
代碼地址:GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
論文地址:https://arxiv.org/pdf/2405.14458
本文介紹了YOLO系列目標檢測器在實時和高效方面的優勢,但是仍然存在一些缺陷,包括依賴非極大值抑制(NMS)后處理導致部署效率降低,以及模型架構設計還有待進一步優化。提出了一種一致雙賦值策略(?consistent dual assignment),用于無需NMS的YOLO訓練,可以在保持檢測性能的同時提高部署效率。提出了一種全面的高效-高精度驅動的模型設計策略,從效率和精度兩個角度對YOLO的各個組件進行了優化設計。基于上述方法,提出了新一代實時端到端目標檢測器YOLOv10,在不同模型規模下,YOLOv10都能實現業界最優的計算效率和檢測精度權衡。在COCO數據集上進行了大量實驗,結果表明YOLOv10在各種模型規模下均顯著優于其他先進的檢測器,如在相似mAP水平下,YOLOv10-S/X比RT-DETR-R18/R101加速1.8/1.3倍。
就在昨天yolo的第10個版本來了,是不是yolov9都還沒有吃透,這緊接著yolov10就來了
Introduction
這篇文章主要討論了兩個方面來推進實時端到端目標檢測任務中YOLO系列模型的性能-效率權衡:
提出了一種稱為"一致雙賦值(?consistent dual assignment)"的方法,用于YOLO模型的無NMS訓練。這種方法在訓練時保留了one-to-many賦值的豐富監督信息,而在推理時則采用one-to-one賦值避免使用NMS后處理,從而獲得更高的推理效率。
提出了一種"全面的效率-精度驅動"的模型設計策略。在效率方面,引入了輕量級分類頭、空間-通道解耦下采樣和基于rank-guided的塊設計等技術減少計算冗余。在精度方面,探索了大核卷積和部分自注意力模塊來提高模型能力。
Related Work
Real-time object detectors.回顧了YOLO系列模型的發展歷程,包括YOLOv1到YOLOv9,以及其他一些重要的實時檢測器如PPYOLOE、RTMDet、YOLO-MS、Gold-YOLO等。
End-to-end object detectors.?介紹了基于Transformer的DETR及其變體(如Deformable DETR、DINO、RT-DETR等)如何實現端到端目標檢測。另一方面也提到了一些基于CNN的端到端檢測器,如OneNet、DeFCN、FCOS等。
這部分概括了YOLO系列和一些其他實時端到端檢測器的最新進展,為接下來提出的YOLOv10工作做鋪墊。同時也指出了現有工作在后處理(依賴NMS)和模型架構設計方面的不足,為作者的工作方向提供了動機。
Methodology
Consistent Dual Assignments for NMS-free Training
3.1節介紹了作者提出的一種稱為"一致雙賦值"(Consistent Dual Assignments)的訓練策略,使YOLO模型能夠在訓練時享有豐富的監督信號,同時在推理時免去NMS后處理,實現真正的端到端檢測,提升部署的推理效率。主要內容包括:
