1. 層
層是一個將輸入數據轉換為輸出數據的神經網絡組件。每個層都會對輸入數據進行一定的操作,例如線性變換、非線性激活函數等,以產生輸出數據。
torch.nn模塊提供了各種預定義的層,如線性層、卷積層、池化層等,
- nn.Linear:線性層
- nn.MaxPool2d:二維池化層
- nn.Conv2d:二維卷積層
- nn.ReLu:激活函數層
也支持基于nn.Module自定義層。
1.1 自定義簡單層
import torch
import torch.nn.functional as F
from torch import nnclass CenteredLayer(nn.Module):def __init__(self):super().__init__()def forward(self, X):return X - X.mean()
這個層的功能是對每個輸入減去均值,運行示例:
layer = CenteredLayer()
layer(torch.FloatTensor([1, 2, 3, 4, 5]))> tensor([-2., -1., 0., 1., 2.])
這個層沒有定義需要訓練的參數,這一類的層往往用于特定的功能轉換,例如數據重排、裁剪、歸一化等。
1.2 定義帶參數的層
使用nn.Parameter來創建需要訓練的參數,以線性全連接層為例
- 需要兩個參數:權重和偏置
- 需要兩個參數in_units和units來指明輸入維度和輸出維度
class MyLinear(nn.Module):def __init__(self, in_units, units):super().__init__()self.weight = nn.Parameter(torch.randn(in_units, units))self.bias = nn.Parameter(torch.randn(units,))def forward(self, X):return torch.matmul(X, self.weight.data) + self.bias.data
實例化MyLinear類實例并用其進行前向傳播計算:
linear = MyLinear(5, 3)
linear(torch.rand(2, 5))> tensor([[ 1.9813, -0.1214, 0.1627],[ 2.6518, -0.8198, 0.6513]])
2. 塊
在神經網絡中,塊可以表示為多個層組成的組件,將多個塊組合能構成復雜的網絡模型。
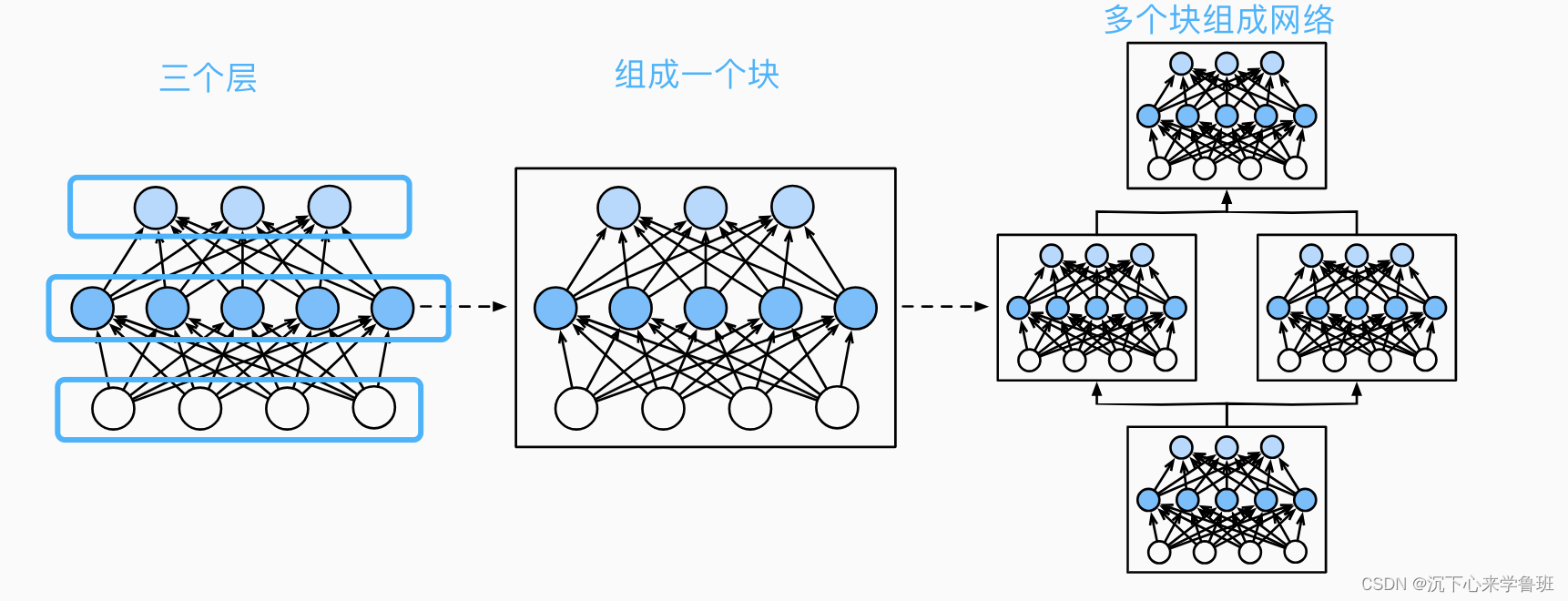
從編程的角度(以pytorch為例),塊也是由繼承nn.Module的類來表示,它必須具有的組成部分:
- 組成塊的層
- 前向傳播函數forward,用于將輸入轉換為輸出;
- 反向傳播函數backward,用于計算梯度;
- 待訓練的參數;
由于pytorch支持反向傳播自動求導,已經由pytorch內部封裝了反向傳播函數的實現,另外pytorch會自動根據層的大小來初始化模型參數w和b,所以我們在定義塊時只需要考慮前向傳播函數和組成塊的層。
2.1 自定義塊
以前一篇文章中的多層感知機為例,可以封裝為一個塊:
class MLP(nn.Module):# 用模型參數聲明層。這里,我們聲明兩個全連接的層def __init__(self):# 調用MLP的父類Module的構造函數來執行必要的初始化。# 這樣,在類實例化時也可以指定其他函數參數,例如模型參數params(稍后將介紹)super().__init__()self.hidden = nn.Linear(20, 256) # 隱藏層self.out = nn.Linear(256, 10) # 輸出層# 定義模型的前向傳播,即如何根據輸入X返回所需的模型輸出def forward(self, X):# 注意,這里我們使用ReLU的函數版本,其在nn.functional模塊中定義。return self.out(F.relu(self.hidden(X)))
2.2 組合塊
前篇文章用到的nn.Sequential其實也是一個塊,只不過它的作用是將其它塊按順序組合到一起,形成一個串行執行的有序列表。
