目錄
核心知識回顧
網絡核心原理
get和post的理解
解析http
加密+請求和響應的一些關鍵字
Cookie和session
對密鑰的理解
核心知識回顧
網絡編程---socket api
UDP DatagramSocket DatagramPacket
TCP ServerSocket? ? Socket
1.讀寫數據通過Socket,通過Socket內置的 lnputStream和OutputStream? ? ? 讀寫基本單位是字節
2.當前在編寫客戶端服務器的時候,是需要約定請求/響應之間的分隔符的.(\n)
3.服務器這邊accept得到的socket對象,記得及時關閉
4.要處理多個客戶端,需要搭配多線程/線程池?如果客戶端進一步增加,此時多線程/線程池,就會產生出大量的線程.
操作系統中內置了IO多路復用--本質上一個線程同時負責處理多個客戶端的請求等到客戶端發來數據的時候線程再來處理就可以了.
多個客戶端同時發數據的概率比較小雖然只有一個線程也能處理多個客戶端了? ?萬一有3k,3w個客戶端,沖突概率大了嘛??
咱又不是說,只有1個線程.多搞一些線程就可以處理更多的客戶端了異步同步是站在客戶端的視角看待的.(上游看待下游)
此處1O多路復用是站在服務器的視角.(下游看待上游)IO多路復用當前開發服務器的主流的核心技術.
操作系統內置的.只需要調用api即可.
Java通過NIO來封裝了IO多路復用.
數據組織格式
具體如何自定義協議呢??? ? 自定義協議,分成兩個階段:
1.根據需求,明確傳輸哪些信息.
2.約定好信息組織的格式.1)行文本的方式
用戶id,用戶的位置\n
1000,45E45N\n
一個響應由多行構成,每一行是一個商家,每個商家中包含一些列信息.
以空行來結尾實際約定的時候,可以有很多變數的,列和列之間,不一定使用,也可以使用;也可以使用.也可以使用\t
多個數據之間,也不一定使用\n,也可以隨心所欲使用任何你喜歡的分隔符.........
自定義協議!!你就是說了算的那個
只要客戶端和服務器都按照這同一套規則來進行構造/解析數據就行了
2)用來網絡傳輸,和瀏覽器怎么顯示無關.html約定瀏覽器怎么顯示的.
xml可以用于很多場景,組織一段格式化數據? ? ?數據用來網絡傳輸,作為配置文件..
xml方案,放到10年前,用的還挺多的.現在,很少用xml進行網絡傳輸了.
優點:可讀性好.
缺點:元余信息太多了.網絡傳輸中,消耗更多的帶寬對于服務器來說,帶寬是最貴的.硬盤最便宜? 內存其次? ?cpu 小貴
3)json當下最流行的網絡數據格式組織的方案.
優點:可讀性也是很好的
消耗的帶寬,也比剛才談到的xml更節省
缺點:還是存在冗余信息.4)protobuf
基于二進制的格式,對數據進行壓縮.不涉及到json/xml元余信息了.
帶寬消耗最少,可讀性就變差了.protobuf,約定這一段二進制數據? 哪幾個字節表示那個信息
數據組織格式
1.行文本(最原始)
2.xml(比較原始,可讀性好,元余較多)
3.json(主流的方式,可讀性好,元余一般)
4.protobuf(高性能場景下使用的方式,可讀性差,余最小)


但凡實現一個具體的程序,寫代碼之前,一定是要先約定應用層協議的格式的
應用層這里,除了自定義協議之外,也有一些大佬們現成搞好的協議了.
FTP文件傳輸
SSH遠程操作主機
telnet 網絡調試工具
?HTTP一問一答模式的協議
客戶端發一個請求,服務器就返回一個響應
請求和響應一一對應瀏覽器打開網頁的場景/手機app加載數據的場景
典型的一問一答場景,使用HTTP就非常合適正向代理(代表客戶端干活)
反向代理(代表服務器干活)你電腦上所有的網絡通信,都會先發給這個抓包程序,抓包程序再把數據轉發給服務
本身網絡傳輸,就是要經過很多節點轉發的.
不在乎間多個一次兩次? 一般來說是沒有影響的
但是不排除特殊軟件會產生沖突
網絡核心原理
通過fiddler可以做到很多事情的
爬蟲本質上就是HTTP的客戶端(自己代碼實現的)
自己寫代碼,偽造出差不多的請求,就可以達成類似的功能效果了.
