Multi-objective reinforcement learning approach for trip recommendation

A B S T R A C T
行程推薦是一項智能服務,為游客在陌生的城市提供個性化的行程規劃。 它旨在構建一系列有序的 POI,在時間和空間限制下最大化用戶的旅行體驗。 將候選 POI 添加到推薦行程時,根據實時上下文捕獲用戶的動態偏好至關重要。 同時,個性化出行中POI的多樣性和流行度對用戶的選擇起著重要作用。 為了應對這些挑戰,在本文中,我們提出了 **MORL-Trip(旅行推薦多目標強化學習的縮寫)**方法。 MORL-Trip 將個性化旅行推薦建模為馬爾可夫決策過程 (MDP),并在 Actor-Critic 框架上實現。 MORL-Trip 通過順序信息、地理信息和順序信息增強狀態表示,以從實時位置了解用戶的上下文。 此外,MORL-Trip 通過設計復合獎勵函數來增強標準 Critic 組件,以實現三個主要目標:準確性、流行度和多樣性。
1. Introduction
隨著移動設備和無線網絡的普及,基于位置的社交網絡(LBSNs)如Flickr, Foursquare和Gowalla在全球范圍內廣泛應用。在這些LBSNs中,用戶可以分享他們的體驗和興趣點(POI)訪問信息。用戶在LBSNs中主動或被動地留下地理位置信息,生成大規模的時空軌跡數據。通過挖掘這些數據記錄,智能旅游服務可以分析用戶的潛在需求,并建議未訪問過的地點以匹配用戶的興趣。這不僅有助于用戶更好地探索吸引人的POIs,還可以幫助公司識別更多潛在用戶,從而提高經濟效益。
作為一種流行的智能旅游服務,行程推薦在工業界和學術界受到了廣泛關注。行程推薦是一個復雜且具有挑戰性的任務,需要發現符合用戶偏好的吸引人的POIs,并在多個約束條件下將這些POIs連接成有序的序列。近年來,許多方法被提出以解決行程推薦問題。例如,Lim等(2018)利用POI的受歡迎程度和用戶偏好為游客生成合適的行程。用戶偏好根據POI類別的訪問頻率計算。然而,這種方法無法為訓練集中從未訪問過某類POI的用戶推薦個性化的行程。為解決這一問題,Chen, Zhang等(2020)將POI類別和POI文本信息融合到行程推薦中,并利用無監督深度神經網絡框架生成個性化行程。為了學習行程中POIs之間的語義順序信息,Gao等(2021)提出了一個結合地理和時間信息的編碼-解碼框架。為了捕捉行程中POI轉換模式的語義,Zhou, Wu等(2020)開發了基于RNN的行程生成方法,使用軌跡-軌跡深度神經網絡(Ma等,2022)。盡管現有方法在推薦結果上取得了不錯的成績,但在行程推薦中仍然存在以下挑戰:
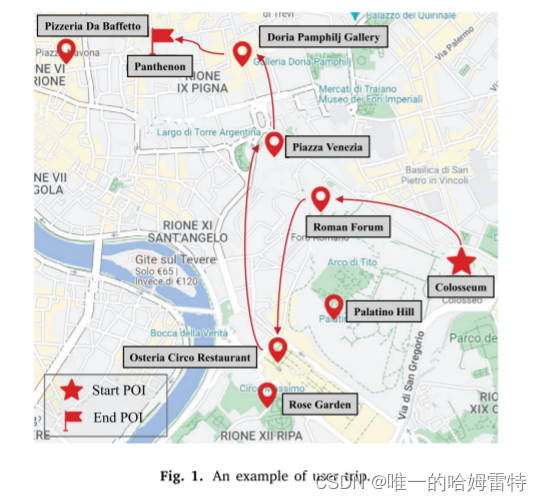
首先,行程推薦是一個動態過程,地理信息和用戶偏好會隨時間變化。為了說明這一點,給出了圖1中的一個示例。在參觀了“Colosseum”和“Roman Forum”之后,長時間的步行可能會讓游客感到疲憊并改變其偏好。與附近的POI“Palatino Hill”相比,該用戶更傾向于選擇一家餐廳(例如“Pizzeria Da Baffetto”或“Osteria Circo Restaurant”)進行晚餐和休息。同時,受當前地理位置的影響,他/她決定訪問離“Roman Forum”更近的“Osteria Circo Restaurant”。因此,在行程推薦中獲取實時信息并根據用戶當前的上下文信息推薦下一個POI可以幫助提高推薦的準確性。
