
文章目錄
目錄
文章目錄
前言
一、vector使用時的注意事項
? ? ? ? 1.typedef的類型
? ? ? ? 2.vector不是string
? ? ? ? 3.vector
? ? ? ? 4.算法sort
二、vector的實現
? ? ? ? 1.通過源碼進行猜測vector的結構
? ? ? ? 2.初步vector的構建
2.1 成員變量
2.2成員函數
? ? ? ? 2.2.1尾插和擴容
? ? ? ? ??2.2.2operator[]
? ? ? ? 2.2.3? 迭代器
? ? ? ? 2.2.4尾刪、指定位置刪除和插入
?3指定位置刪除和插入和迭代器失效
? ? ? ? 3.1insert和迭代器野指針問題
? ? ? ? 3.2erase和迭代器失效
4.拷貝構造
5.operator=賦值
6.迭代器區間初始化
7.n個val初始化和編譯器匹配問題
三、{}的使用
?四、vector的問題
前言
? ? ? ? vector的使用方法和string很類似,但是string設計的接口太多,而vector則較少所有我們直接開始模擬實現,如果你對vector的使用不太熟悉可以通過它的文檔來了解:vector。我們實現vector的簡單模板版本。
? ? ? ? 由于模板的小問題,我們在使用模板時最好聲明和定義在同一個文件。
一、vector使用時的注意事項
? ? ? ? 1.typedef的類型
? ? ? ? 在看文檔時有很多未見過的類型,實際上那是typedef的: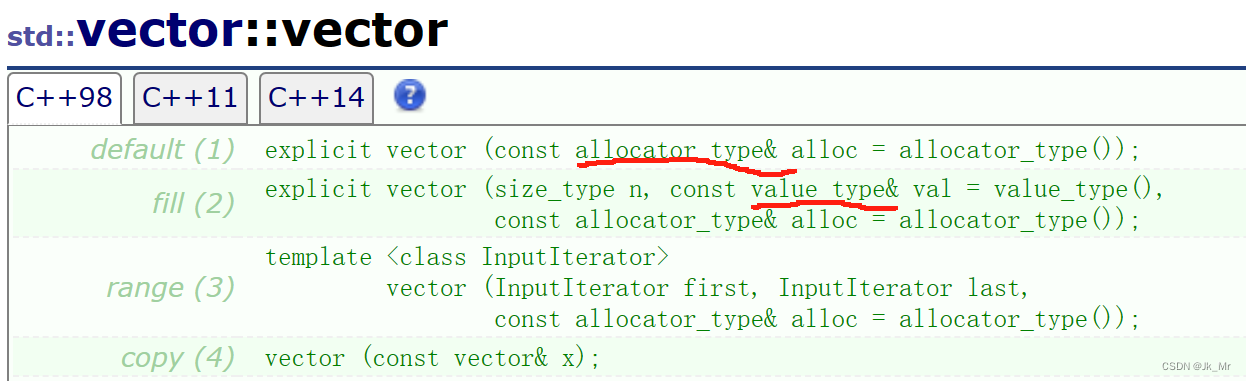

? ? ? ? 2.vector<char>不是string
? ? ? ? 不能把vector<char>和string等價,string是專門對待字符串和字符的自定義類型,而vector<char>是char類型的順序表。
? ? ? ? 區別在于vector<char>后面要手動加'\0',而string會自動加'\0'.
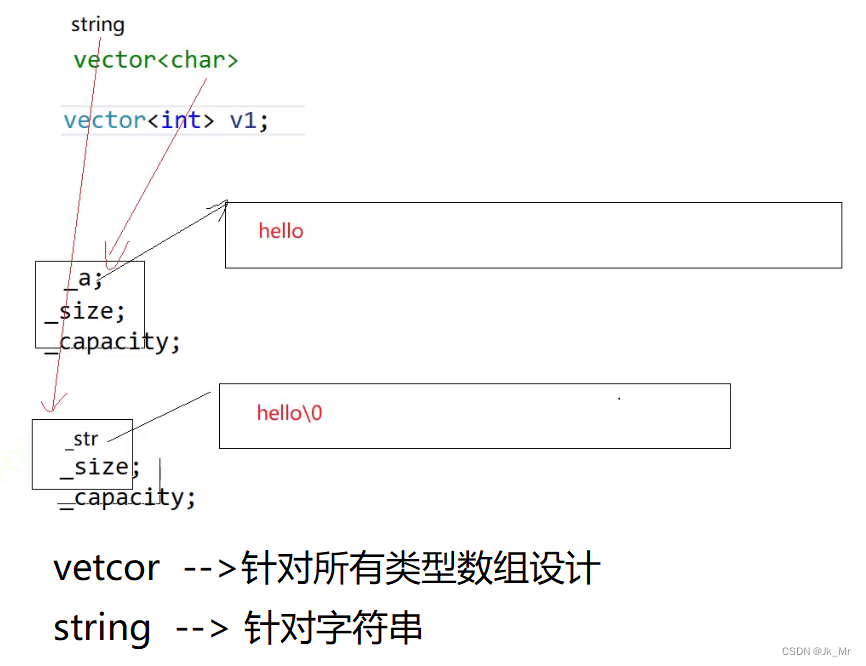
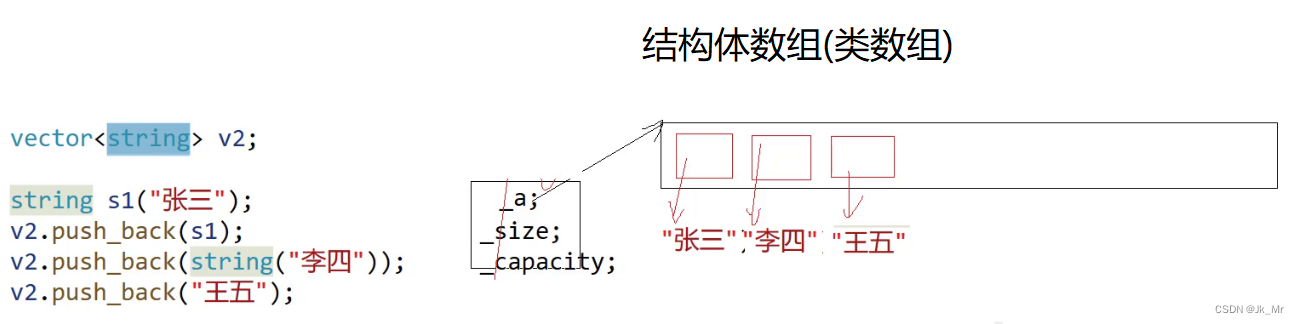
? ? ? ? 3.vector <string>
? ? ? ? vector<string>是string 的順序表,每個元素都是string,如果使用vector<const char*>則空間還需自己手動調整,使用string則不用。
? ? ? ? 4.算法sort
? ? ? ? C++庫函數中提供了一個包含算法的頭文件<algorithm>,現在我們要學會使用sort來排序:
? ? ? ? 默認是升序。
vector<int> v1 = { 5,6,1,3,4,10 };for (const auto& e : v1){cout << e << ' ';}std::sort(v1.begin(), v1.end());cout << endl;for (const auto& e : v1){cout << e << ' ';}?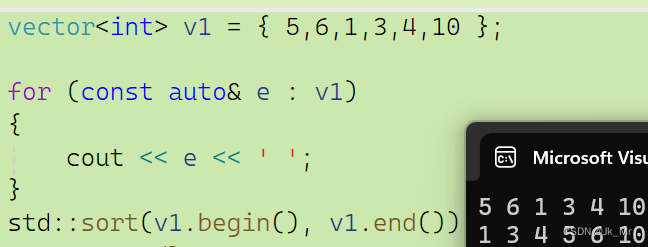
那么該如何降序?
? ? ? ?可以使用反向迭代器:
std::sort(v1.rbegin(), v1.rend());? ? ? ?使用反函數greater<>:
greater<int> gt;std::sort(v1.begin(), v1.end(),gt);//std::sort(v1.begin(),v1.end(),greater<int>());//匿名對象
greater是降序,升序是less.在C++中,我們<為升序,> 為降序,所有greater是降序,less是升序。
這里了解一下,后面會詳細講解。
二、vector的實現
? ? ? ? 1.通過源碼進行猜測vector的結構
? ? ? ? <vctor.h>中,我們先淺淺了解一下,具體實現我們使用我們的思路。

