目錄
一、梯度提升樹?
1、殘差提升樹?Boosting Decision Tree ? ? ??
2、梯度提升樹 Gradient Boosting Decision Tree
二、構建案例
1、?初始化弱學習器(CART樹):
2、 構建第1個弱學習器
3、 構建第2個弱學習器
4、 構建第3個弱學習器
5、 構建最終弱學習器
6、 構建總結
三、XGBoost
1、Xgb的構建思想
2、公式
3、XGBoost關鍵優勢
一、梯度提升樹?
1、殘差提升樹?Boosting Decision Tree ? ? ??
????????思想:通過擬合殘差的思想來進行提升,殘差:真實值 - 預測值
? ? ? ? 例如:

2、梯度提升樹 Gradient Boosting Decision Tree
????????梯度提升樹不再擬合殘差,而是利用梯度下降的近似方法,利用損失函數的負梯度作為提升樹算法中的殘差近似值。

????????GBDT 擬合的負梯度就是殘差。如果我們的 GBDT 進行的是分類問題,則損失函數變為 logloss,此時擬合的目標值就是該損失函數的負梯度值。
二、構建案例
已知:
1、?初始化弱學習器(CART樹):
????????當模型預測值為何值時,會使得第一個弱學習器的平方誤差最小,即:求損失函數對 f(xi) 的導數,并令導數為0。

2、 構建第1個弱學習器
根據負梯度的計算方法得到下表:


以此類推,計算所有切分點情況,得到:
由此得到,當 6.5 作為切分點時,平方損失最小,此時得到第1棵決策樹。
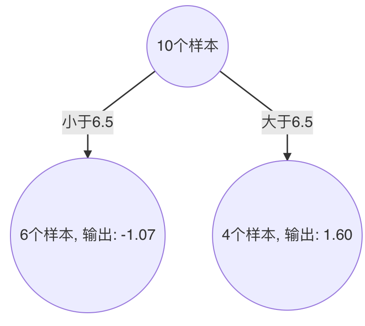
3、 構建第2個弱學習器

以此類推,計算所有切分點情況,得到:

以3.5 作為切分點時,平方損失最小,此時得到第2棵決策樹
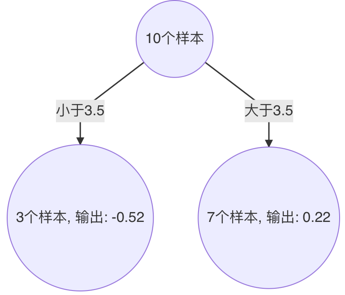
4、 構建第3個弱學習器

以此類推,計算所有切分點情況,得到:

以6.5 作為切分點時,平方損失最小,此時得到第3棵決策樹
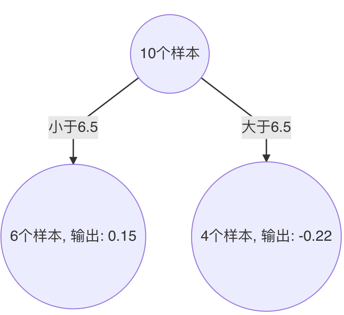
5、 構建最終弱學習器
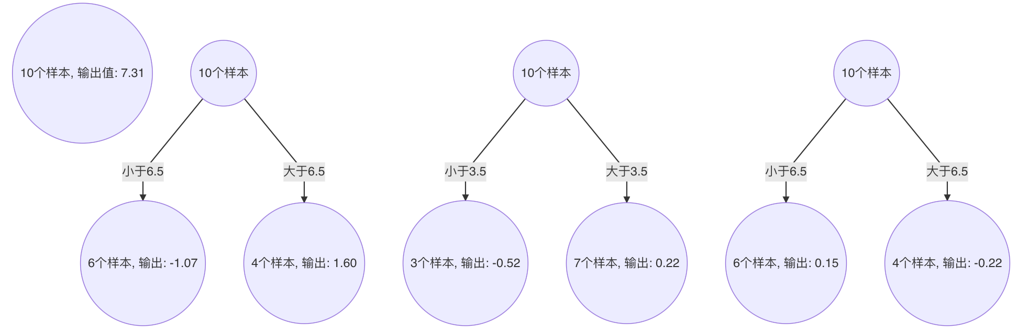
以 x=6 樣本為例:輸入到最終學習器中的結果 :(存在誤差,說明學習器不夠)
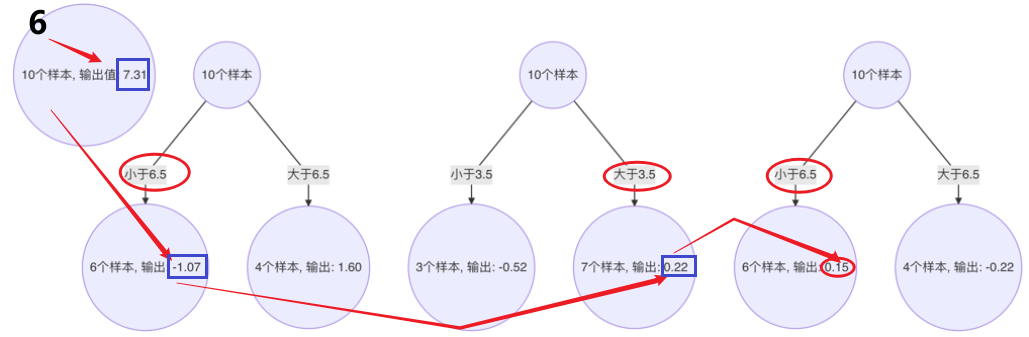
以此類推計算其他的預測值
6、 構建總結
- 初始化弱學習器(目標值的均值作為預測值)
- 迭代構建學習器,每一個學習器擬合上一個學習器的負梯度
- 直到達到指定的學習器個數
- 當輸入未知樣本時,將所有弱學習器的輸出結果組合起來作為強學習器的輸出
三、XGBoost
????????極端梯度提升樹,集成學習方法的王牌,在數據挖掘比賽中,大部分獲勝者用了XGBoost。
1、Xgb的構建思想
????????1、構建模型的方法是最小化訓練數據的損失函數: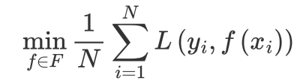
?????????????訓練的模型復雜度較高,易過擬合。
????????2、在損失函數中加入正則化項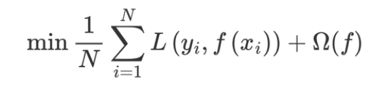 , 提高對未知的測試數據 的泛化性能 。
, 提高對未知的測試數據 的泛化性能 。
2、公式