給你自己的博客點贊,互贊朋友自動評論
網絡這個東西和操作系統是無關的
windows主機能不能訪問linux服務器??必然可以
windows和linux不同的系統,其實是同一套網絡規則
遵守相同的網絡協議響應數據,經常是壓縮后傳輸的.? ?為了節省網絡帶寬.
MySQL是一個"客戶端-服務器"結構的程序.存儲數據的本體是在服務器
域名和ip可以相互轉換.
這個過程通過DNS域名解析系統來完成的
(DNS既是一套服務器系統,也是一種應用層協議)通過IP定位到一臺主機了.? 同一個主機上是有多個程序都在使用網絡
通過端口號來進一步區分
轉義操作,不僅僅是標點符號,對于中文等其他非英語系的文字,也是需要轉義的.
只不過很多瀏覽器為了用戶看起來方便,顯示的時候顯示轉義之前的
實際上抓包中就能看到,是已經轉義的數據urlencode把數據的二進制內容,每個字節取出來十六進制表示,前面加上%
F5刷新,重新訪問服務器.? ? ctrl+F5強制刷新:忽略本地緩存,所有資源都重新從服務器獲取
瀏覽器的緩存機制:瀏覽器從服務器/通過網絡加載網頁.(最快cpu,內存,硬盤,網絡)
通常情況下,從網絡加載數據比從硬盤加載要慢
(如果萬兆網卡,除外.充錢)
瀏覽器為了加快訪問頁面的速度,就會把頁面依賴的一些靜態資源(css,js,圖片,字體,mp3....)這些內容緩存到硬盤上.
第一次訪問服務器,需要加載這么多東西.后續再訪問,就不必重新加載


get和post的理解
POST來說 兩個典型的場景
1.登錄
2.上傳=>請求帶有正文的.正文就是保存了當前上傳的數據的內容
上述請求中,圖片本身是二進制的,通過特殊方式進行轉碼(base64編碼,把二進制其實body也是可以直接填二進制數據)
協議名://ip地址(域名):端口號/路徑。查詢字?
方法GET? POST? PUT??DELETE
Restful api 設計風格GET和POST區別
面試中被問到了首先先拋出結論,GET和POST沒有本質區別,經常是能夠混用的
POST也是可以帶有query string(還是有一些的)
GET理論上也可以帶 body(更少見)
從使用方法習慣上來說,主要是兩個方面的區別
1.語義
2.GET經常把數據放到 url的 query string 中.POST經常把數據放到body 中Host:gitee.com:端口號? ? 當前的請求訪問的服務器在哪里
ip地址(域名):端口號
絕大部分情況下,這倆屬性也是一致
3.GET請求通常建議設計成冪等的.POST無要求? ? HTTP標準文檔給的建議.
但是只是建議,不是強制要求.? ? 請求一定的,得到的響應也是一定的~~冪等
服務器開發中需要考慮一個環節? ? 尤其是像支付的這樣的場景,通常都要考慮冪等性4.GET設計成冪等了,就可以允許GET請求的結果被緩存.
POST由于不要求冪等,經常是不冪等的,就認為不能被緩存的實際上現在GET不冪等的情況太常見了.? ? 現在的互聯網產品,都講究"個性化推薦"
1.POST 比GET更安全? ? 登錄場景.輸入用戶名和密碼.
GET,用戶名密碼就會放到url的querystring中,就會顯示在瀏覽器地址欄上了
保證安全,關鍵是"加密傳輸
https//gitee.com/HGtz2222?username=xoxx&password=xoox
POST傳輸如果不加密,黑客隨便抓個包,也就看到了.
只要明文傳輸,都談不上安全
2.GET傳輸數據有長度限制
上古時期IE瀏覽器的年代,IE6(windows xp)對于URL的長度是有限制的
此時傳輸的數據太多,可能就會被截斷.? ?現在的主流瀏覽器/服務器早都沒有這樣的限制了
比較長的URL很多時候也能見到3.GET只能傳輸文本,POST可以傳輸二進制
GET確實url只能放文本.可以把二進制通過base64轉碼成文本的.