其次,當前POI的選擇對后續POIs的選擇有重要影響。大多數個性化行程推薦方法(Gao等,2019)關注即時獎勵,即讓用戶訪問推薦的POIs,而忽略了推薦POIs對長期獎勵的影響。例如,在參觀了POI“Osteria Circo Restaurant”之后,盡管POI“Rose Garden”比POI“Piazza Venezia”更近,用戶仍然選擇訪問POI“Piazza Venezia”,因為在參觀了POI“Piazza Venezia”之后,他/她可以參觀附近的POIs“Doria Pamphilj Gallery”和“Pantheon”,從而獲得更好的旅行體驗。因此,從長遠來看,考慮未來獎勵可以幫助用戶享受更好的旅行體驗。
第三,雖然大多數行程推薦方法側重于提高推薦的準確性,但推薦質量的其他重要方面(如行程多樣性和行程受歡迎程度)通常被忽視。行程中POIs的多樣性和受歡迎程度也會影響游客的旅行體驗。由于游客通常希望在同一行程中探索不同類別的POIs,一個包含類別過少的POI的行程會讓游客感到無聊。然而,絕大多數行程推薦方法(Fu等,2022;Sarkar等,2020;Zhou等,2021)關注POI相關性,并在多樣性和新穎性方面付出了顯著代價。它們通常根據用戶訪問頻率推薦POI類別,這將使行程中的POI類別非常單一,降低游客的旅行體驗質量。
為了解決上述挑戰,本文提出了一種多目標強化學習方法用于行程推薦(稱為MORL-Trip)。具體來說,我們將個性化行程推薦建模為馬爾可夫決策過程(MDP),并利用基于強化學習的方法自動訓練和更新最優推薦策略。首先,我們設計了序列級、地理級和順序級表示來學習更準確的用戶實時上下文。然后,我們提出創建一個包含準確性、受歡迎程度和多樣性獎勵的獎勵函數,以做出更準確、受歡迎和多樣的推薦。最后,我們利用深度確定性策略梯度(DDPG)算法訓練所提出的模型。總之,本文的貢獻如下:
- 我們將行程推薦任務建模為MDP,用戶偏好基于實時上下文是復雜且動態的,并實現了一個RL框架來形成整個過程。
- 我們通過設計新的狀態表示和獎勵函數擴展了MDP框架用于個性化行程推薦。通過這些擴展,MORL-Trip可以做出更準確、受歡迎和多樣的行程推薦。
- 在公共數據集上進行了綜合實驗評估,結果表明MORL-Trip在行程推薦中能夠持續優于基線方法。
2. Related work
2.1. Trip recommender systems
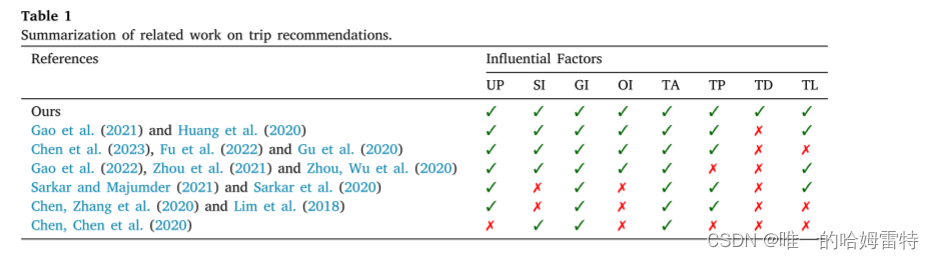
行程推薦系統嘗試設計由一些有序 POI 組成的行程,在預定義的約束下最大限度地提高用戶滿意度。 個性化行程推薦是一項復雜的任務,因為它需要考慮很多因素,如用戶偏好(UP)、順序信息(SI)、地理信息(GI)、訂單信息(OI)、行程準確度(TA)、行程流行度(TA)等。 TP)、行程多樣性(TD)和行程長度(TL)。 表1概述了個性化旅行推薦的相關工作,并展示了我們的論文與現有研究之間的差異。 在這些因素中,用戶偏好對于設計個性化出行起著決定性作用。 早期的工作(Yahi et al., 2015)要求用戶明確說明他們對旅行推薦的偏好。 然而,這個過程非常耗時且不方便。 為了解決這個問題,一些研究引入POI類別信息來計算用戶偏好。 這些研究的想法是,用戶對 POI 類別的偏好與用戶訪問此類 POI 的頻率或在此類 POI 上花費的時間有關。 例如,Lim 等人。 (2018)提出了基于類別的用戶偏好的旅行推薦概念,其中訪問持續時間也通過基于類別的用戶偏好來預測,以更準確地反映現實生活。 布里蘭特等人。 (2015) 引入 TripBuilder 算法來規劃包含 POI 的個性化旅行,根據 POI 類別最大化用戶偏好。 然而,如果用戶沒有訪問過訓練集中某個類別的任何POI,則上述方法無法為該用戶推薦個性化旅行。
2.2. Deep reinforcement learning for recommendations
3. Background and motivation
3.1. Preliminaries



