目錄
什么是C++呢?
C++的發展史
多了一些吃前來很香的“語法糖”。
語法糖一:命名空間
命名空間有個強大的功能
如何使用
語法糖二:缺省參數
語法糖三:函數重載
語法糖四:引用????????
引用傳參
引用返回
引用和指針的不同點:
語法糖五:內聯函數
內聯函數相比于普通函數的特性
語法糖六:auto關鍵字(C++11)
auto的使用規則
語法糖七:基于范圍的for循環(C++11)
范圍for的語法
范圍for的使用條件
語法八:指針空值nullptr(C++11)
什么是C++呢?
先官方的解釋一下:
C語言是結構化和模塊化的語言,適合處理較小規模的程序。對于復雜的問題,規模較大的程序,需要高度的抽象和建模時,C語言則不合適。
為了解決軟件危機, 20世紀80年代, 計算機界提出了OOP(objectoriented programming:面向對象)思想,支持面向對象的程序設計語言應運而生。
?1982年,Bjarne Stroustrup博士在C語言的基礎上引入并擴充了面向對象的概念,發明了一種新的程序語言。為了表達該語言與C語言的淵源關系,命名為C++。
因此:C++是基于C語言而產生的,它既可以進行C語言的過程化程序設計,又可以進行以抽象數據類型為特點的基于對象的程序設計,還可以進行面向對象的程序設計。
簡而言之:
C++就是本賈尼大佬看不慣C語言,想要創造一門用起來更爽的語言,因此創造了C++。
同時C++也是包含C語言的,因此C語言的所有語法在C++都能使用。

看這位大佬的發量,就大體明白,C++也不是容易搞明白的,因此本文將帶你利用C語言的基礎,走進C++。
C++的發展史
雖然本賈尼是C++之父,但是C++的發展卻不只是犧牲了這位大佬的“發際線”,當然還有其他大佬……
- C with classes(C++前身):引入了類及派生類、公有和私有成員、類的構造和析構、友元、內聯函數、賦值運算符重載等特性。
- C++1.0:增加了虛函數概念,支持函數和運算符的重載,以及引用和常量等。
- C++2.0:提供了面向對象編程的支持,包括保護成員、多重繼承、對象的初始化和抽象類、靜態成員等。
- C++3.0:進一步完善了面向對象特性,引入了模板技術來解決多重繼承產生的二義性問題。
- C++98:作為第一個官方發布的C++標準版本,得到了廣泛的支持,并引入了STL(標準模板庫)。
- C++03:對語言特性進行了小幅修訂,主要是為了減少多異性。
- C++05:引入了TR1,正式更名為C++0x,增加了許多新特性,如正則表達式、基于范圍的for循環等。
- C++11:引入了許多革命性的新特性,如lambda表達式、auto類型推導、標準線程庫等,使C++更像一門現代語言。
- C++14:修復了C++11中的漏洞,并增加了新的特性,如泛型lambda表達式、二進制字面常量等。
- C++17:在C++11的基礎上做了改進,增加了19個新特性,包括static_assert()、Fold表達式等。
- C++20:這是自C++11以來最大的發行版,引入了模塊、協程、范圍、概念等特性,并對已有特性進行了更新。
- C++23:目前正在制定中,預計會進一步擴展和優化C++語言的功能。
總的來說,C++語言從最初的C with classes發展到現在的C++23,歷經多次迭代和更新,不斷豐富和完善其功能,使其成為了一門強大而靈活的高級編程語言。
為什么要學習C++
C++是目前市面上使用最多的語言之一,C/C++一直在語言界穩居前三。

對于操作系統、嵌入式開發、服務端開發、游戲開發,都需要大量的使用C++,因此學習C++非常有必要。
言歸正傳,下面進入C++的正式學習。
開篇就提到,C++相比于C語言是用起來很“爽”的語言,為什么真么說呢,主要是C++補充了C語言的一些語法,可以理解為:
多了一些吃前來很香的“語法糖”。
語法糖一:命名空間
當我們寫一些大型的C語言項目時,大量的變量命名常常會搞得我們頭昏腦脹,不會命名、命名沖突,導致語法錯誤頻出,C++便引入了第一個語法糖:命名空間。
對于C語言的函數,變量的命名我們已經很熟悉,那么C++是如何命名的呢?答案是借助一個關鍵字:namespace。namespace顧名思義就是命名空間的意思,因此namespace可以創建一個命名空間。
舉例:
namespace XXX
{int x = 0;double y = 0.0;
}為了防止命名沖突,我們將變x、y放在命名空間XXX中。需要注意的是,一個獨立的命名空間,花括號的尾部不能有分號!