雙標簽賦值(Dual Label Assignments)
為YOLO模型引入另一個one-to-one分支,與原有的one-to-many分支共同優化。前者避免了冗余預測,后者提供豐富監督。在推理時只使用one-to-one分支的預測。
與一對多分配不同,一對一匹配僅將一個預測分配給每個GT,從而避免了 NMS 后處理。然而,它會導致監督薄弱,從而導致精度和收斂速度欠佳。幸運的是,這種缺陷可以通過一對多分配來彌補。為了實現這一目標,作者為 YOLO 引入了雙標簽分配,以結合兩種策略的優點。具體而言,如圖2(a)所示。
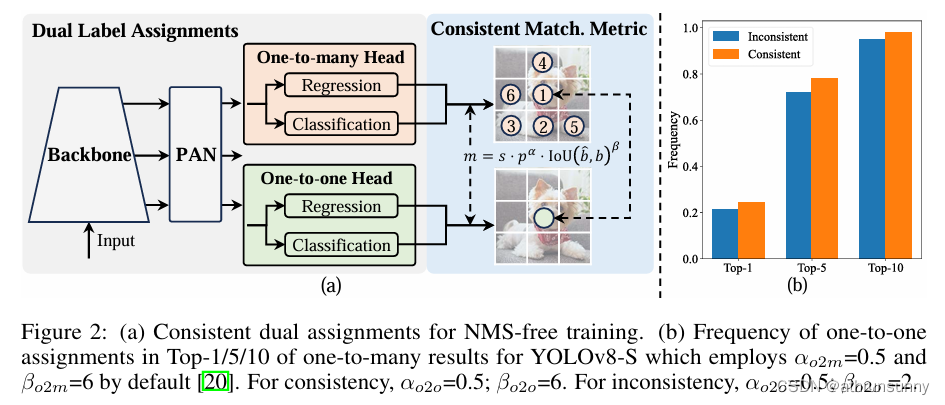
作者為YOLOs加入了另一個一對一的頭。它保留了與原來的一對多分支相同的結構并采用相同的優化目標,但利用一對一匹配來獲得標簽分配。在訓練過程中,兩個頭部與模型共同優化,讓backbone和neck享受一對多任務提供的豐富監督。在推理過程中,丟棄一對多的頭部,并利用一對一的頭部進行預測。這使 YOLO 能夠進行端到端部署,而不會產生任何額外的推理成本。此外,在一對一匹配中,作者采用top one selection,這達到了與匈牙利匹配相同的性能,但額外的訓練時間更少。
一致匹配度量(Consistent Matching Metric)
引入統一的匹配度量公式,使one-to-one分支的最佳正樣本與one-to-many分支一致,從而兩個分支可以協調優化,one-to-one分支獲得改進的監督對齊。
![]()
其中表示分類得分,
和
分別表示prediction和instance的邊界框。
表示空間先驗,指示預測的錨點是否在實例內。
和
是兩個重要的超參數,用于平衡語義預測任務和位置回歸任務的影響。將一對多和一對一指標分別表示為
和
。這些指標會影響兩個heads的標簽分配和監督信息。
在雙標簽分配中,一對多分支比一對一分支提供更豐富的監督信號。直觀地說,如果能夠協調一對一head和一對多head的監督,就可以將一對一head優化到一對多head優化的方向。因此,一對一head可以在推理過程中提供更好的樣本質量,從而獲得更好的性能。為此,首先分析了兩個head之間的監督差距。
由于訓練過程中的隨機性,一開始就用相同的值初始化兩個head并產生相同的預測來啟動檢查,即一對一head和一對多head為每個預測-實例對生成相同的和
。兩個分支的回歸目標并不沖突,因為匹配的預測共享相同的目標,并且不匹配的預測將被忽略。因此,監管差距在于不同的分類對象。
給定一個實例,將預測的最大表示為
,最大的一對多和一對一匹配分數分別表示為
和
。假設一對多分支產生正樣本
,一對一分支選擇度量
的第
個預測,然后可以推導出分類目標
對于
,以及任務對齊損失
。因此,兩個分支之間的監督差距可以通過不同分類目標的1-Wasserstein距離得出,即

差距隨著的增加而減小,即
在
內排名更高。當
時達到最小值,即
是
中最好的正樣本,如圖2(a)所示。為了實現這一點,提出了一致的匹配指標,即
