摘要
在本文中,我們成功應用蒸餾策略以實現YoloV8小模型的無損性能提升。我們采用了CWDLoss作為蒸餾方法的核心,通過對比在線和離線兩種蒸餾方式,我們發現離線蒸餾在效果上更為出色。因此,為了方便廣大讀者和研究者應用,本文所描述的蒸餾方法僅保留了離線蒸餾方案。此外,我們還提供了相關論文的譯文,旨在幫助大家更深入地理解蒸餾方法的原理和應用。
論文翻譯:《用于密集預測任務的通道知識蒸餾》
https://arxiv.org/pdf/2011.13256
知識蒸餾(KD)已被證明是訓練緊湊密集預測模型的簡單有效工具。通過從大型教師網絡轉移而來的額外監督來訓練輕量級學生網絡。大多數先前的針對密集預測任務的KD變體都在空間域中對學生網絡和教師網絡的激活圖進行對齊,通常是通過在每個空間位置標準化激活值并最小化逐點和/或成對差異來實現的。與先前的方法不同,我們提出對每個通道的激活圖進行標準化以獲得軟概率圖。通過簡單地最小化兩個網絡的通道概率圖之間的Kullback-Leibler(KL)散度,蒸餾過程更關注于每個通道的最顯著區域,這對于密集預測任務來說是非常有價值的。
我們在一些密集預測任務上進行了實驗,包括語義分割和對象檢測。實驗表明,我們提出的方法在性能上顯著優于最先進的蒸餾方法,并且在訓練過程中需要的計算成本更低。特別地,我們在COCO數據集上將RetinaNet檢測器(ResNet50主干)的mAP提高了3.4%,在Cityscapes數據集上將PSPNet(ResNet 18主干)的mIoU提高了5.81%。代碼可在以下網址獲取:
https://git.io/Distiller
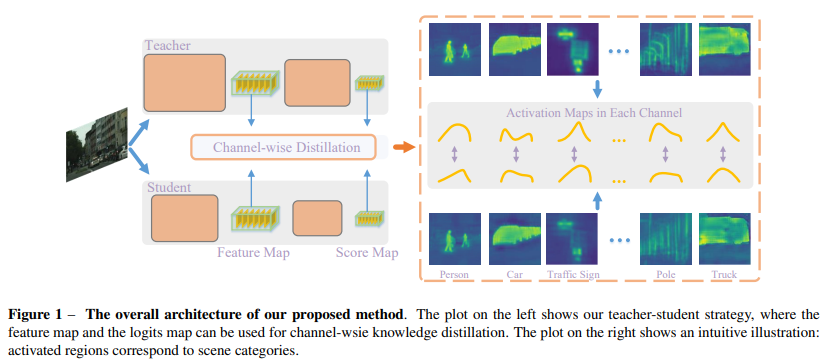
1、引言
密集預測任務是計算機視覺中的一組基礎任務,包括語義分割[48,6]和對象檢測[21,30]。這些任務需要在像素級別上學習強大的特征表示,以實現對復雜場景的理解。因此,最先進的模型通常需要高計算成本,這使得它們難以部署到移動設備上。因此,針對密集預測任務設計的緊湊網絡引起了廣泛關注。此外,先前的工作已經研究了通過使用知識蒸餾(KD)來有效訓練輕量級網絡。緊湊網絡在大教師網絡的監督下進行訓練,可以獲得更好的性能。對于圖像分類任務,已經提出了許多開創性的工作[16,2]并進行了深入研究。
密集預測任務是逐像素預測問題,比圖像級分類更具挑戰性。先前的研究[25,20]發現,直接將分類中的KD方法[16,2]轉移到語義分割可能無法獲得令人滿意的結果。嚴格對齊教師和學生網絡之間的逐點分類分數或特征圖可能會施加過于嚴格的約束,導致次優解。
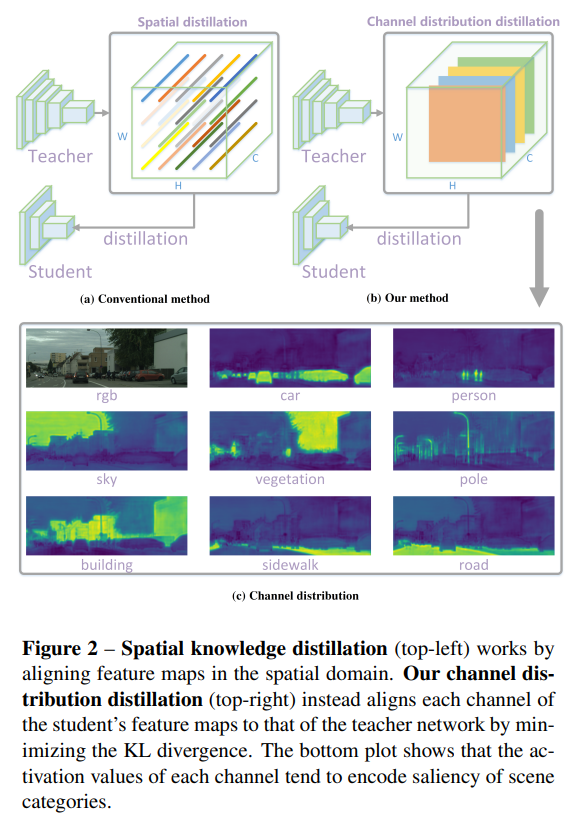
最近的工作[25,24,18]關注于加強不同空間位置之間的相關性。如圖2(a)所示,每個空間位置的激活值{}^{1}被標準化。然后,通過聚合不同空間位置的一個子集來執行一些特定于任務的關系,例如成對關系[25,35]和類間關系[18]。這樣的方法可能在捕獲空間結構信息方面比逐點對齊更好,并提高學生網絡的性能。
然而,在激活圖中,每個空間位置對知識轉移的貢獻是相等的,這可能會從教師網絡中帶來冗余信息。
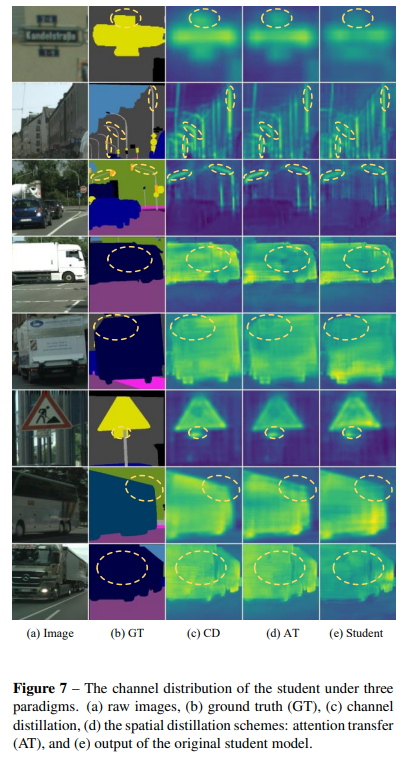