命名空間有個強大的功能
在C++中,命名空間(namespace)是一種將代碼組織成邏輯塊的機制,它可以包含類、函數、變量、模板、類型別名等。命名空間的主要目的是提供一種組織代碼的方式,以避免命名沖突,尤其是在大型項目中或者當多個庫被一起使用時。
類、函數、變量、模板、類型別名,都可以包含在命名空間中。同時命名空間可以套用命名空間。
如何使用
有了命名空間之后,我們該如何使用命名空間的內容呢?
namespace Test
{int test = 10;int Add(int a, int b){return a + b;}
}我們依靠的是一個操作符:域作用限定符 ::
為什么是域作用限定符呢?“域”即是區域,只要被花括號{ }括起來的空間,都可以看作一塊域,訪問命名空間,需要使用 ::限定符。
三大使用方式
以Test為例
方式一:將命名空間全部展開。
展開是一種授權,授權可以去對應的命名空間查找內部成員。具體實現為using namespace Test;
namespace Test
{int test = 10;int Add(int a, int b){return a + b;}
}using namespace Test; //展開命名空間的所有元素int main()
{printf("%d\n", test);return 0;
}test變量屬于Test命名空間,當展開Test命名空間之后,就可以訪問內部成員。
但是,將命名空間全部展開也是一種危險的行為
namespace Test
{
?? ?int test = 10;
?? ?int Add(int a, int b)
?? ?{
?? ??? ?return a + b;
?? ?}
}
int test = 81;
using namespace Test;
見此代碼,當test函數在全局與Test中同時定義時,就會出現命名沖突。因此無論哪種展開方式(包含下面的方案),展開都不應該出現命名沖突。
方法二:將部分成員展開。
具體實現是using Test :: test;表示展開Test空間中的test變量。using + 空間名字 :: 成員名字。此時仍然可以直接訪問test。
方法三:直接在使用處展開。
格式: 命名空間 :: 成員
namespace Test
{int test = 10;int Add(int a, int b){return a + b;}
}// ::域作用限定符int test = 81;int main()
{printf("%d\n", Test::test);return 0;
}雖然出現兩個test,但是在使用處直接引用,就可以限定去Test空間尋找test變量,而不是去全局。
在工程中,常用的符號一般采用第二種展開方式,不常用的用第三種。
對于C++,有一個標準命名空間,叫做std,常用的函數都在std中。
在C++中,輸出用cout,輸入用cin,換行用endl,這些都定義在std中。
#include <iostream> using std::cout;
using std::cin;
using std::endl;int main()
{int i = 0;cin >> i;cout << i << endl;return 0;
}
<< 流插入運算符 , >>是流提取運算符
那為什么引用頭文件之后,還得展開命名空間呢?
