ratio>
#include <vector>
#include <execution>int main()
{std::random_device rd;std::vector<double> vals{10000000};for (auto& d : vals){d = static_cast<double>(rd());}for (int i =0; i < 5; ++i){using namespace std::chrono;std::vector<double> sorted{vals};const auto startTime = high_resolution_clock::now();std::sort(std::execution::par, sorted.begin(), sorted.end());const auto endTime = high_resolution_clock::now();std::cout << "Latency: "<< duration_cast<duration<double, std::milli>>(endTime - startTime).count()<< std::endl;}
}
二、bind與lambda表達式
??在C++中,許多標準庫算法允許通過傳遞可調用對象(Callable Objects)來自定義計算邏輯的細節。這些可調用對象可以是函數、lambda表達式、函數對象或任何可調用的模板實例。使用可調用對象提供了一種高度靈活的方式來定義算法的具體操作,而無需修改算法本身的實現。
以下是一些常見的C++算法,它們接受可調用對象作為參數:
std::for_eachstd::transformstd::accumulatestd::sortstd::copy_ifstd::remove_ifstd::find_if
??如何定義可調用對象,有如下幾種方式:
- 函數指針:概念直觀,但定義位置受限(C++不支持在函數中定義函數)
- 類:功能強大,但書寫麻煩
- bind :基于已有的邏輯靈活適配,但描述復雜邏輯時語法可能會比較復雜難懂,可能需要bind套bind
- lambda 表達式:小巧靈活,功能強大
1.bind
詳細內容可參考:https://zh.cppreference.com/w/cpp/utility/functional/bind
??在C++中,std::bind 是一個函數模板,它用于修改可調用對象的調用方式(通常稱為綁定器),這個綁定器可以固定一個或多個參數,并且可以稍后與剩余的參數一起被調用。std::bind 定義在 <functional> 頭文件中。
類模板定義:
#include <functional>template< class F, class... Args >
/* unspecified */ bind( F&& f, Args&&... args );
模板參數說明:
-
f:可調用的對象(如函數、函數對象、lambda表達式)。 -
args:要綁定實參的列表,這里面可能會用到占位符如:
std::placeholders::_1,std::placeholders::_2等,用于在綁定時保留位置,這些占位符可以被后續調用時提供的參數替換,如:_1表示后續調用時傳入的第一個參數
缺點:
-
調用
std::bind時,傳入的參數會被復制,這可能會產生一些調用風險,如#include <functional> #include <iostream>void Myproc(int *ptr) {}auto fun() {int x;return std::bind(Myproc, &x); }int main() {auto ptr = fun(); //固定的參數為局部對象,有危險,可以嘗試使用智能指針shared_ptr } -
可以使用
std::ref或std::cref避免復制的行為#include <functional> #include <iostream>void Proc(int& x) {++x; }int main() {int x = 0;auto b = std::bind(Proc, std::ref(x));b();std::cout << x << std::endl; //1,若不加std::ref,則返回0 }
示例1:使用占位符
#include <functional>
#include <iostream>int reduce(int a, int b) {return a - b;
}int main() {using namespace std::placeholders;// 綁定函數reduce和占位符_1, _2auto reducer_1 = std::bind(reduce, 10, _1);auto reducer_2 = std::bind(reduce, _1, 10);auto reducer_3 = std::bind(reduce, _1, _2);std::cout << reducer_1(20) << " " << reducer_2(20) << " " << reducer_3(5, 3) << std::endl; return 0;