在這項工作中,我們提出了一種新穎的針對密集預測任務的通道級知識蒸餾方法,通過標準化每個通道的激活圖來實現,如圖2(b)所示。然后,我們最小化了教師網絡和學生網絡之間標準化通道激活圖的非對稱Kullback-Leibler(KL)散度,這些激活圖被轉換為每個通道的分布。我們在圖2?中展示了通道級分布的一個示例。每個通道的激活傾向于編碼場景類別的顯著性。對于每個通道,學生網絡被引導更多地關注于模仿具有顯著激活值的區域,從而在密集預測任務中實現更準確的定位。例如,在對象檢測中,學生網絡更加關注于學習前景對象的激活。
最近的一些工作利用了通道中包含的知識。通道蒸餾[50]提出將每個通道的激活轉換為一個聚合的標量,這對于圖像級分類可能有所幫助,但空間聚合丟失了所有空間信息,因此不適合密集預測。其他工作,如MGD[41]、通道交換[33]和CSC[26]顯示了通道級信息的重要性。MGD將教師通道與學生通道進行匹配,并將其視為一個分配問題來解決。通道交換[33]使用一個融合模塊來動態地在不同模態的子網絡之間交換通道。
我們展示了針對每個通道的簡單標準化操作可以極大地提高基于空間蒸餾的基線性能。所提出的通道級蒸餾方法簡單且易于應用于各種任務和網絡結構。我們總結我們的主要貢獻如下:
- 與現有的空間蒸餾方法不同,我們為密集預測任務提出了一種新穎的通道級蒸餾范式。我們的方法簡單但有效。
- 所提出的通道級蒸餾在語義分割和對象檢測方面顯著優于最先進的KD方法。
- 我們在四個基準數據集上展示了使用不同網絡結構在語義分割和對象檢測任務上的一致改進,證明了我們的方法是通用的。鑒于其簡單性和有效性,我們相信我們的方法可以作為密集預測任務的強大基線KD方法。
2、相關工作
在知識蒸餾領域,大多數工作都集中在分類任務上[11,12,16,27,36,38,45]。然而,這里的工作旨在研究針對密集預測任務的高效和有效的蒸餾方法,而不僅僅是像分類任務中那樣簡單地應用逐像素蒸餾。
語義分割的知識蒸餾。在[35]中,構建了一個局部相似度圖來最小化教師網絡和學生網絡之間分割邊界信息的差異,其中使用中心像素與其8個鄰域像素之間的歐幾里得距離作為傳輸的知識。Liu等人[24,25]提出了兩種方法來捕捉像素之間的結構化信息,包括像素之間的成對相似性和由判別器捕獲的全局相關性。在[34]的工作中,重點在于具有相同標簽的像素之間的類內特征變化,其中通過構建每個像素的特征與其對應的類級原型之間的余弦距離集來傳輸結構知識。He等人[14]則采用了一個特征適配器來減輕教師網絡和學生網絡之間的特征不匹配問題。
此外,正如您所提到的,通道級的知識蒸餾方法在密集預測任務中也逐漸受到關注。例如,一些方法通過標準化每個通道的激活圖并最小化教師網絡和學生網絡之間標準化通道激活圖的非對稱KL散度來改進知識蒸餾的效果。這種方法能夠讓學生網絡更加關注于模仿具有顯著激活值的區域,從而實現更準確的定位。與現有的空間蒸餾方法相比,通道級蒸餾在語義分割和對象檢測方面表現出了顯著的性能提升,并證明了其在不同網絡結構和基準數據集上的通用性。
目標檢測的知識蒸餾。在目標檢測任務中,許多方法發現區分前景和背景區域在蒸餾過程中非常重要。例如,MIMIC [20]通過 L 2 L_{2} L2?損失強制學生網絡的RPN內部特征圖與教師網絡相似,并發現直接應用逐像素損失可能會損害目標檢測的性能。Wang等人 [32] 提出蒸餾對象錨點位置附近的細粒度特征。Zhang和Ma [43] 使用注意力生成的掩碼來區分前景和背景,取得了顯著的效果。
然而,與這些方法不同,我們的方法通過柔和地對齊通道激活來區分前景和背景區域。具體來說,我們關注每個通道中包含的知識。最近的一些工作 [50] 也開始關注每個通道中包含的知識。例如,Zhou等人計算每個通道中激活的平均值,并在分類任務中對每個通道的加權差異進行對齊。CSC [26] 計算所有空間位置和所有通道之間的成對關系以傳輸知識。而Channel exchanging [33] 提出每個通道中包含的信息是通用的,可以在不同的模態之間共享。
