論文精讀-SwinIR: Image Restoration Using Swin Transformer
SwinIR:使用 Swin Transformer進行圖像恢復
參數量:SR 11.8M、JPEG壓縮偽影 11.5M、去噪 12.0M

優點:1、提出了新的網絡結構。它采用分塊設計。包括淺層特征提取:cnn提取,得到低維特征。深層特征提取:使用殘差連接(過程可融合不同維度的特征)+Swin transformer+CNN特征增強,得到高緯特征。高質量圖像重建:融合淺特征和深特征。
2、針對不同任務設計了相應的損失函數,針對SR使用圖像重建模塊函數,并使用L1像素損失。針對去噪和JPEG壓縮使用殘差學習構建LQ和HQ圖像之間的殘差,并使用Charbonnier損失。
3、消融實驗清晰,對比了不同參數的效果,并給出了與先進模型的比較
小結:總體使用深度學習(設計了新的基于SWIN的網絡結構)的方法進行圖像恢復,針對圖像恢復中超分(低尺度)和去噪(噪聲),JPEG壓縮偽影(壓縮圖像)3種代表性任務使用不同的損失函數。
如果無法查看圖片請查看:論文精讀-SwinIR Image Restoration Using Swin Transformer
概述
圖像恢復是一個長期存在的低級視覺問題,其目的是從低質量圖像(例如,低尺度、噪聲和壓縮圖像)中恢復高質量圖像。雖然最先進的圖像恢復方法是基于卷積神經網絡的,但很少有人嘗試用變形金剛在高級視覺任務中表現出令人印象深刻的表現。在本文中,我們提出了一個基于Swin Transformer 的強基線模型SwinIR 用于圖像恢復。SwinIR 包括三個部分:淺層特征提取、深層特征提取和高質量圖像重建。其中,深度特征提取模塊由多個殘差Swin Transformer 塊(RSTB)組成,每個殘差塊都有多個Swin Transformer 層和殘差連接。我們對圖像超分辨率(包括經典圖像、輕量級圖像和真實圖像超分辨率)、圖像去噪(包括灰度圖像和彩色圖像去噪)和JPEG 壓縮偽影減少三個具有代表性的任務進行了實驗。實驗結果表明,SwinIR 在不同任務上的性能優于最先進的方法,最高可達0.14 ~ 0.45dB,而參數總數可減少67%。
背景介紹
大多數基于 cnn 的方法側重于精細的架構設計,如殘差學習[43,51]和密集連接[97,81]。雖然與傳統的基于模型的方法相比,性能有了明顯的提高方法[73,14,28],它們通常會遇到兩個源于基本卷積層的基本問題。首先,圖像和卷積核之間的交互是內容無關的。使用相同的卷積核來恢復不同的圖像區域可能不是最好的選擇。其次,在局部處理的原理下,卷積對于遠程依賴建模是無效的。
作為 CNN 的替代方案,Transformer[76]設計了一種自注意機制來捕捉上下文之間的全局交互,并在幾個視覺問題中顯示出良好的性能[6,74,19,56]。然而,用于圖像恢復的視覺變形金剛[9,5]通常將輸入圖像分割成固定大小的小塊(如 48×48),并對每個小塊進行獨立處理。這樣的策略不可避免地會產生兩個弊端。
1、首先,邊界像素不能利用補丁之外的鄰近像素進行圖像恢復。(使用3x3卷積)
2、其次,修復后的圖像可能會在每個補丁周圍引入邊界偽影。雖然這個問題可以通過斑塊重疊來緩解,但它會帶來額外的計算負擔。
最 近 , Swin Transformer[56] 集成了 CNN 和Transformer 的優點,顯示出很大的前景。
一方面,由于局部注意機制,它具有 CNN處理大尺寸圖像的優勢。
另一方面,它又具有 Transformer 的優勢,可以用移位窗口方案(固定分區與移動分區)對遠程依賴進行建模。
相關工作
1.圖像恢復
與傳統的基于模型的圖像恢復方法[28,72,73,62,32]相比,基于學習的方法,特別是基于 cnn 的方法,由于其令人印象深刻的性能而變得越來越受歡迎。它們經常學習來自大規模配對數據集的低質量圖像和高質量圖像之間的映射。自開創性的 SRCNN[18](用于圖像 SR)、DnCNN90和 ARCNN[17](用于 JPEG 壓縮偽跡還原)以來,已經提出了一系列基于 cnn 的模型,通過使用更精細的神經網絡架構設計,如殘差塊[40,7,88]、密 集 塊 [81,97,98] 和 其 他[10,42,93,78,77,79,50,48,49,92,70,36,83,30,11,16,96,64,38,26,41,25]來提高模型表示能力。其中一些利用了 CNN 框架內的注意機制,如頻道注意[95,15,63]、非局部注意[52,61]和自適應補丁聚集[100]。
2.視覺Transformer
最近,自然語言處理模型 Transformer[76]在計算機視覺界獲得了很大的普及。當用于圖像分類,對象檢測[6,53,74,56],分割[84,99,56,4]和人群計數[47,69]等視覺問題時[66,19,84,56,45,55,75],,它通過探索不同區域之間的全局交互來學習關注重要的圖像區域。由于其令人印象深刻的性能,Transformer 也被引入到圖像恢復中[9,5,82]。Chen 等[9]在標準 Transformer 的基礎上提出了一種針對各種恢復問題的骨干模型 IPT。然而,IPT 依賴于大量的參數(超過115.5 萬個參數)、大規模的數據集(超過 110 萬張圖像)和多任務學習來獲得良好的性能。Cao 等人[5]提出的 VSR-Transformer 利用自注意機制在視頻 SR 中進行更好的特征融合,但仍然從 CNN 中提取圖像特征。此外,IPT 和VSR-Transformer 都是局部關注,可能不適用于圖像恢復。此 外 , 一 項 并 行 研 究 [82] 提 出 了 一 種 基 于 SwinTransformer 的 u型架構[56]。
方法
概述
本文提出了一種基于 Swin Transformer 的圖像恢復模型—SwinIR。更具體地說,SwinIR 包括三個模塊:淺層特征提取、深層特征提取和高質量圖像重建模塊。淺層特征提取模塊使用卷積層提取淺層特征,直接傳輸到重建模塊,從而保留低頻信息。深度特征提取模塊主要由殘差 SwinTransformer 塊(RSTB)組成,每個殘差塊利用多個 SwinTransformer 層進行局部關注和跨窗口交互。此外,我們在塊的末尾添加了一個卷積層用于特征增強,并使用殘差連接為特征聚合提供了一條捷徑。最后,在重建模塊中融合淺特征和深特征,實現高質量的圖像重建。
與流行的基于 cnn 的圖像恢復模型相比,基于transformer 的 SwinIR 具有以下幾個優點:
(1)圖像內容和注意力權重之間基于內容的交互,可以解釋為空間變化的卷積[13,21,75]。
(2)通過移位窗口機制實現遠程依賴建模。
(3)參數更少,性能更好。例如,如圖 1 所示,與現有的圖像 SR 方法相比,SwinIR 以更少的參數獲得了更好的PSNR。
網絡體系結構