}
運行結果:
-10 10 2
示例2:綁定成員函數
#include <functional>
#include <iostream>class Counter {
public:int count() const { return count_; }void increment() { ++count_; }
private:int count_ = 0;
};int main() {Counter c;auto boundIncrement = std::bind(&Counter::increment, &c);boundIncrement(); // 調用Counter的increment成員函數std::cout << c.count() << std::endl; // 輸出: 1return 0;
}
示例3:綁定lambda表達式
#include <functional>
#include <iostream>int main() {auto add = [](int a, int b) { return a + b; };auto addFive = std::bind(add, std::placeholders::_1, 5);std::cout << addFive(3) << std::endl; // 輸出: 8return 0;
}
std::bind_front(C++20引入):std::bind 的簡化形式
詳細內容可參考:https://en.cppreference.com/w/cpp/utility/functional/bind_front
2.lambda表達式
詳細內容可參考:https://zh.cppreference.com/w/cpp/language/lambda
參考書籍:《C++ Lambda Story》
??C++ lambda 表達式是一種便捷的匿名函數語法,允許你在需要時快速定義一個函數對象,而無需顯式定義一個完整的函數或函數對象類。自C++11標準引入lambda表達式以來,它們在后續的C++標準中得到了持續的更新和增強。
- C++11 引入 lambda 表達式
- C++14 支持初始化捕獲、泛型 lambda
- C++17 引入 constexpr lambda , *this 捕獲
- C++20 引入 concepts ,模板 lambda
lambda 表達式會被編譯器翻譯成類進行處理
??這個用C++ Insights來分析。
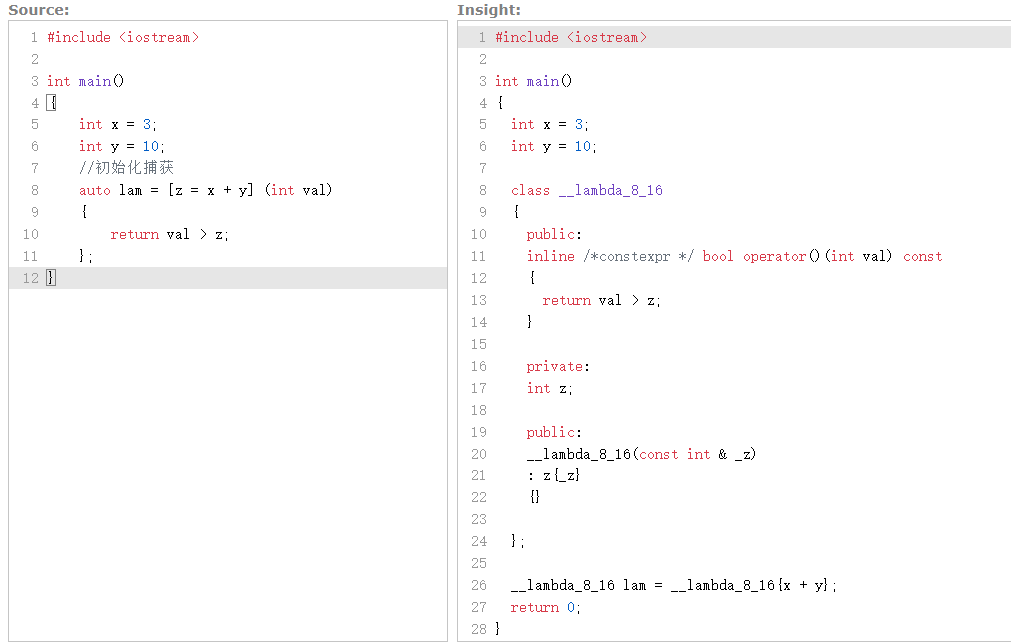
??lambda表達式定義了一個匿名函數,并且可以捕獲一定范圍內的變量。語法形式如下:
[caputer list] (parameters) mutable throw() -> return type{ statement }
各部分介紹:
caputer list是捕獲列表。在C++規范中也稱為lambda導入器,捕獲列表總是出現在lambda函數的開始處。實際上,[]是Lambda引出符。編譯器根據該引出符判斷接下來的代碼是否是lambda函數,捕獲列表能夠捕捉上下文中的變量以供lambda函數使用。parameters是參數列表。與普通函數的參數列表一致。如果不需要參數傳遞,則可以連同括號“()”一起省略。mutable關鍵字。默認情況下Lambda函數總是一個const函數,mutable可以取消其常量性。加上mutable關鍵字后,可以修改傳遞進來的拷貝,在使用該修飾符時,參數列表不可省略(即使參數為空)。throw是異常說明。用于Lamdba表達式內部函數拋出異常。return type是返回值類型。 追蹤返回類型形式聲明函數的返回類型。我們可以在不需要返回值的時候也可以連同符號”->”一起省略。此外,在返回類型明確的情況下,也可以省略該部分,讓編譯器對返回類型進行推導。statement是Lambda表達式的函數體。內容與普通函數一樣,不過除了可以使用參數之外,還可以使用所有捕獲的變量。
注意:可以忽略參數列表和返回類型,但必須永遠包含捕獲列表和函數體
lambda 表達式的基本組成部分:
-
參數與函數體
Lambda表達式可以有零個或多個參數,并包含一個由花括號
{}包圍的函數體。如:[](int x, int y) { return x + y; } -
返回類型
Lambda的返回類型可以顯式指定,也可以由編譯器根據函數體推斷。如果函數體中只有一個返回語句,并且沒有其他語句,編譯器可以自動推斷返回類型。
[](int x, int y) -> int { return x + y; } -
捕獲:針對函數體中使用的局部自動對象進行捕獲
-
值捕獲
值捕獲意味著捕獲的變量通過值傳遞給lambda表達式,即在lambda表達式中創建了這些變量的副本。因此,lambda表達式中使用的是這些變量的副本,而不是原始變量本身。