3、我們的方法
我們首先回顧文獻中相關的空間知識蒸餾方法。
3.1、空間蒸餾
現有的KD方法通常采用逐點對齊或對齊空間位置之間的結構化信息,這可以表示為:
? ( y , y S ) + α ? φ ( ? ( y T ) , ? ( y S ) ) \ell(y, y^{S}) + \alpha \cdot \varphi(\phi(y^{T}), \phi(y^{S})) ?(y,yS)+α?φ(?(yT),?(yS))
在這里,任務損失 ? ( ? ) \ell(\cdot) ?(?)仍然被應用,其中 y y y是真實標簽。例如,在語義分割中,通常使用交叉熵損失。為了稍微濫用符號,這里 y S y^{S} yS和 y T y^{T} yT分別代表學生網絡和教師網絡的logits或內部激活。 α \alpha α是一個超參數,用于平衡損失項。下標 T {}^{T} T和 S {}^{S} S分別表示教師網絡和學生網絡。我們在表1中列出了代表性的空間蒸餾方法。
這些方法的簡要概述如下。注意力轉移(Attention Transfer,AT)[42]使用注意力掩碼將特征圖壓縮為單個通道以進行蒸餾。逐像素損失(Pixel-wise Loss)[17]直接對齊逐點的類別概率。局部親和力(Local Affinity)[35]通過中心像素與其8個鄰域像素之間的距離來計算。成對親和力(Pairwise Affinity)[25, 14, 24]被用來傳遞像素對之間的相似性。計算每個像素的特征與其對應的類別原型之間的相似性以傳遞結構知識[34]。在[25, 24]中的整體損失使用對抗性方案來對齊兩個網絡特征圖之間的高階關系。請注意,最后四項考慮了像素之間的相關性。如表1所示,現有的KD方法都是空間蒸餾方法。所有這些方法都將空間位置上的 N N N個通道激活值作為特征向量進行操作。

3.2、通道蒸餾
為了更好地利用每個通道中的知識,我們提出了在教師網絡和學生網絡之間柔和地對齊對應通道激活的方法。為此,我們首先將一個通道的激活轉換為概率分布,這樣我們就可以使用概率距離度量(如KL散度)來衡量差異。如圖2?所示,不同通道的激活傾向于編碼輸入圖像的場景類別的顯著性。此外,經過良好訓練的語義分割教師網絡顯示出每個通道清晰的特定于類別的掩碼激活圖,如圖1右側所示。在這里,我們提出了一種新穎的通道蒸餾范式,以指導學生從訓練有素的教師那里學習知識。
當我們使用LaTeX格式來表示數學符號時,我們會使用$符號來包圍LaTeX代碼。對于您提供的文本,我們可以將其轉化為LaTeX格式,并用$符號包圍起來。以下是轉化后的結果:
教師網絡和學生網絡分別表示為 T T T 和 S S S,來自 T T T 和 S S S 的激活圖分別為 y T y^{T} yT 和 y S y^{S} yS。通道蒸餾損失可以一般性地表示為:
φ ( ? ( y T ) , ? ( y S ) ) = φ ( ? ( y c T ) , ? ( y c S ) ) . \varphi\left(\phi\left(y^{T}\right), \phi\left(y^{S}\right)\right)=\varphi\left(\phi\left(y_{c}^{T}\right), \phi\left(y_{c}^{S}\right)\right) \,. φ(?(yT),?(yS))=φ(?(ycT?),?(ycS?)).