下面是比較標準的解釋:
在C++中,cout?是?iostream?庫?? 中定義的一個對象,用于輸出數據到標準輸出(通常是終端或控制臺)。iostream?庫定義在?std?命名空間中。命名空間是一種將庫名字封裝起來的方法,以避免不同庫中可能存在的名字沖突。
當您在程序中包含?<iostream>?頭文件時,您實際上是包含了?iostream?庫的所有聲明。然而,默認情況下,這些聲明都是在?std?命名空間之內的。因此,如果您直接使用?cout?而不指明它屬于?std?命名空間,編譯器將不知道您所指的?cout?是?std?命名空間中的?cout。
語法糖二:缺省參數
缺省是默認的意思,缺省參數就是指默認的參數,對于C++函數,可以給形參創建一些缺省值,使之成為缺省參數。
#include <iostream> using std::cout;
using std::cin;
using std::endl;void Date(int year = 2024, int month = 5, int day = 9)
{cout << year << " " << month << " " << day << endl;
}int main()
{Date(2022, 11, 13);Date();return 0;
}對于Date函數,給定了一些缺省參數。
程序運行結果:
2022 11 13
2024 5 9
當傳參時,打印結果是參數結果;不傳參時,打印結果是缺省結果。
同時缺省還分為全缺省和半缺省。全缺省是指將所有參數都設置為缺省參數;半缺省是指將部分參數設置為缺省參數,但是半缺省有一定規則:參數必須從右往左缺省,且中間不能跳過參數。
多提一嘴,函數的定義應該聲明與定義分離,如果定義在頭文件中,那包含頭文件時,會同時在符號表存在多個函數符號,出現符號沖突,連接錯誤。
缺省函數應該在聲明時給出缺省參數,而不是定義時,原因如下:
缺省參數通常在函數原型(函數聲明)中給出,而不是在函數定義中。函數原型通常位于頭文件中,而函數定義位于源文件中。這樣做的好處是,你可以確保無論函數在哪里被調用,調用者都能看到缺省參數的值。
總結一些缺省的注意點:
void Func(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}語法糖三:函數重載
函數重載真是C++最甜的語法糖之一了,通過對比C與C++,就可以得知。
講解函數重載之前,先講一個笑話,這個笑話就體現了函數重載的思想。
NBA的球員,Lebron曾經在一場比賽中投出10中9的優秀命中率,因此球迷樂呵到“出手十次,一次不進”的笑話。大家可以細細品一品“一次不進”這句話。
void SwapInt(int* pa, int* pb)
{int tmp = *pa;*pa = *pb;*pb = tmp;
}void SwapChar(char* pa, char* pb)
{char tmp = *pa;*pa = *pb;*pb = tmp;
}在使用時:
int main()
{int a = 10;int b = 2;SwapInt(&a, &b);char m = 'a';char f = 'b';SwapChar(&m, &f);return 0;
}C++對于swap的實現:
void Swap(int* pa, int* pb)
{int tmp = *pa;*pa = *pb;*pb = tmp;
}void Swap(char* pa, char* pb)
{char tmp = *pa;*pa = *pb;*pb = tmp;
}
int main()
{int a = 10;int b = 2;Swap(&a, &b);cout << a << " " << b << endl;char m = 'a';char f = 'b';Swap(&m, &f);cout << m << " " << f << endl;return 0;
}可以看到,可以直接使用相同的函數名字,對于不同的參數,函數可以自己去匹配類型。
但是注意函數重載與函數缺省參數同時使用時的沖突問題。
那為什么C不支持函數重載,但是C++支持呢?
那就要從程序的運行階段去分析了。程序的運行階段分為:與處理、編譯、匯編、鏈接,四個階段。
在編譯時,會進行符號匯總;匯編會生成符號表;鏈接會對符號表進行合并與重定位。對于C語言,函數名在生成符號時,往往只是直接利用函數名作為符號,或者只是進行簡單的修飾,因此函數名不能沖突;但是C++卻有一套“獨特的命名規則”,這種命名規則叫做名字修飾(name Mangling)。同時名字修飾也是支持重載的原理。
在Linux下,gcc編譯器可以很明顯的觀察到函數符號的名字修飾規則:
【_Z+函數長度+函數名+類型首字母】
因此構成函數重載時,“類型首字母”的不同,也構成了符號表中符號的不同,不至于在鏈接階段出現鏈接錯誤。
語法糖四:引用????????
先解釋下何為引用,引用就是“取別名”。舉個例子,國足因為在球場的拉跨表現,被球迷人稱為“海參隊”,海參隊就是球迷們對國足的別稱。

int main()
{int a = 10;int& b = a;cout << b << endl;return 0;
}b就是a的一個引用變量,可以理解為b就是a的“別名”,對b進行操作,就可以控制a。
int main()
{int a = 10;int& b = a;++b;cout << a << endl; //打印11return 0;
}int& b = a;
?? ?const int& b = a;
?? ?const int& b = a;
Ⅱ
int a = 0;
int func()
{a = 3;return a;
}int main()
{int b = func();return 0;
}這段代碼的意思是用b接收返回值,b接收的是數值的拷貝。
int a = 0;
int func()
{a = 3;return a;
}int main()
{const int& b = func();return 0;
}這段代碼表示用b作為引用變量,接收函數的返回值,引用變量b是a的一個別稱,可以指向這塊空間。但是為什么b需要被const修飾呢?