和
,這意味著
。因此,一對多head的最佳正樣本也是一對一head的最佳樣本。因此,兩個head可以一致、和諧地進行優化。為簡單起見,默認取
,即
和
。為了驗證改進的監督對齊,計算了訓練后一對多結果的前 1 / 5 / 10 內的一對一匹配對數。如圖 2(b) 所示。在一致匹配指標下改進了對齊。更多的細節可以看論文的附錄。
Holistic Efficiency-Accuracy Driven Model Design
3.2節介紹了作者提出的一種全面的效率-精度驅動的模型設計策略,旨在從效率和精度兩個角度對YOLO模型的不同組件進行優化,以進一步推進YOLO的性能-效率邊界。
Efficiency driven model design.?YOLO 中的組件由stem、下采樣層、stages with basic building blocks和head組成。stem產生的計算成本很少,因此對其他三個部分進行效率驅動的模型設計。
總結如下:
- 輕量級分類頭-采用深度可分離卷積構建更高效的分類頭,降低計算開銷。
- 空間-通道解耦下采樣-將下采樣操作解耦為通道變換和空間降維兩步,以獲得更高效率。
- 基于rank-guided的塊設計-分析網絡各階段的冗余程度,對冗余階段采用更緊湊的基本塊結構,如緊湊的逆殘差塊(CIB)。
(1) Lightweight classification head.在 YOLO 中,分類頭和回歸頭通常共享相同的架構。但是,它們在計算開銷方面表現出明顯的差異。例如,YOLOv8-S中分類頭(5.95G/1.51M)的FLOPs和參數數量分別為2.5×和2.4×回歸頭(2.34G/0.64M)。然而,在分析了分類誤差和回歸誤差的影響(見表6)后,作者發現回歸頭對YOLO的性能具有更大的意義。因此,可以減少分類頭的開銷,而不必擔心會嚴重損害性能。因此,作者簡單地為分類頭采用輕量級架構,它由兩個深度可分離卷積組成,核大小為 3×3,后跟一個 1×1 卷積。
(2) Spatial-channel decoupled downsampling.YOLO 通常利用步幅為 2 的常規 3×3 標準卷積,同時實現空間下采樣(從到
)和通道轉換(從
到
)。這引入了
的不可忽略的計算成本和
的參數量。相反,作者提出將空間縮減和信道增加操作解耦,從而實現更有效的下采樣。具體來說,首先利用逐點卷積來調制通道維度,然后利用深度卷積進行空間下采樣。這將計算成本降低到
,參數計數為
。同時,它在縮減采樣過程中最大限度地保留了信息,從而在減少延遲的情況下實現了具有競爭力的性能。
(3) Rank-guided block design.YOLO通常對所有階段都使用相同的基本構建塊,例如YOLOv8中的瓶頸塊。為了徹底檢驗YOLO的這種同質設計,作者利用intrinsic rank來分析每個階段的冗余性。具體來說,作者計算每個階段最后一個基本塊中最后一個卷積的numerical rank,計算大于閾值的奇異值的數量。圖 3(a)給出了YOLOv8的結果,表明深階段和大模型容易表現出更多的冗余。這一觀察結果表明,簡單地對所有階段應用相同的塊設計對于最佳容量效率權衡來說是次優的。為了解決這個問題,作者提出了一種rank-guided block設計方案,旨在通過緊湊的架構設計來降低被證明是多余的階段的復雜性。