? ( ? ) \phi(\cdot) ?(?) 用于將激活值轉換為概率分布,具體為:
? ( y c ) = exp ? ( y c , i T ) ∑ i = 1 W ? H exp ? ( y c , i T ) , \phi\left(y_{c}\right)=\frac{\exp \left(\frac{y_{c, i}}{T}\right)}{\sum_{i=1}^{W \cdot H} \exp \left(\frac{y_{c, i}}{T}\right)} \,, ?(yc?)=∑i=1W?H?exp(Tyc,i??)exp(Tyc,i??)?,
其中 c = 1 , 2 , … , C c=1,2,\ldots,C c=1,2,…,C 索引通道; i i i 索引通道中的空間位置。 T T T 是一個超參數(溫度)。如果教師和學生之間的通道數不匹配,我們會使用一個 1 × 1 1 \times 1 1×1 的卷積層來上采樣學生網絡的通道數。 φ ( ? ) \varphi(\cdot) φ(?) 評估了來自教師網絡和學生網絡的通道分布之間的差異。我們使用 KL 散度:
φ ( y T , y S ) = T 2 C ∑ c = 1 C ∑ i = 1 W ? H ? ( y c , i T ) ? log ? [ ? ( y c , i T ) ? ( y c , i S ) ] . \varphi\left(y^{T}, y^{S}\right)=\frac{\mathcal{T}^{2}}{C} \sum_{c=1}^{C} \sum_{i=1}^{W \cdot H} \phi\left(y_{c, i}^{T}\right) \cdot \log \left[\frac{\phi\left(y_{c, i}^{T}\right)}{\phi\left(y_{c, i}^{S}\right)}\right] \,. φ(yT,yS)=CT2?c=1∑C?i=1∑W?H??(yc,iT?)?log[?(yc,iS?)?(yc,iT?)?].
KL 散度是一個不對稱度量。從上面的方程中我們可以看到,如果 ? ( y c , i T ) \phi\left(y_{c, i}^{T}\right) ?(yc,iT?) 很大, ? ( y c , i S ) \phi\left(y_{c, i}^{S}\right) ?(yc,iS?) 也應該盡可能大以最小化 KL 散度。否則,如果 ? ( y c , i T ) \phi\left(y_{c, i}^{T}\right) ?(yc,iT?) 非常小,KL 散度就不會太關注最小化 ? ( y c , i S ) \phi\left(y_{c, i}^{S}\right) ?(yc,iS?) 的值。
KL散度是一個非對稱度量。從方程(4)中我們可以看到,如果 ? ( y c , i T ) \phi\left(y_{c, i}^{T}\right) ?(yc,iT?)很大,為了最小化KL散度, ? ( y c , i S ) \phi\left(y_{c, i}^{S}\right) ?(yc,iS?)也應該盡可能地大,與 ? ( y c , i T ) \phi\left(y_{c, i}^{T}\right) ?(yc,iT?)一樣大。否則,如果 ? ( y c , i T ) \phi\left(y_{c, i}^{T}\right) ?(yc,iT?)非常小,KL散度在最小化 ? ( y c , i S ) \phi\left(y_{c, i}^{S}\right) ?(yc,iS?)時就不會太關注。因此,學生網絡傾向于在前景顯著區域產生類似的激活分布,而教師網絡背景區域對應的激活對學習的影響較小。我們假設KL的這種非對稱性質有利于密集預測任務的KD學習。
4、實驗
在本節中,我們首先描述實現細節和實驗設置。然后,我們將我們的通道級蒸餾方法與其他最先進的蒸餾方法進行比較,并在語義分割任務上進行消融研究。最后,我們在語義分割和對象檢測任務上展示了使用不同基準和學生網絡結構時的一致改進。
4.1、實驗設置
數據集。我們在這里使用了三個公開的語義分割基準數據集,分別是Cityscapes [8]、ADE20K [49]和Pascal VOC [10]。此外,我們還將提出的蒸餾方法應用于MS-COCO 2017 [23]上的對象檢測任務,這是一個包含超過120k張80個類別的圖像的大規模數據集。
Cityscapes 數據集用于城市場景語義理解。它包含5,000張精細標注的圖像,其中2,975/500/1,525張圖像分別用于訓練/驗證/測試,提供了30個常見類別,其中19個類別用于評估和測試。每張圖像的尺寸為2048x1024像素。這些圖像來自50個不同的城市。在我們的實驗中,我們沒有使用粗略標注的數據。