void func() {size_t v1 = 42;//局部變量//將 v1 拷貝到名為 f 的可調用對象auto f = [v1]{return v1;};v1 = 0;auto j = f();//j為42;f保存了我們創建它時 v1 的拷貝 }由于被捕獲變量的值是在創建時拷貝,因此隨后對其求改不會影響到 lambda 內對應的值。
-
引用捕獲
引用捕獲意味著捕獲的變量通過引用傳遞給lambda表達式,即lambda表達式中使用的是原始變量的引用,這意味著可以在lambda內部修改這些變量的值。
void func1() {size_t v1 = 42;//局部變量//對象 f2 包含 v1 的引用auto f2 = [&v1]{return v1;};v1 = 0;auto j = f2();//j為0;f2保存v1的引用,而非拷貝 }引用捕獲和返回引用有著相同的問題和局限。如果我們采用引用方式捕獲一個變量,就必須確保被引用的對象在 lambda 執行的時候是存在的。lambda 捕獲的都是局部變量,這些變量在函數結束后就不復存在了。如果 lambda 可能在函數結束后執行,捕獲的引用指向的局部變量已經消失,造成未定義行為。
-
混合捕獲
混合捕獲允許在同一個lambda表達式中同時使用值捕獲和引用捕獲。
-
隱式捕獲與顯示捕獲
除了顯式的列出我們希望使用的來自所在函數的變量之外,還可以讓編譯器根據 lambda 體中的代碼來推斷我們要使用哪些變量。為了指示編譯器推斷捕獲列表,應在捕獲列表中寫一個
&或者=。&告訴編譯器采用捕獲引用方式,=則表示采用值捕獲方式。//sz為隱式捕獲,值捕獲方式 wc = find_if(words.begin(), words.end(),[=](const string &s){return s.size() >= sz;});如果我們希望對一部分變量采用值捕獲,對其他變量采用引用捕獲,可以混合使用隱式捕獲和顯式捕獲:
void biggies(vecotr<string> &words, vecotr<string>::size_type sz, ostream &os = cout, char c =' '){//其他處理與前例一樣//os隱式捕獲,引用捕獲方式;c顯示捕獲,值捕獲方式for_each(words.begin(), words.end(), [&,c](const string &s){os << s << c;});//os顯式捕獲,引用捕獲方式;c隱式捕獲,值捕獲方式for_each(words.begin(), words.end(), [=,&os](const string &s){os << s << c;}); }當我們混合使用了隱式捕獲和顯式捕獲時,捕獲列表中的第一個元素必須是一個 & 或 =。此符號指定了默認捕獲方式為引用或值。
??當混合使用隱式捕獲和顯示捕獲時,顯示捕獲的變量必須使用與隱式捕獲不同的方式。即,如果隱式捕獲是引用方式(使用了&)則顯式捕獲命名變量必須采用值方式,因此不能在其名字前使用 & 。類似的,如果隱式捕獲采用的是值方式(使用了=),則顯式捕獲命名變量必須采用引用方式,即,在名字前使用&。
-
this 捕獲(類與結構體中用到,其中
*this捕獲為 C++17 中引入的)??在C++中,
this捕獲是lambda表達式中的一種特殊捕獲形式,它允許將當前對象的指針(this指針)傳遞給lambda表達式。這在成員函數中特別有用,因為它們通常需要訪問或修改類的狀態。??當在類的成員函數中定義lambda表達式時,可以使用
[*this]或[this]來捕獲this指針。這允許lambda表達式訪問類的成員變量和成員函數。[*this]:通過值捕獲整個對象的副本。這通常用于創建線程安全的lambda表達式,因為它捕獲了對象的一個獨立副本。[this]:通過引用捕獲this指針。這允許lambda表達式訪問原始對象的狀態,但不會創建對象的副本。
示例1:通過引用捕獲this指針
class MyClass { public:int value;void memberFunction() {// 使用this指針訪問類的成員auto lambda = [this] {value += 10; // 直接修改類的成員變量};lambda(); // 執行lambda表達式} };示例2:通過值捕獲整個對象的副本
class MyClass { public:int value;void memberFunction() {// 捕獲對象的副本auto lambda = [*this] {value += 10; // 修改對象副本的成員變量};lambda(); // 執行lambda表達式} };lambda通過值捕獲了整個MyClass對象的副本。這意味著lambda內部對value的修改不會影響原始對象的狀態。注意:
在多線程環境中,通過值捕獲對象(使用
[*this])可以提供線程安全性,因為每個線程操作的是對象的獨立副本。 -
初始化捕獲(C++14)
允許在捕獲列表中初始化變量,而不需要在外部作用域中預先定義它們。