作者首先提出了一種compact inverted block(CIB)結構,該結構采用廉價的深度卷積進行空間混合,采用高性價比的逐點卷積進行通道混合,如圖3(b)所示。它可以作為高效的基本構建塊,例如,嵌入到ELAN結構中。然后,作者提倡以rank-guided block分配策略,以在保持競爭力的同時實現最佳效率。
具體來說,給定一個模型,根據其內在ranks按升序對其所有階段進行排序。進一步檢查了用 CIB 替換leading stage的基本塊的性能變化。如果與給定模型相比沒有性能下降,將繼續替換下一階段,否則停止該過程。因此,作者可以跨階段和模型規模實施自適應緊湊模塊設計,在不影響性能的情況下實現更高的效率。附錄中提供了算法的詳細信息。

Accuracy driven model design.?進一步探索了精度驅動設計的大核卷積和自注意力,旨在以最小的成本提高性能。
總結如下:
- 大核卷積-在深層CIB中使用7x7大核深度可分離卷積,增大感受野,提高小目標檢測能力。
- 部分自注意力(PSA)-提出PSA模塊,通過減少注意力頭數量降低計算開銷,同時引入全局建模能力。
(1) Large-kernel convolution.?采用大核深度卷積是擴大感受野和增強模型能力的有效方法。然而,簡單地在所有階段利用它們可能會在用于檢測小物體的淺層特征中引入污染,同時在高分辨率階段也會帶來大量的I/O開銷和延遲。因此,作者建議在深階段利用CIB中的大核深度卷積。具體來說,將 CIB 中第二個3×3深度卷積的核大小增加到7×7。此外,采用結構重參數化技術來引入另一個 3×3 深度卷積分支,以緩解優化問題,而不會產生推理開銷。此外,隨著模型大小的增加,其感受野自然擴大,使用大核卷積的好處會減少。因此,只對小模型尺度采用大核卷積。
(2) Partial self-attention (PSA).自注意力由于其卓越的全局建模能力而被廣泛用于各種視覺任務。但是,它表現出很高的計算復雜性和內存占用。為了解決這個問題,鑒于普遍存在的注意力頭冗余,作者提出了一種高效的部分自注意力(PSA)模塊設計,如圖3(c)所示。
具體來說,在 1×1 卷積之后將通道上的特征均勻地劃分為兩部分。只將一個部分輸入到由多頭自注意力模塊(MHSA)和前饋網絡(FFN)組成的中。然后將兩個部分連接起來,并通過 1×1 卷積融合。此外,按照 [Levit: a vision transformer in convnet’s clothing for faster inference] 將query和key的維度賦值為 MHSA 中值的一半,并將LayerNorm替換為BatchNorm以實現快速推理。此外,PSA僅放置在分辨率最低的Stage 4之后,避免了自注意力的二次計算復雜性帶來的過多開銷。這樣,就可以以較低的計算成本將全局表示學習能力整合到YOLO中,從而很好地增強了模型的能力,提高了性能。