? ? ? ? 觀察源碼typedef:
? ? ? ? 觀察源碼的成員變量:
? ? ? ?start是什么,finish是什么?end_of_storage?從名字上看再對比之前的順序表結構,或許可以大膽猜測:start到finish是一對和size差不多,end_of_storage應該是capacity。
? ? ? ? 通過觀察成員函數來進行猜測:

? ? ? ? 如果finish到了end_of_storage說明滿了進行擴容。擴容操作是由insert_aux函數來完成的:
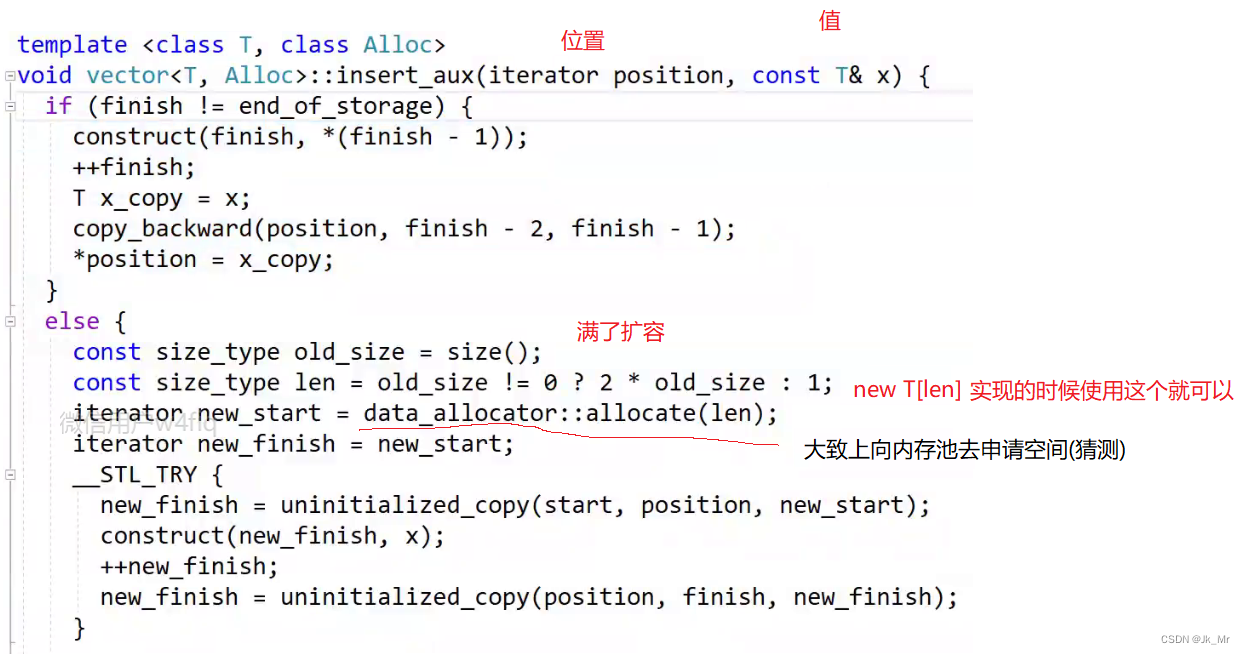
? ? ? ? 如果滿了就進行擴容,大膽猜測擴容操作時進行三段操作: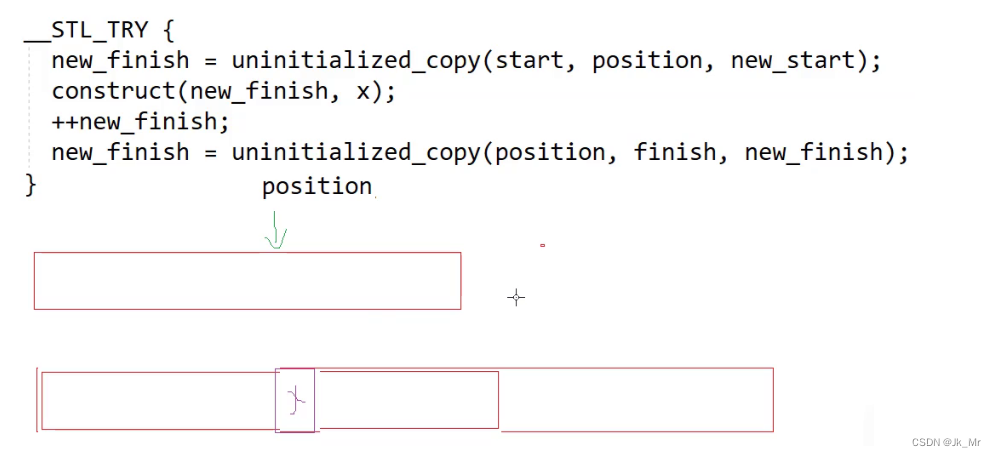
1.把position位置之前的數據拷貝到新空間,
2.把x插入到新的空間的尾部
3.再把position位置之后的數據拷貝到新的空間。
這些了解一下。
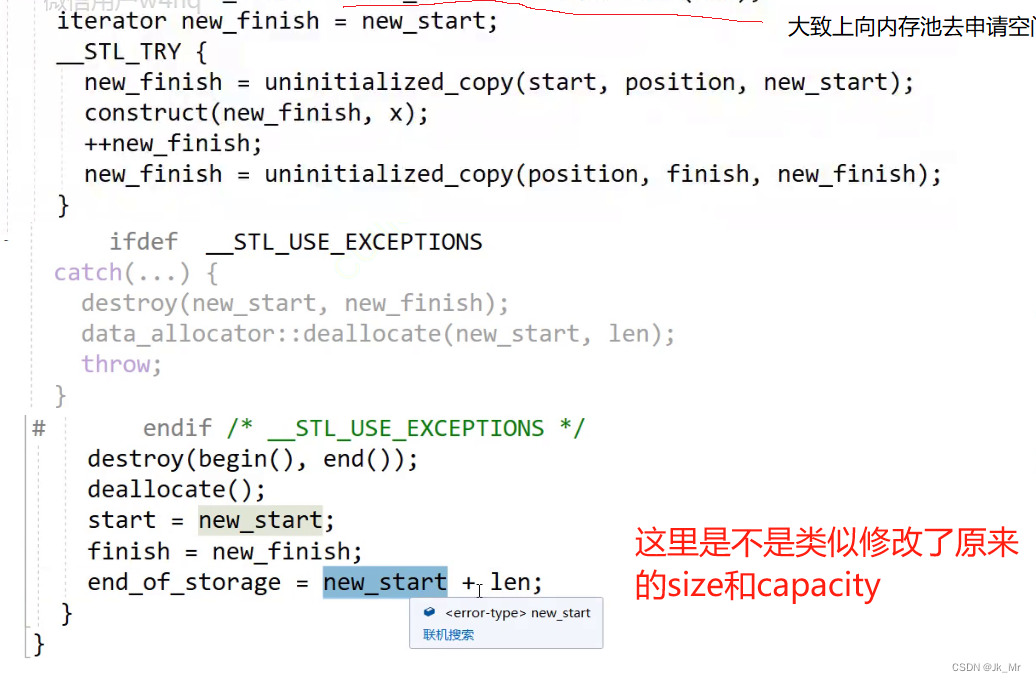
? ? ? ? ?關于construc和destroy實際上和內存池有關:

????????由于內存池調用new和delete不會進行構造和初始化,所以construc和destroy是定位new的函數,用于對內存池的空間進行構造(這里是拷貝構造)和析構?。
? ? ? ? 2.初步vector的構建
? ? ? ? 使用聲明和定義分離來進行模擬實現。在開始我們先不實現構造,使用給缺省值來解決五默認構造的問題。關于為什么給成員變量缺省值就可以進行插入可以查看這一片文章:類和對象(下)初始化列表
2.1 成員變量
#pragma once
#include <iostream>
using namespace std;
#include <vector>namespace vet
{template<class T>class vector{public:typedef T* iterator;private://T* _a;//size_t _size;//size_t _capacity;//倆者本質上是一樣的iterator _start;iterator _finish;iterator _end_of_storage;};
}2.2成員函數
? ? ? ? 2.2.1尾插和擴容
? ? ? ? 尾插涉及擴容,這我們直接實現capacity和size函數。
vector.h中 void reserve(size_t n){if (n > capacity()){T* tmp = new T[n];if (_start)//如果為空不進行拷貝{memcpy(tmp, _start, sizeof(T) * size());delete _start;_start = tmp; }_finish = _start + size();_end_of_storage = _start + n;} }size_t capacity(){return _end_of_storage - start;}size_t size(){return _finish - _start;}void push_back(const T& x){if (_finish == _end_of_storage){//擴容size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);}*finish = x;++finish;}? ? ? ? ??2.2.2operator[]
T& operator[](size_t pos){assert(pos < size());return _start[pos];}? ? ? ? 測試代碼:
? ? ? ? 運行會發現,程序奔潰。
test.cpp中
void test_myvector1()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (int i = 0; i < v1.size(); i++){cout << v1[i] << ' ';}
}? ? ? ? 通過調試發現_finish = x是對空指針操作,實際上錯誤是在size()計算階段:
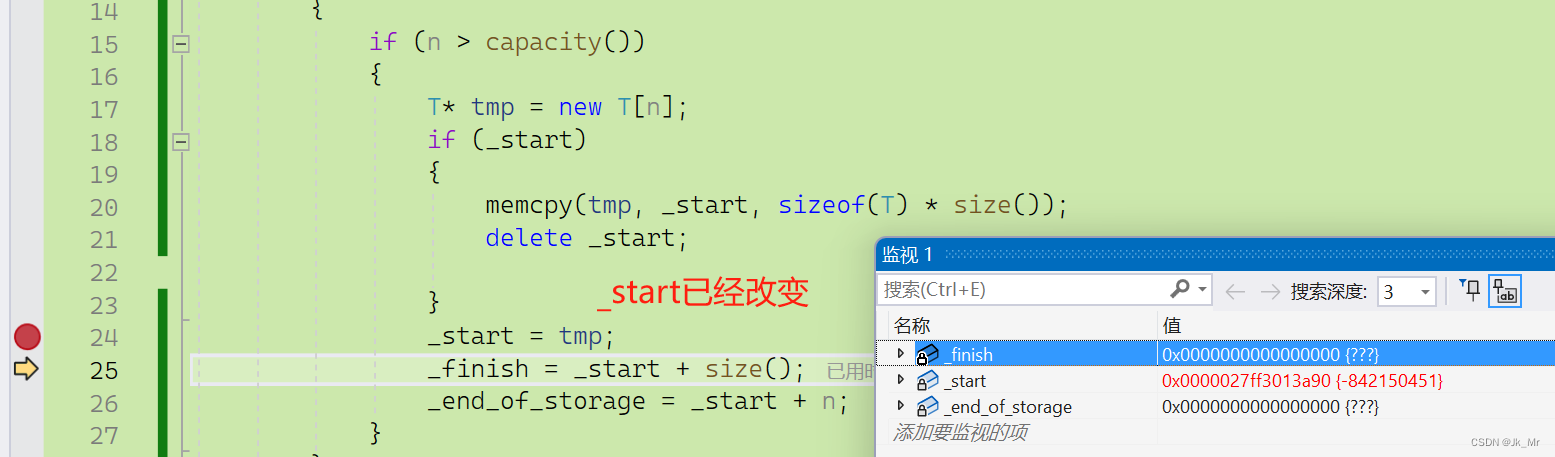
而size()是通過_finish - _start來計算的:

_start指向新的空間,而_finish是nullptr,使用空指針減去_start操作錯誤。size()不是我們想要的size().
倆種解決辦法:
void reserve(size_t n)
{if (n > capacity()){T* tmp = new T[n];if (_start){memcpy(tmp, _start, sizeof(T) * size());delete _start;}_finish = tmp + size();_start = tmp; _end_of_storage = _start + n;}
}這樣順序不好,用戶可能看不懂,所以可以記錄一下size()然后進行更新:
void reserve(size_t n)
{size_t oldsize = size();if (n > capacity()){T* tmp = new T[n];if (_start){memcpy(tmp, _start, sizeof(T) * size());delete _start;}_start = tmp;_finish = _start + oldsize;_end_of_storage = _start + n;}
}結果: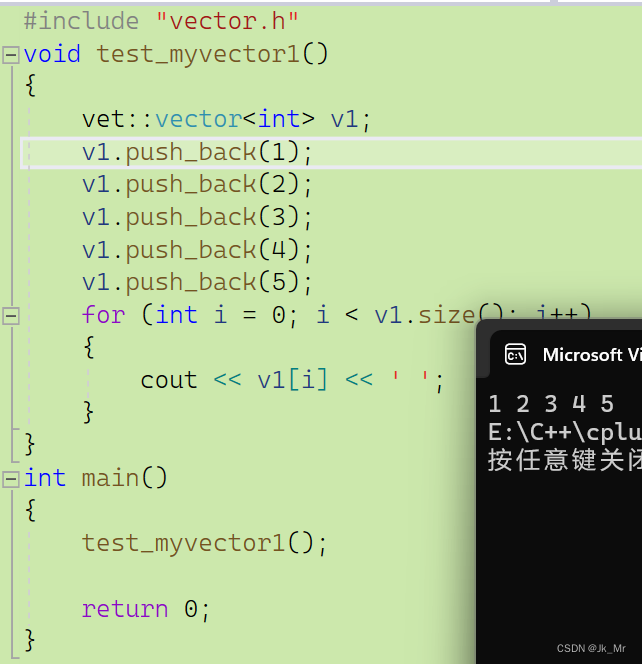
? ? ? ? 我們這里并未寫析構和構造,系統是抽查的機制,動態開辟的一般在delete的時候進行檢測,所以我們有時候可能在越界暴露不出來,推薦寫上析構:
? ? ? ? 再測試有無問題。
~vector(){if (_start){delete[] _start;_finish = _end_of_storage = nullptr;}}
? ? ? ? 2.2.3? 迭代器
? ? ? ? 有了迭代器,那么就可以使用范圍for了;
iterator begin()
{return _start;
}
iterator end()
{return _finish;
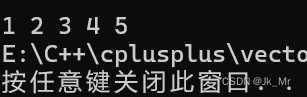
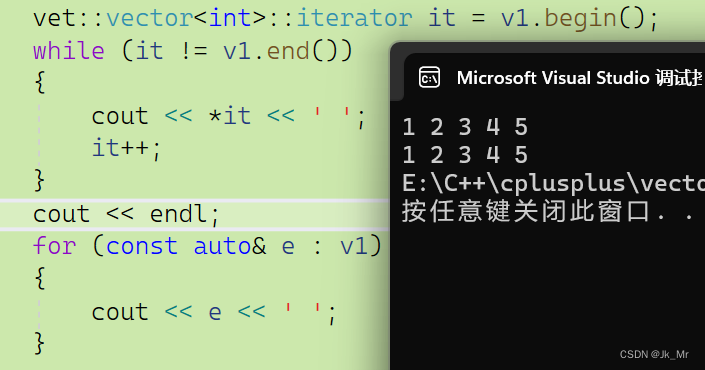
}測試代碼:
vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);vet::vector<int>::iterator it = v1.begin();while (it != v1.end()){cout << *it << ' ';it++;}cout << endl;for (const auto& e : v1){cout << e << ' ';}結果:
? ? ? ? 2.2.4尾刪、指定位置刪除和插入
//尾刪void pop_back(){assert(size() > 0);--_finish;}?3指定位置刪除和插入和迭代器失效
? 指定位置刪除插入:
? ? ? ? 要實現指定位置刪除或插入就要找到要刪除或插入的值。
????????觀察vector 的文檔發現,vector沒有find,是因為在算法<algorithm>中已經存在find的模板:體現了復用,vector,list都可以用。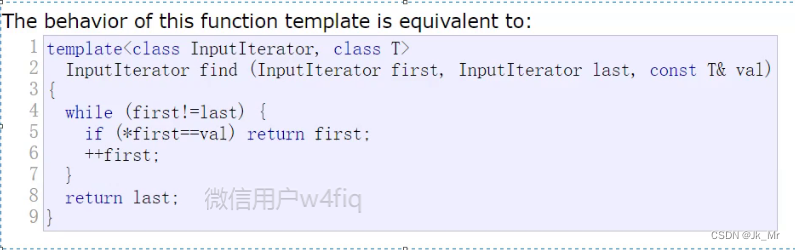
? ? ? ? 3.1insert和迭代器野指針問題
? ? ? ? 空間不夠擴容,夠了挪動數據。
void insert(iterator pos, const T& x){assert(pos >= _start && pos <= _finish);if (_finish == _end_of_storage){//擴容size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);}//挪動數據,從后往前挪iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;--end;}*pos = x;++_finish;}? ? ? ? 運行代碼:
void test_myvector2()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);for (auto e : v1){cout << e << ' ';}cout << endl;v1.insert(v1.begin(), 0);for (auto e : v1){cout << e << ' ';}