這是因為函數在返回的時候,會將返回值傳遞給一個臨時的對象,但是引用不能直接綁定到臨時對象上(臨時對象的生命周期極短),為了防止引用懸空,通常會將引用變量用const修飾,此時這個臨時對象的生命周期也會變長。
引用變量的兩種應用
引用傳參
引用傳參是指用引用變量作為形參,接收實參。再拿Swap函數舉例。
void Swap(int& a, int& b)
{int tmp = a;a = b;b = tmp;
}int main()
{int a = 3, b = 5;Swap(a, b);cout << a << " " << b << endl;return 0;
}既然引用變量只是一個別名,可以指向“本體”,那邊可以用引用變量接收形參,進而修改實參。
引用返回
引用返回是利用引用變量接收引用返回。
先看一段傳值返回的代碼
int Func()
{int n = 3;return n;
}int main()
{int a = Func();return 0;
}a的值是多少呢?a = 3,其過程是,先將n傳給一個臨時的對象,a再接收臨時對象的值。
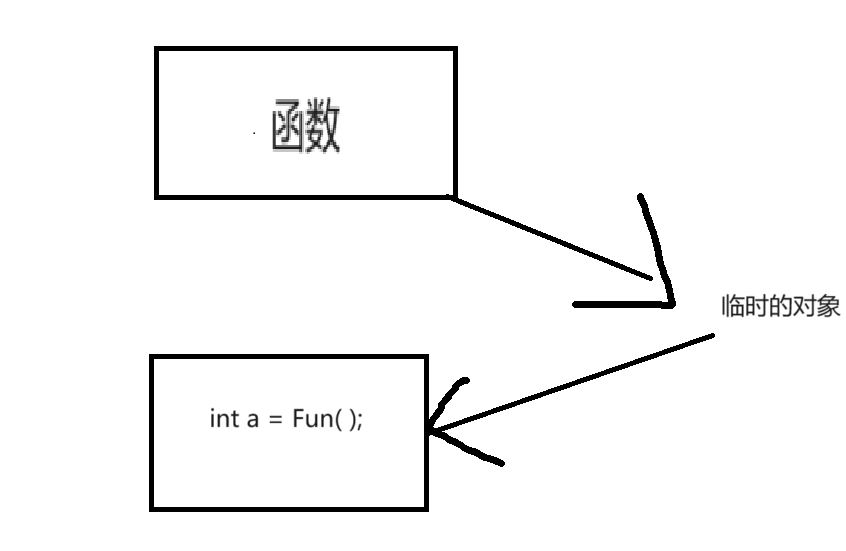
傳值返回用值接收
再看引用返回的代碼
int& Add(int x, int y)
{int z = x + y;return z;
}int main()
{int& a = Add(3, 5);Add(2, 2);cout << a << endl; // 打印 4 return 0;
}引用返回是用引用變量接收函數的返回值(返回類型之后需要加一個&,表示引用返回),傳引用返回用引用變量接收
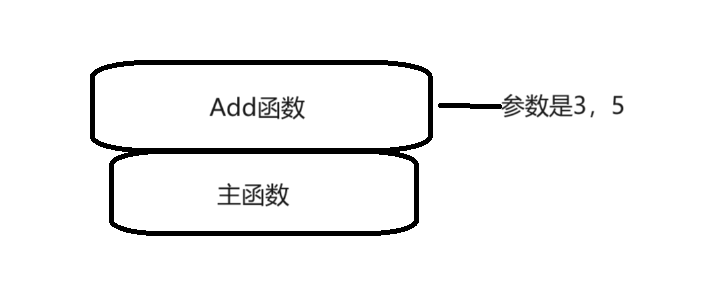
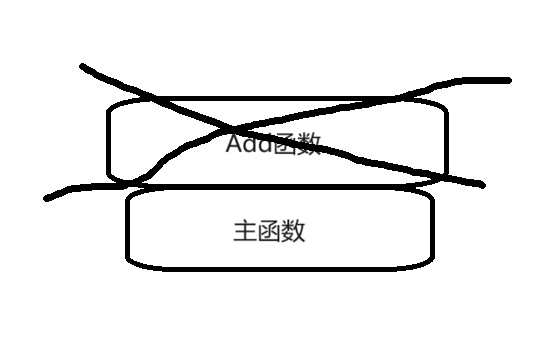
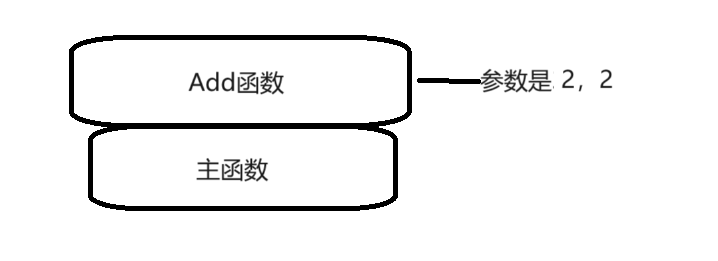
C++中int& 函數利用引用返回時,只能使用引用變量接收嗎
在C++中,使用引用作為函數返回類型時,通常情況下,返回的是某個變量的別名,而不是一個獨立的變量。因此,通常你確實需要使用一個引用變量來接收這個返回值,以便于直接對原始變量進行操作。
因此,在使用引用返回時,一定要注意返回變量會不會出函數留存。
引用傳參與引用返回的優點