3.2. Motivation
目前研究方法的不足

強化學習在推薦系統中展示了其神奇之處,自然適合動態跟蹤用戶偏好變化。因此,我們通過強化學習框架來形式化行程推薦任務。同時,與僅專注于提高推薦準確性的現有行程推薦方法不同,我們提出的方法還考慮了行程多樣性和行程熱度。在這個多目標問題中,下一個訪問的 POI 被視為一個變量,并且獎勵值將根據 POI 的準確性、行程熱度和行程多樣性來計算。我們將推薦行程的長度限制在實際行程的長度內。
4. The MORL-Trip approach
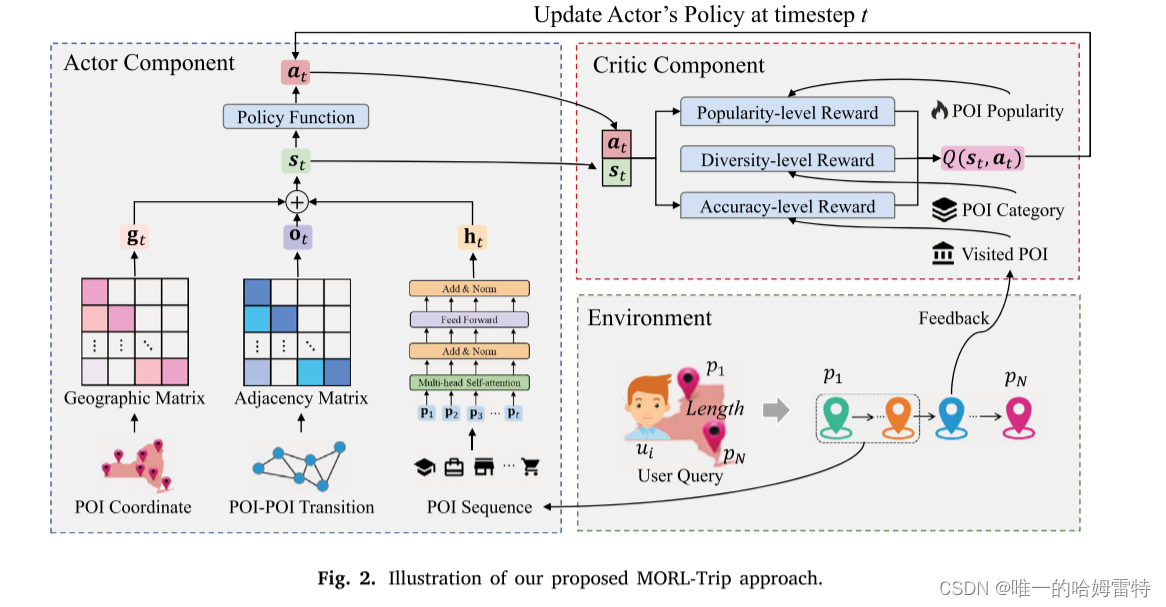
大多數現有的行程推薦方法嘗試以具有多重約束的旅行序列形式推薦一組POI。然而,它們忽略了用戶當前狀態對選擇下一個POI的影響,無法跟蹤用戶偏好的動態變化。為了建模用戶偏好變化并考慮個性化行程的準確性、熱度和多樣性,我們提出了一種多目標強化學習方法。
如圖2所示,MORL-Trip方法由演員(Actor)和評論者(Critic)組件組成。演員組件旨在根據用戶的實時狀態適當地生成下一個POI。評論者組件用于評估演員推薦策略的偏好。
4.1. The architecture of actor framework
Actor組件用于根據用戶當前狀態獲取最合適的POI。構建Actor組件的關鍵在于獲取用戶的狀態。在本文中,我們考慮了用戶的歷史旅行記錄、地理信息和POI-POI轉移模式,以設計一個全面的狀態表示。這種用戶狀態表示是通過結合序列級、地理級和順序級狀態表示來計算的。
4.1.1. Sequence-level state representations
Transformer 已廣泛應用于順序或時間序列數據,其中每個元素通過自注意力機制由其他元素及其自身表示(Fu et al., 2020)。 我們使用 Transformer Encoder 來學習用戶之前 POI 訪問序列的順序特征。 具體來說,給定一個 POI 訪問序列 𝑃1∶𝑡 = {𝑝1, 𝑝2,…, 𝑝𝑡}, 𝐏𝑡 = {𝐩1, 𝐩2,…, 𝐩𝑡} 是序列表示,𝐩𝑖 是維度 𝑑 的 POI 嵌入向量,由 Word2vec 計算 模型(Mikolov et al., 2013; Ye et al., 2021),最初是為詞嵌入而設計的。 為了利用 POI 順序信息,我們通過串聯運算符將位置嵌入(Vaswani 等人,2017)進一步融合到 POI 嵌入中。