GET也不是完全就不能帶body(有些客戶端/服務器不支持)數據部分放哪里
GET 數據放到 url query string? 要傳輸的數據很多,url就會很長
post放到body里,url就可以比較短了
這四個操作的任何一個,都可以進行增刪改查
完全是取決于你代碼咋寫


解析http
HTTP往往是基于傳輸層的TCP協議實現的.(HTTP1.0,HTTP1.1,HTTP2.0均為TCP,HTTP3基于UDP實現)
當我們在瀏覽器中輸入一個搜狗搜索的"網址"(URL)時,瀏覽器就給搜狗的服務器發送了一個HTTP請求,搜狗的服務器返回了一個HTTP響應.
這個響應結果被瀏覽器解析之后,就展示成我們看到的頁面內容.(這個過程中瀏覽器會給服務器發送多個HTTP請求,服務器會對應返回多個響應,這些響應里就包含了頁HTML,CSS,JavaScript,圖片,字體等信息).
所謂"超文本"的含義,就是傳輸的內容不僅僅是文本(比如html,css這個就是文本),還可以是一些其他的資源,比如圖片,視頻,音頻等二進制的數據.
請求報頭:



加密+請求和響應的一些關鍵字
HTTP協議中,傳輸的時候可能會涉及到"加密"(HTTPS)
url 部分是不會被加密的.被加密的是 header 和 body
服務器收到請求之后也就可以做一個最終校驗
驗證url中的內容和header 中加密的內容是否一致一般登錄密碼這種,都是要在業務層加密的
依賴HTTPS這種操作,只能保證傳輸過程中是安全的.
但是如果密碼就明文保存在服務器上,服務器可能會被黑客攻擊,嚴重觸發拖庫
也會造成密碼泄露HTTP協議,傳輸層這里基于TCP實現的(版本號<=2.0)
把這一串字符串,寫入到tcp socket 中
對于TCP來說,一個連接上可以發多個請求
服務器這邊收到數據的時候就得區分一下,從哪里到哪里是一個完整的http請求數據沒有body的http請求,讀到空行,就可以認為是結束了.
有body的 http 請求呢?先讀取首行和header,讀到空行;解析 header 中的Content-Length
根據這里的值,接下來再讀取固定字節的長度UDP中面向數據報的---讀寫的基本單位就是一個UDP數據報.
某個應用層協議,基于UDP,一個UDP數據報就對應一個完整的應用層數據包.
調用一次receive操作,就得到一個明確的UDP的數據包前面寫tcp代碼,next來讀取的(隱含了一個約束,使用空白符作為結束標記)
text/html--HTML
瀏覽器就會解析其中的標簽,把標簽轉換成界面顯示
text/css--CSS
瀏覽器就會解析其中的選擇器和屬性,并且把這里指定的內容應用到頁面的樣式上
application/javascript---JS
瀏覽器通過js引擎解釋執行js中的邏輯
application/json--JSON
瀏覽器不會做任何處理(由對應的js程序員寫的邏輯中)
image/png--圖片image/jpg
瀏覽器嘗試按照圖片的二進制格式,解析出來并顯示C++/Java這樣的代碼,編譯成二進制.? 發布給用戶.
用戶拿到的是二進制代碼.用戶想根據二進制,還原出原始的源代碼是怎樣的,非常麻煩的
js這樣的代碼則是把原始代碼直接由用戶瀏覽器下載到.
用戶就能看到js的原始的樣子從用戶使用的角度來說,沒啥區別.,硬件發展達到一定程度了.
對于32位的系統/CPU來說,能夠支持的最大內存,4G
15年前,計算機的內存差不多就達到4G了
8G內存的機器,必須的是64位~cpu和操作系統32位cpu意味著對應的指針變量就是32個blt(多大的內存空間上尋址)
正常來說,32位cpu運行的是32位的程序4GB
64位cpu運行的是64位的程序.windows兼容做的好.64位的windows系統? 也可以無縫的使用32位的程序
同一個時間段內,有些用戶的瀏覽器,版本是比較舊的,支持的功能少
有些用戶瀏覽器版本更新,支持的功能多.
如果要是支持的功能少,可能就打不過競爭對手
如果支持的功能多,舊版本瀏覽器設備的用戶,可能就展示不了根據用戶使用的設備,進行區分.