Experiments
作者選擇 YOLOv8作為基線模型,因為它具有值得稱贊的延遲-準確性平衡以及它在各種模型大小中的可用性。作者采用一致的雙重分配進行無NMS訓練,并在此基礎上進行整體效率精度驅動的模型設計,從而帶來了作者的YOLOv10模型。YOLOv10 具有與 YOLOv8 相同的變體,即 N / S / M / L / X。此外,作者通過簡單地增加YOLOv10-M的寬度比例因子,推導出了一個新的變體YOLOv10-B。作者在相同的從頭開始訓練設置下驗證了COCO上提出的檢測器。
Comparison with state-of-the-arts
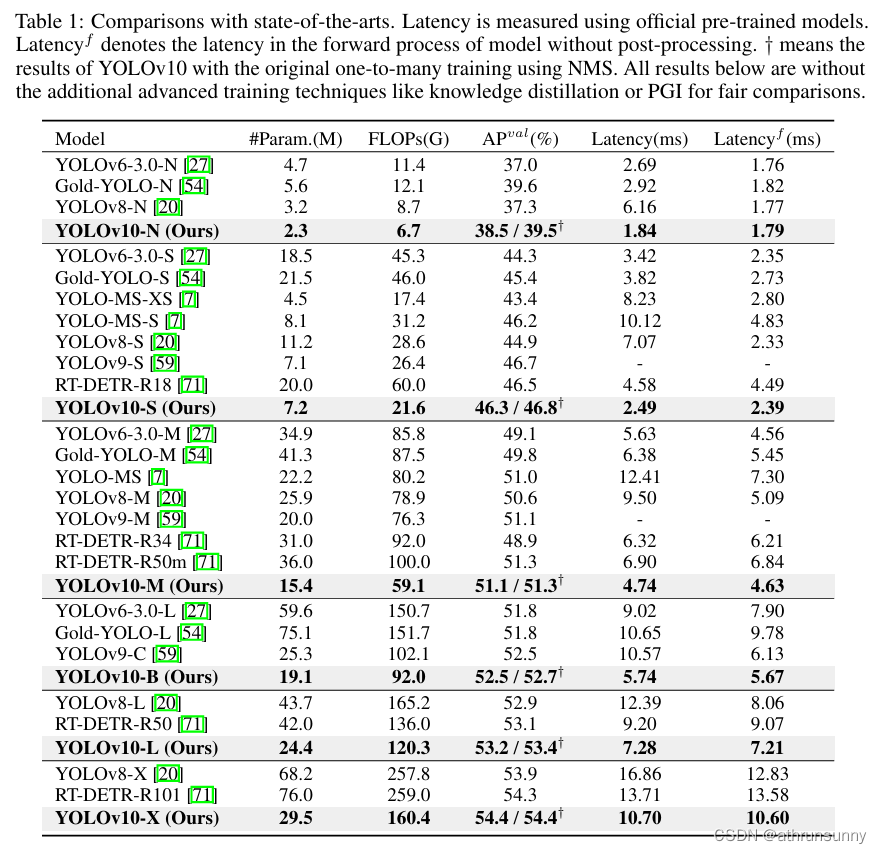
如表 1 所示, YOLOv10 在各種型號規模上實現了最先進的性能和端到端延遲。作者首先將 YOLOv10 與基線模型(即 YOLOv8)進行比較。在 N / S / M / L / X 五種變體上,YOLOv10 實現了1.2% / 1.4% / 0.5% / 0.5% / 0.3% / 0.5% AP 改進,參數量減少了 28% / 36% / 41% / 44% / 57%,計算量減少了 23% / 24% / 25% / 27% / 38%,延遲降低了 70% / 65% / 50% / 41% / 37%。與其他 YOLO 相比,YOLOv10 在精度和計算成本之間也表現出更好的權衡。具體來說,對于輕量級和小型型號,YOLOv10-N/S 的性能比 YOLOv6-3.0-N / S 高出 1.5 AP 和 2.0 AP,參數分別減少 51% / 61% 和計算量減少 41% / 52%。對于中型機型,與YOLOv9-C / YOLO-MS相比,YOLOv10-B/M在相同或更好的性能下分別享受了46%/62%的延遲降低。對于大型型號,與 Gold-YOLO-L 相比,作者的 YOLOv10-L 參數減少了 68%,延遲降低了 32%,AP 顯著提高了 1.4%。此外,與 RT-DETR 相比,YOLOv10 獲得了顯著的性能和延遲改進。值得注意的是,在相似的性能下,YOLOv10-S / X 的推理速度分別比 RT-DETR-R18 / R101 快 1.8× 和 1.3×。
Model Analyses?
Ablationstudy.
表 2 中介紹了基于 YOLOv10-S 和 YOLOv10-M 的消融結果。可以觀察到,無 NMS 訓練和一致的雙重分配顯著降低了 YOLOv10-S 的端到端延遲 4.63ms,同時保持了 44.3% AP 的競爭性能。此外,作者的效率驅動模型設計減少了 11.8 M 參數和 20.8 GFLOPs,YOLOv10-M 的延遲大幅降低了 0.65ms,很好地顯示了其有效性。此外,作者的精度驅動模型設計在 YOLOv10-S 和 YOLOv10-M 上實現了 1.8 AP 和 0.7 AP 的顯著改進,僅單獨只有 0.18 毫秒和 0.17 毫秒的延遲開銷,這很好地證明了其優勢。

AnalysesforNMS-freetraining.