示例1:
#include <iostream>int main() {std::string a = "hello";//初始化捕獲auto lam = [y = std::move(a)] (){std::cout << y << std::endl; };std::cout << a << std::endl;lam(); }示例2:
#include <iostream>int main() {int x = 3;int y = 10;//初始化捕獲auto lam = [z = x + y] (int val){return val > z; }; }構造一個對象z用于lambda表達式,這個對象會用值捕獲的 x + y來初始化。
-
-
說明符
-
mutable
mutable說明符用于lambda表達式,允許在const上下文中修改捕獲的變量。通常,捕獲的變量如果是通過值捕獲的,那么它們在const函數中不能被修改。但是,如果lambda表達式聲明為mutable,即使在const成員函數中,也可以修改這些捕獲的變量。示例:
int main() {int value = 10;auto lambda = [value] (int val) mutable { value += 5; return val > value;};lambda(5); } -
constexpr(C++17)
constexpr說明符用于lambda表達式,允許該lambda表達式在constexpr上下文中使用。constexpr函數或變量必須在編譯時就能確定其值,因此它們可以用于常量表達式。從C++17開始,lambda表達式也可以聲明為constexpr,這意味著它們的執行結果可以在編譯時計算。示例:
int main() {auto lam = [](int val) constexpr{return val + 1;};constexpr int val = lam(100); } -
consteval (C++20)
當
consteval用于lambda表達式時,它表明該lambda表達式旨在作為編譯時常量表達式執行,并且其執行結果應在編譯時確定。
-
lambda表達式的深入應用:
-
捕獲時計算( C++14 )
在C++14中,可以在捕獲列表中直接初始化變量,這被稱為捕獲時計算。這意味著可以在捕獲時直接對變量進行計算,而不需要在外部作用域中預先定義它們。
-
即調用函數表達式( Immediately-Invoked Function Expression, IIFE )
lambda表達式創建后并立即執行
#include <iostream>int main() {int x = 3;int y = 10;//初始化捕獲const auto val = [z = x + y] (l){return z; }(); } -
使用 auto 避免復制( C++14 )
在C++14中,你可以在參數列表中使用
auto關鍵字,這樣lambda表達式將嘗試避免創建參數的副本int main() {auto lam = [](auto x){return x + 1;}; }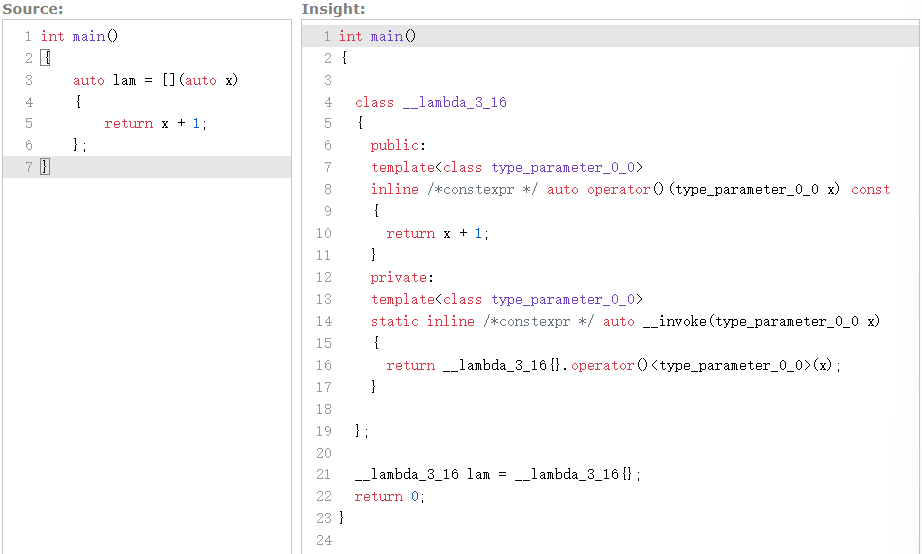
-
Lifting( C++14 )一種技巧,參數列表中使用
auto關鍵字,會被編譯器定義成模板參數,因此,可傳入不同類型參數,且調用對應的fun()函數。示例:
#include <iostream> #include <functional> #include <map>auto fun(int val) {return val + 1; }auto fun(double val) {return val + 1; }int main() {auto lam = [](auto x){return fun(x);};std::cout << fun(3) << std::endl; //4std::cout << fun(3.5) << std::endl; //4.5 } -
遞歸調用( C++14 )
Lambda表達式可以遞歸地調用自身,只要它們捕獲了自身或者通過其他方式在函數體內是可訪問的。
示例:
#include <iostream>int main() {auto factorial = [](int n){auto f_impl = [](int n, const auto& impl) ->int{return n > 1 ? n * impl(n-1, impl) : 1;};return f_impl(n, f_impl);};}編譯器可以翻譯成:
#include <iostream>int main() {class __lambda_5_22{public: inline int operator()(int n) const{class __lambda_7_23{public: template<class type_parameter_0_0>inline int operator()(int n, const type_parameter_0_0 & impl) const{return n > 1 ? n * impl(n - 1, impl) : 1;}/* First instantiated from: insights.cpp:11 */#ifdef INSIGHTS_USE_TEMPLATEtemplate<>inline int operator()<__lambda_7_23>(int n, const __lambda_7_23 & impl) const{return n > 1 ? n * impl.operator()(n - 1, impl) : 1;}#endifprivate: template<class type_parameter_0_0>static inline int __invoke(int n, const type_parameter_0_0 & impl){return __lambda_7_23{}.operator()<type_parameter_0_0>(n, impl);}public: // inline /*constexpr */ __lambda_7_23(__lambda_7_23 &&) noexcept = default;};__lambda_7_23 f_impl = __lambda_7_23(__lambda_7_23{});return f_impl.operator()(n, f_impl);}using retType_5_22 = int (*)(int);inline operator retType_5_22 () const noexcept{return __invoke;};private: static inline int __invoke(int n){return __lambda_5_22{}.operator()(n);}public: // inline /*constexpr */ __lambda_5_22(__lambda_5_22 &&) noexcept = default;};__lambda_5_22 factorial = __lambda_5_22(__lambda_5_22{});return 0; }
三、泛型算法的改進–ranges(c++20)
??C++20 引入了 ranges 庫,這是一個對標準庫中的泛型算法的重大改進。ranges 庫提供了一種新的方式來處理序列,特別是容器,使得代碼更簡潔、更安全、更易于理解。
-
使用容器而非迭代器作為輸入
在 C++20 之前,標準庫算法通常需要迭代器來指定容器的開始和結束。ranges 庫允許直接傳遞整個容器作為參數,從而簡化了代碼。
通過 std::ranges::dangling 避免返回無效的迭代器
??在某些情況下,算法可能返回一個迭代器,該迭代器在某些操作后(如容器的重新分配)變得無效。C++20 引入了
std::ranges::dangling類型,用于明確表示返回的是一個可能無效的迭代器。示例:
#include <ranges> #include <vector> #include <iostream>int main() {std::vector<int> v = {1, 2, 3, 4, 5};auto is_even = std::ranges::views::transform([](int x) { return x % 2 == 0; });auto evens = v | is_even;for (auto e : evens) {std::cout << (e ? "even" : "odd") << '\n';} } -
從類型上區分迭代器與哨兵
ranges 庫強化了迭代器和哨兵(sentinel)的概念,迭代器用于遍歷元素,而哨兵用于表示范圍的結束。這使得算法的接口更加清晰。
-
引入映射概念,簡化代碼編寫
ranges 庫引入了
std::ranges::views::transform,它允許對序列中的每個元素應用一個函數,并創建一個新的視圖(view)來表示變換后的結果,而不是復制整個序列。 -
引入 view ,靈活組織程序邏輯
views 是 ranges 庫的核心概念之一,它們是對原始序列的一種抽象表示,可以透明地應用變換和組合操作。views 是懶加載的,這意味著它們所代表的操作直到真正需要結果時才會執行。
示例:
#include <ranges> #include <vector> #include <iostream>int main() {std::vector<int> v = {1, 2, 3, 4, 5};auto squared = std::ranges::views::transform(v, [](int x) { return x * x; });for (int sq : squared) {std::cout << sq << ' ';}std::cout << '\n'; }



