Pascal VOC 數據集包含 1 , 464 / 1 , 449 / 1 , 456 1,464 / 1,449 / 1,456 1,464/1,449/1,456 張圖像用于訓練/驗證/測試。它包含20個前景對象類別和一個額外的背景類別。此外,該數據集通過額外的粗略標注進行了擴充,其中包含10,582張訓練圖像。我們使用訓練分割進行訓練,并在21個類別上通過驗證集測量最終性能。
ADE20K 數據集涵蓋了150個不同場景的類別。它包含 20 K / 2 K / 3 K 20 \text{K} / 2 \text{K} / 3 \text{K} 20K/2K/3K 張圖像用于訓練、驗證和測試。在我們的實驗中,我們報告了驗證集上的分割精度。
評估指標。為了評估我們在語義分割上提出的通道分布蒸餾方法的性能和效率,我們遵循先前的工作[18,24],在所有實驗中通過單尺度設置下的平均交并比(mIoU)來測試每種策略。每秒浮點運算次數(FLOPs)是在固定輸入大小為 512 × 1024 512 \times 1024 512×1024 像素的情況下計算的。此外,對于Pascal VOC和ADE20K,我們列出了平均類別準確率(mAcc)。為了評估在對象檢測上的性能,我們報告了平均精度(mAP)、推理速度(FPS)和模型大小(參數),遵循[43]中的工作。
實現細節。對于語義分割,教師網絡在所有實驗中都是使用ResNet 101(PSPNet-R101)作為骨干網絡的PSPNet。我們采用了幾種不同的架構,包括PSPNet[48]、使用ResNet18和MobileNetV2作為骨干網絡的Deeplab[44]作為學生網絡,以驗證我們方法的有效性。
在消融研究中,我們基于以ResNet 18為骨干網絡的PSPNet(PSPNet-R18)來分析我們方法的有效性。除非另有說明,學生網絡的每張訓練圖像都被隨機裁剪為 512 × 512 512 \times 512 512×512像素。批處理大小設置為8,訓練步數設置為 40 K 40 \text{K} 40K。在所有實驗中,我們設置溫度參數 T = 4 \mathcal{T}=4 T=4,對于logits圖的損失權重 α = 3 \alpha=3 α=3,對于特征圖的損失權重 α = 50 \alpha=50 α=50。對于對象檢測,我們采用與[43]中相同的教師網絡、學生網絡和訓練設置。
4.2、與最近的知識蒸餾方法比較
為了驗證我們提出的通道蒸餾方法的有效性,我們將我們的方法與以下當前流行的蒸餾方法進行了比較:
- 注意力轉移(Attention Transfer, AT) [42]:Sergey等人計算每個空間位置所有通道的和,以獲得單個通道注意力圖。他們使用 L 2 L_{2} L2?損失來最小化注意力圖之間的差異。
- 局部親和力(Local Affinity, LOCAL) [35]:對于每個像素,構建一個局部相似度圖,該圖考慮了該像素與其8個鄰域像素之間的相關性。同樣,使用 L 2 L_{2} L2?損失來最小化局部親和力圖之間的差異。
- 像素級蒸餾(Pixel-wise Distillation, PI) [25,24,34,7]:使用KL散度來對齊兩個網絡中每個空間位置的分布。
- 成對蒸餾(Pair-wise Distillation, PA) [25,14,24]:考慮了所有像素對之間的相關性。
- 類內特征變化蒸餾(Intra-class Feature Variation Distillation, IFVD) [34]:將每個像素的特征與其對應的類原型之間的相似度集合視為類內特征變化,以傳遞結構知識。
- 全局蒸餾(Holistic Distillation, HO) [25,24,34]:通過鑒別器計算特征圖的全局嵌入,用于最小化高階關系之間的差異。
我們在內部特征圖和最終logits圖上應用了所有這些流行的蒸餾方法。在所有實驗中,都應用了傳統的交叉熵損失。表2報告了空間蒸餾方法的計算復雜度和性能。
給定的輸入特征圖(logits圖)的大小為 h f × w f × c ( h s × w s × n ) h_{f} \times w_{f} \times c\left(h_{s} \times w_{s} \times n\right) hf?×wf?×c(hs?×ws?×n),其中 h f ( h s ) × w f ( w s ) h_{f}\left(h_{s}\right) \times w_{f}\left(w_{s}\right) hf?(hs?)×wf?(ws?) 是特征圖(logits圖)的形狀。 c c c 是通道數, n n n 是類別數。