通過UA中的瀏覽器版本/操作系統版本,區分出當前用戶的設備,最多都支持哪些特性
老的瀏覽器,返回功能少的網頁,正確顯示
程序員就需要維護多套代碼? ? 新的瀏覽器,返回功能多的網頁,體驗豐富UA還有另外一個用途? 可以用來區分用戶的設備.
windows/mac=>PC??ios/android=>手機
根據用戶的設備,返回不同版本的頁面.Referer? ? 描述了當前頁面的來源? ? 這個頁面是從哪個頁面跳轉來的
直接輸入url/點收藏欄打開的頁面是沒有Referer
主頁跳到搜索頁? ?Referer:https://www.sogou.com/? 搜索頁的 referer是否存在可能,有人把referer給改了.
本來是搜狗的referer 改成別人的referer? ?2014年的時候,這種情況非常普遍
對于廣告平臺造成一定的損失有能力的:用戶上網的時候,HTTP請求都是經過運營商的路由器/交換機? ?通過軟件,分析數據流量? ? 把一些廣告的數據的HTTP數據報進行修改就行了
有動機的:運營商也有自己的廣告平臺.(運營商和搜狗/百度是競爭關系)技術上反制~~=>HTTPS
HTTPS協議能夠有效的對HTTP數據報進行加密傳輸 (referer也被加密了)


Cookie和session
Cookie
瀏覽器展示頁面的過程中,頁面里雖然可以通過js來實現一些邏輯
但是js代碼無法訪問你的硬盤的(文件系統)--瀏覽器給js帶上的緊箍咒
怕js要是能操作用戶文件系統再瞎搞的
實際開發中,有的時候還是希望把某些數據能夠保存到本地硬盤的
因此瀏覽器引入了cookie 機制.
cookie就是瀏覽器允許網頁在本地硬盤存儲數據的一種機制.
不是讓網頁代碼直接訪問文件系統,而是做了一層抽象.而是瀏覽器的cookie提供了鍵值對存儲機制有些網站,讓用戶決定,是否愿意存他的cookie數據
瀏覽器保存了這些cookie之后,就會在后續給服務器發送請求的時候,把這些cookie鍵值
Cookie到哪里去:最終發回給服務器.
Cookie從哪里來:也是從服務器這邊來的.(后端開發程序員,決定的)Cookie里的數據都是程序員自定義內容.業務相關的
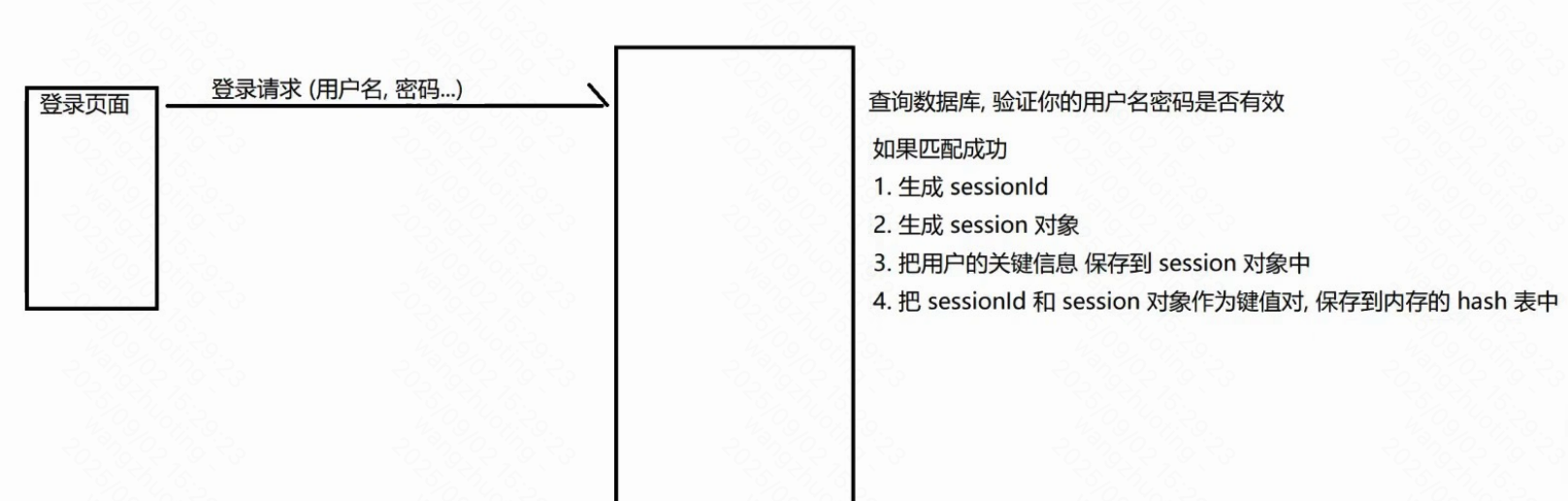
但是有一個典型的場景,屬于"通用業務"? ?登錄和用戶認證
?會話---session 對象也是可以存儲用戶自定義的數據的? 表示了當前這一次會話的詳細信息
會話就是記錄一些重要的信息?