4.1.2. Geography-level state representations
用戶當前位置與其他 POI 之間的地理關系對于選擇下一個 POI 起著重要作用。 用戶傾向于前往距離當前位置不遠的 POI 進行觀光游覽。 因此,我們設計地理級狀態表示來捕獲當前位置的地理信息。 地理級狀態表示的設計基于這樣的直覺:POI距離當前位置越遠,被訪問的概率越低。


4.1.3. Order-level state representations
除了地理因素外,POI-POI的公交模式也會影響用戶對下一個POI的選擇。 流行且有吸引力的參觀模式可能涉及商業活動、商業展位、表演和展覽,這可以改善用戶體驗。 因此,從一個訪問過的 POI 到其他 POI 的轉移概率是一種非均勻分布。 訂單級狀態表示的設計是根據直覺,即POI與當前位置之間的轉移概率越大,該POI被訪問的概率就越大。

4.1.4. Recommendation policy learning

4.2. The architecture of critic framework

4.3. Reward decomposition

4.3.1. Accuracy-level reward

4.3.2. Popularity-level reward

4.3.3. Diversity-level reward

4.4. Training algorithm
MORL-Trip 旨在聯合優化與用戶滿意度密切相關的三個相互沖突的目標。 我們設計了一個復合獎勵函數,能夠計算這三個目標,即 POI 相關性、旅行受歡迎程度和旅行多樣性。 我們還建議使用順序信息、地理信息和順序信息來增強狀態表示,以從實時位置了解用戶的上下文。 考慮到高維和連續動作空間的問題,我們采用深度確定性策略梯度(DDPG)來訓練演員-評論家網絡。 DDPG在DPG的基礎上結合了DQN的概念。 具體來說,Critic 是通過最小化以下損失函數來訓練的









)


)
)


)





——numpy和pandas)