如表2所示,所有蒸餾方法都能提高學生網絡的性能。我們的通道蒸餾方法在所有空間蒸餾方法中表現最好。我們的方法比最佳的空間蒸餾方法(AT)高出2.5%。此外,我們的方法更加高效,因為它在訓練階段需要的計算成本比其他方法更少。
此外,我們在表3中列出了我們的方法與兩種最近的先進方法PA [25]和IFVD [18]的詳細類別IoU(Intersection over Union,交并比)。這些方法旨在在語義分割中轉移結構信息。我們的方法顯著提高了多個對象的類別準確性,如交通燈、地形、墻壁、卡車、公共汽車和火車,這表明通道分布可以很好地轉移結構知識。
4.3、消融研究
在本節中,我們展示了通道蒸餾的有效性,并討論了語義分割中超參數的選擇。基線學生模型是PSPNet-R18,教師模型是PSPNet-R101。所有結果均在Cityscapes驗證集上進行評估。
通道蒸餾的有效性。歸一化的通道概率圖和不對稱KL散度在我們的蒸餾方法中起著重要作用。我們通過四種不同的變體進行實驗,以展示表4中提出的方法的有效性。
所有蒸餾方法都應用于相同的激活圖作為輸入,并且我們使用與第4.1節中描述的相同的訓練方案。
'PI’代表像素級知識蒸餾,它對每個空間位置的激活進行歸一化。' L 2 w / o N O R M L2 w/o NORM L2w/oNORM’表示我們直接最小化來自兩個網絡的特征圖之間的差異,這種方法在所有通道的所有位置都平等地考慮差異。'Bhat’是Bhattacharyya距離[3],它是一個對稱分布度量,用于對齊每個通道中的差異。
從表4中我們可以看到,使用不對稱KL散度來衡量歸一化通道差異的方法取得了最佳性能。請注意,由于KL散度是不對稱的,因此學生和教師的輸入不能互換。我們嘗試在KL散度中改變輸入的順序,但訓練并沒有收斂。
溫度參數和損失權重的影響。我們通過在不同的損失權重α下調整溫度參數 T \mathcal{T} T來改變通道概率圖。實驗在logits圖上進行。結果如圖3所示。
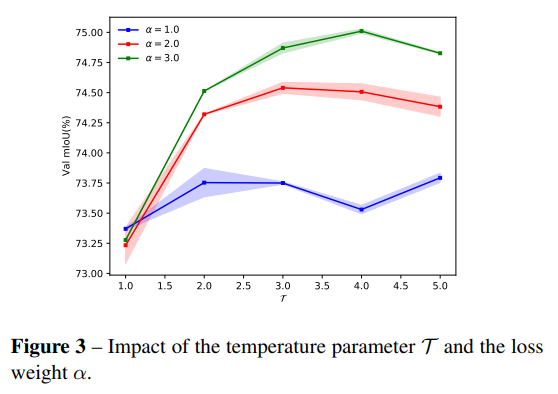
所有結果都是三次運行的平均值。損失權重設置為1, 2, 3,而 T ∈ [ 1 , 5 ] \mathcal{T} \in [1,5] T∈[1,5]。如果我們增加 T \mathcal{T} T,則分布會變得更軟。
從圖中可以看出,較軟的概率圖可能有助于知識蒸餾。此外,在一定范圍內,性能是穩定的。如果 T \mathcal{T} T設置得太小,性能似乎會下降。在這種情況下,該方法僅關注有限的顯著像素。我們在Cityscapes驗證集上使用PSPNet 18時,在 T \mathcal{T} T=4和 α = 3 \alpha=3 α=3時取得了最佳性能。
4.4、語義分割
我們展示了所提出的通道蒸餾方法可以與其他先前的語義分割蒸餾方法相結合,即用于分割/密集預測的結構知識蒸餾(SKDS [24] 和 SKDD [25])以及類內特征變化蒸餾(IFVD [34]),并且適用于各種學生網絡。
我們在logits圖(Ours-logits)和特征圖(Ours-feature)上都使用了所提出的通道蒸餾。同時,根據先前的方法[25,18],我們也包括了logits圖上的像素級蒸餾(PI)和整體蒸餾(HO)。
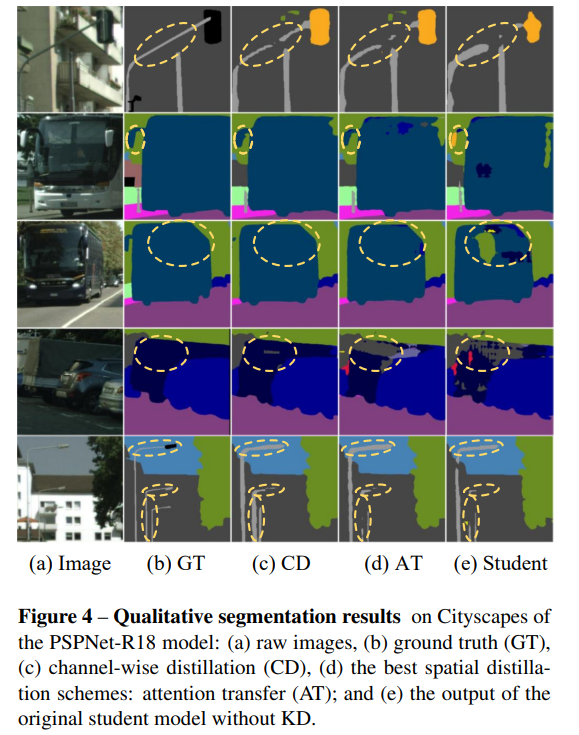
我們首先在Cityscapes數據集上評估了我們方法的性能。使用不同編碼器和解碼器的各種學生網絡來驗證我們方法的有效性。編碼器包括ResNet18(在ImageNet上預訓練權重進行初始化,以及通道減半的ResNet18變體[13]),解碼器包括PSPhead [48]和ASPPhead [6]。表5展示了在Cityscapes上的結果。Pascal VOC [10]和ADE20K [49]上的實驗結果在補充材料中給出。
我們的方法在五個學生網絡和三個基準測試中均優于SKD和IFVD,這進一步表明通道蒸餾在語義分割中是有效的。
對于與教師具有相同架構類型的學生,即 PSPNet-R 1 8 ° ( 0.5 ) \text{PSPNet-R} 18^{\circ}(0.5) PSPNet-R18°(0.5), PSPNet-R 1 8 ° \text{PSPNet-R} 18^{\circ} PSPNet-R18° 和 PSPNet-R18 ? \text{PSPNet-R18}^{\star} PSPNet-R18?,改進更為顯著。對于與教師架構類型不同的學生,即 Deeplab-R 1 8 ° ( 0.5 ) \text{Deeplab-R} 18^{\circ}(0.5) Deeplab-R18°(0.5) 和 Deeplab-R18 ? \text{Deeplab-R18}^{\star} Deeplab-R18?,我們的方法與SKDS和IFVD相比也實現了一致的改進。因此,我們的方法能夠很好地適用于不同的教師和學生網絡。