}
結果: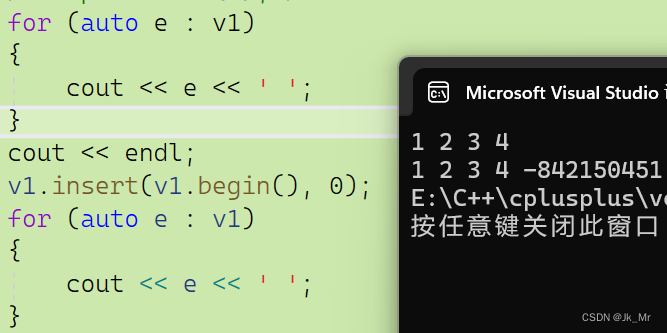
通過運行結果發現,程序崩潰了,這是為什么?
實際上這里是迭代器失效了,空間滿了需要擴容操作,擴容造成了迭代器失效。如果空間足夠則可以正常插入。
迭代器失效是指在使用迭代器遍歷集合(如數組、列表、字典等)的過程中,對集合進行了修改(添加、刪除操作)導致迭代器指向的元素位置發生變化,從而影響迭代器的正確性和結果不可預測的現象。
我們的代碼實在擴容的時候發生了迭代器失效。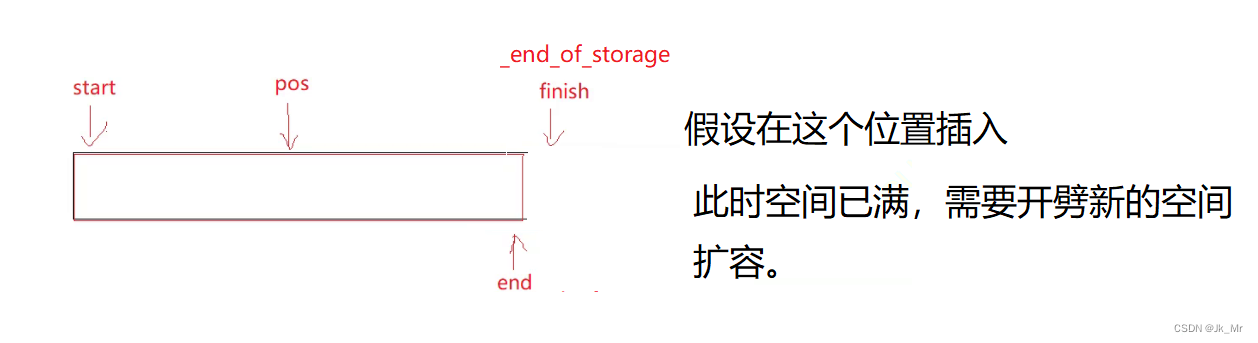
擴容操作改變的是_start和_finish以及_end_of_stroage: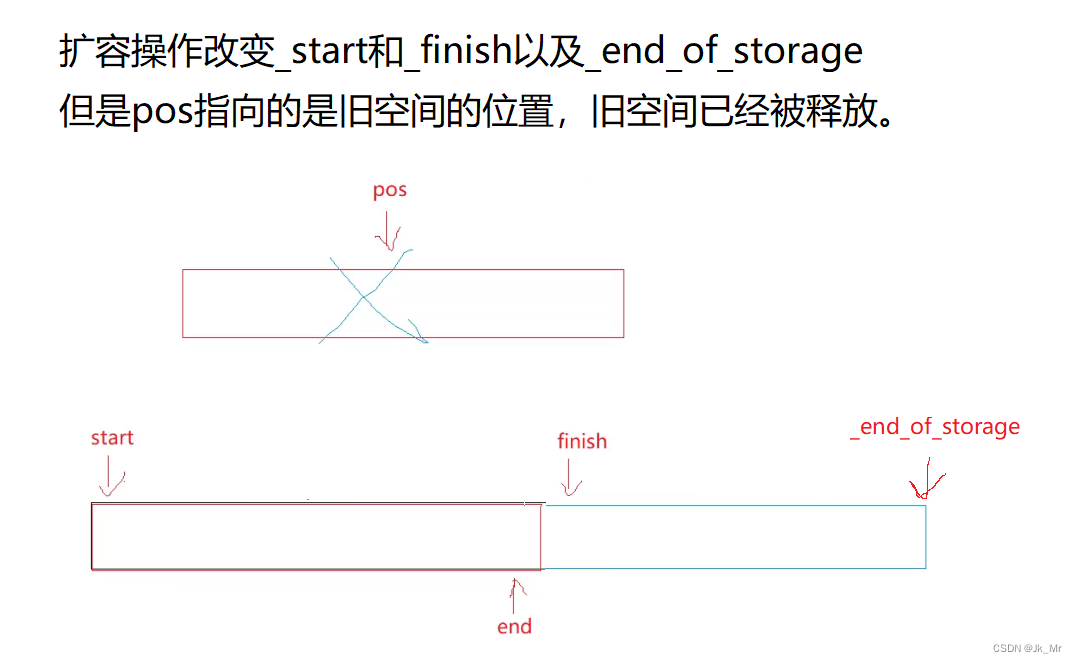
所以這里的迭代器失效本質是野指針問題。
既然pos迭代器失效,那我們就更新pos迭代器。pos要指向新空間的pos位置:
記錄與_start的距離:size_t len = pos - _start;
void insert(iterator pos, const T& x)
{assert(pos >= _start && pos <= _finish);if (_finish == _end_of_storage){size_t len = pos - _start;//擴容size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);pos = _start + len;}//挪動數據,從后往前挪iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;--end;} *pos = x;++_finish;
}此時運行上面的測試代碼: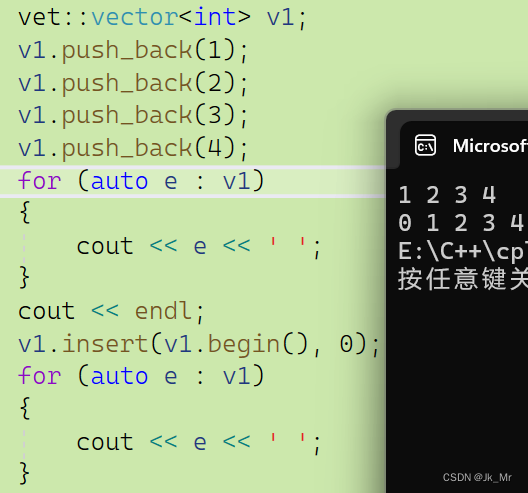 結果運行正常。
結果運行正常。
一般使用insert往往伴隨著find,所以我們使用find再進行測試
vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);for (auto e : v1){cout << e << ' ';}cout << endl;vet::vector<int>::iterator vi = find(v1.begin(),v1.end(),3);v1.insert(vi, 10);for (auto e : v1){cout << e << ' ';}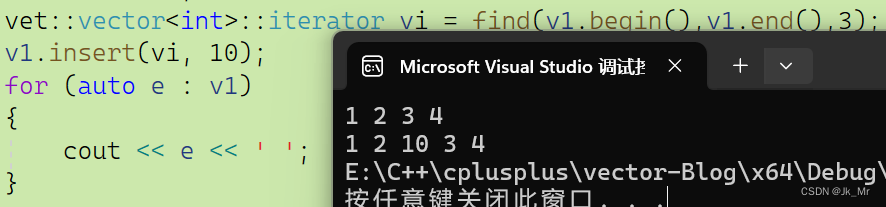
這樣又有一個問題:發生擴容時insert以后vi個迭代器實參會不會失效?
? ? ? ? 仔細想想,空間不足時,需要擴容進行空間轉移,而vi指向的是否是原來的空間?函數中的pos是否會改變vi?
? ? ? ? 答案是會失效,因為,vi是實參,而pos是形參,形參的改變不會影響實參的改變。
vet::vector<int>::iterator vi = find(v1.begin(),v1.end(),3);
if(vi != v1.end())
{ v1.insert(vi, 10);cout << *vi << endl;
}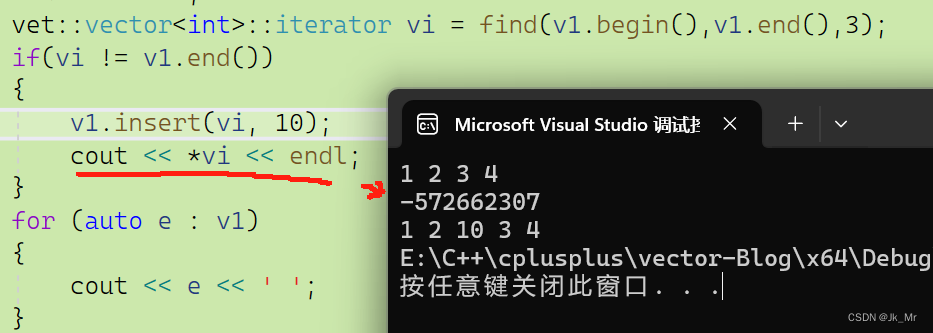
由于不知道什么時候擴容,所以一般認為這種情況是迭代器失效。這時候我們建議不要訪問和修改vi指向的空間了(即不使用失效的迭代器)。
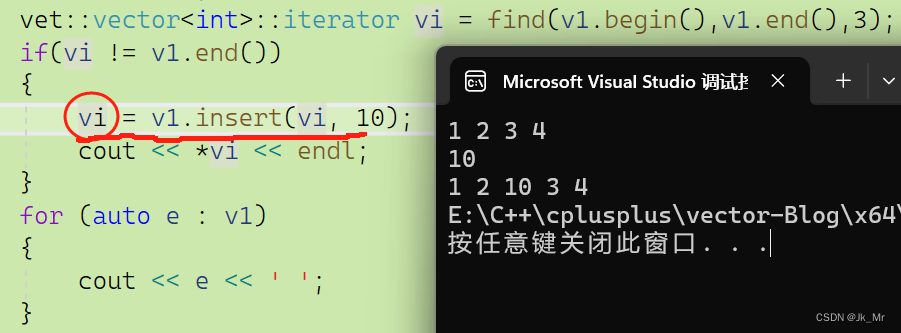
? ? ? ? 如果非要訪問插入的位置呢?該怎么辦?文檔中insert提供了一種方法就是函數的返回值:
iterator insert(iterator pos, const T& x)
{//代碼..return pos;
}
一般也不會這么做,所以一般認為失效了。string也有迭代器失效,其他也不例外。也是通過返回值。
? ? ? ? 3.2erase和迭代器失效
? ? ? ? erase要將pos位置之后的數據前移:

void erase(iterator pos){assert(pos >= _start && pos < _finish);iterator it = pos + 1;//將后面的數據前移while (it != _finish){*(it - 1) = *it;++it;}--_finish;}測試代碼:
void test_myvector03()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);for (auto e : v1){cout << e << ' ';}cout << endl;v1.erase(v1.begin());for (auto e : v1){cout << e << ' ';}
}測試結果:

erase也有迭代器失效,我們使用vector庫里的刪除進行測試看看: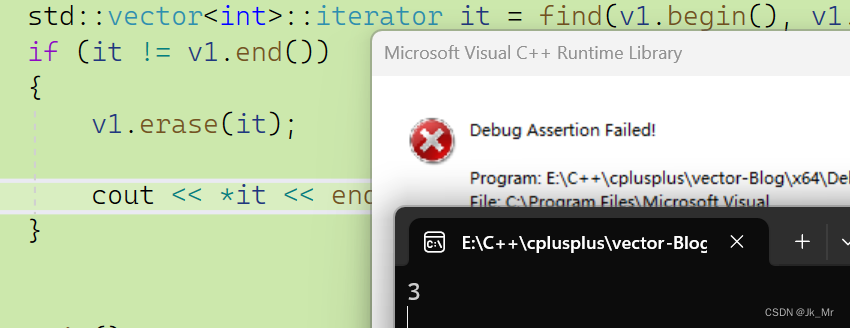
同樣也不能訪問,而且是斷言錯誤。而使用返回值時則可以使用:
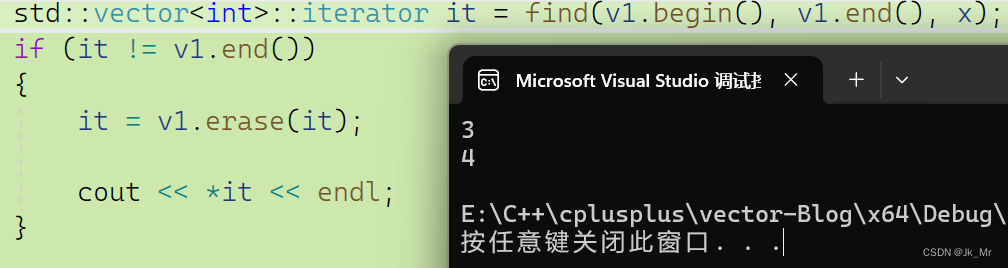
既然刪除只涉及數據移動,那為什么刪除也會是迭代器失效呢?
由于C++并未規定刪除是否會縮容,所以刪除時不同的平臺可能不同:
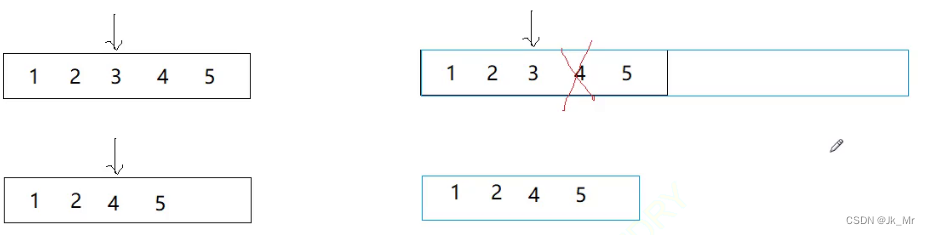
是有可能野指針的。
就算不縮容,那么在刪5的時候呢?刪除5的時候后面沒有數據,如果要訪問迭代器會造成越界訪問。這里迭代器失效并不是野指針。
所以我們認為erase后,迭代器失效。
vs下要訪問迭代器的話,同樣是使用返回值,那我們實現也使用,但是在刪除最后應一個有效元素時,不能進行訪問: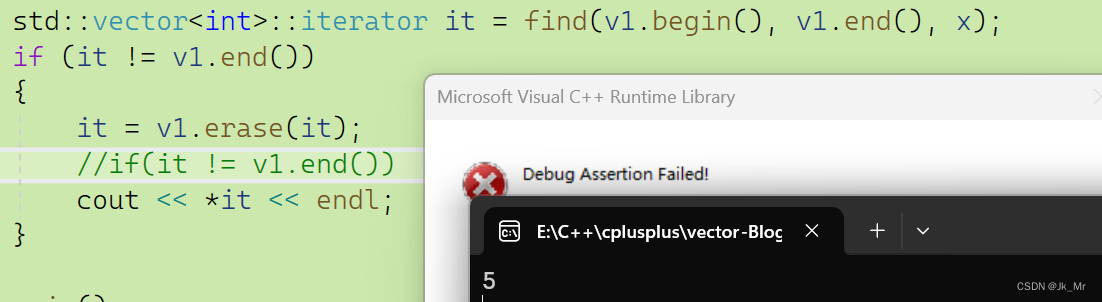
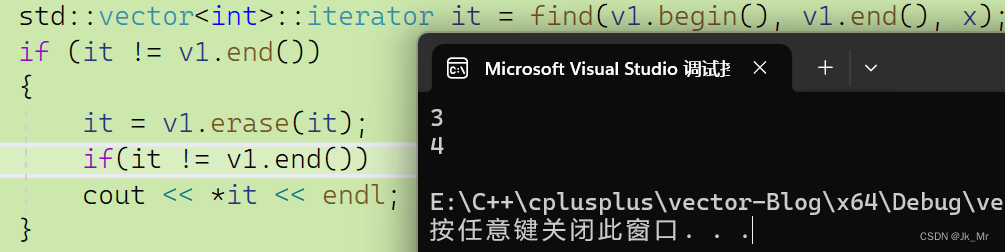
iterator erase(iterator pos)
{assert(pos >= _start && pos < _finish);iterator it = pos + 1;while (it != _finish){*(it - 1) = *it;++it;}--_finish;return pos;
}測試代碼:
std::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);int x;cin >> x;std::vector<int>::iterator it = find(v1.begin(), v1.end(), x);if (it != v1.end()){it = v1.erase(it);if(it != v1.end())cout << *it << endl;}如下題,要刪除所有偶數,使用失效的迭代器則會保存,所有應該使用返回值:
void test_myvector05()
{std::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (auto e : v1){cout << e << ' ';}//刪除所有偶數std::vector<int>::iterator it = v1.begin();while (it != v1.end()){if (*it % 2 == 0)it = v1.erase(it);else++it;}for (auto e : v1){cout << e << ' ';}
}而在linux下不使用返回值則可以。但是不同平臺不一樣,使用最好使用函數返回值更新。
4.拷貝構造
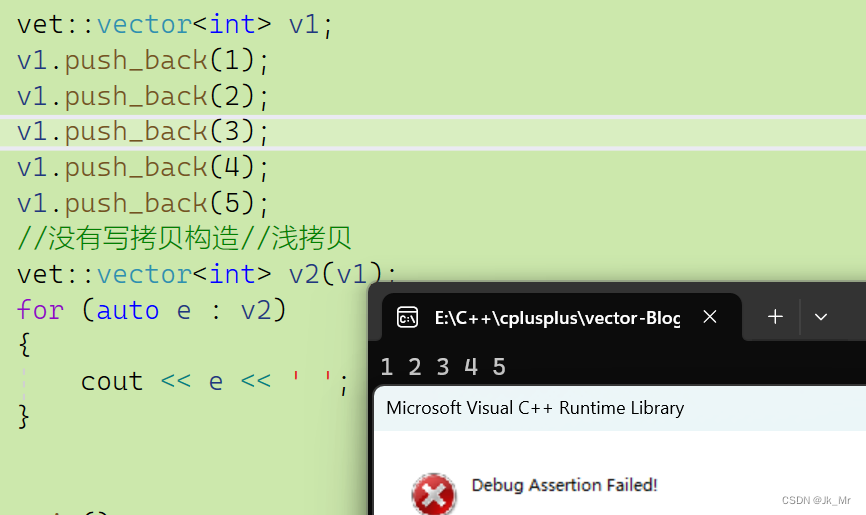
? ? ? ? 在不寫拷貝構造函數時,編譯器會默認生成,該拷貝是淺拷貝。
void test_myvector06()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);//沒有寫拷貝構造//淺拷貝vet::vector<int> v2(v1);for (auto e : v2){cout << e << ' ';}
}結果肯定是報錯,因為淺拷貝是值拷貝,成員變量的值是一樣的,此時v1和v2指向同一塊空間
,在出函數作用域時會調用析構函數,此時v1、v2都會析構,但是指向同一塊空間,所以析構了倆次。
所有我們要寫拷貝構造:
? ? ? ? 像這樣寫就可以開辟空防止指向同一塊空間。
vector(const vector<T>& v)
{for (auto e : v){push_back(e);}
}但是由于我們沒有寫默認構造函數:

由于我們寫了一個拷貝構造,編譯器不會自動生成構造函數(類和對象中上)了。
我們可以通過寫默認構造函數來解決也可以通過下面這種方法:
vector() = default;
vector(const vector<T>& v)
{for (auto e : v){push_back(e);}
}第一行代碼使用于編譯器強制生成默認構造函數。
我們在后面再添加上默認構造函數,這里我們先完成拷貝構造函數,由于拷貝構造我們使用的是尾插的方式,所以每次插入可能涉及很多擴容,所以我們可以提前開好空間:
vector(const vector<T>& v){reserve(v.capacity());for (auto e : v){push_back(e);}}
? ? ? ? 運行時發現不行:

是因為我們的capacity和size,迭代器不是const成員函數,所以我們加上const:

實現const迭代器:
typedef T* iterator;typedef const T* const_iterator;iterator begin(){return _start;}iterator end(){return _finish;}const_iterator begin() const{return _start;}const_iterator end() const{return _finish;}結果:
5.operator=賦值
? ? ? ? 我們使用現代寫法:
//v1 = v2void swap(vector<T> v){std::swap(_start, v._start);std::swap(_finish,v._finish);std::swap(_end_of_storage,v._end_of_storage);}//現代寫法:傳值傳參,v出函數作用域會調析構,//但是我們交換了this和v的成員變量,所以析構的是原來的空間而不是v的而是this的vector<T>& operator=(vector<T> v){swap(v);return this;}6.迭代器區間初始化
? ? ? ? allocator是內存池,內存池是自己寫的空間配置,我們使用new來開空間就好。

? ? ? ? 迭代器區間需要倆個迭代器first和last,我們寫成函數模板,可以支持任意類型:
//支持任意容器的迭代器初始化
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{while (first != last){push_back(*first);++first;}
}測試代碼:
void test_myvector07()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (auto e : v1){cout << e << ' ';}cout << endl;vet::vector<int> v2(v1.begin()+1,v1.end()-1);for (auto e : v2){cout << e << ' ';}
}結果: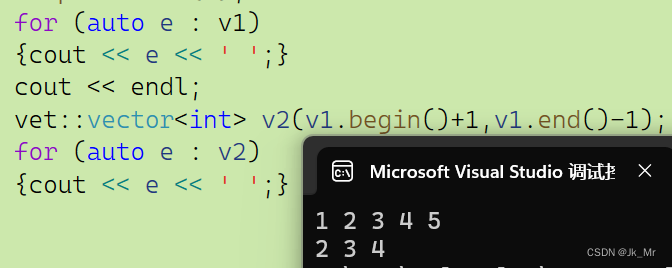
7.n個val初始化和編譯器匹配問題
? ? ? ? 需要考慮缺省值。
![]()
缺省值能否是0?很明顯不能,因為T的類型未知,如果是string、vector、list類型,給0肯定會有問題。所以該怎么辦?
缺省參數一般給常量,但自定義類型怎么辦,C++中自定義類型可以傳T(),即匿名對象(調用默認構造)。內置類型是否可以這樣?是可以的,C++對內置類型進行升級,可以進行構造: 值分別為0、1、0、2。
值分別為0、1、0、2。
測試代碼:
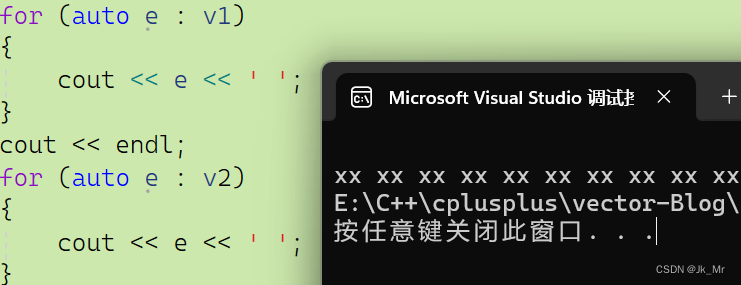
void test_myvector08()
{vet::vector<string> v1(10);vet::vector<string> v2(10, "xx");for (auto e : v1){cout << e << ' ';}cout << endl;for (auto e : v2){cout << e << ' ';}
}結果:
在使用實例化類模板時,如果對它構造n個1會有意想不到的錯誤:
void test_myvector09()
{vet::vector<string> v1(10, 1);for (auto e : v1){cout << e << ' ';}
}? ? ? ? ?報錯到了這里?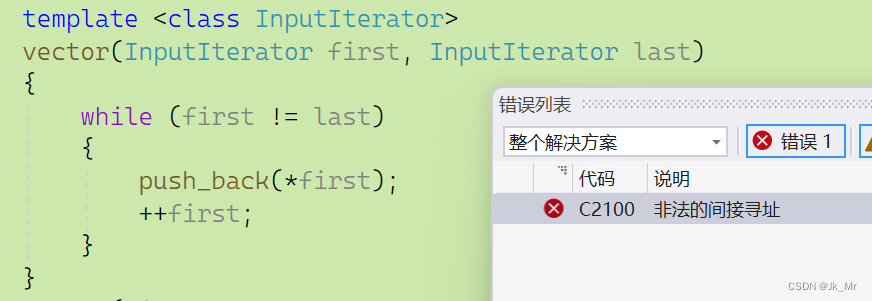
這里提一下調試技巧:目前我們知道時我們的測試代碼上下都沒有其他代碼,
1.如果有其他代碼,先通過屏蔽其他代碼鎖定時哪一段代碼出來問題。
2.通過一步步調試進行觀察。
這里實際上時參數的匹配問題,編譯器的選擇問題。
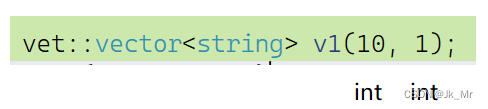
由于我們傳參的都是int,所以模板實例化的也是int int。
編譯器會匹配更好的,參數更匹配的。

實際上vector<int>(10,1)也會出錯: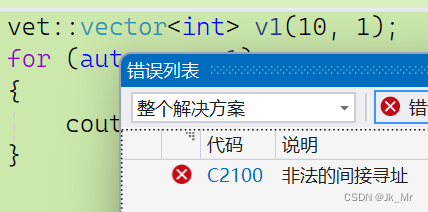
解決辦法:要使得匹配到正確的函數我們就要給出一個重載的函數:
 、
、
這樣就可以匹配到合適的函數。vector庫內也面臨這樣的問題。
三、{}的使用
? ? ? ? 在類和對象(下)中我們提到了多參數和單參數的隱式類型轉換。使用到了{},這時C++11的特性:一切皆可用{}進行初始化。

class A
{
public:A(int a):_a1(a),_a2(a){}A(int a1, int a2):_a1(a1), _a2(a2){}
private:int _a1;int _a2;
};
int main()
{//單參數隱式類型轉換 1-> 構造臨時對象A(1) -> 拷貝構造給 a1 => 優化為直接構造A a1(1);A a2 = 1;A a3{ 1 };A a4 = { 1 };//多參數隱式類型轉換 1,2-> 構造臨時對象A(1,2) -> 拷貝構造給 aa1 => 優化為直接構造A aa1(1, 2);A aa2 = { 1,2 };A aa3{ 1,2 };return 0;
}所以在平常使用中可以使用{}.
再來看下面代碼:
我們使用庫中的vector。
void test_vector1()
{std::vector<int> v1 = { 1,2,3,4,5,6 };for (auto e : v1){cout << e << ' ';}
}這里是隱式類型轉換,但不是轉化為vector<int>而是initializer list,然后再進隱式類型轉化,是C++11的一種構造:

initializer list是C++11新增的類型

它是一個自定義類型:

il1和il2是等價的。由于{}內是常量數組。內部實際上是倆個指針,分別指向常量數組的開始和末尾:

它也有迭代器和size,所以支持范圍for:
所以在我們自己實現的vector中要使用{1,2,3,4,5}這樣的形式我們要支持initializer_list的構造:
vector(initializer_list<T>il){reserve(il.size());//initializer_list支持迭代器for (auto e : il){push_back(e);}}結果:
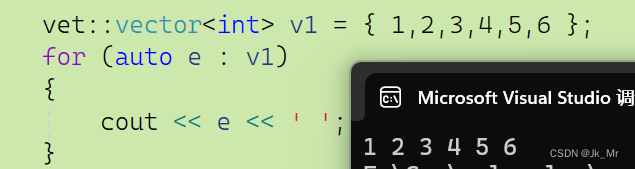
有了這個特性我們就可以像下面這樣:
class A
{
public:A(int a = 0):_a1(a),_a2(a){}A(int a1, int a2):_a1(a1), _a2(a2){}
private:int _a1;int _a2;
};
int main()
{vet::vector<A> v1 = { 1,{1},A(1),A(1,2),A{1},A{1,2},{1,2} };return 0;
}{}的用法很雜,使用再使用{}進行初始化時,盡量不要寫的太奇怪。
?四、vector<string>的問題
? ? ? ? 觀察下面的程序:
void test_myvector11()
{vet::vector<string> v1;v1.push_back("1111111111111111");v1.push_back("1111111111111111");v1.push_back("1111111111111111");v1.push_back("1111111111111111");for (auto e : v1){cout << e << endl;}cout << endl;
}
? ? ? ? 插入4個string,結果沒有問題:
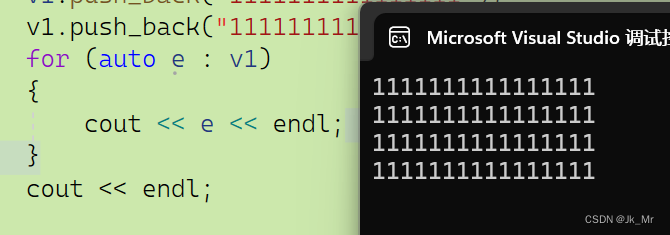
? ? ? ? 而再插入一個string會發生意料之外的結果: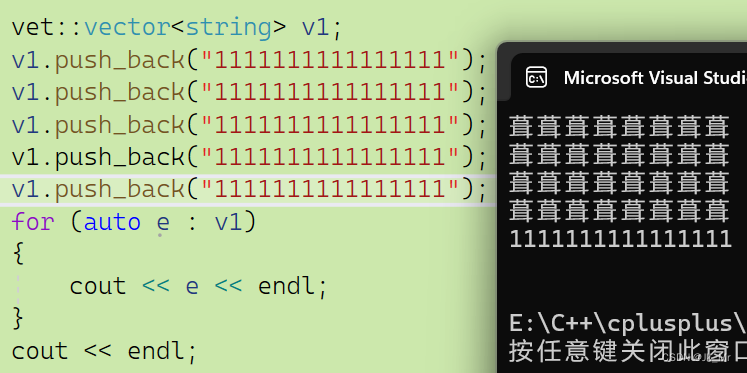
程序崩潰了。這是為什么?關鍵就在我們多插入的一次,通過調試觀察:
到這沒有什么問題,然后進memcpy,釋放就釋放舊空間。
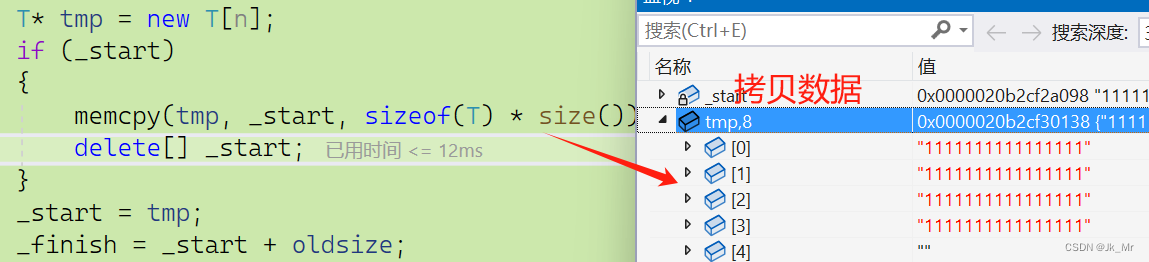
釋放舊空間:

走早這里已經知曉了為什么會改變了,釋放的空間是我們拷貝的空間,這樣的情況就是淺拷貝。
畫圖進行分析:
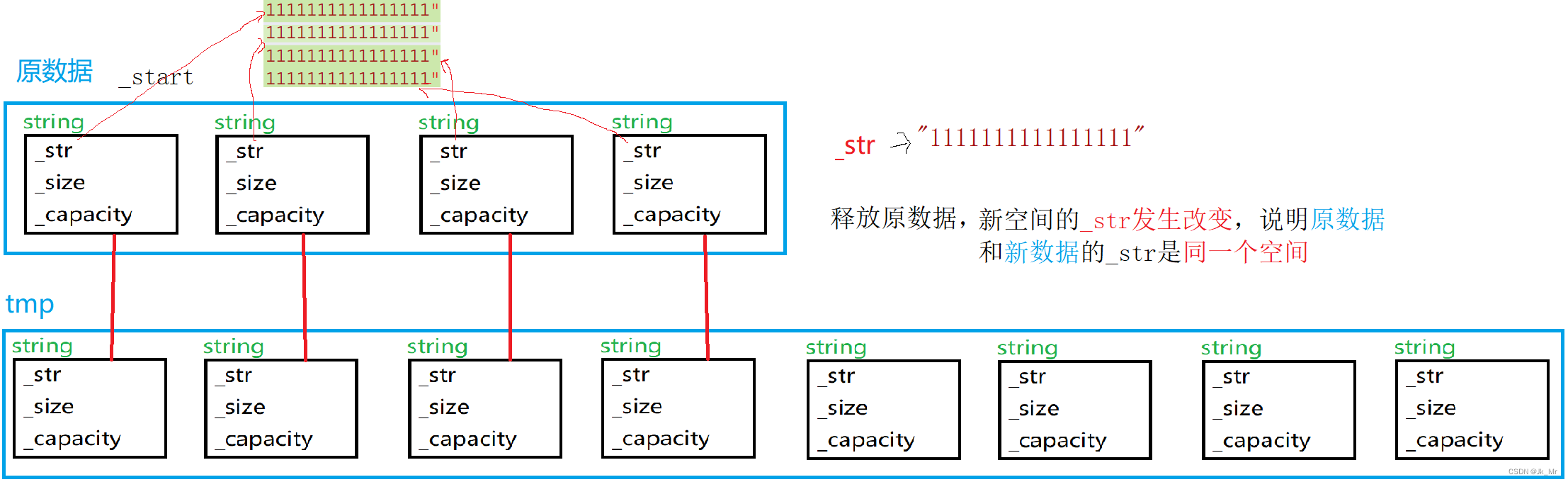
memcpy對任意類型數據拷貝是淺拷貝。memcpy對數據一個字節一個字節拷貝。在對_start進行釋放時,string會調用析構函數,對其中的_str進行釋放。
解決方案:進行深拷貝:
void reserve(size_t n){size_t oldsize = size();if (n > capacity()){T* tmp = new T[n];if (_start){//memcpy(tmp, _start, sizeof(T) * size());for (size_t i = 0; i < oldsize; i++){//進行賦值//內置類型進行賦值,自定義類型調用它的賦值操作tmp[i] = _start[i];}delete[] _start;}_start = tmp;_finish = _start + oldsize;_end_of_storage = _start + n;}}進行賦值,內置類型進行賦值,自定義類型調用它的賦值操作。在這里tmp[i]和_start[i]相當于是
string對象進行賦值。
如果你有所收獲,可以留下你的點贊和關注,謝謝你的觀看!







:配置中心基礎和代碼樣例)



 基于字符設備驅動的I/O操作)
 - 三語言AC題解(Python/Java/Cpp))


)

![[數據結構] -- 單鏈表](http://pic.xiahunao.cn/[數據結構] -- 單鏈表)
list)