class MySequential(nn.Module):def __init__(self, *args):super().__init__()for idx, module in enumerate(args):# module是Module子類的一個實例,這里將它保存在'Module'類型的成員變量_modules中,_modules的類型是OrderedDictself._modules[str(idx)] = moduledef forward(self, X):# OrderedDict保證了按照成員添加的順序遍歷它們for block in self._modules.values():X = block(X)return X
每個nn.Module都有一個內置的_modules屬性,目的是方便系統查找需要初始化參數的子塊
3. 參數管理
訓練模型的目的是為了找到使損失函數最小化的模型參數值,這個訓練過程就如同我們調試程序一樣,有時候需要打印中間結果以輔助我們進行問題的分析和診斷,所以我們有必要知道如何訪問參數。
3.1 參數訪問
當通過Sequential類定義模型時, 我們可以通過索引來訪問模型的任意層,通過每層的state_dict()來獲取該層的參數。
print(net[2].state_dict())
OrderedDict([('weight', tensor([[-0.0427, -0.2939, -0.1894, 0.0220, -0.1709, -0.1522, -0.0334, -0.2263]])), ('bias', tensor([0.0887]))])
可以看出,該層包含權重weight和偏置bias兩個參數。
我們還可以直接訪問權重或偏置。
print(type(net[2].weight)) # 類型
print(net[2].weight) # 直接訪問參數,包含參數值和梯度信息
print(net[2].weight.data) # 訪問參數值
# print(net[2].weight.grid) # 訪問參數的梯度,還沒有訓練,所以梯度還沒值
<class 'torch.nn.parameter.Parameter'>
Parameter containing:
tensor([[ 0.0986, 0.2894, 0.3461, 0.2734, -0.3395, -0.0719, -0.3348, -0.0305]],requires_grad=True)
tensor([[ 0.0986, 0.2894, 0.3461, 0.2734, -0.3395, -0.0719, -0.3348, -0.0305]])
3.2 嵌套塊參數訪問
我們可以將多個塊相互嵌套,組成更大的塊。
- block1有4層, linear, relu, linear, relu
- block2嵌套了3個block1塊
- 最后將block2與一個線性輸出層組合,構成一個網絡
def block1():return nn.Sequential(nn.Linear(4, 2), nn.ReLU(),nn.Linear(2, 4), nn.ReLU())def block2():net = nn.Sequential()# block2中嵌套3個block1for i in range(3):net.add_module(f'block {i}', block1())return netrgnet = nn.Sequential(block2(), nn.Linear(4, 1))
print(rgnet)
這個包含嵌套塊的網絡結構如下:
Sequential((0): Sequential((block 0): Sequential((0): Linear(in_features=4, out_features=2, bias=True)(1): ReLU()(2): Linear(in_features=2, out_features=4, bias=True)(3): ReLU())(block 1): Sequential((0): Linear(in_features=4, out_features=2, bias=True)(1): ReLU()(2): Linear(in_features=2, out_features=4, bias=True)(3): ReLU())(block 2): Sequential((0): Linear(in_features=4, out_features=2, bias=True)(1): ReLU()(2): Linear(in_features=2, out_features=4, bias=True)(3): ReLU()))(1): Linear(in_features=4, out_features=1, bias=True)