緊湊模型容量的學生網絡( PSPNet-R18 ° ( 0.5 ) \text{PSPNet-R18}^{\circ}(0.5) PSPNet-R18°(0.5))顯示出比容量更大的學生( PSPNet-R18 ? \text{PSPNet-R18}^{\star} PSPNet-R18?)更差的蒸餾性能( 68.57 % 68.57\% 68.57% vs 75.90 % 75.90\% 75.90%)。這可能是因為小網絡的能力與教師網絡相比有限,無法充分吸收當前任務的知識。對于 PSPNet-R18 \text{PSPNet-R18} PSPNet-R18,使用在ImageNet上訓練的權重進行初始化的學生獲得了最好的蒸餾性能(從 70.09 % 70.09\% 70.09%提高到 75.90 % 75.90\% 75.90%),進一步證明了良好的初始化參數有助于蒸餾。因此,更好的學生會帶來更好的蒸餾性能,但隨著教師和學生網絡之間的差距減小,這種改進變得不那么顯著。
4.5、目標檢測
我們也將我們的通道蒸餾方法應用于目標檢測任務。實驗在MS COCO2017 [23]上進行。
為了驗證我們方法的有效性,我們使用了不同范式下的各種學生網絡,即基于錨點的兩階段方法(Faster RCNN [28])、基于錨點的一階段方法(RetinaNet [21])和無錨點方法(RepPoints [37])。為了進行公平的比較,我們使用了與[43]中相同的教師和相同的超參數進行實驗。
唯一的改動是將特征對齊改為了我們的通道蒸餾。表6報告了實驗結果。從表中可以看出,我們的方法在強大的基線學生網絡上實現了一致的改進(大約提高了 3.4 % 3.4\% 3.4%的mAP)。與先前的最先進蒸餾方法[43]相比,我們簡單的通道蒸餾表現得更好,尤其是在無錨點方法上。我們提高了RepPoints的性能 3.4 % 3.4\% 3.4%,而Zhang等人只提高了 2 % 2\% 2%。此外,我們可以看到所提出的蒸餾方法能更顯著地提高 A P 75 AP_{75} AP75?。
5、結論
在本文中,我們為密集預測任務提出了一種新穎的通道蒸餾方法。與先前的空間蒸餾方法不同,我們將每個通道的激活值歸一化為概率圖。然后,應用非對稱KL散度來最小化教師網絡和學生網絡之間的差異。實驗結果表明,所提出的蒸餾方法在四個公共基準數據集上,對于不同網絡主干結構的語義分割和目標檢測任務,均一致優于現有的最先進蒸餾方法。
此外,我們的消融實驗證明了通道蒸餾的有效性和效率,并且它可以進一步補充空間蒸餾方法。我們希望所提出的簡單而有效的蒸餾方法能夠作為許多其他密集預測任務(包括實例分割、深度估計和全景分割)中有效訓練緊湊網絡的有力基線。
附錄
A、在Pascal VOC和ADE20K上的結果
為了進一步證明所提出的通道分布蒸餾(CD)的有效性,我們僅在Pascal VOC和ADE20K的特征圖上應用所提出的CD作為最終結果。實驗結果分別在表7和表8中報告。我們使用了具有不同編碼器和解碼器的多個學生網絡變體來驗證我們方法的有效性。這里,編碼器包括ResNet18和MobileNetV2,解碼器包括PSPhead和ASPP-head。
Pascal VOC。我們在Pascal VOC數據集上評估了我們方法的性能。蒸餾結果列在表7中。我們提出的CD提高了無蒸餾的PSPNet-R18性能 3.83 % 3.83\% 3.83%,在SKDS和IFVD的基礎上分別提升了 1.51 % 1.51\% 1.51%和 1.21 % 1.21\% 1.21%。在使用不同編碼器和解碼器的其他學生網絡上,我們也取得了一致的改進。使用我們的方法,PSPNet-MBV2的增益為 3.55 % 3.55\% 3.55%,在SKDS和IFVD的基礎上分別提升了 1.98 % 1.98\% 1.98%和 1.20 % 1.20\% 1.20%。對于Deeplab-R18,我們的CD將學生網絡從 66.81 % 66.81\% 66.81%提升至 69.97 % 69.97\% 69.97%,在SKDS和IFVD的基礎上分別提升了 1.84 % 1.84\% 1.84%和 1.55 % 1.55\% 1.55%。此外,使用我們的蒸餾方法,Deeplab-MBV2的性能從 50.80 % 50.80\% 50.80%提升至 54.62 % 54.62\% 54.62%,在SKDS和IFVD的基礎上分別提升了 2.51 % 2.51\% 2.51%和 1.23 % 1.23\% 1.23%。