引用傳參(何時都可以使用)
1.提高函數效率
2.輸出型參數的修改(如力扣題目returnSize的修改)
引用返回(出函數對象的作用還在,方可使用)
1.提高效率
2.修改返回對象。
看到這里,你或許會疑問,怎么引用與指針如此相似,引用在語法上不會占用空間,其實引用在底層和指針都是一樣的。
引用與指針好比是大眾與保時捷,在很多時候,往往保時捷的發動機等配置與大眾是一樣的,只不過在外部的外觀不一樣。
引用和指針的不同點:
1. 引用概念上定義一個變量的別名,指針存儲一個變量地址。
2. 引用在定義時必須初始化,指針沒有要求
3.引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何
一個同類型實體
4. 沒有NULL引用,但有NULL指針
5. 在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32
位平臺下占4個字節)
6. 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小
7. 有多級指針,但是沒有多級引用
8. 訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理
9. 引用比指針使用起來相對更安全
語法糖五:內聯函數
C++們在使用C語言的宏時,發現了宏(宏常量、宏函數)有大量的弊端:
1.沒有安全類型的檢查
2.不能調試(預處理階段被替換)
3.可維護性差
因此內聯函數便繼承了宏的優點:
1.具有復用性
2.不需要棧幀的建立(針對頻繁調用的小函數),效率高
同時拒絕了宏的弊端,應運而生。
內聯函數的概念
inline int Add(int x, int y)
{int z = x + y;return z;
}int main()
{int a = Add(3, 5); cout << a << endl; //打印8return 0;
}這便是一個內聯函數的使用。那內聯函數和普通函數有什么區別呢?當然有區別,內聯函數不需要建立棧幀,而是在使用的地方直接展開。
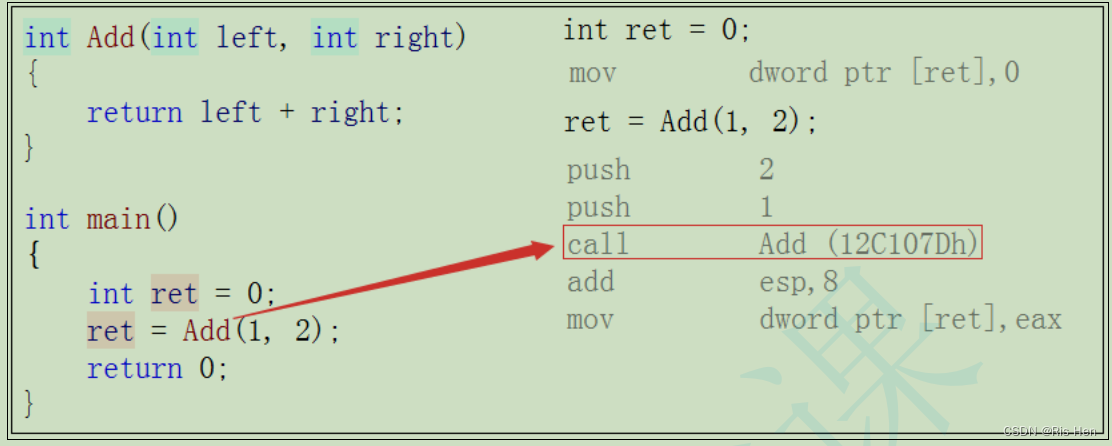
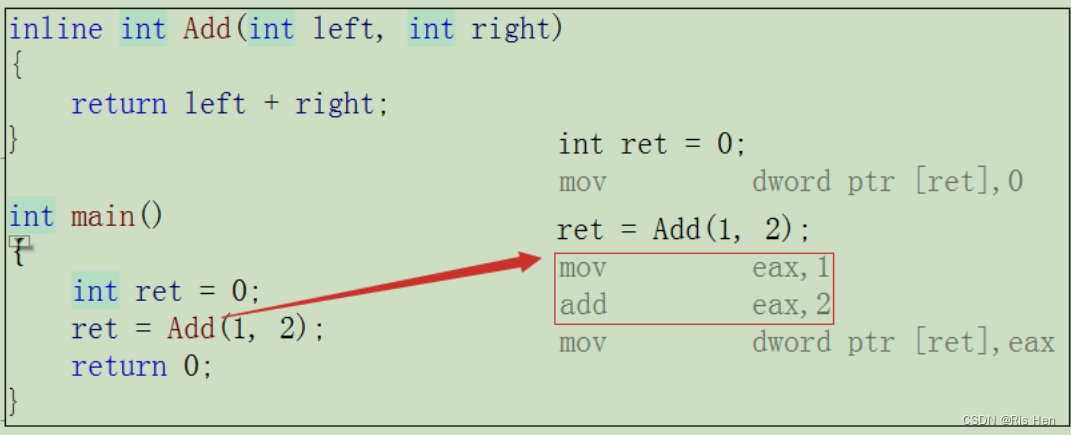
內聯函數相比于普通函數的特性