1、淺層特征提取
給定一個低質量(LQ)輸入ILQ∈RH×W ×C in (H、W和 Cin分別為圖像高度、寬度和輸入通道號),我們使用一個 3 ×3 卷積層 HSFnull(·)提取淺層特征 F0∈RH×W ×C as

卷積層擅長早期視覺處理,導致優化更穩定,結果更好[86]。它還提供了一種將輸入圖像空間映射到高維特征空間的簡單方法。
2、深層特征提取
從 F0中提取深度特征 FDF∈RH×W ×C為

在 HDF(·)為深度特征提取模塊,包含 K 個殘差 Swin Transformer 塊(RSTB)和一個 3 ×3 卷積層。更具體地說,中間特征 F1 F2 ,……FK 和輸出深度特征 FDF 逐塊提取為

在 HRSTBi (·)表示第 i 個 RSTB層,HCONV是最后一
個卷積層。
使用卷積層在特征提取的末端可以將卷積運算的歸納偏置帶入到基于transformer 的網絡中,為后期淺層和深層特征的聚合奠定更好的基礎。
3、特征融合(圖像重建)
針對超分,IRHQ通過將淺層和深層特征聚合
[外鏈圖片轉存中…(img-vYsp7cTc-1716003176503)]
淺層特征主要包含低頻,深層特征側重于恢復丟失的高頻。SwinIR 通過較長的跳線連接,將低頻信息直接傳遞給重構模塊,幫助深度特征提取模塊專注于高頻信息,穩定訓練。
對于重構模塊的實現,我們使用亞像素卷積層[68]對特征進行上采樣。
對于不需要上采樣的任務,如圖像去噪和 JPEG 壓縮偽影減少,使用單個卷積層進行重建。此外,我們使用殘差學習來重建 LQ 和 HQ 圖像之間的殘差,而不是 HQ 圖像。其公式為
[外鏈圖片轉存中…(img-HbmHXEZW-1716003176503)]
式中,HSwinIR(·)為 SwinIR函數。
4、損失函數
1、針對SR,L1像素損失(與之前工作相同,為了凸顯網絡結構的有效性):

IHQ是真實的HQ圖像,而IRHQ是前面網絡輸出結果。
2、針對圖像去噪和減少 JPEG壓縮偽影,我們使用Charbonnier 損失:
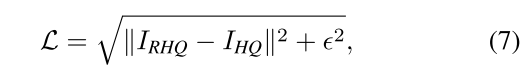
經驗設置偏置項為10^-3
殘差Swin Transformer塊
RSTB是由Swin Transformer 層(STL)和卷積層組成的殘差塊。給定輸入特征 Fi,0 在第 i 個 RSTB 中,我們首先提取中間特征Fi,1, Fi,2,…, Fi,L × L Swin Transformer 層為