描述了客戶端和服務器之間的一種交互關系.
數據庫,也是服務器.? ?對應的客戶端,就是你的應用程序/Workbench....
你的這個客戶端訪問一次數據庫服務器,這個中間的過程? 也可以稱為是一次會話這個過程.關鍵數據的狀態? ? 會話中記錄的內容,只是當前的狀態
日志會記錄整個變化的過程(之前是啥樣的,修改之后又是啥樣的)
服務器收到后續請求之后,直接通過cookie 中的sessionld
就可以知道當前這個請求是哪個用戶發來的了.? 就不需要要求用戶重新登陸.Cookie是可能會過期的.服務器返回Cookie的時候,是可以設置有效時間
如果Cookie 中的sessionld過期了,此時就需要用戶重新登陸了.
用戶重新登陸的時候,是否需要重新手動輸入一遍密碼,瀏覽器的記住密碼功能解決的問題了有的網站,對于安全性要求不高,過期時間就長
有的網站,對于安全性要求很高,過期時間就短
(網銀...只要你把頁面關閉/幾分鐘之內不操作,就會自動過期)
在公共電腦上操作,人就離開了---下一個人拿到這個電腦舉個例子:
1.掛號辦理一個就診卡.就需要填寫表格,記錄一些核心信息? 醫生把這些信息錄入電腦,醫生給你一個就診卡
相當于生成會話.就診卡只存儲一個會話id(卡可能會丟)2.兒科門診? ?刷一下就診卡? ? ?刷卡,醫生電腦上就顯示出了這個患者的所有信息
醫生開了檢查---開了一些單子? ? ?直接記錄到會話中