XGBoost(Extreme Gradient Boosting)是對GBDT的改進,并且在損失函數中加入了正則化項
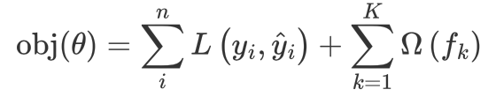
正則化項用來降低模型的復雜度
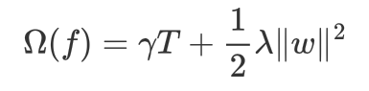
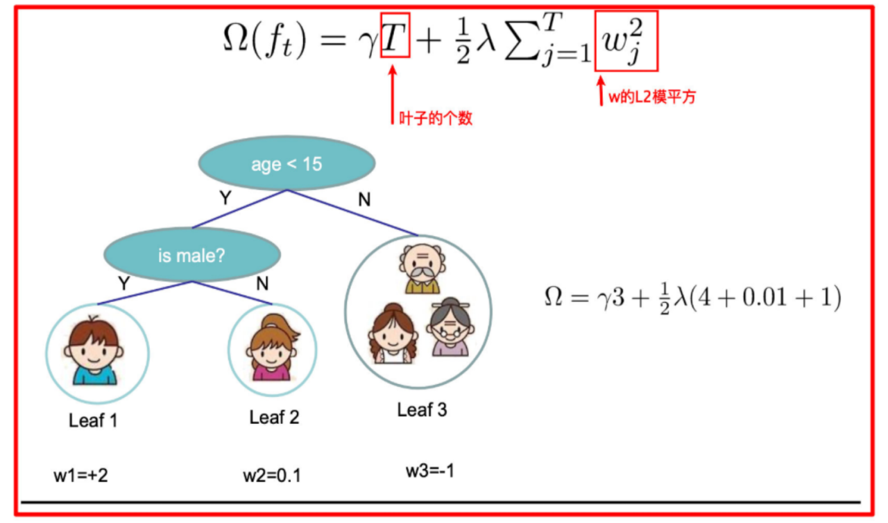
![]() 中的 T 表示一棵樹的葉子結點數量。
中的 T 表示一棵樹的葉子結點數量。
![]() 中的 w 表示葉子結點輸出值組成的向量,
中的 w 表示葉子結點輸出值組成的向量,![]() 向量的模; λ對該項的調節系數
向量的模; λ對該項的調節系數
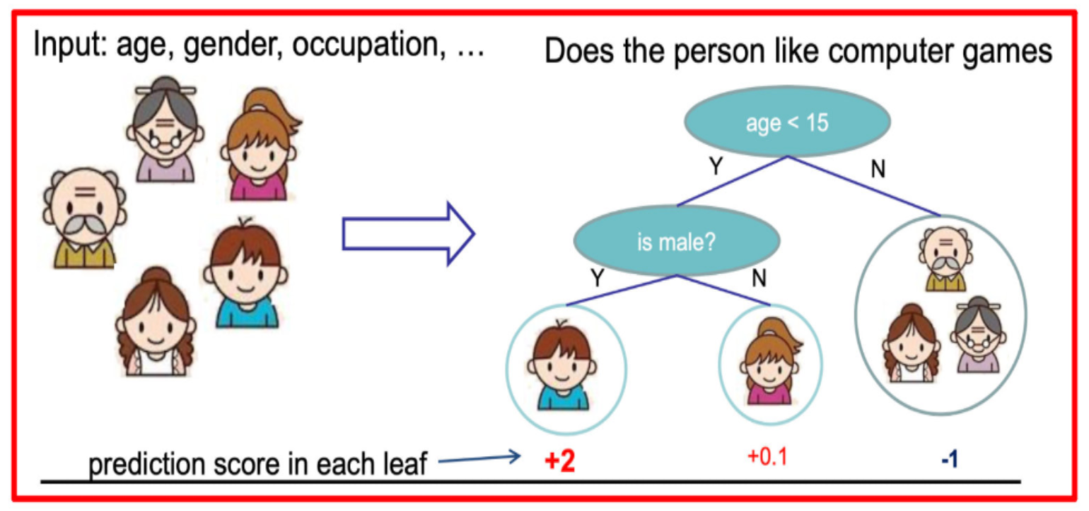
????????假設我們要預測一家人對電子游戲的喜好程度,考慮到年輕和年老相比,年輕更可能喜歡電子游戲,以及男性和女性相比,男性更喜歡電子游戲,故先根據年齡大小區分小孩和大人,然后再通過性別區分開是男是女,逐一給各人在電子游戲喜好程度上打分
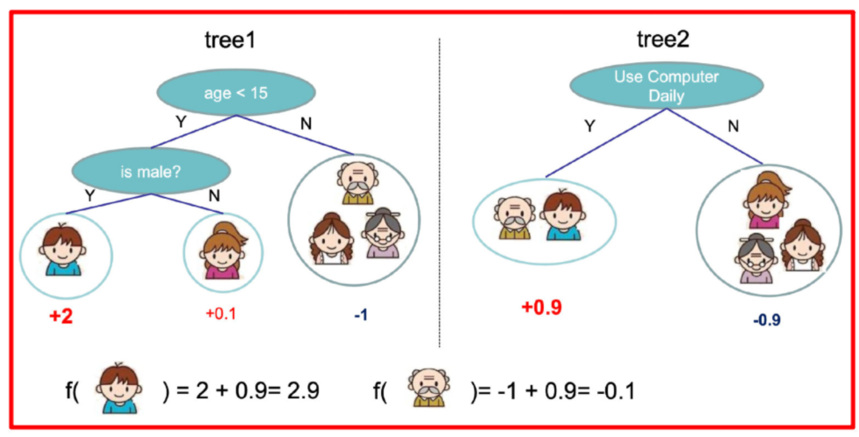
訓練出tree1和tree2,類似之前gbdt的原理,兩棵樹的結論累加起來便是最終的結論
樹tree1的復雜度表示為
以此類推,樹tree2的復雜度表示為
目標函數為:(推導過程比較復雜,可以另行學習)
?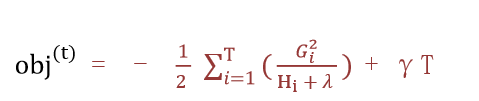