Dual label assignments.作者提出了無NMS的YOLO的雙標簽分配,既可以在訓練過程中帶來對一對多(o2m)分支的豐富監督,又可以在推理過程中帶來一對一(o2o)分支的高效。根據 YOLOv8-S(即表 2 中的 #1)驗證其優勢。具體來說,作者分別引入了僅使用 o2m 分支和僅使用 o2o 分支的訓練基線。如表 3 所示,作者的雙標簽分配實現了最佳的AP-延遲權衡。

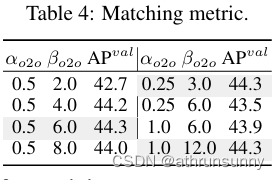
Consistent matching metric.?作者引入了一致的匹配指標,使一對一head與一對多head更加和諧。基于 YOLOv8-S(即表 2 中的 #1)在不同的和
下驗證了它的益處。如表4所示,建議的一致匹配指標,即
和
,可以達到最優性能,其中
,
。這種改進可歸因于監督差距的縮小(方程(2)),這改善了兩個分支之間的監督一致性。此外,所提出的一致匹配指標消除了對窮舉超參數調整的需要,這在實際場景中很有吸引力。
Analysesforefficiencydrivenmodeldesign.?
通過實驗逐步納入基于YOLOv10-S/M的效率驅動設計元素。作者的基線是 YOLOv10-S/M 模型,沒有效率精度驅動的模型設計,即表 2 中的 #2/#6。如表5所示,每個設計組件,包括輕量級分類頭、空間通道解耦下采樣和rank-guided模塊設計,都有助于減少參數計數、FLOPs和延遲。
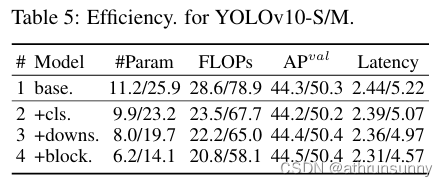
重要的是,這些改進是在保持競爭性能的同時實現的。
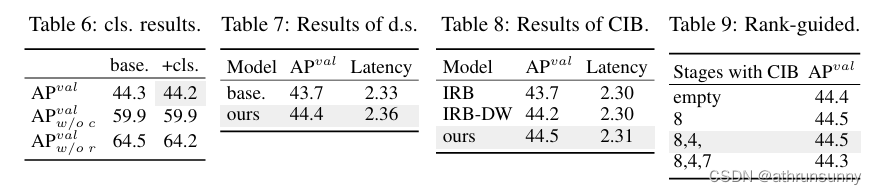
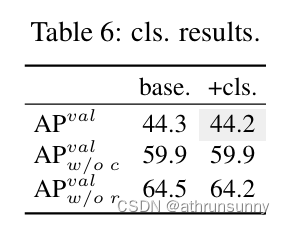
Lightweight classification head.根據表 5 中 #1 和 #2 的 YOLOv10-S 分析了預測的類別和局部誤差對性能的影響。具體來說,通過一對一的分配將預測與實例進行匹配。然后,將預測的類別分數替換為實例標簽,從而得到的沒有分類誤差。同樣,將預測的位置替換為實例的位置,從而生成
沒有回歸誤差。如表6所示,
遠高于
,揭示了消除回歸誤差可以實現更大的改進。因此,性能瓶頸更多地在于回歸任務。因此,采用輕量級分級頭可以在不影響性能的情況下實現更高的效率。
Spatial-channel decoupled downsampling.為了提高效率,作者將下采樣操作解耦,其中通道維度首先通過逐點卷積 (PW) 增加,然后通過深度卷積 (DW) 降低分辨率,以實現最大的信息保留。作者將其與基于表5中#3的YOLOv10-S的DW空間縮減然后PW通道調制的基線方式進行了比較。如表7所示,作者的下采樣策略通過減少下采樣過程中的信息丟失,實現了0.7%的AP改善。
Compact inverted block (CIB).作者引入 CIB 作為緊湊的基本構建塊。根據表 5 中 #4 的 YOLOv10-S 驗證其有效性。具體而言,作者引入倒置殘差塊(IRB) 作為基線,其可實現次優 43.7% AP,如表 8 所示。然后,作者在它后面附加一個 3×3 的深度卷積 (DW),表示為“IRB-DW”,它帶來 0.5% 的 AP 改善。與“IRB-DW”相比,作者的CIB以最小的開銷,進一步實現了0.3%的AP改進,表明了它的優勢。
Rank-guided block design.作者引入了rank-guided塊設計,自適應集成緊湊的塊設計,以提高模型效率。根據表 5 中 #3 的 YOLOv10-S 驗證其優勢。根據內在rank按升序排序的階段是階段 8-4-7-3-5-1-6-2,如圖 3 所示。如表9所示,當逐漸用高效的CIB替換每個階段的bottleneck block時,作者觀察到從階段7開始的性能下降。因此,在Stage 8和4中,固有rank較低,冗余度較多,因此可以在不影響性能的情況下采用高效的模塊設計。這些結果表明,rank-guided塊設計可以作為提高模型效率的有效策略。
Analyses for accuracy driven model design.