3.檢驗科--刷一下就診卡
檢驗科的醫生立即看到了我這邊要查啥
4.影像科--刷一下就診卡
5.回到兒科診室--刷一下就診卡
檢查結果,直接顯示到醫生的電腦上了通過Java socket構造HTTP請求? ? HTTP請求,本質上就是TCP請求
只需要構造字符串,符合HTTP協議格式.? ? 寫入到TCP socket中


對密鑰的理解
HTTPS? ?加密
HTTPS=HTTP+S(SSL/TLS)? ? 也是一個應用層協議. 專門負責加密."加密"是什么
加密就是把明文(要傳輸的信息)進行一系列變換,生成密文,
解密就是把密文再進行一系列變換,還原成明文.在這個加密和解密的過程中,往往需要一個或者多個中間的數據,輔助進行這個過程,這樣的數據稱為密鑰
1.對稱加密.? ?加密和解密使用同一個密鑰
2.非對稱加密? 加密使用一個密鑰? ?解密使用另一個密鑰把其中一個公開出去,公鑰
另一個自己保存好,私鑰你裝了wifi萬能鑰匙之后自動把你手機中已經保存的wifi和密碼上傳到服務器
別人用wifi萬能鑰匙連到同一個wifi上就能破解(獲取到之前別人上傳的密碼)
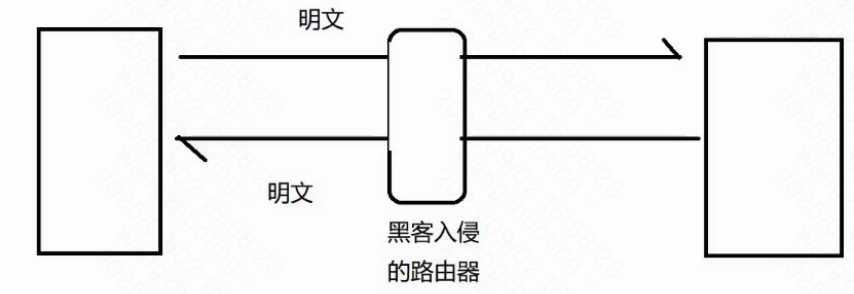
后來被手機廠商做出限制了之前是明文傳輸的:
此時黑客很容易獲取到
傳輸的數據內容,也很容易進行篡改
如果不知道key是啥? ?就無法對數據進行解密? 無法理解數據的含義,更不必說算改了