該公式也叫做打分函數 (scoring function),從損失函數、樹的復雜度兩個角度來衡量一棵樹的優劣。當我們構建樹時,可以用來選擇樹的劃分點,具體操作如下式所示:
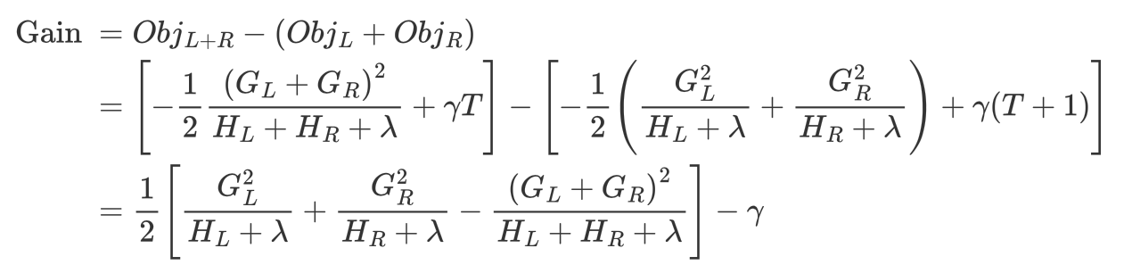
計算的gain值:
1、對樹中的每個葉子結點嘗試進行分裂
2、計算分裂前 - 分裂后的分數:
- 如果gain > 0,則分裂之后樹的損失更小,會考慮此次分裂
- 如果gain< 0,說明分裂后的分數比分裂前的分數大,此時不建議分裂
3、當觸發以下條件時停止分裂:
- 達到最大深度 葉子結點數量低于某個閾值
- 所有的結點在分裂不能降低損失
- 等等...
3、XGBoost關鍵優勢
XGBoost通過多項技術創新實現高效訓練和強大泛化能力:
1、正則化??:在目標函數中加入L1(LASSO)和L2(Ridge)正則化項,懲罰復雜的樹結構(如葉子節點數量過多、權重過大),有效抑制過擬合。
2、??并行處理??:雖然Boosting是串行過程,但XGBoost在特征排序和分裂點選擇上支持并行計算(特征間并行),大幅提升訓練速度。
??3、加權分位法(Weighted Quantile Sketch)??:用于近似尋找最佳分裂點,僅需考察部分候選點,提升大規模數據下的計算效率。
4、??稀疏感知(Sparsity-aware)??:能自動學習處理缺失值的最佳方向(默認分到左子樹或右子樹),無需預先填充,并對稀疏數據(如One-hot編碼)高效處理。
??5、緩存訪問優化(Cache-aware Access)??:通過優化數據存儲和訪問模式(如按塊訪問),提高CPU緩存命中率,加速計算。
6、核外計算(Blocks for Out-of-core)??:當數據無法全部裝入內存時,可將數據分塊存儲在磁盤上,通過塊壓縮和預取(預取到內存緩沖區)技術減少IO開銷,支持大規模數據訓練。
????????XGBoost通過集成學習思想、梯度提升框架,并結合正則化、并行計算、稀疏感知等一系列優化,實現了預測精度與訓練效率的卓越平衡。其靈活性、魯棒性和廣泛適用性使其成為處理結構化數據任務的強有力工具,是許多數據科學家和機器學習實踐者的首選算法之一。

)






:融合Self-Attention的CNN架構)
-- Symbol與集合數據結構)