精度驅動模型設計的分析。本文介紹了基于YOLOv10-S/M的精度驅動設計元素的逐步集成結果。作者的基線是 YOLOv10-S/M 模型,在納入了效率驅動設計后,即表 2 中的 #3/#7。如表10所示,采用大內核卷積和PSA模塊,在0.03ms和0.15ms的最小延遲增加下,YOLOv10-S的性能分別提高了0.4%和1.4%。請注意,YOLOv10-M 不采用大核卷積(參見表 12)。
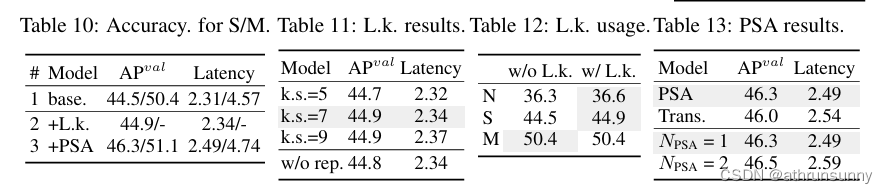
Large-kernelconvolution.作者首先根據表 10 中 #2 的 YOLOv10-S 研究了不同內核大小的影響。如表11所示,性能隨著內核大小的增加而提高,并在7×7的內核大小附近停滯,表明了大感受野的好處。此外,在訓練過程中去除重參數化分支可實現0.1%的AP劣化,顯示出其優化效果。此外,作者基于YOLOv10-N / S / M檢查了跨模型尺度的大核卷積的好處。如表12所示,由于YOLOv10-M固有的大感受野,它對大型模型(即YOLOv10-M)沒有帶來任何改進。因此,作者只對小模型采用大核卷積,即YOLOv10-N/S。
Partialself-attention(PSA).作者引入了PSA,通過以最低的成本整合全局建模能力來提高性能。作者首先根據表 10 中 #3 的 YOLOv10S 驗證其有效性。具體來說,作者引入了transformer模塊,即MHSA,然后是FFN,作為基線,表示為“Trans.”。如表13所示,與它相比,PSA帶來了0.3%的AP改善,延遲降低了0.05ms。性能的提高可歸因于通過減輕注意力頭的冗余,緩解了自注意力中的優化問題。此外,作者還研究了不同的影響。如表 13 所示,將
?提高到2?AP 可提高 0.2%,但延遲開銷為 0.1ms。因此,默認將
設置為 1,以增強模型能力,同時保持高效率。
![[240525] VMware Pro 個人可免費使用 | 人機交互角度 解釋 AI 同事出錯雖多但深得青睞之奧義](http://pic.xiahunao.cn/[240525] VMware Pro 個人可免費使用 | 人機交互角度 解釋 AI 同事出錯雖多但深得青睞之奧義)








![Python序列的概念與使用-課后作業[python123題庫]](http://pic.xiahunao.cn/Python序列的概念與使用-課后作業[python123題庫])






)
![[圖解]產品經理創新之阿布思考法](http://pic.xiahunao.cn/[圖解]產品經理創新之阿布思考法)