ADE20K。我們也在ADE20K數據集上評估了我們的方法,以進一步證明CD比其他結構知識蒸餾方法更有效。結果如表8所示。我們提出的CD將無蒸餾的PSPNetR18提升了 3.83 % 3.83\% 3.83%,并在多個方面分別超越了SKDS和IFVD 1.51 % 1.51\% 1.51%和 1.21 % 1.21\% 1.21%。對于具有不同編碼器和解碼器的其他學生網絡,也始終實現了顯著的性能提升。對于PSPNetMBV2,我們的方法取得了 27.97 % 27.97\% 27.97%的卓越性能,分別比學生網絡、SKDS和IFVD提升了 4.82 % 4.82\% 4.82%、 3.18 % 3.18\% 3.18%和 2.64 % 2.64\% 2.64%。使用我們的CD,Deeplab-R18的增益為 2.48 % 2.48\% 2.48%,分別超越了SKDS和IFVD 1.85 % 1.85\% 1.85%和 0.84 % 0.84\% 0.84%。最后,使用我們的通道蒸餾,Deeplab-MBV2的性能從 24.98 % 24.98\% 24.98%提高到 29.18 % 29.18\% 29.18%,分別比SKDS和IFVD提升了 3.08 % 3.08\% 3.08%和 1.93 % 1.93\% 1.93%。
B、更多的可視化結果
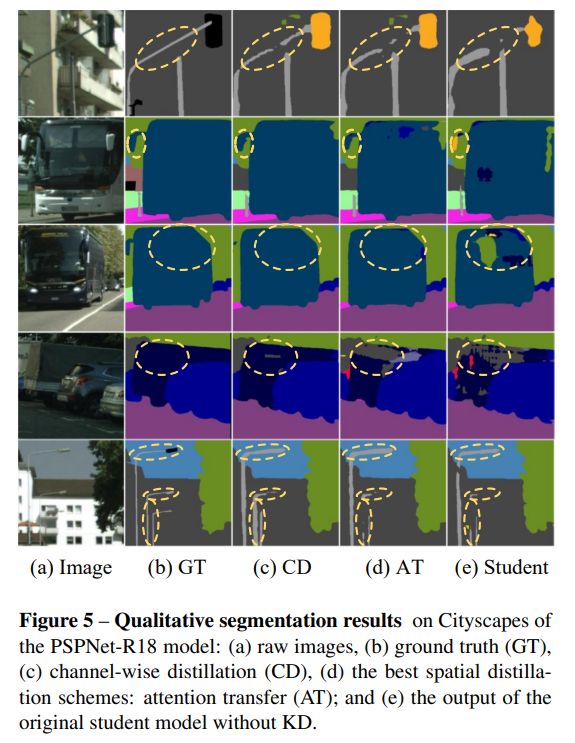
我們在圖6中列出了可視化結果,以直觀地展示通道分布蒸餾方法(CD)優于空間蒸餾策略(注意力轉移)。此外,為了評估所提出的通道分布蒸餾的有效性,我們在圖7和圖8中可視化了三種范式下學生網絡的通道分布,即原始網絡、通過注意力轉移(AT)蒸餾和通過通道分布蒸餾分別蒸餾的網絡。


官方結果
蒸餾結果
Validating runs\detect\train6\weights\best.pt...
Ultralytics YOLOv8.2.20 🚀 Python-3.11.5 torch-2.1.2 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
YOLOv8n summary (fused): 168 layers, 3011888 parameters, 0 gradients, 8.1 GFLOPsClass Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:02<00:00, 7.24it/s]all 230 1412 0.889 0.76 0.876 0.563c17 230 131 0.933 0.952 0.975 0.758c5 230 68 0.952 0.838 0.952 0.739helicopter 230 43 0.836 0.814 0.842 0.477c130 230 85 0.921 0.828 0.925 0.612f16 230 57 0.859 0.749 0.823 0.49b2 230 2 1 0 0.995 0.201other 230 86 0.6 0.86 0.822 0.393b52 230 70 0.916 0.933 0.967 0.746kc10 230 62 0.968 0.966 0.98 0.77command 230 40 0.909 0.9 0.978 0.768f15 230 123 0.938 0.743 0.924 0.583kc135 230 91 0.801 0.842 0.912 0.603a10 230 27 0.675 0.296 0.616 0.22b1 230 20 1 0.833 0.923 0.441aew 230 25 0.92 0.92 0.971 0.753f22 230 17 0.621 0.77 0.692 0.472p3 230 105 0.995 0.962 0.993 0.784p8 230 1 0.769 1 0.995 0.497f35 230 32 0.897 0.547 0.827 0.373f18 230 125 0.972 0.992 0.991 0.768v22 230 41 0.926 0.909 0.957 0.601su-27 230 31 0.92 1 0.995 0.777il-38 230 27 0.864 0.926 0.95 0.654tu-134 230 1 1 0 0.0711 0.0497su-33 230 2 1 0 0.595 0.303an-70 230 2 0.838 1 0.995 0.721tu-22 230 98 0.969 0.939 0.986 0.653
Speed: 0.1ms preprocess, 1.4ms inference, 0.0ms loss, 1.2ms postprocess per image
Results saved to runs\detect\train6







)



)
筆記本電腦原裝出廠Windows11系統鏡像安裝包下載)