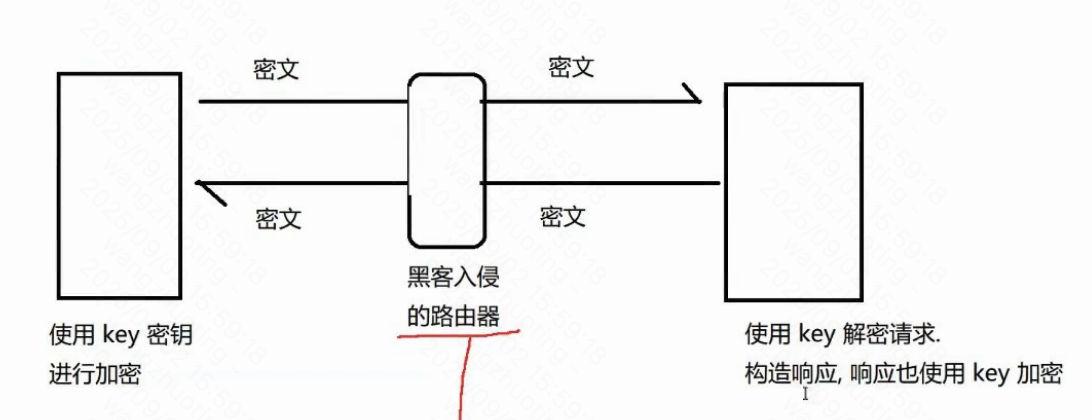
服務器要給N個客戶端提供服務多個客戶端,密鑰是相同還是不同??必須是不同的!!!
如果大家都是相同的密鑰,意味著黑客自己搞個客戶端就拿到密鑰了
(你的銀行卡密碼,和我的能一樣嗎??)
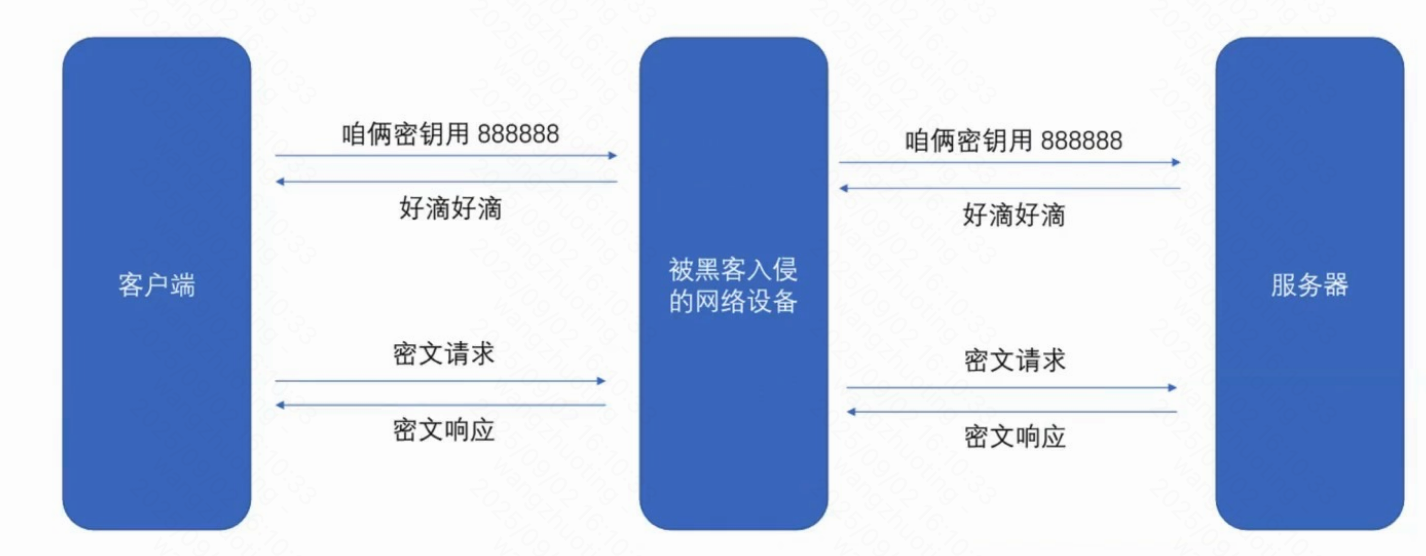
密鑰本身是明文傳輸的~~就可能被黑客獲取到
一旦黑客拿到密鑰,后續的加密操作就無意義了
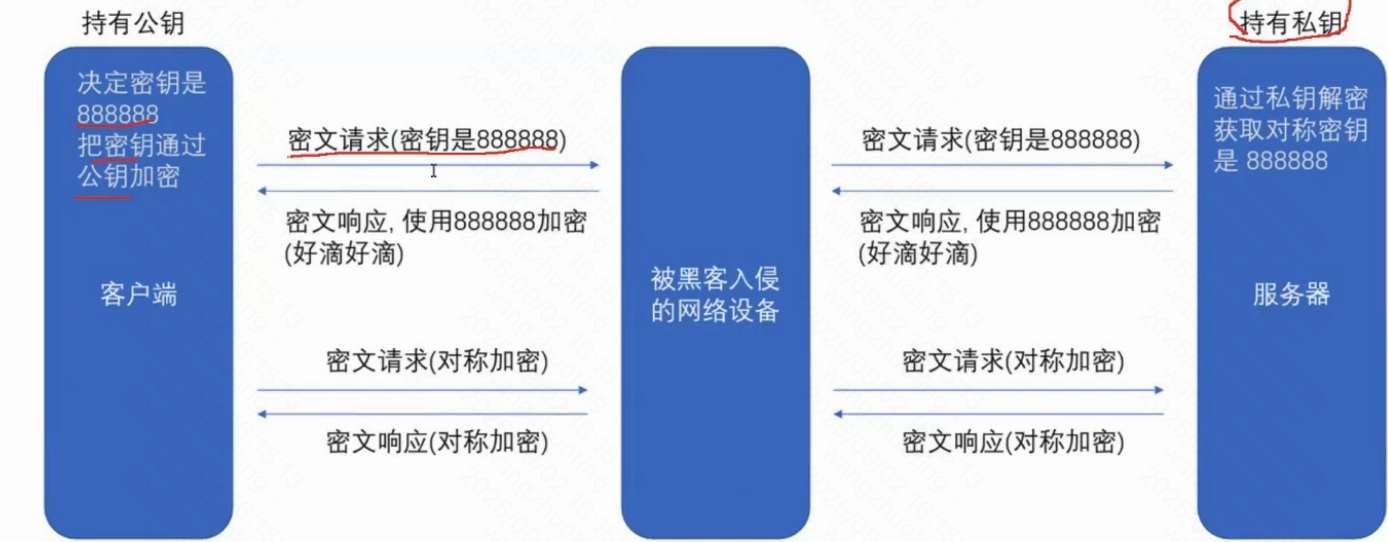
公鑰是一把鎖? 私鑰是對應的鑰匙
基于前人研究出來的加密算法,生成的.(有一系列數學原理)數學上,針對兩個非常大的素數,做乘積,很容易的.? ? 根據乘積因式分解回剛才的兩個大素數,非常難的
這一對公鑰私鑰,就是這兩個大素數
由于黑客手里沒有私鑰.? ?所以黑客不能對888888加密后的數據進行解密的.
此時數據到達服務器,服務器使用自己的私鑰解密就知道了對稱密鑰是多少了直接全用非對稱加密不行嗎??
實際情況是,需要
對稱加密,運算速度快,開銷小.適合針對大量數據進行加密.
非對稱加密,運算速度慢,開銷大.加密小的數據,還行.加密大量數據,非常耗時上述方案存在嚴重漏洞




開發及打包EXE指南)





STM32F103 片內資源 —— 直接存儲 DMA 實戰 編碼詳解)