C++有哪些技術替代宏?
1. 常量定義 換用const enum
2. 短小函數定義 換用內聯函數
語法糖六:auto關鍵字(C++11)
int TestAuto()
{
return 10;
}
int main()
{int a = 10;auto b = a;auto c = 'a';auto d = TestAuto();cout << typeid(b).name() << endl; //打印變量的類型typeid(參數).name()cout << typeid(c).name() << endl; cout << typeid(d).name() << endl;//auto e; 無法通過編譯,使用auto定義變量時必須對其進行初始化return 0;
}auto的使用規則
int main()
{int x = 10;auto a = &x; auto* b = &x; //等價上一行auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;*a = 20;*b = 30;c = 40;cout << x << endl;return 0;
}2.在同一行定義多個變量
語法糖七:基于范圍的for循環(C++11)
范圍for的語法
int main()
{int array[] = { 1, 2, 3, 4, 5 };for (auto& m : array) //此處用引用變量 m ,去不斷指向數組中的元素。m *= 2;for (auto m : array)cout << m << " ";cout << endl;return 0;
}此處必須用引用變量,才能修改數組的元素,&不能漏掉。這也是auto語法的常用場景。
范圍for的強大之處是:1.自動迭代 2.自動判斷結束
范圍for的使用條件
語法八:指針空值nullptr(C++11)
可以看到,這并不是一顆語法糖,而是吃糖吃多了,吃出蛀牙了,此處是填坑。
#ifndef NULL
#ifdef __cplusplus
#define NULL ? 0
#else
#define NULL ? ((void *)0)
#endif
#endif(Java))
)



)


)







。Javaee項目。ssm項目。)
)

)