)
嵌套塊的參數訪問:
rgnet[0][1][0].bias.data> tensor([ 0.4917, -0.3920])
3.3 參數初始化
對于參數的初始化,不明確指定時,pytorch會使用默認的隨機初始化方法。PyTorch的nn.init模塊也提供了多種可供選擇的預置初始化方法。
- 指定使用正態分布的隨機變量來初始化:
# 定義初始化函數
def init_normal(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, mean=0, std=0.01)nn.init.zeros_(m.bias)
# 使用指定函數對整個網絡的參數進行初始化
net.apply(init_normal)
net[0].weight.data[0], net[0].bias.data[0]> (tensor([-0.0101, -0.0117, -0.0116, -0.0016]), tensor(0.))
- 使用常數進行初始化:
def init_constant(m):if type(m) == nn.Linear:nn.init.constant_(m.weight, 1)nn.init.zeros_(m.bias)
net.apply(init_constant)
net[0].weight.data[0], net[0].bias.data[0]> (tensor([1., 1., 1., 1.]), tensor(0.))
- 對不同的塊使用不同的初始化:
net[0].apply(init_normal)
net[2].apply(init_constant)
print(net[0].weight.data[0])
print(net[2].weight.data)> tensor([ 0.0054, -0.0188, -0.0112, 0.0097])
tensor([[1., 1., 1., 1., 1., 1., 1., 1.]])
4.4 參數綁定
含義:通過將一個層共享,可以實現相同的參數權重用于神經網絡中的多個層。目的在于兩方面:
- 減少模型的參數量:通過共享參數,可以大大減少需要學習的參數數量,從而減小模型的復雜度。
- 加速訓練:參數共享可以減少內存占用和計算量,特別是在具有大量參數的深層網絡中,可以顯著提高計算效率。
下面是一個參數共享的代碼示例:
# 給共享層一個名稱,以便可以引用它的參數
shared = nn.Linear(8, 8)
# 第二層和第四層共享shared層的參數
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(),shared, nn.ReLU(),shared, nn.ReLU(),nn.Linear(8, 1))輸出第二層和第四層指定位置的初始參數,兩者是相同的。
print(net[2].weight.data[0, 0])
print(net[4].weight.data[0, 0])> tensor(-0.0253)
tensor(-0.0253)
修改第二層的參數:
net[2].weight.data[0, 0] = 100
再次輸出第二層和第四層指定位置的參數,兩者都變成了修改后的參數:
print(net[2].weight.data[0, 0])
print(net[4].weight.data[0, 0])> tensor(100.)
tensor(100.)
 —— 基礎概念(0))

:學習框架)

)


—集成炫酷的粒子特效)







 默認QtWidget應用包含什么?)