在 HSTLi,j (·) 為第 i 個 RSTB 中的第 j 個 Swin Transformer 層。然后,我們在殘差連接前添加一個卷積層。
RSTB的輸出公式為

其中Hconvi是第i個RSTB卷積層
優點:
1、雖然 Transformer 可以被視為空間變化卷積的具體實例[21,75],但具有空間不變濾波器的卷積層可以增強 SwinIR 的平移等方差。
2、殘差連接提供了從不同塊到重建模塊的基于特征的連接,允許不同級別特征的聚合。
Swin Transformer 層
Swin Transformer 層(STL)[56]是基于原始 Transformer 層的標準多頭自關注[76]。其主要區別在于局部注意和移位窗口機制。
1、將HxWxC的輸入轉換為MxM的局部窗口(padding)

其中HW/M^2是新窗口數量
2、分別計算每個窗口的局部注意力(標準自注意力)

其中 B 為可學習的相對位置編碼。在實踐中,遵循[76],我們并行執行注意函數 h 次,并將多頭自我注意(MSA)的結果連接起來。
(transformer encoder)
3、使用MLP進行進一步的特征轉換,該感知器具有兩個完全連接的層,它們之間具有GELU非線性。
在 MSA和 MLP之前都添加了 LayerNorm(LN)層,兩個模塊都使用了剩余連接。

但是,當為不同的層固定分區時,沒有跨本地窗口的連接。因此,常規和移位的窗口分區交替使用以實現跨窗口連接[56],其中移位的窗口分區意味著將特征移動
 分割前的像素。
分割前的像素。
實驗
1、通道數、RSTB(Residual Swin Transformer Block)數、STL(Swin Transformer Layer)數
對于信道數,雖然性能不斷增加,但參數總數呈二次增長。為了平衡性能和模型大小,我們在其余實驗中選擇 180 作為通道數。
對于 RSTB 數和層數,性能增益逐漸趨于飽和。我們為它們都選擇 6,以獲得一個相對較小的模型。

2、patch大小和訓練圖像數量
訓練數據量越大,patch size越大,最終效果越好。
4、RSTB殘差連接與卷積影響
1)、殘差連接。Pos
2)、3x3卷積可以提取局部鄰近特征。Pos
3)、1x1,幾乎無影響。
4)、多個3x3卷積會減少參數量,但是會影響模型性能。Neg

實驗結果:
1、在基準數據集上,與最先進的經典圖像 SR 方法進行定量比較(平均 PSNR/SSIM)。最佳和次佳表現分別為紅色和藍色。在×8上的結果在附錄中提供。

2、在基準數據集上與最先進的輕量級圖像 SR方法進行定量比較(平均 PSNR/SSIM)。最佳和次佳表現分別用紅色和藍色表示。


3、在基準數據集上使用最先進的 JPEG 壓縮偽影減少方法進行定量比較(平均 PSNR/SSIM/PSNR- b)。最佳和次佳性能分別用紅色和藍色表示。

4、與最先進的灰度圖像去噪方法在基準數據集上的定量比較(平均 PSNR)。最佳和次佳表現分別為紅色和藍色。
5、與最先進的彩色圖像去噪方法在基準數據集上的定量比較(平均 PSNR)。最佳和次佳表現分別為紅色和藍色。
[外鏈圖片轉存中…(img-oNyBcROt-1716003176506)]
QA
(待補充)
Q:圖像超分辨率(包括經典圖像、輕量級圖像和真實圖像超分辨率)、圖像去噪(包括灰度圖像和彩色圖像去噪)和JPEG 壓縮偽影減少?
Q:密集連接?殘差塊,密集塊
Q:局部處理?
Q:圖像和卷積核之間的交互是內容無關的?
Q:一方面,由于局部注意機制,它具有 CNN處理大尺寸圖像的優勢。另一方面,它又具有 Transformer 的優勢,可以用移位窗口方案對遠程依賴進行建模?
Q:卷積層提取淺層特征,低頻信息?
Q:sr方法?psnr?
Q:卷積本質?為什么可以將圖像轉為高維表示?
Q:swin transformer layer(STL)?
Q:類似via, NMP+NAS
A:
Q:上采樣與下采樣?
A:
Q:L1正則化?
A:
Q:Transformer 可以被視為空間變化卷積的具體實例?
A:
Q:最后一個cnn是怎么增強特征的?
A:
Q:卷積運算的歸納偏置?
A:
Q:HREC與HSwinIR?
A:
Q:vit中MLP不同層使用固定分區與移位窗口分區?
A:
Q:平滑,要么過于銳化,無法恢復豐富的紋理?
A:
Q:邊界偽影?
[Ref:Liang J, Cao J, Sun G, et al. Swinir: Image restoration using swin transformer[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 1833-1844.]



)




)




)





